【数据分析】pandas (三)
基本功能
在这里,我们将讨论pandas数据结构中常见的许多基本功能
让我们创建一些示例对象:
index = pd.date_range(“1/1/2000”, periods=8)
s = pd.Series(np.random.randn(5), index=[“a”, “b”, “c”, “d”, “e”]).
df = pd.DataFrame(np.random.randn(8, 3), index=index, columns=[“A”, “B”, “C”])
head 和 tail
要查看一个Series或DataFrame对象的部分内容,可以使用head()和tail()方法。要显示的元素的默认数量是5个,但是可以传递一个自定义的数字。
一般head为前面5行,tail为后面5行
long_series = pd.Series(np.random.randn(1000))
long_series.head()
0 -1.157892
1 -1.344312
2 0.844885
3 1.075770
4 -0.109050
dtype: float64long_series.tail(3)
997 -0.289388
998 -1.020544
999 0.589993
dtype: float64
属性和基础数据
Pandas对象具有许多属性,使您能够访问元数据
- shape给出对象的轴尺寸,与narray一致
- Axis label:
Series:索引(仅轴)
DataFrame:索引(行)和列
df
df[:2]
A B C2000-01-01 0.646715 -0.533237 0.512050
2000-01-02 0.473347 -1.401934 -0.101406
2000-01-03 -1.736713 0.793529 0.600978
2000-01-04 -0.105295 -0.154846 -0.121468
2000-01-05 0.740262 0.009942 0.508145
2000-01-06 0.152475 0.010283 0.599246
2000-01-07 1.909515 -0.662262 1.074580
2000-01-08 -2.146941 -1.081284 0.282604A B C2000-01-01 0.646715 -0.533237 0.512050
2000-01-02 0.473347 -1.401934 -0.101406
pandas的对象(index,Series,DataFrame)可以被认为是数组的容器,他保存实际数据并进行实际计算。对于许多数据类型,底层数组是numpy.ndarry。但是pandas和第三方库可能会扩展Numpy的类型系统以添加对自定义数组的支持。
要获取 Index 或 Series中的数据,使用==.arry==
s
a 0.591348
b -0.209001
c 0.632891
d -0.148446
e -0.161156
dtype: float64
s.array
PandasArray
[ 0.4691122999071863, -0.2828633443286633, -1.5090585031735124,
-1.1356323710171934, 1.2121120250208506]
Length: 5, dtype: float64
s.index,array
PandasArray
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]
Length: 5, dtype: object
如果你需要一个Numpy数组,使用to_numpy()或者numpy.asarray()
s.to_numpy()
[out]:
array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
np.asarray(s)
[out]
array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
to_numpy()对numpy.ndarry的结果有一些控制,例如,考虑带时区的日期时间。numpy没有dtype,来表示具有时区意识的日期时间,所以有两种可能有用的表示:
- numpy.ndarray带有Timestamp对象,每一个都有正确的tz
- 一个datetime64[ns] dtype numpy.ndarray,其中的值在转化为UTC和时区是被丢弃。
时区可以使用dtype=object
In [14]: ser = pd.Series(pd.date_range(“2000”, periods=2, tz=“CET”))
In [15]: ser.to_numpy(dtype=object)
Out[15]:
array([Timestamp(‘2000-01-01 00:00:00+0100’, tz=‘CET’),
Timestamp(‘2000-01-02 00:00:00+0100’, tz=‘CET’)], dtype=object)
或者丢弃 dtype=‘datetime64[ns]’
In [16]: ser.to_numpy(dtype=“datetime64[ns]”)
Out[16]:
array([‘1999-12-31T23:00:00.000000000’, ‘2000-01-01T23:00:00.000000000’],
dtype=‘datetime64[ns]’)
Merage,join,concatenate and compare
pandas提供了各种工具,可以在连接/合并类型操作的情况下,轻松地将Series或DataFrame与用于索引和关系代数功能的各种集合逻辑组合在一起。
此外,pandas还提供了比较两个Series或DataFrame并总结其差异的实用程序
连接对象
**concat()**功能(在主pandas名称空间中)完成沿一个轴执行连接操作的所有繁重工作,同时在其他轴上执行索引(如果有的话)可选集合逻辑。下面给一个简单的示例:
df1 = pd.DataFrame(
{
“A”: [“A0”, “A1”, “A2”, “A3”],
“B”: [“B0”, “B1”, “B2”, “B3”],
“C”: [“C0”, “C1”, “C2”, “C3”],
“D”: [“D0”, “D1”, “D2”, “D3”],
},
index=[0, 1, 2, 3],
)df2 = pd.DataFrame(
{
“A”: [“A4”, “A5”, “A6”, “A7”],
“B”: [“B4”, “B5”, “B6”, “B7”],
“C”: [“C4”, “C5”, “C6”, “C7”],
“D”: [“D4”, “D5”, “D6”, “D7”],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
“A”: [“A8”, “A9”, “A10”, “A11”],
“B”: [“B8”, “B9”, “B10”, “B11”],
“C”: [“C8”, “C9”, “C10”, “C11”],
“D”: [“D8”, “D9”, “D10”, “D11”],
},
index=[8, 9, 10, 11],
)
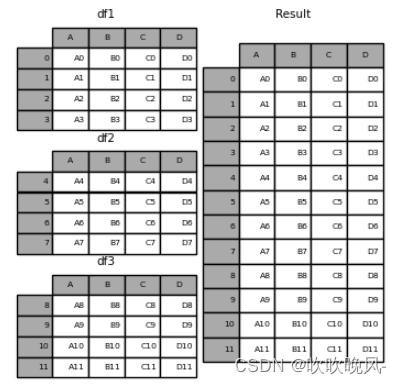
frames = [df1, df2, df3]
result = pd.concat(frames)
pd.concat(
objs,
axis=0,
join=“outer”,
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)
- objs:一个Series或者一个DataFrame对象的序列或映射,如果传递了dict,则将排序后的键用作keys参数,除非传递了dict,在这种情况下将选择值(见下文)。任何None对象都将被静默丢弃,除非它们都是None,在这种情况下会引发ValueError
- axis:{0,1,…} 默认为0 表示连接的轴
- join:{’ inner ', ’ outer ‘},默认为’ outer '。如何处理其他轴上的索引。外为并,内为交
- ignore_index:boolean,默认为False。如果为True,则不要使用连接轴上的索引值。生成的轴将被标记为0,…,n - 1。如果您正在连接对象,其中连接轴没有有意义的索引信息,则这很有用。注意,在连接中仍然尊重其他轴上的索引值。
- keys:顺序,默认为None,使用传递的键作为最外层构建分层索引。如果通过了多个级别,则应该包含元组。
- levels:序列列表,默认为None。用于构造MultiIndex的特定级别(惟一值)。否则,它们将从键中推断出来。
- names:生成的层次索引中级别的名称。
- verify_integrity:boolean,默认为False。检查新连接的轴是否包含重复项。相对于实际的数据连接,这可能非常昂贵。
- copy:boolean,默认为True。如果为False,则不要复制不必要的数据。
result = pd.concat(frames, keys=[“x”, “y”, “z”])
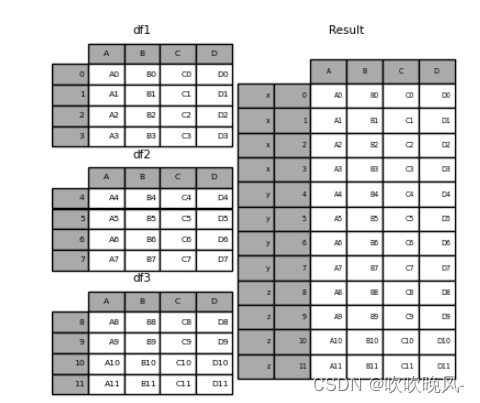
result.loc[“y”]
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
值得注意的是,concat()生成数据的完整副本,并且不断重用该函数可能会对性能造成重大影响。如果需要在多个数据集上使用操作,请使用列表推导式。
在其他轴上设置逻辑
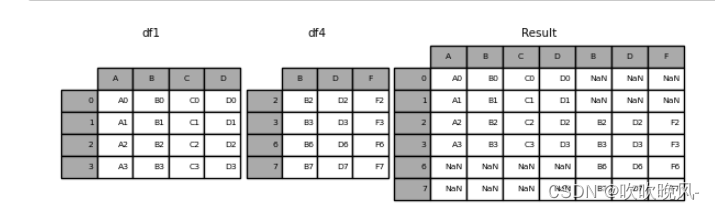
将多个 DataFrame 粘合在一起时,您可以选择如何处理其他轴(除了连接的轴之外)。这可以通过以下两种方式完成:
- 将它们全部结合起来,join=‘outer’. 这是默认选项,因为它的结果为零
- 采取交叉路口,join=‘inner’。
以下是每种方法的示例。首先,默认join=‘outer’ 行为:
In [8]: df4 = pd.DataFrame(
…: {
…: “B”: [“B2”, “B3”, “B6”, “B7”],
…: “D”: [“D2”, “D3”, “D6”, “D7”],
…: “F”: [“F2”, “F3”, “F6”, “F7”],
…: },
…: index=[2, 3, 6, 7],
…: )
…:
In [9]: result = pd.concat([df1, df4], axis=1)
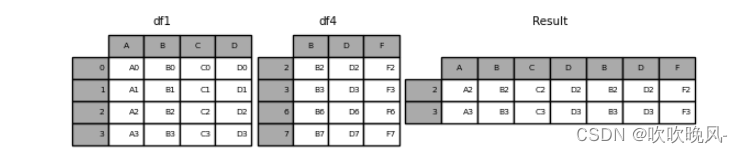
这里也是一样的join=‘inner’:
In [10]: result = pd.concat([df1, df4], axis=1, join=“inner”)
append
pd.append() 函数专门用于在 dataframe 对象后 添加新的行,如果添加的列名不在 dataframe 对象中,将会被当作新的列进行添加。
s = pd.DataFrame(np.random.randn(5,3), index=[“a”, “b”, “c”, “d”, “e”],columns=[“A”, “B”, “C”])
s2 = pd.DataFrame(np.random.randn(5,3), index=[“a”, “b”, “c”, “d”, “e”],columns=[“B”, “E”, “F”])
A B Ca 0.457078 1.023073 -0.562775
b 1.298108 -0.759387 0.524104
c -2.316800 -1.842333 -0.027894
d 1.588192 -0.024175 0.554156
e 1.881850 -0.979311 -1.519555
B E F
a 0.382541 1.595857 1.304981
b 1.924457 0.115844 0.495387
c -1.054523 0.170910 -0.299745
d 0.754534 0.392500 -0.675588
e -0.269393 1.920908 0.899837
a=s.append(s2,sort=True)

相关文章:
【数据分析】pandas (三)
基本功能 在这里,我们将讨论pandas数据结构中常见的许多基本功能 让我们创建一些示例对象: index pd.date_range(“1/1/2000”, periods8) s pd.Series(np.random.randn(5), index[“a”, “b”, “c”, “d”, “e”]). df pd.DataFrame(np.random.…...

nvm命令
1. 常见命令 1. nvm -v //查看nvm版本 nvm --version :显示 nvm 版本 2. nvm list //显示版本列表 nvm list :显示已安装的版本(同 nvm list installednvm list installed:显示已安装的版本nvm list available:显示所有…...

从此已是义无反顾
距离上次发这个专栏的文章已经过去了十多天,现在我已经开始准备面试内容,迟迟还没有投出第一份简历,只是因为我感觉对知识点的理解还不到位,于是开始一边看JavaGuide老师总结的面试题目,一边翻看以前学习的笔记&#x…...
Element组件浅尝辄止2:Card卡片组件
根据官方说法: 将信息聚合在卡片容器中展示。 1.啥时候使用?When? 既然是信息聚合的容器,那场景就好说了 新建页面时可以用来当做页面容器页面的某一部分,可以用来当做子容器 2.怎样使用?How? //Card …...

“深入剖析Java多态:点燃编程世界火花“
White graces:个人主页 🙉专栏推荐:Java入门知识🙉 🙉 内容推荐:“继承与组合:代码复用的两种策略“🙉 🐹今日诗词:马踏祁连山河动,兵起玄黄奈何天🐹 快去学习 🌸思维导…...

golang官方限流器rate包实践
日常开发中,对于某些接口有请求频率的限制。比如登录的接口、发送短信的接口、秒杀商品的接口等等。 官方的golang.org/x/time/rate包中实现了令牌桶的算法。 封装限流器可以将ip、手机号这种的作为限流器组的标识。 接下来就是实例化限流器和获取令牌函数的实现…...
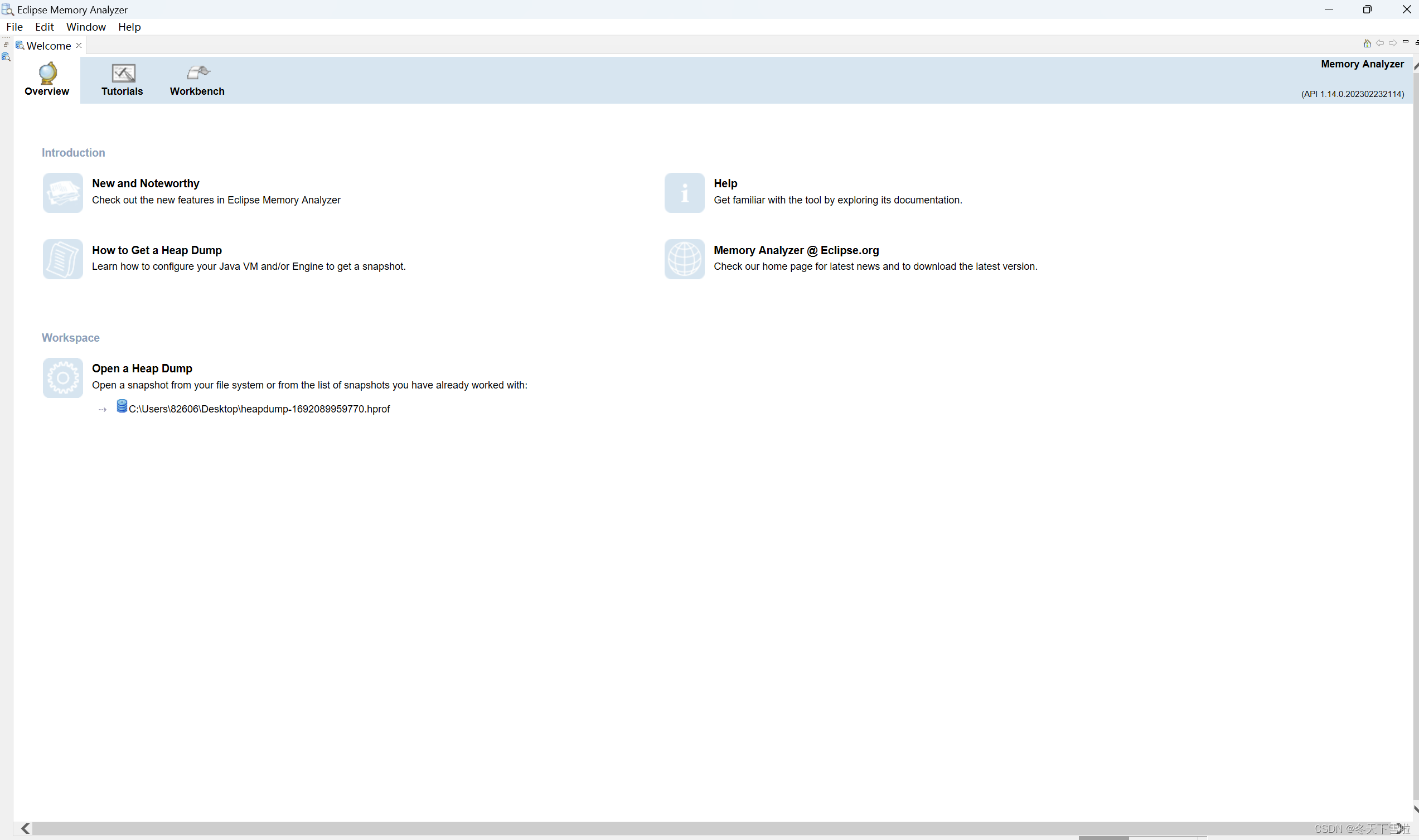
[windows]MAT- 下载及安装
1. 下载安装包 1.1MAT下载链接: https://pan.baidu.com/s/1sUWPITSto8MjOrcF0BsJQg?pwd1111 提取码:1111 1.2MAT需要jdk17版本及以上支持,下载链接: https://pan.baidu.com/s/111jz90S4tie_48lQeExcZg?pwd1111 提取码:1…...

数组模拟环形队列详解
数组模拟环形队列 实现逻辑 创建一个固定大小的数组作为队列的存储空间,同时定义队列的头部和尾部指针(front和rear)。初始时,将头部和尾部指针都设置为0,表示队列为空。入队操作(enqueue)&am…...

《论文阅读12》RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
一、论文 研究领域:全监督3D语义分割(室内,室外RGB,kitti)论文:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds CVPR 2020 牛津大学、中山大学、国防科技大学 论文链接论文gi…...
elementPlus使用el-icon
安装 # NPM $ npm install element-plus/icons-vue # Yarn $ yarn add element-plus/icons-vue # pnpm $ pnpm install element-plus/icons-vue一、main.ts(全局注册) import * as ElementIcons from element-plus/icons-vuefor (const key in Element…...
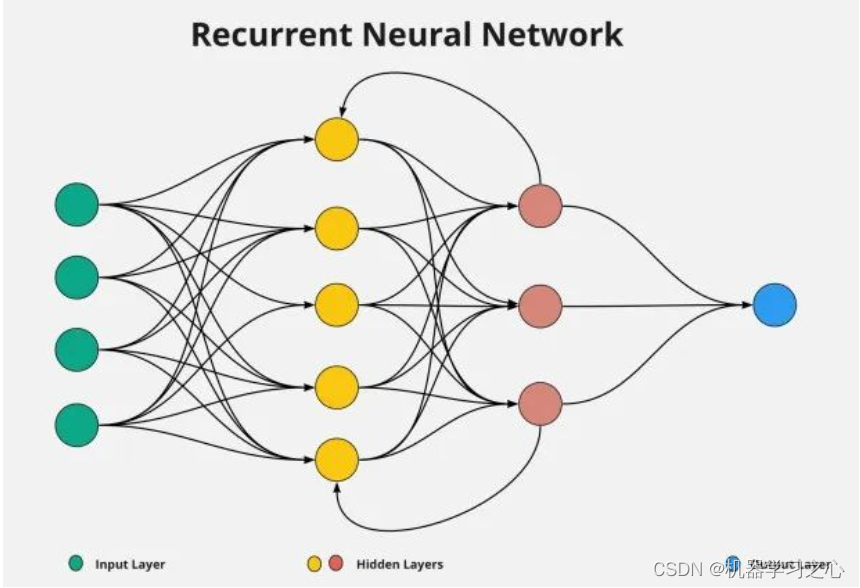
预测知识 | 神经网络、机器学习、深度学习
预测知识 | 预测技术流程及模型评价 目录 预测知识 | 预测技术流程及模型评价神经网络机器学习深度学习参考资料 神经网络 神经网络(neural network)是机器学习的一个重要分支,也是深度学习的核心算法。神经网络的名字和结构,源自…...
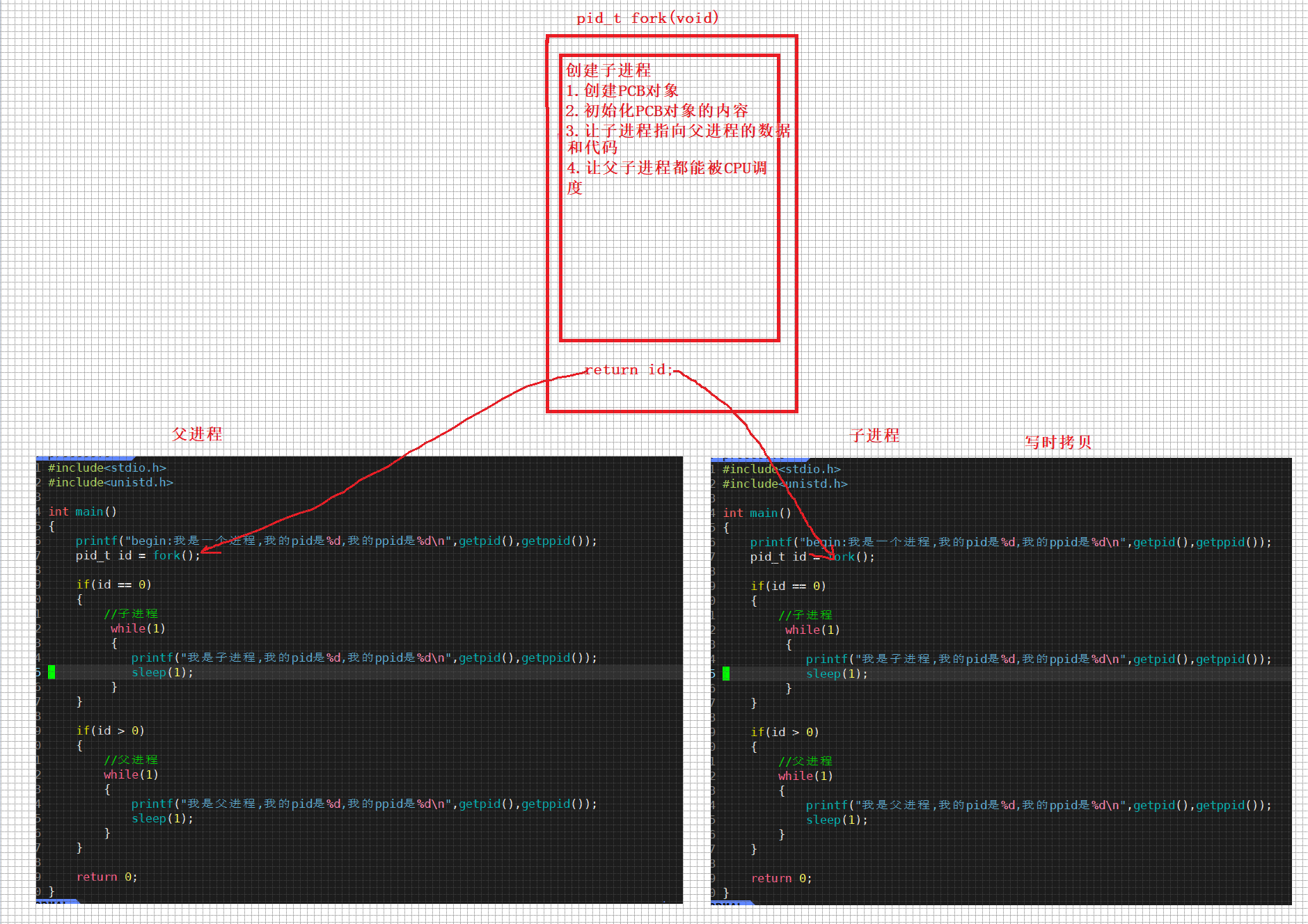
【Linux】进程的基本属性|父子进程关系
个人主页:🍝在肯德基吃麻辣烫 我的gitee:Linux仓库 个人专栏:Linux专栏 分享一句喜欢的话:热烈的火焰,冰封在最沉默的火山深处 文章目录 前言进程属性1.进程PID和PPID2.fork函数创建子进程1)为什…...
)
CCF考试:201809-1 卖菜(java代码)
目录 1、【问题描述】 2、【思路分析】 3、【代码区】 1、【问题描述】 在一条街上有n个卖菜的商店,按1至n的顺序排成一排,这些商店都卖一种蔬菜。 第一天,每个商店都自己定了一个价格。店主们希望自己的菜价和其他商店的一致…...

android wifi扫描 framework层修改扫描间隔
frameworks/opt/net/wifi/service/java/com/android/server/wifi/ScanRequestProxy.java 这个也就是说前台应用可以在120s(2分钟) 扫描 4 次 * a) Each foreground app can request a max of* {link #SCAN_REQUEST_THROTTLE_MAX_IN_TIME_WINDOW_FG_APPS} scan every* {l…...
webstorm debug调试vue项目
1.运行npm,然后控制台会打印下图中的地址,复制local的地址 2.run–>Edit Configuration,如下图 3.设置测试项 4.在你需要的js段打好断点 5.在上边框的工具栏里面有debug运行,点击debug运行的图标运行即可...

嵌入式linux的八股文之旅 DAY1
1 三次握手 四次挥手 服务端 先从close到listen 然后第一个syn报文 客户端 生成初始序列号 client_isn (就是iternal sequence number 初始序列号) 然后放到TCP首部的序列号端里 然后把SYN标志位置一 然后发送给服务器端 之后处于SYN-SENT状态 服务器…...

同创永益郑阳|与数智化共舞·业务稳定性保障新动力
2023年8月2日,由北大创新评论主办的2023 Inno China中国产业创新大会-保险产业创新论坛在京举办。本次论坛由同创永益、青牛软件、DaoCloud道客联合主办,INNO创新家、产业集群发展提供战略支持,未名数创承办,邀请到了学术专家、行…...

史上最全的Qt控件
本软件是收费工具,学生党勿扰,闹眼子党勿扰,白嫖党勿扰 收费金额:1000元 1 概述 经过这两年的编写,写不少控件,甚至把刘某某90%的控件都绘制了一遍。当然后还有一些其他刘某没有控件。 2 功能 借用刘某博…...

星星之火:国产讯飞星火大模型的实际使用体验(与GPT对比)
#AIGC技术内容创作征文|全网寻找AI创作者,快来释放你的创作潜能吧!# 文章目录 1 前言2 测试详情2.1 文案写作2.2 知识写作2.3 阅读理解2.4 语意测试(重点关注)2.5 常识性测试(重点关注)2.6 代码…...
传输控制协议TCP
目录 TCP报文格式 TCP的特点 TCP原理: 1.确认应答机制 2.超时重传机制 3.连接管理机制 建立连接 编辑关闭连接 4.滑动窗口机制 5.流量控制 6.拥塞控制 7.延迟应答 8.捎带应答 TCP报文格式 1.源端口号:发送端的哪一个端口发出的 2.目的端口号:接收端的哪一个端…...

阿伐曲泊帕常见副作用头痛及疲劳的临床特征与管理
头痛与疲劳是阿伐曲泊帕治疗慢性肝病相关血小板减少症时患者报告频率最高的两项非肝脏系统不良反应。两项副作用虽极少直接危及生命,却实实在在地侵蚀着患者的日常功能与长期治疗依从性。ADAPT-1与ADAPT-2两项三期临床试验的完整安全性数据,为这两项副作…...

专业影像场景优选:三大维度拆解分析高速稳定CFexpress存储卡如何保障拍摄顺利
文章概览:从工程视角看CFexpress存储卡选型在专业影像制作中,存储卡不仅仅是数据载体,更是整个工作流中的关键节点。针对高强度8K视频录制、RAW格式连拍、不可重拍场景下数据安全等核心诉求,本文对市场上主流CFexpress存储卡进行工…...

TI IWR6843ISK-ODS雷达固件开发环境搭建:从MATLAB Runtime到CCS的保姆级避坑指南
TI IWR6843ISK-ODS雷达固件开发环境搭建实战手册 毫米波雷达技术正在智能感知领域掀起革命浪潮,而德州仪器(TI)的IWR6843ISK-ODS评估板因其出色的集成度和性价比,成为众多开发者进入这一领域的首选平台。然而,从硬件拆封到第一个雷达点云成功…...

EMD vs NEMD:分子动力学算热导率,新手到底该选哪个?
EMD与NEMD方法实战指南:如何为你的热导率计算选择最佳方案 在纳米材料和新型功能材料的研究中,热导率的精确计算是理解材料热输运性能的关键。面对平衡态分子动力学(EMD)和非平衡态分子动力学(NEMD)两种主流方法,许多研究者常常陷入选择困境。…...

Kubernetes Operator开发实战
Kubernetes Operator开发实战 一、Operator概述 Kubernetes Operator是一种软件扩展模式,用于管理复杂的有状态应用。 1.1 Operator模式 ┌──────────────────────────────────────────────────────────…...

HC32F4A0外设引脚自由配置全攻略:如何像STM32重映射一样灵活规划你的原理图?
HC32F4A0外设引脚自由配置全攻略:如何像STM32重映射一样灵活规划你的原理图? 在嵌入式硬件设计中,引脚规划往往是决定项目成败的关键第一步。传统MCU如STM32通过固定功能引脚和有限的重映射功能,给工程师带来诸多限制。而华大半导…...

告警爆炸,根因定位困难?用DevOps Agent帮你自动查!
随着企业在亚马逊云科技上的工作负载日益复杂——Amazon EC2集群、Amazon RDS数据库、Amazon ECS/EKS容器、Amazon Lambda函数、网络与负载均衡等多种服务交织运行——运维团队面临严峻挑战:告警爆炸:Amazon CloudWatch、第三方监控(Datadog、…...

物联网数据采集网关实战:从协议解析到边缘计算的完整指南
1. 项目概述:从“黑盒子”到“数据枢纽”的蜕变 在物联网的世界里,传感器是感知世界的“神经末梢”,而物联网网关,则是连接这些神经末梢与云端大脑的“神经中枢”。很多人觉得它像个神秘的黑盒子,插上线,数…...

AI 智能体 8 层架构:生产级系统构建指南
AI 智能体(Agentic AI)革命的关键不在更好的提示词,而在于系统化的架构设计。随着企业竞相部署能够自主感知、推理、规划和行动的 AI 智能体(AI Agent),真正的挑战已经从"我们能构建吗?“转变为"…...
)
保姆级教程:在VMware上安装BCLinux for Euler 21.10最小化系统(附镜像校验与网络配置)
虚拟化环境实战:BCLinux for Euler 21.10最小化系统部署全指南 在云计算和容器化技术盛行的今天,本地虚拟化环境仍然是开发者进行系统测试、软件验证的重要工具。BCLinux for Euler作为一款针对企业级场景优化的Linux发行版,其21.10版本在性能…...