gulimall-缓存-缓存使用
文章目录
- 前言
- 一、本地缓存与分布式缓存
- 1.1 使用缓存
- 1.2 本地缓存
- 1.3 本地模式在分布式下的问题
- 1.4 分布式缓存
- 二、整合redis测试
- 2.1 引入依赖
- 2.2 配置信息
- 2.3 测试
- 三、改造三级分类业务
- 3.1 代码改造
- 四、高并发下缓存失效问题
- 4.1 缓存穿透
- 4.2 缓存雪崩
- 4.3 缓存击穿
- 五、分布式下加锁
- 5.1 分布式锁示意图
- 5.2 锁的时序问题
前言
本文继续记录B站谷粒商城项目视频 P151-157 的内容,做到知识点的梳理和总结的作用。
一、本地缓存与分布式缓存
1.1 使用缓存
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落盘工作。
哪些数据适合放入缓存?
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
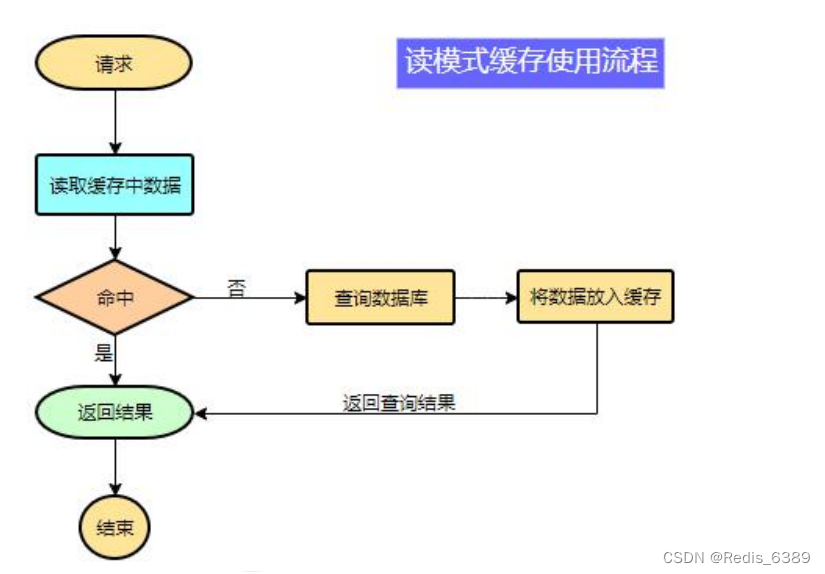
伪代码
data = redisTemplate.opsForValue().get(redisKey);//从缓存加载数据
If(data == null){//缓存中没有则从数据库加载数据data = db.getDataFromDB(id);//保存到 cache 中redisTemplate.opsForValue().set(redisKey,data);
}
return data;
1.2 本地缓存
在单体项目中,我们可以使用 Map 集合存储数据作为项目的本地缓存,因为 Map 数据是存储与内存的,相比于数据库查询要从磁盘加载到内存有着更高的效率。
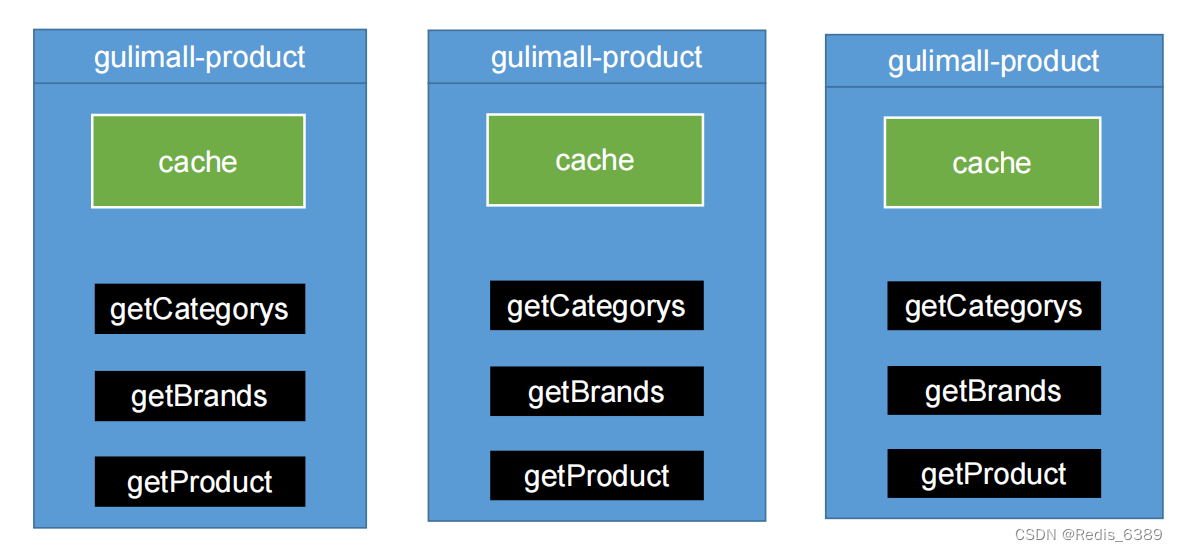
1.3 本地模式在分布式下的问题
但是在分布式情况下这种情况就不再适用了,每个微服务可能部署在多台机器上,每个机器上有各自的缓存 Map 对象,会导致数据不一致的问题。
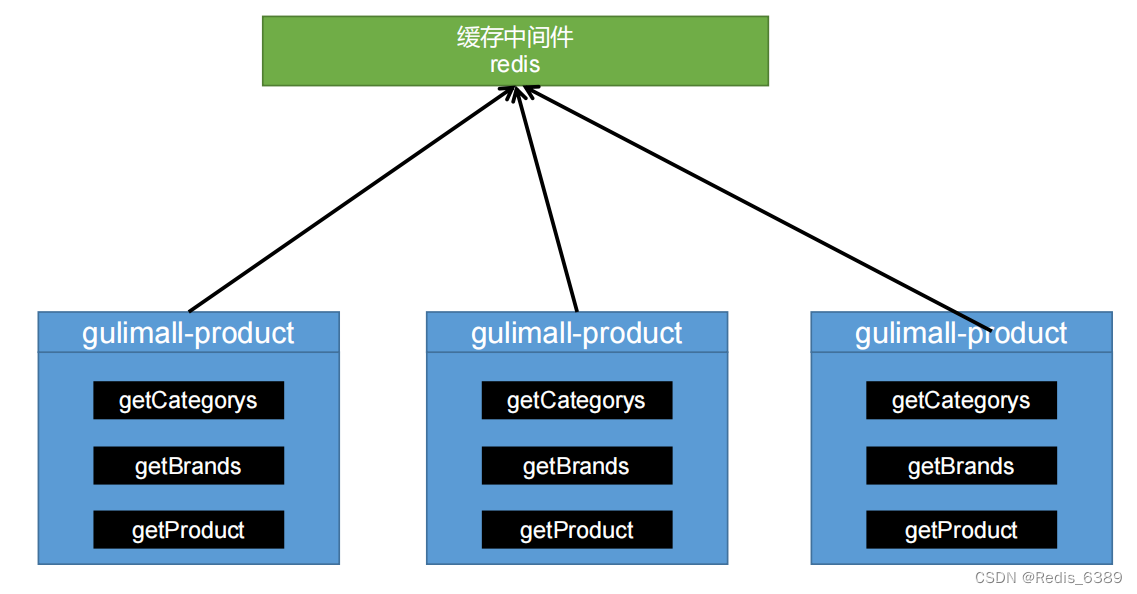
1.4 分布式缓存
所以应该将数据缓存在同一个缓存中间件中,才能保证数据一致性问题
二、整合redis测试
2.1 引入依赖
<!-- 缓存中间件redis依赖-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.2 配置信息
spring:redis:host: 192.168.57.129port: 6379
2.3 测试
@Autowired
StringRedisTemplate redisTemplate;@Test
public void testRedis() {//存储redisTemplate.opsForValue().set("HELLO_REDIS", "SpringBoot!");//获取String value = redisTemplate.opsForValue().get("HELLO_REDIS");System.out.println(value);
}

三、改造三级分类业务
3.1 代码改造
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {//给缓存中放json字符串,拿出的json字符串,还用逆转为能用的对象类型:【序列化与反序列化】/*** 1、空结果缓存:解决缓存穿透* 2、设置过期时间(加随机值):解决缓存雪崩* 3、加锁:解决缓存击穿*///1、加入缓存逻辑,缓存中存的数据是json字符串。//JSON跨语言,跨平台兼容。String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");if (StringUtils.isEmpty(catalogJSON)) {//2、缓存中没有,查询数据库//保证数据库查询完成以后,将数据放在redis中,这是一个原子操作。log.info("缓存不命中....将要查询数据库...");Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDB();String result = JSON.toJSONString(catalogJsonFromDb);redisTemplate.opsForValue().set("catalogJSON",result);}log.info("缓存命中....直接返回....");//转为我们指定的对象。return JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {});
}
四、高并发下缓存失效问题
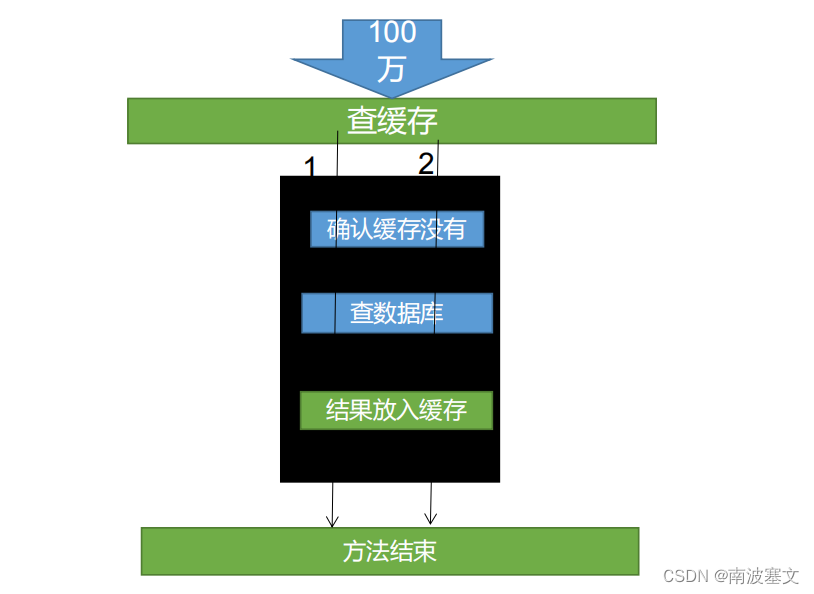
4.1 缓存穿透

解决方案1:null 结果放入缓存,并加入短暂的过期时间
伪代码
//从缓存加载数据
data = redisTemplate.opsForValue().get(redisKey);
If(data == null){//缓存中没有则从数据库加载数据data = db.getDataFromDB(id);if(data == null) {//空结果保存到 cache 中redisTemplate.opsForValue().set(redisKey,null,300,TimeUnit.SECONDS);}else {//保存到 cache 中redisTemplate.opsForValue().set(redisKey,data);}
}
return data;
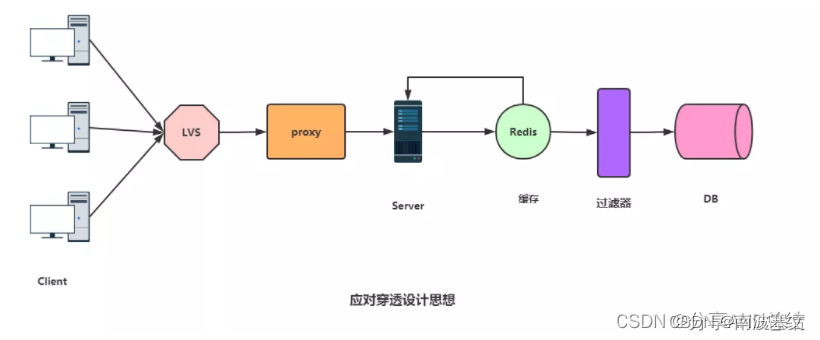
解决方案2:使用布隆过滤器
这种技术在缓存之前再加一层屏障,里面存储目前数据库中存在的所有key。当业务系统有查询请求的时候,首先去BloomFilter中查询该key是否存在。若不存在,则说明数据库中也不存在该数据,因此缓存都不要查了,直接返回null。若存在,则继续执行后续的流程,先前往缓存中查询,缓存中没有的话再前往数据库中的查询。伪代码如下:
String get(String key) {String value = redis.get(key); if (value == null) {if(!bloomfilter.mightContain(key)){//不存在则返回return null; }else{//可能存在则查数据库value = db.get(key); redis.set(key, value); } }return value;
}
布隆过滤器示意图
4.2 缓存雪崩

4.3 缓存击穿

五、分布式下加锁
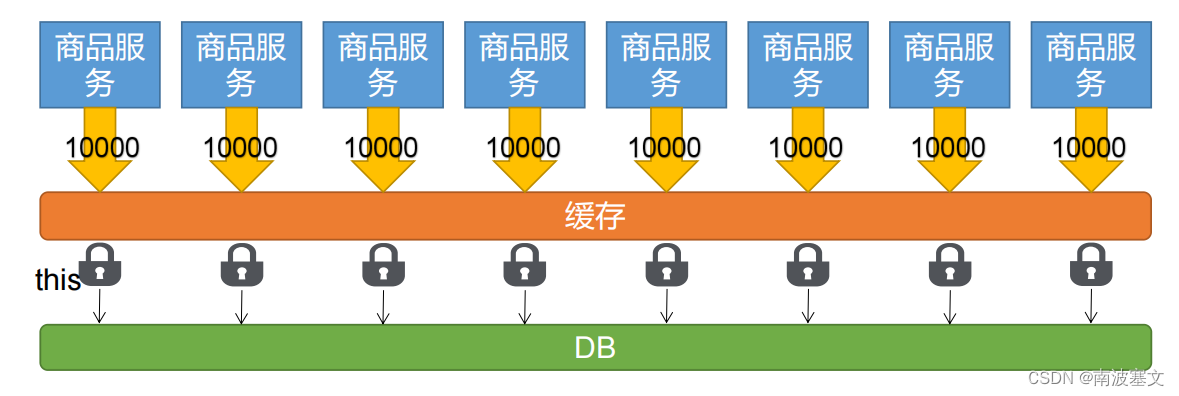
5.1 分布式锁示意图
本地锁,只能锁住当前进程,所以我们需要分布式锁。
5.2 锁的时序问题
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {//给缓存中放json字符串,拿出的json字符串,还用逆转为能用的对象类型:【序列化与反序列化】/*** 1、空结果缓存:解决缓存穿透* 2、设置过期时间(加随机值):解决缓存雪崩* 3、加锁:解决缓存击穿*///1、加入缓存逻辑,缓存中存的数据是json字符串。//JSON跨语言,跨平台兼容。String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");if (StringUtils.isEmpty(catalogJSON)) {//2、缓存中没有,查询数据库//保证数据库查询完成以后,将数据放在redis中,这是一个原子操作。log.info("缓存不命中....将要查询数据库...");Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDB();return catalogJsonFromDb;}log.info("缓存命中....直接返回....");//转为我们指定的对象。return JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {});
}
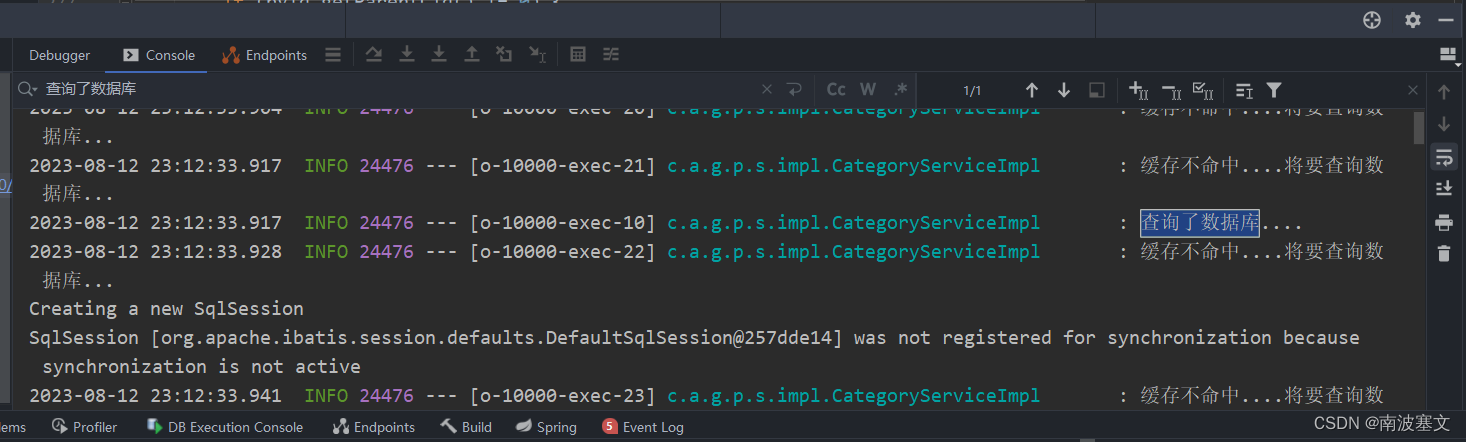
查询数据库后将结果放入缓存,保证这是一个原子性操作,防止多个线程查询数据库而导致日志输出多个查询了数据库…
//从数据库查询并封装分类数据
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDB() {//只要同一把锁,就能锁住需要这个锁的所有线程//synchronized (this):springBoot所有组件在容器中都是单实例的//TODO 本地锁:synchronized JUC(Lock) 在分布式情况下只能使用分布式锁才能锁住资源synchronized (this) {//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");if (!StringUtils.isEmpty(catalogJSON)) {return JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {});}log.info("查询了数据库....");//1、将数据库的多次查询变为一次,查询所有分类信息List<CategoryEntity> selectList = baseMapper.selectList(null);//1、查出所有1级分类List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);//2、封装数据Map<String, List<Catelog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1、每一个的一级分类,查到这个一级分类的二级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());//2、封装上面的结果List<Catelog2Vo> catelog2Vos = null;if (categoryEntities != null) {catelog2Vos = categoryEntities.stream().map(l2 -> {Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());//1、找当前二级分类的三级分类封装成voList<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());if (level3Catelog != null) {List<Catelog2Vo.Catelog3Vo> collect = level3Catelog.stream().map(l3 -> {//2、封装成指定格式Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return catelog3Vo;}).collect(Collectors.toList());catelog2Vo.setCatalog3List(collect);}return catelog2Vo;}).collect(Collectors.toList());}return catelog2Vos;}));String result = JSON.toJSONString(parent_cid);redisTemplate.opsForValue().set("catalogJSON",result,1,TimeUnit.DAYS);return parent_cid;}
}
压力测试结果:日志只输出一个查询了数据库…,表面只有一个线程查询了数据库。
相关文章:
gulimall-缓存-缓存使用
文章目录 前言一、本地缓存与分布式缓存1.1 使用缓存1.2 本地缓存1.3 本地模式在分布式下的问题1.4 分布式缓存 二、整合redis测试2.1 引入依赖2.2 配置信息2.3 测试 三、改造三级分类业务3.1 代码改造 四、高并发下缓存失效问题4.1 缓存穿透4.2 缓存雪崩4.3 缓存击穿 五、分布…...

概述、搭建Redis服务器、部署LNP+Redis、创建Redis集群、连接集群、集群工作原理
Top NSD DBA DAY09 案例1:搭建redis服务器案例2:常用命令限案例3:部署LNPRedis案例4:创建redis集群 1 案例1:搭建redis服务器 1.1 具体要求如下 在主机redis64运行redis服务修改服务运行参数 ip 地址192.168.88.6…...

redis数据类型与底层数据结构对应关系
对应关系如下 SDSZipListHashTableQuickListintsetSkipListString✔Hash✔✔List✔Set✔✔Zset✔✔ String SDS Hash ZipList 对应对象编码 OBJ_ENCODING_ZIPLIST HashTable 对应对象编码 OBJ_ENCODING_HT 当一个Hash对象的键值对数据量增加到一定数量时就会触发编码转换…...
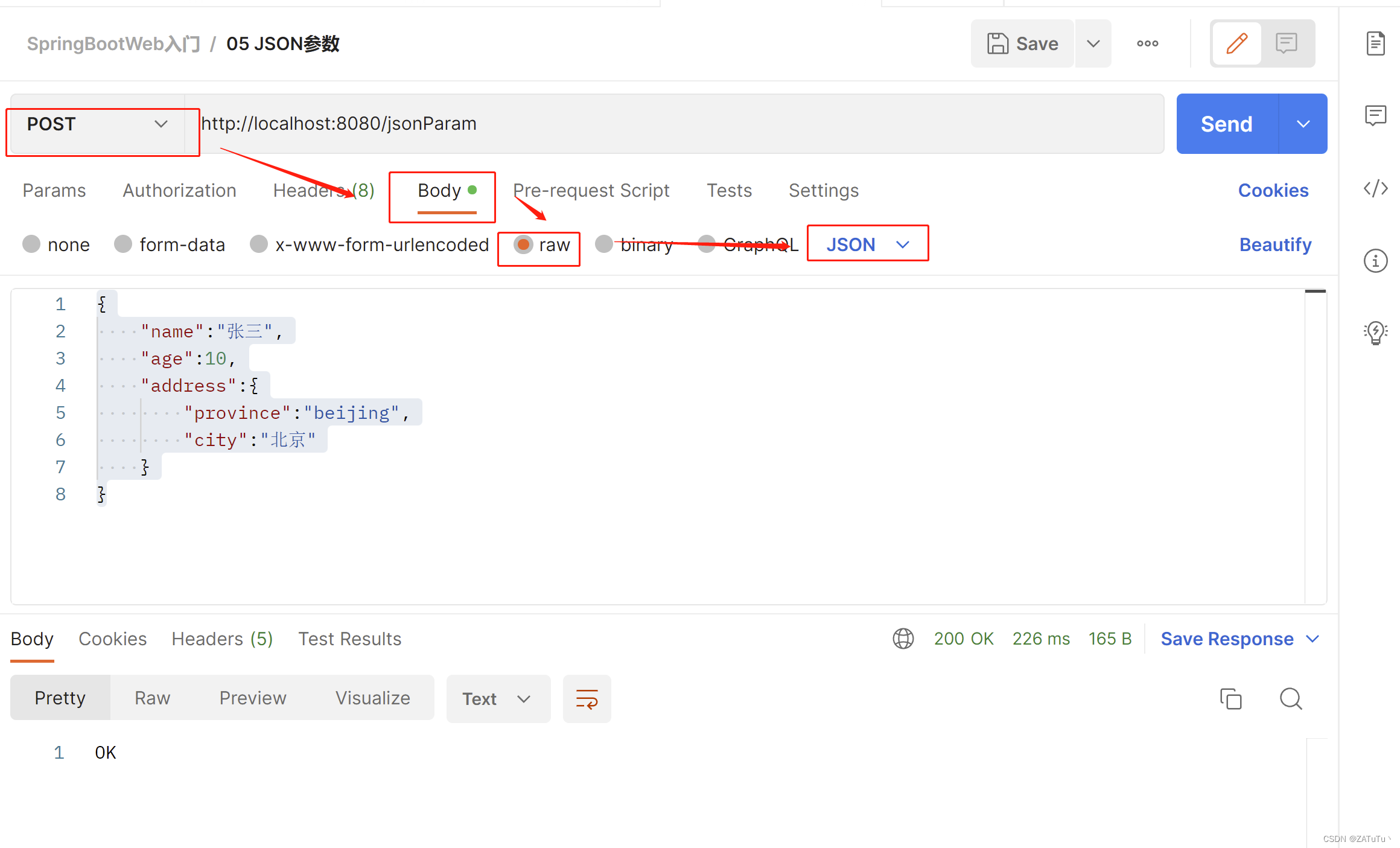
SpringBoot请求响应
简单参数 1. 原始方式获取请求参数 Controller方法形参中声明httpServletRequest对象 调用对象的getParameter参数名 RestController public class RequestController {RequestMapping("/simpleParam")public String simpleParam(HttpServletRequest request){Strin…...
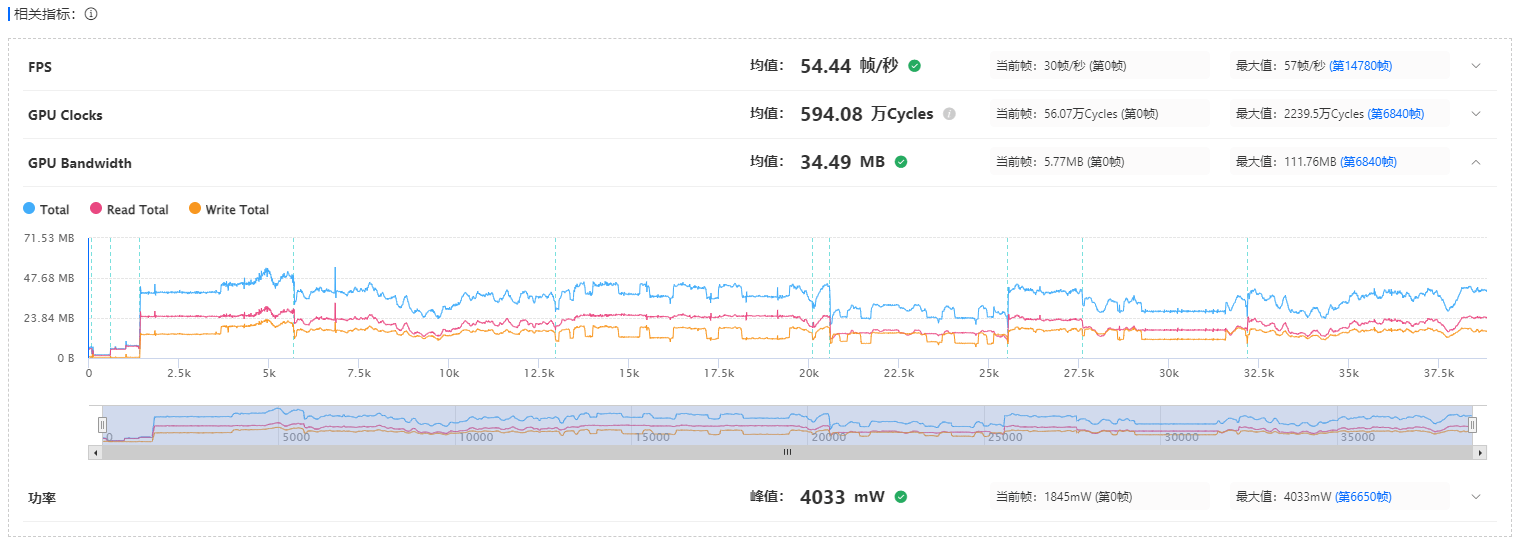
功能上新|全新GPU性能优化方案
GPU优化迎来了全新的里程碑!我们深知移动游戏对高品质画面的追求日益升温,因此UWA一直着眼于移动设备GPU性能优化,以确保您的游戏体验尽善尽美。然而,不同GPU芯片之间的性能差异及可能导致的GPU瓶颈问题,让优化工作变得…...
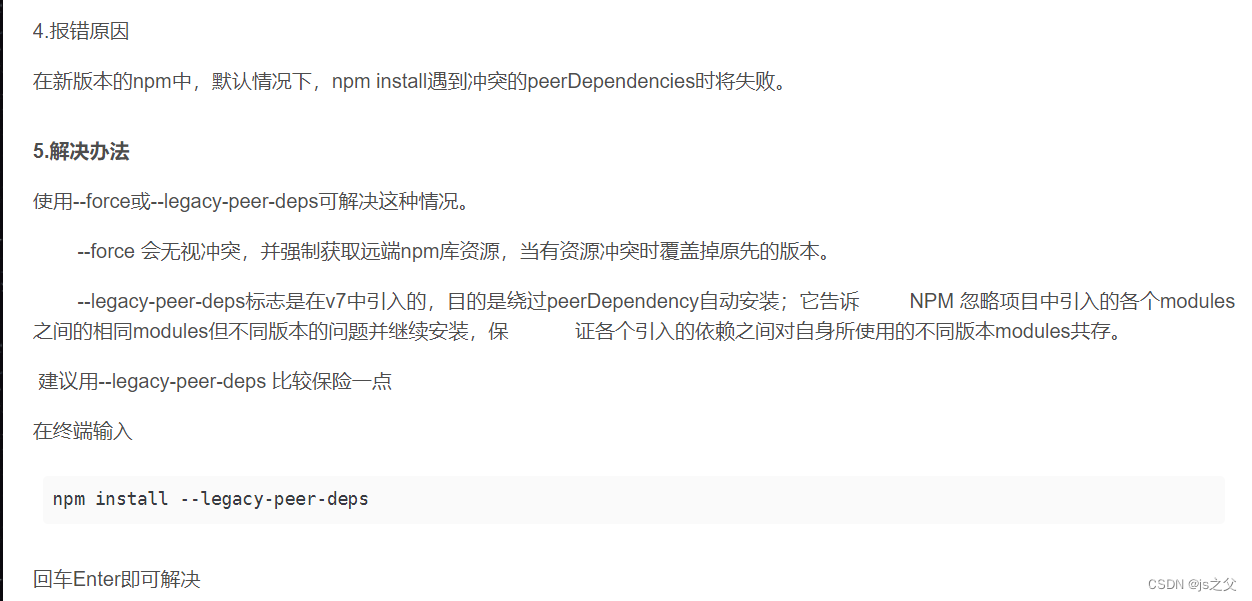
试岗第一天问题
1、公司的一个项目拉下来 ,npm i 不管用显示 后面百度 使用了一个方法 虽然解决 但是在增加别的依赖不行,后面发现是node版本过高,更换node版本解决。 2、使用插件动态的使数字从0到100(vue-animate-number插件) 第一…...

2023-08-15力扣每日一题
链接: 833. 字符串中的查找与替换 题意: n组操作,其中第i组: 检查 子字符串 sources[i] 是否出现在 原字符串 s 的索引 indices[i] 处。如果没有出现, 什么也不做 。如果出现,则用 targets[i] 替换 该子…...
)
Java单例模式详解(五种实现方式)
1、什么是单例模式? Java单例模式是一种设计模式,用于确保一个类只有一个实例,并提供全局访问点以获取该实例。它通常用于需要共享资源或控制某些共享状态的情况下。 例如: 一个日志记录器(Logger)。在一个…...
【javaweb】学习日记Day1 - HTML CSS入门
目录 一、图片标签 ① 绝对路径 1.绝对磁盘路径 2.绝对网络路径 ② 相对路径 (推荐) 二、标题标签 三、水平线标签 四、标题样式 1、CSS引入样式 ① 行内样式 ② 内嵌样式 ③ 外嵌样式 2、CSS选择器 ① 元素选择器 ② id选择器 ③…...
贴吧照片和酷狗音乐简单爬取
爬取的基本步骤 很简单,主要是两大步 向url发起请求 这里注意找准对应资源的url,如果对应资源不让程序代码访问,这里可以伪装成浏览器发起请求。 解析上一步返回的源代码,从中提取想要的资源 这里解析看具体情况,一…...

Databend 开源周报第 106 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 数据脱敏 Data…...

Mysql中使用存储过程插入decimal和时间数据递增的模拟数据
场景 Mysql插入数据从指定选项中随机选择、插入时间从指定范围随机生成、Navicat使用存储过程模拟插入测试数据: Mysql插入数据从指定选项中随机选择、插入时间从指定范围随机生成、Navicat使用存储过程模拟插入测试数据_mysql循环插入随机数据_霸道流氓气质的博客…...
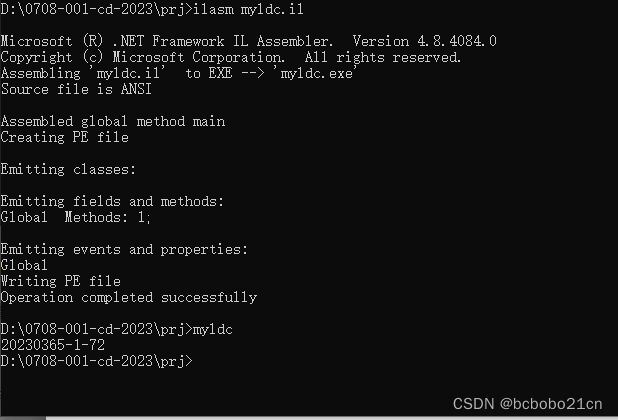
IL汇编ldc指令学习
ldc指令是把值送到栈上, 说明如下, ldc.i4 将所提供的int32类型的值作为int32推送到计算堆栈上; ldc.i4.0 将数值0作为int32推送到计算堆栈上; ... ldc.i4.8 将数值8作为int32推送到计算堆栈上; ldc.i4.m1 将数值-…...
【Redis基础篇】浅谈分布式系统(一)
一、浅谈分布式系统 1. 单机架构:只有一台服务器,这个服务器负责所有的工作。 如果遇到了服务器不够的场景怎么处理? 开源:增加更多的硬件资源节流:软件上的优化,优化代码等…一台服务器资源使用有限,就…...

CSS中的calc()函数有什么作用?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ CSS中的calc()函数及其作用⭐ 作用⭐ 示例1. 动态计算宽度:2. 响应式布局:3. 自适应字体大小:4. 计算间距: ⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点…...

由浅入深学习Tapable
文章目录 由浅入深学习TapableTapable是什么Tapable的Hook分类同步和异步的 使用Sync*同步类型钩子基本使用bailLoopWaterfall Async*异步类型钩子ParallelSeries 由浅入深学习Tapable webpack有两个非常重要的类:Compiler和Compilation。他们通过注入插件的方式&a…...
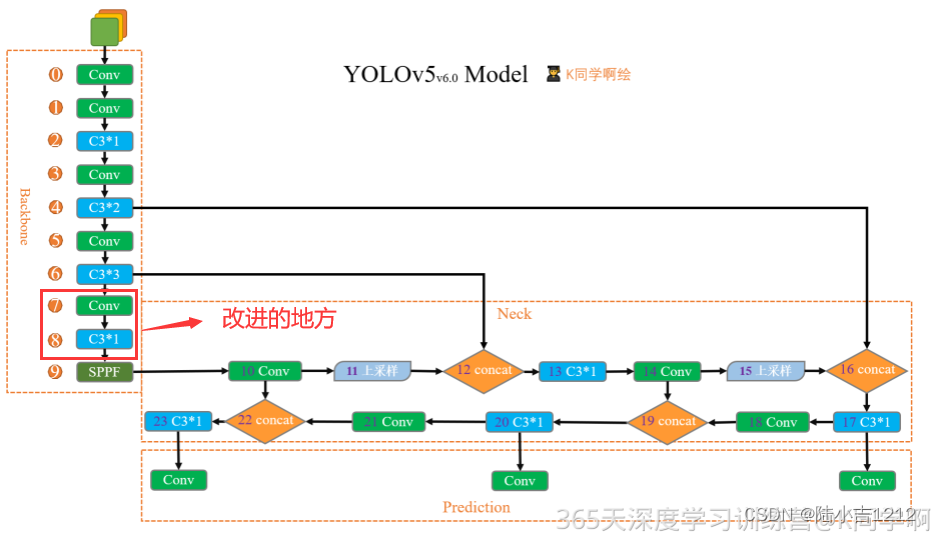
YOLOv5白皮书-第Y6周:模型改进
📌本周任务:模型改进📌 注:对yolov5l.yaml文件中的backbone模块和head模块进行改进。 任务结构图: YOLOv5s网络结构图: 原始模型代码: # YOLOv5 v6.0 backbone backbone:# [from, number, module, args]…...
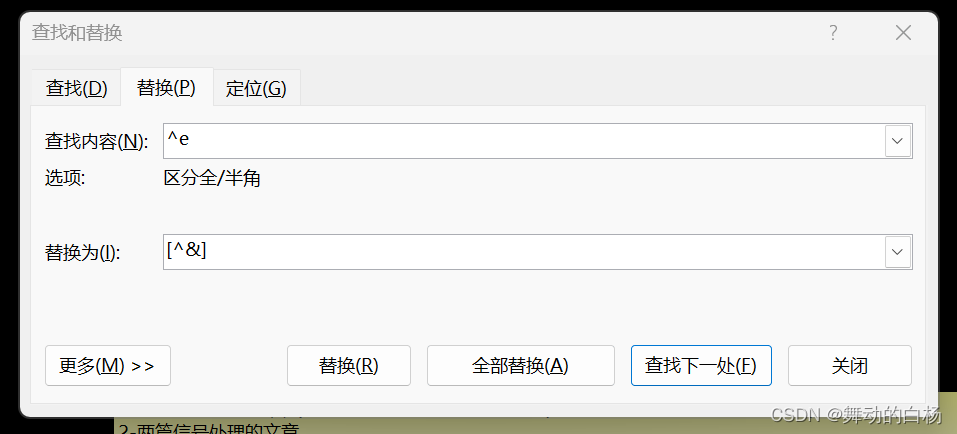
word之插入尾注+快速回到刚才编辑的地方
1-插入尾注 在编辑文档时,经常需要对一段话插入一段描述或者附件链接等,使用脚注经常因占用篇幅较大导致文档页面内容杂乱,这事可以使用快捷键 ControlaltD 即可在 整个行文的末尾插入尾注,这样文章整体干净整洁,需…...
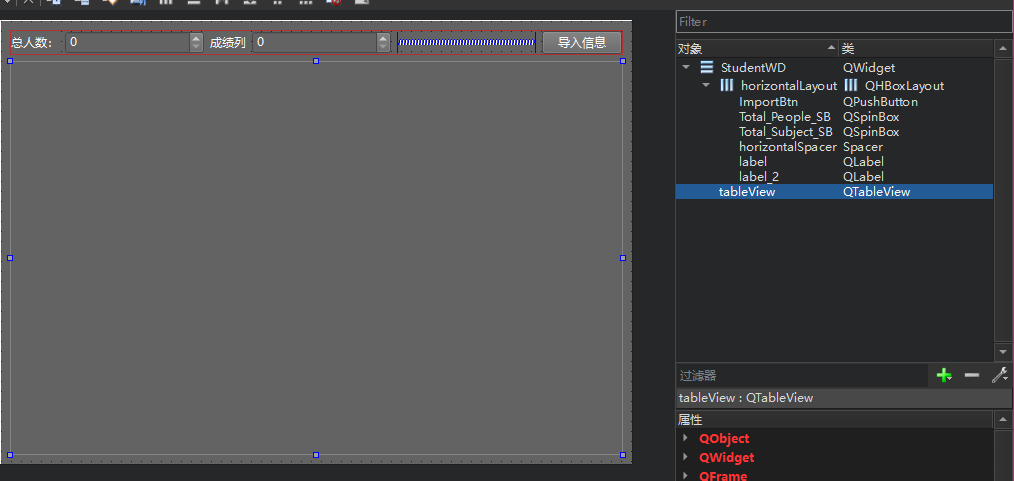
Qt扫盲-QTableView理论总结
QTableView理论总结 一、概述二、导航三、视觉外观四、坐标系统五、示例代码1. 性别代理2. 学生信息模型3. 对应视图 一、概述 QTableView实现了一个tableview 来显示model 中的元素。这个类用于提供之前由QTable类提供的标准表,但这个是使用Qt的model/view架构提供…...
从外部访问K8s中Pod的五种方式
hostNetwork、 hostPort、 NodePort、 LoadBalancer、 Ingress 暴露Pod与Service一样,因为Pod就是Service的backend 1、hostNetwork:true 这是一种直接定义 Pod 网络的方式。 如果在 Pod 中使用 hostNetwork:true 配置, pod 中运行的应用程序…...

软件测试会被AI取代吗?我用数据告诉你真相
在探讨“取代”之前,我们先看一组具有代表性的数据。根据Gartner的预测,到2027年,80%的企业将把AI驱动的测试工具整合进其测试流程中,目前这一比例仅为大约20%。与此同时,World Quality Report显示,过去五年…...

红队实战信息收集:从域名枚举到攻击链路建模
1. 这不是教科书里的“信息收集”,而是红队进现场前真正要干的活 你拿到一个目标域名,比如 example.com,老板说:“先摸清家底,别急着打。” 这时候,90%的人会立刻打开终端敲 nmap -sV example.com &…...

第37天:SQL详解之DDL
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、SQL概述 1.1 建库建表 1.2 DDL关键注意事项 二、存储引擎对比 三、数据类型选择 四、删除表和修改表 4.1 删除表 4.2 修改表 总结 前言 在前一篇文章中,我们了解了关系型…...
)
常用shell命令总结(Linux命令)
当前目录 .上一级目录 …根目录,或者是目录拼接符 /管道符(左侧输出作为右侧输入) |上一个命令的返回码 $?或 ||且 &&cat 查看文档 cat XX.txt加权限 chmod x 文件 chmod 777 文件改变文件的所有者 chown newowner file.txt改变文件…...

Taotoken用量看板与成本管理功能实操体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能实操体验 在将多个大模型API集成到实际项目中时,除了对接的便利性,团队往往…...

乐聚智能拟募资26亿冲击创业板,人形机器人商业化初期盈利难题待解
乐聚智能冲击创业板,投后估值43.27亿近日,乐聚智能(深圳)股份有限公司向深交所递交招股书,拟在创业板上市,保荐人为东方证券。乐聚智能是首家选择使用创业板第四套标准申请上市的企业,该标准要求…...

Layerdivider:AI智能分层工具完整指南 - 快速将单张图片转为分层PSD
Layerdivider:AI智能分层工具完整指南 - 快速将单张图片转为分层PSD 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一个革命性…...

免ROOT使用Frida:Android合规调试的底层原理与四条落地路径
1. 这不是“越狱式”调试,而是一条被低估的合规路径 很多人一听到 Frida,第一反应就是“得先 root 手机”“得 patch apk”“得重打包签名”——仿佛不撬开系统大门,就进不了应用内存。我最初也这么想,直到在某次金融类 App 的灰…...

Upscayl Windows编译深度解析:从Vulkan初始化失败到成功构建的专业指南
Upscayl Windows编译深度解析:从Vulkan初始化失败到成功构建的专业指南 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl…...

3步快速定位:哪个程序偷走了你的Windows快捷键?
3步快速定位:哪个程序偷走了你的Windows快捷键? 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...