百日筑基篇——python爬虫学习(一)
百日筑基篇——python爬虫学习(一)
文章目录
- 前言
- 一、python爬虫介绍
- 二、URL管理器
- 三、所需基础模块的介绍
- 1. requests
- 2. BeautifulSoup
- 1. HTML介绍
- 2. 网页解析器
- 四、实操
- 1. 代码展示
- 2. 代码解释
- 1. 将大文件划分为小的文件(根据AA的ID数量划分)
- 2. 获得结果页面的url
- 3. 获取结果页面,提取出所需信息
- 4. 文件合并操作
- 总结
前言
随着学习的深入,有关从各种不同的数据库中以及互联网上的海量信息,如何有选择性的爬取我们所需的数据以方便我们的数据分析工作,爬虫的学习是必要的。
一、python爬虫介绍
Python爬虫是指使用Python编程语言编写的程序,通过模拟浏览器行为从网页中提取数据的过程
主要用途包括:
-
数据采集:通过爬虫可以从互联网上收集大量的数据,如新闻、论坛帖子、商品信息等。
-
数据分析:爬虫可以获取特定网站或多个网站的数据,进行统计和分析。
-
自动化测试:爬虫可以模拟用户行为,自动化地访问网站,并检查网站的功能、性能等。
-
内容聚合:通过爬虫可以自动化地从多个网站上获取信息,并将其聚合成为一个平台,方便用户浏览。
二、URL管理器
是指对爬取URL进行管理,防止重复和循环爬取,方便新增URL和取出URL。
class UrlManager():"""url管理器"""def __init__(self):self.new_urls = set()self.old_urls = set()def add_newurl(self,url):if url is None or len(url) == 0:returnif url in self.new_urls or url in self.old_urls:returnself.new_urls.add(url)def add_newurls(self,urls):if urls is None or len(urls) == 0:returnfor url in urls:self.add_newurl(url)def get_url(self):if self.has_newurl():url = self.new_urls.pop()self.old_urls.add(url)return urlelse:return Nonedef has_newurl(self):return len(self.new_urls) > 0该类中创建了两个集合:new_urls和 old_urls ,分别表示新增url和已爬取完的url的存储集合。
定义了四个方法,
- add_newurl(self, url): 添加新的URL到new_urls集合中。如果URL为空或已经存在于new_urls或old_urls中,则不添加。
- add_newurls(self, urls): 批量添加URL到new_urls集合中。如果URL为空,则不添加。
- get_url(self): 从new_urls中获取一个未爬取的URL,将其移动到old_urls集合中,并返回该URL。如果new_urls为空,则返回None。
- has_newurl(self): 判断是否还有未爬取的URL。返回new_urls集合的长度是否大于0。
三、所需基础模块的介绍
1. requests
用于发送HTTP请求,并获取网页内容。
import requests
requests.post(url=,params=,data=,headers=,timeout=,verify=,allow_redirects=,cookies=)
#里面的参数依次代表请求的URL、查询参数、请求数据、请求头、超时时间、SSL证书验证、重定向处理和Cookies。url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"r = requests.post(url)
#查看状态码,200为请求成功
print(r.status_code)#查看当前编码,以及改变编码
print(r.encoding)
r.encoding = "utf-8"
print(r.encoding)#查看返回的网页内容
print(r.text)#查看返回的http的请求头
print(r.headers)#查看实际返回的URL
print(r.url)#以字节的方式返回内容
print(r.content)#查看服务端写入本地的cookies数据
print(r.cookies)2. BeautifulSoup
用于解析HTML或XML等文档,提取所需的数据。
1. HTML介绍
HTML指的是超文本标记语言,一种用于创建网页结构的标记语言。它由一系列的元素(标签)组成,通过标签来描述网页中的内容和结构。
HTML标签:
是由< >包围的关键词,标签通常成对出现,且标签对中的第一个标签是开始标签,第二个则是结束标签,如下图所示:
在HTML语言中,标签中一般伴随着属性,比如:”id、class、herf等"
2. 网页解析器
导入 BeautifulSoup 模块
解析的一般步骤是:
- 得到HTML网页的文本
- 创建BeautifulSoup对象
- 搜索节点 (使用find_all或 find,前者返回满足条件的所有节点,后者返回第一个)
- 访问节点 (名称、属性、文字等)
示例代码如下:
base_url = "https://wolfpsort.hgc.jp/"from bs4 import BeautifulSoupwith open("D:\python\PycharmProjects\pythonProject1\pachou\linshi.html", "r", encoding="utf-8") as f:html_doc = f.read()soup = BeautifulSoup(html_doc, # HTML文档字符串"html.parser", # 解析器
)#可以分区
div_node = soup.find("div",id ="content")
links= div_node.find_all("a")# links = soup.find_all("a")
for link in links:print(link.name,base_url+link["href"],link.get_text())imgs = soup.find_all("img")
for img in imgs:print(base_url+img["src"])
这是一个基于wolfpsort网页的页面内容的爬取,根据该网页的HTML文本,可以通过标签以及属性的设置,来获得我们所需的指定的节点,再获取节点中的内容,如"herf"等
四、实操
1. 代码展示
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
import os
import pandas as pddef split_gene_file(source_file, output_folder, ids_per_file):os.makedirs(output_folder, exist_ok=True)current_file = Nonecount = 0with open(source_file, "r") as f:for line in f:if line.startswith(">"):count += 1if count % ids_per_file == 1:if current_file:current_file.close()output_file = f"{output_folder}/gene_file_{count // ids_per_file + 1}.csv"current_file = open(output_file, "w", encoding='utf-8')current_file.write(line)else:current_file.write(line)if current_file:current_file.close()split_gene_file("D:\yuceji\Lindera_aggregata.gene.pep", "gene1", 500)files = os.listdir("D:\python\PycharmProjects\pythonProject1\pachou\gene1")result_urls = []for i in range(0, 4): #可自行设置所需文件数# 设置WebDriver路径,启动浏览器driver = webdriver.Edge()# 打开网页url = "https://wolfpsort.hgc.jp/"driver.get(url)time.sleep(5)wuzhong_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[1]/input[2]')wuzhong_type.click()wenjian_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[2]/input[2]')wenjian_type.click()input_element = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[3]/input')input_element.send_keys(f"D:\python\PycharmProjects\pythonProject1\pachou\gene1\gene_file_{i + 1}.csv")time.sleep(10)# 提交表单submit_button = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[2]/td/p/input[1]')submit_button.click()time.sleep(30)with open("result_urls","a",encoding="utf-8") as f:# 获取结果页面的URLresult_url = driver.current_urlf.write(result_url+ "\n")# 输出结果页面的URLprint(result_url)result_urls.append(result_url)# 关闭浏览器driver.quit()for i in range(len(result_urls)):r = requests.get(result_urls[i])print(r.status_code)text = r.textlines = text.split("<BR>")AA_ID_list = []yaxibao_list = []for line in lines:if "details" in line:AA_ID = line.split("<A")[0].strip().split()[-1]yaxibao = line.split("details")[1].strip().split()[1][:-1]AA_ID_list.append(AA_ID)yaxibao_list.append(yaxibao)with open(fr"D:\python\PycharmProjects\pythonProject1\pachou\result_dir\yaxibao{i}.csv", "w", encoding="utf-8") as f:f.write("AA_ID, yaxibao\n") # 写入列名for j in range(len(AA_ID_list)):f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")print(result_urls)# 再将所有的结果文件合并为一个大文件
result_csv = r"D:\python\PycharmProjects\pythonProject1\pachou\result_dir"
# 获取结果文件列表
result_files = os.listdir(result_csv)[:-1]
print(result_files)
# 创建一个空的DataFrame用于存储合并后的结果
merged_data = pd.DataFrame()
# 遍历每个结果文件
for file in result_files:# 读取结果文件df = pd.read_csv(result_csv + "\\" + file)#print(df)# 将结果文件的数据添加到合并后的DataFrame中merged_data = pd.concat([merged_data, df])
#print(merged_data)
# 保存合并后的结果到一个大文件
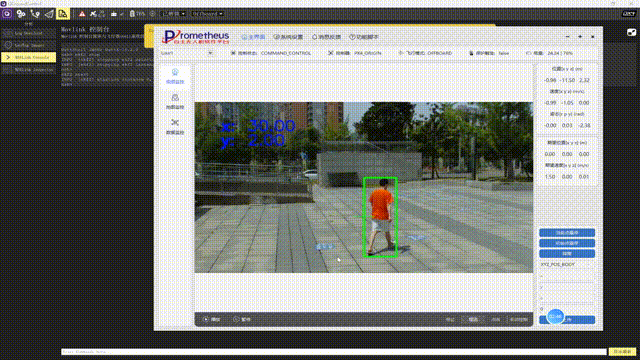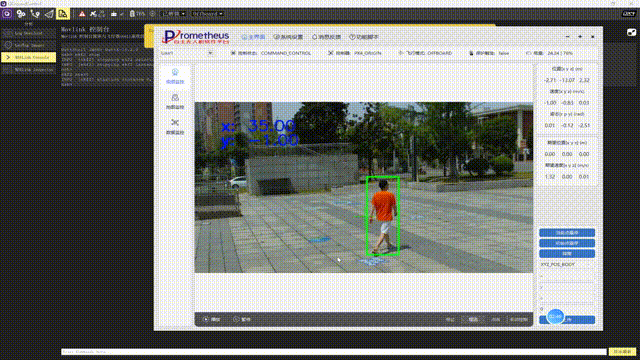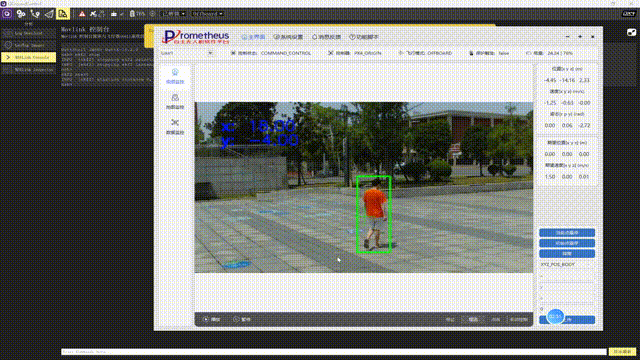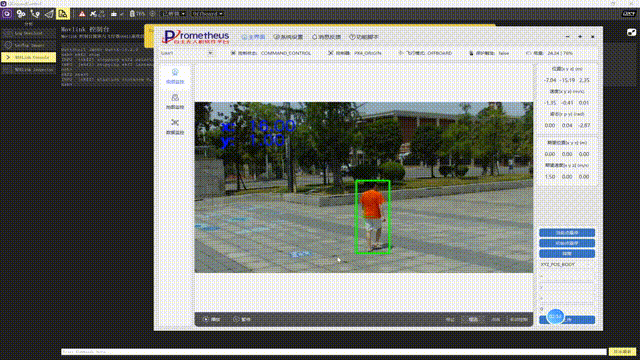
merged_data.to_csv("merged_results.csv", index=False)我运行了这个代码,遍历前面四个文件,发现都很好的得到了结果页面的URL。说明这个代码是可行的。
2. 代码解释
这个代码差不多可以分为四个部分:
- 将大文件划分为小的文件
- 使用selenium库进行模拟用户行为,以获得结果页面的url
- 使用requests模块,通过上一步获得的url,发送请求,获取结果页面,并提取出所需信息
- 文件合并操作,使用pandas库中的concat方法,将前面得到的众多小文件的结果整合到一个大文件中。
1. 将大文件划分为小的文件(根据AA的ID数量划分)
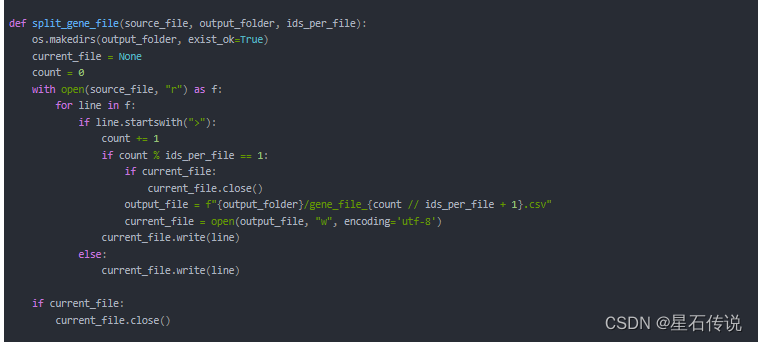
- 定义一个split_gene_file()函数,其中"ids_per_file"参数表示指定每个文件中的ID数
- 创建一个存储文件的文件夹
- 使用with语句打开源文件,并且遍历文件中的每一行,之后使用if语句判断当前行是否是有ID的行,如果不是,就直接将当前行写入当前文件(current_file);如果是,就将count(表示已读取到的ID数)的数加上1,然后再判断已读取的ID数量是否达到了自己指定的每个文件的ID数量,如果达到了,就表示需要创建一个新的输出文件output_file, 并将文件对象赋值给current_file变量,使用"w"模式表示以写入模式打开文件,并将当前行写入当前文件。
- 在处理完源文件后,检查是否存在当前正在写入的文件对象。如果是,则关闭该文件。
2. 获得结果页面的url
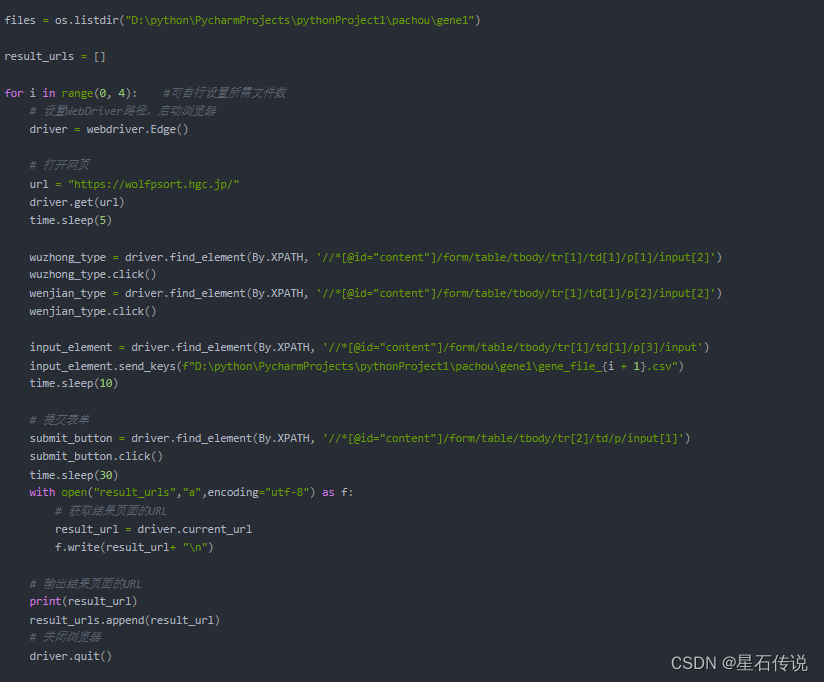
这是基于python的selenium库,
Selenium是一个用于Web自动化的工具,可以用于模拟用户在网页浏览器上的行为,包括点击、输入、提交表单等操作。
其中最主要的步骤还是查看官网页面的源代码,通过HTML文本的标签获取元素的定位。
例如:
我要查看”Please select an organism type:" ,可以右键单击,然后点击检查
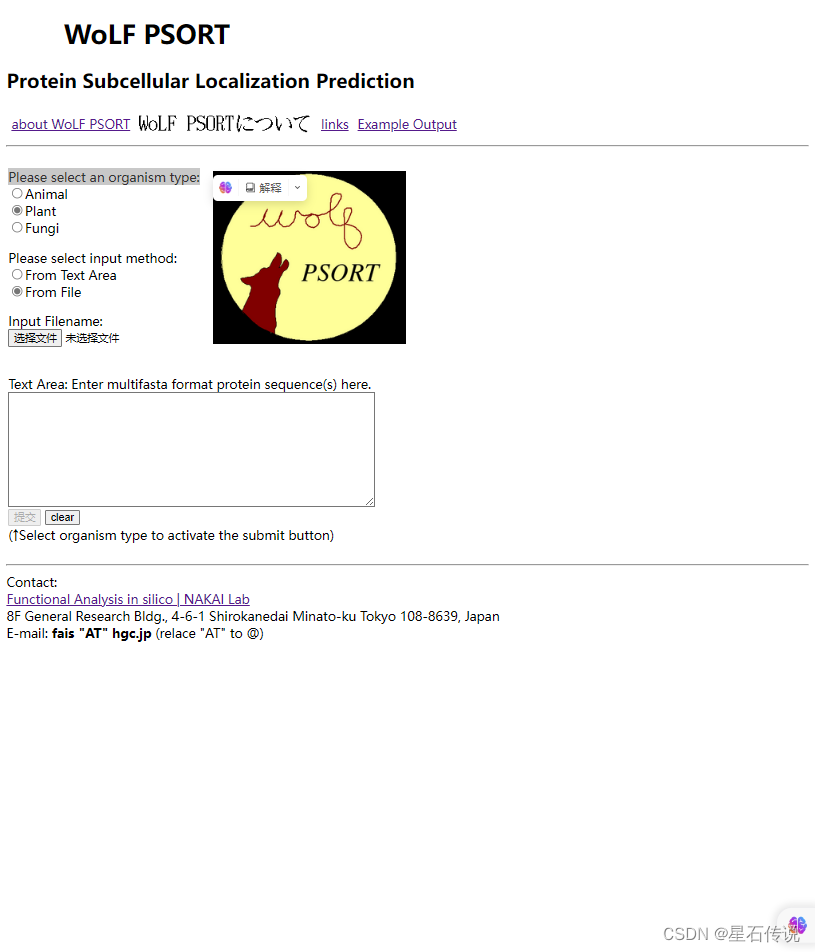
得到有关信息:
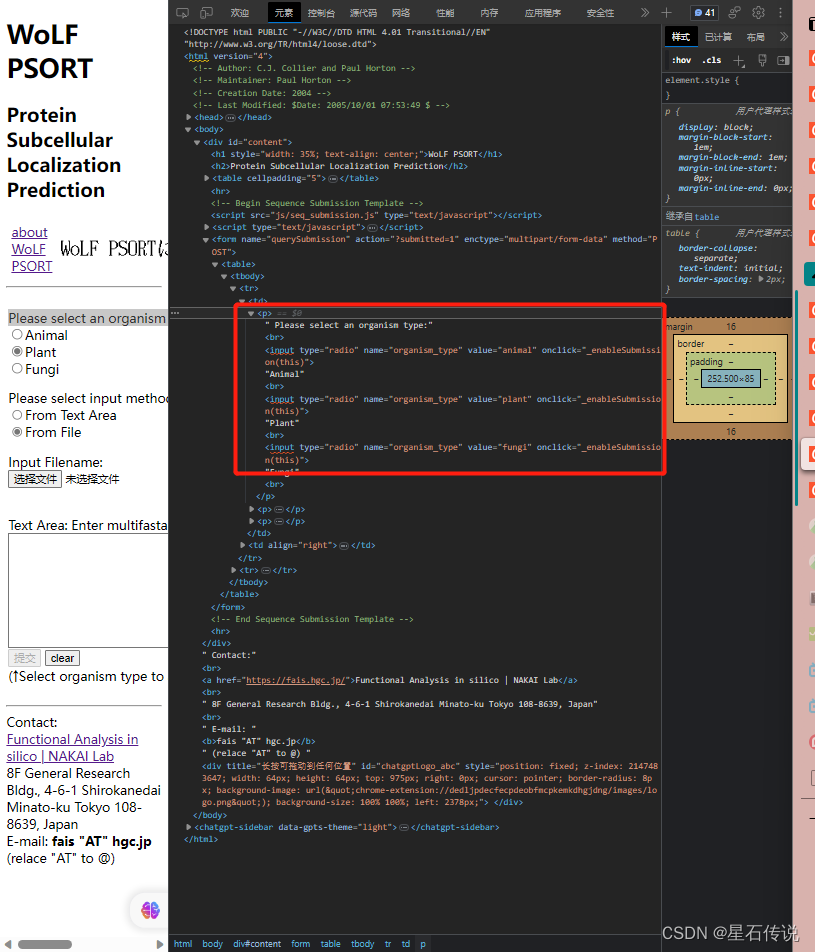
比如我在”Please select an organism type:“框中想选择"Plant”,那么我只要选择上图红框中表示输入是"plant"的框就行,然后再右键选择复制 “Xpath”
之后再将复制的Xpath粘贴到函数中,充当参数,如下所示:
wuzhong_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[1]/input[2]')
因为在这个定位元素函数中,我第一个参数填的是“By.XPATH”,故后面那个参数就便是元素的“Xpath”。
3. 获取结果页面,提取出所需信息
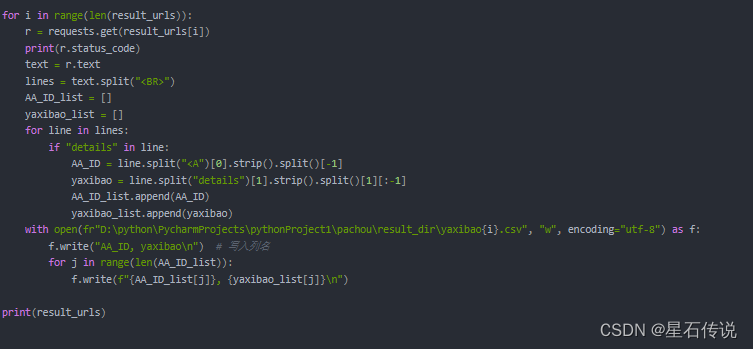
对前面得到的URL列表(result_urls)进行循环遍历,并将得到的结果保存于指定文件中
4. 文件合并操作

前面得到的结果文件是通过循环得到的,故会是众多小文件。若是欲将所有的结果信息合并于一个大文件中,可以使用pandas库中的concat方法,来合并文件,最后将循环完毕后的合并结果,保存为一个csv文件。
总结
本章主要简述了python爬虫的有关信息,并且进行了一个实操(这个爬虫是基于WoLF PSORT官网,爬取亚细胞定位结果的数据)。更多有关蛋白质亚细胞定位的信息,请看
亚细胞定位
零落成泥碾作尘,只有香如故。
–2023-8-13 筑基篇
相关文章:
百日筑基篇——python爬虫学习(一)
百日筑基篇——python爬虫学习(一) 文章目录 前言一、python爬虫介绍二、URL管理器三、所需基础模块的介绍1. requests2. BeautifulSoup1. HTML介绍2. 网页解析器 四、实操1. 代码展示2. 代码解释1. 将大文件划分为小的文件(根据AA的ID数量划…...
【Spring专题】Spring之底层架构核心概念解析
目录 前言前置知识课程内容一、BeanDefinition:图纸二、BeanDefinitionReader:图纸注册器——Spring工厂基础设施之一2.1 AnnotatedBeanDefinitionReader2.2 XmlBeanDefinitionReader2.3 ClassPathBeanDefinitionScanner基本介绍总结使用示例 三、BeanFa…...

electron 使用node C++插件 node-gyp
node C插件使用,在我们常规使用中,需要使用node-gyp指定对饮的node版本即可 在electron的使用中,我们需要指定的是electron版本要不然会报错使用的v8内核版本不一致导致C扩展无法正常引入 electron官方文档-node原生模块 package.json {&quo…...
)
学习Vue:使用条件渲染指令(v-if,v-else,v-show)
在 Vue.js 中,条件与循环是实现动态交互界面的关键要素。通过使用条件渲染指令,您可以根据不同的条件决定是否显示或隐藏特定的内容。在本文中,我们将介绍三个常用的条件渲染指令:v-if、v-else 和 v-show,以及它们的用…...

【图像去噪的滤波器】非局部均值滤波器的实现,用于鲁棒的图像去噪研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Redis辅助功能
一、Redis队列 1.1、订阅 subscribe ch1 ch2 1.2 publish:发布消息 publish channel message 1.3 unsubscribe: 退订 channel 1.4 模式匹配 psubscribe ch* 模糊发布,订阅,退订, p* <channelName> 1.5 发布订阅原理 订阅某个频道或…...
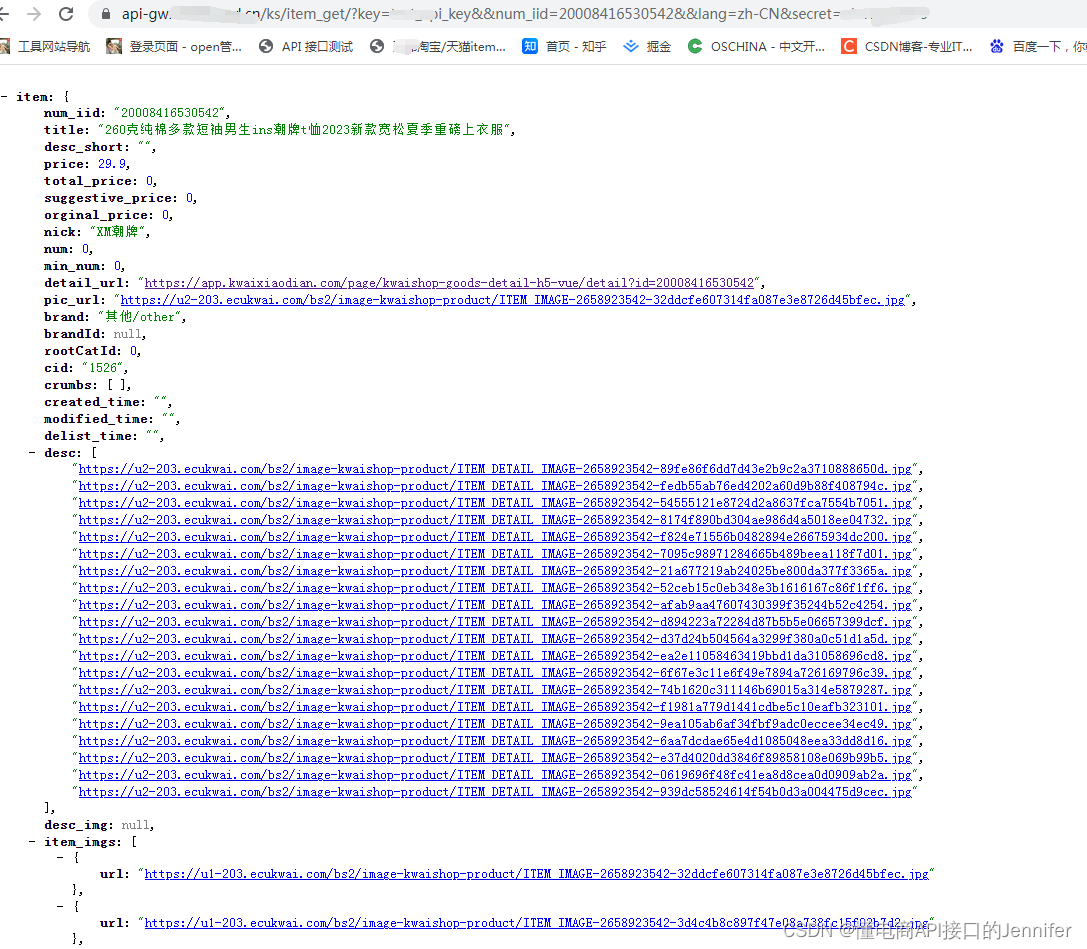
快手商品详情数据API 抓取快手商品价格、销量、库存、sku信息
快手商品详情数据API是用来获取快手商品详情页数据的接口,请求参数为商品ID,这是每个商品唯一性的标识。返回参数有商品标题、商品标题、商品简介、价格、掌柜昵称、库存、宝贝链接、宝贝图片、商品SKU等。 接口名称:item_get 公共参数 名…...

linux系统部署jenkins详细教程
一、Linux环境 1、下载war包 官网下载地址: https://get.jenkins.io/war-stable/2.332.4/jenkins.war 2、将war包上传至服务器 创建目录/home/ubuntu/jenkins 上传war包至该目录 3、将jenkins添加到环境变量 进入环境变量文件 vim /etc/profile # 文件下方追加…...
)
Arduino驱动BME680环境传感器(环境传感器篇)
目录 1、传感器特性 2、硬件原理图 3、控制器和传感器连线图 4、驱动程序...
领航未来!探索开源无人机与5G组网的前沿技术
近年来无人机行业高速发展,无人机被广泛应用于航拍、农业、电力、消防、科研等领域。随着无人机市场不断增长,其对实时超高清图传、远程低时延控制、海量数据处理等需求也在不断扩张,这无疑给通信链路带来了巨大的挑战。 为应对未来的需求变…...

分布式事务CAP与BASE简介
一、CAP理论 CAP理论是由Eric Brewer教授在2000年举⾏的ACM研讨会上提出的⼀个著名猜想:⼀致性(Consistency)、可⽤性(Availability)、分区容错(Partition-tolerance),并且在分布式系…...
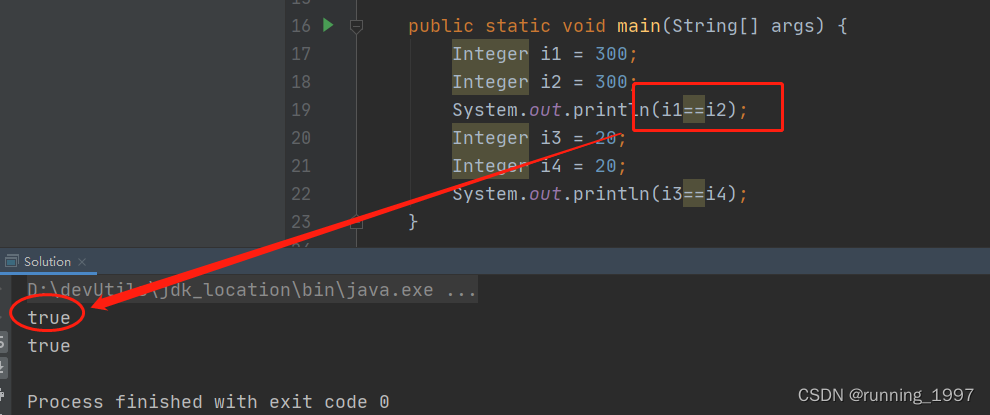
Integer中缓存池讲解
文章目录 一、简介二、实现原理三、修改缓存范围 一、简介 Integer缓存池是一种优化技术,用于提高整数对象的重用和性能。在Java中,对于整数值在 -128 到 127 之间的整数对象,会被放入缓存池中,以便重复使用。这是因为在这个范围…...

PHP Smarty模板如何与MVC框架集成?
首先,让我们来了解一下这两个工具。PHP Smarty模板是一种模板引擎,它可以帮助我们分离模板和逻辑,让代码更加清晰和易于维护。而MVC(Model-View-Controller)是一种常用的Web应用程序架构模式,它将应用程序分…...

spring cloud alibaba 应用无法注册到sentinel dashboard
一。技术背景 由于升级jdk17的需要 我们将项目中的 spring cloud spring cloud alibaba 以及springboot进行了升级 各版本如下 spring cloud 2021.0.5 spring cloud alibaba 2021.0.5.0 spring boot 2.6.13 二。问题表现 当启动项目服务后,服务无法注册到 sentin…...

如何在vue3中加入markdown语法
1、首先需要安装 md-editor-v3 yarn add md-editor-v3 或者是在vue图形化界面中直接搜索 md-editor-v3 进行安装。 2、引入该编辑页 引入可以参考这个,根据自己的需求进行修改和添加。 <template><md-editor v-model"text"/> </templat…...
R语言的物种气候生态位动态量化与分布特征模拟实践技术
在全球气候快速变化的背景下,理解并预测生物种群如何应对气候变化,特别是它们的地理分布如何变化,已经变得至关重要。利用R语言进行物种气候生态位动态量化与分布特征模拟,不仅可以量化描述物种对环境的需求和适应性,预…...

大数据Flink(六十一):Flink流处理程序流程和项目准备
文章目录 Flink流处理程序流程和项目准备 一、Flink流处理程序的一般流程...

C语言快速回顾(一)
前言 在Android音视频开发中,网上知识点过于零碎,自学起来难度非常大,不过音视频大牛Jhuster提出了《Android 音视频从入门到提高 - 任务列表》,结合我自己的工作学习经历,我准备写一个音视频系列blog。C/C是音视频必…...

Element Plus报错:ResizeObserver loop completed with undelivered notifications.
el-selected踩坑:el-selected 显示下拉框 mouseover 时报错!!! 原来是属性 popper-append-to-body 被废除,改为 teleported。 element ui <el-select:popper-append-to-body"false"value-key"id&q…...
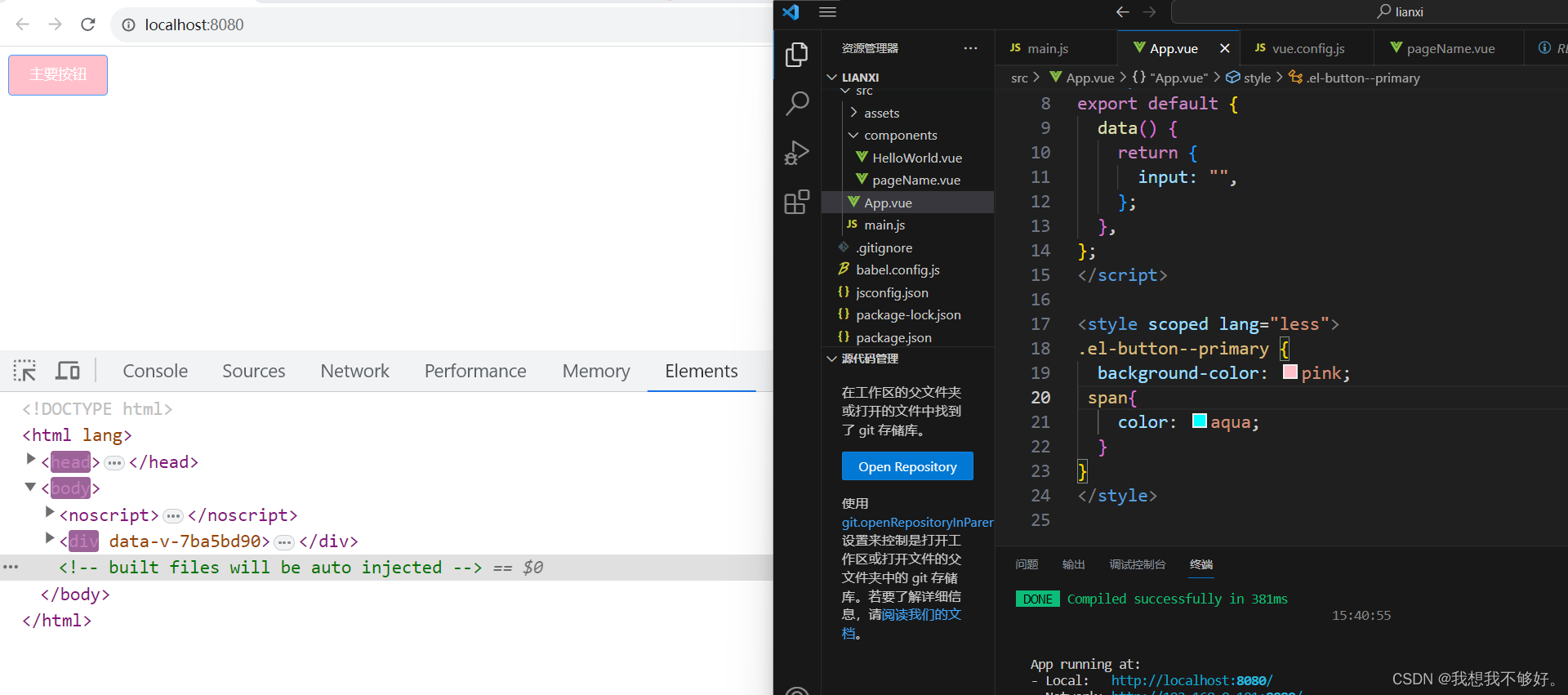
scope穿透(二)
上篇文章已经讲了,如何穿透样式,今天我们进入element-ui官网进行大规模的穿透处理。 1.输入框 <template><div class""><el-input v-model"input" placeholder"请输入内容"></el-input></div> </template>…...

对比直接使用厂商API体验Taotoken在用量监控方面的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken在用量监控方面的便利性 在直接调用多个大模型厂商的API进行开发时,一个普遍存在的管…...

戴森球计划工厂蓝图宝典:5000+免费设计助你轻松建设星际工厂
戴森球计划工厂蓝图宝典:5000免费设计助你轻松建设星际工厂 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为戴森球计划中复杂的工厂布局头疼吗࿱…...

为什么公平感比财富本身更影响希望
有些时刻,普通人最难受的不是自己暂时没钱。而是你发现,自己已经很努力地排队、提交材料、遵守规则、等待结果,可最后还是不知道机会到底怎么分配。 孩子上学,要反复比较资源差异。 老人看病,要担心排队、费用和后续照…...

ASP.NET Core 分层设计实践拒绝胖Controller
Controller 是 API 的入口,理论上应该只做三件事:接收请求、调用下层、返回响应。但在实际项目中,不少开发者会把用户校验、金额判断、业务限制条件直接写进 Controller Action,久而久之就成了所谓的"胖 Controller"。 这不只是代码整洁的问题。业务规则一旦耦合…...

从一道SWPUCTF题复盘PHP文件包含漏洞:allow_url_include开启后,除了伪协议还能怎么玩?
从SWPUCTF赛题探索PHP文件包含漏洞的深层攻防 在CTF竞赛和实际渗透测试中,PHP文件包含漏洞一直是Web安全领域的重要课题。这道来自SWPUCTF新生赛的题目看似简单,却蕴含了丰富的攻防对抗思路。当allow_url_include配置被开启时,攻击面会显著扩…...

在Taotoken模型广场中根据任务与预算选择合适的AI模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场中根据任务与预算选择合适的AI模型 当你准备将大模型能力集成到自己的应用或工作流中时,面对市场上…...

Meet Composer:基于控制原语的分层可控文生图架构
1. 项目概述:Meet Composer不是又一个“画图玩具”,而是控制力重构的起点最近在整理一批国产多模态模型的技术简报时,Meet Composer这个名字反复跳出来——不是因为它的宣传声量最大,而是因为它在技术文档里反复强调一个被多数人忽…...
)
捡垃圾实战:让ESXi 7.0 U3识别老古董Mellanox ConnectX-2 10G网卡(附驱动修改全流程)
老硬件焕新:ESXi 7.0 U3下Mellanox ConnectX-2网卡驱动改造指南 在二手市场以几十元价格淘到的Mellanox ConnectX-2 10G双口网卡,性能依然强劲,却因为官方停止支持而无法在现代虚拟化平台上使用。本文将带你深入探索如何通过驱动改造…...
)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程) 当一块崭新的ESP32开发板躺在桌面上时,许多开发者会陷入两难:既渴望体验这款低功耗Wi-Fi/蓝牙双模芯片的强大性能,又对繁琐的环境配置望而…...

远程办公时代,如何防止公司机密被截屏泄露?
远程办公已经成为很多企业的常态,但随之而来的信息安全问题也日益突出。其中,截屏泄露是最常见也最难防范的一种。员工可以轻易地将聊天记录、文件内容截屏保存,然后转发给他人,而企业却很难察觉和追踪。【图片1】 传统的防截屏方…...