C++ STL priority_queue
目录
一.认识priority_queue
二. priority_queue的使用
三.仿函数
1.什么是仿函数
2.控制大小堆
3.TopK问题
四.模拟实现priority_queue
1.priority_queue的主要接口框架
2.堆的向上调整算法
3.堆的向下调整算法
4.仿函数控制大小堆
五.priority_queue模拟实现整体代码和测试
一.认识priority_queue
priority_queue----reference
1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
5. 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
6. 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
二. priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆。
| 函数声明 | 接口说明 |
| priority_queue()/priority_queue(first,last) | 构造一个空的优先级队列 |
| empty( ) | 检测优先级队列是否为空,是返回true,否则返回 false |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
测试:
#include<queue>
#include<iostream>
using namespace std;
int main()
{//够一个空的优先级队列priority_queue<int> pri_q;//插入数据pri_q.push(2);pri_q.push(27);pri_q.push(25);pri_q.push(244);pri_q.push(212);pri_q.push(9);//连续取出堆顶数据打印while (!pri_q.empty()){cout << pri_q.top()<<' ';pri_q.pop();}return 0;
}
三.仿函数
如果我们像控制优先级队列是大堆排,还是小堆排,就需要我们使用放仿函数去控制。
1.什么是仿函数
首先仿函数是一个类,它重载了括号运算符,在使用的时候,定义出对象,就像函数一样使用。
例如:
//仿函数
template<class T>
struct Add
{int operator()(int e1, int e2){return e1 + e2;}
};int main()
{Add<int> add;cout << add(10, 20) << endl;return 0;
}
2.控制大小堆
在头文件<functional>中包含了两个仿函数,less和granter。
less是判断小于的仿函数,对应堆排出来是大堆,granter是判断大于的仿函数,对应堆排出来是小堆。
#include<queue>
#include<functional>
#include<iostream>
using namespace std;
int main()
{//小堆priority_queue<int,vector<int>,greater<int>> small_q;//插入数据small_q.push(2);small_q.push(27);small_q.push(25);small_q.push(244);small_q.push(212);small_q.push(9);//连续取出堆顶数据打印while (!small_q.empty()){cout << small_q.top()<<' ';small_q.pop();}cout << endl;//大堆priority_queue<int, vector<int>, less<int>> big_q;//插入数据big_q.push(2);big_q.push(27);big_q.push(25);big_q.push(244);big_q.push(212);big_q.push(9);//连续取出堆顶数据打印while (!big_q.empty()){cout << big_q.top() << ' ';big_q.pop();}return 0;
}
3.TopK问题
这个问题我们在数据结构二叉树堆的部分已经详细的分析了,感兴趣的可以去看看:数据结构---二叉树---堆
四.模拟实现priority_queue
1.priority_queue的主要接口框架
template<class T, class Continer = vector<T>>
class Priority_queue
{
public://插入数据void push(const T& val){_con.push_back(val);//向上调整adjust_up(_con.size() - 1);}//删除数据void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();//向下调整adjust_down(0);}//返回栈顶数据const T& top(){return _con[0];}//判断栈是否为空bool empty(){return _con.empty();}private:Continer _con;//适配容器,默认是vector
};
2.堆的向上调整算法

堆的插入需要保证插入以后还是一个堆,所以这里用到了向上调整算法。
在数组中就是,插入一个数在数组的尾上,再通过向上调整算法,调整到合适的位置。
在以堆的角度来看(小堆)为例,将新插入的值看作孩子与其父亲位置的值比较,如果比父亲位置的值还要小,那就将该值与父亲位置的值进行交换,交换后将父亲位置当作新的孩子,继续与其父亲位置的值比较,这样一直向上比较并交换,直到父亲位置的值比自己小或该位置已经没有父亲了,调整结束。

//向上调整算法void adjust_up(size_t child){//1.计算父亲size_t parent = (child - 1) / 2;while (child > 0){//如果孩子比父亲大,就交换,否则就直接推出if (_con[parent]< _con[child]){swap(_con[parent], _con[child]);//交换之后,父亲成为新的孩子,继续算新的父亲,直到没有孩子了child = parent;parent = (child - 1) / 2;}else{break;}}}3.堆的向下调整算法
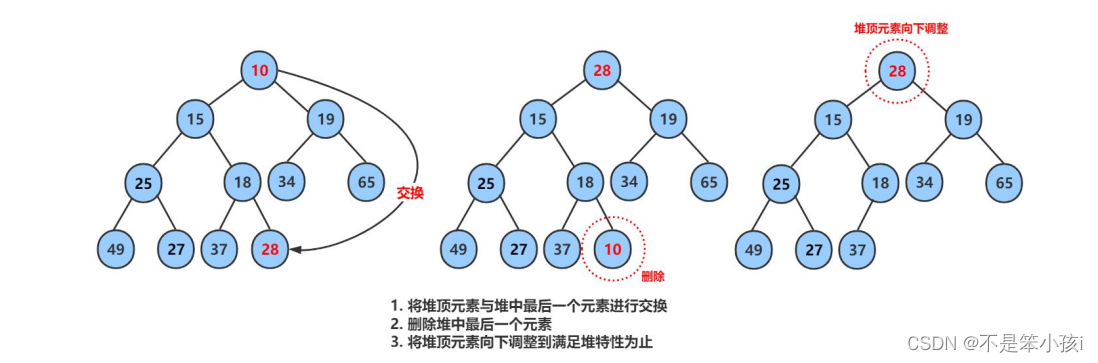
向下调整算法(大堆为例):从第一个结点开始,找到其孩子结点中较大的一个与父亲位置进行交换,然后将孩子作为新的父亲,再次比较和交换,直到父亲结点比两个结点的值都大或者已经没有孩子了为止。
//向下调整void adjust_down(size_t parent){//计算出左孩子size_t child = parent * 2 + 1;while (child < _con.size()){//判断是否有右孩子,右孩子是否比左孩子大if (child + 1 < _con.size() && _con[child]< _con[child + 1]){child++;}//较大的孩子如果比父亲大就交换,否则就直接退出循环if (_con[parent]< _con[child]){swap(_con[child], _con[parent]);}else{break;}//孩子成为新的父亲,继续算出新的孩子parent = child;child = parent * 2 + 1;}}4.仿函数控制大小堆
//比较小于的仿函数,控制大堆template<class T>struct less{bool operator()(const T& val1,const T& val2){return val1 < val2;}};//比较大于的仿函数,控制小堆template<class T>struct grater{bool operator()(const T& val1, const T& val2){return val1 > val2;}};template<class T, class Continer = vector<T>,class Compare =less<T>>//默认大堆
class Priority_queue
{
public:Compare com;//插入数据void push(const T& val){_con.push_back(val);//向上调整adjust_up(_con.size() - 1);}//删除数据void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();//向下调整adjust_down(0);}//返回栈顶数据const T& top(){return _con[0];}//判断栈是否为空bool empty(){return _con.empty();}private:Continer _con;//适配容器,默认是vector
};
五.priority_queue模拟实现整体代码和测试
Queue.hpp:
template<class T, class Continer = vector<T>,class Compare =less<T>>class Priority_queue{public:Compare com;void push(const T& val){_con.push_back(val);adjust_up(_con.size()-1);}void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}const T& top(){return _con[0];}size_t size(){return _con.size();}bool empty(){return _con.empty();}private://向上调整算法void adjust_up(size_t child){size_t parent = (child - 1) / 2;while (child > 0){if (com(_con[parent] , _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}//向下调整void adjust_down(size_t parent){size_t child = parent * 2 + 1;while (child<_con.size()){if (child + 1 < _con.size() && com(_con[child],_con[child + 1])){child++;}if (com(_con[parent] , _con[child])){swap(_con[child], _con[parent]);}else{break;}parent = child;child = parent * 2 + 1;}}private:Continer _con;};
}main:
#include<iostream>
#include<vector>
#include<list>
using std::vector;
using std::list;
using std::cout;
using std::endl;
using std::swap;#include"Queue.hpp"
using namespace Qikun;int main()
{//小堆Priority_queue<int,std::vector<int>, greater<int>> small_q;//插入数据small_q.push(2);small_q.push(27);small_q.push(25);small_q.push(244);small_q.push(212);small_q.push(9);//连续取出堆顶数据打印std::cout << "小堆:";while (!small_q.empty()){cout << small_q.top()<<' ';small_q.pop();}cout << endl;//大堆Priority_queue<int, vector<int>, less<int>> big_q;//插入数据big_q.push(2);big_q.push(27);big_q.push(25);big_q.push(244);big_q.push(212);big_q.push(9);//连续取出堆顶数据打印cout << "大堆:";while (!big_q.empty()){cout << big_q.top() << ' ';big_q.pop();}return 0;
}

相关文章:
C++ STL priority_queue
目录 一.认识priority_queue 二. priority_queue的使用 三.仿函数 1.什么是仿函数 2.控制大小堆 3.TopK问题 四.模拟实现priority_queue 1.priority_queue的主要接口框架 2.堆的向上调整算法 3.堆的向下调整算法 4.仿函数控制大小堆 五.priority_queue模拟实现整体代码和测…...

[PyTorch][chapter 50][创建自己的数据集 2]
前言: 这里主要针对图像数据进行预处理.定义了一个 class Pokemon(Dataset) 类,实现 图像数据集加载,划分的基本方法. 目录: 整体框架 __init__ load_images save_csv divide_data __len__ denormalize __g…...
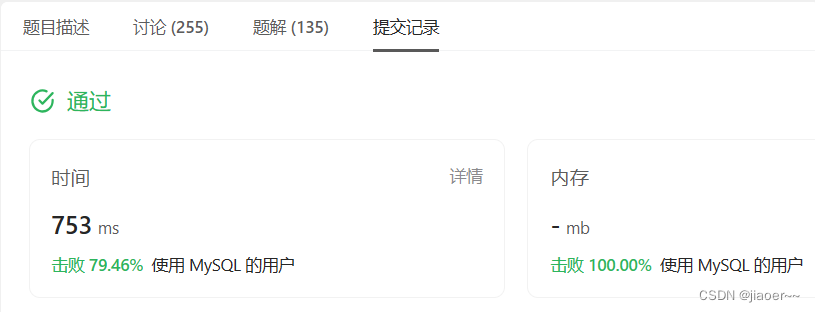
SQL-每日一题【1341. 电影评分】
题目 表:Movies 表:Users 请你编写一个解决方案: 查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。 …...
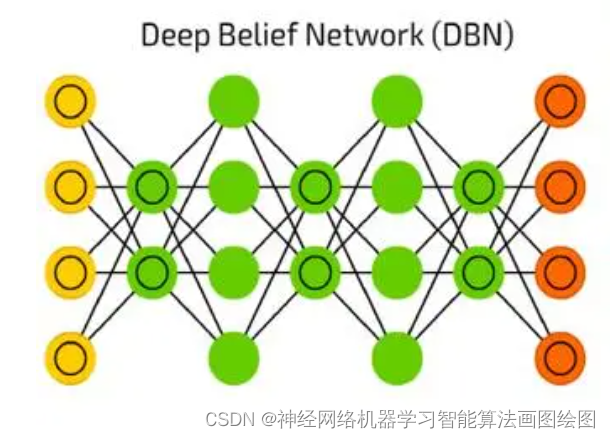
基于DBN的伪测量配电网状态估计,DBN的详细原理
目录 背影 DBN神经网络的原理 DBN神经网络的定义 受限玻尔兹曼机(RBM) DBN的伪测量配电网状态估计 基本结构 主要参数 数据 MATALB代码 结果图 展望 背影 DBN是一种深度学习神经网络,拥有提取特征,非监督学习的能力,是一种非常好的分类算法,本文将DBN算法伪测量配电网…...
Python运算符全解析:技巧与案例探究
在Python编程中,运算符是强大的工具,能够使我们在数据处理和逻辑判断方面更加灵活。本篇博客将全面探讨Python中常用的运算符,包括算术、比较、逻辑、赋值、位、成员和身份运算符,通过实际案例为你展示如何妙用运算符解决问题。 …...

NPCon:AI模型技术与应用峰会北京站 (参会感受)
8月12日,我有幸参加了在北京皇家格兰云天大酒店举行的“AI模型技术与应用峰会”。 这次会议邀请了很多技术大咖,他们围绕: 六大论点 大模型涌现,如何部署训练架构与算力芯片 LLM 应用技术栈与Agent全景解析 视觉GPU推理服务部署 …...
为什么爬虫要用高匿代理IP?高匿代理IP有什么优点
只要搜代理IP,度娘就能给我们跳出很多品牌的推广,比如我们青果网路的。 正如你所看到的,我们厂商很多宣传用词都会用到高匿这2字。 这是为什么呢?高匿IP有那么重要吗? 这就需要我们从HTTP代理应用最多最广的…...
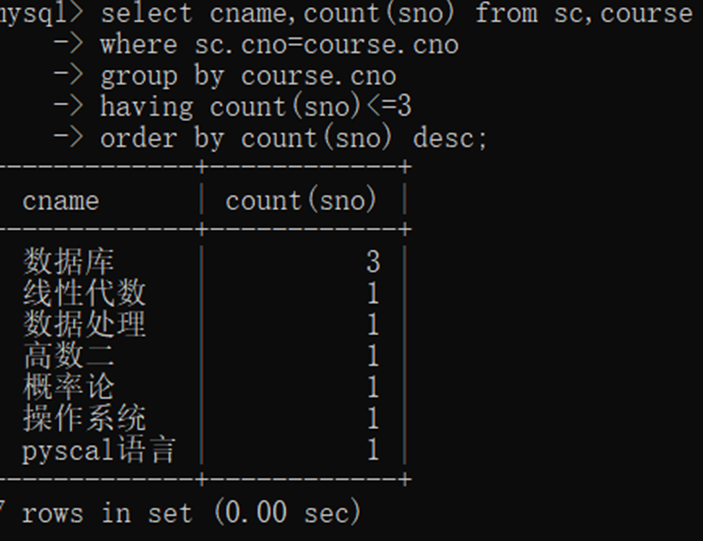
【JavaWeb】MySQL约束、事务、多表查询
1 约束 PRIMARY KEY 主键约束 UNIQUE 唯一约束 NOT NULL 非空约束 DEFAULT 默认值约束 FOREIGN KEY 外键约束 主键 主键值必须唯一且非空;每个表必须有一个主键 建表时主键约束 CREATE TABLE 表名 (字段名 字段类型 PRIMARY KEY,字段名 字段类型 );CR…...

【并发编程】自研数据同步工具优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
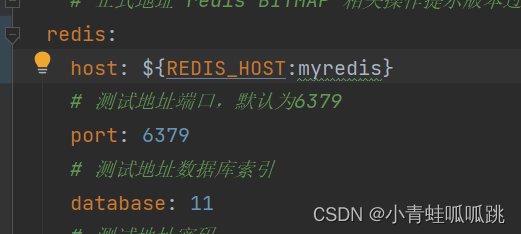
七、dokcer-compose部署springboot的jar
1、准备 打包后包名为 ruoyi-admin.jar 增加接口 httpL//{ip}:{port}/common/test/han #环境变量预application.yml 中REDIS_HOSTt的值,去环境变量去找;如果找不到REDIS_HOST就用myredis 1、Dockerfile FROM hlw/java:8-jreRUN ln -sf /usr/share/z…...

k8s 使用 containerd 运行时配置 http 私服
简介 Kubernetes 从 v1.20 开始弃用 Docker,并推荐用户切换到基于容器运行时接口(CRI)的容器引擎,如 containerd、cri-o 等。 目前使用的环境中使用了 Kubernetes v1.22.3,containerd 1.4.3,containerd 在…...

【新品发布】ChatWork企业知识库系统源码
系统简介 基于前后端分离架构以及Vue3、uni-app、ThinkPHP6.x、PostgreSQL、pgvector技术栈开发,包含PC端、H5端。 ChatWork支持问答式和文档式知识库,能够导入txt、doc、docx、pdf、md等多种格式文档。 导入数据完成向量化训练后,用户提问…...
疫情打卡 vue+springboot疾病防控管理系统java jsp源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 疫情打卡 vuespringboot 系统有1权限:管理…...

python --连接websocket
如果只是模拟js端发送接收的话,已经有了websocket server的话,只有client就好了 pip install websocket-client#-*- encoding:utf-8 -*-import sys sys.path.append("..") from socket import * import json, time, threading from websocket…...

数据库内日期类型数据大于小于条件查找注意事项
只传date格式的日期取查datetime的字段的话默认是 00:00:00 日期类型字符串需要使用 ’ ’ 单引号括住 使用大于小于条件查询某一天的日期数据 前后判断条件不能是同一天 一个例子 数据库内数据: 查询2023-08-14之后的数据: select * from tetst…...

网易有道押宝大模型,打响智能硬件突围战
本文转载自产业科技 自今年开年以来,AI大模型这场火势能不减,如今已燃到教育领域。 7月26日,网易有道举办了“powered by子曰”教育大模型应用成果发布会,推出国内首个教育领域垂直大模型“子曰”,并一口气发布了基于…...
KAFKA第二课之生产者(面试重点)
生产者学习 1.1 生产者消息发送流程 在消息发送的过程中,涉及到了两个线程——main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到K…...
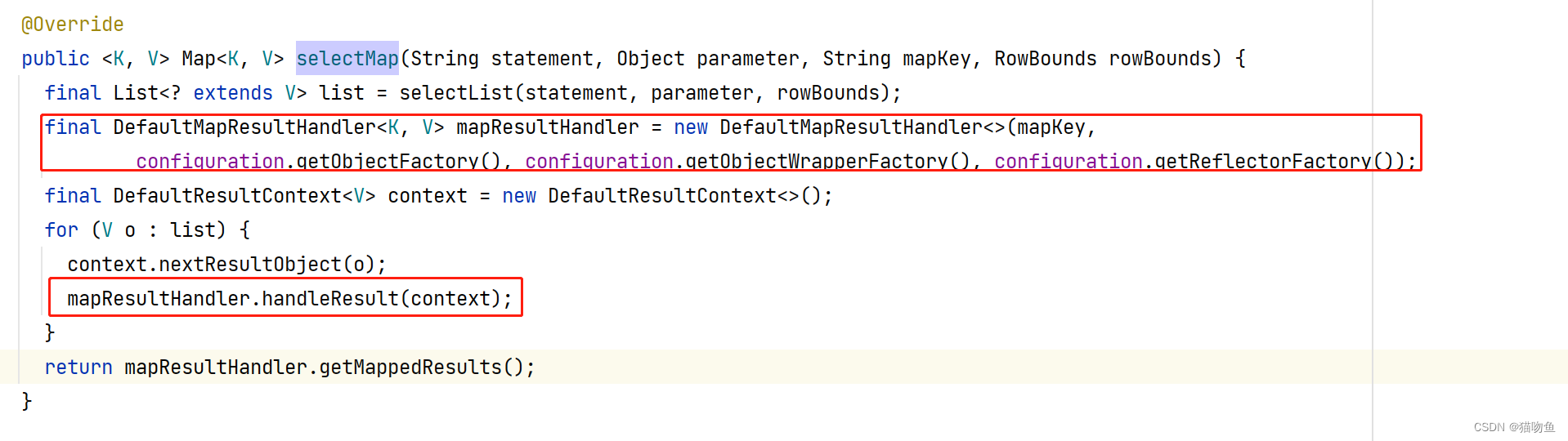
Mybatis 源码 ∞ :杂七杂八
文章目录 一、前言二、TypeHandler三、KeyGenerator四、Plugin1 Interceptor2 org.apache.ibatis.plugin.Plugin3. 调用场景 五、Mybatis 嵌套映射 BUG1. 示例2. 原因3. 解决方案 六、discriminator 标签七、其他1. RowBounds2. ResultHandler3. MapKey 一、前言 Mybatis 官网…...
堆的实现以及应用
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大家三连关注&…...

MySql011——检索数据:过滤数据(使用正则表达式)
前提:使用《MySql006——检索数据:基础select语句》中创建的products表 一、正则表达式介绍 关于正则表达式的介绍大家可以看我的这一篇博客《Java038——正则表达式》,这里就不再累赘。 二、使用MySQL正则表达式 2.1、基本字符匹配 检索…...

Arm功能安全编译器6.6文档体系与认证要点解析
1. Arm Compiler for Functional Safety 6.6文档体系解析在功能安全软件开发领域,工具链的可靠性和文档完整性直接关系到最终产品的认证通过率。Arm Compiler for Functional Safety 6.6作为面向汽车电子、工业控制等安全关键领域的专用工具链,其文档体系…...
如何用Zotero PDF Translate插件高效阅读外文文献:一站式终极指南
如何用Zotero PDF Translate插件高效阅读外文文献:一站式终极指南 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/…...

交叉验证方差分析:从数学原理到工程实践
1. 交叉验证:从直觉到数学的模型评估基石在机器学习的日常工作中,我们训练模型、调整参数,最终目标都是希望模型在真实世界中、在从未见过的数据上,依然能稳定可靠地工作。但一个棘手的问题始终存在:我们如何知道一个模…...

多指灵巧手技术解析与应用实践
1. 多指灵巧手技术概述 多指灵巧手作为机器人操作系统的核心执行部件,其设计理念直接决定了机器人在非结构化环境中的操作能力。这类机械手通过模拟人类手指的解剖学结构和运动方式,实现了从简单抓取到复杂精细操作的功能跨越。与传统的二指夹持器相比&a…...
)
RHEL 9保姆级教程:手把手教你用阿里云镜像替换官方yum源(附完整命令)
RHEL 9极速配置指南:阿里云镜像源一键切换实战刚拿到RHEL 9服务器时,最令人抓狂的莫过于看着进度条像蜗牛一样缓慢爬行。官方源的速度不仅影响工作效率,更可能让紧急部署变成一场噩梦。本文将用最直白的操作语言,带你三步完成阿里…...

避坑指南:在VMware里定制麒麟KylinOS 2303自动安装镜像,我踩过的那些‘雷’
麒麟KylinOS 2303自动安装镜像定制实战:那些手册没告诉你的细节当第一次尝试为麒麟KylinOS 2303创建自定义安装镜像时,我以为这不过是简单的文件替换和配置调整。直到深夜三点面对第七次失败的ISO构建,才意识到这个看似标准化的流程里藏着无数…...

机器学习赋能系统综述:SyROCCo项目实战解析与NLP应用指南
1. 项目概述:当系统综述遇上机器学习如果你做过系统综述,一定对那种“望洋兴叹”的感觉不陌生。面对动辄成千上万的文献,光是筛选、阅读、提取数据这几步,就足以耗掉一个团队数月甚至数年的精力。更头疼的是,等你终于完…...

高能物理数据分析实战:从W玻色子截面测量到机器学习应用
1. 项目概述:从海量对撞数据到物理发现如果你对宇宙的构成充满好奇,想知道我们是如何发现希格斯玻色子,或者顶夸克的质量是如何被精确测量的,那么高能物理数据分析就是你正在寻找的钥匙。这听起来可能离日常生活很远,但…...

相对噪声模型下梯度下降的收敛性分析与实践指南
1. 项目概述:当梯度方向遇上相对噪声在机器学习和优化的世界里,梯度下降算法就像我们手中的指南针,指引着我们在复杂的高维地形中寻找最低点。但现实往往没那么理想,这个指南针的指针会晃动,我们得到的梯度方向总带着“…...

机器学习加速格点QCD计算:从强子真空极化到重子质量修正
1. 项目概述:当格点QCD遇上机器学习在格点量子色动力学(Lattice QCD)的计算世界里,我们这些常年跟海量数据和超级计算机打交道的人,最头疼的问题之一就是“噪声”。这可不是实验室里嗡嗡响的那种声音,而是统…...