嵌入式 C 语言程序数据基本存储结构
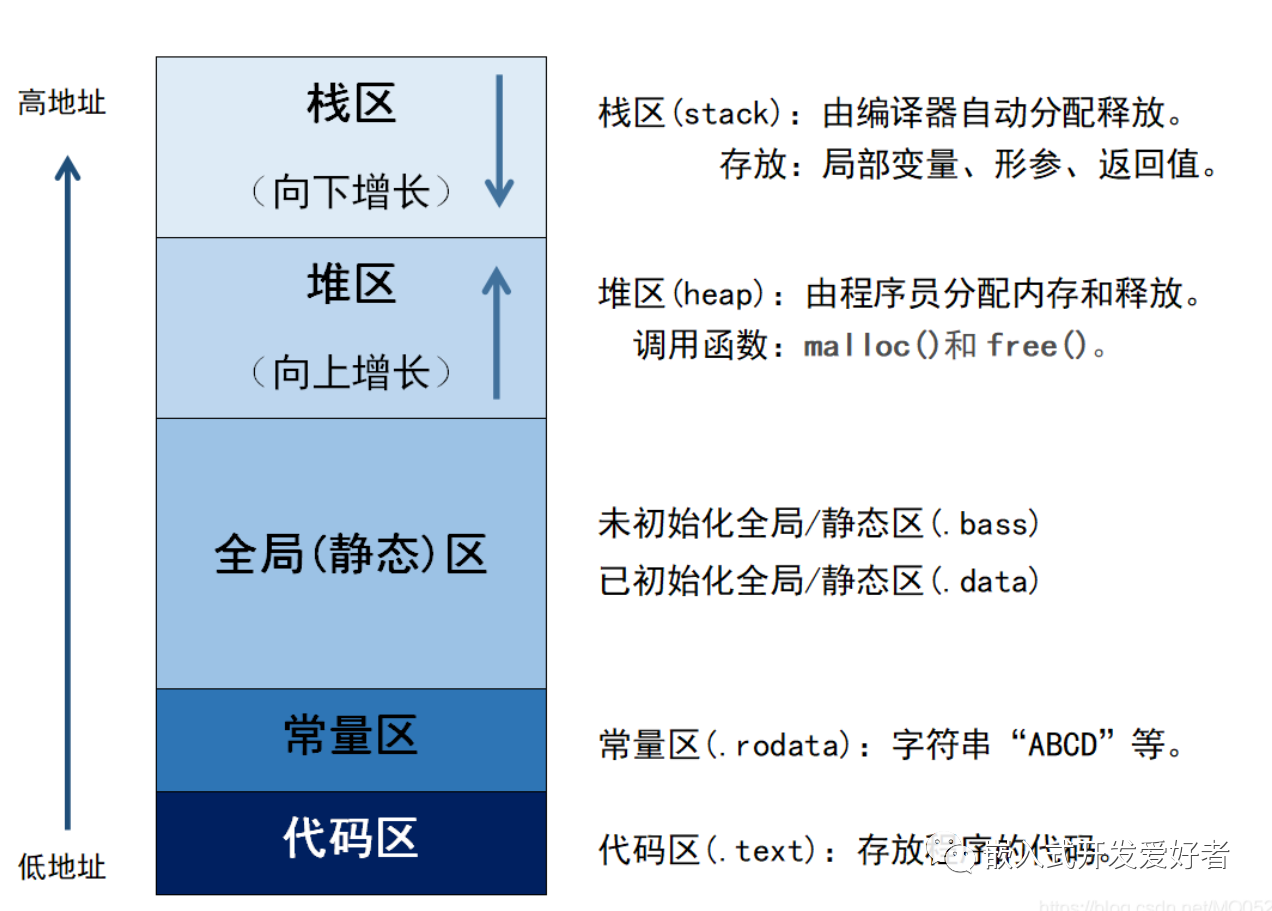
一、5大内存分区
内存分成5个区,它们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
1、栈区(stack):FIFO就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
2、堆区(heap):就是那些由new分配的内存块,它们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3、自由存储区:就是那些由malloc等分配的内存块,它和堆是十分相似的,不过它是用free来结束自己的生命。
4、全局/静态存储区:全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
5、常量存储区:这是一块比较特殊的存储区,它们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多)
内存主要分为代码段,数据段和堆栈。代码段放程序代码,属于只读内存。数据段存放全局变量,静态变量,常量等,堆里存放自己malloc或new出来的变量,其他变量就存放在栈里,堆栈之间空间是有浮动的。数据段的内存会到程序执行完才释放。调用函数先找到函数的入口地址,然后计算给函数的形参和临时变量在栈里分配空间,拷贝实参的副本传给形参,然后进行压栈操作,函数执行完再进行弹栈操作。字符常量一般放在数据段,而且相同的字符常量只会存一份。
二、C语言程序的存储区域
1、由C语言代码(文本文件)形成可执行程序(二进制文件),需要经过编译-汇编-连接三个阶段。编译过程把C语言文本文件生成汇编程序,汇编过程把汇编程序形成二进制机器代码,连接过程则将各个源文件生成的二进制机器代码文件组合成一个文件。
2、C语言编写的程序经过编译-连接后,将形成一个统一文件,它由几个部分组成。在程序运行时又会产生其他几个部分,各个部分代表了不同的存储区域:
1)代码段(Code或Text)
代码段由程序中执行的机器代码组成。在C语言中,程序语句执行编译后,形成机器代码。在执行程序的过程中,CPU的程序计数器指向代码段的每一条机器代码,并由处理器依次运行。
2)只读数据段(RO data)
只读数据段是程序使用的一些不会被更改的数据,使用这些数据的方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
3)已初始化读写数据段(RW data)
已初始化数据是在程序中声明,并且具有初值的变量,这些变量需要占用存储器的空间,在程序执行时它们需要位于可读写的内存区域内,并且有初值,以供程序运行时读写。
4)未初始化数据段(BBS)
未初始化数据是在程序中声明,但是没有初始化的变量,这些变量在程序运行之前不需要占用存储器的空间。
5)堆(heap)
堆内存只在程序运行时出现,一般由程序员分配和释放。在具有操作系统的情况下,如果程序没有释放,操作系统可能在程序(例如一个进程)结束后会后内存。
6)栈(statck)
堆内存只在程序运行时出现,在函数内部使用的变量,函数的参数以及返回值将使用栈空间,栈空间由编译器自动分配和释放。
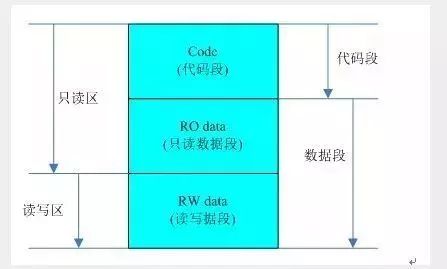
3、代码段、只读数据段、读写数据段、未初始化数据段属于静态区域,而堆和栈属于动区域。代码段、只读数据段和读写数据段将在连接之后产生,未初始化数据段将在程序初始化的时候开辟,而对堆和栈将在程序饿运行中分配和释放。
4、C语言程序分为映像和运行时两种状态。在编译-连接后形成的映像中,将只包含代码段(Text)、只读数据段(R0 Data)和读写数据段(RW Data)。在程序运行之前,将动态生成未初始化数据段(BSS),在程序的运行时还将动态生成堆(Heap)区域和栈(Stack)区域。
1、一般来说,在静态的映像文件中,各个部分称之为节(Section),而在运行时的各个部分称之为段(Segment)。如果不详细区分,统称为段。
2、C语言在编译连接后,将生成代码段(TEXT),只读数据段(RO Data)和读写数据段(RW Data)。在运行时,除了上述三个区域外,还包括未初始化数据段(BBS)区域和堆(heap)区域和栈(Stack)区域。
三、C语言程序的段
1、段的分类
每一个源程序生成的目标代码将包含源程序所需要表达的所有信息和功能。目标代码中各段生成情况如下:
1)代码段(Code)
代码段由程序中的各个函数产生,函数的每一个语句将最终经过编译和汇编生成二进制机器代码
2)只读数据段(RO Data)
只读数据段由程序中所使用的数据产生,该部分数据的特点在运行中不需要改变,因此编译器会将数据放入只读的部分中。C语言的一些语法将生成只读数据数据段。
2、只读数据段(RO Data)
只读数据段(RO Data)由程序中所使用的数据产生,该部分数据的特点是在运行中不需要改变,因此编译器会将数据放入只读的部分中。以下情况将生成只读数据段。
1)只读全局变量
定义全局变量const char a[100]=”abcdefg”将生成大小为100个字节的只读数据区,并使用字符串“abcdefg”初始化。如果定义为const char a[]=”abcdefg”,没有指定大小,将根据“abcdefgh”字串的长度,生成8个字节的只读数据段。
2)只读局部变量
例如:在函数内部定义的变量const char b[100]=”9876543210”;其初始化的过程和全局变量。
3)程序中使用的常量
例如:在程序中使用printf("informationn”),其中包含了字串常量,编译器会自动把常量“information n”放入只读数据区。
注:在const char a[100]={“ABCDEFG”}中,定义了100个字节的数据区,但是只初始化了前面的8个字节(7个字符和表示结束符的‘0’)。在这种用法中,实际后面的字节米有初始化,但是在程序中也不能写,实际上没有任何用处。因此,在只读数据段中,一般都需要做完全的的初始化。
3、读写数据段(RW Data)
读写数据段表示了在目标文件中一部分可以读也可以写的数据区,在某些场合它们又被称为已初始化数据段。这部分数据段和代码,与只读数据段一样都属于程序中的静态区域,但是具有科协的特点。
1)已初始化全局变量
例如:在函数外部,定义全局的变量char a[100]=”abcdefg”
2)已初始化局部静态变量
例如:在函数中定义static char b[100]=”9876543210”。函数中由static定义并且已经初始化的数据和数组将被编译为读写数据段。
说明:
读写数据区的特点是必须在程序中经过初始化,如果只有定义,没有初始值,则不会生成读写数据区,而会定义为未初始化数据区(BSS)。如果全局变量(函数外部定义的变量)加入static修饰符,写成static char a[100]的形式,这表示只能在文件内部使用,而不能被其他文件使用。
4、未初始化数据段(BSS)
未初始化数据段常被称之为BSS(英文名为Block start by symbol的缩写)。与读写数据段类似,它也属于静态数据区。但是该段中数据没有经过初始化。因此它只会在目标文件中被标识,而不会真正称为目标文件中的一个段,该段将会在运行时产生。未初始化数据段只有在运行的初始化阶段才会产生,因此它的大小不会影响目标文件的大小。
四、在C语言的程序中,对变量的使用需要注意的问题:
1、在函数体中定义的变量通常是在栈上,不需要在程序中进行管理,由编译器处理。
2、用malloc,calloc,realoc等分配分配内存的函数所分配的内存空间在堆上,程序必须保证在使用后使用后freee释放,否则会发生内存泄漏
3、所有函数体外定义的是全局变量,加了static修饰符后的变量不管在函数内部或者外部存放在全局区(静态区)。
4、使用const定义的变量将放于程序的只读数据区。
说明:
在C语言中,可以定义static变量:在函数体内定义的static变量只能在该函数体内有效;在所有函数体外定义的static变量,也只能在该文件中有效,不能在其他源文件中使用;对于没有使用 static修饰的全局变量,可以在其他的源文件中使用。这些区别是编译的概念,即如果不按要求使用变量,编译器会报错。使用static 和没使用static修饰的全局变量最终都将放置在程序的全局去(静态去)。
四、程序中段的使用
C语言中的全局区(静态区),实际上对应着下述几个段:
只读数据段:RO Data
读写数据段:RW Data
未初始化数据段:BSS Data
一般来说,直接定义的全局变量在未初始化数据区,如果该变量有初始化则是在已初始化数据区(RW Data),加上const修饰符将放置在只读区域(RO Data).
例如:
const char ro[ ]=”this is a readonlydata”; //只读数据段,不能改变ro数组中的内容,ro存放在只读数据段。
char rw1[ ]=”this is global readwrite data”; //已初始化读写数据段,可以改变数组rw1中的内容。应为数值/是赋值不是把”this is global readwrite data” 地址给了rw1,不能改变char rw1[ ]=”this is global readwrite data”; //已初始化读写数据段,可以改变数组rw1中的内容。应为数值/是赋值不是把”this is global readwrite data” 地址给了rw1,不能改变”this is global readwrite data”的数值。因为起是文字常量放在只读数据段中
char bss_1[100];//未初始化数据段
const char *ptrconst = “constant data”; //”constant data”放在只读数据段,不能改变ptrconst中的值,因为其是地址赋值。ptrconst指向存放“constant data”的地址,其为只读数据段。但可以改变ptrconst地址的数值,因其存放在读写数据段中。
实例讲解:
int main( ){short b;//b放置在栈上,占用2个字节char a[100];//需要在栈上开辟100个字节,a的值是其首地址char s[]=”abcde”;//s在栈上,占用4个字节,“abcde”本身放置在只读数据存储区,占6字节。s是一个地址//常量,不能改变其地址数值,即s++是错误的。char *p1;//p1在栈上,占用4个字节char *p2 ="123456";//"123456"放置在只读数据存储区,占7个字节。p2在栈上,p2指向的内容不能更//改,但是p2的地址值可以改变,即p2++是对的。static char bss_2[100]; //局部未初始化数据段static int c=0 ; //局部(静态)初始化区p1 = (char *)malloc(10*sizeof(char)); //分配的内存区域在堆区strcpy(p1,”xxx”); //”xxx”放置在只读数据存储区,占5个字节free(p1); //使用free释放p1所指向的内存return 0;}
说明:
1、只读数据段需要包括程序中定义的const型的数据(如:const char ro[]),还包括程序中需要使用的数据如“123456”。对于const char ro[]和const char * ptrconst的定义,它们指向的内存都位于只读数据据区,其指向的内容都不允许修改。区别在于前者不允许在程序中修改ro的值,后者允许在程序中修改ptrconst本身的值。对于后者,改写成以下的形式,将不允许在程序中修改ptrconst本身的值:
const char * const ptrconst = “const data”;
2、读写数据段包含了已经初始化的全局变量static char rw1[]以及局部静态变量static char rw2[]。rw1和rw2的差别在于编译时,是在函数内部使用的还是可以在整个文件中使用。对于前者,static修饰在于控制程序的其他文件时候可以访问rw1变量,如果有static修饰,将不能在其他的C语言源文件中使用rw1,这种影响针对编译-连接的特性,但无论有static,变量rw1都将被放置在读写数据段。对于后者rw2,它是局部的静态变量,放置在读写数据区;如果不使用static修饰,其意义将完全改变,它将会是开辟在栈空间局部变量,而不是静态变量。
3、未初始化数据段,事例1中的bss_1[100]和 bss_2[200]在程序中代表未初始化的数据段。其区别在于前者是全局的变量,在所有文件中都可以使用;后者是局部的变量,只在函数内部使用。未初始化数据段不设置后面的初始化数值,因此必须使用数值指定区域的大小,编译器将根据大小设置BBS中需要增加的长度。
4、栈空间包括函数中内部使用的变量如short b和char a[100],以及char *p1中p1这个变量的值。
1)变量p1指向的内存建立在堆空间上,堆空间只能在程序内部使用,但是堆空间(例如p1指向的内存)可以作为返回值传递给其他函数处理。
2)栈空间主要用于以下3类数据的存储:
a、函数内部的动态变量
b、函数的参数
c、函数的返回值
3)栈空间主要的用处是供函数内部的动态变量使用,变量的空间在函数开始之前开辟,在函数退出后由编译器自动回收。看一个例:
int main( ){char *p = "tiger";p[1] = 'I';p++;printf("%sn",p);}
编译后提示:段错误
分析:
char *p = "tiger";系统在栈上开辟了4个字节存储p的数值。"tiger"在只读存储区中存储,因此"tiger"的内容不能改变,*p="tiger",表示地址赋值,因此,p指向了只读存储区,因此改变p指向的内容会引起段错误。但是因为p是存放在栈上,因此p的数值是可以改变的,因此p++是正确的。
五、const的使用
1、前言:
const是一个C语言的关键字,它限定一个变量不允许被改变。使用const在一定程序上可以提高程序的健壮性,另外,在观看别人代码的时候,清晰理解const所起的作用,对理解别人的程序有所帮助。
2、const变量和常量
1)const修饰的变量,其值存放在只读数据段中,其值不能被改变。称为只读变量。
其形式为 const int a=5;此处可以用a代替5
2)常量:其也存在只读数据段中,其数值也不能被改变。其形式为"abc" ,5
3、const 变量和const限定的内容,先看一个事例:
typedef char* pStr;int main( ){char string[6] = “tiger”;const char *p1 = string;const pStr p2 = string;p1++;p2++;printf(“p1=%snp2=%sn”,p1,p2);}
程序经过编译后,提示错误为
error:increment of read-only variable ‘p2’
1)const 使用的基本形式为:const char m;
//限定m 不可变
2)替换1式中的m,const char *pm;
//限定*pm不可变,当然pm是可变的,因此p1++是对的。
3)替换1式中的char,const newType m;
//限定m不可变,问题中的pStr是一种新类型,因此问题中p2不可变,p2++是错误的。
4、const 和指针
类型声明中const用来修饰一个常量,有如下两种写法:
1)const在前面
const int nValue;//nValue是const
const char *pContent;//*pContent是const,pConst可变
const (char *)pContent;//pContent是const,*pContent可变
char *const pContent;//pContent是const,*pContent可变
const char * const pContent;//pContent和*pContent都是const
2)const 在后面与上面的声明对等
int const nValue;// nValue是const
char const *pContent;//*pContent是const, pContent可变
(char *) constpContent;//pContent是const, *pContent可变
char* const pContent;// pContent是const, *pContent可变
char const* const pContent;//pContent和*pContent都是const
说明:const和指针一起使用是C语言中一个很常见的困惑之处,下面是两天规则:
1)沿着*号划一条线,如果const位于*的左侧,则const就是用来修饰指针所指向的变量,即指针指向为常量;如果const位于*的右侧,const就是修饰指针本身,即指针本身是常量。你可以根据这个规则来看上面声明的实际意义,相信定会一目了然。
2)对于const (char *) ; 因为char *是一个整体,相当于一个类型(如char),因此,这是限定指针是const。
六、data、idata、xdata、pdata、code
从数据存储类型来说,8051系列有片内、片外程序存储器,片内、片外数据存储器,片内程序存储器还分直接寻址区和间接寻址类型,分别对应code、data、xdata、idata以及根据51系列特点而设定的pdata类型,使用不同的存储器,将使程序执行效率不同,在编写C51程序时,最好指定变量的存储类型,这样将有利于提高程序执行效率(此问题将在后面专门讲述)。与ANSI-C稍有不同,它只分SAMLL、COMPACT、LARGE模式,各种不同的模式对应不同的实际硬件系统,也将有不同的编译结果。
在51系列中data,idata,xdata,pdata的区别:
data:固定指前面0x00-0x7f的128个RAM,可以用acc直接读写的,速度最快,生成的代码也最小。
idata:固定指前面0x00-0xff的256个RAM,其中前128和data的128完全相同,只是因为访问的方式不同。idata是用类似C中的指针方式访问的。汇编中的语句为:mox ACC,@Rx.(不重要的补充:c中idata做指针式的访问效果很好)
xdata:外部扩展RAM,一般指外部0x0000-0xffff空间,用DPTR访问。
pdata:外部扩展RAM的低256个字节,地址出现在A0-A7的上时读写,用movx ACC,@Rx读写。这个比较特殊,而且C51好象有对此BUG,建议少用。但也有他的优点,具体用法属于中级问题,这里不提。
单片机C语言unsigned char code table[]code 是什么作用?
code的作用是告诉单片机,我定义的数据要放在ROM(程序存储区)里面,写入后就不能再更改,其实是相当与汇编里面的寻址MOVX(好像是),因为C语言中没办法详细描述存入的是ROM还是RAM(寄存器),所以在软件中添加了这一个语句起到代替汇编指令的作用,对应的还有data是存入RAM的意思。
程序可以简单的分为code(程序)区,和data (数据)区,code区在运行的时候是不可以更改的,data区放全局变量和临时变量,是要不断的改变的,cpu从code区读取指令,对data区的数据进行运算处理,因此code区存储在什么介质上并不重要,象以前的计算机程序存储在卡片上,code区也可以放在rom里面,也可以放在ram里面,也可以放在flash里面(但是运行速度要慢很多,主要读flash比读ram要费时间),因此一般的做法是要将程序放到flash里面,然后load到 ram里面运行的;DATA区就没有什么选择了,肯定要放在RAM里面,放到rom里面改动不了。
bdata如何使用它呢?
若程序需要8个或者更多的bit变量,如果你想一次性给8个变量赋值的话就不方便了,(举个例子说说它的方便之处,想更深入的了解请在应用中自己琢磨)又不可以定义bit数组,只有一个方法
char bdata MODE;
sbit MODE_7 = MODE^7;
sbit MODE_6 = MODE^6;
sbit MODE_5 = MODE^5;
sbit MODE_4 = MODE^4;
sbit MODE_3 = MODE^3;
sbit MODE_2 = MODE^2;
sbit MODE_1 = MODE^1;
sbit MODE_0 = MODE^0;
8个bit变量MODE_n 就定义好了
这是定义语句,Keilc 的特殊数据类型。记住一定要是sbit
不能 bit MODE_0 = MODE^0;
赋值语句要是这么写C语言就视为异或运算。
Flash相对单片机里的RAM属于外部存取器,虽其结构位置装在单片机中,其实xdata是放在相对RAM的外面,而flash正是相对RAM外面。
inta变量定义在内部RAM,xdatainta定义在外部RAM或flash,uchar codea定义在flash。
uchar code duma[]={0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x40,0x00}; //共阴的数码管段选,P2口要取的数值。
若定义 uchar aa[5],aa[5]中的内容是存放在数据存储区(RAM)中的,在程序运行工程中各个数组元素的值可以被修改,掉电后aa[5]中的数据无法保存。
若定义 uchar code bb[5]中的内容是存放在程序存储区(如flash)中的,只有在烧写程序时,才能改变bb[5]中的各元素的值,在程序运行工程中无法修改,并且掉电后bb[5]中的数据不消失。
七、C语言中堆和栈的区别
C语言程序经过编译连接后形成编译、连接后形成的二进制映像文件由栈、堆、数据段(由三部分部分组成:只读数据段,已经初始化读写数据段,未初始化数据段即BBS)和代码段组成,如下图所示:
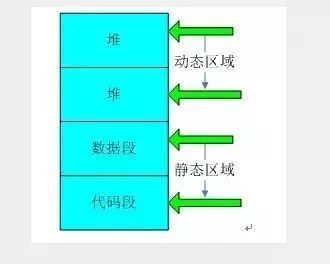
1、栈区(stack):由编译器自动分配释放,存放函数的参数值,局部变量等值。其操作方式类似于数据结构中的栈。
2、堆区(heap):一般由程序员分配释放,若程序员不释放,则可能会引起内存泄漏。注堆和数据结构中的堆栈不一样,其类是与链表。
3、程序代码区:存放函数体的二进制代码。
4、数据段:由三部分组成:
1)只读数据段:
只读数据段是程序使用的一些不会被更改的数据,使用这些数据的方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。一般是const修饰的变量以及程序中使用的文字常量一般会存放在只读数据段中。
2)已初始化的读写数据段:
已初始化数据是在程序中声明,并且具有初值的变量,这些变量需要占用存储器的空间,在程序执行时它们需要位于可读写的内存区域内,并且有初值,以供程序运行时读写。在程序中一般为已经初始化的全局变量,已经初始化的静态局部变量(static修饰的已经初始化的变量)
3)未初始化段(BSS):
未初始化数据是在程序中声明,但是没有初始化的变量,这些变量在程序运行之前不需要占用存储器的空间。与读写数据段类似,它也属于静态数据区。但是该段中数据没有经过初始化。未初始化数据段只有在运行的初始化阶段才会产生,因此它的大小不会影响目标文件的大小。在程序中一般是没有初始化的全局变量和没有初始化的静态局部变量。
堆和栈的区别
1、申请方式
(1)栈(satck):由系统自动分配。例如,声明在函数中一个局部变量int b;系统自动在栈中为b开辟空间。
(2)堆(heap):需程序员自己申请(调用malloc,realloc,calloc),并指明大小,并由程序员进行释放。容易产生memory leak.
eg:charp;
p = (char *)malloc(sizeof(char));//但是,p本身是在栈中。
2、申请大小的限制
1)栈:在windows下栈是向底地址扩展的数据结构,是一块连续的内存区域(它的生长方向与内存的生长方向相反)。栈的大小是固定的。如果申请的空间超过栈的剩余空间时,将提示overflow。
2)堆:堆是高地址扩展的数据结构(它的生长方向与内存的生长方向相同),是不连续的内存区域。这是由于系统使用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由底地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。
3、系统响应:
1)栈:只要栈的空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
2)堆:首先应该知道操作系统有一个记录空闲内存地址的链表,但系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的free语句才能正确的释放本内存空间。另外,找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
说明:对于堆来讲,对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题。
4、申请效率
1)栈由系统自动分配,速度快。但程序员是无法控制的
2)堆是由malloc分配的内存,一般速度比较慢,而且容易产生碎片,不过用起来最方便。
5、堆和栈中的存储内容
1)栈:在函数调用时,第一个进栈的主函数中后的下一条语句的地址,然后是函数的各个参数,参数是从右往左入栈的,然后是函数中的局部变量。注:静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续执行。
2)堆:一般是在堆的头部用一个字节存放堆的大小。
6、存取效率
1)堆:char *s1=”hellowtigerjibo”;是在编译是就确定的
2)栈:char s1[]=”hellowtigerjibo”;是在运行时赋值的;用数组比用指针速度更快一些,指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上读取。
补充:
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
7、分配方式:
1)堆都是动态分配的,没有静态分配的堆。
2)栈有两种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的。它的动态分配是由编译器进行释放,无需手工实现。
相关文章:
嵌入式 C 语言程序数据基本存储结构
一、5大内存分区 内存分成5个区,它们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。 1、栈区(stack):FIFO就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。 …...

记录VS2022离线安装NuGet包的过程
离线安装NuGet包主要分为两个阶段:指定安装源及下载包及其依赖项。本文记录在VS2022中离线安装NuGet包的过程及注意事项。 离线安装NuGet包,主要有两种方式:1)搭建局域网或本机NuGet服务器,将VS2022的源指定为NuGe…...

tomcat的多实例和动静分离
目录 多实例 安装tomcat 配置 tomcat 环境变量 修改server.xml文件 修改开关文件,添加环境变量 tomcat1 tomcat2 启动 浏览器访问测试 nginxtomcat实现动静分离 Nginx实现负载均衡的原理 部署nginx的负载器 搭建第三台tomcat 配置多实例服务器 Tomcat…...

点成案例丨比浊仪用于乳酸菌抑菌活性测定
乳酸菌概述 自1929年英国科学家弗莱明发现青霉素以来,抗生素为人类医学的进步做出了巨大贡献。然而,抗生素在临床上广泛且持续的使用导致病原微生物产生了耐药性。目前,病原微生物对抗生素的耐药性正在威胁人们的健康,寻找具有抑…...

总结synchronized
一.synchronized的特性 synchronized 是 Java 语言中内置的关键字,用于实现线程同步,以确保多线程环境下共享资源的安全访问。 互斥性:synchronized保证了同一时刻只有一个线程可以执行被synchronized修饰的代码块或方法。当一个线程进入sync…...

react实现模拟弹框遮罩的自定义hook
需求描述 点击按钮用于检测鼠标是否命中按钮 代码实现 import React from react; import {useState, useEffect, useRef} from react;// 封装一个hook用来检测当前点击事件是否在某个元素之外 function useClickOutSide(ref,cb) {useEffect(()>{const handleClickOutside…...
直接在html中引入Vue.js的cdn来实现一个简单的博客
摘要 其实建立一个博客系统是非常简单的,有很多开源的程序,如果你不喜欢博客系统,也可以自己开发,也可以自己简单做一个。我这次就是用Vue.js和php做后端服务实现一个简单的博客。 界面 代码结构 代码 index.html <!DOCTYP…...

Android Studio瀑布流实现
效果: ImageDetail class package com.example.waterfallflow; import android.app.Activity; import android.content.Intent; import android.os.Bundle; import android.widget.ImageView;public class ImageDetail extends Activity{Overrideprotected void …...

Java 中的 == 运算符、equals 方法和 hashcode 方法
一、 运算符 是 Java 中的一个运算符,用于比较两个对象,但在比较两个对象的时候需要根据比较类型分情况进行讨论。 1.1 基本数据类型与基本数据类型 基本数据类型之间通过 进行比较的时候,是直接比较它们的大小,而与它们的具体…...

第一个ArkTS项目实践-鸿蒙ArkTS
第一个ArkTS项目实践-ArkTS 第一个ArkTS项目实践-ArkTS自定义组件的组成配置属性与布局配置属性布局 改变组件状态循环渲染列表数据代码ToDoItem组件ToDoList页面 效果参考资料 第一个ArkTS项目实践-ArkTS 本篇文章是官网上视频对ArkTS开发实践的第一个视频,主要是引…...
)
【数据结构•堆】序列和的前n小元素(堆排序)
题目描述 问题:序列和的前 n n n小元素 给出两个长度为 n n n的有序表 A A A和 B B B, 在A和B中各任取一个, 可以得到 n 2 n^2 n2 个和. 求这些和最小的 n n n个。 输入输出格式 输入格式: 输入数据共三行。 第一行,一个整数值 n n …...

Keepalived+http高可用实战
环境准备: 两台安装了keepalived的服务器 ip:192.168.134.170;192.168.134.172 1、安装http服务 yum install httpd -y2、写一个测试页面 [rootlocalhost ~]# echo "hostname -I,web1 test page. " > /var/www/html/inde [rootlocalho…...
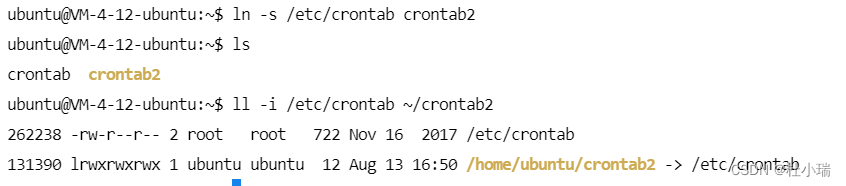
Linux文件系统管理
Linux文件系统管理 磁盘的组成与分区 计算机用于存取文件的硬件是磁盘,磁盘的组成主要有磁盘盘、机械手臂、磁盘读取头与主轴马达所组成, 而数据的写入其实是在磁盘盘上面。磁盘盘上面又可细分出扇区(Sector)与磁道(Track)两种单位, 其中扇区…...

MyBatis-Plugin源码全面分析
三、MyBatis-Plugin 1. 基本开发方式 需求:在MyBatis执行之前打印一行醒目的日志,携带参数 实现Interceptor接口: Intercepts(Signature(type Executor.class,method "query",args {MappedStatement.class,Object.class, RowB…...
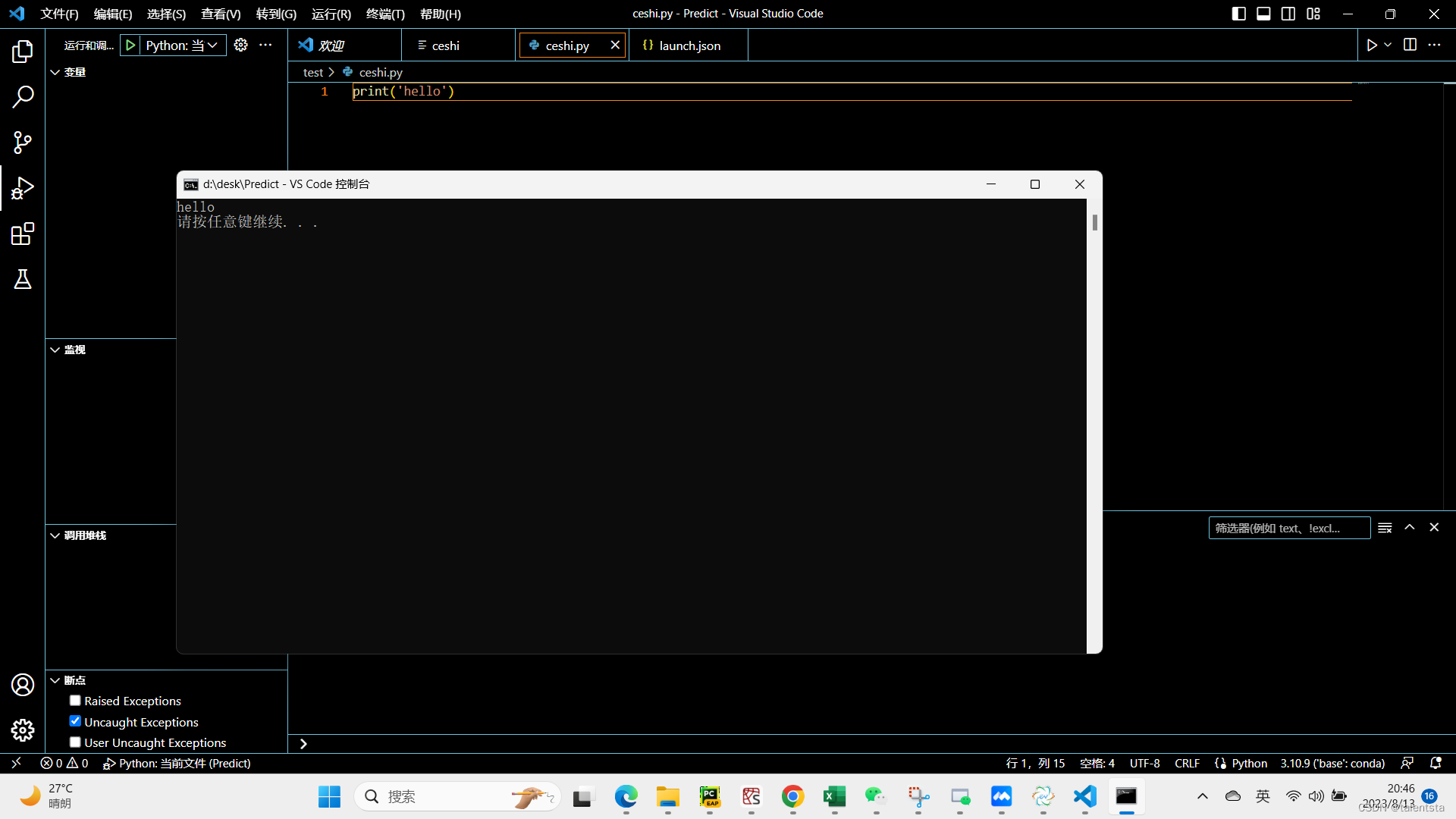
Vscode 常用操作教程
一、语言换成中文 这是我们可以直接点击左边栏第四个图标搜索插件 chinese ,也可以直接ctrlshiftp快捷键也会出来如图所示图标,出来chinese 插件之后选择安装install,安装完成之后重新ctrlshiftp会出现如图所示页面 找到我的鼠标在的地方对应的中文,此时…...
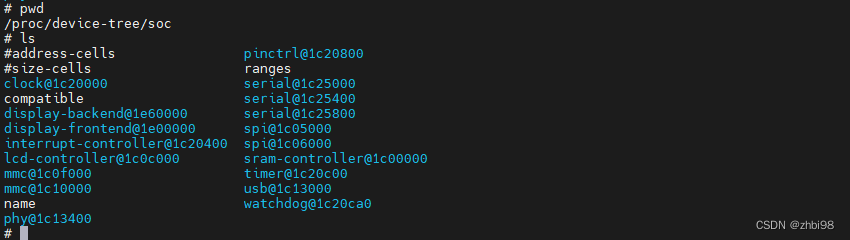
Linux设备树详解
Linux 设备树详解 Linux 操作系统早期是针对个人电脑设备而开发的操作系统,而个人电脑处理器产商较为单一(例如只有 Intel,AMD)同时个人电脑产商均使用 Intel 或 AMD 制造的处理器,业界形成了统一的总线/硬件接口标准…...
.netcore grpc服务端流方法详解
一、服务端流式处理概述 客户端向服务端发送请求,服务端可以将多个消息流式传输回调用方和客户端流相反,客户端流发出请求,服务端可以传输一批消息给客户端,直至本次请求响应完全结束。针对文件分段传输下载,该方式非…...
python爬虫数据解析xpath、jsonpath,bs4
数据的解析 解析数据的方式大概有三种 xpathJsonPathBeautifulSoup xpath 安装xpath插件 打开谷歌浏览器扩展程序,打开开发者模式,拖入插件,重启浏览器,ctrlshiftx,打开插件页面 安装lxml库 安装在python环境中的Scri…...

go语言的database/sql结合squirrel工具sql生成器完成数据库操作
database/sql database/sql是go语言内置数据库引擎,使用sql查询数据库,配置datasource后使用其数据库操作方法对数据库操作,如下: package mainimport ("database/sql""fmt"_ "github.com/Masterminds…...

LVS集群和分布式
LVS 一.集群和分布式概念 1.1 集群 在计算机领域,集群早在 1960 年就出现,随着互联网和计算机相关技术的发展,现在 集群这一技术已经在各大互联网公司普及。 1.1.1 集群概念 计算机集群指一组通过计算机网络连接的计算机,它们…...

vue项目简单创建方式
npm init vite-app demo...

表面等离子体神经网络:微波感知技术的革命性突破
1. 表面等离子体神经网络:微波感知的技术革命在自动驾驶和智能物联网领域,微波感知技术正面临一个根本性挑战:传统毫米波雷达受限于数字信号处理的串行链路,系统刷新率被限制在几百赫兹量级。这种瓶颈直接影响了系统对动态场景的实…...

终极指南:如何使用unrpa快速提取Ren‘Py游戏资源文件
终极指南:如何使用unrpa快速提取RenPy游戏资源文件 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 你是否曾经想要提取RenPy视觉小说游戏中的精美立绘、背景音乐或脚本…...

如何快速掌握XELFViewer:Linux二进制文件分析的终极指南
如何快速掌握XELFViewer:Linux二进制文件分析的终极指南 【免费下载链接】XELFViewer ELF file viewer/editor for Windows, Linux and MacOS. 项目地址: https://gitcode.com/gh_mirrors/xe/XELFViewer 你是否曾面对复杂的Linux可执行文件感到无从下手&…...

Windows与Office智能激活终极指南:KMS_VL_ALL_AIO完整解决方案
Windows与Office智能激活终极指南:KMS_VL_ALL_AIO完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在数字化工作环境中,稳定可靠的操作系统和办公软件是高效工…...

Appium Inspector本质是Android UI调试的视觉探针
1. 这不是“下载个工具”那么简单:Appium Inspector本质是Android UI调试的视觉探针很多人搜“Appium Inspector下载”,点开就找exe或dmg文件,下完双击打开,连设备、点Start Session——结果卡在“Waiting for device”或者弹出一…...

3分钟快速解密QQ音乐加密音频:qmc-decoder终极解决方案
3分钟快速解密QQ音乐加密音频:qmc-decoder终极解决方案 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾在QQ音乐下载了心爱的歌曲,却发现只…...

UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力
UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer UnrealPakViewer是一款专门…...

RAG:终结AI“一本正经胡说八道”,让AI回答问题不再答非所问!
本文用通俗易懂的方式解释了RAG技术,即“检索增强生成”,它通过为AI构建专属知识库,在回答问题时先检索相关信息再生成答案,有效解决AI“答非所问”和“幻觉”问题。文章详细介绍了RAG的工作原理、核心价值及实用场景,…...

ComfyUI视频助手套件:解锁AI视频创作的无限可能性
ComfyUI视频助手套件:解锁AI视频创作的无限可能性 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI视频创作日益普及的今天,ComfyUI视频…...