Python 装饰器 - 推导式(列表推导式) - 迭代器 - 生成器 - 闭包
目录
推导式
1、列表推导式(用得最多的)
给你一个列表,求所有数据的绝对值
列表推导式跟if运算
打印50以内能被3整除的数的平方(filter)(if的使用)
找到1000以内开平方的结果是整数的数(if的使用)
打印50以内如果被2整除的数的平方,否则打印自己(map)(if和else的使用)
打印名字中包含g的数据(双重for循环)
将二维数组转一维数据(双重for循环)
二维转一维,将名字包含g的数据直接输出,不包含g的数据转大写输出
2、集合推导式(在列表推导式的基础上去重) => set
3、字典推导式 => dict
构建一个字典: {'a':1,"b":2,"c":3,"d":4........."z":26}
迭代器
可迭代对象: 实现了__iter__方法,并且该方法返回一个迭代器
可以使用dir查看是否实现了__iter__方法,即可判断是否为可迭代对象
迭代器
判断是否为迭代器,或者是可迭代对象
可迭代对象 和 迭代器的区别:
迭代器实现列表内数据的平方
map函数使用了惰性求值的特点(map就是迭代器)
实现一个迭代器(类似range函数的迭代器=>返回0到num的数据)
实现一个可以无限生成的斐波拉契数列的迭代器
生成器:
生成器表达式:(返回的数据 for 临时变量 in 可迭代对象)
生成器函数:如果一个函数中包含了yield关键字,它是一个生成器函数
使用生成器函数 --》 创建了一个生成器:g (g = func_g())
用生成器函数实现,传递给函数一下列表,返回列表中每个元素的平方
生成器yield 和 yield from返回数据的区别
闭包:
什么是闭包?
闭包形成的条件
闭包的特点
闭包函数
装饰器:
例子:希望获取每一个函数运行时候的耗时
用装饰器来实现给函数添加记录运行时间的功能(runtime装饰器)
实现加记日志的功能:如函数XXX被调用了(log装饰器)
一个函数可以使用多个装饰器(多重装饰器)
模块化拆分装饰器:
创建 utils.py 文件,将我们的runtime和log装饰器写入文件中:
然后我们在父文件中调用 utils.py 文件中的装饰器
装饰器可以装饰普通的函数、也可以用来装饰类
作业:
推导式
# 列表推导式(用得最多的)
# 字典推导式
# 集合推导式
1、列表推导式(用得最多的)
li1 = [1,2,3,4]
# [返回值 for 临时变量 in 可迭代对象]
result = [x*x for x in li1]
print(type(result), result)# map和列表推导式都可以做到
# map => map object
# 列表推导式 => list输出:
<class 'list'> [1, 4, 9, 16]给你一个列表,求所有数据的绝对值
# 给你一个列表,求所有数据的绝对值
li2 = [1,2 ,-1, 4, 6, -4]
result = [abs(x) for x in li2 ]
print(result)输出:
[1, 2, 1, 4, 6, 4]列表推导式跟if运算
打印50以内能被3整除的数的平方(filter)(if的使用)
result = [x**2 for x in range(1,50) if x%3 == 0]
print(result)找到1000以内开平方的结果是整数的数(if的使用)
result = [x for x in range(1,1000) if x**0.5%1==0 ]
print(result)打印50以内如果被2整除的数的平方,否则打印自己(map)(if和else的使用)
result = [x**2 if x%2 == 0 else x for x in range(1,50) ]
print(result)打印名字中包含g的数据(双重for循环)
names = [['asdf', 'ag'],['abg', 'abc'],
]
result = [name for lst in names for name in lst if 'g' in name]
print(result)
将二维数组转一维数据(双重for循环)
li = [[1,2,3,4],[5,6,7,8]]
result = [x for lst in li for x in lst]
print(result)相当于:
# result = []
# for lst in li:
# for x in lst:
# result.append(x)二维转一维,将名字包含g的数据直接输出,不包含g的数据转大写输出
names = [['asdf', 'ag'],['abg', 'abc'],
]
result = [name if 'g' in name else name.upper() for lst in names for name in lst]
print(result)与下面意思的一样:
result = []
for lst in names:for name in lst:if 'g' in name:result.append(name)else:result.append(name.upper())
print(result)输出:
['ASDF', 'ag', 'abg', 'ABC']2、集合推导式(在列表推导式的基础上去重) => set
lst = [-1, 1, -4, 2, 4]
# 求数据的绝对值,去重
result = {abs(x) for x in lst}
print(result)# for 临时变量 in 可迭代数据3、字典推导式 => dict
d1 = {"a":2, "b":1}
# 将key转化为大小
# {key:value for 临时数据 in 可迭代对象}
result = {key.upper():value for key,value in d1.items()}
print(result)输出:
{'A': 2, 'B': 1}构建一个字典: {'a':1,"b":2,"c":3,"d":4........."z":26}
# 构建一个字典: {'a':1,"b":2,"c":3,"d":4........."z":26}
# ord => 字母转ASCII chr(ord('a')+i)
# chr => ASCII转字母 chr(97) => 'a'result = {chr(97+i):i+1 for i in range(26)}
print(result)输出:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26}
迭代器
迭代器(Iterator)是Python中的一种对象,它用于实现迭代(遍历)的机制,允许你逐个访问集合中的元素,而无需提前加载所有元素到内存中。迭代器提供了一种延迟获取数据的方式,这对于处理大量数据或需要逐步处理数据的情况非常有用。
迭代器需要实现两个方法:
__iter__():返回迭代器对象自身。通常该方法返回self。
__next__():返回集合中的下一个元素。如果没有元素可返回,则引发StopIteration异常,表示迭代已经结束。迭代器的特点:
惰性求值:需要用到数据的时候,再去计算结果(不会一次性占用很多的内存空间和cpu,十分的高效)
可迭代对象: 实现了__iter__方法,并且该方法返回一个迭代器
可迭代对象(Iterable)是指可以被迭代(遍历)的对象。它们通常用于循环结构,比如
for循环。可迭代对象可以包含多个元素,每次迭代都返回其中的一个元素,直到所有元素都被访问完为止。
可以使用dir查看是否实现了__iter__方法,即可判断是否为可迭代对象
print(dir(1))
print(dir(list))
# for i in 1:
# pass
# 报错:'int' object is not iterable 表示 int 类型是不可迭代对象 # 常见的可迭代对象:
# set, tuple, dict, str, bool迭代器
str1 = "abc"
# 迭代器
# 获得一个迭代器
# 迭代器实现了__iter__(返回自己)和__next__(返回下一个数据)方法
str1_iter = str1.__iter__()
print(type(str1_iter), str1_iter)
print(str1_iter.__next__())
print(str1_iter.__next__())
print(next(str1_iter)) # 跟str1_iter.__next__()效果一样,只是写法不一样
# 当没有数据了的时候,会引发StopIteration错误
# print(str1_iter.__next__())# 当使用for去循环的时候,会调用对象的__iter__方法获得一个迭代器
# 每次循环,都是获取迭代器的__next__方法
# 如果遇到StopIteration错误,循环结束
# 等同于:for i in str1:输出:
<class 'str_iterator'> <str_iterator object at 0x000002B1DFDA5DE0>
a
b
c报错:
Traceback (most recent call last):File "D:\衡山-开发\python\pythonProject_day01\test.py", line 11, in <module>print(str1_iter.__next__())
StopIteration
判断是否为迭代器,或者是可迭代对象
from collections.abc import Iterator,Iterable
print(isinstance(str1_iter, Iterator))#collections.abc模块的使用输出:
True / False可迭代对象 和 迭代器的区别:
可迭代对象:print => 直接打印所有的数据
迭代器:print打印对象本身,无数据 => 对象.__next__ 或next(对象)
可迭代对象=> 存10w个数据 => 占用很多内存
迭代器 => 惰性求值(next调用的时候,才会去计算数据)(可用于数据量比较大的时候)
=> 不会一次占用很多的内存和CPU资源
迭代器实现了__iter__(返回自己)和__next__(返回下一个数据)方法
如果只实现了__iter__方法,那么它只能是可迭代对象
迭代器实现列表内数据的平方
map函数使用了惰性求值的特点(map就是迭代器)
li = [1,2,3,4,5]
result = map(lambda x:x*x,li)
print(type(result), dir(result))
# result => map => 迭代器
print(result.__next__())
print(next(result))实现一个迭代器(类似range函数的迭代器=>返回0到num的数据)
class MyRange():def __init__(self,num):self._start = -1self.num = num# 返回它自己def __iter__(self):return self# 返回def __next__(self):self._start += 1if self._start < self.num:return self._startelse:raise StopIteration #如果我们需要停止迭代器,直接raise StopIteration
for item in MyRange(10):print(item)如果我们需要停止迭代器,直接raise StopIteration
实现一个可以无限生成的斐波拉契数列的迭代器
#0, 1,1,2,3,5,8,13....
class Fib(object):def __init__(self):self.cur = 0self.next = 1def __iter__(self):return selfdef __next__(self):self.cur,self.next = self.next,self.cur+self.nextreturn self.cur
for i in Fib():if i>=100:breakprint(i,end=' ')
生成器:
"生成器"(Generator)通常指的是一种能够逐步产生数据、内容或事件序列的程序或模型。
生成器通常是指一种特殊类型的函数,它可以逐步产生数据流,而不是一次性生成所有数据并将其存储在内存中。这在处理大量数据或需要逐步生成结果的情况下非常有用,因为它可以减少内存占用。在Python中,生成器函数使用关键字
yield来逐步生成值。
特殊的迭代器:不需要自己编写__iter__和__next__ 方法
生成器特点与迭代器一样。
数量大,不需要立刻计算出结果,而是需要的时候再计算。
生成器表达式:(返回的数据 for 临时变量 in 可迭代对象)
li1 = [1,2,3,4]
# (返回值 for 临时变量 in 可迭代对象)
result = (x*x for x in li1)
print(type(result), dir(result))
print(next(result))
print(next(result))
print(next(result))
print(next(result))生成器函数:如果一个函数中包含了yield关键字,它是一个生成器函数
def func_g():print("start")yield 1print("No1")yield 2print("No2")yield 3使用生成器函数 --》 创建了一个生成器:g (g = func_g())
迭代器\生成器 中能保存一些状态的。迭代器\生成器 中的数据只能取一次。
g = func_g()
print(g, type(g), dir(g))
result = next(g) # 执行函数代码, 遇到yield 返回yield后面的数据,停止执行
print(result)
result = next(g) # 接着之前的代码继续执行
print(result)
result = next(g) # 接着之前的代码继续执行
print(result)输出:
<generator object func_g at 0x00000274E4845E70> <class 'generator'> ['__class__', '__del__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']start
1
No1
2
No2
3用生成器函数实现,传递给函数一下列表,返回列表中每个元素的平方
li1 = [1,2,3,4]
# func_g2(li1)
def func_g1(li):for item in li:yield item*item
g = func_g1(li1)
for i in g:print(i)输出:
1
4
9
16生成器yield 和 yield from返回数据的区别
yield 返回的数据
yield from 迭代器
def func_g3():yield range(10)g3 = func_g3()
print(next(g3))def func_g4():yield from range(10)
g4 = func_g4()
print(next(g4))
print(next(g4))
print(next(g4))输出:
range(0, 10)
0
1
2闭包:
什么是闭包?
闭包是在函数内部定义的函数,它可以访问其外部函数的变量,即使外部函数已经执行完毕并且其作用域不再存在。这种机制允许变量的状态在函数调用之间得以保留。
闭包形成的条件
# 1. 必须有内外函数(函数中嵌套函数)
# 2. 外部函数必须返回内部函数
# 3. 内部函数要使用外部函数的变量
闭包的特点
变量不会随着外部变量执行完成而释放,数据会被保存下来。(有状态的)
闭包函数
def outer_function(x):def inner_function(y):return x + yreturn inner_functionclosure = outer_function(10)
result = closure(5) # result 等于 15在这个例子中,
outer_function返回了一个内部函数inner_function,内部函数引用了外部函数的参数x。即使outer_function执行完毕后,我们仍然可以通过调用closure(5)来使用内部函数,这是因为闭包捕获了x的值。
装饰器:
装饰器:一种设计模式。
如果需要给函数或类添加一个功能,但不改变原来的调用方式,同时又不希望修改源代码或类的继承实现。
装饰器允许您在不修改原始函数代码的情况下,通过添加额外的行为来扩展或修改函数的行为。
例子:希望获取每一个函数运行时候的耗时
import time# 希望获取每一个函数运行时候的耗时
def func1():print("this is func1")time.sleep(1)def func2():print("this is func2")time.sleep(2)def func3():print("this is func3")time.sleep(3)start = time.time()
func1()
print("func1 cost:", time.time()-start)start = time.time()
func2()
print("func2 cost:", time.time()-start)start = time.time()
func3()
print("func3 cost:", time.time()-start)输出:
this is func1
func1 cost: 1.0075395107269287
this is func2
func2 cost: 2.010779619216919
this is func3
func3 cost: 3.002288579940796以上缺点:存在重复代码
用装饰器来实现给函数添加记录运行时间的功能(runtime装饰器)
import time# 希望获取每一个函数运行时候的耗时
# 装饰器接收的是一个函数, 返回值也需要是一个函数(才能保证调用方式不变)
def rumtime(func):# func --> 被装饰的函数# 因为被装饰的函数可能带参数也可能不带参数,因此这里使用可变长参数# 目的是让代码更加灵活def inner(*args, **kwargs):start = time.time()result = func(*args, **kwargs)print(f"函数运行时间为:{time.time() - start}")return result# 返回值需要是一个函数return inner# 在被装饰的对象上方加@装饰器名
@rumtime
def func1():print("this is func1")time.sleep(1)
# 当使用@runtime装饰func1时,相当于执行了:
# func1 = runtime(func1) => 内部runtime.inner函数
# 装饰器就相当于被装饰的函数func1()放到runtime()函数里面去了,运行完后,runtime装饰器会再返回一个函数放到func1()函数中去@rumtime
def func2():print("this is func2")time.sleep(2)
# func2 = runtime(func2)
# 新函数:记录运行时间,其中的函数功能 =>runtime.inner函数的功能@rumtime
def func3():print("this is func3")time.sleep(3)func1()
func2()
func3()输出:
this is func1
函数运行时间为:1.0070466995239258
this is func2
函数运行时间为:2.004884958267212
this is func3
函数运行时间为:3.0066428184509277
实现加记日志的功能:如函数XXX被调用了(log装饰器)
log => 实现日志功能的装饰器
import time# 希望获取每一个函数运行时候的耗时
# 装饰器接收的是一个函数, 返回值也需要是一个函数(才能保证调用方式不变)
def rumtime(func):def inner(*args, **kwargs):start = time.time()result =func(*args, **kwargs)print(f"函数运行时间为:{time.time() - start}")return resultreturn innerdef log(func):def inner(*args, **kwargs):print(f"{func.__name__}函数被执行了...")result =func(*args, **kwargs)return resultreturn inner# 在被装饰的对象上方加@装饰器名
@rumtime
def func1():print("this is func1")time.sleep(1)
# 当使用@runtime装饰func1时,相当于执行了:
# func1 = runtime(func1) => 内部runtime.inner函数@log
def func2():print("this is func2")time.sleep(2)#调用装饰器
@log
def func3():print("this is func3")time.sleep(3)func1()
func2()
func3()输出:
this is func1
函数运行时间为:1.0148968696594238
func2函数被执行了...
this is func2
func3函数被执行了...
this is func3
一个函数可以使用多个装饰器(多重装饰器)
实现的效果:
func3 =》 log(runtime(func3)) =》 log(runtime.inner)
因此当我们使用如下多个装饰器的时候log装饰器其实调用的函数是runtime内返回的inner函数,因此log装饰器上显示的函数名就是inner函数啦
# 双重装饰器 @log @rumtime def func3():print("this is func3")time.sleep(3)输出: inner函数被执行了... this is func3 函数运行时间为:3.0028884410858154因此如果我们想要我们的log能调用到真正的func3函数,我们需要对runtime装饰器进行修改
import time import functools# 希望获取每一个函数运行时候的耗时 # 装饰器接收的是一个函数, 返回值也需要是一个函数(才能保证调用方式不变) def rumtime(func):# functools.wraps(func)装饰器的功能是将func的原数据复制到inner上,其中就包括了函数名@functools.wraps(func)def inner(*args, **kwargs):start = time.time()result =func(*args, **kwargs)print(f"函数运行时间为:{time.time() - start}")return resultreturn innerdef log(func):@functools.wraps(func)def inner(*args, **kwargs):print(f"{func.__name__}函数被执行了...")result =func(*args, **kwargs)return resultreturn inner# 在被装饰的对象上方加@装饰器名 @rumtime def func1():print("this is func1")time.sleep(1) # 当使用@runtime装饰func1时,相当于执行了: # func1 = runtime(func1) => 内部runtime.inner函数@log def func2():print("this is func2")time.sleep(2)# 多重装饰器 @log @rumtime def func3():print("this is func3")time.sleep(3)func1() func2() func3()输出: this is func1 函数运行时间为:1.0131046772003174 func2函数被执行了... this is func2 func3函数被执行了... this is func3 函数运行时间为:3.0059847831726074如上所示,我们添加了functools包,并在runtime和log装饰器里面调用了它,如@functools.wraps(func),它能将func的原数据复制到inner上,其中就包括了函数名
模块化拆分装饰器:
创建 utils.py 文件,将我们的runtime和log装饰器写入文件中:
import time
import functools
# 装饰器接收的是一个函数,返回值也需要是一个函数(才能保证调用方式不变)
# 用闭包实现了一个装饰器
def runtime(func):# print("runtime-this is :",func)# func => 被装饰的函数# 因为被装饰的函数可能带参数也可能不带参数,因此这里使用可变长参数# 让代码更加灵活# functools.wraps:将func函数的元数据复制到inner (函数名)@functools.wraps(func)def inner(*args, **kwargs):start = time.time()result = func(*args, **kwargs)print(f"函数执行花了:{time.time()-start}s")return result# 返回值需要是一个函数return inner# import logging
from inspect import isfunction
def log(func):# print("log-this is :",func)# func => 被装饰的函数# 因为被装饰的函数可能带参数也可能不带参数,因此这里使用可变长参数# 让代码更加灵活@functools.wraps(func)def inner(*args, **kwargs):# logging.log()# isfunction可以用来判断func是否为函数,输出Ture或者Falseif isfunction(func):print(f"{func.__name__}函数被执行了...")else:print(f"{func.__name__}创建了一个实例...")result = func(*args, **kwargs)return result# 返回值需要是一个函数return inner
然后我们在父文件中调用 utils.py 文件中的装饰器
from utils import log, runtime装饰器可以装饰普通的函数、也可以用来装饰类
@log
class A():@logdef count(self):pass# log装饰器内可以判断它调用的到底是类还是函数
a = A()
a.count()输出:
A函数被执行了...
count函数被执行了...作业:
# 实现一个装饰器,login_required
# 如果需要调用被装饰的函数,你需要已经登录了
# @login_required
# def index():pass
# 1. 全局变量:user = None => 未登录:打印“请先登录再访问”,不调用index
# not None => 已经登录:调用index
# 2. 将用户数据保存到文件,从文件中读取用户信息。
相关文章:
 - 迭代器 - 生成器 - 闭包)
Python 装饰器 - 推导式(列表推导式) - 迭代器 - 生成器 - 闭包
目录 推导式 1、列表推导式(用得最多的) 给你一个列表,求所有数据的绝对值 列表推导式跟if运算 打印50以内能被3整除的数的平方(filter)(if的使用) 找到1000以内开平方的结果是整数的数&am…...

【大数据】Flink 详解(二):核心篇 Ⅲ
Flink 详解(二):核心篇 Ⅲ 29、Flink 通过什么实现可靠的容错机制? Flink 使用 轻量级分布式快照,设计检查点(checkpoint)实现可靠容错。 30、什么是 Checkpoin 检查点? Checkpoint …...
Jmeter性能测试系列-性能测试需求分析
性能测试需求分析 性能测试需求分析与传统的功能测试需求有所不同,功能测试需求分析重点在于从用户层面分析被测对象的功能性、易用性等质量特性,性能测试则需要从终端用户应用、系统架构设计、硬件配置等多个纬度分析系统可能存在性能瓶颈的业务。 性…...

Syncfusion Essential Studio JavaScrip Crack
Syncfusion Essential Studio JavaScrip Crack 数据透视表 添加了在将数据透视表导出到PDF文档时自定义列宽的支持。 签名 添加了对在特定位置绘制文本的支持。 Syncfusion Essential Studio for JavaScript在一个包中包含80多个高性能、轻量级、模块化和响应式UI组件。包括Jav…...

8.13黄金是否进入下行通道?下周开盘如何布局
近期有哪些消息面影响黄金走势?黄金多空该如何研判? 黄金消息面解析:周五(8月11日)现货黄金小幅收低,受累于美元走强和美国国债收益率上升,本周录得6月底以来最差单周表现。投资者在评估最新一批通胀报告和消费者信…...
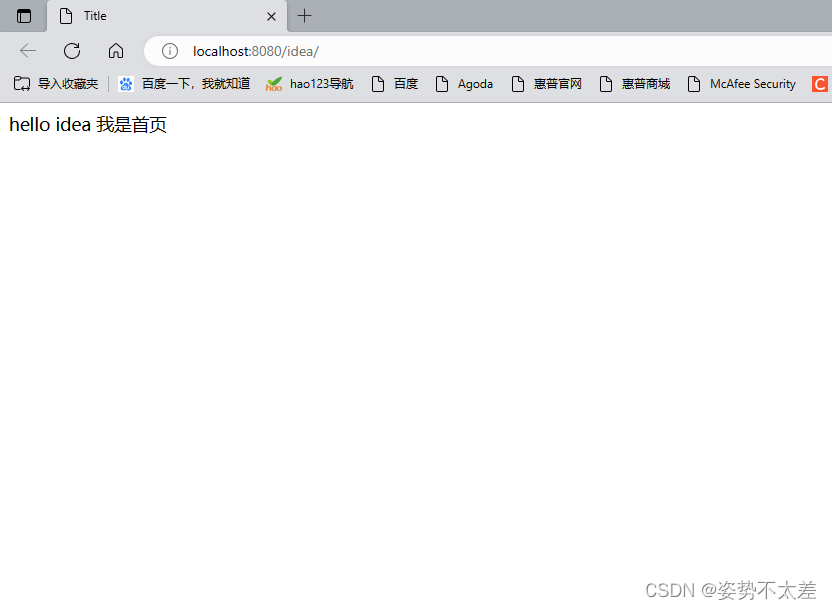
Idea的基本使用带案例---详细易懂
一.idea是什么 有专业人士说,idea是天生适合做微软,当时我还想肯定是夸大其词了,但当你用起来的时候确实很爽,😊😊 ntelliJ IDEA是一种集成开发环境(IDE),由JetBrains开发…...

MySQL中的用户管理
系列文章目录 MySQL常见的几种约束 MySQL中的函数 MySQL中的事务 MySQL中的视图 MySQL中的索引 文章目录 系列文章目录前言一、用户管理1、用户管理入门2、用户管理操作及示例 二、权限管理1.权限管理语法2.权限操作示例 三、角色管理1、角色管理入门2、角色操作示例 总结…...
【STM32】利用CubeMX对FreeRTOS用按键控制任务
对于FreeRTOS中的操作,最常用的就是创建、删除、暂停和恢复任务。 此次实验目标: 1.创建任务一:LED1每间隔1秒闪烁一次,并通过串口打印 2.创建任务二:LED2每间隔0.5秒闪烁一次,并通过串口打印 3.创建任…...

c# .net mvc的IHttpHandler奇妙之旅--图片文件请求安全过滤,图片防盗链
源码下载: c# .net mvc图片文件请求安全过滤,图片防盗链 https://download.csdn.net/download/cplvfx/88206428 在阅读该文章前,请先阅读该文章 c# .net mvc的IHttpHandler奇妙之旅。.net的生命周期和管道你听说过吗?你可以利用他处理业务如:跳转业务页面,文件请求的安全…...
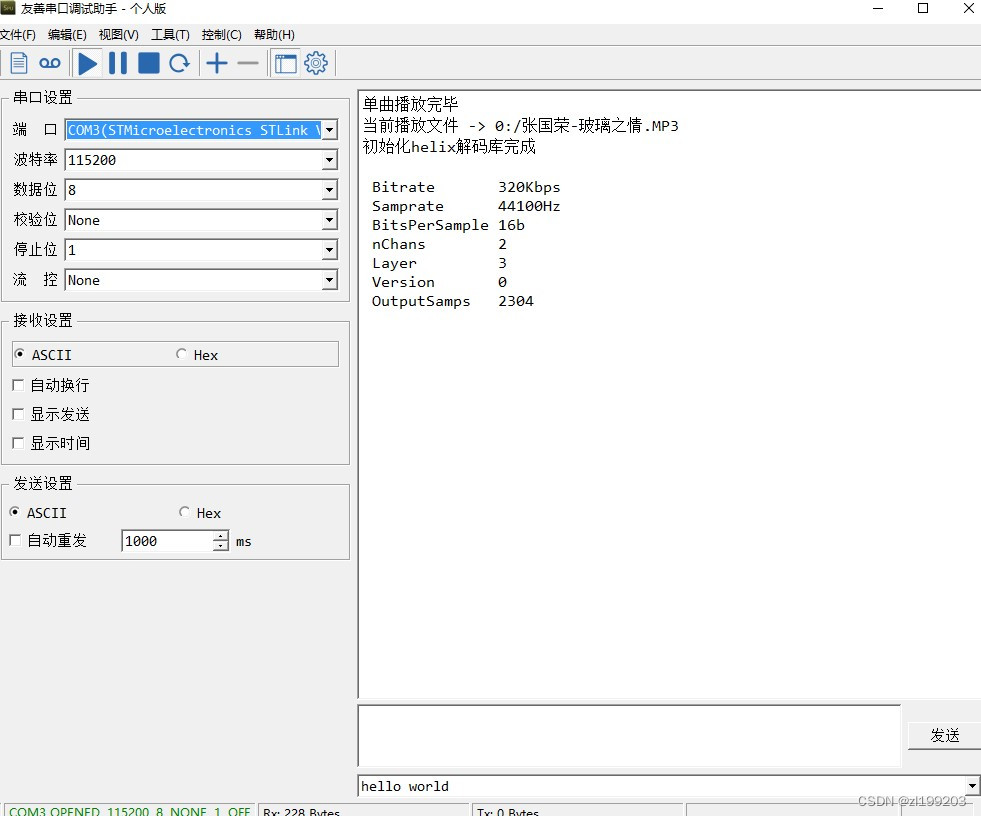
STM32F407使用Helix库软解MP3并通过DAC输出,最精简的STM32+SD卡实现MP3播放器
只用STM32单片机SD卡耳机插座,实现播放MP3播放器! 看过很多STM32软解MP3的方案,即不通过类似VS1053之类的解码器芯片,直接用STM32和软件库解码MP3文件,通常使用了labmad或者Helix解码库实现,Helix相对labm…...

STM32 CAN 过滤器设置
做个笔记吧 ,免得以后忘记了 芯片是stm32F207 ,用cubeMX 6.80 版本生成 CAN 的使用总体包含4个部分 第一步:CAN初始化,配置波特率 (cubeMX 里面配置好后自动生成,不需要手动添加) MX_CAN1_Init(); 第二步&#…...

日常BUG—— maven编译报错
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 一个maven项目在由于在代码中书写了如下代码: public static ConcurrentMap<…...
Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理
Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理 目录 Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理 一、简单介绍 二、实现原理 三、实现步骤 四、关键代码 一、简单介绍 Unity 工具类,自己整理的一些游戏开发可…...

学习Vue:插值表达式和指令
在 Vue.js 中,Vue 实例与数据绑定是构建动态交互界面的关键。在这篇文章中,我们将重点介绍 Vue 实例中两种实现数据绑定的方式:插值表达式和指令。这些机制允许您将数据无缝地渲染到界面上,实现实时的数据更新和展示。 插值表达式…...
echart 3d立体颜色渐变柱状图
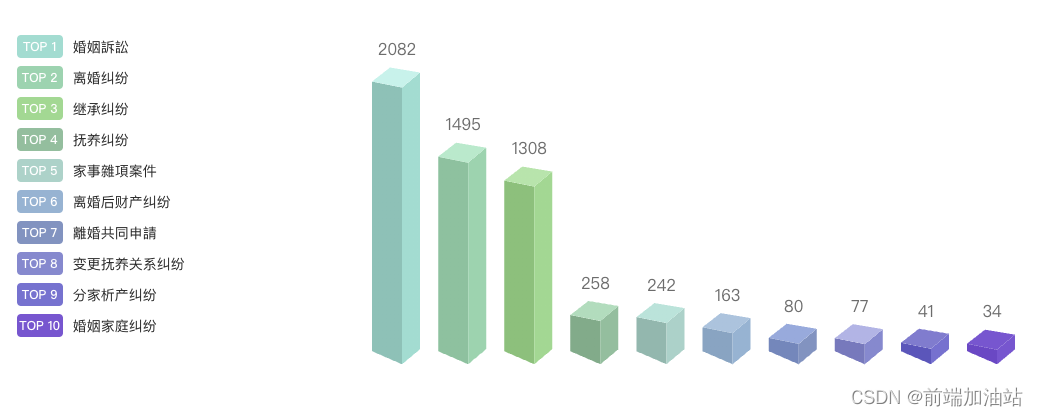
如果可以实现记得点赞分享,谢谢老铁~ 1.需求描述 根据业务需求将不同的法律法规,展示不同的3d立体渐变柱状图。 2.先看下效果图 3. 确定三面的颜色,这里我是自定义的颜色 // 右面生成颜色const rightColorArr ref(["#79D…...

linux shell变量
linux shell变量 1、变量命名规则2、只读变量3、删除变量 1、变量命名规则 变量名不能加$命名只能使用英文字母、数字和下划线,首个字母不能以数字开头中间不能有空格。可以有下划线不能使用标点符号不能使用bash中的关键字 username"tom"引用 $userna…...
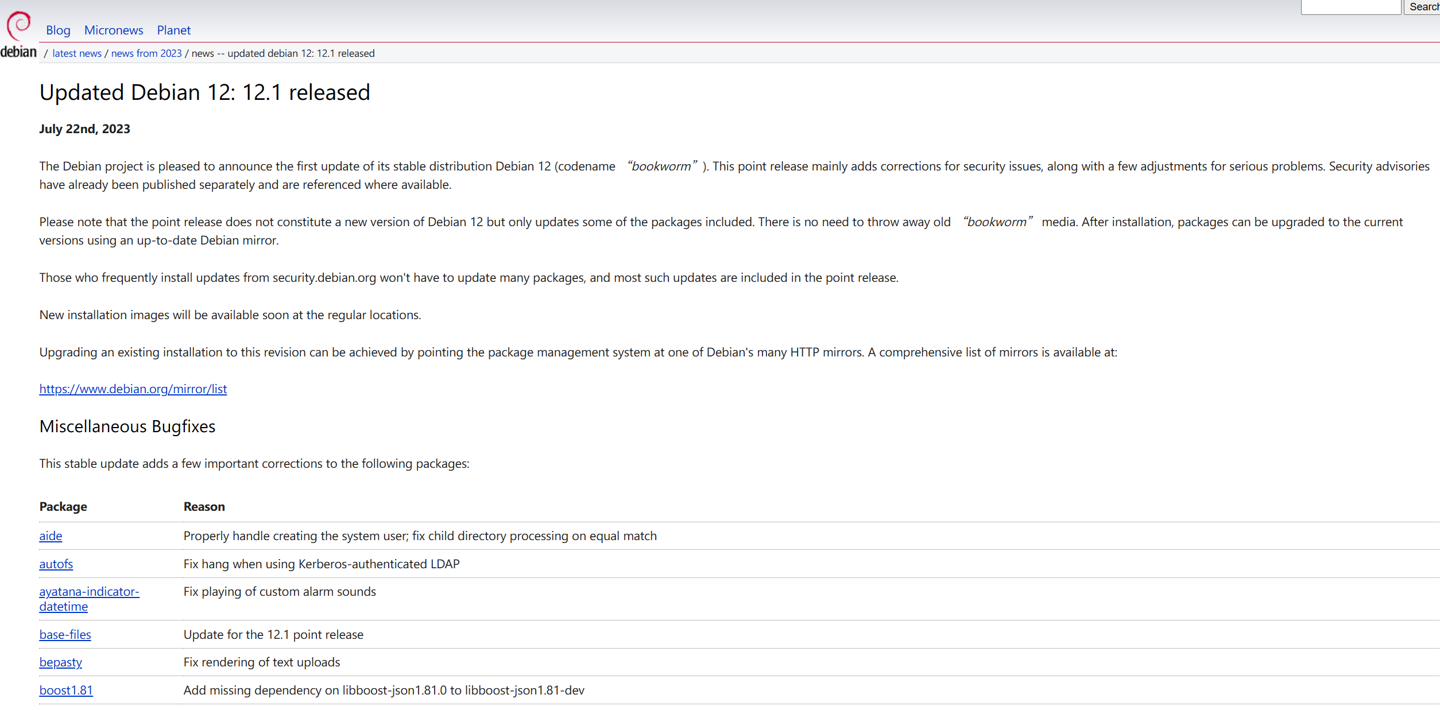
Linux 发行版 Debian 12.1 发布
在今年 6 月初,Debian 12“bookworm”发布,而日前 Debian 迎来了 12.1 版本,主要修复系统用户创建等多个安全问题。 Debian 是最古老的 GNU / Linux 发行版之一,也是许多其他基于 Linux 的操作系统的基础,包括 Ubuntu…...
【Rust】Rust学习 第七章使用包、Crate和模块管理不断增长的项目
目前为止,我们编写的程序都在一个文件的一个模块中。伴随着项目的增长,你可以通过将代码分解为多个模块和多个文件来组织代码。一个包可以包含多个二进制 crate 项和一个可选的 crate 库。伴随着包的增长,你可以将包中的部分代码提取出来&…...

网站SSL安全证书是什么及其重要性
网站SSL安全证书具体来说是一个数字文件,是由受信任的数字证书颁发机构(CA机构)进行审核颁发的,其中包含CA发布的信息,该信息表明该网站已使用加密连接进行了安全保护。 网站SSL安全证书也被称为SSL证书、https证书和…...
Android Alarm闹钟API使用心得
前言 有什么办法可以在不打开App的时候,也能够触发一些操作呢?比如说发送通知,解决这个需求的办法有很多种选择,比如说官方推荐的WorkManager API,可以在后台执行一次性、耗时、定时的任务,但WorkManager是…...

ZeRO显存优化原理:从Adam状态切分到三阶段实战配置
1. 项目概述:当大模型训练卡在显存上,ZeRO 是怎么“拆墙”又“省电”的?你有没有试过在单张 A100 上跑一个 7B 参数的 LLaMA 模型微调?刚把模型 load 进去,torch.cuda.memory_allocated()就飙到 98%,OOM报错…...

【纳瓦尔宝典】财富篇精读:程序员实现财富自由的底层逻辑
本文是《纳瓦尔宝典》第一部分"财富"与第二部分"判断力"的完整精读笔记,专为程序员群体量身打造。结合技术职场实际,拆解每一个核心观点,提供可落地的行动指南。一、积累财富:不是靠打工,而是靠创…...

Docker Login 报错“unauthorized”怎么办?从排查到解决的完整指南
Docker登录报错"unauthorized"全解析:从根因定位到企业级解决方案 当你满心欢喜地敲下docker login准备拉取镜像时,终端突然跳出刺眼的红色错误提示——"unauthorized: authentication required"。这种场景对开发者而言绝不陌生&…...

Unity碰撞器性能优化:从幽灵Collider到物理契约治理
1. 为什么一个“看不见”的碰撞器,能让60帧的游戏掉到20帧?在Unity项目上线前的性能压测阶段,我接手过一个看似普通的横版跳跃游戏——美术资源干净,逻辑简单,主角只有3个动画状态,连粒子特效都控制在5个以…...

解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案
解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐消费日益普及的今天&…...
)
CAD图纸版本转换软件 | Teigha File Converter (v4.3.2.0)
介绍 Teigha File Converter 是一款 CAD 图纸版本转换软件,它支转换到 2018 及以下的 DMG、DXF 格式。截图下载地址👇👇https://pan.baidu.com/s/1LbqDZMZjfzsqueFsVSvyjA?pwd4274...

BBEdit 16 正式发布!新增百多项功能,部分用户可免费升级
产品 产品 BBEdit Yojimbo iPad 版 Yojimbo TextWrangler 支持 支持 BBEdit Yojimbo iPad 版 Yojimbo TextWrangler 产品下载 找回序列号 SDK 与开发者信息 公司书架 商店 商店 购物车 许可协议 Mac App Store 常见问题 销售政策 查找经销商 多用户许可证 联系我们 联系我们 找…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...

Cortex-M3/M4处理器模式判断与调试技巧
1. Cortex-M3/M4处理器模式判断原理在嵌入式开发中,理解Cortex-M3和Cortex-M4处理器的运行模式对调试和异常处理至关重要。这两种处理器架构都采用了两级特权等级和两种执行模式的组合设计:特权等级(Privilege Level):…...

从分子设计到社交网络:聊聊DiGress在图生成领域的实战潜力与当前局限
从分子设计到社交网络:DiGress在图生成领域的实战潜力与当前局限 当药物研发团队需要快速生成数百万种候选分子结构,或是社交平台试图模拟用户关系网络时,图生成技术正悄然改变这些行业的创新范式。在众多前沿方法中,DiGress&…...