ELK常见部署架构以及出现的问题及解决方案
ELK常见部署架构以及出现的问题及解决方案
ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats 、Logstash 、Elasticsearch 、
Kibana 等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介绍ELK常见的架
构以及相关问题解决。
Filebeat :Filebeat是一款轻量级,占用服务资源非常少的数据收集引擎,它是ELK家族的新成员,可以代替
Logstash作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到Kafka,Redis等队列。
Logstash :数据收集引擎,相较于Filebeat比较重量级,但它集成了大量的插件,支持丰富的数据源收集,
对收集的数据可以过滤,分析,格式化日志格式。
Elasticsearch :分布式数据搜索引擎,基于Apache Lucene实现,可集群,提供数据的集中式存储,分析,
以及强大的数据搜索和聚合功能。
Kibana :数据的可视化平台,通过该web平台可以实时的查看 Elasticsearch 中的相关数据,并提供了丰富
的图表统计功能。
1、ELK常见部署架构
1.1 Logstash作为日志收集器
这种架构是比较原始的部署架构,在各应用服务器端分别部署一个Logstash组件,作为日志收集器,然后将
Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展示。
这种架构不足的是:Logstash比较耗服务器资源,所以会增加应用服务器端的负载压力。

1.2 Filebeat作为日志收集器
该架构与第一种架构唯一不同的是:应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以
使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最
常用的架构。

1.3 引入缓存队列的部署架构
该架构在第二种架构的基础上引入了Kafka消息队列(还可以是其他消息队列),将Filebeat收集到的数据发送至
Kafka,然后在通过Logstasth读取Kafka中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队
列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力。

1.4 以上三种架构的总结
第一种部署架构由于资源占用问题,现已很少使用,目前使用最多的是第二种部署架构,至于第三种部署架构个人
觉得没有必要引入消息队列,除非有其他需求,因为在数据量较大的情况下,Filebeat 使用压力敏感协议向
Logstash 或 Elasticsearch 发送数据。
如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并
继续发送数据。
2、问题及解决方案
2.1 如何实现日志的多行合并功能?
系统应用中的日志一般都是以特定格式进行打印的,属于同一条日志的数据可能分多行进行打印,那么在使用ELK
收集日志的时候就需要将属于同一条日志的多行数据进行合并。
解决方案:使用Filebeat或Logstash中的multiline多行合并插件来实现
在使用multiline多行合并插件的时候需要注意,不同的ELK部署架构可能multiline的使用方式也不同,如果是本
文的第一种部署架构,那么multiline需要在Logstash中配置使用,如果是第二种部署架构,那么multiline需要
在Filebeat中配置使用,无需再在Logstash中配置multiline。
1、multiline在Filebeat中的配置方式:
filebeat.prospectors:-paths:- /home/project/elk/logs/test.loginput_type: logmultiline:pattern: '^\['negate: truematch: after
output:logstash:hosts: ["localhost:5044"]
pattern:正则表达式negate:默认为false,表示匹配pattern的行合并到上一行;true表示不匹配pattern的行合并到上一行match:after表示合并到上一行的末尾,before表示合并到上一行的行首
如:
pattern: '\['
negate: true
match: after
该配置表示将不匹配pattern模式的行合并到上一行的末尾。
2、multiline在Logstash中的配置方式
input {beats {port => 5044
}
}filter {multiline {pattern => "%{LOGLEVEL}\s*\]"negate => truewhat => "previous"}
}output {elasticsearch {hosts => "localhost:9200"}
}
(1)Logstash中配置的what属性值为previous,相当于Filebeat中的after,Logstash中配置的what属性值为
next,相当于Filebeat中的before。
(2)pattern => "%{LOGLEVEL}\s*\]" 中的LOGLEVEL 是Logstash预制的正则匹配模式,预制的还有好多常
用的正则匹配模式,详细请看:
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
2.2 如何将Kibana中显示日志的时间字段替换为日志信息中的时间?
默认情况下,我们在Kibana中查看的时间字段与日志信息中的时间不一致,因为默认的时间字段值是日志收集时
的当前时间,所以需要将该字段的时间替换为日志信息中的时间。
解决方案:使用grok分词插件与date时间格式化插件来实现
在Logstash的配置文件的过滤器中配置grok分词插件与date时间格式化插件,如:
input {beats {port => 5044}
}filter {multiline {pattern => "%{LOGLEVEL}\s*\]\[%{YEAR}%{MONTHNUM}%{MONTHDAY}\s+%{TIME}\]"negate => truewhat => "previous"
}# 时间格式配置
grok {match => [ "message" , "(?<customer_time>%{YEAR}%{MONTHNUM}%{MONTHDAY}\s+%{TIME})" ]
}# 时间格式配置
date {# 格式化时间match => ["customer_time", "yyyyMMdd HH:mm:ss,SSS"]# 替换默认的时间字段target => "@timestamp"}
}output {elasticsearch {hosts => "localhost:9200"}
}
如要匹配的日志格式为:
[DEBUG][20170811 10:07:31,359][DefaultBeanDefinitionDocumentReader:106] Loading bean definitions
解析出该日志的时间字段的方式有:
①、通过引入写好的表达式文件,如表达式文件为./customer-patterms/mypatterns,内容为:
CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}\s+%{TIME}
注: 内容格式为:[自定义表达式名称] [正则表达式]
然后logstash中就可以这样引用:
filter {grok {# 引用表达式文件路径patterns_dir => ["./customer-patterms/mypatterns"]# 使用自定义的grok表达式match => [ "message" , "%{CUSTOMER_TIME:customer_time}" ]}
}
②、以配置项的方式,规则为:(?<自定义表达式名称>正则匹配规则),如:
filter {grok {match => [ "message" , "(?<customer_time>%{YEAR}%{MONTHNUM}%{MONTHDAY}\s+%{TIME})" ]}
}
2.3 如何在Kibana中通过选择不同的系统日志模块来查看数据?
一般在Kibana中显示的日志数据混合了来自不同系统模块的数据,那么如何来选择或者过滤只查看指定的系统模
块的日志数据?
解决方案:新增标识不同系统模块的字段或根据不同系统模块建ES索引
1、新增标识不同系统模块的字段,然后在Kibana中可以根据该字段来过滤查询不同模块的数据,这里以第二种部
署架构讲解,在Filebeat中的配置内容为:
filebeat.prospectors:-paths:- /home/project/elk/logs/account.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterfields: log_from: account-paths:- /home/project/elk/logs/customer.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterfields:log_from: customeroutput:logstash:hosts: ["localhost:5044"]
通过新增:
log_from字段来标识不同的系统模块日志
2、根据不同的系统模块配置对应的ES索引,然后在Kibana中创建对应的索引模式匹配,即可在页面通过索引模式
下拉框选择不同的系统模块数据。
filebeat.prospectors:-paths:- /home/project/elk/logs/account.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterfields: log_from: account-paths:- /home/project/elk/logs/customer.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterfields:log_from: customer
output:logstash:hosts: ["localhost:5044"]
通过新增:
log_from字段来标识不同的系统模块日志
这里以第二种部署架构讲解,分为两步:
①、在Filebeat中的配置内容为:
filebeat.prospectors:-paths:- /home/project/elk/logs/account.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterdocument_type: account-paths:- /home/project/elk/logs/customer.loginput_type: logmultiline:pattern: '^\['negate: truematch: afterdocument_type: customer
output:logstash:hosts: ["localhost:5044"]
通过document_type来标识不同系统模块
②、修改Logstash中output的配置内容为:
output {elasticsearch {hosts => "localhost:9200"index => "%{type}"}
}
在
output中增加index属性,%{type}表示按不同的document_type值建ES索引
3、总结
本文主要介绍了ELK实时日志分析的三种部署架构,以及不同架构所能解决的问题,这三种架构中第二种部署方式
是时下最流行也是最常用的部署方式。
最后介绍了ELK作在日志分析中的一些问题与解决方案,说在最后,ELK不仅仅可以用来作为分布式日志数据集中
式查询和管理,还可以用来作为项目应用以及服务器资源监控等场景,更多内容请看官网。
相关文章:
ELK常见部署架构以及出现的问题及解决方案
ELK常见部署架构以及出现的问题及解决方案 ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats 、Logstash 、Elasticsearch 、 Kibana 等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介…...

windows使用vscode配置java开发环境
安装JDK 下载windows版本的JDK,解压到一个目录 openJDK下载地址:Archived OpenJDK GA Releases (java.net) 下载 Microsoft Build of OpenJDK | Microsoft Learn 添加环境变量:JAVA_HOME:JDK的解压目录 编辑PATH:…...
)
centos系统kubeadm安装K8S_v1.27.x容器使用docker(K8S_v1.24版本以后依然使用docker容器管理)
kubeadm安装K8S_v1.27.x容器使用docker 按照需要的文档点击这里下载 一.环境部署 1.1基础环境配置 主机IP 主机名规划 192.168.186.128 k8s-master01 192.168.186.129 k8s-node01 192.168.186.130 k8s-node02 1.2修改机器名称 #永久修改主机名 hostnamectl set-hostname …...

如何使用索引加速 SQL 查询 [Python 版]
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑器的3D应用场景 假设您正在筛选一本书的页面。而且您希望更快地找到所需的信息。你是怎么做到的?好吧,您可能会查找术语索引,然后跳转到引用特定术语的页面。SQL 中的索引的工作方…...

Oracle 开发篇+Java通过DRCP访问Oracle数据库
标签:DRCP、Database Resident Connection Pooling、数据库驻留连接池释义:DRCP(全称Database Resident Connection Pooling)数据库驻留连接池(Oracle自己的数据库连接池技术) ★ Oracle开启并配置DRCP sq…...
在安装 ONLYOFFICE 协作空间社区版时如何使用额外脚本参数
ONLYOFFICE 协作空间社区版是免费的文档中心工具,可帮助您将用户与文档聚合至同一处,提高协作效率。 ONLYOFFICE 协作空间主要功能 使用 ONLYOFFICE 协作空间,您可以: 邀请他人,协作和沟通完成工作创建协作房间&…...

ChatGPT在智能家居控制和环境管理中的应用如何?
智能家居控制和环境管理是近年来在科技领域迅速发展的重要领域之一。智能家居技术通过将物联网、人工智能和自动化技术相结合,实现了家居设备的智能化、自动化控制和远程管理。ChatGPT作为强大的自然语言处理模型,在智能家居控制和环境管理方面具有广泛的…...
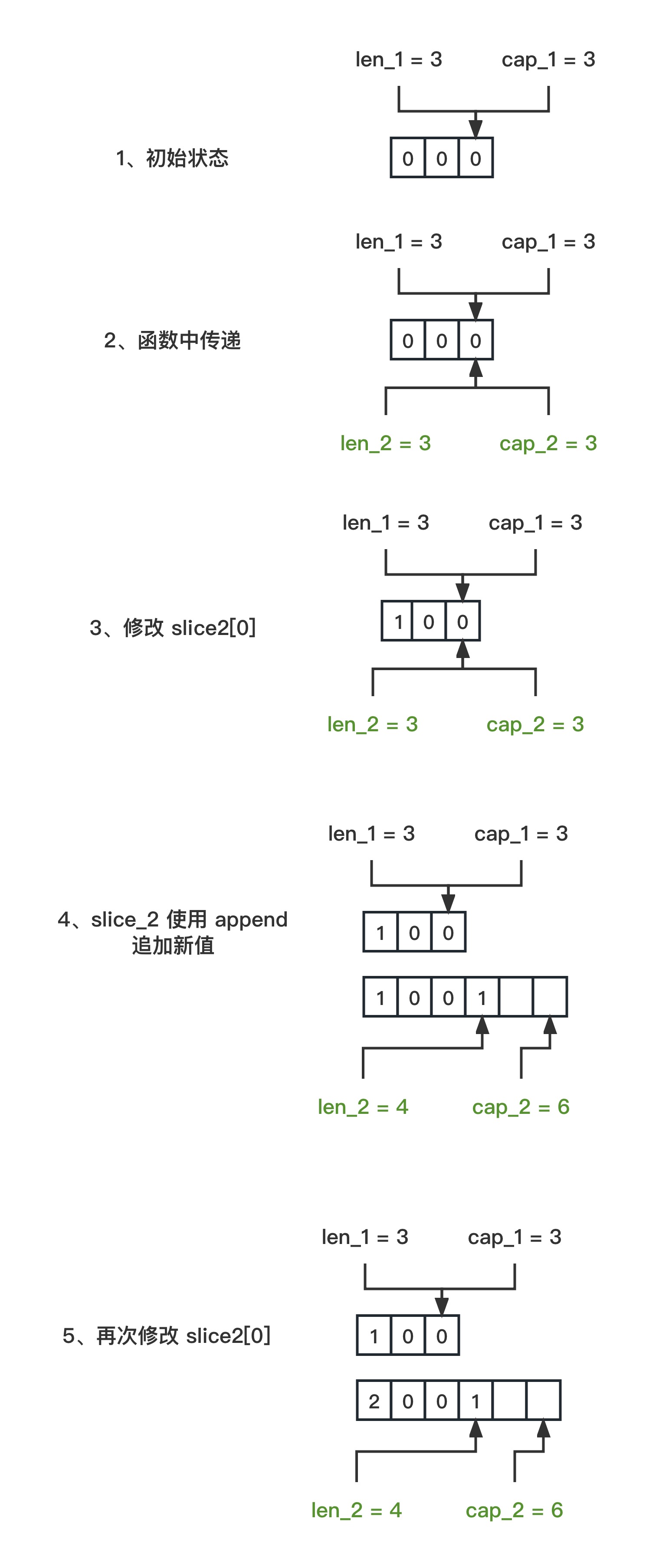
理解 Go 中的切片:append 操作的深入分析(篇2)
理解 Go 语言中 slice 的性质对于编程非常有益。下面,我将通过代码示例来解释切片在不同函数之间传递并执行 append 操作时的具体表现。 本篇为第 2 篇,当切片的容量 cap 不够时 func main() {// slice1 当前长度为 3,容量大小也为 3slice1 :…...

GPT-4 如何为我编写测试
ChatGPT — 每个人都在谈论它,每个人都有自己的观点,玩起来很有趣,但我们不是在这里玩— 我想展示一些实际用途,可以帮助您节省时间并提高效率。 我在本文中使用GPT-4 动机 我们以前都见过这样的情况——代码覆盖率不断下降的项目——部署起来越来越可怕,而且像朝鲜一样…...
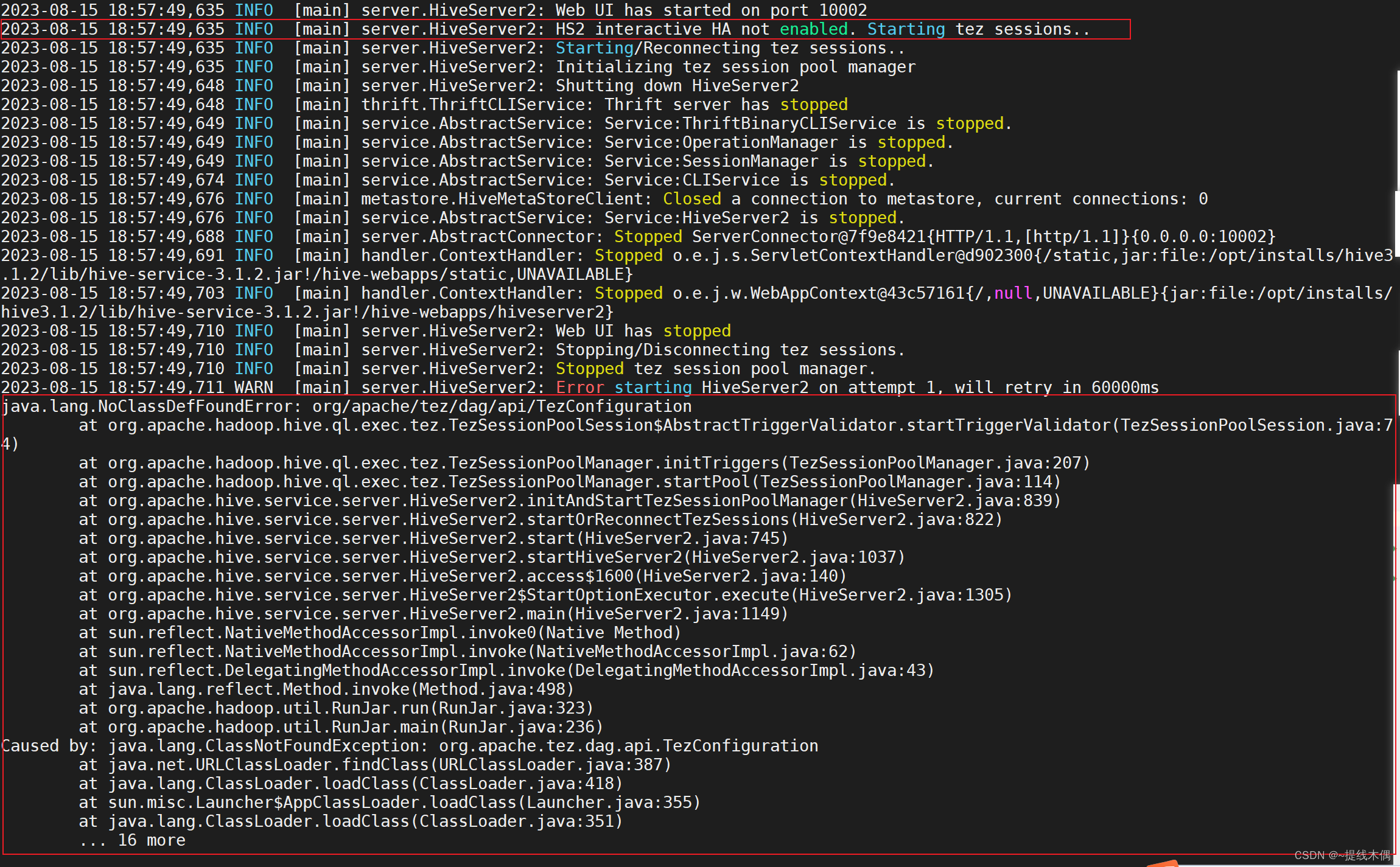
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration
错误: java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfigurationat org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolSession$AbstractTriggerValidator.startTriggerValidator(TezSessionPoolSession.java:74)at org.apache.hadoop.hive.ql.e…...

19、SQL注入之SQLMAP绕过WAF
目录 逻辑层1、逻辑问题2、性能问题 白名单方式一:IP白名单方式二:静态资源方式三:url白名单方式四: 爬虫白名单 sqlmap在测试漏洞的时候,选择了no,它就不会去测试其它的了,我们一般选择yes,为了…...

Redis对象类型和结构、内存回收、对象共享
对象类型和结构 在Redis中,无论是键key还是值value都是一个对象,每次对Redis数据库创建一个新的键值对时,就至少会创建两个对象。 常见的对象类型有: 字符串列表哈希集合有序集合 这些对象在Redis中统一用一个结构体redisObjec…...

标准模板库STL——容器适配器-stack/queue/priority_queue
目录 容器适配器的理解 容器适配器的实现与使用 三类容器适配器 基本概述 示例代码 容器适配器的理解 容器适配器对底层容器进行封装,不具备自己的数据结构 容器适配器的方法全都由底层容器实现,不支持迭代器 容器适配器的实现与使用 // 容器适配器…...
)
Golang实现完整聊天室(内附源码)
项目github地址: 由于我们项目的需要,我就研究了一下关于websocket的相关内容,去实现一个聊天室的功能。 经过几天的探索,现在使用Gin框架实现了一个完整的聊天室消息实时通知系统。有什么不完善的地方还请大佬指正。 用到的技术…...
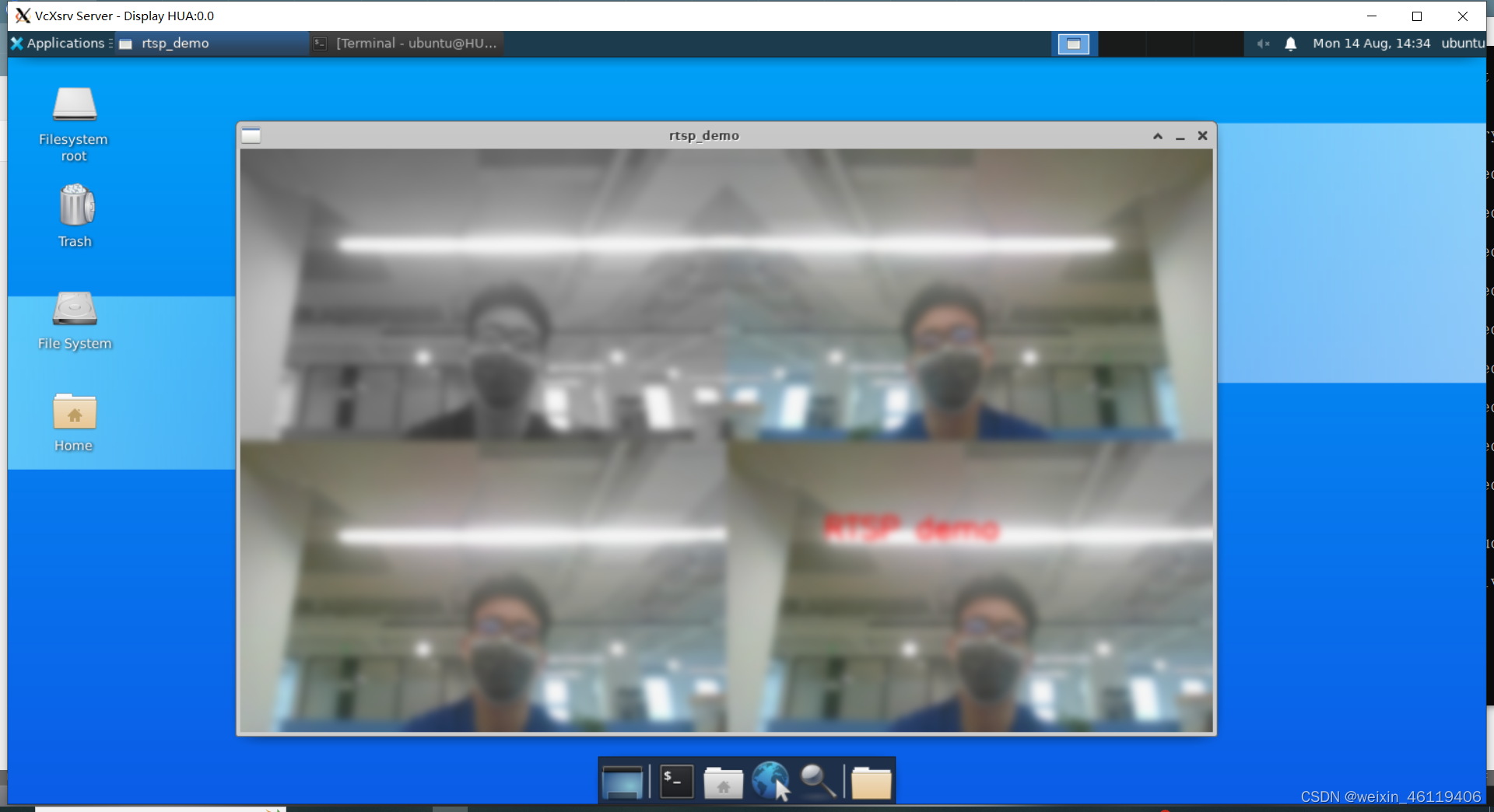
WSL2 ubuntu子系统OpenCV调用本机摄像头的RTSP视频流做开发测试
文章目录 前言一、Ubuntu安装opencv库二、启动 Windows 本机的 RTSP 视频流下载解压 EasyDarwin查看本机摄像头设备开始推流 三、在ubuntu 终端编写代码创建目录及文件创建CMakeLists.txt文件启动 cmake 配置并构建 四、结果展示启动图形界面在图形界面打开终端找到 rtsp_demo运…...
20230814让惠普(HP)锐14 新AMD锐龙电脑不联网进WIN11进系统
20230814让惠普(HP)锐14 新AMD锐龙电脑不联网进WIN11进系统 2023/8/14 17:19 win11系统无法跳过联网 https://www.xpwin7.com/jiaocheng/28499.html Win11开机联网跳过不了怎么办?Win11开机联网跳过不了解决方法 Win11开机联网跳过不了怎么办?Win11开机…...

基于ScrollView的下拉刷新
基于ScrollView的下拉刷新 组件使用 组件 import React, {useState} from react; import {ScrollView, RefreshControl, Platform} from react-native;const RefreshComponent ({children, onRefresh, onScroll}) > {const [refreshing, setRefreshing] useState(false);…...
强训第31天
选择 传输层叫段 网络层叫包 链路层叫帧 A 2^16-2 C D C 70都没收到,确认号代表你该从这个号开始发给我了,所以发70而不是71 B D C 248&123120 OSI 物理层 数据链路层 网络层 传输层 会话层 表示层 应用层 C 记一下304读取浏览器缓存 502错误网关 编…...

什么是Java中的策略模式?
Java中的策略模式是一种行为设计模式,它允许您在不改变客户端代码的情况下,在运行时动态地切换行为。这是一种非常有用的模式,因为它允许您在运行时根据需要更改算法或行为。 策略模式通常涉及到一个或多个策略类,每个策略类都实…...

【Visual Studio Code】--- Win11 安装 VS Code 超详细
Win11 安装 VS Code 超详细 概述一、下载 Vscode二、安装 Vscode 概述 一个好的文章能够帮助开发者完成更便捷、更快速的开发。书山有路勤为径,学海无涯苦作舟。我是秋知叶i、期望每一个阅读了我的文章的开发者都能够有所成长。 一、下载 Vscode Vscode官网 二、…...

对比直接使用官方api与通过taotoken接入后的网络连接稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 与通过 Taotoken 接入后的网络连接稳定性体验 1. 引言 在开发基于大语言模型的应用程序时,一个…...

用知识图谱重构搜索引擎
一、传统搜索:关键词的“机械匹配”时代你输入词,它找文档我们熟悉的搜索引擎,无论是早期的Google还是百度的首页,核心逻辑都是关键词匹配。你输入“苹果热量”,它就把互联网里包含“苹果”和“热量”两个词的网页抓出…...

Windows平台苹果USB网络共享驱动自动化部署方案
Windows平台苹果USB网络共享驱动自动化部署方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap/Apple-Mob…...
)
从厨房小白到AI大模型高手:小白程序员也能轻松掌握大模型的秘密(收藏版)
本文旨在打破对AI大模型的刻板印象,用通俗易懂的语言解释AI大模型的工作原理,并通过实例教学,帮助读者从零开始掌握AI大模型的应用。文章涵盖了AI大模型的基本概念、提示词工程、RAG技术、函数调用、智能体构建、微调与部署等关键知识点&…...

3步找出谁删了你:微信好友检测神器使用指南
3步找出谁删了你:微信好友检测神器使用指南 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是一个…...

BarrageGrab:如何构建企业级跨平台直播数据采集系统?
BarrageGrab:如何构建企业级跨平台直播数据采集系统? 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播…...

在数据分析和报告自动化场景中集成Taotoken调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据分析和报告自动化场景中集成Taotoken调用大模型 数据分析与报告生成是许多团队日常工作中的高频任务。传统流程中࿰…...

小爱音箱音乐播放限制破解实战:从基础配置到高级玩法深度解析
小爱音箱音乐播放限制破解实战:从基础配置到高级玩法深度解析 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经对着小爱音箱说"播放周杰伦…...

Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞
Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞 【免费下载链接】Sub-Zero.bundle Subtitles for Plex, as good you would expect them to be. 项目地址: https://gitcode.com/gh_mirrors/su/Sub-Zero.bundle Sub-Zero是Plex媒体服务器最强大的字幕插件之…...

中兴光猫工厂模式智能解锁:3步获得完全控制权限
中兴光猫工厂模式智能解锁:3步获得完全控制权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾因中兴光猫的限制而无法进行高级网络配置?是否在需要深…...