OCR项目实战(一):手写汉语拼音识别(Pytorch版)
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
📝OCR专栏导读: 本系列主要介绍计算机视觉领域OCR文字识别领域技术发展方向,每章将分别从OCR技术发展、概念、算法、论文、数据集、现有平台及未来发展方向等各种角度展开详细介绍,综合基础与实战知识。以下是本系列目录,内容目前包括不限于文字检测、识别、表格分析等方向,未来会结合更新NLP方向知识,主要面向深度学习及CV的同学学习,如有错误请大家在评论区指正,如有侵权联系删除。 [ 欢迎专栏下方入群交流,群内将分享更多大数据与人工智能方向知识。]
📝OCR入门教程系列目录:
1️⃣OCR系列第一章 【OCR技术导论】:OCR文字识别技术总结(一) [试读]
2️⃣OCR系列第二章 【OCR基础介绍】:OCR文字识别技术总结(二)
3️⃣OCR系列第三章 【文字检测技术】:OCR文字识别技术总结(三)
4️⃣OCR系列第四章 【文字识别技术】:OCR文字识别技术总结(四)
5️⃣OCR系列第五章 【实战代码解析】:OCR文字识别技术总结(五)
6️⃣OCR系列文章【OCR数据集与评价指标详解】(待更新)
7️⃣OCR系列文章【OCR后处理:文本纠错】(待更新)
8️⃣OCR系列文章 【OCR后处理:版面分析】(待更新)
9️⃣OCR系列文章 【表格识别】(待更新)
🔟OCR系列文章 【关键信息抽取】(待更新)
🆙OCR系列文章 【OCR资料总结】(待更新)
注:以上系列将继续更新及完善,非最终版本!后续更新内容包括不限于文字检测、文件识别、表格识别、版面分析、纠错及结构化、部署及实战等方面内容,欢迎大家订阅该专栏!
📝OCR领域经典论文汇总:
1️⃣OCR文字识别经典论文详解 [试读]
2️⃣OCR文字识别方法综述
3️⃣场景识别文字识别综述(待更新)
4️⃣文字检测方法综述(待更新)
📝OCR领域论文详解系列:
1️⃣CRNN:CRNN文字识别 [试读]
2️⃣ASTER:ASTER文本识别详解
🆙目前在整理阶段,后续会更新其他文字检测与识别方向论文解读。
📝OCR项目实战系列:
1️⃣Pyotch、TensoFlow
2️⃣PaddleOCR
- 基于CRNN的文本字符交易验证码识别
- 车牌检测与识别
- 体检报告识别
- 中文场景文字识别
- 手写汉语拼音识别(已更新)
- 手写英文识别(待更新)
- 票据识别(待更新)
- 公式识别(待更新)
- 表格识别(待更新)
…
注:更多实战项目敬请期待,详细介绍可以参考本系列其他文章,每个系列对应部分会陆续更新,欢迎大家交流订阅!!
OCR项目实战(一):手写汉语拼音识别
引言:汉语拼音识别存在人工识别慢,效率低下而且容易识别出错在批阅小学生试卷时带来很大困难。此外汉语拼音是中国小学生启蒙教育的重要一环,因此手写汉语拼音的识别具有很高的研究价值。人工识别手写汉语拼音已经难以满足社会需求,所以需要加快手写汉语拼音识别的数字化和信息化,通过科技手段来推动手写汉语拼音识别工作。
一、项目介绍:
本项目基于深度学习的手写汉语拼音识别方法研究与实现。项目采用Pytorch框架,整体采用主流深度学习文字识别算法CRNN+CTC方法,项目流程主要分为数据集采集及标注,算法构建、模型训练、预测与评估等。
后续会补充PaddleOCR版本的手写汉语拼音识别,将引入更多模型测试,并结合数据增强手段提升模型泛化性。
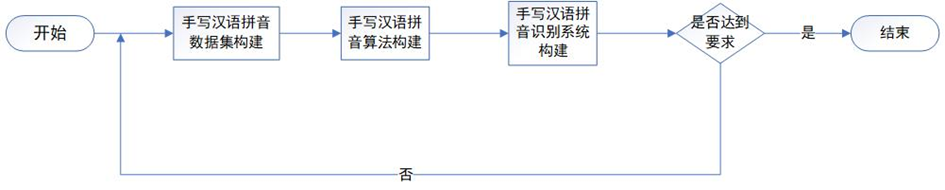
1.项目链接:
https://github.com/GoAlers/Pinyin_recognize 正在整理,后续会补充!
2.项目大致流程:
1.首先将制作好的图片放入data目录下,图片名按具体写的拼音命名,格式jpg。
2.执行pic_to_txt.py文件,生成all_pic.txt,内容需要包含图片路径名+拼音,空格分割。
3.运行split.py数据集脚本将图片总数量按9:1比例 (将all_pic.txt分别生成train.txt 和test.txt)
4.将txt格式转为lmdb格式数据集执行create_lmdb,得到train和testd lmdb文件夹,将两个路径替换main.py里的训练及测试路径。
5.运行train.py训练,跑一定时间将模型保存运行demo进行测试。
二、数据集构建:
本项目采用手写汉语拼音数据集,通过随机生成500个不同的汉语拼音,并将汉语拼音分配给尽量多的人在A4纸上进行书写,以此来保证手写汉语拼音的字迹的多样化。对500个手写汉语拼音进行图像采集,使用人工对拼音进行对应标注。数据集也可以通过Python脚本生成,考虑到脚本自动生成如果没有经过一定规则过滤,可能存在语法错误,因此,本文最终采取人工拍照的方式进行数据集构建,由于时间限制,本项目仅制作500张手写拼音图片,后续可以增加更多数据集增加模型泛化能力。
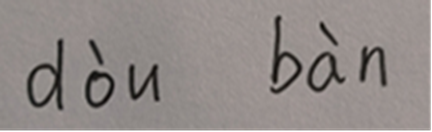
三、数据集标注:
首先将收集的手写汉语拼音图片进行重命名,进行标签式标注,完成数据集的初步构建,用于进行后续的模型测练。对数据集按9:1比例进行划分。共制作500张手写拼音图片,随机选取 50个图片作为测试集,以此来测试所构建的算法对手写汉语拼音识别的准确率。另外450个图片则作为训练集,为算法构建后的神经网络进行训练,最终数据集预览如图所示。

数据集格式:
路径 标注信息 (注:以 ‘\t’ 分割,路径按自己实际情况写)
D:\Python\PycharmProjects\CRNN\ATT_PY\data\bàocháng.png bàocháng
D:\Python\PycharmProjects\CRNN\ATT_PY\data\diànnǎo.png diànnǎo
D:\Python\PycharmProjects\CRNN\ATT_PY\data\guòyǐn.png guòyǐn
D:\Python\PycharmProjects\CRNN\ATT_PY\data\húshōuzhàn.png húshōuzhàn
D:\Python\PycharmProjects\CRNN\ATT_PY\data\kǒngpà.png kǒngpà
D:\Python\PycharmProjects\CRNN\ATT_PY\data\péiyǎng.png péiyǎng
D:\Python\PycharmProjects\CRNN\ATT_PY\data\qǔdāo.png qǔdāo
D:\Python\PycharmProjects\CRNN\ATT_PY\data\tiānnèi.png tiānnèi
四、技术介绍
本项目构建手写汉语拼音识别算法:本文手写汉语拼音识别算法采用序列到序列的识别方法CRNN+Attenton,CRNN主要用来对端到端的不定长文本序列加以识别,采用的汉语拼音识别算法分为编码网络和解码网络两个部分。首先,编码网络的主体框架采用卷积神经网络,骨干网络使用Resnet,语言模型使用BiLSTM。其次,解码网络的核心部分由LSTM结合注意力机制实现,其过程根据LSTM每个时刻输入项进行注意力分值计算并加权求和。最后,将上述得分通过Softmax进行多分类处理,得到最终汉语拼音分类结果。通过仿真实验,调整网络结构以及配置参数,最终手写汉语拼音识别精度可以达到92%以上。
五、算法介绍及构建
1.1CRNN算法
CRNN具体介绍可以参考我的这篇:链接
官方论文:An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
参考代码:https://github.com/meijieru/crnn.pytorch
CRNN的全名为Convolutional Recurrent Neural Network,主要是被设计用来对端到端的长宽度不确定的长文本序列加以识别。它就可以实现不用先去对其他任何一类单个的图像文字序列识别进行切割,而是借助将单个的图形文字序列的辨识学习步骤依次转变为一类由时间序列的依赖图形文本序列的辨识的学习过程的问题,进行更高效地基适应于用单一的图像文字序列实现的所有图像文本序列的标识。
CRNN借鉴采用了语音识别建模理论框架中最为常用的一种LSTM+CTC网络的声音建模分析技术方法,输入接收到的从LSTM所提取得到的声音特征,不再意味着完全可以是当前语音领域所常用到的各种声学特征,而是一种由CNN网络中所无法提取到声音的图像特征。CRNN网络实现结合CNN和RNN网络结构,其结构如图3.5所示:
1.1.1.CRNN+CTC
算法网络结构

网络结构包含三部分,从下到上依次为:
(1)卷积层。作用是从输入图像中提取特征序列。
(2)循环层。作用是预测从卷积层获取的特征序列的标签(真实值)分布。
(3)转录层。作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
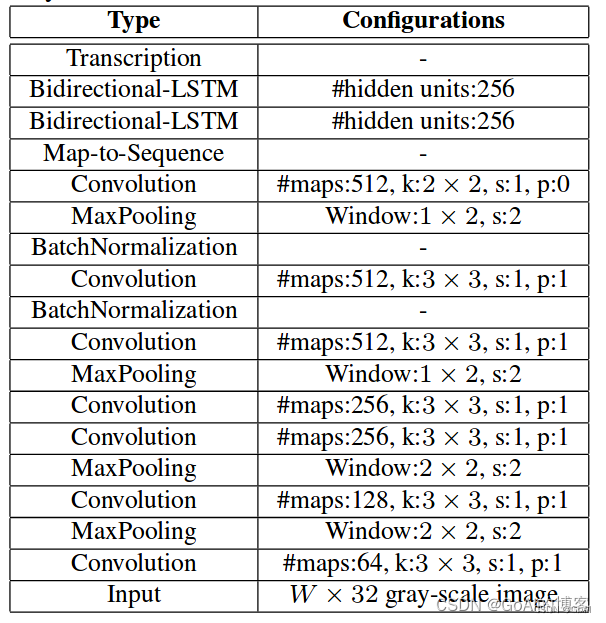
网络配置信息(VGG)
六、代码实战
train.py
# encoding: utf-8from __future__ import print_function
from __future__ import division
import argparse
import random
import torch
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
import numpy as np
#from warpctc_pytorch import CTCLoss
import os
import utils as utils1
import dataset
import hypy_alphabet
import models.crnn as crnnparser = argparse.ArgumentParser()parser.add_argument('--trainRoot', default = r'../ATT_PY/train502', help='path to dataset')
parser.add_argument('--valRoot', default = r'../ATT_PY/test502', help='path to dataset')
parser.add_argument('--workers', type=int, help='number of demo_data loading workers', default=0)
parser.add_argument('--batchSize', type=int, default=4, help='input batch size')
parser.add_argument('--imgH', type=int, default=32, help='the height of the input image to network')
parser.add_argument('--imgW', type=int, default=300, help='the width of the input image to network')
parser.add_argument('--nh', type=int, default=256, help='size of the lstm hidden state')
parser.add_argument('--nepoch', type=int, default=200, help='number of epochs to sxmv for') #迭代次数
# TODO(meijieru): epoch -> iter
parser.add_argument('--cuda',default=True, action='store_true', help='enables cuda') #有GPU时--cuda,另加了default=True
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
# parser.add_argument('--pretrained', default='', help="path to pretrained model (to continue training)") #预训练模型,可以设置断
#parser.add_argument('--pretrained', default=r'./exprpy/netCRNN_188_73.pth', help="path to pretrained model (to continue training)")
# parser.add_argument('--alphabet', type=str, default='-1234abcdefghijklmnopqrstuvwxyz')
parser.add_argument('--alphabet', type=str, default='abcdefghijklmnopqrstuvwxyzāáǎàōóǒòēéěèīíǐìūúǔùǖǘǚǜ')
parser.add_argument('--expr_dir', default='exprpy', help='Where to store samples and models') #输出模型路径
parser.add_argument('--displayInterval', type=int, default=10, help='Interval to be displayed')
parser.add_argument('--n_test_disp', type=int, default=10, help='Number of samples to display when test')
parser.add_argument('--valInterval', type=int, default=119, help='Interval to be displayed') #一轮保留一次模型
parser.add_argument('--saveInterval', type=int, default=119, help='Interval to be displayed') #设置多少次迭代保存一次模型
parser.add_argument('--lr', type=float, default=0.0001, help='learning rate for Critic, not used by adadealta')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
# 以下为两个优化器 ,可以选 ,其中下一行设置default=True,等于默认执行文件时加 --adam
parser.add_argument('--adam', default=True, help='Whether to use adam (default is rmsprop)')
parser.add_argument('--adadelta', action='store_true', help='Whether to use adadelta (default is rmsprop)')
parser.add_argument('--keep_ratio', action='store_true', help='whether to keep ratio for image resize')
parser.add_argument('--manualSeed', type=int, default=1234, help='reproduce experiemnt')
parser.add_argument('--random_sample', action='store_true', default=True, help='whether to sample the dataset with random sampler')#以上参数可以通过opt.名字访问
opt = parser.parse_args()
#输出各参数内容
print(opt)
# opt.alphabet = hypy_alphabet.alphabet()
# print(opt.alphabet)
if not os.path.exists(opt.expr_dir):os.makedirs(opt.expr_dir)random.seed(opt.manualSeed)
np.random.seed(opt.manualSeed)
torch.manual_seed(opt.manualSeed)cudnn.benchmark = Trueif torch.cuda.is_available() and not opt.cuda:print("WARNING: You have a CUDA device, so you should probably run with --cuda")train_dataset = dataset.lmdbDataset(root=opt.trainRoot)
assert train_dataset#设置随机采样
if not opt.random_sample:sampler = dataset.randomSequentialSampler(train_dataset, opt.batchSize)
else:sampler = None#加载训练及测试集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=opt.batchSize,shuffle=True, sampler=sampler,num_workers=int(opt.workers),collate_fn=dataset.alignCollate(imgH=opt.imgH, imgW=opt.imgW, keep_ratio=opt.keep_ratio))
test_dataset = dataset.lmdbDataset(root=opt.valRoot, transform=dataset.resizeNormalize((opt.imgW, 32)))#分类含空格+Mathorcuo_final
nclass = len(opt.alphabet) + 1
nc = 1converter = utils1.strLabelConverter(opt.alphabet)
criterion = torch.nn.CTCLoss()# custom weights initialization called on crnn
def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:m.weight.data.normal_(0.0, 0.02)elif classname.find('BatchNorm') != -1:m.weight.data.normal_(1.0, 0.02)m.bias.data.fill_(0)crnn = crnn.CRNN(opt.imgH, nc, nclass, opt.nh)
crnn.apply(weights_init)
#加载预训练
if opt.pretrained != '':print('loading pretrained model from %s' % opt.pretrained)# crnn.load_state_dict(torch.load(opt.pretrained)) #预训练模型出现参数报错,将本行改为下列代码执行成功crnn.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(opt.pretrained).items()})
# print(crnn)image = torch.FloatTensor(opt.batchSize, 3, opt.imgH, opt.imgH)
text = torch.IntTensor(opt.batchSize * 5)
length = torch.IntTensor(opt.batchSize)
if opt.cuda:crnn.cuda()# 迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练crnn = torch.nn.DataParallel(crnn, device_ids=range(opt.ngpu))image = image.cuda()criterion = criterion.cuda()image = Variable(image)
# print(image)
text = Variable(text)
# print(text)
length = Variable(length)
# print(length)
# loss averager
loss_avg = utils1.averager()# 两种优化器参数设置setup optimizer
if opt.adam:optimizer = optim.Adam(crnn.parameters(), lr=opt.lr,betas=(opt.beta1, 0.999))
elif opt.adadelta:optimizer = optim.Adadelta(crnn.parameters())
else:optimizer = optim.RMSprop(crnn.parameters(), lr=opt.lr)def val(net, dataset, criterion, max_iter=100):print('Start val')for p in crnn.parameters():p.requires_grad = Falsenet.eval()data_loader = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=opt.batchSize, num_workers=int(opt.workers))val_iter = iter(data_loader)i = 0n_correct = 0loss_avg = utils1.averager()max_iter = min(max_iter, len(data_loader))for i in range(max_iter):data = val_iter.next()i += 1cpu_images, cpu_texts = databatch_size = cpu_images.size(0)utils1.loadData(image, cpu_images)t,l = converter.encode(cpu_texts)utils1.loadData(text, t)utils1.loadData(length, l)preds = crnn(image)preds_size = Variable(torch.IntTensor([preds.size(0)] * batch_size))cost = criterion(preds, text, preds_size, length) / batch_sizeloss_avg.add(cost)_, preds = preds.max(2)# print(preds.size())# preds = preds.squeeze(2)preds = preds.transpose(1, 0).contiguous().view(-1)sim_preds = converter.decode(preds.data, preds_size.data, raw=False)for pred, target in zip(sim_preds, cpu_texts):if pred == target.lower():n_correct += 1raw_preds = converter.decode(preds.data, preds_size.data, raw=True)[:opt.n_test_disp]for raw_pred, pred, gt in zip(raw_preds, sim_preds, cpu_texts):print('%-20s => %-20s, gt: %-20s' % (raw_pred, pred, gt))accuracy = n_correct / float(max_iter * opt.batchSize)print('Test loss: %f, accuray: %f' % (loss_avg.val(), accuracy))def trainBatch(net, criterion, optimizer):data = train_iter.next()cpu_images, cpu_texts = databatch_size = cpu_images.size(0)utils1.loadData(image, cpu_images)t, l = converter.encode(cpu_texts)utils1.loadData(text, t)utils1.loadData(length, l)preds = crnn(image)preds_size = Variable(torch.IntTensor([preds.size(0)] * batch_size))
# print(preds.shape)
# print(text.shape)
# print(text.demo_data, length.demo_data)cost = criterion(preds, text, preds_size, length) / batch_sizecrnn.zero_grad()cost.backward()optimizer.step()return costfor epoch in range(opt.nepoch):train_iter = iter(train_loader)i = 0while i < len(train_loader):for p in crnn.parameters():p.requires_grad = Truecrnn.train()cost = trainBatch(crnn, criterion, optimizer)loss_avg.add(cost)i += 1#设置保留模型频率,可以设置每次保留最优模型。if i % opt.displayInterval == 0:print('[%d/%d][%d/%d] Loss: %f' %(epoch, opt.nepoch, i, len(train_loader), loss_avg.val()))loss_avg.reset()if i % opt.valInterval == 0:val(crnn, test_dataset, criterion)# do checkpointingif i % opt.saveInterval == 0:torch.save(crnn.state_dict(), '{0}/netCRNN_{1}_{2}.pth'.format(opt.expr_dir, epoch, i))1.1.2.CRNN+Attenton
算法网络结构
官方论文:ASTER: An Attentional Scene Text Recognizer with Flexible Rectification
参考代码:https://github.com/ayumiymk/aster.pytorch
ASTER具体介绍可以参考我的这篇:链接
本手写汉语拼音算法模型参考ASTRE论文中的方法,使用的是一种序列到序列的识别CRNN+Attenton,此算法由编码网络和解码网络两个部分构成。
-
编码网络系统包括两个由两个单向的ResNet(残差神经网络)和另外两个由双向的LSTM(长短期记忆网络)而构成的。ResNet网络是通过不同的卷积核大小将用户输入到的手写或汉语拼音图像信息进行了多层次的特征化提取,进而获得特征图像,再借助全连接操作将特征图像转化为特征序列。特征序列借助双向LSTM网络转变获得一种固定的宽度的矩阵。
-
解码网络由单向LSTM网络、注意力机制和Softmax组成。单向的LSTM网络主要作用就是把特征序列转化为相应的拼音序列,将目标矩阵上的信息进行训练。注意力机制作为解码编码过程中的重要纽带,它能从编码器获取每一处隐藏信息,从而提供给解码器做进一步处理,使该模型更关注手写汉语拼音特征序列的重要信息。Softmax则是对提取到的特征进行多分类,最后将结果一一提取。
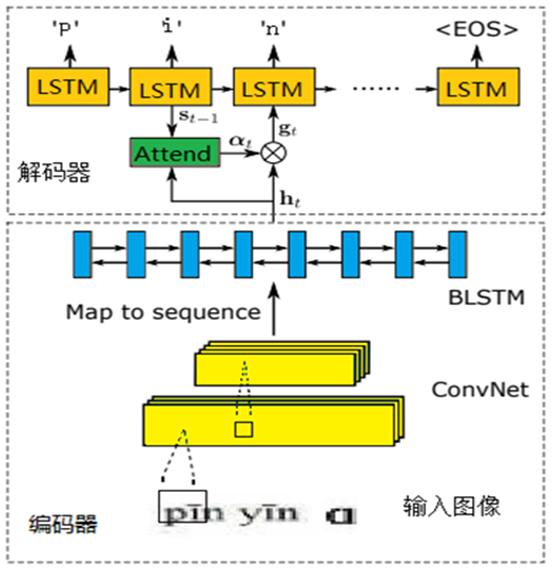
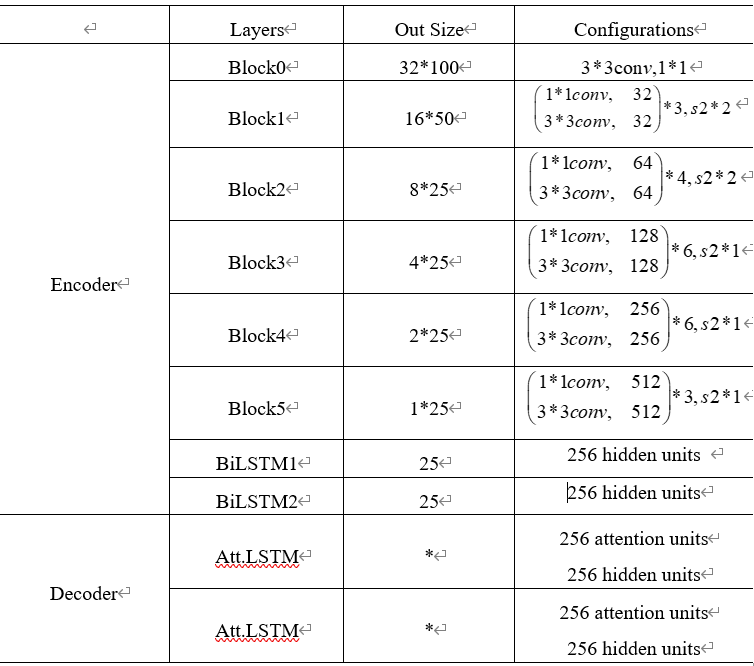
本方法的特征提取层先经过Resnet,结果采用多个Block堆叠组成,其卷积大小为1×1和3×3,经过双向的LSTM,隐藏层单元数量为256。最终得到形状为(B,W, C)的三维特征向量,其中B代表batch size,W是time steps,C是channels。比如说根据原文,当输入大小为(32,100)时,输出就是(B,25,512),详细网络配置如表所示:
七、仿真实验
本课题以CRNN+CTC算法为例,进行手写汉语拼音识别实验。
在实验中,通过调整迭代次数(epoch)、学习率(lr)及批处理大小(batchsize)进行训练,对比分析不同条件下手写汉语拼音识别的识别精度得到该模型下的最优识别效果。
训练前首先进行参数的设置,在代码中输入图片的长和宽,按照数据集标注时的设置的类别添加进代码中。每迭代完一次都保存一次模型。由于电脑配置较低,GPU参数设置为1,单GPU运行。通过遍历所有测试集中的图片进行测试,计算这些图片的识别精度。
第一次实验时将初始学习率设置为0.0001,批处理大小为4保持不变,分别测试迭代次数为50、100、150、200的识别精度结果。测试结果如表4.1所示。
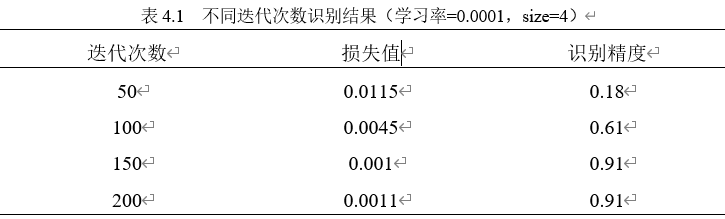
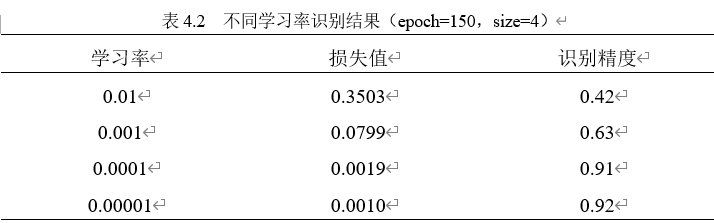
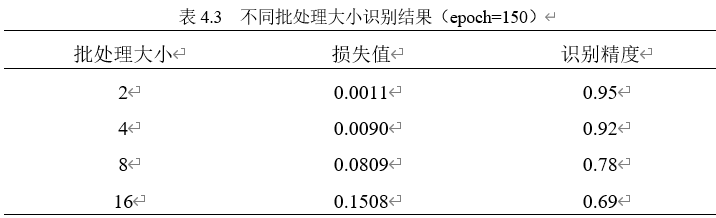
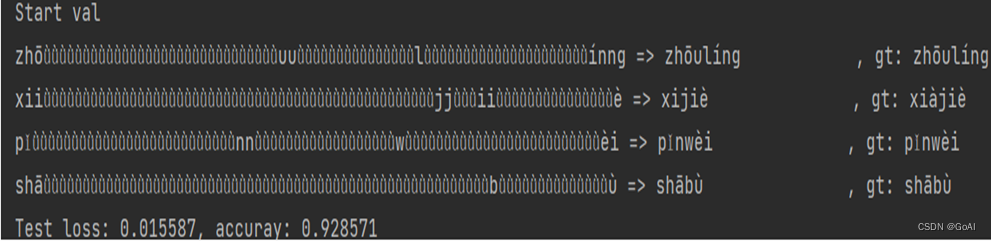
综上所述,设置模型迭代次数为150,学习率为0.0001,批处理大小为4为实验中最佳方案。多数手写汉语拼音识别效果良好,少数手写汉语拼音识别效果较差。当手写汉语拼音图片较为清晰和完整时,手写汉语拼音识别效果非常好构建的算法识别手写汉语拼音精确率最高,达到了91.2%。
仿真实验识别效果
识别成功拼音的原文件
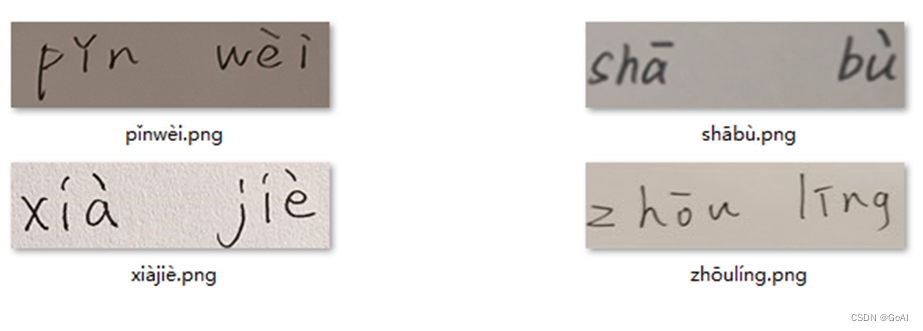
八、项目总结
本课题介绍了两种手写汉语拼音识别方法,以CRNN+CTC算法为例对手写汉语拼音识别进行研究与实现,全文介绍了手写汉语拼音识别的背景以及研究意义,深度学习的相关知识,对手写汉语拼音识别的算法构建以及仿真实验的过程及效果,最终模型在识别准确率方法效果较好。
九、不足及改进:
1.对于相对清晰的手写汉语拼音图片可以具有很好的识别效果,但是对于一些字迹连笔、字迹很淡的图片,测试效果就并不好,准确度较低,因此,算法还有需要改进的地方。
2.数据集的样本图片数量也相对较少,所以能达到的识别效果有限,如果数据集更加丰富的话,识别效果会更好。另外,在网络模型选择上,本文仅使用CRNN基本模型,vgg网络进行特征提取,后续可以更换ResNet、MoblineNetV3等其他网络进行实验。
3.而且在实验过程中,由于实验设备的配置较低,每次调整参数进行实验都会耗费大量的时间,一些调试中的问题解决起来会比较困难,所以并没有做更多的模型对比实验。
以上这些不足都还需要继续改进,才能更好的应用于手写汉语拼音识别的实现。
后续会补充PaddleOCR版本的手写汉语拼音识别,将引入更多模型测试,并结合数据增强提升模型泛化性。
相关文章:
OCR项目实战(一):手写汉语拼音识别(Pytorch版)
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。 📝OCR专栏…...

【js】export default也在影响项目性能呢
这里写目录标题介绍先说结论分析解决介绍 无意间看到一个关于export与exprot default对比的话题, 于是对二者关于性能方面,有了想法,二者的区别,仅仅是在于写法吗? 于是,有了下面的测试。 先说结论 太长…...

《软件安全》 彭国军 阅读总结
对于本书,小编本意是对其讲述的内容,分点进行笔记的整理,后来学习以后,发现,这本书应该不算是一本技术提升类的书籍,更像是一本领域拓展和知识科普类书籍,所讲知识广泛,但是较少实践…...

深入讲解Kubernetes架构-节点与控制面之间的通信
本文列举控制面节点(确切说是 API 服务器)和 Kubernetes 集群之间的通信路径。 目的是为了让用户能够自定义他们的安装,以实现对网络配置的加固, 使得集群能够在不可信的网络上(或者在一个云服务商完全公开的 IP 上&am…...

120个IT冷知识,看完就不愁做选择题了
目录 IT冷知识 01-10 1.冰淇淋馅料 2.蠕虫起源 3.Linux和红帽子 4."间谍软件"诞生 5.游戏主机的灵魂 6.Linux之父 7.NetBSD的口号 8.安卓起源 9.不是第七代的 Win 7 10.域名金字塔 11~20 11.神奇魔盒 12. 第一个Ubuntu 正式版本 13.巾帼英雄 14.密码…...
Java之动态规划之机器人移动
目录 0.动态规划问题 一.不同路径 1.题目描述 2.问题分析 3.代码实现 二.不同路径 II 1.题目描述 2.问题分析 3.代码实现 三.机器人双向走路 1.题目描述 2.问题分析 3.代码实现 0.动态规划问题 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问…...
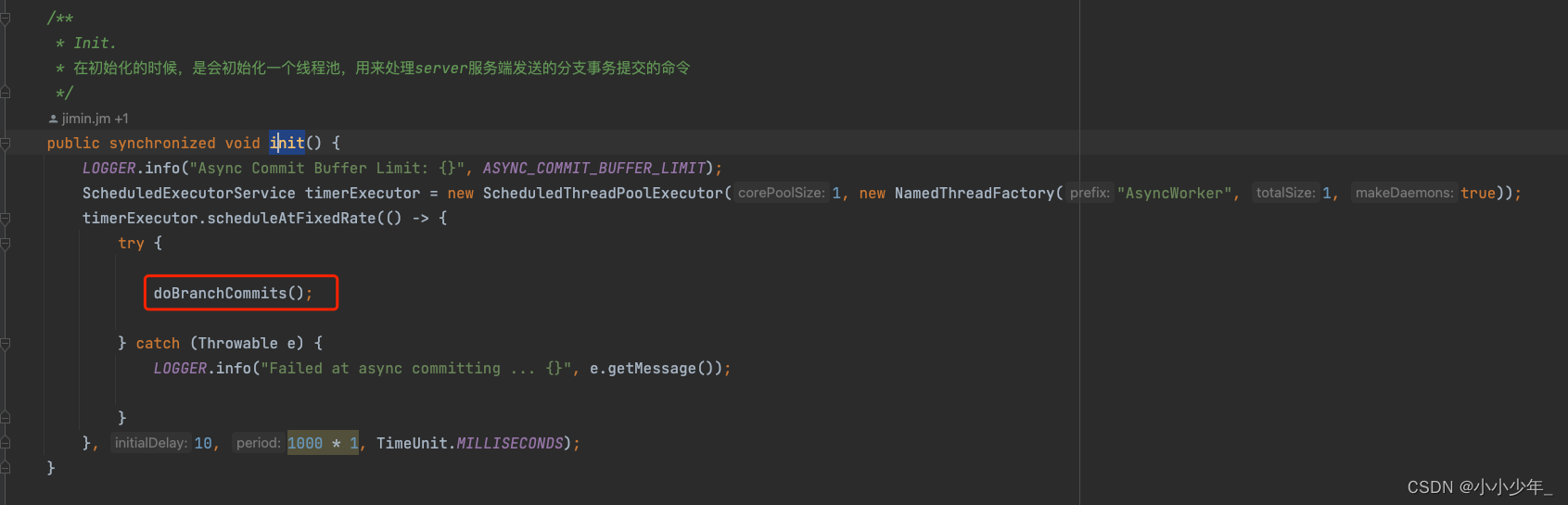
seata源码-全局事务提交 服务端源码
前面的博客中,我们介绍了,发起全局事务时,是如何进行全局事务提交的,这篇博客,主要记录,在seata分布式事务中,全局事务提交的时候,服务端是如何进行处理的 发起全局事务提交操作 事…...
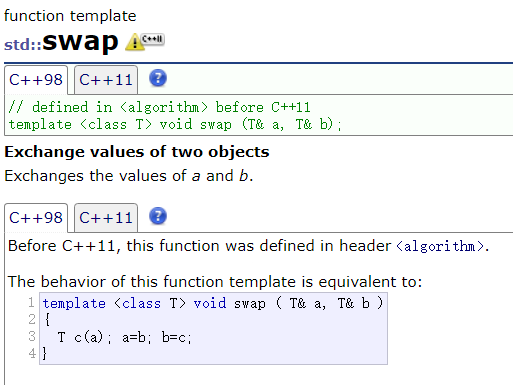
C++ 模板
文章目录一、泛型编程二、 函数模板三、类模板一、泛型编程 泛型编程:编写与类型无关的通用代码,代码复用的一种方法 在 C 中,我们可以通过函数重载实现通用的交换函数 Swap ,但是有一些缺点 重载函数只有类型不同,…...
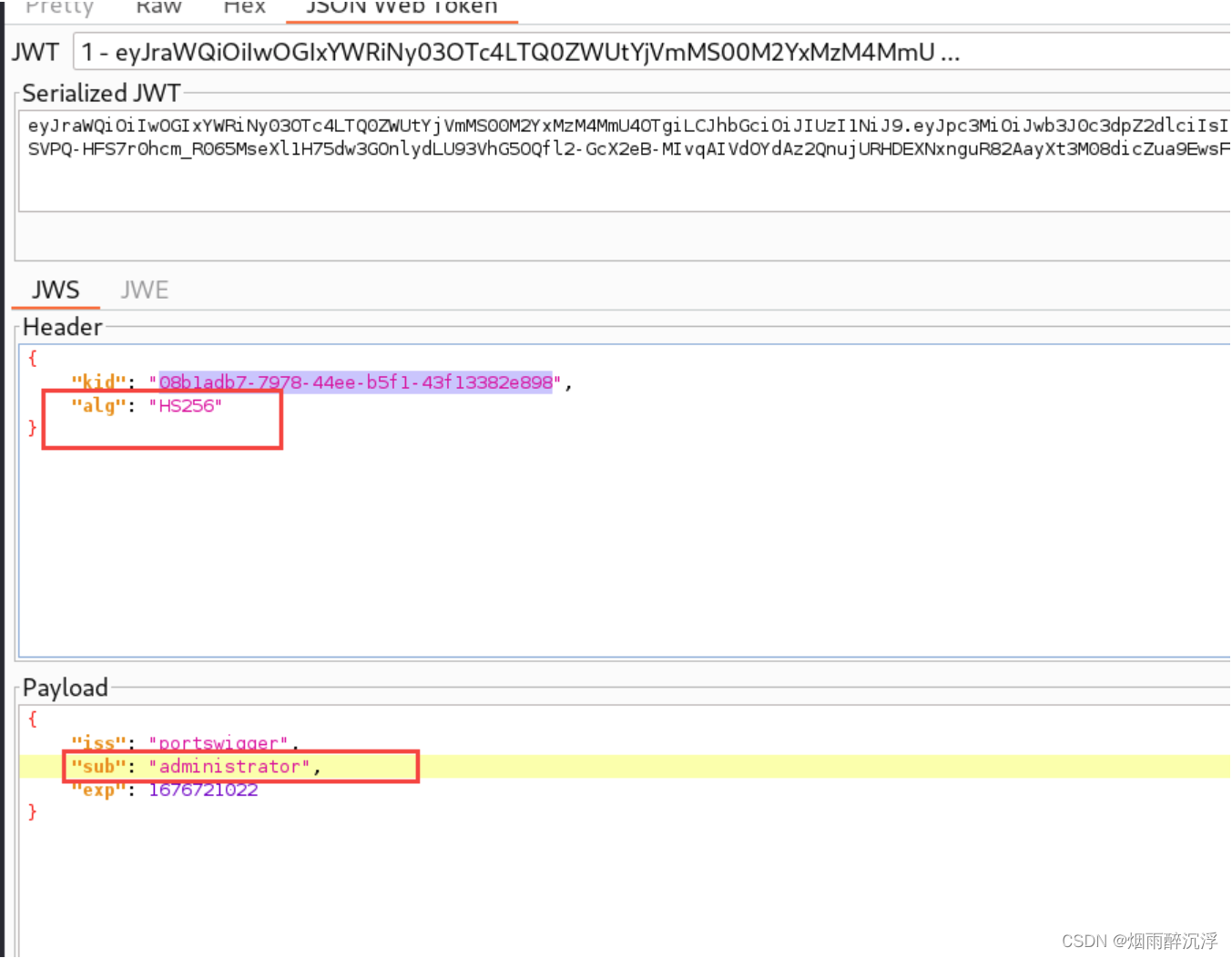
JWT安全漏洞以及常见攻击方式
前言 随着web应用的日渐复杂化,某些场景下,仅使用Cookie、Session等常见的身份鉴别方式无法满足业务的需要,JWT也就应运而生,JWT可以有效的解决分布式场景下的身份鉴别问题,并且会规避掉一些安全问题,如CO…...
)
华为OD机试题 - 最小施肥机能效(JavaScript)
最近更新的博客 华为OD机试题 - 任务总执行时长(JavaScript) 华为OD机试题 - 开放日活动(JavaScript) 华为OD机试 - 最近的点 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试题 - 最小步骤数(JavaScript) 华为OD机试题 - 任务混部(JavaScript) 华为OD机试题 - N 进…...
Python(1)变量的命名规则
目录 1.变量的命名原则 3.内置函数尽量不要做变量 4.删除变量和垃圾回收机制 5.结语 参考资料 1.变量的命名原则 ①由英文字母、_(下划线)、或中文开头 ②变量名称只能由英文字母、数字、下画线或中文字所组成。 ③英文字母大小写不相同 实例: 爱_aiA1 print(…...
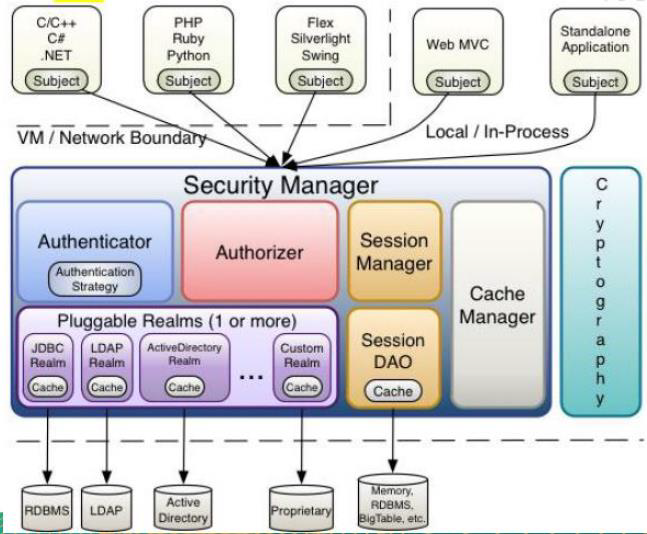
Shiro1.9学习笔记
文章目录一、Shiro概述1、Shiro简介1.1 介绍1.2 Shiro特点2、Shiro与SpringSecurity的对比3、Shiro基本功能4、Shiro原理4.1 Shiro 架构(外部)4.2 shiro架构(内部)二、Shiro基本使用1、环境准备2、登录认证2.1 登录认证概念2.2 登录认证基本流程2.3 登录认证实例2.4 身份认证源…...
2.5|iot|嵌入式Linux系统开发与应用|第4章:Linux外壳shell脚本程序编程
1.shell基础 Shell是Linux操作系统内核的外壳,它为用户提供使用操作系统的命令接口。 用户在提示符下输入的每个命令都由shell先解释然后发给Linux内核,所以Linux中的命令通称为shell命令。 通常我们使用shell来使用Linux操作系统。Linux系统的shell是…...

九龙证券|连续七周获加仓,四大行业成“香饽饽”!
本周17个申万职业北上资金持股量环比增加。 北上资金抢筹铝业龙头 本周A股商场全体冲高回落,沪指收跌1.12%,深成指跌2.18%,创业板指跌3.76%。北上资金周内小幅净流入。在大盘体现较差的周四周五,北上资金别离逆市回流67.94亿元、…...
210天从外包踏进华为跳动那一刻,我泪目了
前言 没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年4月,我有幸成为了华为的一名高级测试工程师,正如标题所…...

CMake 引入第三方库
CMake 引入第三方库 在 CMake 中,如何引入第三方库是一个常见的问题。在本文中,我们将介绍 CMake 中引入第三方库的不同方法,以及它们的优缺点。 1. 使用 find_package 命令 在 CMake 中,使用 find_package 命令是最简单和最常…...

软考中级-面向对象
面向对象基础(1)类类分为三种:实体类(世间万物)、接口类(又称边界类,提供用户与系统交互的方式)、控制类(前两类之间的媒介)。对象:由对象名数据&…...

Linux 系统构成:bootloader、kernel、rootfs
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录前言bootloaderk…...
SpringCloud - Eureka注册发现
目录 提供者与消费者 Eureka原理分析 搭建Eureka服务 服务注册 服务发现 提供者与消费者 服务提供者: 一次业务中,被其它微服务调用的服务(提供接口给其它微服务)服务消费者: 一次业务中,调用其它微服务的服务(调用其它微服务…...
WampServer安装教程
文章目录简介:官网地址安装步骤:我是阿波,学习PHP记录一下笔记,如果对你有帮助,欢迎一键三连,谢谢! 简介: WampServer是一个用于Windows操作系统的Web开发环境,其名称来…...

文献综述效率提升300%?NotebookLM在区域地理分析中的7个颠覆性用法,含真实课题复现代码
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度语义理解与问答的 AI 工具,其在地理学研究中展现出独特价值——尤其适用于处理多源异构的地理文献、野外调…...

Spring源码全家桶核心宝典,Java程序员提升基础内功必备!
Spring是我们Java程序员面试和工作都绕不开的重难点。很多粉丝就经常跟我反馈说由Spring衍生出来的一系列框架太多了,根本不知道从何下手;大家学习过程中大都不成体系,但面试的时候都上升到源码级别了,你不光要清楚了解Spring源码…...
)
基于AI的MRI图像超分辨率重建与去噪,当AI遇见MRI:基于深度学习的超分辨率重建与去噪实战(从SwinIR到Diffusion)
目录 1. 问题的起点:MRI为什么需要超分和去噪? 2. 最新技术选型:为什么不用简单CNN? 3. 数据准备:模拟MRI的退化过程 4. SwinIR核心原理与MRI适配 简化的SwinIR模型结构(PyTorch实现) 5. 去噪专用:Restormer(Transformer for Restoration) 关键组件:MDTA(Mu…...

别再死记硬背了!一张图看懂5G NR LDPC码BG1和BG2的选择规则
5G NR LDPC码BG选择逻辑:从标准文档到工程实践的精要解析 在5G新空口(NR)物理层设计中,低密度奇偶校验(LDPC)码作为数据信道的核心编码方案,其性能直接决定了系统吞吐量与可靠性。而基本图&…...

STM32WLE5CCU6 LoRaWAN节点实战:用AT指令连接TTN服务器并收发数据
STM32WLE5CCU6 LoRaWAN节点实战:从硬件配置到TTN云端交互全解析 在物联网设备爆炸式增长的今天,低功耗广域网络(LPWAN)技术正成为连接海量终端的关键基础设施。作为LPWAN的代表性技术之一,LoRaWAN以其超长传输距离和极低功耗特性,…...

Kleiber:简化多架构Docker镜像构建与发布的自动化工具
1. 项目概述与核心价值最近在整理自己的开发工具链时,又翻出了devgap/kleiber这个项目,它在我日常的容器化开发工作流中扮演了一个相当关键但又不那么起眼的角色。简单来说,Kleiber 是一个 Docker 镜像的构建和发布自动化工具,但它…...

历史学博士生紧急避坑指南:NotebookLM误用导致的3类史料误读及权威校验方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在历史学研究中的定位与风险图谱 NotebookLM 是 Google 推出的基于用户上传文档构建语义理解模型的实验性工具,其核心能力在于对私有史料(如扫描PDF、OCR文本、手稿转…...

如何用一句话让小爱音箱播放你的私人音乐库?Docker部署XiaoMusic完全指南
如何用一句话让小爱音箱播放你的私人音乐库?Docker部署XiaoMusic完全指南 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经想过,只…...

Boss-Key终极指南:一键隐藏窗口,打造高效安全的办公环境
Boss-Key终极指南:一键隐藏窗口,打造高效安全的办公环境 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办…...

2026年十大最佳小程序制作平台:革新数字化运营体验
小程序制作已成为企业数字化运营的重要抓手,2026年市场涌现多个高效平台。本文聚焦十大主流工具,涵盖从开发效率到生态构建的核心维度。好赞科技凭借地域精准算法领跑,亿点通科技以低代码开发见长,启帆数字突出定制化能力。各平台…...