Kafka第一课概述与安装
生产经验 面试重点
Broker面试重点
代码,开发重点
67 章了解
如何记录行为数据
1. Kafka概述
1.产生原因
前端 传到日志 日志传到Flume 传到HADOOP
但是如果数据特比大,HADOOP就承受不住了
2.Kafka解决问题
控流消峰
Flume传给Kafka
存到Kafka
Hadoop 从Kafka取数据 ,而不是Kafka强行发
类似 菜鸟驿站, 先存取来,我们主动去取,或者指定他去送
存到HDFS的,一定不是实时数据,因为HDFS太慢了

3.应用场景
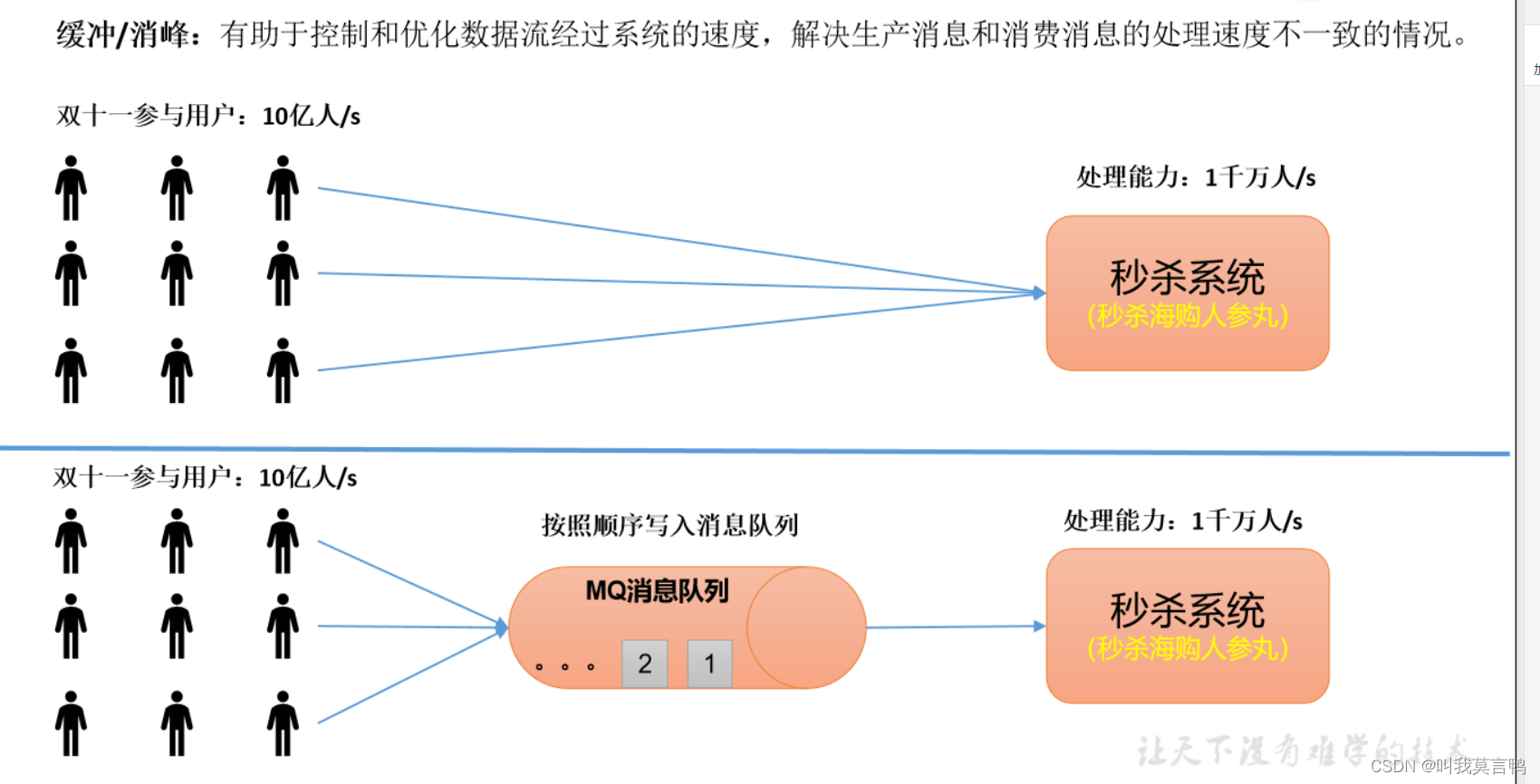
1. 缓冲/消峰
消息队列存储数据,而不是直接发给处理系统,处理完一部分,再取,再处理
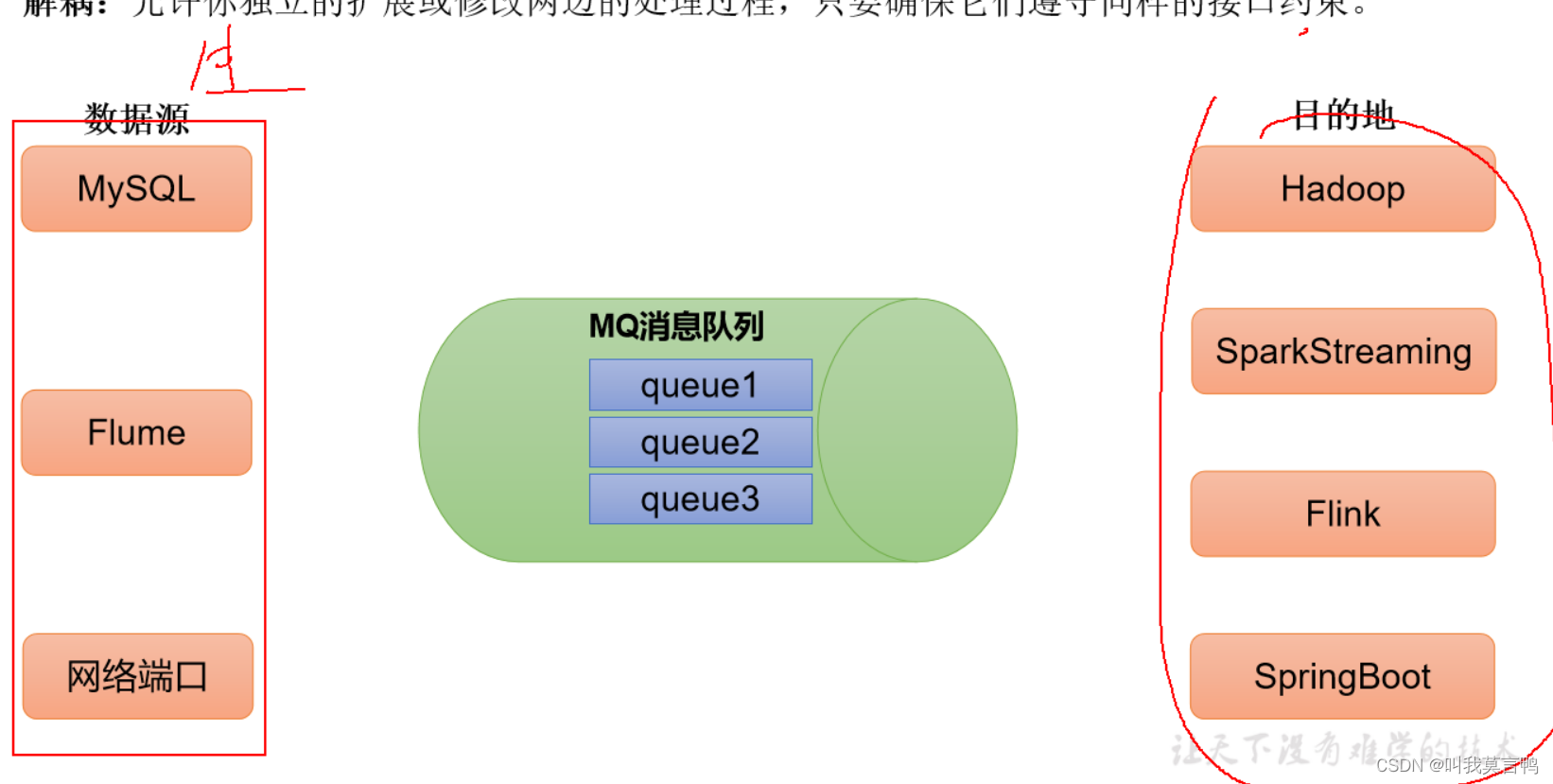
2.解耦
通过中间件接口,适配不同数据源和目的地
3.异步通信
允许用户将消息放入队列,但不立即处理,然后再需要的时候处理。
为什么异步处理快: 同步需要等待
点餐:
同步:服务员过来给我点餐 ,这里需要服务员过来
异步:扫桌子码自己点餐
4.消息队列模式

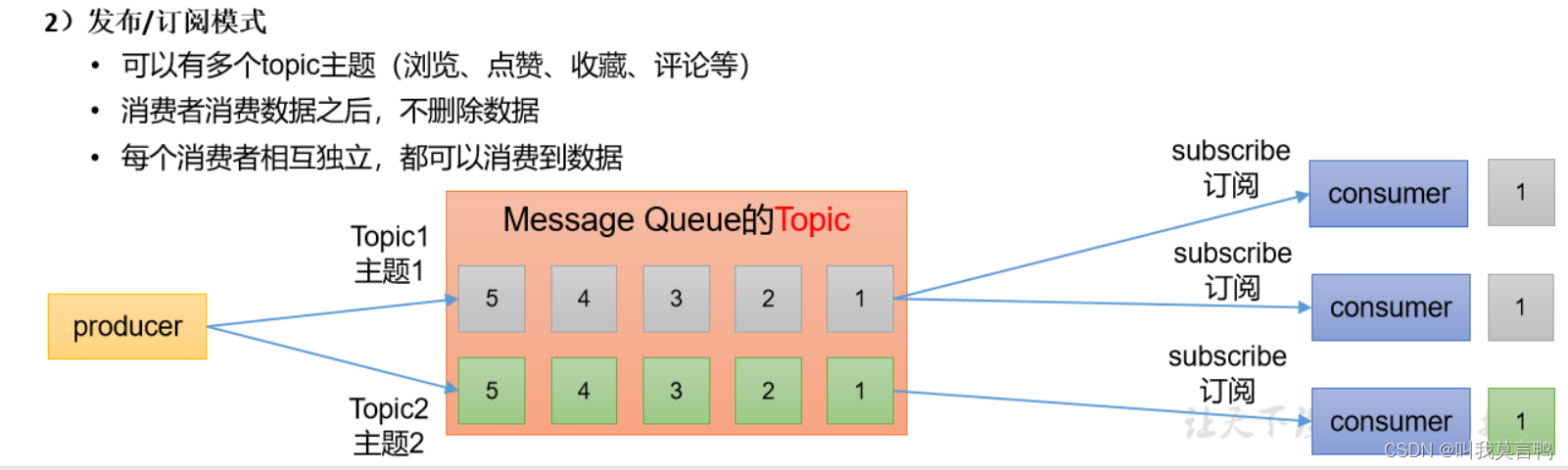
Kafka使用发布订阅模式
数据会保存一段时间
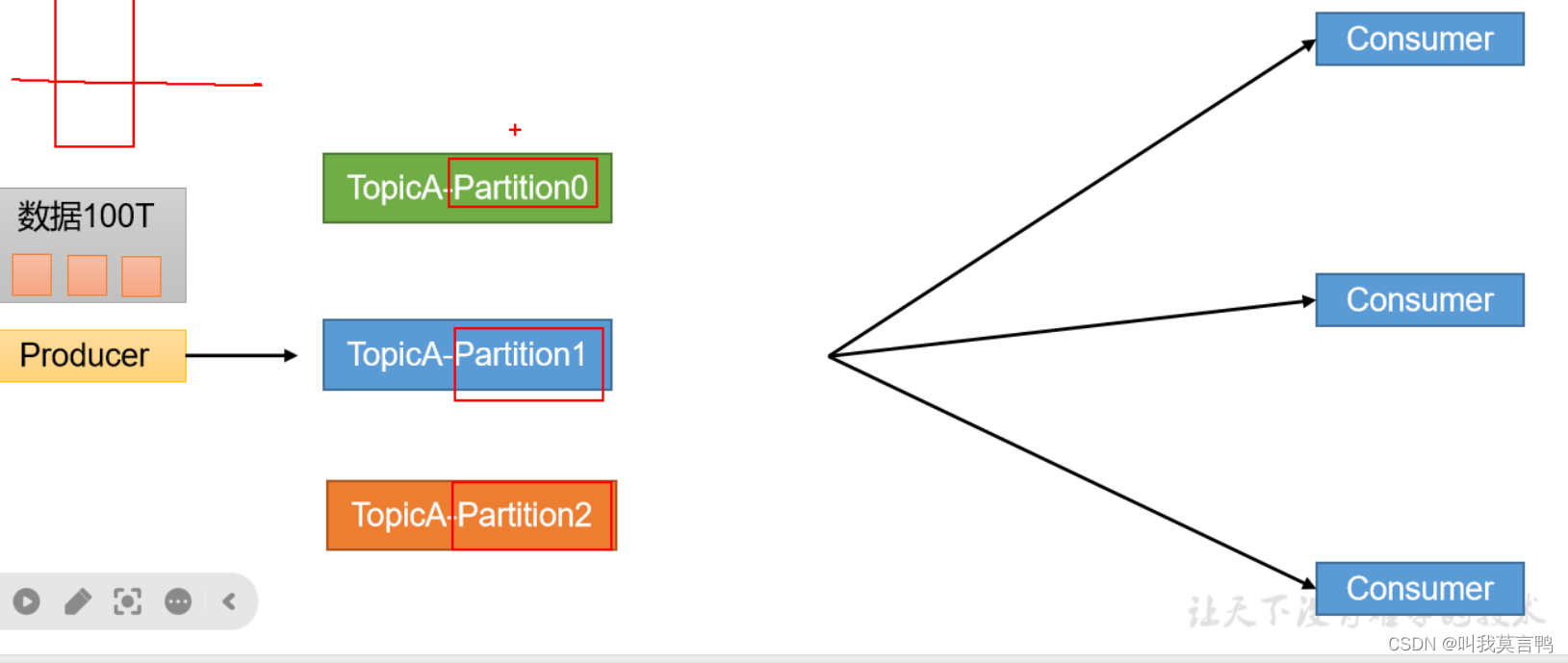
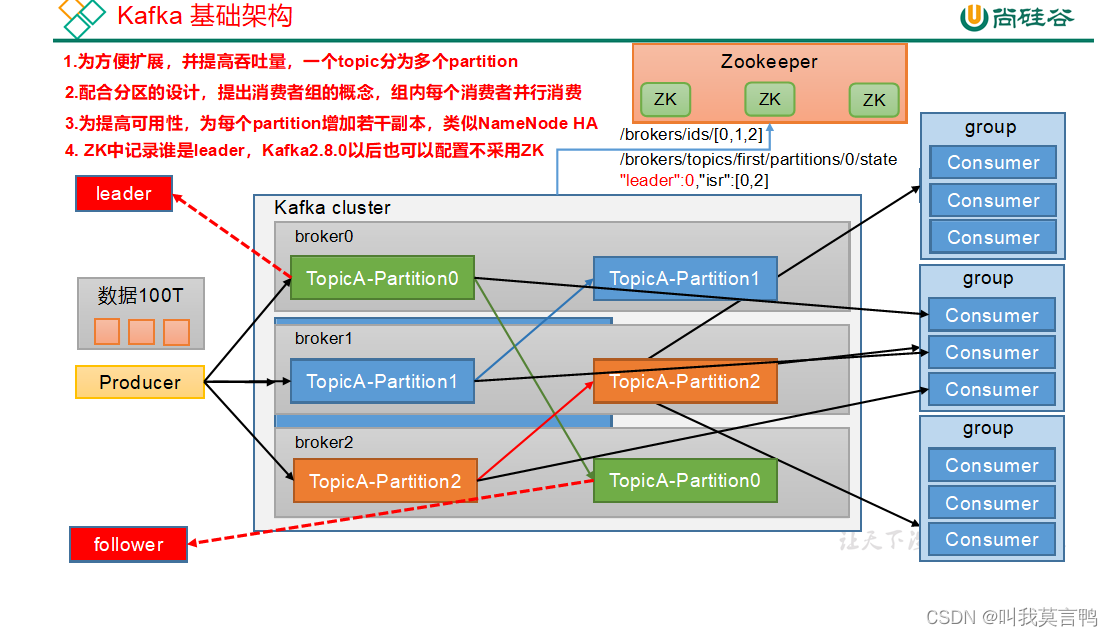
5.基础架构
生产者 - Broker - Group
TopicA是什么?
这里的分区是什么?
分区: 物理分割
为什么要分割:结合集群分散存储
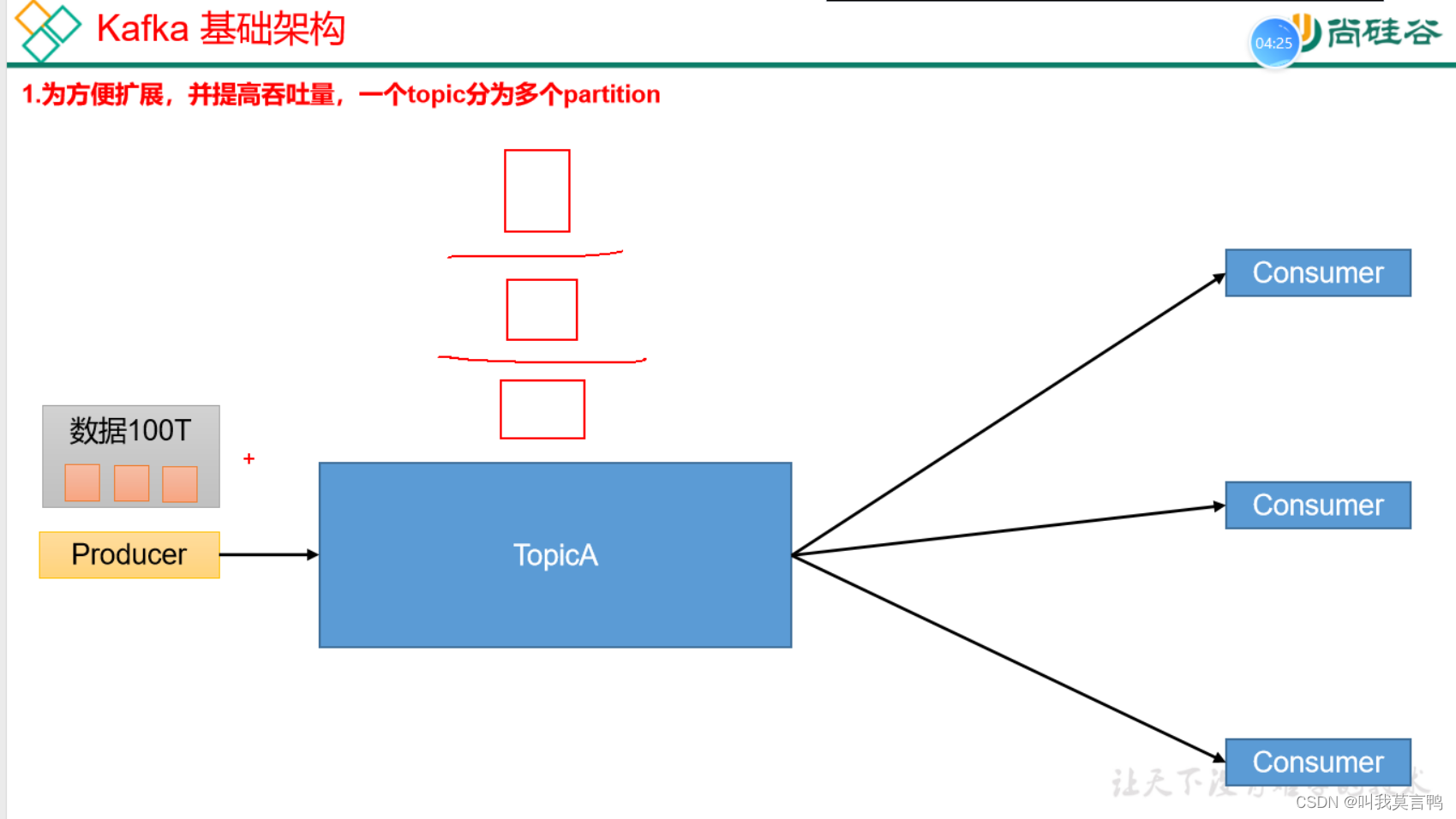
1. 分区操作
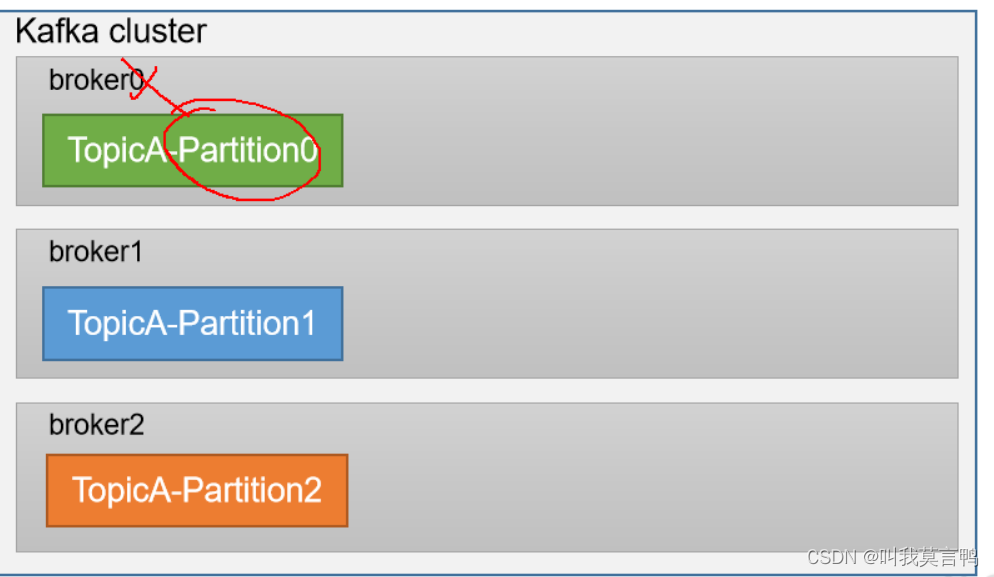
topic 是一整个数据 ,分区是为了将数据分在不同的Broker上。类似于HDFS,
Broker是物理存储
Partition 类似于DN
2.消费者组的概念
类似权限管理把,组内并行消费,便于管理
- Producer生产者: 向Kafka broker发消息的客户端(自主)
- Consumer消费者: 从Kafka取消息的客户端(自主)
- Group 组: 消费者组。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
这个说明,分区不支持并行读取,一个分区只能同时一个组内消费者消费。
组内消费者对不同分区进行读取,是为了优化读取速率. - Broker 一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本中的“从”,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。
- Replica:副本。一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
3.副本
备份功能,备份partition 多个副本, 类似HDFS,类似DN(存入一下子3个)把
多副本时,一个副本叫leader 另一个副本叫follower,
也是选出来的角色 交互时只和leader交互
follower平时只有备份作用,但是当leader倒下时,他直接成为leader

这里是存储数据的目录,而不是存Kafka自己日志的目录
高可用, 配置多个

replicas 是存储副本的位置
lsr 是目前存活的副本
分区数只能改大,不能改小
副本数修改,
通过JSON手动修改
消费者按最新的offect进行消费
5.配置
1.解压
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/module/
[atguigu@hadoop102 module]$ mv kafka_2.12-3.3.1/ kafka
2.配置文件
配置文件目前只需要修改三个
broker编号 不同机器只需要编号不同即可
log.dir 数据存放位置
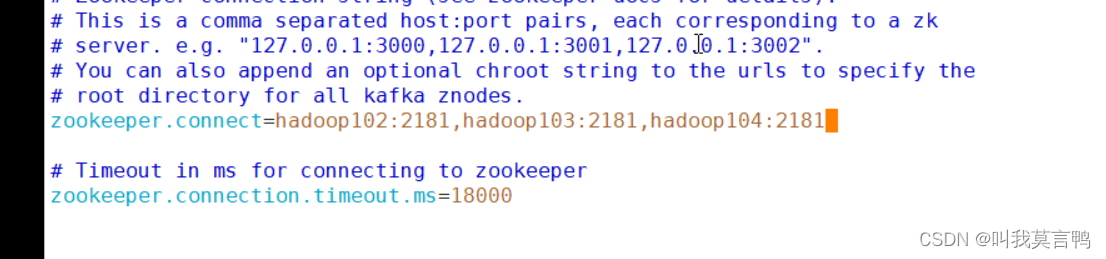
zookeeper.connect 连接集群的地址
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vim server.properties
# 修改1 broker的全局唯一编号,不能重复,只能是数字。
broker.id=0#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#修改2 这里其实是是存放到Kafka的数据的地方 kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#修改3 连接集群的位置 配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
3. 环境变量
sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
这个是为了启动的时候不需要输入一长串地址
比如:bin/kafka-server-start.sh -daemon config/server.properties
这里的config是kafka的路径 启动需要输入全路径
bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
修改后
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
4.集群脚本
#! /bin/bash
if [ $# -lt 1 ]
then echo "参数错误,请输入start或者stop"exit
fi
case $1 in
"start"){for i in hadoop102 hadoop103 hadoop104 do echo "---------------启动 $i Kafka ----------------------"ssh $i "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"done
};;
"stop"){for i in hadoop102 hadoop103 hadoop104do echo "---------------停止 $i Kafka ---------------------"ssh $i "$KAFKA_HOME/bin/kafka-server-stop.sh -daemon $KAFKA_HOME/config/server.properties"done
};;
esac
2.命令
1.主题命令
1. --bootstrap-server <String: server toconnect to>
连接Broker 操作Kafka必须有这个命令
既可以输入一个,也可以输入多个
kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092
2.主题的创建和删除
– create +空格 ±-topic+空格+主题名
– delete +空格 ±-topic+空格+主题名
主题 主题名 一般放最后
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first

–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数

3.查看所有主题
–list
4.查看主题详细描述
可以看单个主题,可以看全部主题
不加后缀默认查看全部
查看单个需要+空格 ±-topic+空格+主题名


5.修改–alter
设置分区数
–partitions <Integer: # of partitions>

分区只能调大,不能调小
设置分区副本
–replication-factor<Integer: replication factor>
// 手动调整kafka topic分区的副本数 {// 1. 版本号 这个是自定义的版本号"version":1,// 2. 分区是重点,因为副本改变分区也要改变。// 其实就是将分区的副本重新进行布局"partitions":[{"topic":"first","partition":0,"replicas":[1,2,0]},{"topic":"first","partition":1,"replicas":[2,0,1]},{"topic":"first","partition":2,"replicas":[2,0,1]}]
}
// 运行命令
//kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file ./rep.json --execute

更新系统默认的配置。
–config <String: name=value>
临时调配参数
2.生产者命令
1.操作
--topic <String: topic>
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first

3.消费者
kafka-console-consumer.sh --bootstrap-server +集群+ 主题
- –bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
- –topic <String: topic> 操作的topic名称。
- –from-beginning 从头开始消费。
- –group <String: consumer group id> 指定消费者组名称。
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
为什么消费者未开启时,生产者发送的消息,等消费者起来了收不到?
没有指定消费者组时,每次开启,消费者属于的消费者组就是随机的,那么就无法进行断点续传
当主动指定组后,再次登录,在指定组后,会自动开启断点续传功能
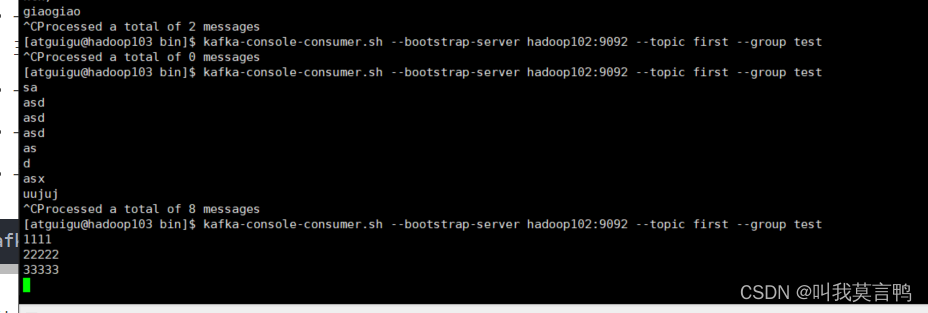
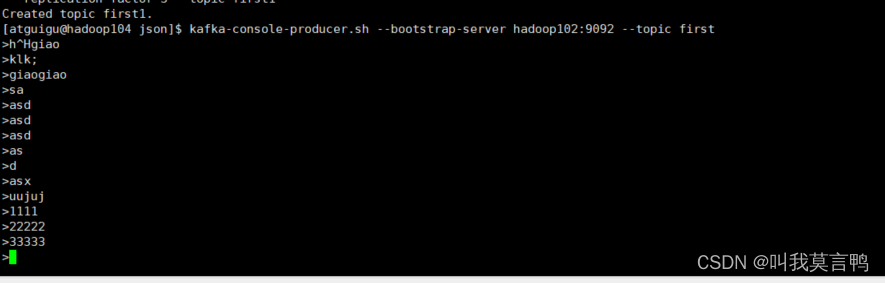
想要提前的顺序,就需要,–from-beginning
但是不能和用户组一起跑
相关文章:
Kafka第一课概述与安装
生产经验 面试重点 Broker面试重点 代码,开发重点 67 章了解 如何记录行为数据 1. Kafka概述 1.产生原因 前端 传到日志 日志传到Flume 传到HADOOP 但是如果数据特比大,HADOOP就承受不住了 2.Kafka解决问题 控流消峰 Flume传给Kafka 存到Kafka Hadoop 从Kafka…...

Linux MQTT智能家居项目(智能家居界面布局)
文章目录 前言一、创建工程项目二、界面布局准备工作三、正式界面布局总结 前言 一、创建工程项目 1.选择工程名称和项目保存路径 2.选择QWidget 3.添加保存图片的资源文件: 在工程目录下添加Icon文件夹保存图片: 将文件放入目录中: …...
【Vue3】Vue3 UI 框架 | Element Plus —— 创建并优化表单
安装 # NPM $ npm install element-plus --save // 或者(下载慢切换国内镜像) $ npm install element-plus -S// 可以选择性安装 less npm install less less-loader -D // 可以选择性配置 自动联想src目录Element Plus 的引入和注入 main.ts import…...
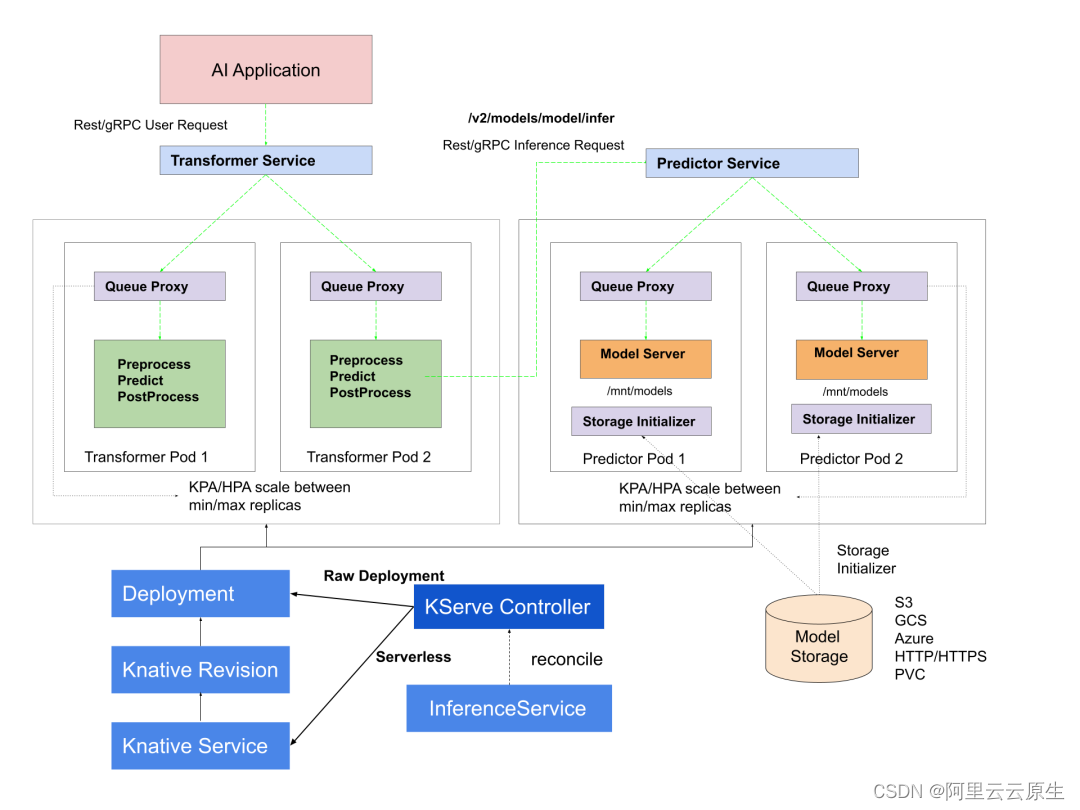
如何基于 ACK Serverless 快速部署 AI 推理服务
作者:元毅 随着 AI 浪潮的到来,各种 AI 应用层出不穷,众所周知 AI 应用对 GPU 资源强烈依赖,但 GPU 很昂贵,如何降低 GPU 资源使用成本成为用户首要问题。而 AI 与 Serverless 技术结合,完全可以达到按需使…...
【奥义】如何用ChatGPT写论文搞模型
目录 你是否曾经在复现科研论文的结果时感到困难重重? 引言 1 打开需要复现的目标文献 2 提取公式定义的语句 3 文章公式、图实现 (1)用python复现目标文献中的公式 (2)用python复现目标文献中的图 4 Copy代码…...
欢迎光临,博客网站
欢迎光临:YUNYE博客~https://yunyeblog.com/更多的文章,供大家参考学习!!!...
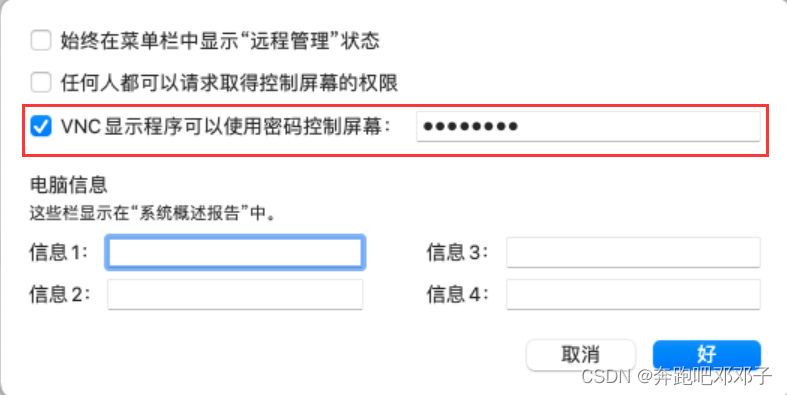
通过TightVNC远程访问MacOS
目录 一、下载 TightVNC 下载链接:https://www.tightvnc.com/ 下载后按步骤进行安装,安装完成后安装目录如下: 运行 tvnviewer.exe,输入远程 IP,点击【connect】: 输入密码,点击【OK】后即可远…...

智安网络|网络安全:危机下的创新与合作
随着信息技术的迅猛发展和互联网的普及,我们进入了一个高度网络化的社会。网络在提供便利和连接的同时,也带来了许多安全隐患和挑战。 一、网络安全的危险 **1.数据泄露和隐私侵犯:**网络上的个人和机构数据存在遭受泄露和盗取的风险&#…...
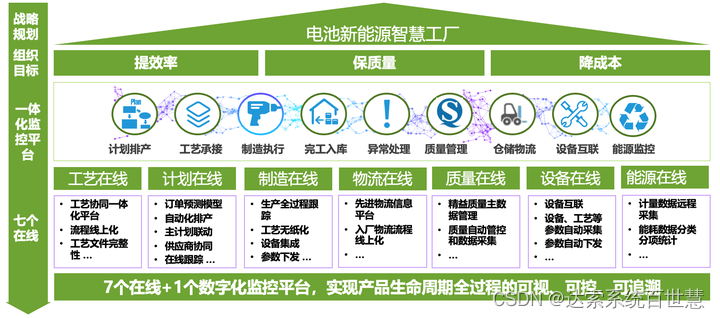
从系统角度,看智能制造|百世慧®
7月31日我们结束了智能制造专题第二期“电池智能制造质量管理应用及案例分享”的线上研讨会,有不少朋友没有来得及参加智能制造专题第一期研讨会,同时又工作繁忙。所以!今天就由我百小能为大家快速讲解第一期研讨会——“电池智能制造应用”的…...
Dubbo 与 gRPC、Spring Cloud、Istio 的关系
很多开发者经常会问到 Apache Dubbo 与 Spring Cloud、gRPC 以及一些 Service Mesh 项目如 Istio 的关系,要解释清楚它们的关系并不困难,你只需要跟随这篇文章和 Dubbo 文档做一些更深入的了解,但总的来说,它们之间有些能力是重合…...

【uniapp 中使用uni-popup阻止左滑退出程序】
在uniapp中,可以使用uni-app插件uni-popup提供的阻止左滑退出程序的功能。具体步骤如下: 安装uni-popup插件:在HBuilderX编辑器中,打开manifest.json文件,找到“dependencies”字段,在其后添加:…...
netty学习分享(一)
TCP与UDP TCP 是面向连接的、可靠的流协议,通过三次握手建立连接,通讯完成时要拆除连接。 UDP是面向无连接的通讯协议,UDP通讯时不需要接收方确认,属于不可靠的传输,可能会出现丢包现象 端口号: 端口号用…...
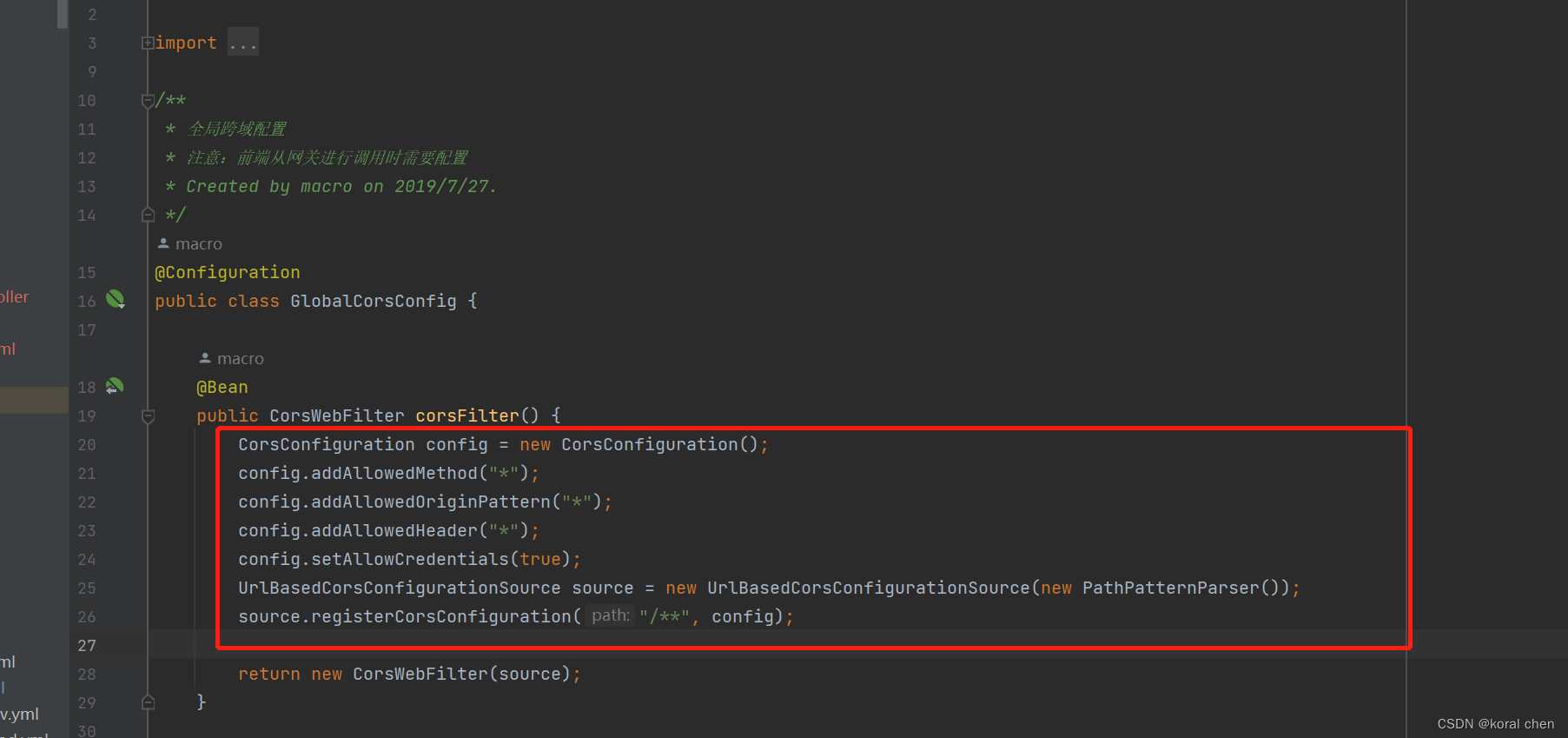
前端跨域问题解决方法
跨域是WEB浏览器专有的同源限制访问策略。(后台接口调用和postman等工具会出现) 跨源资源共享(CORS,或通俗地译为跨域资源共享)是一种基于 HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其他源(域、协议或端…...
)
html基础面试题 html的元素居中的常用方法(基础知识温习)
html基础面试题 & html的元素居中的常用方法日常温习 1,使用text-align: center;属性: 对于内联元素(如文本或图片),可以将其父元素的text-align属性设置为center。 <div style"text-align: center;&quo…...

VScode如何设置中文教程
前言:打开VSCode软件,可以看到刚刚安装的VSCode软件默认使用的是英文语言环境,但网上都是vscode中文界面教你怎么设置中文,可能不利于小白阅读,所以重装vscode,手摸手从英文变成中文。 设置为中文 打开VS…...
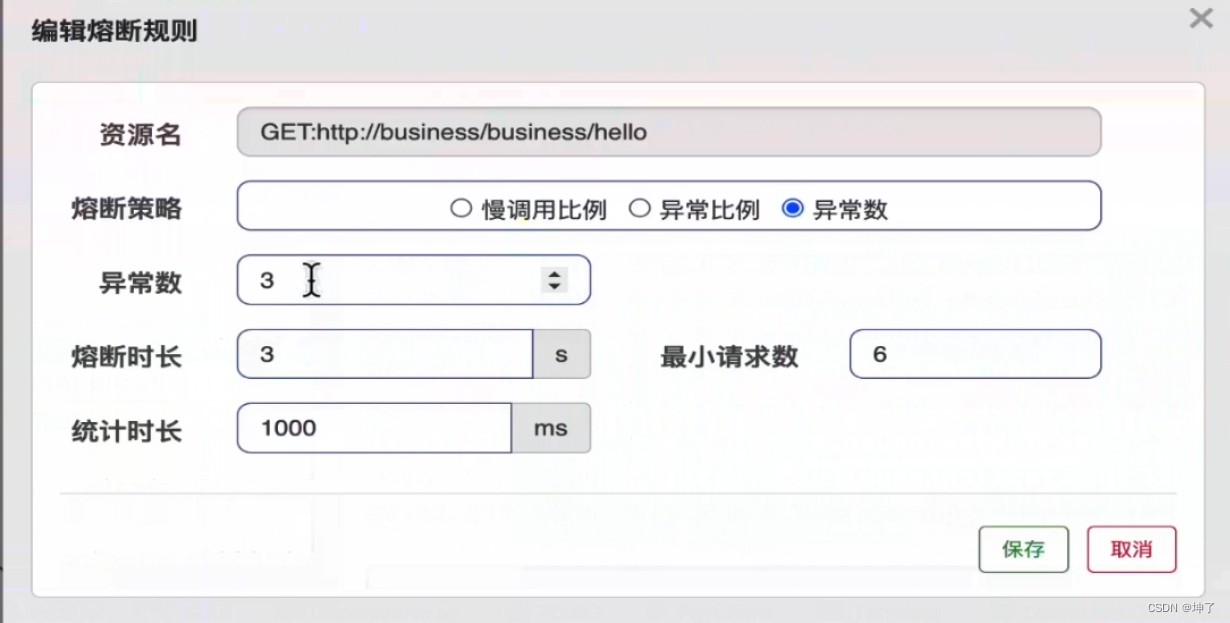
SpringCloud中 Sentinel 限流的使用
引入依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>手动编写限流规则,缺点是不够灵活,如果需要改变限流规则需要修改源码…...
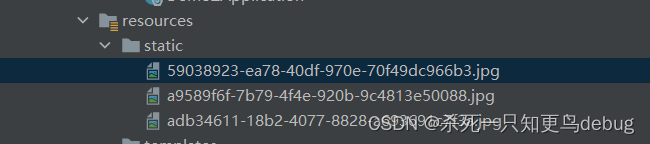
springboot文件上传和下载接口的简单思路
springboot文件上传和下载的简单思路 文件上传文件下载 文件上传 在springboot中,上传文件只需要在接口中通过 MultipartFile 对象来获取前端传递的数据,然后将数据存储,并且返回一个对外访问路径即可。一般对于上传文件的文件名,…...
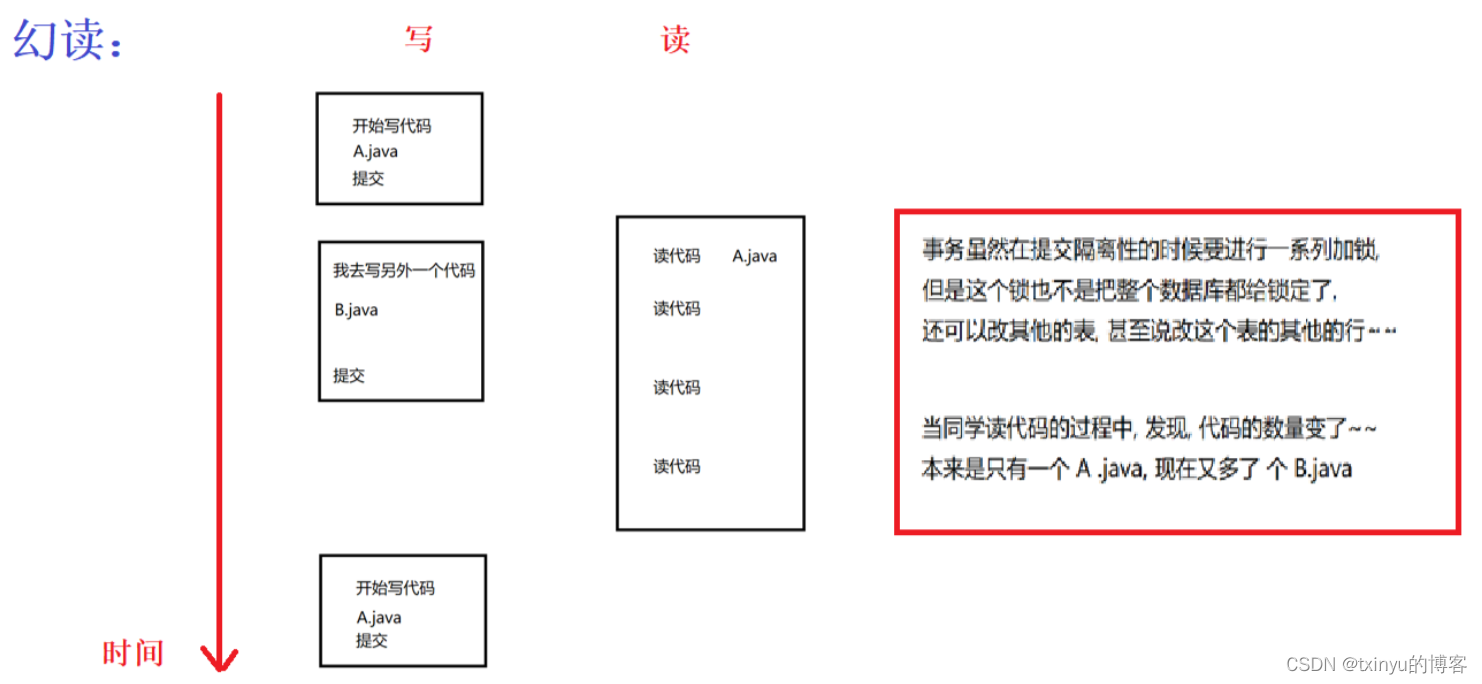
MySQL索引和事务
目录 索引的作用 与 概念 MySQL有哪几种索引类型 如何提高查找效率 聚簇索引与非聚簇索引 覆盖索引 索引的优点和缺点 索引的一些基本操作 索引优化 B树、B树、Hash、红黑树的区别 B树与B树的区别 MySQL为什么使用B树作为索引 联合索引中的顺序 MySQL的最左前缀原…...

typeScript 之 基础
工具: PlayGround 源码: GitHub TypeScript 变量声明 typeScript中变量声明注意: 开头不能以数字开头变量名称可以包含数字和字母除了下划线_和美元$符号外,不能包含其他任意特殊字符 声明的结构: let 变量名: 类型…...
android app控制ros机器人五(百度地图)
半吊子改安卓,新增了标签页,此标签页需要显示百度地图 按照官方教程注册信息,得到访问应用AK,步骤也可以参照下面csdn Android地图SDK | 百度地图API SDK 【Android】实现百度地图显示_宾有为的博客-CSDN博客 本人使用的是aar开…...

Postman并发测试入门:从手动点击到真并行压测
1. 为什么“并发测试”不是点几下Postman就能搞定的事?很多人第一次听说“用Postman做并发测试”,第一反应是:不就是把接口地址填进去,点一下Send,再点几次Send,就算并发了?我刚入行那会儿也这么…...
:金融、电商、教育三大垂直领域实测数据首度公开)
企业级AI写作Agent部署全链路(从POC到规模化上线):金融、电商、教育三大垂直领域实测数据首度公开
更多请点击: https://kaifayun.com 第一章:企业级AI写作Agent部署全链路(从POC到规模化上线):金融、电商、教育三大垂直领域实测数据首度公开 企业级AI写作Agent的落地并非模型调用的简单叠加,而是涵盖需求…...

播客主必看的AI语音合成合规红线,版权/声纹/数据跨境三重雷区全解析,错过即违规
更多请点击: https://codechina.net 第一章:AI语音合成在播客制作中的应用 AI语音合成技术正深刻重塑播客内容的生产范式。借助高质量、低延迟、多风格可调的TTS(Text-to-Speech)引擎,创作者无需专业录音棚、配音演员…...

别再被GPG签名卡住了!手把手教你修复Kali老版本apt更新源报错
Kali Linux系统更新源管理进阶指南:从故障修复到高效运维当你成功解决了Kali Linux老版本因GPG签名失效导致的apt更新源报错后,这只是系统维护的第一步。真正的挑战在于如何构建一套可持续的运维策略,避免类似问题反复出现,同时提…...

AArch64架构下非缓存内存的指令缓存机制解析
1. AArch64架构下非缓存正常内存的指令缓存机制解析在Armv8-A和Armv9-A架构的AArch64执行状态下,关于指令缓存(Instruction Cache)如何处理非缓存(Non-cacheable)内存区域的指令访问,存在一个值得深入探讨的技术细节。这个问题直接关系到处理器对内存访问…...

AI翻译准确率99.9%,专业翻译岗位反而增加了——这说明了什么
有一组数据很有意思:AI翻译的准确率已经能到99.9%,速度快,成本低,理论上完全具备替代人工翻译的能力。但实际情况是,专业翻译岗位的需求这几年不降反升。这背后的逻辑,对理解芯片工程师的核心价值也很有启发…...

遥感因果分析:多尺度表征拼接技术解析与工程实践
1. 项目概述:从“看”到“理解”的遥感因果分析新思路在遥感图像分析领域,我们早已不满足于仅仅“看到”地物。从土地利用分类到灾害评估,核心目标正从“是什么”转向“为什么”和“会怎样”。比如,我们不仅想知道某片区域是农田&…...

AI驱动的高能物理探测器协同优化设计与实践
1. 高能物理探测器设计的范式转变在大型强子对撞机(LHC)时代,探测器设计面临前所未有的挑战。以CMS实验为例,其硅像素跟踪器的材料预算曾引发激烈讨论——虽然40-60%的光子转换概率有助于希格斯玻色子双光子衰变通道的识别&#x…...

1000个文件重命名,1秒完成!批量文件重命名软件
前言: 大家好,这里是惠众资料库, 在日常办公、资料归档、素材整理、摄影剪辑等各类场景中,用户会积累大量图片、文档、视频、音频、文件夹等各类文件。为了实现文件分类规整、统一命名规范、方便快速检索调用,文件重命…...

大脑规则:为什么你学不进去?10个科学方法提升学习效率
大脑规则:为什么你学不进去?10个科学方法提升学习效率 副标题: 从进化论到认知科学,附实战学习方案 一、痛点:为什么你总是学不进去? 你有没有这样的经历: 坐在书桌前,书翻开了,但脑子一片空白 熬夜学习,第二天效率更低,形成恶性循环 一边看视频一边回消息,结果什…...