python爬虫数据解析xpath、jsonpath,bs4
数据的解析
解析数据的方式大概有三种
- xpath
- JsonPath
- BeautifulSoup
xpath
安装xpath插件

打开谷歌浏览器扩展程序,打开开发者模式,拖入插件,重启浏览器,ctrl+shift+x,打开插件页面


安装lxml库
安装在python环境中的Scripts下边,这里就是python库的位置,例如我的地址为:E:\python\python3.10.11\Scripts
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple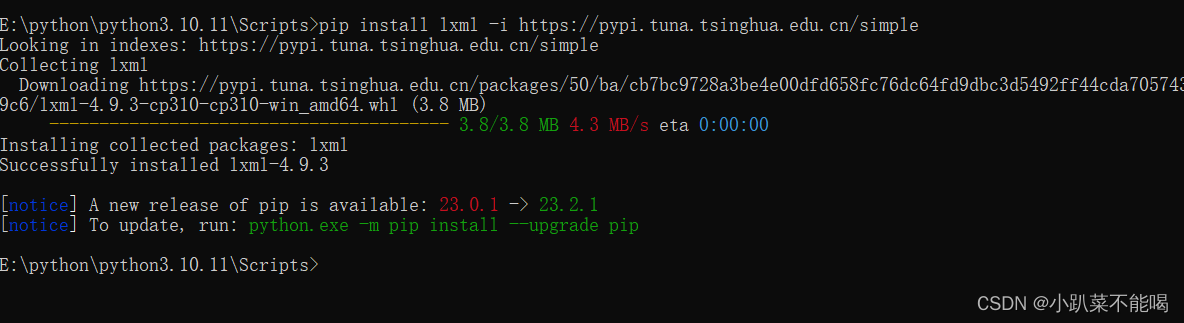
xpath使用和基本语法
解析本地文件etree.parse( 'xx.html')4.etree.HTML()
解析服务器响应文件html_tree = etree.HTML(response.read().decode( 'utf-8')4.html tree.xpath(xpath路径)
xpath基本语法:
路径查询
// : 查找所有子孙节点,不考虑层级关系
/ :找直接子节点
谓词查询
//div[@id] :包含id属性的div
//div[@id="maincontent"] :id = maincontent的div
属性查询
//@class : 返回指定标签的class属性
模糊查询
//div[contains(@id,"he")] : 包含
//div[starts-with(@id,"he")] :以he开头
内容查询
//div/h1/text() : text()显示内容
逻辑运算
//div[@id="head" and @class="s down"] : 逻辑&&
xpath解析本地文件
本地文件如下
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="00" class="beijing">北京</li><li>上海</li><li>深圳</li><li>广州</li></ul><ul><li id="11" class="shenyang">沈阳</li><li>南京</li></ul>
</body>
</html>解析本地文件
from lxml import etree# 解析本地文件 使用etree.parse
tree = etree.parse('Test.html')# 找到所有的ul
ul_list = tree.xpath("//ul")# 查找所有的li
li_list = tree.xpath("//ul/li")# 查找所有包含id的li
id_li_list = tree.xpath("//ul/li[@id]")# 查找id为00的li,并找到内容 注意引号问题
content_list = tree.xpath("//ul/li[@id='00']/text()")# 查找id包含0的li的内容
contains_list = tree.xpath("//ul/li[contains(@id,'0')]/text()")# 获取id为11的li class属性值@class
li = tree.xpath("//ul/li[@id='11']/@class")
print(ul_list)print(li_list)print(id_li_list)print(contains_list)print(content_list)print(li)"""
输出结果:
[<Element ul at 0x22c26c38240>, <Element ul at 0x22c26c38600>]
[<Element li at 0x22c26c38640>, <Element li at 0x22c26c385c0>, <Element li at 0x22c26c38680>, <Element li at 0x22c26c386c0>, <Element li at 0x22c26c38700>, <Element li at 0x22c26c38780>]
[<Element li at 0x22c26c38640>, <Element li at 0x22c26c38700>]
['北京']
['北京']
['shenyang']
"""xpath解析服务器文件
使用xpath插件检查xpath路径的匹配,解析定位dom

from lxml import etree
import urllib.request as request# 下载图片
url = "https://www.baidu.com/"headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}# 构建的请求对象
geneRequest=request.Request(url=url,headers = headers)
# 模拟浏览器发送请求
response = request.urlopen(geneRequest)
# 获取内容
content = response.read().decode('utf-8')# 解析服务器文件
tree = etree.HTML(content)# 找到百度一下的值
result = tree.xpath('//input[@id="su"]/@value')print(result)"""
输出结果:['百度一下']
"""
jsonpath
jsonpath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,只能读取本地的json文件,与xpath类似,只不过对应符号不同
jsonpath安装
pip install jsonpath -i https://pypi.tuna.tsinghua.edu.cn/simple
xpath和jsonpath的对应关系
| XPath | JSONPath | 描述 |
| / | $ | 根节点 |
| . | @ | 现行节点 |
| / | .or[] | 取子节点 |
| 、、 | n/a | 取父节点,Jsonpath未支持 |
| // | 、、 | 就是不管位置,选择所有符合条件的条件 |
| * | * | 匹配所有元素节点 |
| @ | n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要 |
| [] | [] | 迭代器标识(可以在里边做简单的迭代操作,如数组下标,根据内容选值等 |
| [] | ?() | 支持过滤操作 |
| | | [,] | 支持迭代器中做多选 |
| n/a | () | 支持表达式计算 |
| () | n/a | 分组,JsonPath不支持 |
jsonpath解析
准备json
{"store": {"book":[{ "category": "射手","author": "鲁班七号","title": "王者荣耀","price": 8.95},{"category": "打野","author": "李白","title": "大河之水天上来","price": 22.99}],"bicycle": {"color": "red","price": 19.95}}}
通过jsonpath解析json数据
import json
import jsonpathobj = json.load(open('test.json',"r",encoding="utf-8"))# 查看store下的bicycle的color属性 $ 对应xpath/
colorAttr = jsonpath.jsonpath(obj, "$.store.bicycle.color")# 输出book节点的第一个对象
bookFirst = jsonpath.jsonpath(obj, "$.store.book[0]")# 输出book节点中所有对象对应的属性title值
titles = jsonpath.jsonpath(obj, "$.store.book[*].title")# 输出book节点中所有价格小于10的对象 ?() 对应xpath [] @ 对应当前节点
books = jsonpath.jsonpath(obj, "$.store.book[?(@.price<10)]")print(colorAttr)print(bookFirst)print(titles)print(books)"""
输出结果:
['red']
[{'category': '射手', 'author': '鲁班七号', 'title': '王者荣耀', 'price': 8.95}]
['王者荣耀', '大河之水天上来']
[{'category': '射手', 'author': '鲁班七号', 'title': '王者荣耀', 'price': 8.95}]
"""BeautifulSoup
Beautifulsoup简称bs4,Beautifulsoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
- 缺点: 效率没有1xm1的效率高
- 优点: 接口设计人性化,使用方便
BeautifulSoup安装
pip install bs4 - i https://pypi.tuna.tsinghua.edu.cn/simple
BeautifulSoup节点定位规则
soup = soup = Beautifulsoup(response.read().decode(),'Ixml') 解析服务器文件
soup = soup = Beautifulsoup(open('1.html').lxml') 解析本地文件
根据标签名查找节点
soup.a 只能找到第一个a
soup.a.namesoup.a.attrs 获取标签的属性和属性值函数查找
.find (返回一个对象 只能找到第一个a标签)
find('a')
find('a',title='名字')
find('a',class='名字')
.find_all (返回一个列表 )
find all('a')
find all(['a’,'span']) 返回所有的a和span
.select(根据选择器得到节点对象)[推荐]
element
eg: div
class
eg:.firstname
id
eg:#firstname
属性选择器
eg:li = soup.select('li[class]')
eg:li = soup.select('li[class="hengheng"]')
层级选择器
element element
div p
eg:soup = soup.select('a span')
element>element
div>p
eg:soup = soup.select('a>span')
element,element
div,p
eg:soup = soup.select('a,span')
BeautifulSoup节点信息
获取节点内容
obj.string
obj.get_text()[推荐]
获取节点的属性
eg:tag = find('li)
tag.name 获取标签名
tag.attrs将属性值作为一个字典返回
获取节点属性
obj.attrs.get('title')[常用]
obj.get('title')
obj['title']
BeautifulSoup解析文件
以上述xpath中的本地文件Test.html为例,上边已经写过,这里直接上代码
from bs4 import BeautifulSoupsoup = BeautifulSoup(open('Test.html',encoding='utf-8'),'lxml')# 查找第一个ul
print(soup.find("ul"))# 查找所有的ul
print(soup.find_all("ul"))# 选择查找 li class为beijing的标签
print(soup.select("li[class =beijing]"))#层级选择查找ul下的class为beijing的li节点
nodeli=soup.select("ul li[class = beijing]")[0]# 获取li节点内容
print(nodeli.get_text())# 获取li标签名
print(nodeli.name)#获取li的属性
print(nodeli.attrs)# 获取li的id属性
print(nodeli.attrs.get('id'))"""
输出结果:
<ul>
<li class="beijing" id="00">北京</li>
<li>上海</li>
<li>深圳</li>
<li>广州</li>
</ul>
[<ul>
<li class="beijing" id="00">北京</li>
<li>上海</li>
<li>深圳</li>
<li>广州</li>
</ul>, <ul>
<li class="shenyang" id="11">沈阳</li>
<li>南京</li>
</ul>]
[<li class="beijing" id="00">北京</li>]
北京
li
{'id': '00', 'class': ['beijing']}
00"""相关文章:
python爬虫数据解析xpath、jsonpath,bs4
数据的解析 解析数据的方式大概有三种 xpathJsonPathBeautifulSoup xpath 安装xpath插件 打开谷歌浏览器扩展程序,打开开发者模式,拖入插件,重启浏览器,ctrlshiftx,打开插件页面 安装lxml库 安装在python环境中的Scri…...

go语言的database/sql结合squirrel工具sql生成器完成数据库操作
database/sql database/sql是go语言内置数据库引擎,使用sql查询数据库,配置datasource后使用其数据库操作方法对数据库操作,如下: package mainimport ("database/sql""fmt"_ "github.com/Masterminds…...

LVS集群和分布式
LVS 一.集群和分布式概念 1.1 集群 在计算机领域,集群早在 1960 年就出现,随着互联网和计算机相关技术的发展,现在 集群这一技术已经在各大互联网公司普及。 1.1.1 集群概念 计算机集群指一组通过计算机网络连接的计算机,它们…...
使用QT可视化设计对话框详细步骤与代码
一、创建对话框基本步骤 创建并初始化子窗口部件把子窗口部件放到布局中设置tab键顺序建立信号-槽之间的连接实现对话框中的自定义槽 首先前面三步在这里是通过ui文件里面直接进行的,剩下两步则是通过代码来实现 二、项目创建详细步骤 创建新项目 为项目命名 为…...

TFTP Server
简介 TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为69。 TFTP和FTP的区别 安全性区别 FTP支持登录安全&…...
登录验证码实现
Hutool代码改造 Hutool 有参考文档;很多工具类;把一些功能都封装好;都不用你自己去写;直接调用它的工具类 它这里会详细告诉你引入方式Hutool <dependency><groupId>cn.hutool</groupId><artifactId>hu…...

2. 获取自己CSDN文章列表并按质量分由小到大排序(文章质量分、博客质量分、博文质量分)(阿里云API认证)
文章目录 写在前面步骤打开CSDN质量分页面粘贴查询文章url按F12打开调试工具,点击Network,点击清空按钮点击查询是调了这个接口https://bizapi.csdn.net/trends/api/v1/get-article-score用postman测试调用这个接口(不行,认证不通…...

在Windows和MacOS环境下实现批量doc转docx,xls转xlsx
一、引言 Python中批量进行办公文档转化是常见的操作,在windows状态下我们可以利用changeOffice这个模块很快进行批量操作。 二、在Windows环境下的解决文案 Windows环境下,如何把doc转化为docx,xls转化为xlsx? 首先ÿ…...
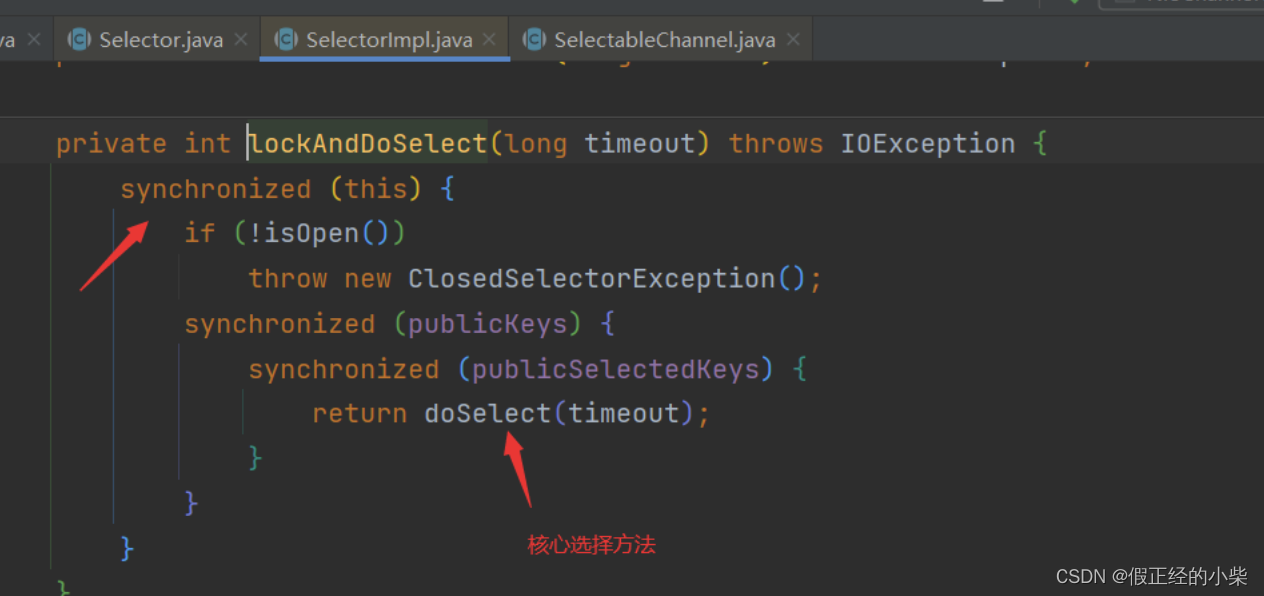
【网络编程(二)】NIO快速入门
NIO Java NIO 三大核心组件 Buffer(缓冲区):每个客户端连接都会对应一个Buffer,读写数据通过缓冲区读写。Channel(通道):每个channel用于连接Buffer和Selector,通道可以进行双向读…...
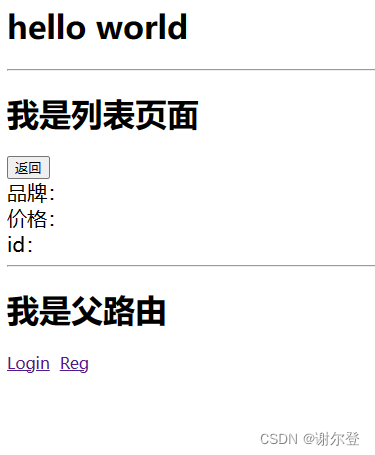
【Vue-Router】嵌套路由
footer.vue <template><div><router-view></router-view><hr><h1>我是父路由</h1><div><router-link to"/user">Login</router-link><router-link to"/user/reg" style"margin-left…...
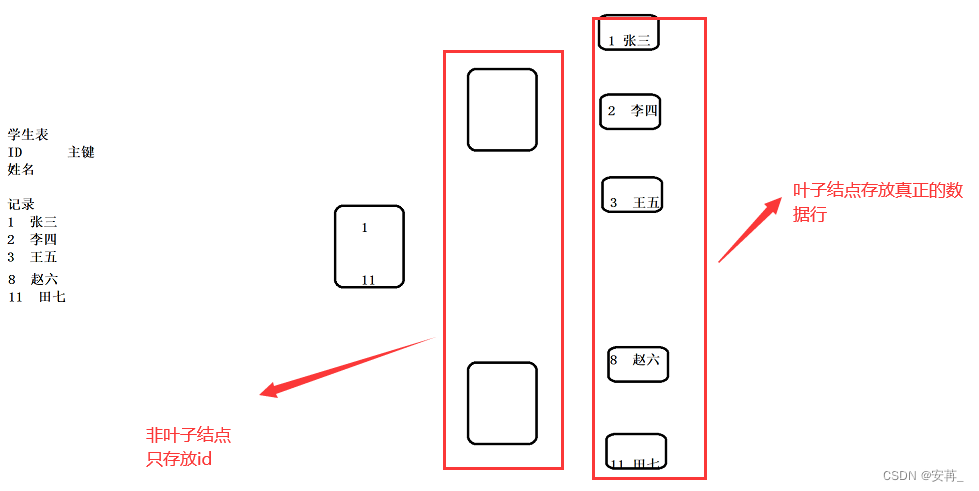
MySQL索引总结
MySQL索引总结 1.索引的概念、作用与使用场景 本质上就是减少读写磁盘的次数。 索引是一种特殊的文件,包含这对数据表中所有记录的引用指针,可以对表中的一列或多列创建索引,并指定索引的类型,每种类型都有对应数据结构实现。 …...

谷粒商城第十二天-基本属性销售属性管理功能的实现
目录 一、总述 二、前端部分 三、后端部分 四、总结 一、总述 前端的话,依旧是直接使用老师给的。 前端的话还是那些增删改查,业务复杂一点的话,无非就是设计到多个字段多个表的操作,当然这是后端的事了,前端这里…...

利用安全区域的概念解决移动端兼容不同手机刘海的问题
移动端 安全区 在做移动端的项目时,由于不同的手机设备设置的不同,有些手机在上方有刘海的设计,我们需要做适配,即把想要展示的内容放在安全区域内展示。 1.自定义导航栏 在pages.json中修改如下配置 {"path":"…...

数据结构---图
这里写目录标题 图的基本概念和术语基本概念和术语1基本概念和术语2 图的类型定义抽象数据类型定义二级目录二级目录 一级目录二级目录二级目录二级目录二级目录二级目录二级目录 图的基本概念和术语 基本概念和术语1 V代表顶点的有穷非空集合 E代表边的有穷集合 n为顶点 有向…...
励志长篇小说《周兴和》书连载之十八 内外交困搞发明
内外交困搞发明 路灯发出昏黄而惺忪的光影。 周兴和疲惫地从车间出来,拖着沉重的腿爬上几级石阶,准备回到家里去。可走到家门口,他想了想,又折了回去,在车间的一条长条椅子上,他用一块试验用的废料当枕头&…...
web基础入门和php语言基础入门 二
web基础入门和php语言基础入门 二 MySQL入门-续MySQL之数据查询操作MySQL其他知识点 php语言基础入门认识PHPPHP的工作流程安装PHP环境认识一个PHP程序PHP基础知识点进入正题 PHP与WEB交互PHP与MySQL交互总结 MySQL入门-续 MySQL之数据查询操作 WHERE 子句,条件限…...

typeScript 之 Array
工具: PlayGround 源码:GitHub TypeScript 数组简介 在TypeScript中, 使用[]表示数组, 它的结构:let valus: 类型名[] 数据; // 数字 let numList: number[] [1, 2, 3]; // 字符串 let strList: string[] ["hello"…...

【题解】二叉树的前中后遍历
文章目录 二叉树的前序遍历二叉树的中序遍历二叉树的后序遍历 二叉树的前序遍历 题目链接:二叉树的前序遍历 解题思路1:递归 代码如下: void preorder(vector<int>& res, TreeNode* root){if(root nullptr) return;//遇到空节点…...

文件操作/IO
文件 文件是一种在硬盘上存储数据的方式,操作系统帮我们把硬盘的一些细节都封装起来了,程序员只需要了解文件相关的接口即可,相当于操作文件就是间接的操作硬盘了 硬盘用来存储数据,和内存相比硬盘的存储空间更大,访问…...
基于Java+SpringBoot+vue前后端分离共享汽车管理系统设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

Cursor Pro破解工具完整指南:5步实现机器标识重置与永久Pro功能解锁
Cursor Pro破解工具完整指南:5步实现机器标识重置与永久Pro功能解锁 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve rea…...

AI代理实战能力评估:MLE-Bench基准测试深度解析与工程启示
1. 项目概述与核心价值最近在跟进AI代理(AI Agent)领域的发展,特别是它们在自动化复杂工作流方面的潜力。作为一个在机器学习工程一线摸爬滚打了十来年的从业者,我深知从数据清洗、特征工程、模型调优到实验管理的全流程ÿ…...

如何用开源工具GoldenCheetah将训练数据转化为科学优势
如何用开源工具GoldenCheetah将训练数据转化为科学优势 【免费下载链接】GoldenCheetah Performance Software for Cyclists, Runners, Triathletes and Coaches 项目地址: https://gitcode.com/gh_mirrors/go/GoldenCheetah GoldenCheetah是一款专为自行车、跑步和铁人…...

别再猜了!用blkid命令一键定位U盘盘符,搞定CentOS7安装时的dracut timeout报错
精准定位U盘盘符:blkid命令在CentOS7安装中的高阶应用当你在多硬盘服务器上安装CentOS7系统时,是否曾被dracut timeout报错困扰?这个看似简单的安装问题背后,隐藏着一个关键的技术细节——如何准确识别U盘盘符。本文将带你深入探索…...

量化精度不妥协,吞吐翻2.8倍——DeepSeek-R1推理优化黄金参数组合大曝光,仅限本周公开
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1推理优化的底层逻辑与精度守恒原理 DeepSeek-R1作为面向长上下文、高吞吐场景设计的开源大语言模型,其推理优化并非以牺牲数值精度为代价换取速度提升,而是建立在计算…...

对比按量计费与Token Plan套餐在长期开发中的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐在长期开发中的成本体感差异 对于一个持续进行大模型应用开发的中型团队而言,成本的可预…...

如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南
如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 还在为复杂的AI换脸工…...

B站CC字幕下载与转换解决方案:实现视频学习资源本地化管理
B站CC字幕下载与转换解决方案:实现视频学习资源本地化管理 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 在视频学习日益普及的今天,B站作…...

QModMaster:5分钟解决工业通信调试难题的开源ModBus工具
QModMaster:5分钟解决工业通信调试难题的开源ModBus工具 【免费下载链接】qModbusMaster Fork of QModMaster (https://sourceforge.net/p/qmodmaster/code/ci/default/tree/) 项目地址: https://gitcode.com/gh_mirrors/qm/qModbusMaster 还在为复杂的工业设…...

PXE启动Ubuntu时,你的initrd.img配置对了吗?一个参数让无盘启动快3倍
PXE启动Ubuntu时initrd.img的深度调优指南当你在凌晨三点盯着PXE启动进度条缓慢爬升时,是否想过那个看似简单的initrd.img文件里藏着多少性能玄机?作为运维老兵的我在经历了数十次无盘系统部署后,发现90%的PXE启动性能问题都源于initrd配置不…...