全面梳理Python下的NLP 库

一、说明
Python 对自然语言处理库有丰富的支持。从文本处理、标记化文本并确定其引理开始,到句法分析、解析文本并分配句法角色,再到语义处理,例如识别命名实体、情感分析和文档分类,一切都由至少一个库提供。那么,你从哪里开始呢?
本文的目标是为每个核心 NLP 任务提供相关 Python 库的概述。这些库通过简要说明进行了解释,并给出了 NLP 任务的具体代码片段。继续我对 NLP 博客文章的介绍,本文仅显示用于文本处理、句法和语义分析以及文档语义等核心 NLP 任务的库。此外,在 NLP 实用程序类别中,还提供了用于语料库管理和数据集的库。
涵盖以下库:
- NLTK
- TextBlob
- Spacy
- SciKit Learn
- Gensim
- 这篇文章最初出现在博客 admantium.com。
二、核心自然语言处理任务
2.1 文本处理
任务:标记化、词形还原、词干提取
NLTK 库为文本处理提供了一个完整的工具包,包括标记化、词干提取和词形还原。
from nltk.tokenize import sent_tokenize, word_tokenizeparagraph = '''Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.'''
sentences = []
for sent in sent_tokenize(paragraph):sentences.append(word_tokenize(sent))sentences[0]
# ['Artificial', 'intelligence', 'was', 'founded', 'as', 'an', 'academic', 'discipline'使用 TextBlob,支持相同的文本处理任务。它与NLTK的区别在于更高级的语义结果和易于使用的数据结构:解析句子已经生成了丰富的语义信息。
from textblob import TextBlobtext = '''
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.
'''blob = TextBlob(text)
blob.ngrams()
#[WordList(['Artificial', 'intelligence', 'was']),
# WordList(['intelligence', 'was', 'founded']),
# WordList(['was', 'founded', 'as']),blob.tokens
# WordList(['Artificial', 'intelligence', 'was', 'founded', 'as', 'an', 'academic', 'discipline', 'in', '1956', ',', 'and', 'in',借助现代 NLP 库 Spacy,文本处理只是主要语义任务的丰富管道中的第一步。与其他库不同,它需要首先加载目标语言的模型。最近的模型不是启发式的,而是人工神经网络,尤其是变压器,它提供了更丰富的抽象,可以更好地与其他模型相结合。
import spacy
nlp = spacy.load('en_core_web_lg')text = '''
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.
'''doc = nlp(text)
tokens = [token for token in doc]print(tokens)
# [Artificial, intelligence, was, founded, as, an, academic, discipline三、句法分析
任务:解析、词性标记、名词短语提取
从 NLTK 开始,支持所有语法任务。它们的输出作为 Python 原生数据结构提供,并且始终可以显示为简单的文本输出。
from nltk.tokenize import word_tokenize
from nltk import pos_tag, RegexpParsertext = '''
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.
'''pos_tag(word_tokenize(text))
# [('Artificial', 'JJ'),
# ('intelligence', 'NN'),
# ('was', 'VBD'),
# ('founded', 'VBN'),
# ('as', 'IN'),
# ('an', 'DT'),
# ('academic', 'JJ'),
# ('discipline', 'NN'),
# noun chunk parser
# source: https://www.nltk.org/book_1ed/ch07.htmlgrammar = "NP: {<DT>?<JJ>*<NN>}"
parser = RegexpParser(grammar)
parser.parse(pos_tag(word_tokenize(text)))
#(S
# (NP Artificial/JJ intelligence/NN)
# was/VBD
# founded/VBN
# as/IN
# (NP an/DT academic/JJ discipline/NN)
# in/IN
# 1956/CD文本 Blob 在处理文本时立即提供 POS 标记。使用另一种方法,创建包含丰富语法信息的解析树。
from textblob import TextBlobtext = '''
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.
'''
blob = TextBlob(text)blob.tags
#[('Artificial', 'JJ'),
# ('intelligence', 'NN'),
# ('was', 'VBD'),
# ('founded', 'VBN'),blob.parse()
# Artificial/JJ/B-NP/O
# intelligence/NN/I-NP/O
# was/VBD/B-VP/O
# founded/VBN/I-VP/OSpacy 库使用转换器神经网络来支持其语法任务。
import spacy
nlp = spacy.load('en_core_web_lg')for token in nlp(text):print(f'{token.text:<20}{token.pos_:>5}{token.tag_:>5}')#Artificial ADJ JJ
#intelligence NOUN NN
#was AUX VBD
#founded VERB VBN四、语义分析
任务:命名实体识别、词义消歧、语义角色标记
语义分析是NLP方法开始不同的领域。使用 NLTK 时,生成的语法信息将在字典中查找以识别例如命名实体。因此,在处理较新的文本时,可能无法识别实体。
from nltk import download as nltk_download
from nltk.tokenize import word_tokenize
from nltk import pos_tag, ne_chunknltk_download('maxent_ne_chunker')
nltk_download('words')
text = '''
As of 2016, only three nations have flown crewed spacecraft: USSR/Russia, USA, and China. The first crewed spacecraft was Vostok 1, which carried Soviet cosmonaut Yuri Gagarin into space in 1961, and completed a full Earth orbit. There were five other crewed missions which used a Vostok spacecraft. The second crewed spacecraft was named Freedom 7, and it performed a sub-orbital spaceflight in 1961 carrying American astronaut Alan Shepard to an altitude of just over 187 kilometers (116 mi). There were five other crewed missions using Mercury spacecraft.
'''pos_tag(word_tokenize(text))
# [('Artificial', 'JJ'),
# ('intelligence', 'NN'),
# ('was', 'VBD'),
# ('founded', 'VBN'),
# ('as', 'IN'),
# ('an', 'DT'),
# ('academic', 'JJ'),
# ('discipline', 'NN'),
# noun chunk parser
# source: https://www.nltk.org/book_1ed/ch07.htmlprint(ne_chunk(pos_tag(word_tokenize(text))))
# (S
# As/IN
# of/IN
# [...]
# (ORGANIZATION USA/NNP)
# [...]
# which/WDT
# carried/VBD
# (GPE Soviet/JJ)
# cosmonaut/NN
# (PERSON Yuri/NNP Gagarin/NNP)Spacy 库使用的转换器模型包含一个隐式的“时间戳”:它们的训练时间。这决定了模型使用了哪些文本,因此模型能够识别哪些文本。
import spacy
nlp = spacy.load('en_core_web_lg')text = '''
As of 2016, only three nations have flown crewed spacecraft: USSR/Russia, USA, and China. The first crewed spacecraft was Vostok 1, which carried Soviet cosmonaut Yuri Gagarin into space in 1961, and completed a full Earth orbit. There were five other crewed missions which used a Vostok spacecraft. The second crewed spacecraft was named Freedom 7, and it performed a sub-orbital spaceflight in 1961 carrying American astronaut Alan Shepard to an altitude of just over 187 kilometers (116 mi). There were five other crewed missions using Mercury spacecraft.
'''
doc = nlp(paragraph)
for token in doc.ents:print(f'{token.text:<25}{token.label_:<15}')
# 2016 DATE
# only three CARDINAL
# USSR GPE
# Russia GPE
# USA GPE
# China GPE
# first ORDINAL
# Vostok 1 PRODUCT
# Soviet NORP
# Yuri Gagarin PERSON五、文档语义
任务:文本分类、主题建模、情感分析、毒性识别
情感分析也是NLP方法差异不同的任务:在词典中查找单词含义与在单词或文档向量上编码的学习单词相似性。
TextBlob 具有内置的情感分析,可返回文本中的极性(整体正面或负面内涵)和主观性(个人意见的程度)。
from textblob import TextBlobtext = '''
Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.
'''blob = TextBlob(text)
blob.sentiment
#Sentiment(polarity=0.16180290297937355, subjectivity=0.42155589508530683)Spacy 不包含文本分类功能,但可以作为单独的管道步骤进行扩展。下面的代码很长,包含几个 Spacy 内部对象和数据结构 — 以后的文章将更详细地解释这一点。
## train single label categorization from multi-label dataset
def convert_single_label(dataset, filename):db = DocBin()nlp = spacy.load('en_core_web_lg')for index, fileid in enumerate(dataset):cat_dict = {cat: 0 for cat in dataset.categories()}cat_dict[dataset.categories(fileid).pop()] = 1doc = nlp(get_text(fileid))doc.cats = cat_dictdb.add(doc)db.to_disk(filename)## load trained model and apply to text
nlp = spacy.load('textcat_multilabel_model/model-best')
text = dataset.raw(42)
doc = nlp(text)
estimated_cats = sorted(doc.cats.items(), key=lambda i:float(i[1]), reverse=True)print(dataset.categories(42))
# ['orange']print(estimated_cats)
# [('nzdlr', 0.998894989490509), ('money-supply', 0.9969857335090637), ... ('orange', 0.7344251871109009),SciKit Learn 是一个通用的机器学习库,提供许多聚类和分类算法。它仅适用于数字输入,因此需要对文本进行矢量化,例如使用 GenSims 预先训练的词向量,或使用内置的特征矢量化器。仅举一个例子,这里有一个片段,用于将原始文本转换为单词向量,然后将 KMeans分类器应用于它们。
from sklearn.feature_extraction import DictVectorizer
from sklearn.cluster import KMeansvectorizer = DictVectorizer(sparse=False)
x_train = vectorizer.fit_transform(dataset['train'])
kmeans = KMeans(n_clusters=8, random_state=0, n_init="auto").fit(x_train)print(kmeans.labels_.shape)
# (8551, )print(kmeans.labels_)
# [4 4 4 ... 6 6 6]最后,Gensim是一个专门用于大规模语料库的主题分类的库。以下代码片段加载内置数据集,矢量化每个文档的令牌,并执行聚类分析算法 LDA。仅在 CPU 上运行时,这些最多可能需要 15 分钟。
# source: https://radimrehurek.com/gensim/auto_examples/tutorials/run_lda.html, https://radimrehurek.com/gensim/auto_examples/howtos/run_downloader_api.htmlimport logging
import gensim.downloader as api
from gensim.corpora import Dictionary
from gensim.models import LdaModellogging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
docs = api.load('text8')
dictionary = Dictionary(docs)
corpus = [dictionary.doc2bow(doc) for doc in docs]_ = dictionary[0]
id2word = dictionary.id2token
# Define and train the modelmodel = LdaModel(corpus=corpus,id2word=id2word,chunksize=2000,alpha='auto',eta='auto',iterations=400,num_topics=10,passes=20,eval_every=None
)print(model.num_topics)
# 10print(model.top_topics(corpus)[6])
# ([(4.201401e-06, 'done'),
# (4.1998064e-06, 'zero'),
# (4.1478743e-06, 'eight'),
# (4.1257395e-06, 'one'),
# (4.1166854e-06, 'two'),
# (4.085097e-06, 'six'),
# (4.080696e-06, 'language'),
# (4.050306e-06, 'system'),
# (4.041121e-06, 'network'),
# (4.0385708e-06, 'internet'),
# (4.0379923e-06, 'protocol'),
# (4.035399e-06, 'open'),
# (4.033435e-06, 'three'),
# (4.0334166e-06, 'interface'),
# (4.030141e-06, 'four'),
# (4.0283044e-06, 'seven'),
# (4.0163245e-06, 'no'),
# (4.0149207e-06, 'i'),
# (4.0072555e-06, 'object'),
# (4.007036e-06, 'programming')],六、公用事业
6.1 语料库管理
NLTK为JSON格式的纯文本,降价甚至Twitter提要提供语料库阅读器。它通过传递文件路径来创建,然后提供基本统计信息以及迭代器以处理所有找到的文件。
from nltk.corpus.reader.plaintext import PlaintextCorpusReadercorpus = PlaintextCorpusReader('wikipedia_articles', r'.*\.txt')print(corpus.fileids())
# ['AI_alignment.txt', 'AI_safety.txt', 'Artificial_intelligence.txt', 'Machine_learning.txt', ...]print(len(corpus.sents()))
# 47289print(len(corpus.words()))
# 1146248Gensim 处理文本文件以形成每个文档的词向量表示,然后可用于其主要用例主题分类。文档需要由包装遍历目录的迭代器处理,然后将语料库构建为词向量集合。但是,这种语料库表示很难外部化并与其他库重用。以下片段是上面的摘录——它将加载 Gensim 中包含的数据集,然后创建一个基于词向量的表示。
import gensim.downloader as api
from gensim.corpora import Dictionarydocs = api.load('text8')
dictionary = Dictionary(docs)
corpus = [dictionary.doc2bow(doc) for doc in docs]print('Number of unique tokens: %d' % len(dictionary))
# Number of unique tokens: 253854print('Number of documents: %d' % len(corpus))
# Number of documents: 1701七、数据
NLTK提供了几个即用型数据集,例如路透社新闻摘录,欧洲议会会议记录以及古腾堡收藏的开放书籍。请参阅完整的数据集和模型列表。
from nltk.corpus import reutersprint(len(reuters.fileids()))
#10788print(reuters.categories()[:43])
# ['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa', 'coconut', 'coconut-oil', 'coffee', 'copper', 'copra-cake', 'corn', 'cotton', 'cotton-oil', 'cpi', 'cpu', 'crude', 'dfl', 'dlr', 'dmk', 'earn', 'fuel', 'gas', 'gnp', 'gold', 'grain', 'groundnut', 'groundnut-oil', 'heat', 'hog', 'housing', 'income', 'instal-debt', 'interest', 'ipi', 'iron-steel', 'jet', 'jobs', 'l-cattle', 'lead', 'lei', 'lin-oil']SciKit Learn包括来自新闻组,房地产甚至IT入侵检测的数据集,请参阅完整列表。这是后者的快速示例。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups()
dataset.data[1]
# "From: guykuo@carson.u.washington.edu (Guy Kuo)\nSubject: SI Clock Poll - Final Call\nSummary: Final call for SI clock reports\nKeywords: SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization: University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA fair number of brave souls who upgraded their SI clock oscillator have\nshared their experiences for this poll.八、结论
对于 Python 中的 NLP 项目,存在大量的库选择。为了帮助您入门,本文提供了 NLP 任务驱动的概述,其中包含紧凑的库解释和代码片段。从文本处理开始,您了解了如何从文本创建标记和引理。继续语法分析,您学习了如何生成词性标签和句子的语法结构。到达语义,识别文本中的命名实体以及文本情感也可以在几行代码中解决。对于语料库管理和访问预结构化数据集的其他任务,您还看到了库示例。总而言之,这篇文章应该会给你一个良好的开端,进入你的下一个NLP项目,从事核心NLP任务。
NLP方法向使用神经网络,特别是大型语言模型的演变引发了一套完整的新库的创建和适应,从文本矢量化,神经网络定义和训练开始,以及语言生成模型的应用等等。这些模型涵盖了所有高级 NLP 任务,将在以后的文章中介绍。
塞巴斯蒂安
相关文章:
全面梳理Python下的NLP 库
一、说明 Python 对自然语言处理库有丰富的支持。从文本处理、标记化文本并确定其引理开始,到句法分析、解析文本并分配句法角色,再到语义处理,例如识别命名实体、情感分析和文档分类,一切都由至少一个库提供。那么,你…...

系统设计类题目汇总三
20 秒杀系统的一些拓展和优化 20.1 你发送消息时,流程是将消息发送给MQ做异步处理,然后消费者去消费消息,之后调用运营商的发送消息接口,那如果调用运营商的接口后消息发送失败怎么办? 确实,对于这种核心…...

“深入解析JVM:探索Java虚拟机的内部工作原理“
标题:深入解析JVM:探索Java虚拟机的内部工作原理 摘要:本文将深入解析Java虚拟机(JVM)的内部工作原理,包括类加载、内存管理、垃圾回收、即时编译等关键概念。通过对这些概念的详细讲解和示例代码的演示&a…...

VB+sql小型超市管理系统设计与实现
1、项目计划 1.1系统开发目的 (1)大大提高超市的运作效率; (2)通过全面的信息采集和处理,辅助提高超市的决策水平; (3)使用本系统,可以迅速提升超市的管理水平,为降低经营成本, 提高效益,增强超市扩张力, 提供有效的技术保障。 1.2背景说明 21世纪,超市的…...

mysql面试
基础篇 通用语法及分类 DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的数据进行增删改DQL: 数据查询语言,用来查询数据库中表的记录DCL: 数据控制语言,用…...

3.1 Ansible 的使用和配置管理
Ansible 的使用和配置管理 文章目录 Ansible 的使用和配置管理Ansible 基础Ansible 模块和变量主机管理和组织角色和剧本部署应用和配置自动化与批量操作Ansible 常见用例Ansible 最佳实践和性能优化 大纲 Ansible 简介和特点 介绍 Ansible 的定义和作用,以及它在配…...

神经网络基础-神经网络补充概念-06-计算图
概念 “计算图”(Computational Graph)是一种用于表示数学表达式计算过程的图结构,广泛用于深度学习和自动微分等领域。计算图将复杂的数学表达式分解为一系列简单的计算节点,这些节点之间通过边连接,形成了一个有向无…...
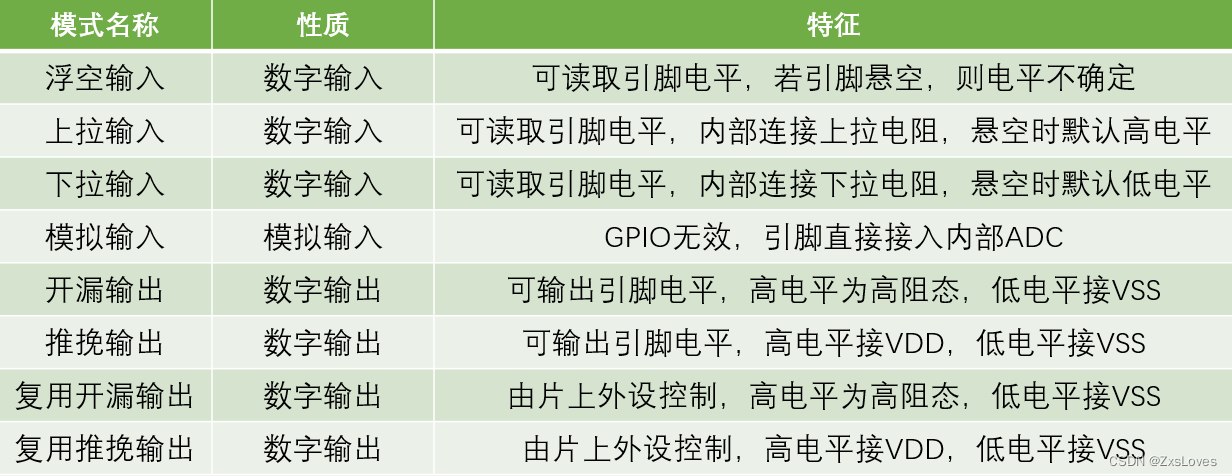
【【STM32之GPIO】】
STM32之GPIO 学完了正点原子自带的视频课之后感觉仍然一知半解现在更新一下来自其他版本的STM32学习 GPIO 就是 General Purpose Input Output 中文名叫通用输入输出口 可配置8种输入输出模式 引脚电平 0V~3.3V 部分引脚可容忍5V 输出模式下可控制端口输出高低电平ÿ…...
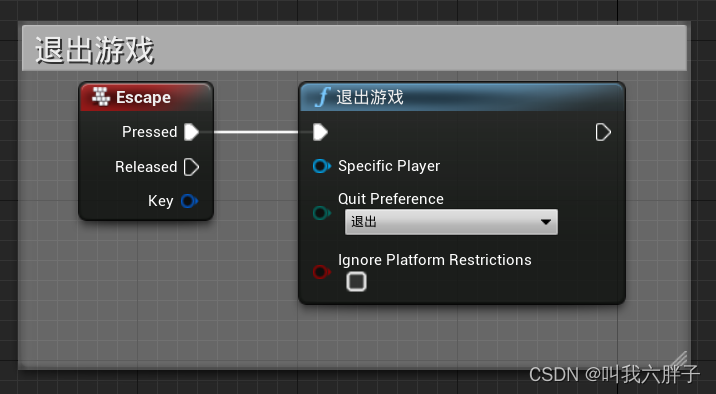
【动画】p60动画蓝图、播放蒙太奇、打包
p60动画蓝图、播放蒙太奇、打包 p60动画蓝图、播放蒙太奇、打包添加动画动画蓝图使模型使用动画蓝图奔跑跳舞蒙太奇 移动打断蒙太奇打包退出游戏 p60动画蓝图、播放蒙太奇、打包 添加动画 右键内容浏览器-》动画-》混合空间1D-》选择新的角色的骨骼 如下图在资产详情修改参数…...
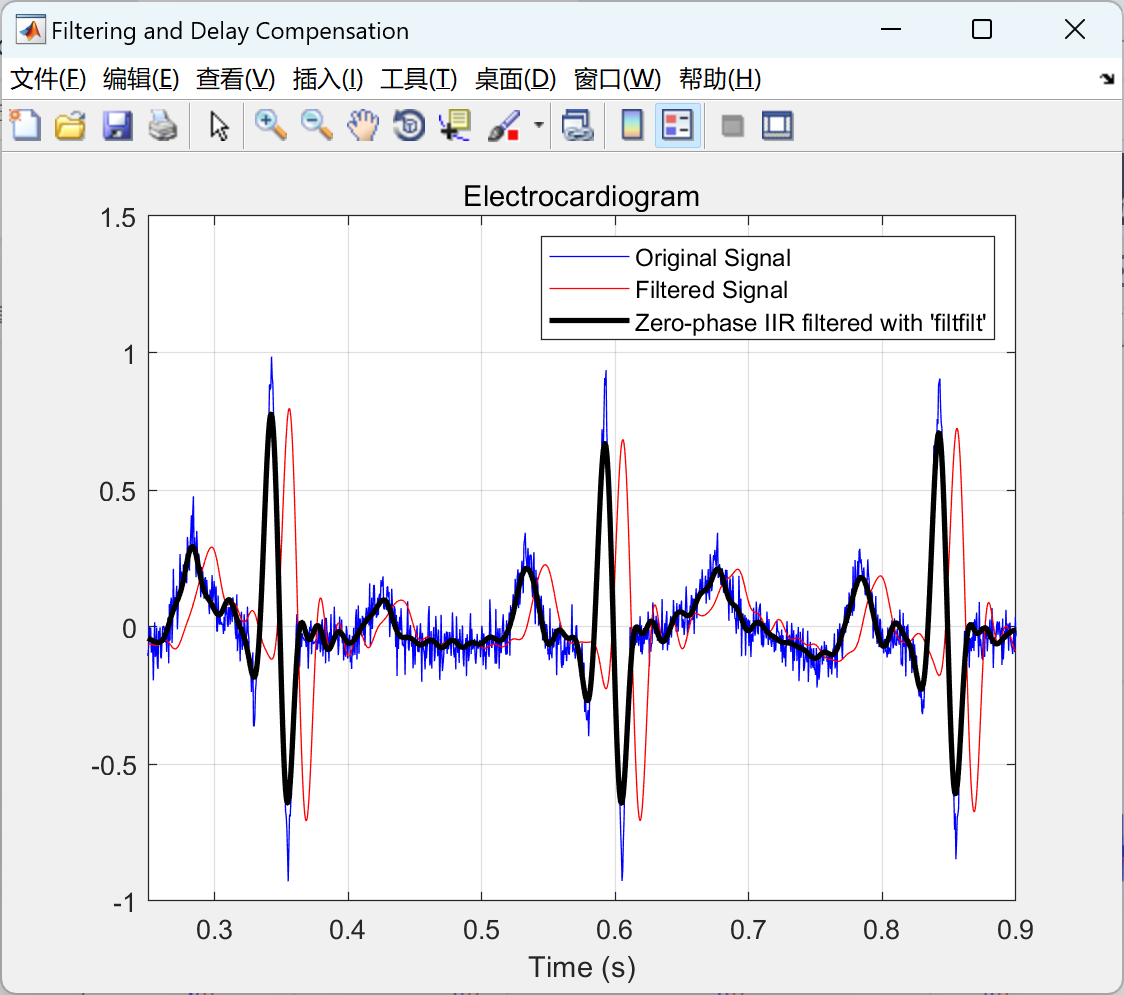
去趋势化一个心电图信号、信号功率谱、低通IIR滤波器并平滑信号、对滤波器引起的延迟进行补偿研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

NTN(六) switchover
NTN中的switchover包括feeder link switchover和 serving link switch。所谓feeder link switchover就是将feeder link从source NTN 网关更改为特定 NTN payload的target NTN 网关的过程。 feeder link switchover是网络层过程。 而service link switch则是指serving NTN paylo…...

Ceph三个接口的创建
目录 一、创建 CephFS 文件系统 MDS 接口 服务端操作 1)在管理节点创建 mds 服务 2)查看各个节点的 mds 服务 编辑3)创建存储池,启用 ceph 文件系统 创建 cephfs 4)查看mds状态,一个up,其…...

接口测试和功能测试的区别
接口测试和功能测试的区别: 2023最新Jmeter接口测试从入门到精通(全套项目实战教程) 本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者…...
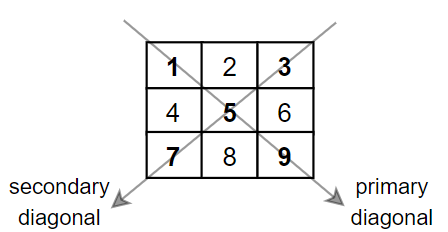
LeetCode 1572. 矩阵对角线元素的和
【LetMeFly】1572.矩阵对角线元素的和 力扣题目链接:https://leetcode.cn/problems/matrix-diagonal-sum/ 给你一个正方形矩阵 mat,请你返回矩阵对角线元素的和。 请你返回在矩阵主对角线上的元素和副对角线上且不在主对角线上元素的和。 示例 1&…...

SQLSERVER 查询语句加with (NOLOCK) 报ORDER BY 报错 除非另外还指定了 TOP、OFFSET 或 FOR XML
最近有一个项目在客户使用时发现死锁问题,用的数据库是SQLSERVER ,死锁的原因是有的客户经常去点报表,报表查询时间又慢,然后又有人在做单导致了死锁,然后主管要我们用SQLSERVER查询时要加with (NOLOCK),但是我在加完 …...

创建react native项目的笔记
创建react native项目的笔记 重新下载 ruby安装 watchman安装 cocoapods安装 react native 项目创建好项目后安装 ios 依赖清除设备缓存安装 android 依赖链接 网易 mumu 模拟器安装路由 Navigation页面之间的跳转逻辑自定义头部样式判断不同设备平台代码示例安装 Axios安装本地…...

Java自动化测试之Chrome网页爬取
记录一个好玩的小插件,可以通过它获取网页上的某个元素,然后得到他的值,不过需要懂前端技术,同时还需要一个chrome的小工具,工具放在我的共享文件里了,叫 chromedriver插件 pom 依赖 <dependency>&…...

boost下的asio异步高并发tcp服务器搭建
C 网络编程 asio 使用总结 - 知乎 (zhihu.com) 基于Boost::asio的多线程异步TCP服务器,实现了io_service线程池,测试了1万左右的并发访问,读写无压力_boost asio支持最大并发_E404的博客-CSDN博客 单线程 server.cpp #include <cstdlib&g…...
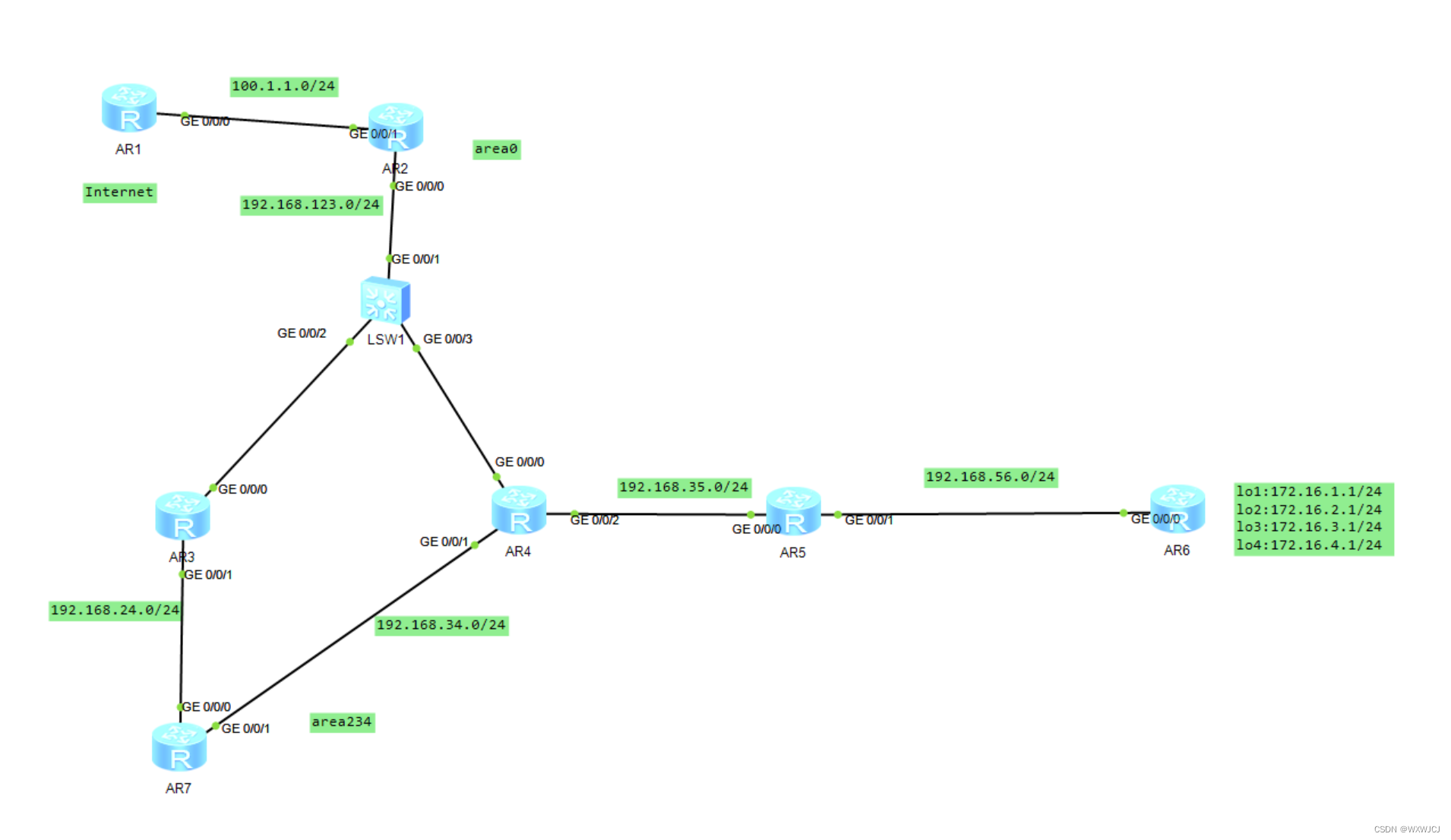
HCIP第五节------------------------------------------ospf
一、OSPF基础 1、动态路由分类 2、距离矢量协议 运行距离矢量路由协议的路由器周期性地泛洪自己的路由表。通过路由的交互,每台路由器都从相邻的路由器学习到路由,并且加载进自己的路由表中,然后再通告给其他相邻路由器。 对于网络中的所有…...

Golang下载安装
目录 1. 下载压缩包 2. 解压 3. 查看SDK是否安装成功 4. 配置环境变量 5. 查看环境变量是否配置成功 1. 下载压缩包 官网下载地址: All releases - The Go Programming Language Windows64位选择如下下载: 2. 解压 解压后内容如下: …...

3分钟学会Switch破解:TegraRcmGUI图形化注入工具完全指南
3分钟学会Switch破解:TegraRcmGUI图形化注入工具完全指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Windows平台设计…...

LCD人体秤嵌入式方案全解析:从传感器到低功耗设计
1. 项目概述:从“称重”到“健康管理”的智能跨越“电子秤方案——LCD人体秤方案”这个标题,乍一看似乎只是关于一个简单的称重工具。但在这个全民关注健康、数据驱动生活的时代,一台现代的人体秤早已超越了“称体重”的单一功能。它集成了传…...

深入理解Android网络开发:以OkHttp为核心的全面指南
引言 在移动应用开发中,网络通信是核心功能之一。Android平台提供了丰富的网络库和工具,但开发者常面临挑战,如性能优化、安全配置和弱网环境处理。OkHttp作为Android生态中最流行的HTTP客户端库,由Square公司开发,以其高效、灵活和易扩展的特性成为行业标准。它支持同步…...

厂房分区控温需求,水冷空调按需布设灵活调配
在工业生产与商业运营中,高温作业环境长期困扰着企业和劳动者。一方面,传统中央空调的高昂安装与运营成本让大多数中小企业望而却步;另一方面,超大厂房、物流仓库、汽车制造车间等开放或半开放场景,难以实现完全密封&a…...

嵌入式Linux UVC驱动开发:DWC2控制器与处理单元数据流详解
1. 项目概述:从DWC2控制器到UVC处理单元在嵌入式Linux系统里搞USB摄像头驱动开发,尤其是用DWC2这种集成在SoC里的USB控制器,UVC(USB Video Class)驱动的“处理单元”绝对是个绕不开的核心。很多朋友在移植或调试摄像头…...

量子-经典混合计算平台架构:从监控溯源到弹性推理引擎
1. 项目概述:当量子计算遇见经典算力最近几年,我身边不少做高性能计算和AI的朋友,都开始把目光投向一个听起来有点“科幻”的领域——量子计算。但大家聊着聊着,总会回到一个非常现实的问题:我们实验室那台价值不菲的量…...

Unity il2cpp元数据损坏修复指南:从崩溃定位到字节级修复
1. 这不是Bug报告,而是一场元数据层面的“外科手术”你有没有遇到过这样的情况:Unity项目在iOS或Android真机上跑得好好的,一升级Unity版本、一接入新SDK、甚至只是改了几行C#逻辑,打包出来的il2cpp构建就直接崩溃在启动阶段&…...
-更高级训练,如何把大规模知识“刻”入模型)
大模型训练师的炼丹之道 (3)-更高级训练,如何把大规模知识“刻”入模型
前言 在《炼丹之道》前两篇中,我们完成了从基础认知到身份重塑的入门仪式——当模型脱口而出“我是威震天”时,你已触摸到微调的魔法边缘。但那终究只是角色扮演的雏形,真正的炼丹术,在于将冰冷、精确的商业事实熔铸为模型的“肌…...

Cadence AMS数模混合仿真保姆级教程:从Virtuoso环境搭建到仿真加速全流程
Cadence AMS数模混合仿真实战指南:从环境配置到性能调优 数模混合仿真在现代集成电路设计中扮演着关键角色,它打破了传统数字与模拟设计之间的壁垒,让工程师能够在统一环境中验证复杂SoC的系统级行为。Cadence AMS Designer作为行业标杆工具&…...

论软件系统建模方法及其应用——以飞秒激光加工控制系统为例
摘要 2024年1月,我参与了某精密制造企业“高精度飞秒激光加工控制系统”项目的研发,担任系统架构设计师,主要负责系统建模、核心模块设计与集成测试。该项目旨在开发一套用于航空叶片微孔加工的数控系统,要求实现1μm的定位精度、实时补偿与工艺自适应调整。系统具有强实时…...