pytorch入门-神经网络
神经网络的基本骨架
import torch
from torch import nn #nn模块是PyTorch中用于构建神经网络模型的核心模块。它提供了各种类和函数,可以帮助你定义和训练神经网络。class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() #调用 super(Tudui, self).__init__() 初始化父类 nn.Module,这样我们才能正常使用神经网络模块的功能。def forward(self,input):output = input + 1 #在 forward 方法中,定义了模型的前向传播过程。输入 input 加上 1,并将结果作为输出返回。return outputtudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)卷积操作
import torch
import torch.nn.functional as F #torch.nn.functional模块提供了一系列的函数,用于构建神经网络的各种操作,如激活函数、损失函数、池化操作等。# torch.tensor是PyTorch中的一个类,用于创建多维数组或张量。它是使用PyTorch进行科学计算和深度学习的核心数据结构之一。
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])
#input是一个张量,通过调用torch.reshape(input, (1, 1, 5, 5))将其形状重塑为(1, 1, 5, 5)。这意味着原先的张量形状为(5, 5),重塑后的张量形状为(1, 1, 5, 5)。
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))output = F.conv2d(input, kernel, stride=1) #conv2d函数接收三个参数:input、kernel和stride。它执行了一个二维卷积操作,将输入张量input与卷积核张量kernel进行卷积运算,并返回卷积结果。stride参数指定了卷积操作的步幅,默认为1。
print(output)output2 = F.conv2d(input, kernel, stride=2)
print(output2)output3 = F.conv2d(input, kernel, stride=1, padding=1)#padding参数用于在输入张量的周围添加零填充(zero-padding),以控制输出的尺寸。通过在输入的周围添加零值像素,可以保持输出具有与输入相同的空间尺寸。
print(output3)卷积层
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader #用于加载数据集的实用工具类。
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(r"D:\PyCharm\learn_torch\dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)#加载CIFAR-10数据集。#DataLoader类主要用于将数据集分割成小批量数据并提供数据加载的功能。它接收两个主要参数:dataset和batch_size。
# dataset参数是一个数据集对象,可以是之前加载的CIFAR-10数据集 (torchvision.datasets.CIFAR10) 或其他自定义的数据集对象。
# batch_size参数指定了每个小批量数据的样本数量。在这个例子中,batch_size被设置为64,表示每个小批量数据中包含64个样本。
dataLoader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()#Conv2d 类需要指定一些参数来定义卷积层的属性:# in_channels:输入张量的通道数,这里为 3,表示输入是 RGB 彩色图像,具有 3 个通道。# out_channels:输出张量的通道数,这里为 6,表示输出将包含 6 个通道。# kernel_size:卷积核的大小,这里为 3,表示卷积核的宽度和高度都为 3。# stride:卷积的步幅大小,这里为 1,表示每次卷积的滑动步幅为 1。# padding:零填充的大小,这里为 0,表示不对输入进行零填充。self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)#forward(self, x) 是模型类中的方法,用于定义模型的前向传播过程。在该方法中,输入张量 x 经过模型的各个层(如卷积层、池化层、全连接层等)进行计算,并返回最终的输出结果。# x = self.conv1(x)# x = torch.relu(x)# x = x.view(x.size(0), -1)# x = self.fc1(x)def forward(self,x):x = self.conv1(x) #这行代码将输入张量 x 通过卷积层 conv1 进行卷积操作,更新 x 的值为卷积操作的结果。return xtudui = Tudui()write = SummaryWriter(r"../logs")#创建了一个 SummaryWriter 对象,用于将训练过程中的数据写入到指定的日志目录中。step = 0
for data in dataLoader:#这行代码将 data 数据拆分为 imgs 和 target 两个部分。# 假设 data 是一个包含图像和标签的数据集,在进行训练或测试时,常常需要将数据拆分为图像和对应的标签。这样可以方便地对图像进行处理和输入模型,同时获取对应 的标签用于计算损失或评估模型性能。# imgs 表示图像数据,target 表示对应的标签数据,可能是一个类别标签、一个数字标签或者其他形式的标签。imgs, target = dataoutput = tudui(imgs)#将图像数据 imgs 作为输入传递给名为 tudui 的函数(或模型),并将输出结果赋值给变量 output。print(imgs.shape)print(output.shape)#torch.Size([64, 3, 32, 32])write.add_images("input", imgs, step)#torch.Size([64, 6, 30, 30])output = torch.reshape(output, (-1, 3, 30, 30))#这行代码将名称为 “input” 的图像数据 imgs 添加到 SummaryWriter 对象中,用于生成可视化的输入图像。# 在使用 TensorBoard 进行可视化时,可以通过 SummaryWriter 对象的 add_images 方法将图像数据写入到日志文件中,以便后续在 TensorBoard 中展示和分 析。# 第一个参数是图像的名称,可以是任意字符串,用于在# TensorBoard# 中标识不同的图像。# 第二个参数是图像数据,在这里是# imgs# 变量,可能是一个张量或数组,表示一批图像数据。图像数据的形状通常是[batch_size, channels, height, width]。# 第三个参数是步数 / 迭代次数,用于在# TensorBoard# 中确定图像数据对应的时间或步数。这个参数是可选的,如果不提供,则默认使用# SummaryWriter对象的全局步数。write.add_images("output",output, step)step = step + 1最大池化
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(r"../dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=64)input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]],dtype=torch.float32)#指定了数据的类型为 torch.float32,这意味着张量中的元素将被解释为 32 位浮点数。# 第一个维度(-1):将根据其他维度确定,以使得重塑后的总元素数量与原始张量保持一致。
# 第二个维度(1):表示每个批次中的通道数为 1。
# 第三个维度(5):表示每个图像的高度为 5。
# 第四个维度(5):表示每个图像的宽度为 5。
input = torch.reshape(input, (-1, 1, 5, 5))print(input.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()#池化操作是深度学习中常用的一种操作,用于减小特征图的空间尺寸,从而降低模型参数量和计算量,并提取出更显著的特征。# kernel_size = 3:池化窗口的大小为 3x3。这意味着在进行池化操作时,将以3x3的窗口滑动在输入特征图上,每次选取窗口内的最大值作为输出。# ceil_mode = False:在默认情况下,当输入特征图的大小除以池化窗口的大小时存在小数部分时,输出特征图的大小将向下取整。即输入特征图大小与输出特征图 大小之间存在下取整关系。设为False表示不进行这种向上取整操作。self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=False)def forward(self, input):output = self.maxpool(input)return outputtudui = Tudui()
# output = tudui(input)
# print(output)write = SummaryWriter(r"../logs--maxpool")
step = 0
for data in dataloader:imgs, target = datawrite.add_images("input",imgs,step)output = tudui(imgs)write.add_images("output", output, step)step = step + 1write.close()非线性激活
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterinput = torch.tensor([[1, -0.5],[-1, 3]])output = torch.reshape(input, (-1, 1, 2, 2))
print(output.shape)dataset = torchvision.datasets.CIFAR10("../dataset", train=False, download=True,transform=torchvision.transforms.ToTensor())
datalodar = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.relu1 = ReLU() # ReLU(Rectified Linear Unit)是深度学习中常用的一种非线性激活函数。它的作用是在神经网络的模型中引入非线性映射,以增强模型的表达能力。self.sigmoid1 = Sigmoid() # Sigmoid激活函数是一种常用的非线性激活函数,用于在神经网络中引入非线性变换。它的输出范围在 (0, 1) 之间,将输入值映射到概率形式的输出。def forward(self, input):output = self.sigmoid1(input)return outputtudui = Tudui()writer = SummaryWriter("../log_relu")
step = 0for data in datalodar:imgs, target = datawriter.add_images("input", imgs, global_step=step)output = tudui(imgs)writer.add_images("output", imgs, global_step=step)step = step + 1writer.close()
线性层及其他层介绍
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download = True)dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()#self.linear是类中的一个成员变量,它被赋值为一个Linear对象。Linear对象的构造函数需要两个参数:输入特征的大小和输出特征的大小。在这里,输入特征的大小为196608,输出特征的大小为10。#linear = Linear(in_features, out_features)# output = linear(input)#in_features 表示输入的特征维度大小,out_features 表示输出的特征维度大小。self.linear = Linear(196608,10)def forward(self,input):output = self.linear(input)return outputtudui = Tudui()for data in dataloader:imgs, targets = dataprint(imgs.shape)# output = torch.reshape(imgs, (1, 1, 1, -1))output = torch.flatten(imgs)#通过调用 torch.flatten 函数,可以将输入张量 imgs 展平成一个一维张量。展平后的张量 output 中的元素顺序与原始张量保持一致,只是维度形状变为一维。print(output.shape)output = tudui(output)print(output.shape)神经网络搭建和Sequential的使用
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriterclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# self.conv1 = Conv2d(3, 32, 5, padding=2)# self.maxpool1 = MaxPool2d(2)# self.conv2 = Conv2d(32, 32, 5, padding=2)# self.maxpool2 = MaxPool2d(2)# self.conv3 = Conv2d(32, 64, 5, padding=2)# self.maxpool3 = MaxPool2d(2)# self.flatten = Flatten()# self.linear1 = Linear(1024, 64)# self.linear2 = Linear(64, 10)# 这个模型使用了Sequential模型,并依次添加了多个层来构建网络结构。每个层的作用如下:# Conv2d(3, 32, 5, padding=2):卷积层,输入通道数为3,输出通道数为32,卷积核大小为5x5,填充为2。# MaxPool2d(2):池化层,池化核大小为2x2。# Conv2d(32, 32, 5, padding=2):卷积层,输入通道数为32,输出通道数为32,卷积核大小为5x5,填充为2。# MaxPool2d(2):池化层,池化核大小为2x2。# Conv2d(32, 64, 5, padding=2):卷积层,输入通道数为32,输出通道数为64,卷积核大小为5x5,填充为2。# MaxPool2d(2):池化层,池化核大小为2x2。# Flatten():展平层,用于将多维的输入数据展平为一维。# Linear(1024, 64):全连接层,输入维度为1024,输出维度为64。# Linear(64, 10):全连接层,输入维度为64,输出维度为10。self.modul1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)x = self.modul1(x)return xtudui = Tudui()
print(tudui)
input = torch.ones(64, 3, 32, 32)
output = tudui(input)
print(output.shape)writer = SummaryWriter("../logs_seq")
writer.add_graph(tudui, input)
writer.close()相关文章:

pytorch入门-神经网络
神经网络的基本骨架 import torch from torch import nn #nn模块是PyTorch中用于构建神经网络模型的核心模块。它提供了各种类和函数,可以帮助你定义和训练神经网络。class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() #调用 super(Tudui,…...
)
kafka使用心得(二)
kafka进阶 消息顺序保证 Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序。 消费者和分区的对应关系 参考这篇文章。 分区文件 一个分区对应着log.dirs下的…...

(二)掌握最基本的Linux服务器用法——Linux下简单的C/C++ 程序、项目编译
1、静态库与动态库 静态库(Static Library):静态库是编译后的库文件,其中的代码在编译时被链接到程序中,因此它会与程序一起形成一个独立的可执行文件。每个使用静态库的程序都会有自己的库的副本,这可能会导致内存浪费。常用后缀…...
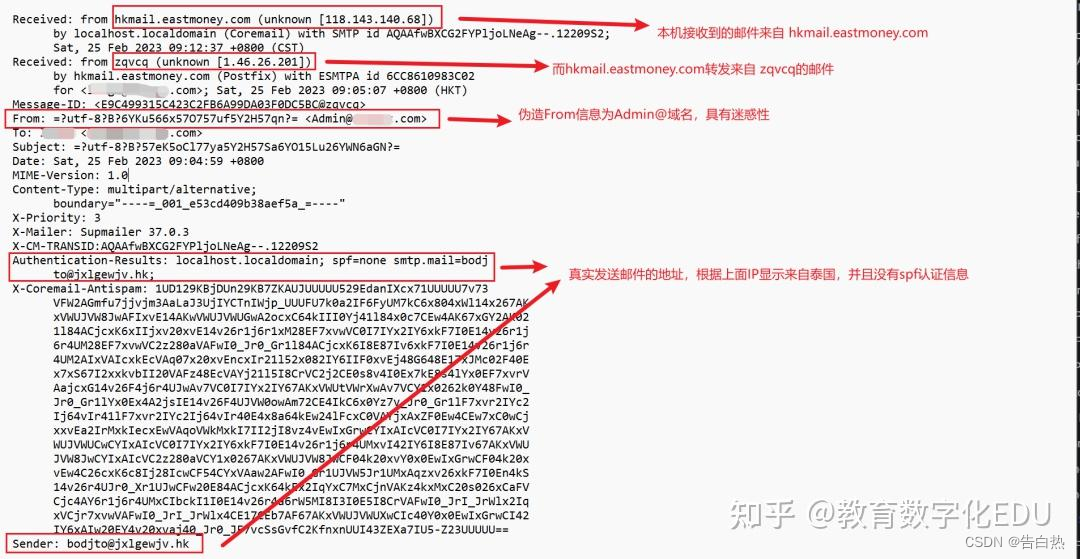
应急响应-钓鱼邮件的处理思路溯源及其反制
0x00 钓鱼邮件的危害 1.窃取用户敏感信息,制作虚假网址,诱导用户输入敏感的账户信息后记录 2.携带病毒木马程序,诱导安装,使电脑中病毒木马等 3.挖矿病毒的传输,勒索病毒的传输等等 0x01 有指纹的钓鱼邮件的溯源处理…...
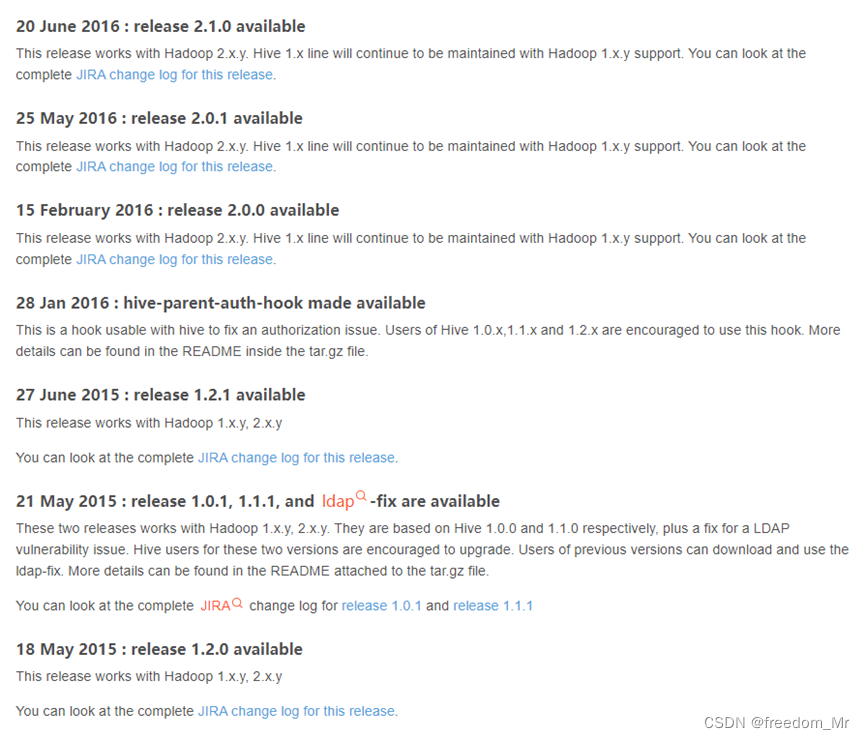
Hadoop Hbase Hive 版本对照一览
这里写目录标题 一、Hadoop 与 Hbase 版本对照二、Hadoop 与 Hive 版本对照 官网内容记录,仅供参考 一、Hadoop 与 Hbase 版本对照 二、Hadoop 与 Hive 版本对照...

Postgresql 基础使用语法
1.数据类型 1.数字类型 类型 长度 说明 范围 与其他db比较 Smallint 2字节 小范围整数类型 32768到32767 integer 4字节 整数类型 2147483648到2147483647 bigint 8字节 大范围整数类型 -9233203685477808到9223203685477807 decimal 可变 用户指定 精度小…...

Qt 之 QDebug,QString
文章目录 前言一、QDebug二、QString总结 前言 一、QDebug QDebug是Qt中用于进行调试和输出日志的类。它提供了一种便捷的方式来输出各种类型的数据,并可轻松地与流式输出一起使用,方便调试和查看程序的运行情况。 引入QDebug: 在使用QDebug…...

【C++】面试题
1、都说c是面向对象的语言,面向对象的三个特性能 [展开] 介绍一下吗? 封装:封装是一种集中管理的思想,把内部的数据和实现方法组合在一起,并且不对外暴漏内部的数据和实现方法,只对外提供几个接口来完成函数…...
机器学习算法之-逻辑回归(1)
什么是回归 回归树,随机森林的回归,无一例外他们都是区别于分类算法们,用来处理和预测连续型标签的算法。然而逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问…...

JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译) java多线程面试问题 1. 进程和线程之间有什么不同? 一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序…...
正中优配:2023新股上市涨跌幅规则?新股上市涨跌幅限制为几天?
A股与美股不同,股票存在涨跌幅限制,那么,2023新股上市涨跌幅规矩?新股上市涨跌幅限制为几天?下面正中优配为我们预备了相关内容,以供参阅。 2023年新股上市涨跌幅存在以下规矩: 1、主板初次公开…...

如何查看线程在哪个cpu核上
1、ps -eLF查看PSR值 2、 taskset -pc $pid(进程/线程) 参考链接:https://blog.csdn.net/test1280/article/details/87993669...
【Vue前端】设置标题用于SEO优化
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 1.vue全局配置2.创建并暴露getPageTitle方法3.通过全局前置守卫设置title4.页面上引用title5.项目使用中英文翻译,title失效 1.vu…...

maven install
maven install maven 的 install 命令,当我们的一个 maven 模块想要依赖其他目录下的模块时,直接添加会找不到对应的模块,只需要找到需要引入的模块,执行 install 命令,就会将该模块放入本地仓库,就可以进…...
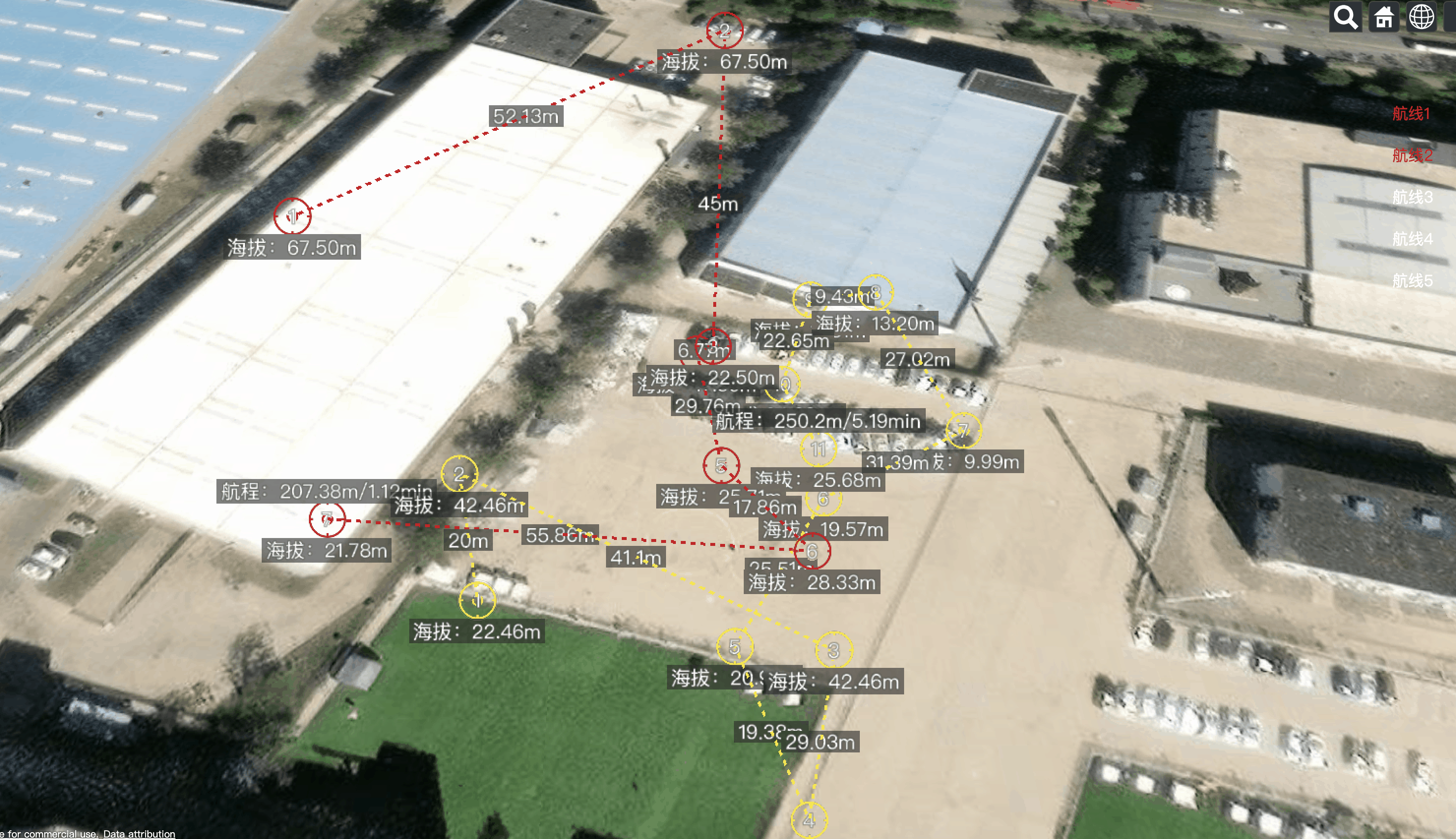
Vue.js2+Cesium1.103.0 七、Primitive 绘制航线元素
Vue.js2Cesium1.103.0 七、Primitive 绘制航线元素 用 Primitive 绘制航线元素,包括航点图标,航线线段,线段距离标注,航点序号,海拔标注,总航程等信息。 可同时绘制多条航线;可根据 id 清除指…...

Mybatis 源码 ④ :TypeHandler
文章目录 一、前言二、DefaultParameterHandler1. DefaultParameterHandler#setParameters1.1 UnknownTypeHandler1.2 自定义 TypeHandler 三、DefaultResultSetHandler1. hasNestedResultMaps2. handleRowValuesForNestedResultMap2.1 resolveDiscriminatedResultMap2.2 creat…...

RabbitMQ和JMeter,一个完美的组合!优化你的中间件处理方式
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息中间件,它是基于Erlang语言编写的,并发能力强,性能好,是目前主流的消息队列中间件之一。 RabbitMQ的安装可参照官网( https://www.rabbitmq.c…...

WARNING: IPv4 forwarding is disabled. Networking will not work
当我在运行某条语句的时候 docker run -it -p 30001:22 --namecentos-ssh centos /bin/bash 提示 WARNING: IPv4 forwarding is disabled. Networking will not work. 解决: vim /usr/lib/sysctl.d/00-system.conf net.ipv4.ip_forward1 systemctl restart networ…...
@EnableConofigurationProperties注解的用法)
SpringBoot复习:(40)@EnableConofigurationProperties注解的用法
一、配置文件: server.port9123 二、配置类: package cn.edu.tju.config;import com.mysql.fabric.Server; import org.springframework.boot.autoconfigure.web.ServerProperties; import org.springframework.boot.context.properties.EnableConfigu…...

Live Market是如何做跨境客户服务的?哪些技术赋能?
在面对不同的海外市场和用户群体时,如何进行有效地出海营销是跨境商家面临的挑战。其中消费者服务管理和卖家保障尤其关键,如何做好客户服务管理?包括处理好客户投诉,提升消费者满意度是所有跨境商家和品牌独立站卖家非常重视的问题。 在数字化浪潮席卷之下&#…...

戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进
戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 在戴森球计划的工厂建设中,蓝图设计…...

3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移
3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper 你是否曾梦想过让普通人也能跳出专业舞者的优美动作?…...

【Appium 系列】第19节-Allure 报告与 Bug 管理 — 测试结果的可视化
对应代码:utils/allure_helper.py、utils/bug_reporter.py、utils/bug_allure_helper.py说明:本节代码来自一个真实的移动端自动化测试项目,已做模糊化处理,可直接复用。1. 为什么需要报告体系?测试跑完之后࿰…...

避坑指南:用STM32F4的HAL库驱动L298N和TB6612,CubeMX配置有哪些关键点不同?
STM32F4电机驱动实战:L298N与TB6612的CubeMX配置差异全解析 在机器人底盘或智能小车开发中,电机驱动模块的选择直接影响着系统的响应速度、能耗效率和整体稳定性。作为两种经典的有刷直流电机驱动方案,L298N和TB6612在STM32F4开发中各有拥趸。…...
)
别再让串口中断拖慢你的STM32F407了!手把手教你配置UART4的DMA收发(附完整代码)
STM32F407 UART4 DMA通信实战:突破串口中断的性能瓶颈 如果你正在使用STM32F407的UART4进行数据通信,却频繁遇到系统响应迟缓的问题,很可能是因为传统的串口中断方式正在消耗大量CPU资源。每次收发一个字节都触发中断,当数据量大…...

zotero-addons:Zotero生态扩展框架的模块化设计与架构解析
zotero-addons:Zotero生态扩展框架的模块化设计与架构解析 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing and installing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 在学术研究…...

Play Integrity API Checker:快速检测Android设备安全性的完整指南
Play Integrity API Checker:快速检测Android设备安全性的完整指南 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-a…...

3个问题让你了解为什么我们需要中文AI的“数据粮仓“
3个问题让你了解为什么我们需要中文AI的"数据粮仓" 【免费下载链接】MNBVC MNBVC(Massive Never-ending BT Vast Chinese corpus)超大规模中文语料集。对标chatGPT训练的40T数据。MNBVC数据集不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC…...

Runtime不是跑kernel的——它是昇腾CANN里的执行层
前言 昇腾NPU上的算子是怎么跑起来的?有人说"runtime就是负责跑kernel的",有人说"runtime管内存分配",还有人说"runtime就是CUDA runtime的对应物"。这些答案都有对的地方,但都没说到根子上。 Ru…...

深入CPU内部:8086的MUL指令是如何工作的?从硬件视角理解乘法结果为何放在AX和DX
深入CPU内部:8086的MUL指令硬件实现原理全解析 记得第一次在调试器中单步执行MUL指令时,看到AX和DX寄存器突然被一堆十六进制数填满,那种既兴奋又困惑的感觉至今难忘。作为x86架构中最基础的乘法指令,MUL表面看似简单,…...