2. 获取自己CSDN文章列表并按质量分由小到大排序(文章质量分、博客质量分、博文质量分)(阿里云API认证)
文章目录
- 写在前面
- 步骤
- 打开CSDN质量分页面
- 粘贴查询文章url
- 按F12打开调试工具,点击Network,点击清空按钮
- 点击查询
- 是调了这个接口`https://bizapi.csdn.net/trends/api/v1/get-article-score`
- 用postman测试调用这个接口(不行,认证不通过)
- 我查了一下,这种认证方式貌似是阿里云的API认证
- 这里有一篇巨好的参考文章
- 参考上面参考文章中的获取质量分java代码部分,用python代码实现获取博文质量分(可以成功查询)
- 读取我们上一篇文章中的博客列表articles.json,逐个获取质量分,最后把结果保存到processed_articles.json★★★
- 编写代码处理processed_articles.json,提取原创文章,根据url去重,并按质量分由小到大排序,生成original_sorted_articles.json★★★
- 编写代码统计original_sorted_articles.json中原创文章数量,计算平均质量分★★★
- 搞了个监控程序,如果我们更新了博客,就去original_sorted_articles.json把对应的score置零,然后程序马上感应到并重新获取质量分,重新计算平均质量分★★★
上一篇:1. 如何爬取自己的CSDN博客文章列表(获取列表)(博客列表)(手动+python代码方式)
写在前面
上一篇文章中,我们已经成功获取到了自己的CSDN已发布博文列表:
(articles.json)
本篇文章将实现获取每篇原创文章的质量分,并由小到大排序。
步骤
打开CSDN质量分页面
https://www.csdn.net/qc?utm_source=1966961068
粘贴查询文章url
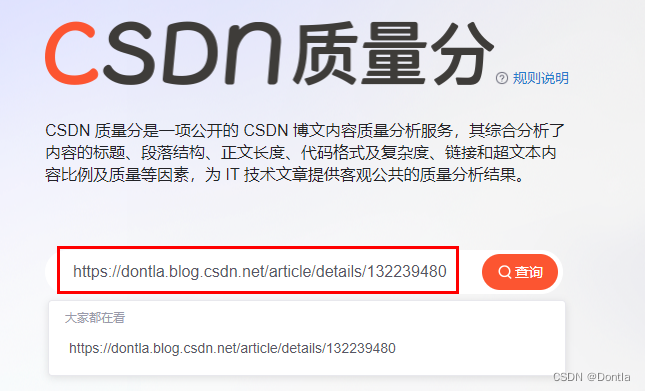
按F12打开调试工具,点击Network,点击清空按钮
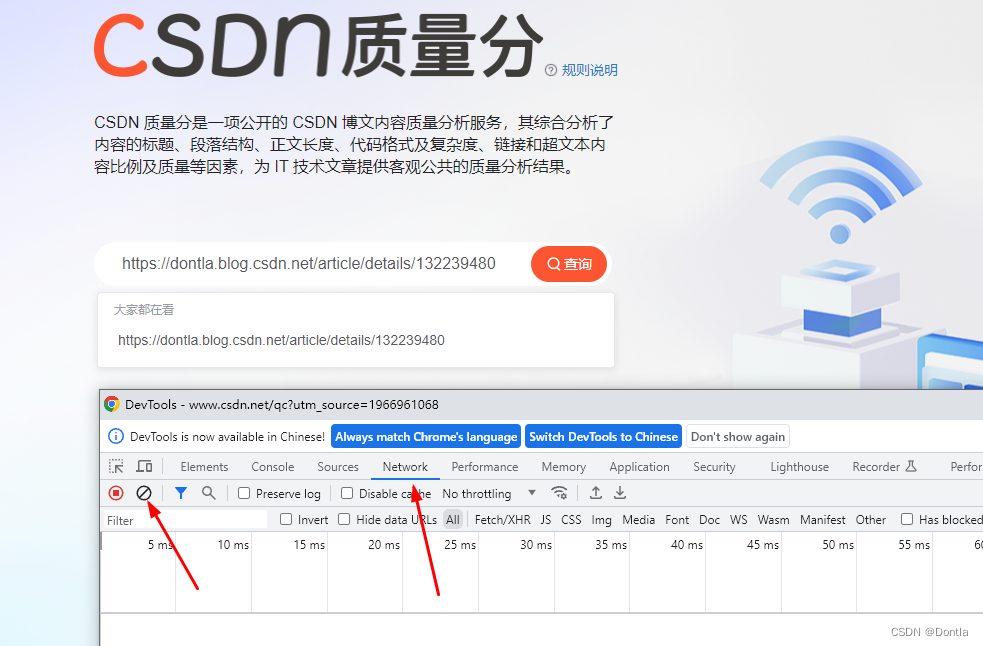
点击查询
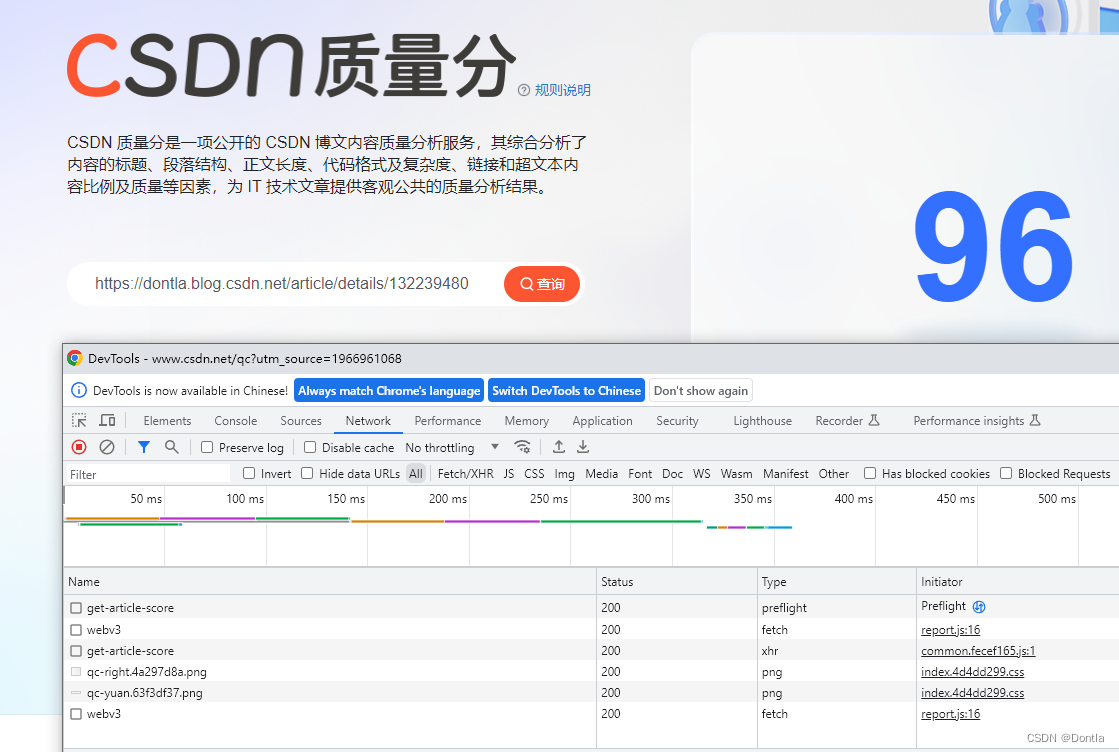
是调了这个接口https://bizapi.csdn.net/trends/api/v1/get-article-score
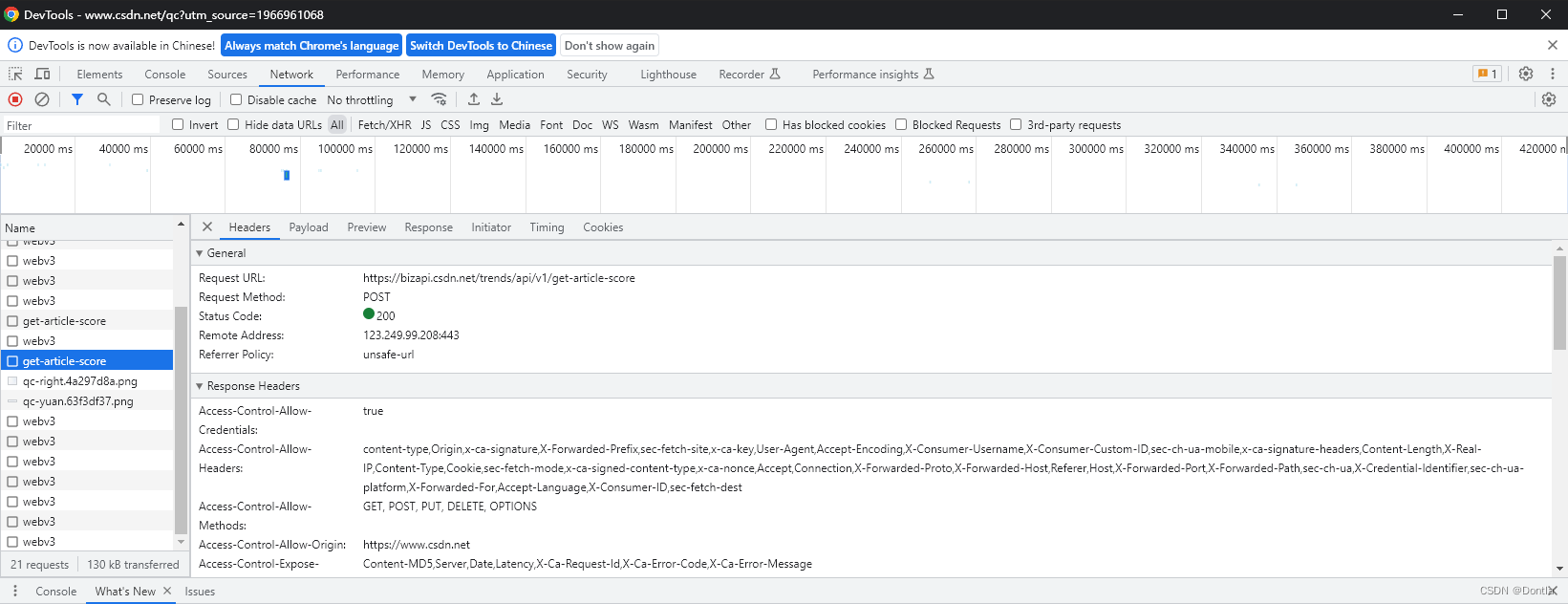
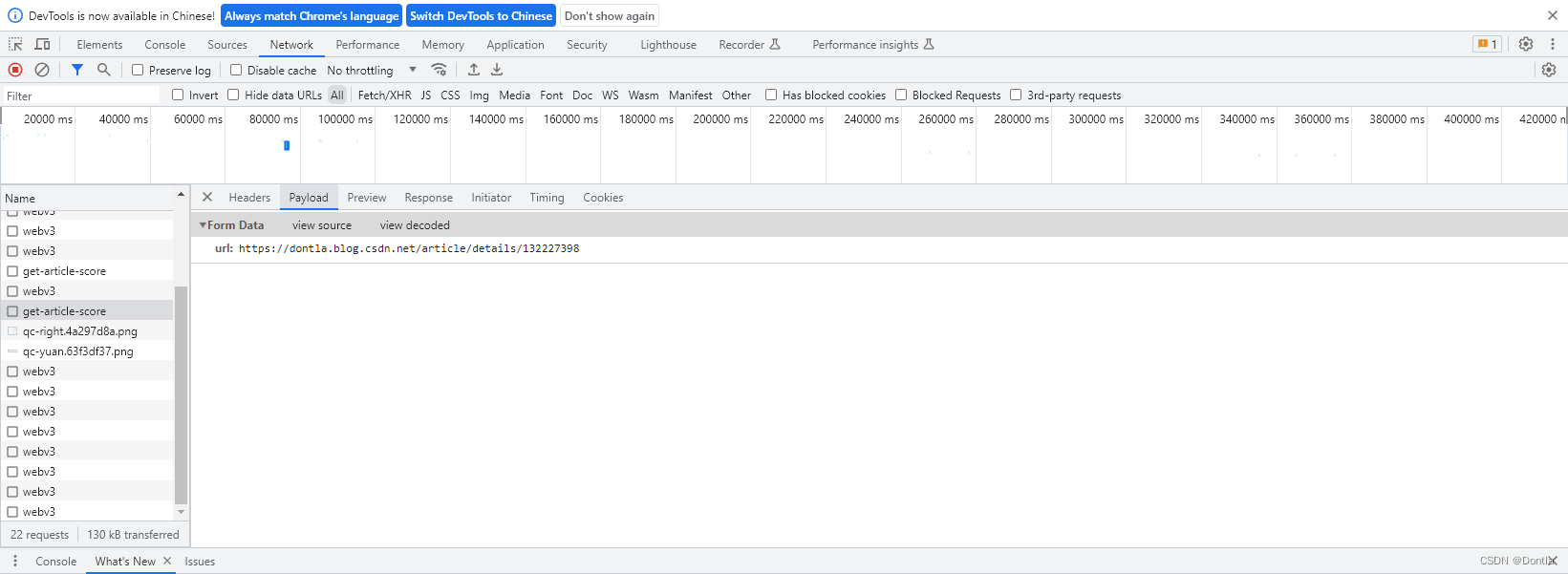
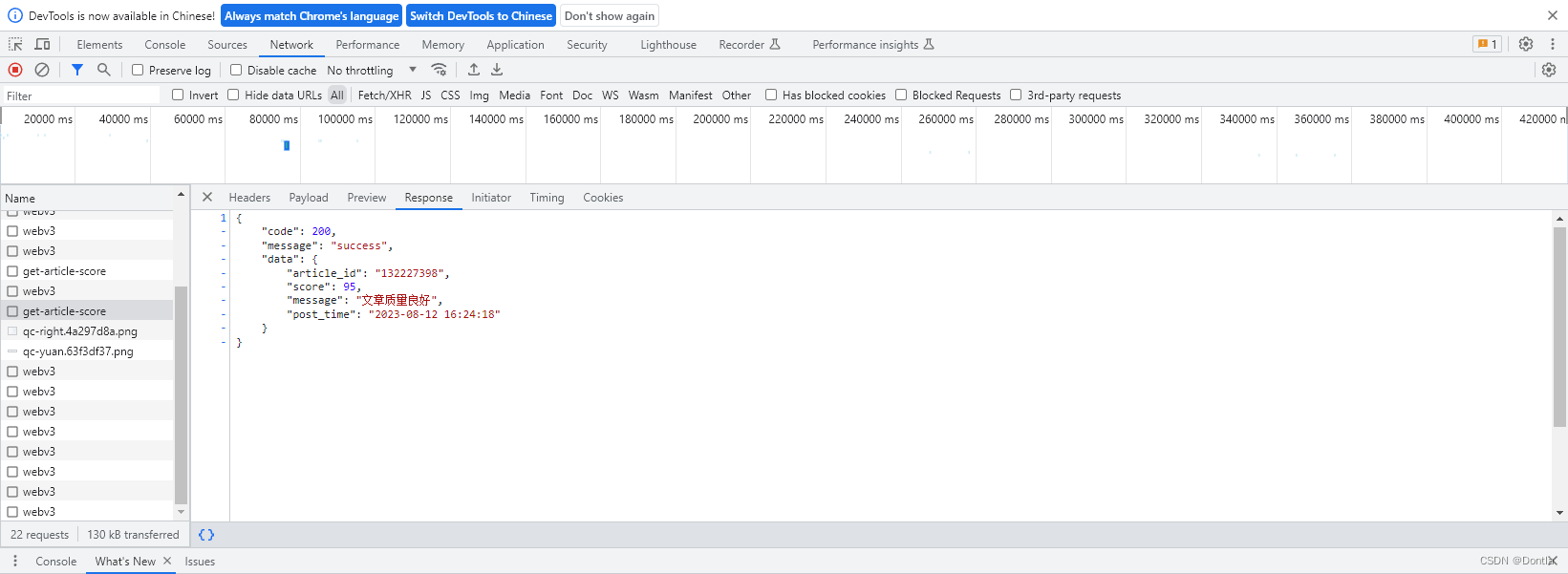
用postman测试调用这个接口(不行,认证不通过)
POST https://bizapi.csdn.net/trends/api/v1/get-article-score
{"url": "https: //dontla.blog.csdn.net/article/details/132227398"
}
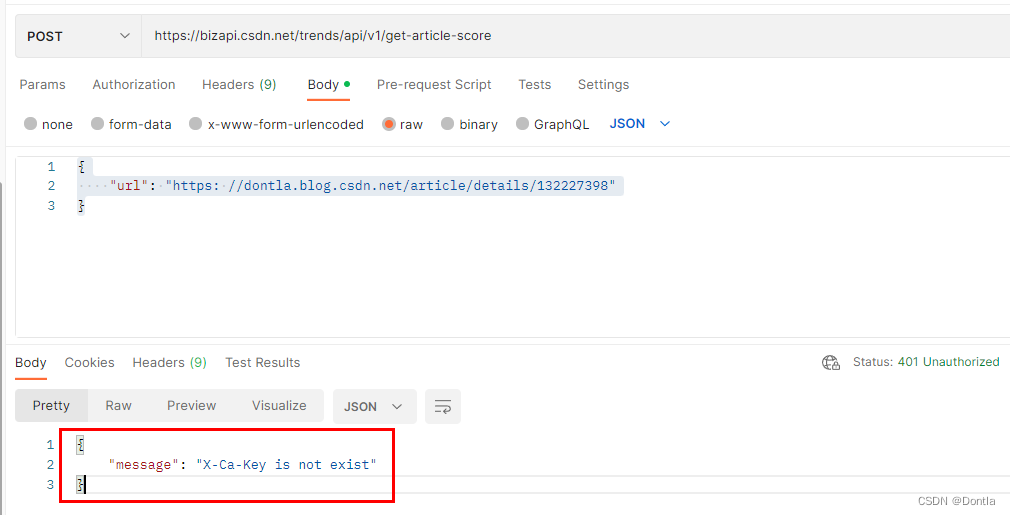
提示:
{"message": "X-Ca-Key is not exist"
}
然后我把X-Ca-Key从浏览器复制下来,给它加到Headers参数里了:
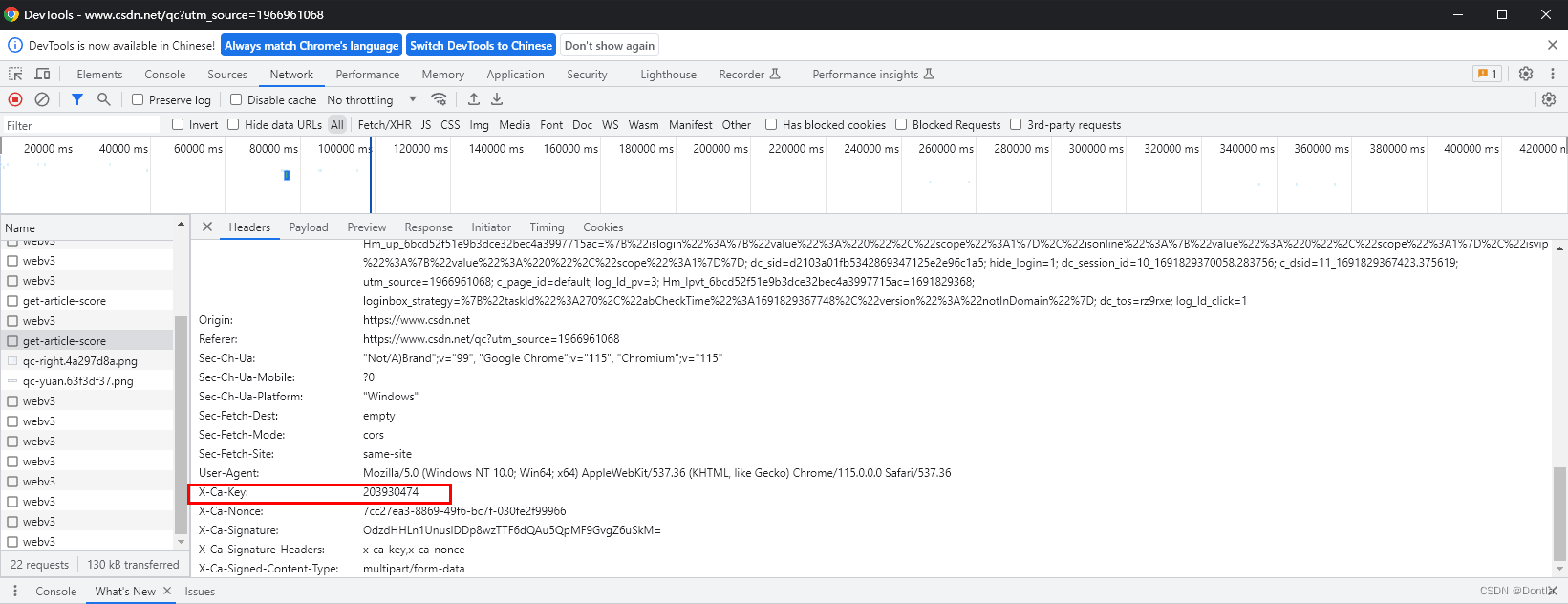
然后它又提示什么:
{"message": "X-Ca-Signature not exist"
}
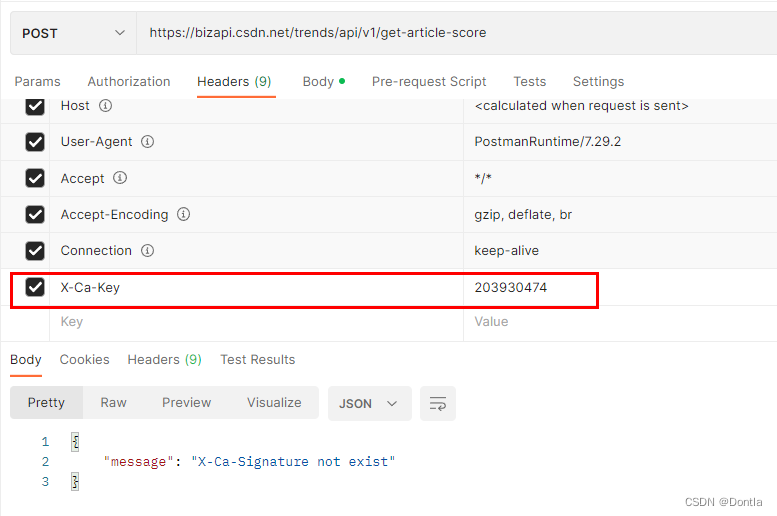
然后我故技重施,把那些提示缺少的东西统统从浏览器复制下来给它加上:
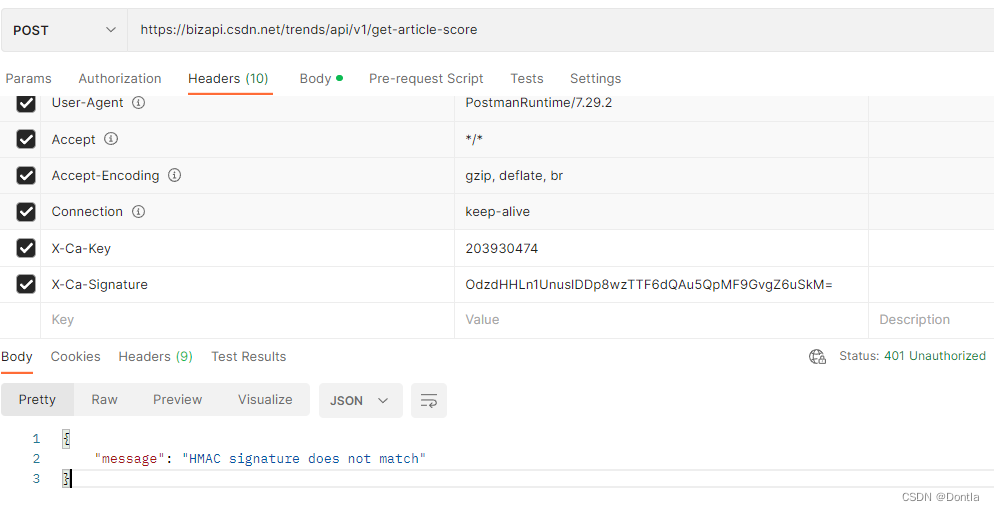
但是最后提示:
{"message": "HMAC signature does not match"
}
这有点尴尬啊。。。
我查了一下,这种认证方式貌似是阿里云的API认证
有亿点复杂,一时半会搞不懂
这里有一篇巨好的参考文章
如何批量查询自己的CSDN博客质量分
参考上面参考文章中的获取质量分java代码部分,用python代码实现获取博文质量分(可以成功查询)
就是这一段:
// //循环调用csdn接口查询所有的博客质量分
String urlScore = “https://bizapi.csdn.net/trends/api/v1/get-article-score”;
//
//请求头
HttpHeaders headers = new HttpHeaders();
headers.set(“accept”,“application/json, text/plain, /”);
headers.set(“x-ca-key”,“203930474”);
headers.set(“x-ca-nonce”,“22cd11a0-760a-45c1-8089-14e53123a852”);
headers.set(“x-ca-signature”,“RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=”);
headers.set(“x-ca-signature-headers”,“x-ca-key,x-ca-nonce”);
headers.set(“x-ca-signed-content-type”,“multipart/form-data”);
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
//调用接口获取数据
List scoreModels = new ArrayList<>();
for (String bkUrl : urlList) {
MultiValueMap<String,String> requestBody = new LinkedMultiValueMap<>();
requestBody.put(“url”, Collections.singletonList(bkUrl));
HttpEntity<MultiValueMap<String, String>> requestEntity = new HttpEntity<>(requestBody, headers);
URI uri = URI.create(urlScore);
ResponseEntity responseEntity = restTemplate.postForEntity(uri, requestEntity, String.class);
JSONObject data1 = JSON.parseObject(responseEntity.getBody(),JSONObject.class) ;
ScoreModel scoreModel = JSONObject.parseObject(data1.get(“data”).toString(),ScoreModel.class);
scoreModels.add(scoreModel);
System.out.println("名称: "+scoreModel.getTitle() +"分数: " + scoreModel.getScore() +"时间: " + scoreModel.getPost_time());
}
return scoreModels;
}
传入参数为urlList:
import requests
from requests.models import PreparedRequestdef get_score_models(url_list):url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"headers = {"accept": "application/json, text/plain, */*","x-ca-key": "203930474","x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852","x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=","x-ca-signature-headers": "x-ca-key,x-ca-nonce","x-ca-signed-content-type": "multipart/form-data"}score_models = []for bk_url in url_list:data = {"url": [bk_url]}response = send_request(url_score, data, headers)data1 = response.json()print(data1)'''{'code': 200, 'message': 'success', 'data': {'article_id': '132240693', 'score': 95, 'message': '文章质量良好', 'post_time': '2023-08-12 17: 45: 24'}} '''score_model = data1["data"]score_models.append(score_model)print(f'文章Id:{score_model["article_id"]}\n分数:{score_model["score"]}\n文章质量:{score_model["message"]}\n发布时间:{score_model["post_time"]}')return score_modelsdef send_request(url, data, headers):session = requests.Session()prepared_request = PreparedRequest()prepared_request.prepare(method='POST', url=url,headers=headers, data=data)return session.send(prepared_request)# 示例调用
urlList = ["https://dontla.blog.csdn.net/article/details/132240693"]
scoreModels = get_score_models(urlList)上面的验证信息,我从那篇博客里搞来的,怎么生成的,我就搞不清楚了。。。
运行上面代码,能成功得到质量分信息:

读取我们上一篇文章中的博客列表articles.json,逐个获取质量分,最后把结果保存到processed_articles.json★★★
我们上一篇文章得到的articles.json是这样的:
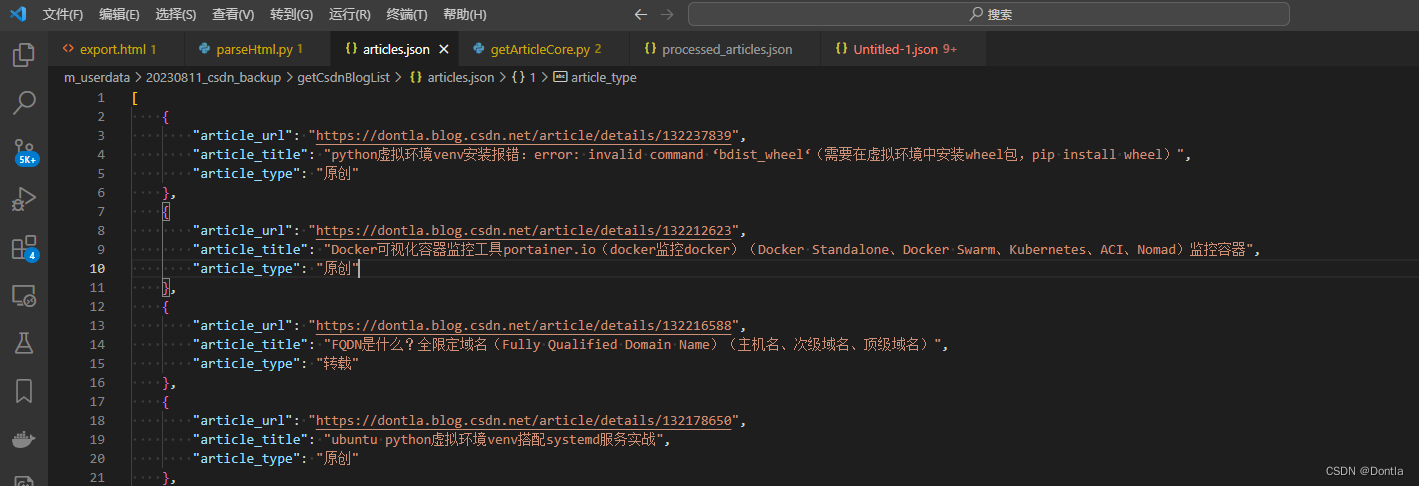
下面代码将读取它并逐个获取质量分:
(getArticleScore.py)
import requests
from requests.models import PreparedRequest
import jsondef get_score_models(url):url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"headers = {"accept": "application/json, text/plain, */*","x-ca-key": "203930474","x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852","x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=","x-ca-signature-headers": "x-ca-key,x-ca-nonce","x-ca-signed-content-type": "multipart/form-data"}data = {"url": url}response = send_request(url_score, data, headers)data1 = response.json()# print(data1)'''{'code': 200, 'message': 'success', 'data': {'article_id': '132240693', 'score': 95, 'message': '文章质量良好', 'post_time': '2023-08-12 17: 45: 24'}} '''score_model = data1["data"]return score_modeldef send_request(url, data, headers):session = requests.Session()prepared_request = PreparedRequest()prepared_request.prepare(method='POST', url=url,headers=headers, data=data)return session.send(prepared_request)def process_article_json():# 读取articles.json文件with open('articles.json', 'r') as f:articles = json.load(f)# 遍历每个元素并处理for article in articles:score_model = get_score_models(article['article_url'])article['article_score'] = score_model['score']print(article)# 保存处理后的结果到新的JSON文件output_file = 'processed_articles.json'with open(output_file, 'w') as f:json.dump(articles, f, ensure_ascii=False, indent=4)if __name__ == '__main__':process_article_json()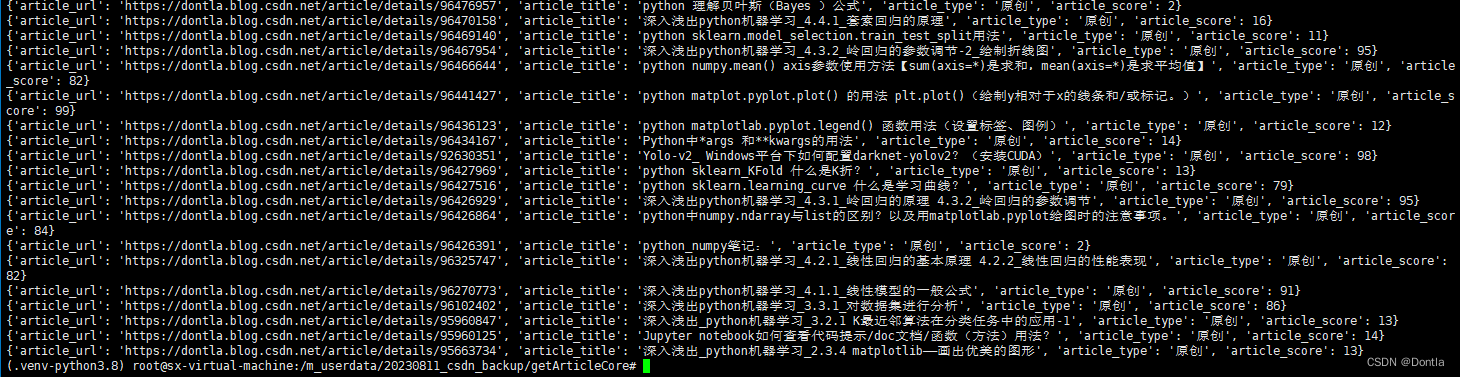
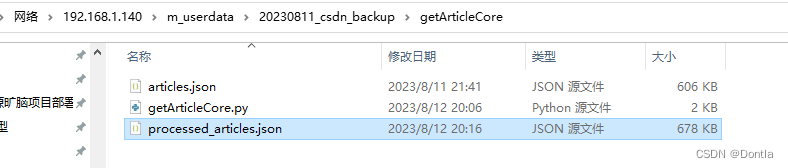
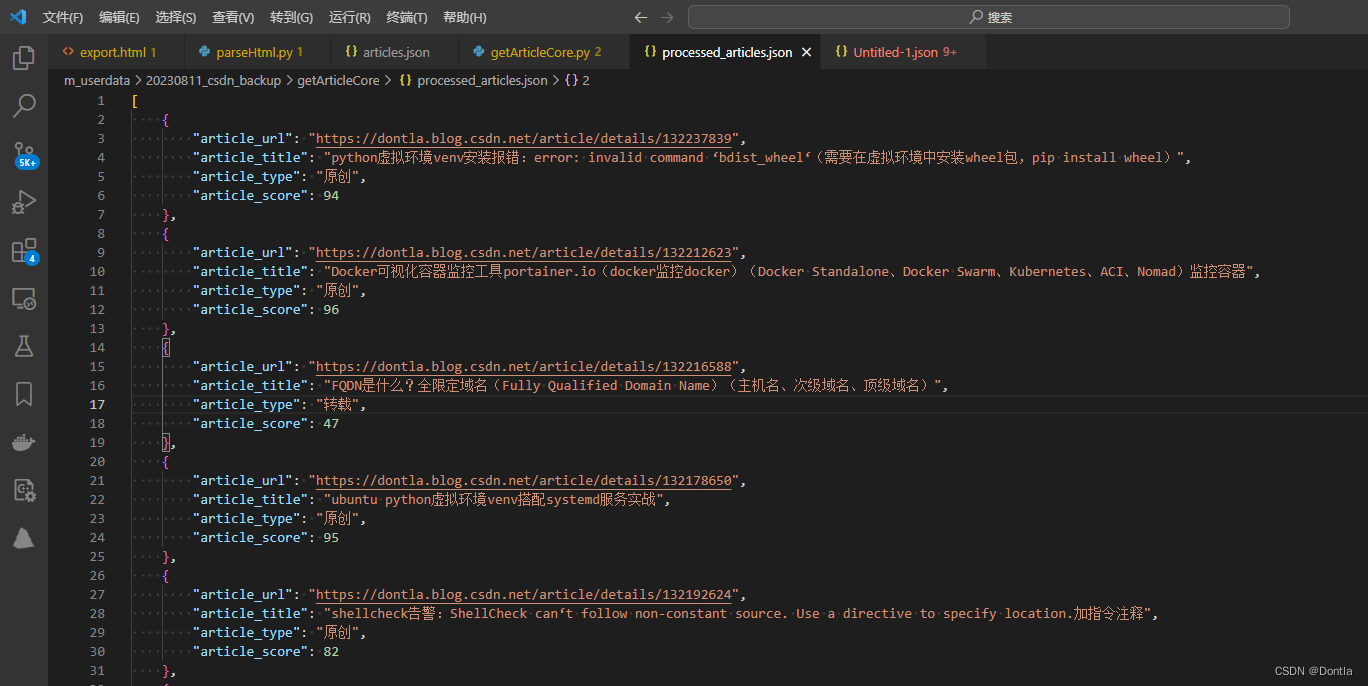
最终得到processed_articles.json:
编写代码处理processed_articles.json,提取原创文章,根据url去重,并按质量分由小到大排序,生成original_sorted_articles.json★★★
(getOriginalSort.py)
import json# 读取JSON文件
with open('processed_articles.json', 'r') as f:data = json.load(f)# 过滤和排序数据,并去除重复的元素
filtered_data = []
seen_urls = set()
for article in data:if article['article_type'] == '原创' and article['article_url'] not in seen_urls:filtered_data.append(article)seen_urls.add(article['article_url'])sorted_data = sorted(filtered_data, key=lambda x: x['article_score'])# 保存到新的JSON文件
with open('original_sorted_articles.json', 'w') as f:json.dump(sorted_data, f, indent=4, ensure_ascii=False)执行:
python3 getOriginalSort.py
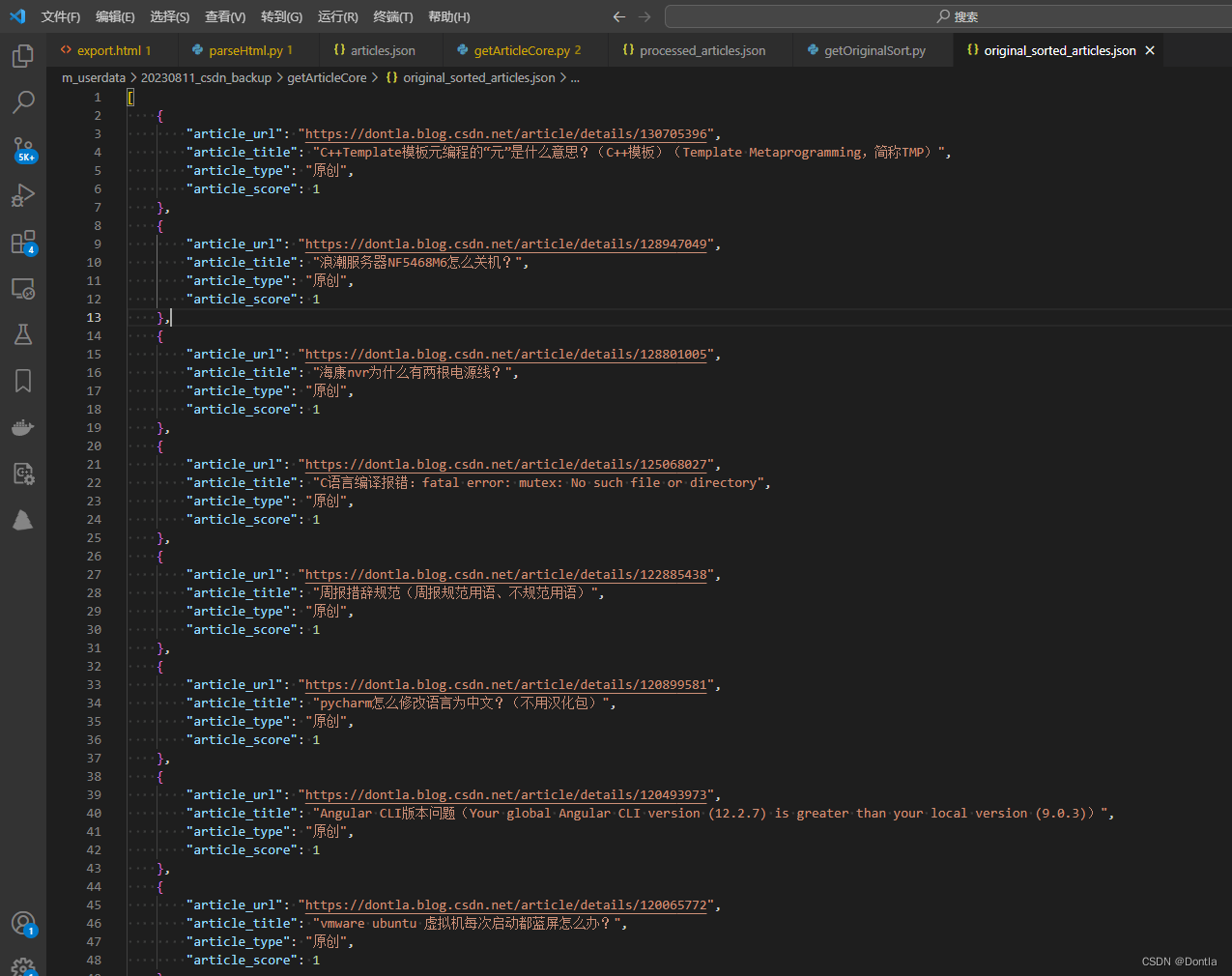
生成文件original_sorted_articles.json:
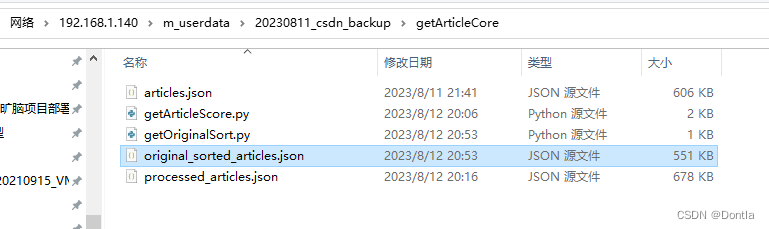
不看不知道,一看吓一跳啊,居然这么多一分的。。。心塞
编写代码统计original_sorted_articles.json中原创文章数量,计算平均质量分★★★
(getAverageScore.py)
import json# 读取 JSON 文件
with open('original_sorted_articles.json', 'r') as file:articles = json.load(file)# 统计 article_score 并计算平均值
total_score = 0
num_articles = len(articles)
for article in articles:total_score += article['article_score']
average_score = total_score / num_articles# 打印结果
print(f"元素数量:{num_articles}")
print(f"平均 article_score:{average_score}")# 保存结果到文本文件
with open('average_score_result.txt', 'w') as file:file.write(f"元素数量:{num_articles}\n")file.write(f"平均 article_score:{average_score}\n")
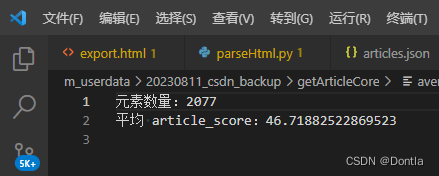
我去,这也太低了吧,客服咋给我算出60几分的,难道只统计最近一两年的?
唉,反正慢慢改吧。。。😔
搞了个监控程序,如果我们更新了博客,就去original_sorted_articles.json把对应的score置零,然后程序马上感应到并重新获取质量分,重新计算平均质量分★★★
(update_score.py)
import time
import json
import requests
from requests.models import PreparedRequestdef get_score_models(url):url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"headers = {"accept": "application/json, text/plain, */*","x-ca-key": "203930474","x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852","x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=","x-ca-signature-headers": "x-ca-key,x-ca-nonce","x-ca-signed-content-type": "multipart/form-data"}data = {"url": url}response = send_request(url_score, data, headers)data1 = response.json()# print(data1)'''{'code': 200, 'message': 'success', 'data': {'article_id': '132240693', 'score': 95, 'message': '文章质量良好', 'post_time': '2023-08-12 17: 45: 24'}} '''score_model = data1["data"]return score_modeldef send_request(url, data, headers):session = requests.Session()prepared_request = PreparedRequest()prepared_request.prepare(method='POST', url=url,headers=headers, data=data)return session.send(prepared_request)def getAverageScore(articles):# 统计 article_score 并计算平均值total_score = 0num_articles = len(articles)for article in articles:total_score += article['article_score']average_score = total_score / num_articles# 打印结果print(f"元素数量:{num_articles}")print(f"平均 article_score:{average_score}")def update_article_scores(file_path):while True:with open(file_path, 'r') as f:articles = json.load(f)for article in articles:if article['article_score'] == 0:print(f'监测到文章 {article["article_url"]} 改变,重新获取质量分')article['article_score'] = get_score_models(article['article_url'])['score']print(f'文章 {article["article_url"]} 新质量分为 {article["article_score"]}')# 排序# articles = sorted(articles, key=lambda x: x['article_score'])# 统计 article_score 并计算平均值getAverageScore(articles)with open(file_path, 'w') as f:json.dump(articles, f, indent=4, ensure_ascii=False,)print()time.sleep(1) # 暂停1秒后再次遍历文件if __name__ == '__main__':# 在主程序中调用update_article_scores函数来更新article_scorefile_path = 'original_sorted_articles.json'update_article_scores(file_path)(original_sorted_articles.json)
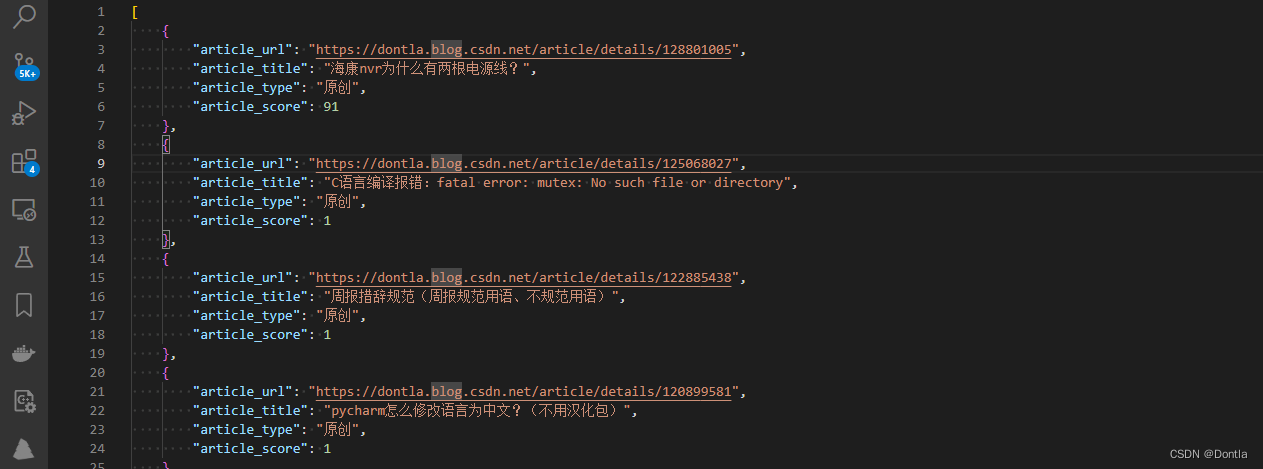
如果我们改了博客,把那篇的article_score置零:

这样实时计算就比较方便
相关文章:
2. 获取自己CSDN文章列表并按质量分由小到大排序(文章质量分、博客质量分、博文质量分)(阿里云API认证)
文章目录 写在前面步骤打开CSDN质量分页面粘贴查询文章url按F12打开调试工具,点击Network,点击清空按钮点击查询是调了这个接口https://bizapi.csdn.net/trends/api/v1/get-article-score用postman测试调用这个接口(不行,认证不通…...

在Windows和MacOS环境下实现批量doc转docx,xls转xlsx
一、引言 Python中批量进行办公文档转化是常见的操作,在windows状态下我们可以利用changeOffice这个模块很快进行批量操作。 二、在Windows环境下的解决文案 Windows环境下,如何把doc转化为docx,xls转化为xlsx? 首先ÿ…...
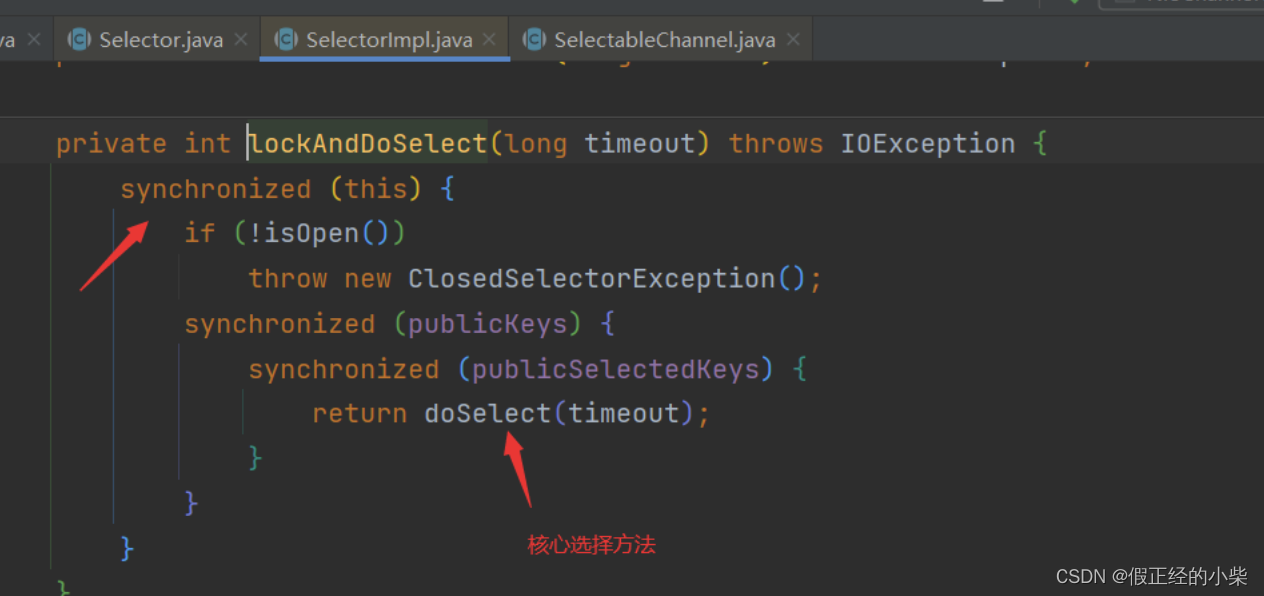
【网络编程(二)】NIO快速入门
NIO Java NIO 三大核心组件 Buffer(缓冲区):每个客户端连接都会对应一个Buffer,读写数据通过缓冲区读写。Channel(通道):每个channel用于连接Buffer和Selector,通道可以进行双向读…...
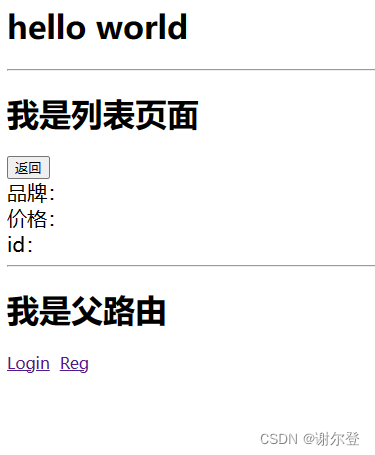
【Vue-Router】嵌套路由
footer.vue <template><div><router-view></router-view><hr><h1>我是父路由</h1><div><router-link to"/user">Login</router-link><router-link to"/user/reg" style"margin-left…...
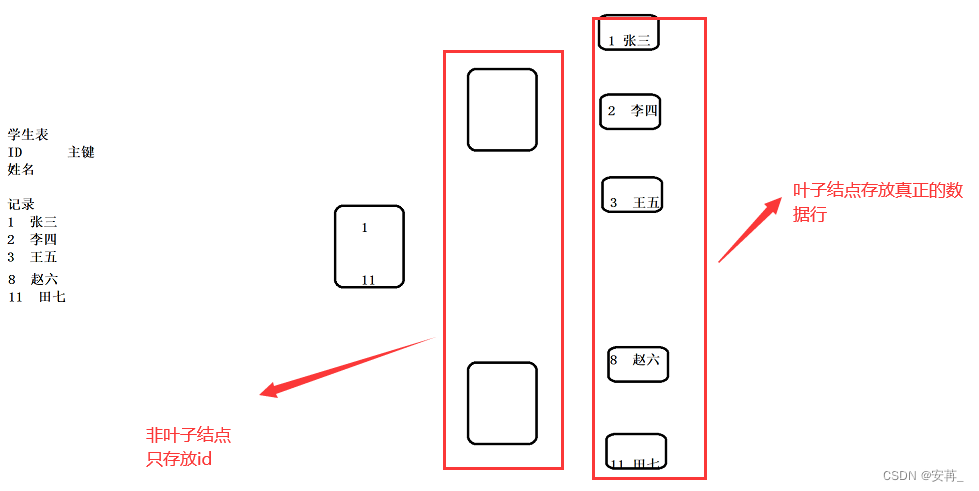
MySQL索引总结
MySQL索引总结 1.索引的概念、作用与使用场景 本质上就是减少读写磁盘的次数。 索引是一种特殊的文件,包含这对数据表中所有记录的引用指针,可以对表中的一列或多列创建索引,并指定索引的类型,每种类型都有对应数据结构实现。 …...

谷粒商城第十二天-基本属性销售属性管理功能的实现
目录 一、总述 二、前端部分 三、后端部分 四、总结 一、总述 前端的话,依旧是直接使用老师给的。 前端的话还是那些增删改查,业务复杂一点的话,无非就是设计到多个字段多个表的操作,当然这是后端的事了,前端这里…...

利用安全区域的概念解决移动端兼容不同手机刘海的问题
移动端 安全区 在做移动端的项目时,由于不同的手机设备设置的不同,有些手机在上方有刘海的设计,我们需要做适配,即把想要展示的内容放在安全区域内展示。 1.自定义导航栏 在pages.json中修改如下配置 {"path":"…...

数据结构---图
这里写目录标题 图的基本概念和术语基本概念和术语1基本概念和术语2 图的类型定义抽象数据类型定义二级目录二级目录 一级目录二级目录二级目录二级目录二级目录二级目录二级目录 图的基本概念和术语 基本概念和术语1 V代表顶点的有穷非空集合 E代表边的有穷集合 n为顶点 有向…...
励志长篇小说《周兴和》书连载之十八 内外交困搞发明
内外交困搞发明 路灯发出昏黄而惺忪的光影。 周兴和疲惫地从车间出来,拖着沉重的腿爬上几级石阶,准备回到家里去。可走到家门口,他想了想,又折了回去,在车间的一条长条椅子上,他用一块试验用的废料当枕头&…...
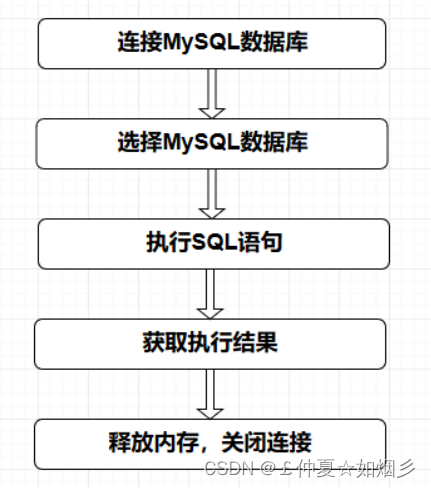
web基础入门和php语言基础入门 二
web基础入门和php语言基础入门 二 MySQL入门-续MySQL之数据查询操作MySQL其他知识点 php语言基础入门认识PHPPHP的工作流程安装PHP环境认识一个PHP程序PHP基础知识点进入正题 PHP与WEB交互PHP与MySQL交互总结 MySQL入门-续 MySQL之数据查询操作 WHERE 子句,条件限…...

typeScript 之 Array
工具: PlayGround 源码:GitHub TypeScript 数组简介 在TypeScript中, 使用[]表示数组, 它的结构:let valus: 类型名[] 数据; // 数字 let numList: number[] [1, 2, 3]; // 字符串 let strList: string[] ["hello"…...

【题解】二叉树的前中后遍历
文章目录 二叉树的前序遍历二叉树的中序遍历二叉树的后序遍历 二叉树的前序遍历 题目链接:二叉树的前序遍历 解题思路1:递归 代码如下: void preorder(vector<int>& res, TreeNode* root){if(root nullptr) return;//遇到空节点…...

文件操作/IO
文件 文件是一种在硬盘上存储数据的方式,操作系统帮我们把硬盘的一些细节都封装起来了,程序员只需要了解文件相关的接口即可,相当于操作文件就是间接的操作硬盘了 硬盘用来存储数据,和内存相比硬盘的存储空间更大,访问…...
基于Java+SpringBoot+vue前后端分离共享汽车管理系统设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
Mac RN环境搭建
RN ios android原生环境搭建有时候是真恶心,电脑环境不一样配置也有差异。 我已经安装官网的文档配置了ios环境 执行 npx react-nativelatest init AwesomeProject 报错 然后自己百度查呀执行 gem update --system 说是没有权限,执行失败。因为Mac…...

log4j教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;我们也可以控制每一条日志的输出格式;…...

DP——背包问题
DP——背包问题 01背包问题分数背包问题多重背包问题完全背包问题 当我们谈论背包问题时,可以想象成一个小朋友要去旅行,但是他只能带一个容量有限的背包。他有一些物品可以选择放入背包,每个物品都有自己的重量和价值。小朋友的目标是在不超…...
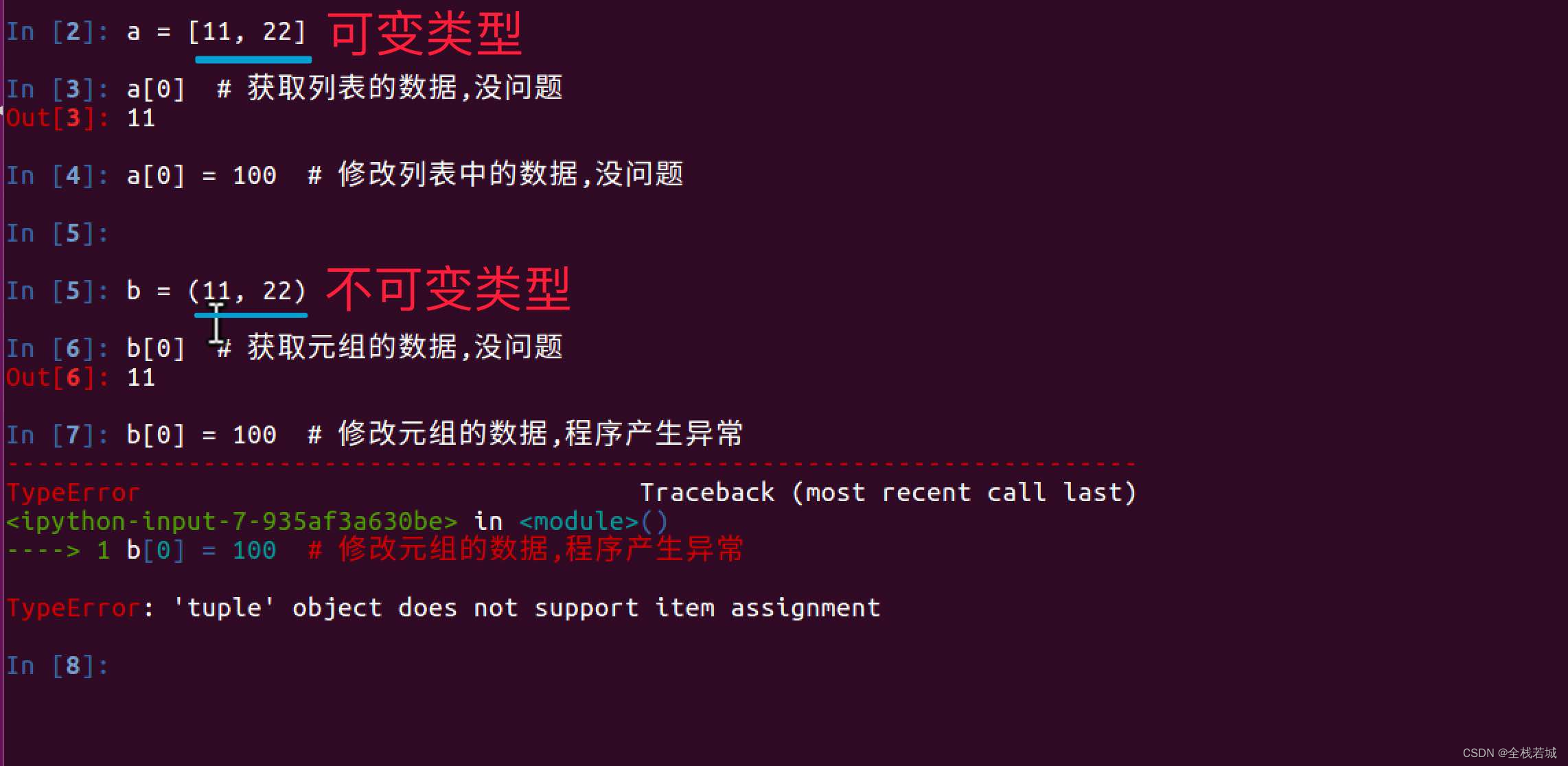
【从零学习python 】29. 「函数参数详解」——了解Python函数参数的不同用法
文章目录 函数参数详解一、缺省参数二、不定长参数三、缺省参数在*args后面可变、不可变类型总结 进阶案例 函数参数详解 一、缺省参数 调用函数时,缺省参数的值如果没有传入,则取默认值。 下例会打印默认的age,如果age没有被传入…...
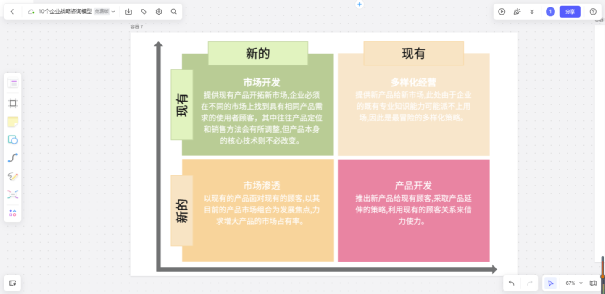
10个经典战略分析模型,助力洞察市场明确优势
在企业的经营管理过程中,要时刻清晰内外部环境和自身的优劣势,做好企业略规划,进行企业内外部资源的分析,对经营环境,企业核心竞争力有足够的判断,才能明确企业的发展方向。本文为大家分享10个常用的战略分…...

C++(Qt)软件调试---将调试工具安装到AeDebug(11)
C(Qt)软件调试—将调试工具安装到AeDebug(11) 文章目录 C(Qt)软件调试---将调试工具安装到AeDebug(11)1、前言1.1 使用的调试工具 2、调试器安装1.1 WinDbg1.2 procdump1.3 DrMinGW1.4 vsjitdebugger 更多精彩内容👉个…...

CS Demo Manager:3步掌握免费CS比赛回放分析,快速提升竞技水平终极指南
CS Demo Manager:3步掌握免费CS比赛回放分析,快速提升竞技水平终极指南 【免费下载链接】cs-demo-manager Companion application for your Counter-Strike demos. 项目地址: https://gitcode.com/gh_mirrors/cs/cs-demo-manager CS Demo Manager…...

腾讯 Ardot 深度评测:一句话画 App,一键转代码,Figma 终于有了一个能打的对手?
2026 年 5 月 18 日,腾讯自研 AI 设计智能体平台 Ardot 正式公测。它不是又一个"AI 画图工具",而是一个真正打通产品、设计、研发三端的协作利器——从一句话生成可编辑设计稿,到一键交付生产级代码,全在一个工具里闭环…...
)
AI动态简报之商业洞察篇(2026.05.24)
聚焦:AI商业应用与变现 5条精选💡 第1条:大模型进入"价值验证年"——行业从技术信仰转向商业回报商业价值:2026年5月,全球AI行业呈现清晰转折信号:行业正从"技术信仰期"(2…...

AI智能体:从概念到现实的技术演进与应用前景
AI智能体正渐渐从科幻概念转变成现实应用里的关键角色,这是随着人工智能技术的快速发展而出现的情况。按照2024年发布的报告来看,全球已经存在超过67%的企业其正在规划或者早已经部署了和AI智能体相关的项目,预计到2026年的时候,这…...

如何用Flut Renamer高效管理文件:跨平台批量重命名完整指南
如何用Flut Renamer高效管理文件:跨平台批量重命名完整指南 【免费下载链接】renamer Flut Renamer - A bulk file renamer written in flutter (dart). Available on Linux, Windows, Android, iOS and macOS. 项目地址: https://gitcode.com/gh_mirrors/ren/ren…...

Godot 4.0桌面应用开发实战:跨平台GUI工程化落地指南
1. 这不是游戏引擎的“副业”,而是桌面开发的新路径很多人第一次看到“用Godot做桌面应用”时,下意识会皱眉:一个标榜“2D/3D游戏开发”的引擎,去碰文件管理器、RSS阅读器、本地笔记工具这类传统桌面软件?是不是大炮打…...

终极指南:如何使用Universal x86 Tuning Utility释放你的硬件潜能
终极指南:如何使用Universal x86 Tuning Utility释放你的硬件潜能 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility …...

ChatGPT账号被封怎么办?20年合规架构师给出终极答案:1套可审计的账号生命周期管理SOP
更多请点击: https://codechina.net 第一章:ChatGPT账号被封怎么办 当您的ChatGPT账号突然无法登录、提示“Account suspended”或跳转至封禁通知页时,需冷静判断原因并采取合规应对措施。OpenAI官方明确指出,封禁通常源于违反《…...

DeepXDE终极指南:5分钟快速掌握科学机器学习神器
DeepXDE终极指南:5分钟快速掌握科学机器学习神器 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde 还在为复杂的偏微分方程求解而头疼吗࿱…...

Cursor Free VIP:AI编程助手Pro功能永久免费的技术解决方案
Cursor Free VIP:AI编程助手Pro功能永久免费的技术解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...