[PyTorch][chapter 50][创建自己的数据集 2]
前言:
这里主要针对图像数据进行预处理.定义了一个 class Pokemon(Dataset) 类,实现
图像数据集加载,划分的基本方法.
目录:
- 整体框架
- __init__
- load_images
- save_csv
- divide_data
- __len__
- denormalize
- __getitem__
- main
- ImageFolder
一 整体框架
我们需要创建一个自定义的数据集类,该类必须继承自Dataset类,
重点实现以下三个方法:
__init__
__len__()
__getitem__()
二 __init__
实现了图像数据集的加载
根据mode 进行划分
def __init__(self, root, resize, mode,fileName):#初始化函数super(Pokemon, self).__init__()self.root = rootself.resize = resizeself.name2label ={}#遍历目录path = os.path.join(root)#用子目录文件夹名字作为分类keyfor name in sorted(os.listdir(path)):subDir = os.path.join(root, name)if not os.path.isdir(subDir):continueelse:self.name2label[name] = len(self.name2label.keys())csv_path = os.path.join(self.root, fileName)print("\n csv_path: ",csv_path)if not os.path.exists(csv_path):images = self.load_images()self.save_csv(fileName, images)self.images, self.labels = self.load_csv(fileName)self.divide_data(mode)三 load_images
加载指定目录下面的图片,
把图片路径保存到列表里面
def load_images(self):images =[]for name in self.name2label.keys():#pokeon\\newtwoo\\00001.png#返回所有匹配的文件路径列表。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。下面是使用glob.glob的例子:pngPath = os.path.join(self.root, name,'*.png')jpgPath = os.path.join(self.root, name,'*.jpg')jpegPath = os.path.join(self.root, name,'*.jpeg')png = glob.glob(pngPath)jpg =glob.glob(jpgPath)jpeg = glob.glob(jpegPath)images +=jpgimages +=jpegimages +=pngprint("\n images ",len(images))random.shuffle(images)return images四 save_csv
图片路径,标签保存到csv 文件里面
#image, labeldef save_csv(self, fileName, images):path = os.path.join(self.root, fileName)csvfile = open(path,mode='w',newline='')writer = csv.writer(csvfile)for img in images:name = img.split(os.sep)[-2]label = self.name2label[name]writer.writerow([img, label])csvfile.close()四 load_csv
加载 csv 文件
def load_csv(self, fileName):path = os.path.join(self.root, fileName)csvfile = open(path,mode='r',newline='')reader = csv.reader(csvfile)images =[]labels =[]for row in reader:img, label = rowlabel = int(label)images.append(img)labels.append(label)m = len(images)n = len(labels)print("\n number images: %d number labels: %d"%(m,n))return images,labels五 divide_data
数据集划分
训练集: 60%
验证集: 20%
测试机:20%
def divide_data(self,mode):N = len(self.images)if 'train' == mode: #0->60%start = 0end = int(0.6*N)elif 'val' == mode:#60%->80%start = int(0.6*N)end = int(0.8*N)else:#80%->100%start = int(0.8*N)end = Nself.images = self.images[start:end]self.labels = self.labels[start:end]m = len(self.images )print("\n number divide images: %d "%(m))六 __len__
返回数据集大小
def __len__(self):#总的数据N = len(self.images)return N七 denormalize
图像数据 标准后,当需要显示原图片的时候,需要反标准化
def denormalize(self,x_hat):#x_hat =(x-mean)/std#x = x_hat*std+mean#x: [c,h,w]#mean: [3]=>[3,1,1]mean=[0.485, 0.456, 0.406]std=[0.229, 0.224, 0.225]mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)std = torch.tensor(std).unsqueeze(1).unsqueeze(1)x =x_hat*std+meanreturn x八 __getitem__
根据指定的索引获取对应的图片,以及标签值
def __getitem__(self, index):#返回当前index 对应的图片数据#self.images, self.labels#idx ~[0,N]img_path = self.images[index] #图片路径label = self.labels[index] #图片标签#print("\n img_path",img_path)tf = transforms.Compose([ lambda x:Image.open(x).convert('RGB'),transforms.Resize((int(self.resize*1.25) , int(self.resize*1.25))), transforms.RandomRotation(15), transforms.ToTensor(),transforms.CenterCrop(self.resize),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])img = tf(img_path)label = torch.tensor(label)#print("\n index ",index, "\t img ",img.shape,"\t label ",label)return img, label九 main
1 先定义一个class Pokemon(Dataset): 类,并实现上面的方法
2 数据集的迭代加载,以及通过visdom 工具加载显示
def main():root ='pokemon'resize =224mode = 'test' #数据集分为三种 tain,val,testcsvfile ='data.csv'db = Pokemon(root, resize, mode,csvfile)viz = visdom.Visdom()# datetime转字符串time.time() #显示当前的时间戳curtime = time.strftime('%H:%M:%S') #结构化输出当前的时间BATCH_SIZE = 32loader = DataLoader(dataset = db, batch_size = BATCH_SIZE,shuffle = True)for step, (batchX, batchY) in enumerate(loader):print( '| Step: ', step, '| batch x: ',batchX.shape, '| batch y: ', batchY.shape)viz.images(db.denormalize(batchX),nrow=8, win='batchX',opts=dict(title=curtime))viz.text(str(batchY.numpy()),win='batchY',opts=dict(title='label'))time.sleep(10)if __name__ == "__main__" :main()十 ImageFolder
自己的图像数据集如果有规律的话,可以直接用PyTorch API 函数实现 Pokemon
类的功能

from torchvision.datasets import ImageFolder
from torchvision import transformsimgMean =[0.485, 0.456, 0.406]
imgStd = [0.229, 0.224, 0.225]
normalize=transforms.Normalize(mean=imgMean,std=imgStd)
transform=transforms.Compose([transforms.RandomCrop(180),transforms.RandomHorizontalFlip(),transforms.ToTensor(), #将图片转换为Tensor,归一化至[0,1]normalize
])dataset=ImageFolder('./data/train',transform=transform)
参考:
torchvision.datasets.ImageFolder使用详解_☞源仔的博客-CSDN博客
课时102 自定义数据集实战-5_哔哩哔哩_bilibili
相关文章:
[PyTorch][chapter 50][创建自己的数据集 2]
前言: 这里主要针对图像数据进行预处理.定义了一个 class Pokemon(Dataset) 类,实现 图像数据集加载,划分的基本方法. 目录: 整体框架 __init__ load_images save_csv divide_data __len__ denormalize __g…...
SQL-每日一题【1341. 电影评分】
题目 表:Movies 表:Users 请你编写一个解决方案: 查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。 …...
基于DBN的伪测量配电网状态估计,DBN的详细原理
目录 背影 DBN神经网络的原理 DBN神经网络的定义 受限玻尔兹曼机(RBM) DBN的伪测量配电网状态估计 基本结构 主要参数 数据 MATALB代码 结果图 展望 背影 DBN是一种深度学习神经网络,拥有提取特征,非监督学习的能力,是一种非常好的分类算法,本文将DBN算法伪测量配电网…...
Python运算符全解析:技巧与案例探究
在Python编程中,运算符是强大的工具,能够使我们在数据处理和逻辑判断方面更加灵活。本篇博客将全面探讨Python中常用的运算符,包括算术、比较、逻辑、赋值、位、成员和身份运算符,通过实际案例为你展示如何妙用运算符解决问题。 …...

NPCon:AI模型技术与应用峰会北京站 (参会感受)
8月12日,我有幸参加了在北京皇家格兰云天大酒店举行的“AI模型技术与应用峰会”。 这次会议邀请了很多技术大咖,他们围绕: 六大论点 大模型涌现,如何部署训练架构与算力芯片 LLM 应用技术栈与Agent全景解析 视觉GPU推理服务部署 …...
为什么爬虫要用高匿代理IP?高匿代理IP有什么优点
只要搜代理IP,度娘就能给我们跳出很多品牌的推广,比如我们青果网路的。 正如你所看到的,我们厂商很多宣传用词都会用到高匿这2字。 这是为什么呢?高匿IP有那么重要吗? 这就需要我们从HTTP代理应用最多最广的…...
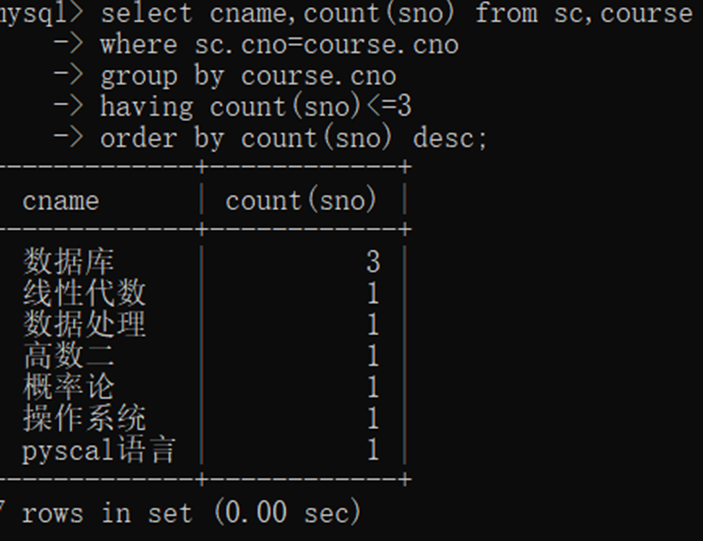
【JavaWeb】MySQL约束、事务、多表查询
1 约束 PRIMARY KEY 主键约束 UNIQUE 唯一约束 NOT NULL 非空约束 DEFAULT 默认值约束 FOREIGN KEY 外键约束 主键 主键值必须唯一且非空;每个表必须有一个主键 建表时主键约束 CREATE TABLE 表名 (字段名 字段类型 PRIMARY KEY,字段名 字段类型 );CR…...

【并发编程】自研数据同步工具优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
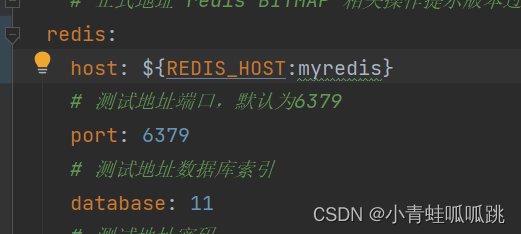
七、dokcer-compose部署springboot的jar
1、准备 打包后包名为 ruoyi-admin.jar 增加接口 httpL//{ip}:{port}/common/test/han #环境变量预application.yml 中REDIS_HOSTt的值,去环境变量去找;如果找不到REDIS_HOST就用myredis 1、Dockerfile FROM hlw/java:8-jreRUN ln -sf /usr/share/z…...

k8s 使用 containerd 运行时配置 http 私服
简介 Kubernetes 从 v1.20 开始弃用 Docker,并推荐用户切换到基于容器运行时接口(CRI)的容器引擎,如 containerd、cri-o 等。 目前使用的环境中使用了 Kubernetes v1.22.3,containerd 1.4.3,containerd 在…...

【新品发布】ChatWork企业知识库系统源码
系统简介 基于前后端分离架构以及Vue3、uni-app、ThinkPHP6.x、PostgreSQL、pgvector技术栈开发,包含PC端、H5端。 ChatWork支持问答式和文档式知识库,能够导入txt、doc、docx、pdf、md等多种格式文档。 导入数据完成向量化训练后,用户提问…...
疫情打卡 vue+springboot疾病防控管理系统java jsp源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 疫情打卡 vuespringboot 系统有1权限:管理…...

python --连接websocket
如果只是模拟js端发送接收的话,已经有了websocket server的话,只有client就好了 pip install websocket-client#-*- encoding:utf-8 -*-import sys sys.path.append("..") from socket import * import json, time, threading from websocket…...

数据库内日期类型数据大于小于条件查找注意事项
只传date格式的日期取查datetime的字段的话默认是 00:00:00 日期类型字符串需要使用 ’ ’ 单引号括住 使用大于小于条件查询某一天的日期数据 前后判断条件不能是同一天 一个例子 数据库内数据: 查询2023-08-14之后的数据: select * from tetst…...

网易有道押宝大模型,打响智能硬件突围战
本文转载自产业科技 自今年开年以来,AI大模型这场火势能不减,如今已燃到教育领域。 7月26日,网易有道举办了“powered by子曰”教育大模型应用成果发布会,推出国内首个教育领域垂直大模型“子曰”,并一口气发布了基于…...
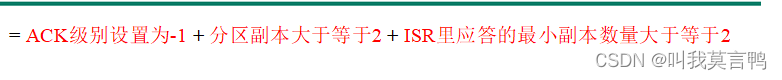
KAFKA第二课之生产者(面试重点)
生产者学习 1.1 生产者消息发送流程 在消息发送的过程中,涉及到了两个线程——main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到K…...
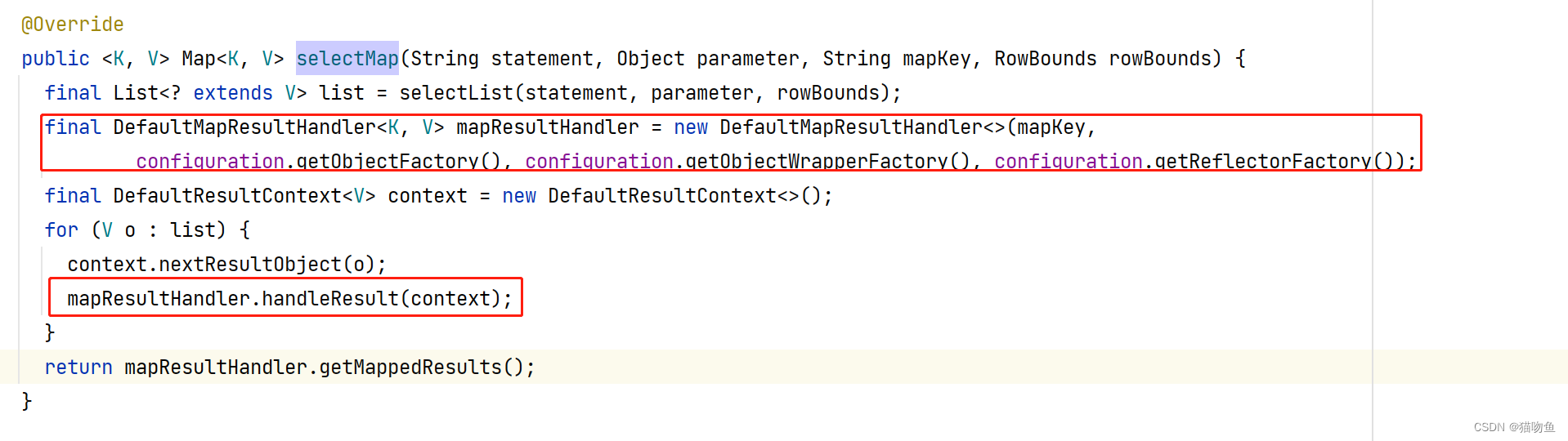
Mybatis 源码 ∞ :杂七杂八
文章目录 一、前言二、TypeHandler三、KeyGenerator四、Plugin1 Interceptor2 org.apache.ibatis.plugin.Plugin3. 调用场景 五、Mybatis 嵌套映射 BUG1. 示例2. 原因3. 解决方案 六、discriminator 标签七、其他1. RowBounds2. ResultHandler3. MapKey 一、前言 Mybatis 官网…...
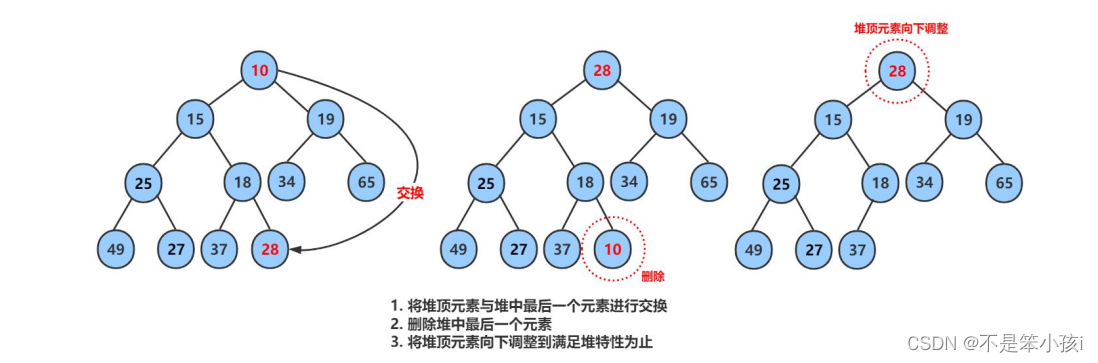
堆的实现以及应用
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大家三连关注&…...

MySql011——检索数据:过滤数据(使用正则表达式)
前提:使用《MySql006——检索数据:基础select语句》中创建的products表 一、正则表达式介绍 关于正则表达式的介绍大家可以看我的这一篇博客《Java038——正则表达式》,这里就不再累赘。 二、使用MySQL正则表达式 2.1、基本字符匹配 检索…...
数据结构与算法-栈(LIFO)(经典面试题)
一:面试经典 1. 如何设计一个括号匹配的功能?比如给你一串括号让你判断是否符合我们的括号原则, 栈 力扣 2. 如何设计一个浏览器的前进和后退功能? 思想:两个栈,一个栈存放前进栈&…...
)
课题框架设计:认知流形的拓扑缺陷与精神病理学映射(世毫九实验室原创课题)
课题框架设计:认知流形的拓扑缺陷与精神病理学映射(世毫九实验室原创课题) 作者:方见华 单位:世毫九实验室 摘要与核心观点 本课题基于世毫九实验室原创认知几何学框架及GLZ认知拓扑互补理论支撑,核心假设为…...

3步解决方案:用BG3 Mod Manager彻底解决博德之门3模组管理难题
3步解决方案:用BG3 Mod Manager彻底解决博德之门3模组管理难题 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 博德之门3模组管理器&…...

深入浅出arm7架构下大模型API调用,Taotoken多模型聚合平台接入指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 深入浅出arm7架构下大模型API调用,Taotoken多模型聚合平台接入指南 对于在arm7架构设备上进行开发的工程师而言&#x…...

高性能桌面管理架构解析:NoFences技术实现深度剖析
高性能桌面管理架构解析:NoFences技术实现深度剖析 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences NoFences作为一款开源免费的桌面管理工具,通过创新…...

VisualGGPK2终极指南:如何轻松编辑《流放之路》游戏资源文件
VisualGGPK2终极指南:如何轻松编辑《流放之路》游戏资源文件 【免费下载链接】VisualGGPK2 Library for Content.ggpk of PathOfExile (Rewrite of libggpk) 项目地址: https://gitcode.com/gh_mirrors/vi/VisualGGPK2 VisualGGPK2是一款专为《流放之路》玩家…...

GitHub汉化插件终极指南:3分钟打造中文开发环境,提升协作效率
GitHub汉化插件终极指南:3分钟打造中文开发环境,提升协作效率 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese …...

解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手
解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

高斯混合期望传播算法:突破高阶MIMO检测性能瓶颈
1. 项目概述与核心挑战在无线通信系统的演进中,多输入多输出(MIMO)技术早已不是新鲜概念,它通过部署多根天线,在相同的频带内同时传输多个独立的数据流,从而成倍地提升了频谱效率和系统容量。然而ÿ…...

抖音无水印视频解析终极指南:5分钟快速上手DouYinBot
抖音无水印视频解析终极指南:5分钟快速上手DouYinBot 【免费下载链接】DouYinBot 该项目仅自用,不提供抖音视频下载 项目地址: https://gitcode.com/gh_mirrors/do/DouYinBot 在短视频创作日益普及的今天,如何快速获取抖音无水印视频、…...

Go语言消息队列集成与异步通信实践
Go语言消息队列集成与异步通信实践 引言 消息队列是微服务架构中实现异步通信的核心组件。本文将深入探讨Go语言中常见的消息队列系统(Kafka、RabbitMQ、Redis)的集成与最佳实践。 一、消息队列概述 1.1 消息队列的作用 场景说明解耦生产者和消费者解耦&…...