论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 预训练Pretraining
- 3.1.1 预训练细节
- 3.1.2 Llama2模型评估
- 3.2 微调Fine-tuning
- 3.2.1 Supervised Fine-Tuning(FT)
- 3.2.2 Reinforcement Learning with Human Feedback(RLHF)
- 3.2.2.1 偏好数据
- 3.2.2.2 Reward Modeling(RM)
- 3.2.2.3 Iterative Fine-Tuning
- 3.2.3 多轮对话一致性
- 3.2.4 RLHF结果
- 3.3 Safety
- 3.3.1 Safety in Pretraining
- 3.3.2 Safety Fine-Tuning
- 3.3.3 Red Teaming
- 3.3.4 Safety评估
- 4. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:Llama 2: Open Foundation and Fine-Tuned Chat Models
- 作者:Touvron H, Martin L, Stone K, et al.
- 日期:2023
- 期刊:arxiv preprint
2. 文章概括
文章训练并开源了模型Llama2系列模型。文章对Llama2做了大量的安全和有用性的微调,并进行了大量的数值试验,实验证明,Llama2-chat比其它被比较的开源的chat模型(BLOOM,LLaMa1,Falcon)效果好,且有潜力成为一些未开源chat模型(ChatGPT,BARD)的替代。meta公司发行了如下开源模型
- LLAMA2模型:LLAMA1[1]的更新版本,包含7B,13B,70B参数三个版本
- LLAMA2-CHAT模型:在LLAMA2之上对对话场景进行微调的chat模型,包含7B,13B,70B参数三个版本。文章整体框架如下图
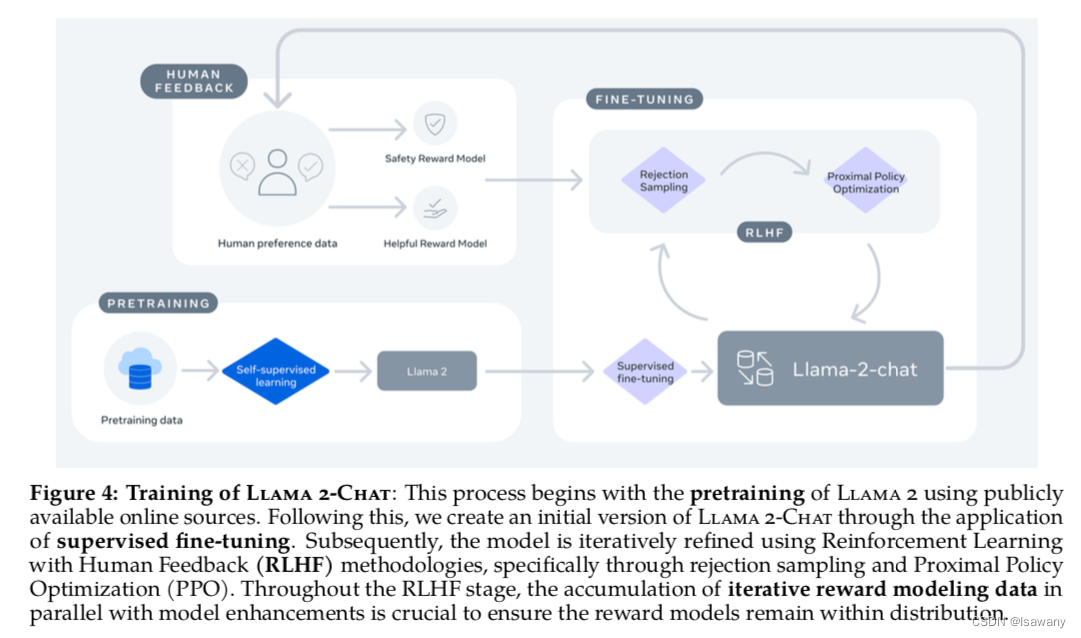
由于文章内容比较多,笔者挑选了其中重点的部分进行介绍。全部数值实验结果可参见原文。(这篇文章读起来和写起来真的很费力😣,因为文章很长,细节很多,而且好多技术细节写的好晦涩啊)
3 文章重点技术
3.1 预训练Pretraining
3.1.1 预训练细节
文章使用自回归Transformer模型,在LLAMA1[1]的基础之上进行了一些增强,具体包括
- 增加数据:Llama的语料库包含2trillion个tokens,且全部为公共可用数据,不包含Meta自己的数据集
- 增加40%的token数
- 增加上下文长度从2048到4096
- 修改attention为Grouped-query attention(GQA),以提升推理效率
具体差异可见下表

3.1.2 Llama2模型评估
文章对上述Llama2模型与Llama1,MosaicML,Falcon这些开源模型效果进行了评估、比对。文章选择了包含代码、常识推理、世界知识、阅读理解、数学、MMLU等benchmarks进行了数值实验。如下表所示,Llama2模型效果超过了Llama1,且超过所有其他被比较的开源模型。
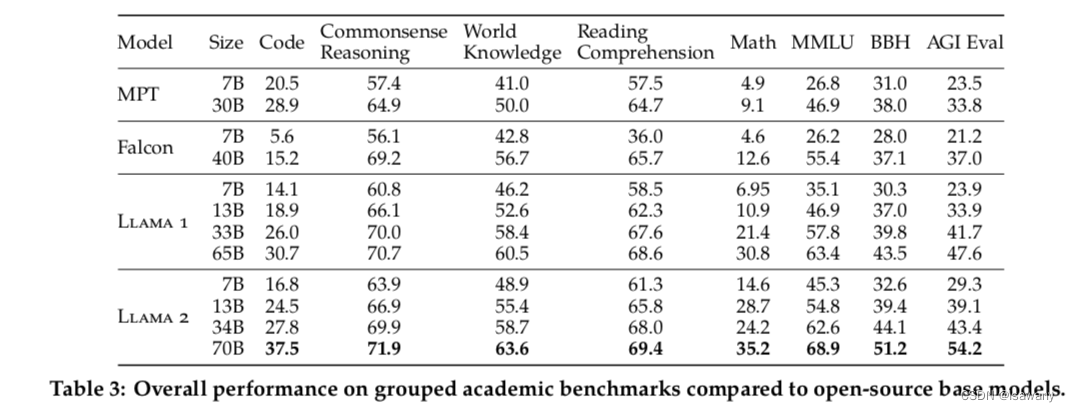
此外,文章将Llama2模型与GPT-3.5、GPT-4,PaLM,PaLM-2-L这些闭源模型进行了比较,通过调用这些模型的API来获得在benchmarks上面的数值实验结果。从下表可以看出,在Llama2 70B和GPT-4等闭源模型中还是有一定的性能差距的。

3.2 微调Fine-tuning
3.2.1 Supervised Fine-Tuning(FT)
类似于LIMA[2]的结论,文章发现少量高质量的SFT数据的效果超过使用大量无法保证质量的三方数据。文章发现,大约几万条高质量的SFT标注就可以实现高精度的结果,最终文章标注了27540条SFT数据。
3.2.2 Reinforcement Learning with Human Feedback(RLHF)
3.2.2.1 偏好数据
类似InstructGPT[3],文章尝试收集人类偏好数据,并通过RLHF来将模型和人类偏好和指令遵循进行对齐。
首先,文章通过如下程序收集人类偏好数据:1) 标记员写一个prompt 2) 让模型基于该prompt生成两个回答 3) 标记员基于给定的标准进行二选一 4) 标记员给出两个回答的差异程度:significantly better, better, slightly better或者unsure。按照如上程序,文章每周迭代收集helpfulness和safety两个基准的偏好数据,从而迭代训练llama2-chat模型。
此外,标记员需要给出一个安全性的标签,标签指向三个类别:1) 被选择的答案是安全的,另一个答案不安全 2) 两个答案都是安全的 3) 两个答案都是不安全的。结果表明三种选择的占比分别为18%, 47%和35%。文章将上述第一个分类的数据移除,因为安全的回答自然会被人类偏爱。
3.2.2.2 Reward Modeling(RM)
接下来,文章利用上述helpfulness, safety偏好数据分别训练两个奖励模型Helpfulness RM和 Safety RM。文章利用预训练的chat模型作为RM的初始化参数,这样可以包含预训练阶段学习到的知识,模型参数和架构与预训练阶段一致,除了将用于预测token的分类head修改为一个计算奖励的份的回归head。
为了学习人类偏好数据,文章参考InstructGPT[3]中的ranking损失函数 L r a n k i n g = − log ( σ ( r θ ( x , y c ) − r θ ( x , y r ) ) ) \mathcal{L}_{ranking} = - \log (\sigma (r_{\theta} (x, y_c) - r_{\theta}(x, y_r))) Lranking=−log(σ(rθ(x,yc)−rθ(x,yr))),其中 x x x为prompt, y c y_c yc为被选择的回答, y r y_r yr为被拒绝的回答, r θ r_{\theta} rθ表示奖励模型的输出分值。上述损失函数旨在令被偏好的回答 y c y_c yc的得分尽可能高于被拒绝的回答 y r y_r yr的得分。在此基础上,文章将收集到的偏好程度数据囊括进来: L r a n k i n g = − log ( σ ( r θ ( x , y c ) − r θ ( x , y r ) ) − m ( r ) ) \mathcal{L}_{ranking} = - \log (\sigma (r_{\theta} (x, y_c) - r_{\theta}(x, y_r))-m(r)) Lranking=−log(σ(rθ(x,yc)−rθ(x,yr))−m(r)),其中 m ( r ) m(r) m(r)表示偏好程度(前面收集的significantly better, better, slightly better或者unsure), m ( r ) m(r) m(r)越大表示被选择的回答被人类的偏好程度越明显,从而两个回答之间的得分差异要更大。
最后,将Helpfulness RM和Safety RM模型分别在Meta Helpfulness data和Meta Safety data上训练得到连个奖励模型。RM满足scaling law,即在相同的数据集上,模型越大,效果越好:
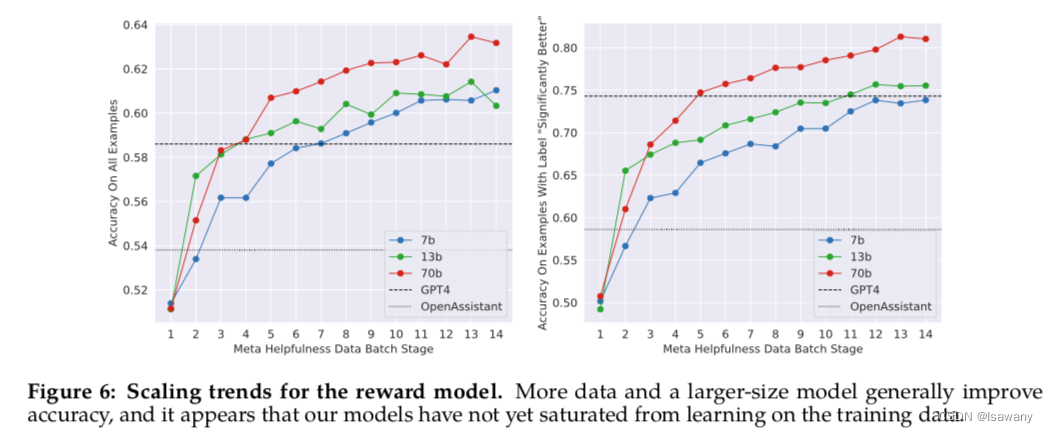
3.2.2.3 Iterative Fine-Tuning
由于Meta的人类偏好数据按周更新,从而可通过更新的数据迭代训练模型:RLHF-V1, …, RLHF-V5。具体来说,每个版本的RLHF模型可通过下述两种策略进行微调的:
- PPO(proximal Policy Optimization):标准RLHF策略,第 t t t步的样本为 t − 1 t-1 t−1步的更新策略的函数。PPO的目的是最大化奖励函数的期望,奖励函数定义如下: R ( g ∣ p ) = R ~ c ( g ∣ p ) − β D K L ( π θ ( g ∣ p ) ∥ π 0 ( g ∣ p ) ) R(g|p) = \tilde{R}_c(g|p) - \beta D_{KL} (\pi_{\theta} (g|p) \Vert \pi_0 (g|p)) R(g∣p)=R~c(g∣p)−βDKL(πθ(g∣p)∥π0(g∣p)),其中 π 0 ( g ∣ p ) \pi_0 (g|p) π0(g∣p)表示初始化的策略,公式第二项的作用为限制当前策略距离最初策略不要太远, R ~ c \tilde{R}_c R~c表示奖励函数得分的logits+白化,定义如下: R ~ c ( g ∣ p ) = WHITEN ( LOGIT ( R c ( g ∣ p ) ) ) R c ( g ∣ p ) = { R s ( g ∣ p ) , if IS_SAFETY ( p ) or R s ( g ∣ p ) < 0.15 R h ( g ∣ p ) , otherwise \tilde{R}_c(g|p) = \text{WHITEN}(\text{LOGIT} (R_c(g|p)))\\ R_c(g|p) = \begin{cases} R_s(g|p), \ \text{if}\ \text{IS\_SAFETY}(p)\ \text{or} \ R_s(g|p) < 0.15\\ R_h(g|p) , \ \text{otherwise}\end{cases} R~c(g∣p)=WHITEN(LOGIT(Rc(g∣p)))Rc(g∣p)={Rs(g∣p), if IS_SAFETY(p) or Rs(g∣p)<0.15Rh(g∣p), otherwise,简单解释下上式,IS_SAFETY就是代表模型中可能引发不安全回答的prompt p p p,即对不安全的prompt或safety RM模型 R s R_s Rs给出得分小于0.15的prompt,我们让RLHF优先学习安全奖励模型,对其它prompt才学习有用性模型 R h R_h Rh。
- Rejection Sampling fine-tuning(RSFT):从模型输出中采样K个样本,通过RM选择最好的候选作为新的gold standard,在这些样本上对模型进行梯度更新。文章只对70B的模型进行RSFT,对7B和13B的模型,文章通过70B的rejection sample进行微调,相当于对大模型的蒸馏。
在V4版本之前,文章通过RSFT进行微调,在V4之后,文章通过两个策略结合(先应用RSFT,再应用PPO)进行微调。此外,文章发现,迭代过程中模型出现了遗忘。为了解决此问题,文章每次都会将早期版本的样本包含进入微调的数据集。
3.2.3 多轮对话一致性
作者发现,在多轮对话之后,RHLF模型很容易忘记最初的指令。为此文章提出了Ghost Attention(GAtt)。给定消息序列 [ u 1 , a 1 , … , u n , a n ] [u_1, a_1, \dots, u_n, a_n] [u1,a1,…,un,an],其中 u i u_i ui代表用户在第 i i i轮给出的信息, a i a_i ai为对应的模型回答。假设用户在最初的时候给出了指令inst(比如act as …)。为使模型在每一轮对话中遵循该指令,一种简单的方法是将inst直接拼接到每一个user信息中,即 [ u 1 + i n s t , a 1 , u 2 + i n s t , a 2 , … , u n + i n s t , a n ] [u_1+inst, a_1, u_2+inst, a_2, \dots, u_n+inst, a_n] [u1+inst,a1,u2+inst,a2,…,un+inst,an]。然后文章通过Rejection Sampling的到上述数据的回答(作为标记数据?);结下来在学习该标记数据时,只在第一轮增加inst,即 [ u 1 + i n s t , a 1 , u 2 , a 2 , … , u n , a n ] [u_1+inst, a_1, u_2, a_2, \dots, u_n, a_n] [u1+inst,a1,u2,a2,…,un,an]还原到真实状态,但这样得到的结果会造成其与标记数据的mismatch,从而文章在训练每一轮对话的时候将该轮对话之前的token loss全部设置为0。
GAtt的效果非常好,实验发现GAtt下的inst可以持续到20+轮次的对话,直至达到最大的context长度。
3.2.4 RLHF结果
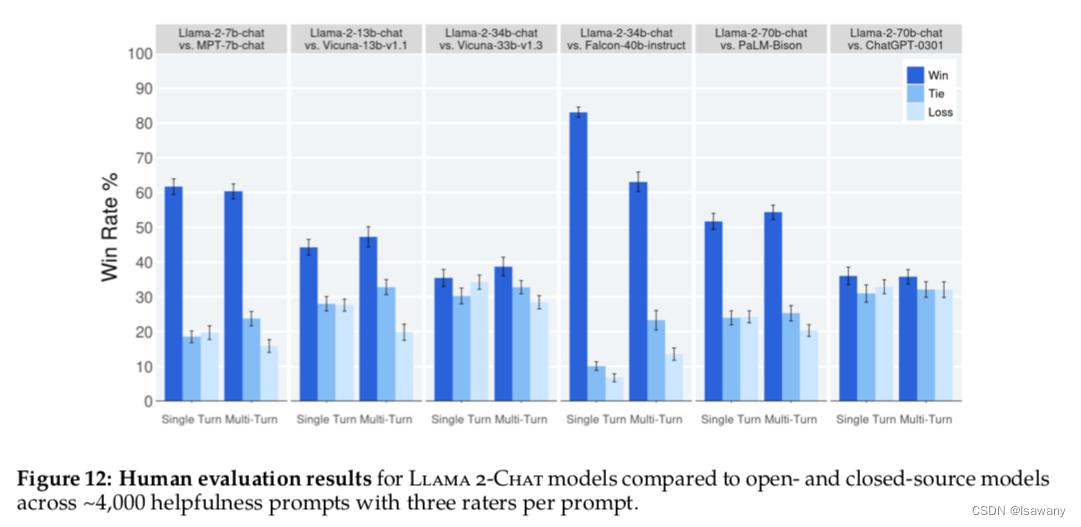
首先文章基于模型对RLHF进行自动评估。为了确定RW自动评估的效果是否准确,文章收集了一系列的包含有用性和安全性的prompts测试机,然后让标记员评估回答的Likert Score。我们发现RM给出的分数和人类的Likert score强相关。基于RM对不同阶段的模型结果进行评估,文章发现RM模型和ChatGPT模型对llama2-chat模型评估效果都很好,在V3之后helpfulness和safety指标上都高于ChatGPT(50%),如下图所示。
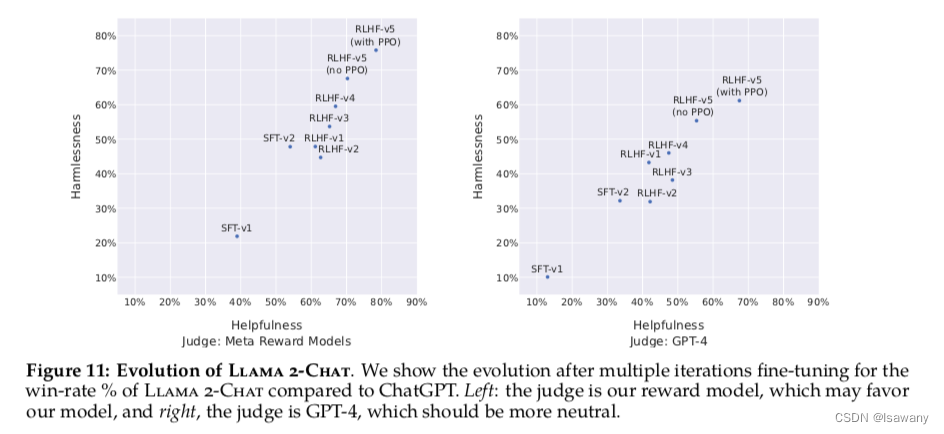
文章又进行了人工评估:令人类标记员在4000个单轮+多轮对话上对主要模型版本的回答质量进行打分(多轮对话当作整体)。如下图所示,llama2-chat模型在单轮对话和多轮对话上表现均优于所有开源模型。
3.3 Safety
3.3.1 Safety in Pretraining
首先文章预训练数据集未包含任何包含个人信息的数据,且未使用meta自己用户的数据,除此之外未进行其它过滤。
文章对预训练语料库进行了统计分析
- 在英语语料中,He出现的次数相比于She出现的要多,从而学习到的模型很可能会生成更多的He相关的语句
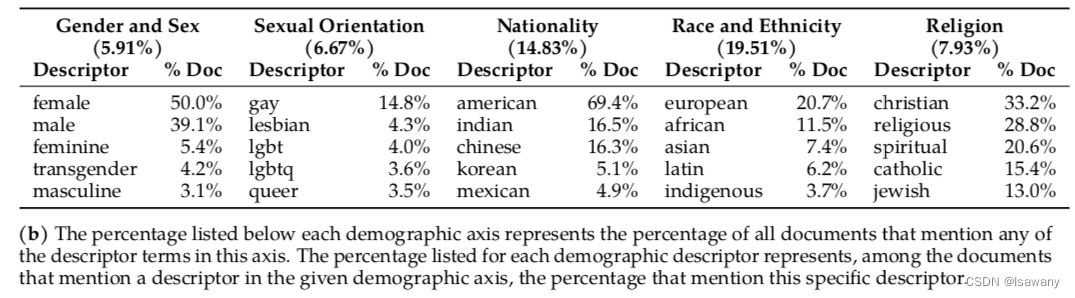
- 文章考虑了宗教、性别、国际、种族和性取向这5种敏感话题,并计算语料库中每个话题的top5元素,如下表所示。可以看到,female出现次数更多(尽管she出现次数少),这说明这些词之间的表达语境可能不同。在国籍上,语料库中包含更多的西方国家。
- 文章通过HateBERT评估了英语语料中的有毒语料(toxicity),发现仅0.2%的文档中可能包含有毒文本(似然分数>=0.5)
- 文章使用fastText来进行语言检测,超过0.5似然分数的认为属于该语言。最终检测结果表明89.7%的语料,从而针对其它语言要谨慎使用llama2。
此外,文章通过safety benchmarks来对预训练模型进行安全分析,具体包含以下benchmarks:
- Truthfulness:通过TruthfulQA数据来检测模型输出是否可靠、真实、符合常理。
- Toxicity:通过ToxiGen来检测有毒回答
- Bias:通过BOLD检测模型生成是否有政治倾向
如下表所示,相比于llama1-7B,llama2-7B提升了21.37%的truthfulness,降低了7.61%的toxicity,且bias有提升。但相比于其它开源模型,llama2的toxicity还是很高,这是因为文章用到的数据集未经系统的过滤。但增加过滤之后模型很难再执行一些诸如hate speech的任务了。

3.3.2 Safety Fine-Tuning
接下来文章介绍了在FT阶段的safety策略,主要包含以下几种
- Supervised Safety FT:首先将adversarial prompts(用户选择的可能造成不安全回答的prompts)和安全的生成内容结合,将该数据放入SFT数据中。从而模型可以在RLHF之前就和安全指导对齐。
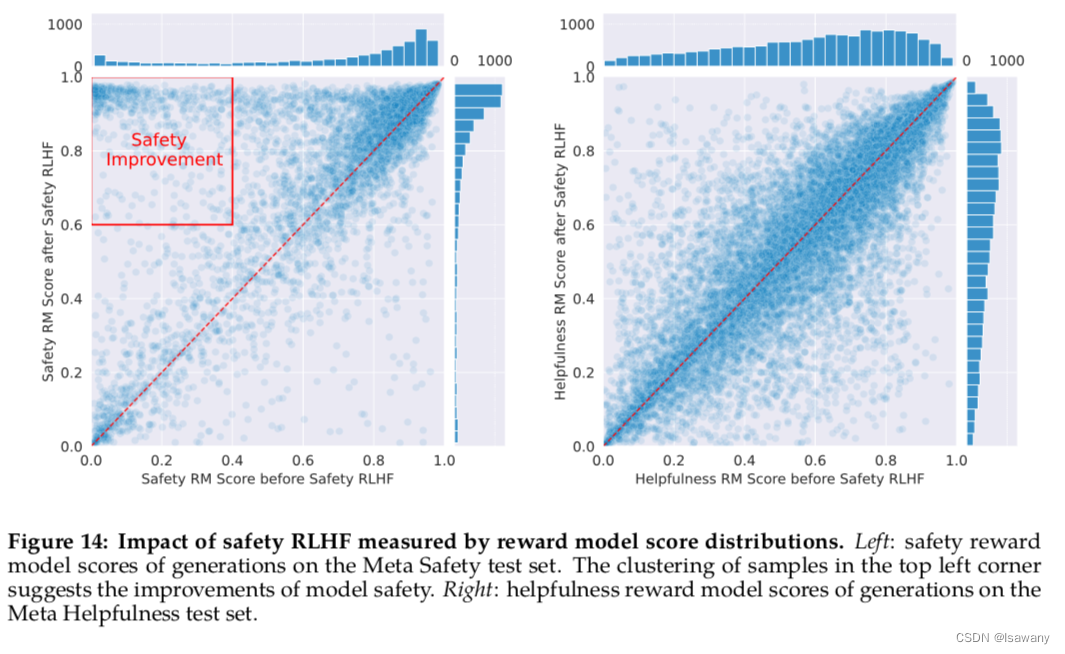
- Safety RLHF:在RLHF阶段,文章训练了一个安全的safety RM来指导模型生成安全的回答。Safety RLHF的效果如下图所示,可以看到,下图左的Safety RM分值在应用safety RLHF之后(y轴)相比于之前(x轴)有明显的提升,且下图右的helpfulness RM分值在应用safety RLHF之后(y轴)相比于之前(x轴)未发生明显降低。
- Safety Context Distillation:最后,文章将一个preprompt作为前文介绍的inst(比如:you are a safe and responsible preprompt )和prompt结合,让模型生成安全的回答。
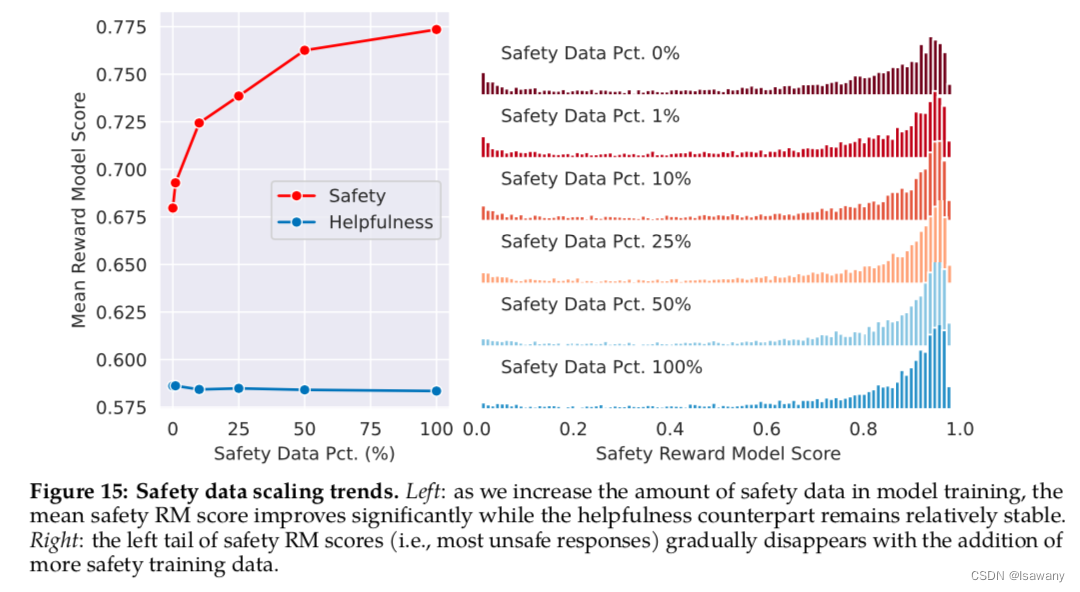
此外,文章证明了,当helpfulness数据不变时,safety数据越多,模型处理不安全prompts的能力越强,且低安全性的回答越少(ligher score),如下图所示
为了判断模型是否有false refusal(拒绝安全的prompts),文章在helpfulness数据集和精心设计的安全的但包含一些敏感词的prompts上(borderline dataset)进行评估,结果发现在helpfulness数据上false refusal大约仅有0.05%,占比很低。但在精心设计的borderline dataset上大的多(20%以上),说明llama2-chat针对此类数据的判断能力仍需提高。
3.3.3 Red Teaming
文章组建了一个red teaming组,包含各个领域的专家来对不同风险分类进行模拟风险,从而减少模型的安全性问题。参与者需要标注出对话的风险领域、风险等级,作者会根据标注结果进行训练策略调整。
定义模型的鲁棒性指标为 γ \gamma γ,文章发现在几轮red teaming 和模型优化之后,模型鲁棒性有所提升: γ : 1.8 → 0.45 \gamma : 1.8 \to 0.45 γ:1.8→0.45。
3.3.4 Safety评估
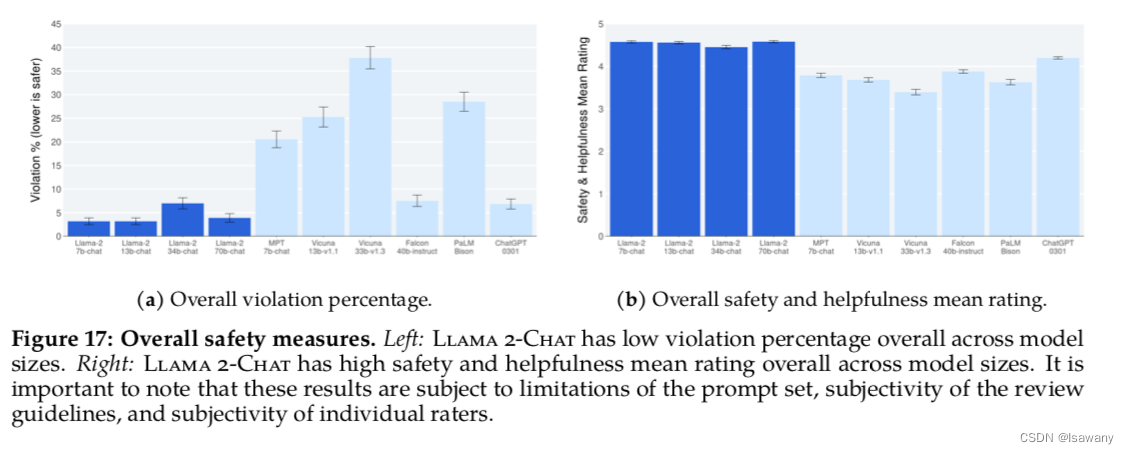
文章收集了2000个adversial prompts来进行人工评估,其中1351个是单轮对话,623个是多轮对话。然后人工对模型的安全性进行打分:1~5,分数越高表示越安全且有用。考虑打分1-2为violation,则如下图左所示,llama-整体的violation在所比较的模型中最低,且下图右表明llama2整体的整体打分也高于其它模型。
4. 文章亮点
文章训练并发行了一系列llama2模型,其中llama2-chat是迄今为止开源的chat模型中表现最好的。且文章给出的llama2给出了一系列安全性增强策略,可供其它LLM参考。
5. 原文传送门
Llama 2: Open Foundation and Fine-Tuned Chat Models
llama2 模型
llama2 代码
6. References
[1] 论文笔记–LLaMA: Open and Efficient Foundation Language Models
[2] 论文笔记–LIMA: Less Is More for Alignment
[3] 论文笔记–Training language models to follow instructions with human feedback
[4] GAtt示例
相关文章:
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…...
客达天下项目案例
本资料转载于传智播客https://www.itheima.com/ https://space.bilibili.com/3493265607232348 黑马程序员主办的全日制统招大学——大同互联网职业技术学院 预计2024年开始招生,敬请持续关注! B站视频入口:002_接口项目介绍_哔哩哔哩_bili…...

系统设计类题目汇总二
12 如何在实际的生产者端减少数据库的IO次数? 我自己想到的: 1 对于局部性很强的数据,启用mysql缓存机制,这样就不用磁盘IO 2 对于行数很多的表,可以分库分表,单表的数据量下来了,则查找索引要…...
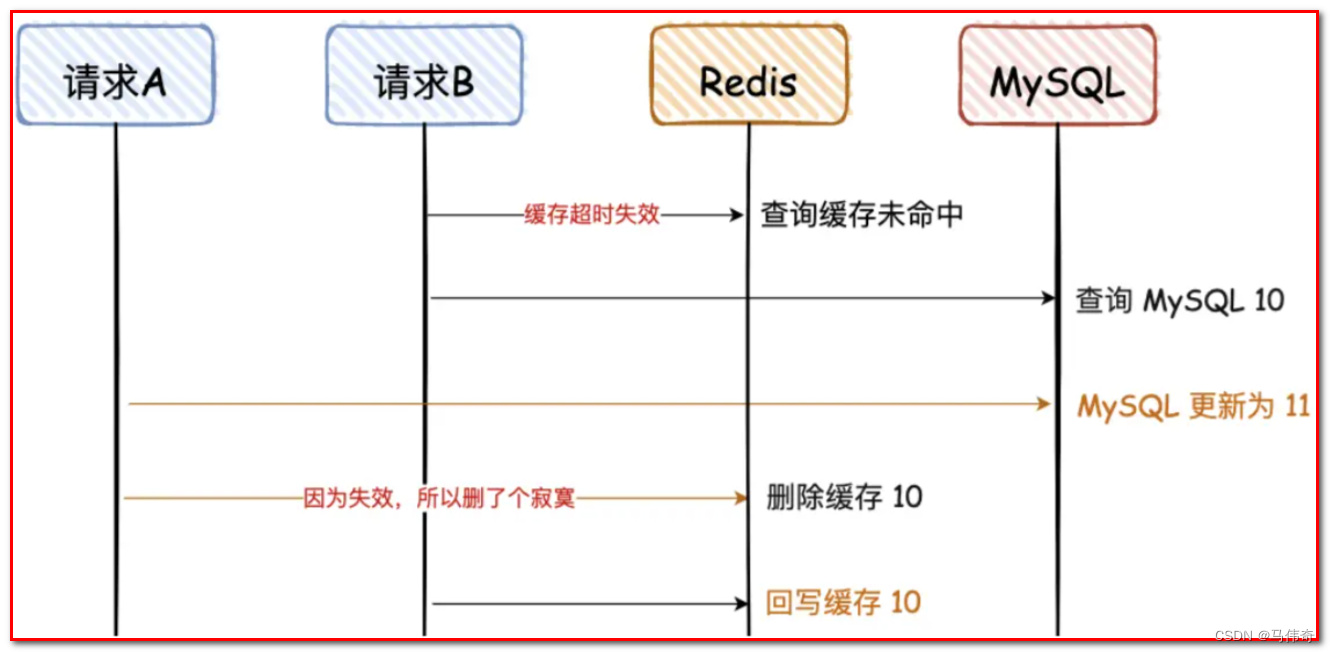
MySQL和Redis如何保证数据一致性
MySQL与Redis都是常用的数据存储和缓存系统。为了提高应用程序的性能和可伸缩性,很多应用程序将MySQL和Redis一起使用,其中MySQL作为主要的持久存储,而Redis作为主要的缓存。在这种情况下,应用程序需要确保MySQL和Redis中的数据是…...

Go学习第九天
使用sqlite3 package mainimport ("database/sql""fmt"_ "github.com/go-sql-driver/mysql""github.com/jmoiron/sqlx"_ "github.com/mattn/go-sqlite3""log""time" )var schema CREATE TABLE perso…...
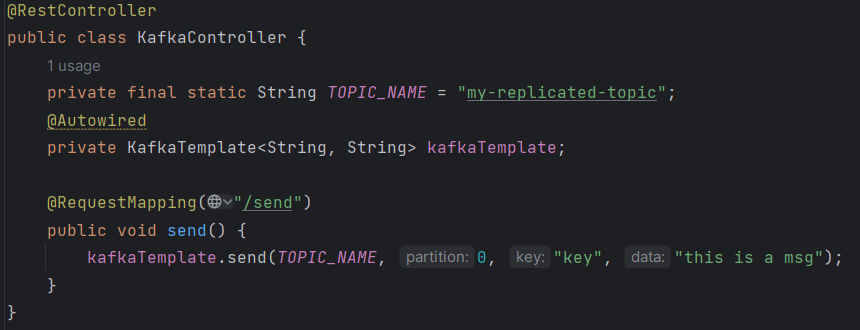
kafka集成篇
kafka的Java客户端 生产者 1.引入依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.6.3</version></dependency>2.生产者发送消息的基本实现 /*** 消息的发送⽅*/ …...

go-安装部署
一、安装go 详细安装方式可以查看官网 # 下载 wget https://golang.google.cn/dl/go1.21.0.linux-amd64.tar.gz # 解压缩 tar -xzf go1.21.0.linux-amd64.tar.gz # 迁移目录 mv go /usr/local # 配置环境变量 export PATH$PATH:/usr/local/go/bin # 检查go的版本 go version有…...

vue项目的实用性总结
1、mockjs 基本使用 ★ 安装:npm i mockjs。 在src/mock/index.js内容如下: import Mock from mockjs //制订拦截规则 Mock.mock(http://www.0313.com,get,你好啊)记得在main.js中引入一下,让其参与整个项目的运行。 只要发出去的是get类型…...
IOC容器
DI(依赖注入):DI(Dependency Injection)是一种实现松耦合和可测试性的软件设计模式。它的核心思想是将依赖关系的创建与管理交给外部容器,使得对象之间只依赖于接口而不直接依赖于具体实现类。通过依赖注入…...
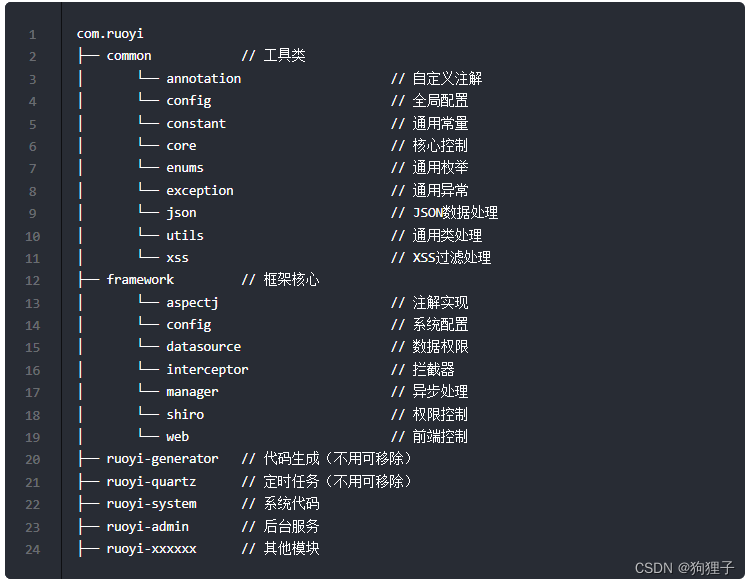
若依框架浅浅介绍
由若依官网所给介绍可知 1、文件结构介绍 在ruoyi-admin的pom.xml文件中引入了ruoyi-framework、ruoyi-quartz和ruoyi-generatior模块,在ruoyi-framework的pom.xml文件中引入了ruoyi-system模块。 2、技术栈介绍 前端:Vue、Element UI后端:…...
echarts 柱状图-折线图-饼图的基础使用
上图示例图表展示相关配置: var myChart echarts.init(this.$refs.firstMain);myChart.setOption({legend: { // 图例设置top: "15%",type: "scroll",orient: "vertical",//图例列表的布局朝向。left: "right",pageIconCo…...

mac电脑 node 基本操作命令
1. 查看node的版本 node -v2. 查看可安装的node版本 sudo npm view node versions3. 安装指定版本的node sudo n 18.9.04. 安装最新版本node sudo n latest5. 安装最新稳定版 sudo n stable6. 清楚node缓存 sudo npm cache clean -f7. 列举已经安装的node版本 n ls 8. 在…...
Hlang社区项目说明
文章目录 前言Hlang社区技术前端后端 前言 Hello,欢迎来到本专栏,那么这也是第一次做这种类型的专栏,如有不做多多指教。那么在这里我要隆重介绍的就是这个Hlang这个项目。 首先,这里我要说明的是,我们的这个项目其实是分为两个…...

RTC实验
一、RTC简介 RTC(Real Time Clock)即实时时钟,它是一个可以为系统提供精确的时间基准的元器件,RTC一般采用精度较高的晶振作为时钟源,有些RTC为了在主电源掉电时还可以工作,需要外加电池供电BCD码,四位二进制表示一位…...

C#多线程报错:The destination thread no longer exists.
WinForm,C#多线程报错: System.ComponentModel.InvalidAsynchronousStateException: An error occurred invoking the method. The destination thread no longer exists. 研究一番,找到了原因: 有问题的写法: ne…...
使用 Visual Studio GoogleTest编写 C/C++ 单元测试——入门篇
入门教程 Visual Studio 新建 GoogleTest项目,一路选默认参数 pch.h #pragma once#include "gtest/gtest.h"int add(int a, int b);pch.cpp #include "pch.h"int add(int a, int b) {return a b; }test.cpp #include "pch.h"TES…...

Linux下TA_Lib安装失败的问题处理
Linux下TA_Lib安装失败的问题处理 TA_Lib是python的量化指标库,其中包含了很多150多种量化指标 ,量化分析中经常使用。 This is a Python wrapper for TA-LIB based on Cython instead of SWIG. From the homepage: TA-Lib is widely used by trading …...

egg.js企业级web框架
egg与express、koa的区别 三者皆为node.js web框架,但: express适合做个人项目,灵活性太高;egg是基于koa封装的企业级框架,奉行约定优于配置,按照一套统一的约定进行应用开发,减少开发学习成本…...

小说网站第二章-关于文章的上传的实现
简述 因为最近比较忙,所以只有时间把以前的东西整理一下。前端方面,我使用了既存md5框架语法来保存数据,原谅我展示没找到好的方法。后端的话,我使用nodemongodb来保存数据。下面我就来简单介绍一下我的东西。 前端的实现 前端的…...

Java面试题01
1、以下不属于oracle的逻辑结构的是?答案:B A.段 B.数据文件 C.表空间 D.区 2、构造函数何时被调用?答案:A A.创建对象时 B.使用对象变量时 C.调用对象方法时 D.类定义时 3、下列排序…...

微信小程序 消防知识学习平台系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术实现特色亮点适用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 微信小程序“消…...

AI赋能·精准适配——API风险监测系统筑牢教育数据流转安全防线
一、概要提示:本文围绕数据流转安全与静态数据安全的核心差异,结合教育行业数字化转型特性,系统阐述API风险监测系统的核心逻辑、核心能力、常见疑问及发展趋势,全面呈现系统在教育场景中的数据化应用成效,凸显“AI赋能…...

Image2.0生成的PPT图片转换成可编辑的PPT的一种方法
老弟,PPT不想做,用AI生成的PPT图片编辑不了很烦恼是吧,俺有一法!~ Edit Banana(最强,开源免费) 能把 AI 图→可编辑 PPTX / DrawIO / SVG 原理:用 SAM 分割图标 / 形状,用…...

千问 LeetCode 2561. 重排水果 Python3实现
这道题的核心是贪心 利用全局最小值做中介交换。下面给出Python3实现,附带详细注释。from typing import List from collections import Counterclass Solution:def minCost(self, basket1: List[int], basket2: List[int]) -> int:# 1. 统计每个水果在两个篮子…...

Gramophone安全与权限管理:Android 13+存储权限最佳实践
Gramophone安全与权限管理:Android 13存储权限最佳实践 【免费下载链接】Gramophone A sane music player built with media3 and material design library that is following androids standard strictly. 项目地址: https://gitcode.com/gh_mirrors/gr/Gramopho…...
MindSpore Transformers 训练任务快速上手
MindSpore Transformers(简称 MindFormers)是昇思 MindSpore 生态下的大模型训练套件,集成 BERT、GPT、LLaMA、Qwen 等主流 Transformer 模型,提供一键式预训练 / 微调、分布式并行、混合精度、监控可视化能力,适配昇腾…...

HCIP-Datacom Core Technology V1.0_18 IGMP原理与配置
IGMP用于接收者和直连组播路由之间,建立和维护组播成员关系的组播协议,本章课程将介绍IGMP的原理,以及它不同版本的区别,还有一些其它特性。IGMP介绍组播网络的转发困境正常情况下,组播源将组播报文推送给第一跳路由器…...

【产品发布】建享云智能单据扫描仪正式上线,一站式解决单据数字化处理难题
建享云正式推出全新智能单据扫描仪,聚焦各行业单据数字化处理的核心痛点,无需复杂部署流程、无需专业技术支撑,轻松适配个人办公与企业级各类场景。本文将简洁明了地介绍产品核心功能、操作方法及适配范围,帮助用户快速了解产品价…...

2026实测:租用RTX 4090 CUDA适配与PyTorch精准安装教程
RTX 4090搭载Ada Lovelace架构、4nm制程工艺,配备16384个CUDA核心、24GB GDDR6X显存、1TB/s显存带宽,FP32算力82.6 TFLOPS,是7B-13B大模型训练、图像识别、深度学习推理的核心主流算力。个人开发者、中小团队自建RTX 4090硬件,存在…...

强烈推荐!这个 Skill 画架构图质量超高,一句话出图
做技术这行,总有些事是真心懒得做的,画架构图算一个。 不是不重要,是太麻烦。要么打开 http://draw.io 从头拖组件,要么用 Mermaid 写一堆语法还要反复调位置,最后搞出来的效果差强人意,发给别人一看&…...