SQL代码编码原则和规范

目录
- 1、先了解MySQL的执行过程
- 2、数据库常见规范
- 3、所有表必须使用Innodb存储引擎
- 4、每个Innodb表必须有个主键
- 5、数据库和表的字符集统一使用UTF8
- 6、查询SQL尽量不要使用select *,而是具体字段
- 7、避免在where子句中使用 or 来连接条件
- 8、尽量使用数值替代字符串类型
- 9、使用varchar代替char
- 10、财务、银行相关的金额字段必须使用decimal类型
- 11、避免使用ENUM类型
- 12、去重distinct过滤字段要少
- 13、where中使用默认值代替null
- 14、避免在where子句中使用!=或<>操作符
- 15、inner join 、left join、right join,优先使用inner join
- 16、提高group by语句的效率
- 17、清空表时优先使用truncate
- 18、操作delete或者update语句,加个limit或者循环分批次删除
- 19、UNION操作符
- 20、SQL语句中IN包含的字段不宜过多
- 21、批量插入性能提升
- 22、表连接不宜太多,索引不宜太多,一般5个以内
- 23、禁止给表中的每一列都建立单独的索引
- 24、如何选择索引列的顺序
- 25、对于频繁的查询优先考虑使用覆盖索引
- 26、建议使用预编译语句进行数据库操作
- 27、避免产生大事务操作
- 28、避免在索引列上使用内置函数
- 29、组合索引
- 30、复合索引最左特性
- 31、必要时可以使用force index来强制查询走某个索引
- 32、优化like语句
- 33、统一SQL语句的写法
- 34、不要把SQL语句写得太复杂
- 35、关于临时表
- 36、将大的DELETE,UPDATE、INSERT 查询变成多个小查询
- 37、使用explain分析你SQL执行计划
- 38、读写分离与分库分表
- 39、使用合理的分页方式以提高分页的效率
- 40、尽量控制单表数据量的大小,建议控制在500万以内。
- 41、谨慎使用Mysql分区表
- 42、尽量做到冷热数据分离,减小表的宽度
- 43、禁止在表中建立预留字段
- 44、禁止在数据库中存储图片,文件等大的二进制数据
- 45、建议把BLOB或是TEXT列分离到单独的扩展表中
- 46、TEXT或BLOB类型只能使用前缀索引
- 47、一些其它优化方式
1、先了解MySQL的执行过程
了解了MySQL的执行过程,我们才知道如何进行sql优化。
- 客户端发送一条查询语句到服务器;
- 服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据;
- 未命中缓存后,MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树,MySQL解析器将使用MySQL语法进行验证和解析。例如,验证是否使用了错误的关键字,或者关键字的使用是否正确;
- 预处理是根据一些MySQL规则检查解析树是否合理,比如检查表和列是否存在,还会解析名字和别名,然后预处理器会验证权限;
- 根据执行计划查询执行引擎,调用API接口调用存储引擎来查询数据;
- 将结果返回客户端,并进行缓存;

2、数据库常见规范
- 所有数据库对象名称必须使用小写字母并用下划线分割;
- 所有数据库对象名称禁止使用mysql保留关键字;
- 数据库对象的命名要能做到见名识意,并且最后不要超过32个字符;
- 临时库表必须以tmp_为前缀并以日期为后缀,备份表必须以bak_为前缀并以日期(时间戳)为后缀;
- 所有存储相同数据的列名和列类型必须一致;
3、所有表必须使用Innodb存储引擎
没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎(mysql5.5之前默认使用Myisam,5.6以后默认的为Innodb)。
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
4、每个Innodb表必须有个主键
Innodb是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
Innodb是按照主键索引的顺序来组织表的
- 不要使用更新频繁的列作为主键,不适用多列主键;
- 不要使用UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长);
- 主键建议使用自增ID值;
5、数据库和表的字符集统一使用UTF8
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储emoji表情的需要,字符集需要采用utf8mb4字符集。
6、查询SQL尽量不要使用select *,而是具体字段
select *的弊端:
- 增加很多不必要的消耗,比如CPU、IO、内存、网络带宽;
- 增加了使用覆盖索引的可能性;
- 增加了回表的可能性;
- 当表结构发生变化时,前端也需要更改;
- 查询效率低;
7、避免在where子句中使用 or 来连接条件
- 使用
or可能会使索引失效,从而全表扫描; - 对于
or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描; - 也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定;
- 虽然
mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的;
8、尽量使用数值替代字符串类型
- 因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
- 而对于数字型而言只需要比较一次就够了;
- 字符会降低查询和连接的性能,并会增加存储开销;
9、使用varchar代替char
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间;char按声明大小存储,不足补空格;- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高;
10、财务、银行相关的金额字段必须使用decimal类型
- 非精准浮点:float,double
- 精准浮点:decimal
- Decimal类型为精准浮点数,在计算时不会丢失精度;
- 占用空间由定义的宽度决定,每4个字节可以存储9位数字,并且小数点要占用一个字节;
- 可用于存储比bigint更大的整型数据;
11、避免使用ENUM类型
- 修改ENUM值需要使用ALTER语句;
- ENUM类型的ORDER BY操作效率低,需要额外操作;
- 禁止使用数值作为ENUM的枚举值;
12、去重distinct过滤字段要少
- 带distinct的语句占用
cpu时间高于不带distinct的语句 - 当查询很多字段时,如果使用
distinct,数据库引擎就会对数据进行比较,过滤掉重复数据 - 然而这个比较、过滤的过程会占用系统资源,如
cpu时间
13、where中使用默认值代替null
- 并不是说使用了
is null或者is not null就会不走索引了,这个跟mysql版本以及查询成本都有关; - 如果
mysql优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件!=,<>,is null,is not null经常被认为让索引失效; - 其实是因为一般情况下,查询的成本高,优化器自动放弃索引的;
- 如果把
null值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点;
14、避免在where子句中使用!=或<>操作符
- 使用
!=和<>很可能会让索引失效 - 应尽量避免在
where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描 - 实现业务优先,实在没办法,就只能使用,并不是不能使用
15、inner join 、left join、right join,优先使用inner join
三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小。
- inner join 内连接,只保留两张表中完全匹配的结果集;
- left join会返回左表所有的行,即使在右表中没有匹配的记录;
- right join会返回右表所有的行,即使在左表中没有匹配的记录;
为什么?
- 如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点;
- 使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少;
- 这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优;
16、提高group by语句的效率
1、反例
先分组,再过滤
select job, avg(salary) from employee
group by job
having job ='develop' or job = 'test';
2、正例
先过滤,后分组
select job,avg(salary) from employee
where job ='develop' or job = 'test'
group by job;
3、理由
可以在执行到该语句前,把不需要的记录过滤掉
17、清空表时优先使用truncate
truncate table在功能上与不带 where子句的 delete语句相同:二者均删除表中的全部行。但 truncate table比 delete速度快,且使用的系统和事务日志资源少。
delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。 truncate table通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
truncate table删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 drop table语句。
对于由 foreign key约束引用的表,不能使用 truncate table,而应使用不带 where子句的 DELETE 语句。由于 truncate table不记录在日志中,所以它不能激活触发器。
truncate table不能用于参与了索引视图的表。
18、操作delete或者update语句,加个limit或者循环分批次删除
(1)降低写错SQL的代价
清空表数据可不是小事情,一个手抖全没了,删库跑路?如果加limit,删错也只是丢失部分数据,可以通过binlog日志快速恢复的。
(2)SQL效率很可能更高
SQL中加了limit 1,如果第一条就命中目标return, 没有limit的话,还会继续执行扫描表。
(3)避免长事务
delete执行时,如果age加了索引,MySQL会将所有相关的行加写锁和间隙锁,所有执行相关行会被锁住,如果删除数量大,会直接影响相关业务无法使用。
(4)数据量大的话,容易把CPU打满
如果你删除数据量很大时,不加 limit限制一下记录数,容易把cpu打满,导致越删越慢。
(5)锁表
一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误,所以建议分批操作。
19、UNION操作符
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select username,tel from user
union
select departmentname from department
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
推荐方案:采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
20、SQL语句中IN包含的字段不宜过多
MySQL的IN中的常量全部存储在一个数组中,这个数组是排序的。如果值过多,产生的消耗也是比较大的。如果是连续的数字,可以使用between代替,或者使用连接查询替换。
21、批量插入性能提升
(1)多条提交
INSERT INTO user (id,username) VALUES(1,'哪吒编程');INSERT INTO user (id,username) VALUES(2,'妲己');
(2)批量提交
INSERT INTO user (id,username) VALUES(1,'哪吒编程'),(2,'妲己');
默认新增SQL有事务控制,导致每条都需要事务开启和事务提交,而批量处理是一次事务开启和提交,效率提升明显,达到一定量级,效果显著,平时看不出来。
22、表连接不宜太多,索引不宜太多,一般5个以内
(1)表连接不宜太多,一般5个以内
- 关联的表个数越多,编译的时间和开销也就越大
- 每次关联内存中都生成一个临时表
- 应该把连接表拆开成较小的几个执行,可读性更高
- 如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了
- 阿里规范中,建议多表联查三张表以下
(2)索引不宜太多,一般5个以内
- 索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率;
- 索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间;
- 索引表的数据是排序的,排序也是要花时间的;
insert或update时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定;- 一个表的索引数最好不要超过5个,若太多需要考虑一些索引是否有存在的必要;
23、禁止给表中的每一列都建立单独的索引
真有这么干的,我也是醉了。
24、如何选择索引列的顺序
建立索引的目的是:希望通过索引进行数据查找,减少随机IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)。
尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好)。
使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)。
25、对于频繁的查询优先考虑使用覆盖索引
覆盖索引:就是包含了所有查询字段(where,select,ordery by,group by包含的字段)的索引。
覆盖索引的好处:
(1)避免Innodb表进行索引的二次查询
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。
而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了IO操作,提升了查询效率。
(2)可以把随机IO变成顺序IO加快查询效率
由于覆盖索引是按键值的顺序存储的,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO。
26、建议使用预编译语句进行数据库操作
预编译语句可以重复使用这些计划,减少SQL编译所需要的时间,还可以解决动态SQL所带来的SQL注入的问题。
只传参数,比传递SQL语句更高效。
相同语句可以一次解析,多次使用,提高处理效率。
27、避免产生大事务操作
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对MySQL的性能产生非常大的影响。
特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
28、避免在索引列上使用内置函数
使用索引列上内置函数,索引失效。
29、组合索引
排序时应按照组合索引中各列的顺序进行排序,即使索引中只有一个列是要排序的,否则排序性能会比较差。
create index IDX_USERNAME_TEL on user(deptid,position,createtime);
select username,tel from user where deptid= 1 and position = 'java开发' order by deptid,position,createtime desc;
实际上只是查询出符合 deptid= 1 and position = 'java开发'条件的记录并按createtime降序排序,但写成order by createtime desc性能较差。
30、复合索引最左特性
(1)创建复合索引
ALTER TABLE employee ADD INDEX idx_name_salary (name,salary)
(2)满足复合索引的最左特性,哪怕只是部分,复合索引生效
SELECT * FROM employee WHERE NAME='哪吒编程'
(3)没有出现左边的字段,则不满足最左特性,索引失效
SELECT * FROM employee WHERE salary=5000
(4)复合索引全使用,按左侧顺序出现 name,salary,索引生效
SELECT * FROM employee WHERE NAME='哪吒编程' AND salary=5000
(5)虽然违背了最左特性,但MySQL执行SQL时会进行优化,底层进行颠倒优化
SELECT * FROM employee WHERE salary=5000 AND NAME='哪吒编程'
(6)理由
复合索引也称为联合索引,当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
联合索引不满足最左原则,索引一般会失效。
31、必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用forceindex来强制优化器使用我们制定的索引。
32、优化like语句
模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效。
- 首先尽量避免模糊查询,如果必须使用,不采用全模糊查询,也应尽量采用右模糊查询, 即
like ‘…%’,是会使用索引的; - 左模糊
like ‘%...’无法直接使用索引,但可以利用reverse + function index的形式,变化成like ‘…%’; - 全模糊查询是无法优化的,一定要使用的话建议使用搜索引擎。
33、统一SQL语句的写法
对于以下两句SQL语句, 程序员认为是相同的,数据库查询优化器认为是不同的。
select * from user;
select * From USER;
这都是很常见的写法,也很少有人会注意,就是表名大小写不一样而已。然而,查询解析器认为这是两个不同的SQL语句,要解析两次,生成两个不同的执行计划,作为一名严谨的Java开发工程师,应该保证两个一样的SQL语句,不管在任何地方都是一样的。
34、不要把SQL语句写得太复杂
经常听到有人吹牛逼,我写了一个800行的SQL语句,逻辑感超强,我们还开会进行了SQL讲解,大家都投来了崇拜的目光。。。
一般来说,嵌套子查询、或者是3张表关联查询还是比较常见的,但是,如果超过3层嵌套的话,查询优化器很容易给出错误的执行计划,影响SQL效率。SQL执行计划是可以被重用的,SQL越简单,被重用的概率越大,生成执行计划也是很耗时的。
35、关于临时表
- 避免频繁创建和删除临时表,以减少系统表资源的消耗;
- 在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log;
- 如果数据量不大,为了缓和系统表的资源,应先create table,然后insert;
- 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除。先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
36、将大的DELETE,UPDATE、INSERT 查询变成多个小查询
能写一个几十行、几百行的SQL语句是不是显得逼格很高?然而,为了达到更好的性能以及更好的数据控制,你可以将他们变成多个小查询。
37、使用explain分析你SQL执行计划
(1)type
- system:表仅有一行,基本用不到;
- const:表最多一行数据配合,主键查询时触发较多;
- eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型;
- ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
- range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range;
- index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小;
- all:全表扫描;
- 性能排名:system > const > eq_ref > ref > range > index > all。
- 实际sql优化中,最后达到ref或range级别。
(2)Extra常用关键字
- Using index:只从索引树中获取信息,而不需要回表查询;
- Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
- Using temporary:mysql常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的
GROUP BY和ORDER BY子句时;
38、读写分离与分库分表
当数据量达到一定的数量之后,限制数据库存储性能的就不再是数据库层面的优化就能够解决的;这个时候往往采用的是读写分离与分库分表同时也会结合缓存一起使用,而这个时候数据库层面的优化只是基础。
读写分离适用于较小一些的数据量;分表适用于中等数据量;而分库与分表一般是结合着用,这就适用于大数据量的存储了,这也是现在大型互联网公司解决数据存储的方法之一。
39、使用合理的分页方式以提高分页的效率
select id,name from user limit 100000, 20
使用上述SQL语句做分页的时候,随着表数据量的增加,直接使用limit语句会越来越慢。
此时,可以通过取前一页的最大ID,以此为起点,再进行limit操作,效率提升显著。
select id,name from user where id> 100000 limit 20
40、尽量控制单表数据量的大小,建议控制在500万以内。
500万并不是MySQL数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
41、谨慎使用Mysql分区表
- 分区表在物理上表现为多个文件,在逻辑上表现为一个表;
- 谨慎选择分区键,跨分区查询效率可能更低;
- 建议采用物理分表的方式管理大数据。
42、尽量做到冷热数据分离,减小表的宽度
Mysql限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节。
减少磁盘IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO);
更有效的利用缓存,避免读入无用的冷数据;
经常一起使用的列放到一个表中(避免更多的关联操作)。
43、禁止在表中建立预留字段
- 预留字段的命名很难做到见名识义;
- 预留字段无法确认存储的数据类型,所以无法选择合适的类型;
- 对预留字段类型的修改,会对表进行锁定;
44、禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机IO操作,文件很大时,IO操作很耗时。
通常存储于文件服务器,数据库只存储文件地址信息。
45、建议把BLOB或是TEXT列分离到单独的扩展表中
Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,Mysql还是要进行二次查询,会使sql性能变得很差,但是不是说一定不能使用这样的数据类型。
如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select * 而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。
46、TEXT或BLOB类型只能使用前缀索引
因为MySQL对索引字段长度是有限制的,所以TEXT类型只能使用前缀索引,并且TEXT列上是不能有默认值的。
47、一些其它优化方式
(1)当只需要一条数据的时候,使用limit 1
limit 1可以避免全表扫描,找到对应结果就不会再继续扫描了。
(2)如果排序字段没有用到索引,就尽量少排序
(3)所有表和字段都需要添加注释
使用comment从句添加表和列的备注,从一开始就进行数据字典的维护。
(4)SQL书写格式,关键字大小保持一致,使用缩进。
(5)修改或删除重要数据前,要先备份。
(6)很多时候用 exists 代替 in 是一个好的选择
(7)where后面的字段,留意其数据类型的隐式转换。
(8)尽量把所有列定义为NOT NULL
NOT NULL列更节省空间,NULL列需要一个额外字节作为判断是否为 NULL的标志位。
NULL列需要注意空指针问题,NULL列在计算和比较的时候,需要注意空指针问题。
(9)伪删除设计
(10)索引不适合建在有大量重复数据的字段上,比如性别,排序字段应创建索引
(11)尽量避免使用游标
因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。

Java学习路线总结,搬砖工逆袭Java架构师
10万字208道Java经典面试题总结(附答案)
Java基础教程系列
Java基础教程系列(进阶篇)
相关文章:
SQL代码编码原则和规范
目录1、先了解MySQL的执行过程2、数据库常见规范3、所有表必须使用Innodb存储引擎4、每个Innodb表必须有个主键5、数据库和表的字符集统一使用UTF86、查询SQL尽量不要使用select *,而是具体字段7、避免在where子句中使用 or 来连接条件8、尽量使用数值替代字符串类型…...

【博客627】gobgp服务无损变更:graceful restart特性
gobgp服务无损变更:graceful restart特性 场景 当我们的bgp网关在对外宣告bgp路由的时候,如果我们网关有新的特性要发布,那么此时如果把网关停止再启动新版本,此时bgp路由会有短暂撤回再播出的过程,会有网络抖动 期待…...

一起学 pixijs(1):常见图形的绘制
大家好,我是前端西瓜哥。 pixijs 是一个强大的 Web Canvas 2D 库,以其强大性能而著称。其底层使用了 WebGL 实现了硬件加速,当然如果不支持的话,也能回退为 Canvas。 本文使用的 pixijs 版本为 7.1.2。 Application Applicati…...
2023年PMP考试教材有哪些?(含pmp资料)
PMP考试教材是《PMBOK指南》,但这次的考试因为大纲的更新,而需要另外的敏捷书籍来备考。且官方发了通知,3、5月还是第六版指南,8月及8月之后,使用第七版教材。 新版考纲将专注于以下三个新领域: 人 – 强调与有效领导项…...
centos7防火墙工具firewall-cmd使用
centos7防火墙工具firewall-cmd使用防火墙概述centos7防火墙工具firewall-cmd使用介绍firewalld的基本使用服务管理工具相关指令配置firewalld-cmd防火墙概述 防火墙是可以帮助计算机在内部网络和外部网络之间构建一道相对隔绝的保护屏障,从而保护数据信息的一种技…...

js html过滤所有标签格式并清除所有nbsp;
var odiv document.getElementsByTagName("*"); for(var i 0; i<odiv.length; i){ if(odiv[i].className newDetail){ let obj odiv[i].childNodes[3]; let oldHtml odiv[i].childNodes[3].innerText;//获取html中不带标签内容 //console.log(odiv[i].childN…...
「技术选型」深度学习软件如何选择?
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。 深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对…...
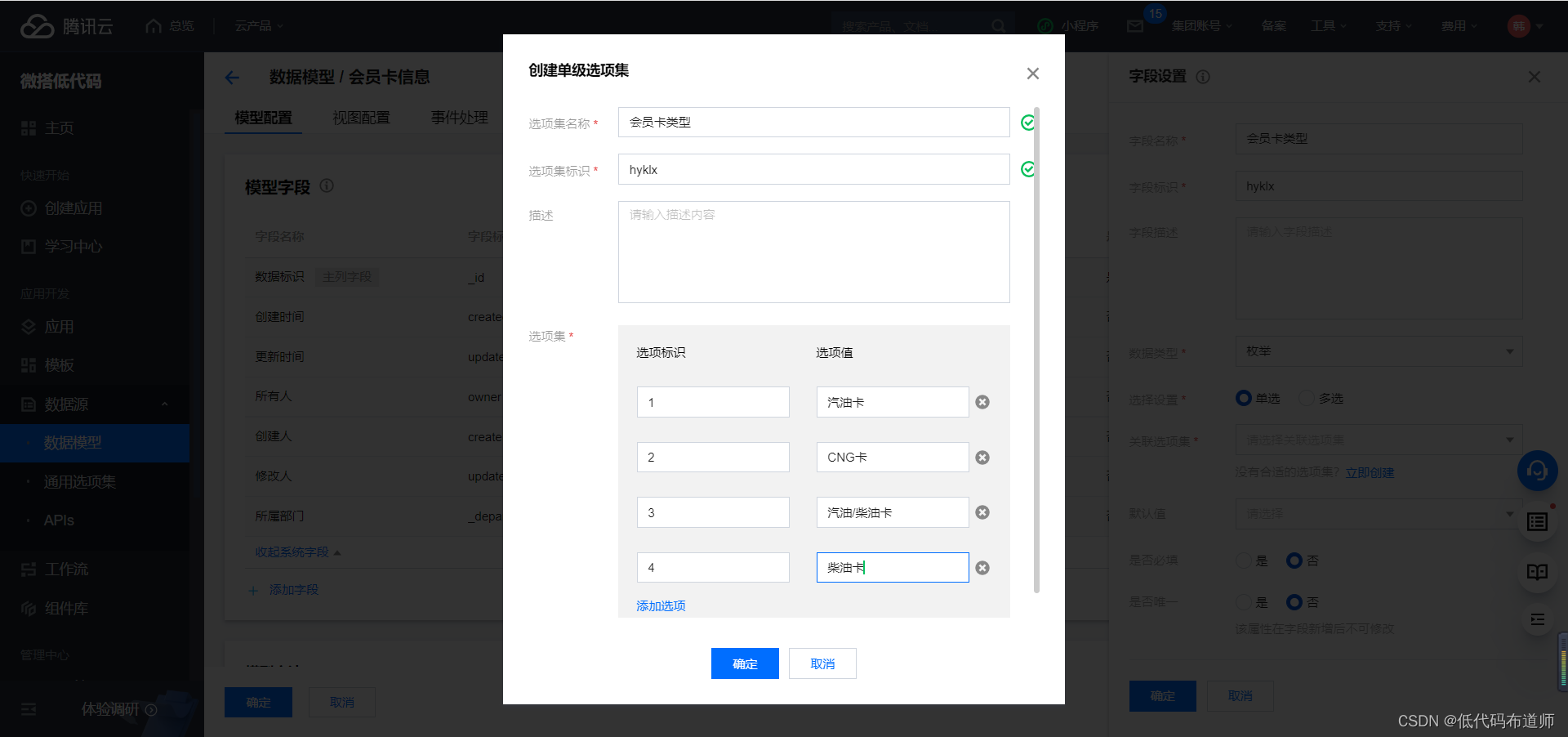
加油站会员管理小程序实战开发教程13
我们上一篇讲解了会员注册的功能,本篇我们介绍一下会员开卡的功能。 会员注册之后,可以进行开卡的动作。一个会员可以有多张会员卡,在微搭中用来描述这种一对多的关系的,我们用关联关系来表达。 登录微搭的控制台,点击数据模型,点击新建数据模型 输入数据源的名称会员卡…...
Go语言Web入门之浅谈Gin框架
Gin框架Gin简介第一个Gin示例HelloworldRESTful APIGin返回数据的几种格式Gin 获取参数HTTP重定向Gin路由&路由组Gin框架当中的中间件Gin简介 Gin 是一个用 Go (Golang) 编写的 web 框架。它是一个类似于 martini 但拥有更好性能的 API 框架,由于 httprouter&a…...
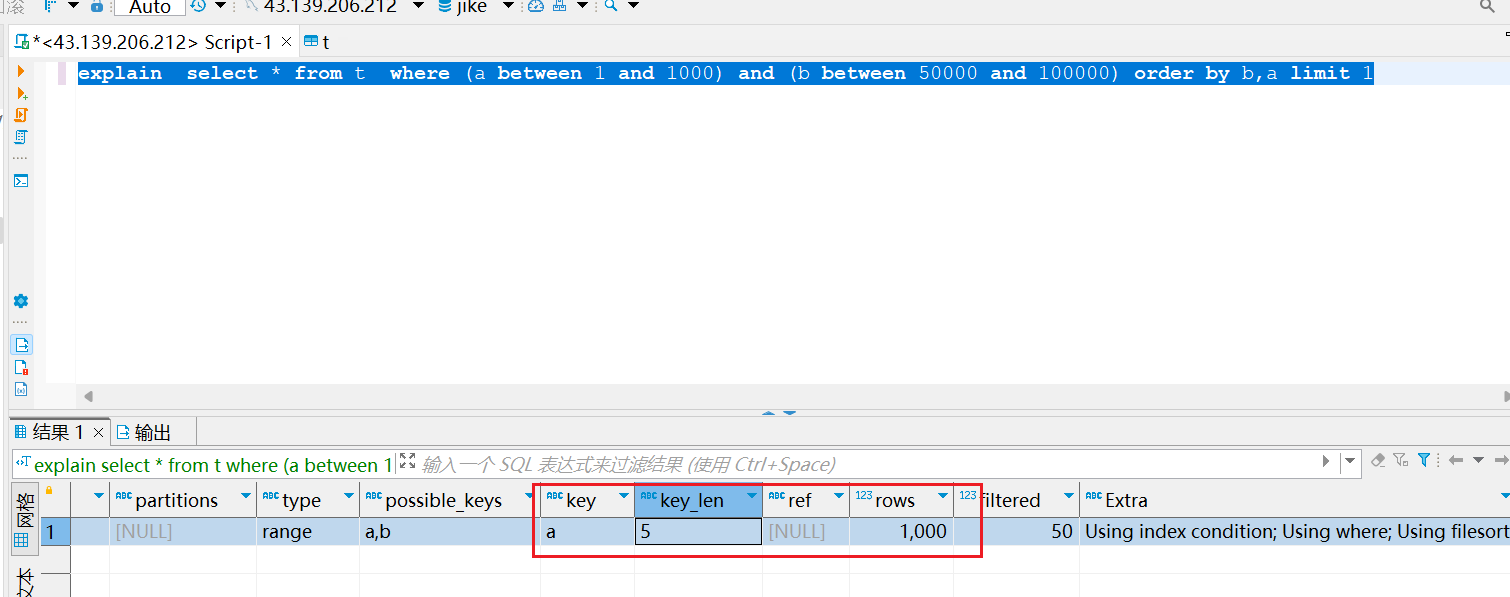
《MySQL学习》 MySQL优化器选择如何选择索引
一.优化器的选择逻辑 建表语句 CREATE TABLE t (id int(11) NOT NULL AUTO_INCREMENT,a int(11) DEFAULT NULL,b int(11) DEFAULT NULL,PRIMARY KEY (id),KEY a (a),KEY b (b) ) ENGINEInnoDB;往表中插入10W条数据 delimiter ;; create procedure idata() begindeclare i in…...
uniapp 悬浮窗(应用内、无需授权) Ba-FloatWindow2
简介(下载地址) Ba-FloatWindow2 是一款应用内并且无需授权的悬浮窗插件。支持多种拖动;自定义位置、大小;支持动态修改。 支持自动定义起始位置支持自定义悬浮窗大小支持贴边显示支持多种拖动方效果:不可拖动、任意…...
MMKV与mmap:全方位解析
概述 MMKV 是基于 mmap 内存映射的移动端通用 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今,在 iOS 微信上使用已有近 3 年,其性能和稳定性经过了时间的验证。近期已移植…...
)
【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度)
【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度) 【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度)【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度ÿ…...

一起学 pixijs(3):Sprite
大家好,我是前端西瓜哥。今天来学习 pixijs 的 Sprite。 Sprite pixijs 的 Sprite 类用于将一些纹理(Texture)渲染到屏幕上。 Sprite 直译为 “精灵”,是游戏开发中常见的术语,就是将一个角色的多个动作放到一个图片…...

深入讲解Kubernetes架构-垃圾收集
垃圾收集(Garbage Collection)是 Kubernetes 用于清理集群资源的各种机制的统称。 垃圾收集允许系统清理如下资源:终止的 Pod已完成的 Job不再存在属主引用的对象未使用的容器和容器镜像动态制备的、StorageClass 回收策略为 Delete 的 PV 卷…...
Flink03: 集群安装部署
Flink支持多种安装部署方式 StandaloneON YARNMesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境下一般还是用on yarn 这种模式比较多,因为这样可以综合利…...
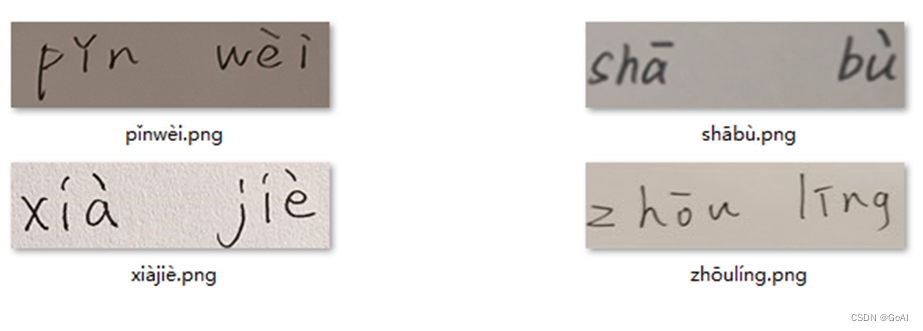
OCR项目实战(一):手写汉语拼音识别(Pytorch版)
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。 📝OCR专栏…...

【js】export default也在影响项目性能呢
这里写目录标题介绍先说结论分析解决介绍 无意间看到一个关于export与exprot default对比的话题, 于是对二者关于性能方面,有了想法,二者的区别,仅仅是在于写法吗? 于是,有了下面的测试。 先说结论 太长…...

《软件安全》 彭国军 阅读总结
对于本书,小编本意是对其讲述的内容,分点进行笔记的整理,后来学习以后,发现,这本书应该不算是一本技术提升类的书籍,更像是一本领域拓展和知识科普类书籍,所讲知识广泛,但是较少实践…...

深入讲解Kubernetes架构-节点与控制面之间的通信
本文列举控制面节点(确切说是 API 服务器)和 Kubernetes 集群之间的通信路径。 目的是为了让用户能够自定义他们的安装,以实现对网络配置的加固, 使得集群能够在不可信的网络上(或者在一个云服务商完全公开的 IP 上&am…...

Vibeproxy:轻量级可编程HTTP代理,实现API Mock与故障注入
1. 项目概述:一个轻量级的HTTP代理工具最近在折腾一些需要模拟不同网络环境或者进行API测试的项目时,我一直在寻找一个足够轻量、灵活且易于集成的HTTP代理工具。市面上成熟的代理方案很多,但要么功能过于臃肿,要么配置起来相当繁…...

告别虚拟机卡顿:在 Windows WSL2 的 Kali 子系统中配置 Pwn 调试环境
告别虚拟机卡顿:在 Windows WSL2 的 Kali 子系统中配置 Pwn 调试环境 对于安全研究人员和 CTF 爱好者来说,Kali Linux 是必不可少的工具集。然而,传统的虚拟机方案常常面临性能瓶颈——内存占用高、启动速度慢、与主机系统交互不便。WSL2 的出…...

量子计算中的辛基理论与MBQC实现
1. 量子计算中的辛基基础概念在量子计算领域,辛基(Symplectic Basis)是描述多量子比特系统的重要数学工具。它本质上是一个满足特定对易关系的基组,能够简洁地表示量子态和量子操作。理解辛基需要从有限域上的向量空间开始——具体…...

工业级加密漏洞检测工具Cryptoscope解析
1. Cryptoscope:工业级加密漏洞检测工具解析在软件开发领域,加密技术的正确使用一直是个棘手问题。我见过太多项目因为加密实现不当导致数据泄露——有的使用了已被证明不安全的算法,有的密钥管理存在严重缺陷,还有的甚至把加密密…...

Axure RP中文界面汉化终极指南:3分钟免费切换,让原型设计更高效
Axure RP中文界面汉化终极指南:3分钟免费切换,让原型设计更高效 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-c…...

明日方舟素材库:从游戏资产到创意引擎的技术解密
明日方舟素材库:从游戏资产到创意引擎的技术解密 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 在数字创作的广阔天地中,专业级游戏素材往往被锁在商业游戏的围…...

Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线
Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task 在当今的机器学习开发中&#x…...

AISuperDomain:轻量级AI服务域名映射系统,简化多服务配置管理
1. 项目概述:一个面向AI应用的超级域名系统最近在折腾一些AI应用部署和集成的时候,我遇到了一个挺有意思的项目,叫AISuperDomain。乍一看这个名字,可能会让人联想到某种“万能域名”或者“AI域名服务商”,但实际上&…...

5分钟快速上手GSE:魔兽世界智能技能循环终极指南
5分钟快速上手GSE:魔兽世界智能技能循环终极指南 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compiler …...

避坑指南:用MOT17训练YOLOv7检测器时,为什么你的mAP上不去?可能是数据划分的锅
MOT17数据集划分陷阱:为什么你的YOLOv7检测器性能不达标? 当你在MOT17数据集上训练YOLOv7检测器时,是否遇到过这样的困境:损失曲线看起来完美,训练集准确率节节攀升,但验证集mAP却始终徘徊在低水平…...