MySQL相关面试题
文章目录
- union 和 unionAll 的区别?
- drop、delete与truncate的区别 ?
- sql 语句如何优化 ?
- 什么是事务 ?
- 事务的四个特性(ACID) ?
- 事务的隔离级别?
- 索引主要有哪几种分类 ?
- 什么时候适合添加索引,哪些列适合添加索引 ?
- 索引的设计原则 ?
- 索引的数据结构有哪些 ?
- 为什么B+树比B树更适合实现数据库索引 ?
- B 树和 B+树的区别?为什么 Mysql 使⽤B+树 ?
- 什么情况会使索引失效 ?
- MyISAM 和 InnoDB 的区别 ?
- MyISAM和InnoDB使用的锁?
- 从锁的分类来说,MySQL都有哪些锁?
- 行级锁和表级锁对比 ?
- 什么是死锁?如何解决?
- 数据库的乐观锁和悲观锁是什么?怎么实现的?
- 乐观锁和悲观锁的使用场景 ?
- 索引的三种常见底层数据结构以及优缺点 ?
- 什么是redo log日志 ?
- 什么是binlog日志 ?
- 什么是undo log日志 ?
- 什么是 MVCC 以及实现 ?
- 什么是主从复制 ?
- 主从复制的作用 ?
union 和 unionAll 的区别?
union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序
unionAll: 对两个结果集进行并集操作,包括重复行,不进行排序
drop、delete与truncate的区别 ?
相同点:
truncate和不带where子句的delete,以及drop都会删除表内的数据
不同点:
-
truncate会清除表数据并重置id从1开始,delete就只删除记录,drop可以用来删除表或数据库并且将表所占用的空间全部释放
-
truncate和delete只删除数据不删除表的结构。drop语句将删除表的结构被依赖的约(constrain),触发器(trigger),依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
-
速度上一般来说: drop> truncate > delete
-
使用上,想删除部分数据行用 delete,想删除表用 drop,想保留表而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,或者想触发trigger,还是用delete。
-
delete是DML语句,不会自动提交。drop/truncate都是DDL语句,执行后会自动提交。
sql 语句如何优化 ?
1.建议少用*代替所有列名
2.用 exists 代替 in
3.多表连接时,尽量减少表的查询次数
4.删除全表数据的时候用 truncate 代替 delete
5.sql 语句尽量大写,Oracle 会默认把小写转换成大写在执行
6.优化 group by,将不需要的数据尽量在分组之前过滤掉
7.连表查询的时候尽量使用表的别名,减少解析时间
8.表连接在 where 之前,where 条件过滤顺序,能够更多的过滤数据的放在前面
9.合理使用索引
什么是事务 ?
事务是由一条或多条操作数据库的SQL组成的一个不可分割的工作单元,这些操作要么全部执行成功,要么全部失败。
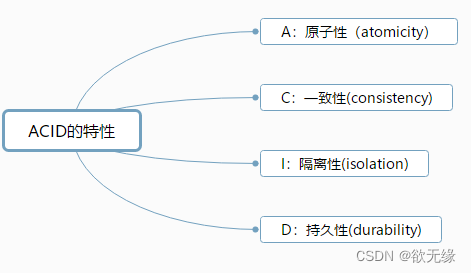
事务的四个特性(ACID) ?
-
原子性: 要么全部执行成功,要么全部执行失败
-
一致性: 在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
-
隔离性: 多个并发事务之间要相互隔离,不能被其他事务的操作所干扰
-
持久性: 当事务正确完成后,对于数据的改变是永久性的。
事务的隔离级别?

索引主要有哪几种分类 ?
普通索引: 是最基本的索引,它没有任何限制
唯一索引: 索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
主键索引: 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
组合索引: 一个索引包含多个列,实际开发中推荐使用组合索引。
全文索引: 全文搜索的索引。FULLTEXT 用于搜索很长一篇文章的时候,效果最好。只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。
主键索引和唯一索引的区别:
主键必唯一,但是唯一索引不一定是主键;
一张表上只能有一个主键,但是可以有一个或多个唯一索引。
什么时候适合添加索引,哪些列适合添加索引 ?
数据量大的时候
1.经常用作查询的列
2.多表关联时作为关联条件的列
3.在经常需要根据范围查询的列
4.经常需要排序的列
5.主键默认添加唯一索引
索引的设计原则 ?
索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,查询速度更快。
索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
利用最左前缀原则。
索引的数据结构有哪些 ?
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和Hash索引。InnoDB引擎的索引类型有B+树索引和Hash索引,默认的索引类型为B+树索引。
Hash索引
哈希索引是基于哈希表实现的,当我们要给某张表某列增加索引时,存储引擎会对这列进行哈希计算得到哈希码,将哈希码的值作为哈希表的key值,将指向数据行的指针作为哈希表的value值。这样查找一个数据的时间复杂度就是O(1),一般多用于精确查找。所以在= in <=>(安全等于的时候)塔的效率是非常,但我们开发一般会选择Btree,因为Hash会存在如下一些缺点。
Hash索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。
Hash 索引无法被用来避免数据的排序操作。
Hash索引不能利用部分索引键查询。
Hash索引在任何时候都不能避免表扫描。
Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
B+树索引
相对于cpu和内存操作,磁盘IO开销很大,非常容易成为系统的性能瓶颈。为什么索引能提升数据库查询效率呢?根本原因就在于索引减少了查询过程中的IO次数。那么它是如何做到的呢?使用B+树。下面先简单了解一下B树和B+树。
B树
B树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的查找树,它类似普通的平衡二叉树,不同的一点是B树允许每个节点有更多的子节点。下图是 B树的简化图.
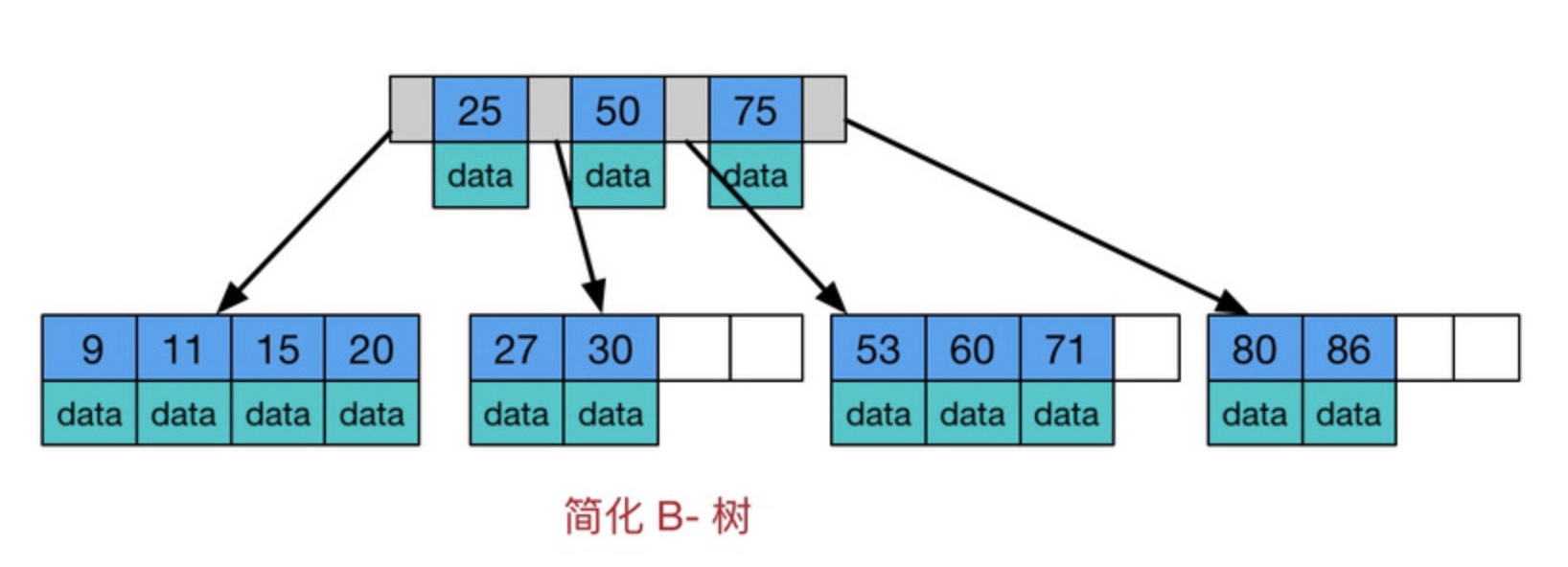
观察上图可见B树的两个特点:
树内的每个节点都存储数据
叶子节点之间无指针连接
B+树
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
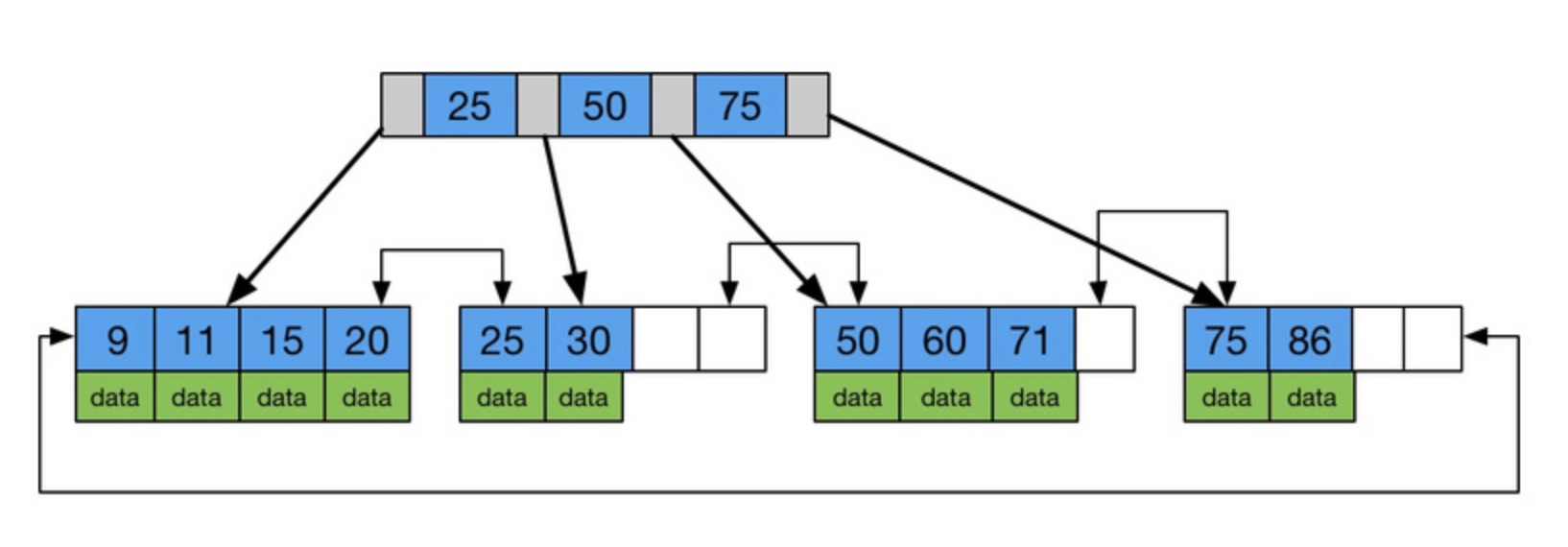
B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
为什么B+树比B树更适合实现数据库索引 ?
B+ 树叶子结点之间用链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。
B+ 树更相比 B 树减少了 I/O 读写的次数。由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
B+树的查询效率更加稳定,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B 树和 B+树的区别?为什么 Mysql 使⽤B+树 ?
B 树的特点:
- 节点排序
- ⼀个节点了可以存多个元素,多个元素也排序了
B+树的特点: - 拥有 B 树的特点
- 叶⼦节点之间有指针
- ⾮叶⼦节点上的元素在叶⼦节点上都冗余了,也就是叶⼦节点中存储了所有的元素,并
且排好顺序
Mysql 索引使⽤的是 B+树,因为索引是⽤来加快查询的,⽽B+树通过对数据进⾏排序所以
是可以提⾼查
询速度的,然后通过⼀个节点中可以存储多个元素,从⽽可以使得 B+树的⾼度不会太⾼,
在 Mysql 中⼀
个 Innodb⻚就是⼀个 B+树节点,⼀个 Innodb⻚默认 16kb,所以⼀般情况下⼀颗两层的 B+
树可以存 2000
万⾏左右的数据,然后通过利⽤B+树叶⼦节点存储了所有数据并且进⾏了排序,并且叶⼦
节点之间有指
针,可以很好的⽀持全表扫描,范围查找等 SQL 语句。
什么情况会使索引失效 ?
1.where 条件中有 or
2.like 查询时以%开头
3.列的类型为 varchar where 条件没有使用’’
4.not in, not exists, <>
5.=左边为表达式或者函数
MyISAM 和 InnoDB 的区别 ?
1)InnoDB 支持事务,而 MyISAM 不支持。
2)InnoDB 支持外键,而 MyISAM 不支持。因此将一个含有外键的 InnoDB 表 转为 MyISAM 表会失败。
3)InnoDB 和 MyISAM 均支持 B+ Tree 数据结构的索引。但 InnoDB 是聚集索引,而 MyISAM 是非聚集索引。
4)InnoDB 不保存表中数据行数,执行 select count(*) from table 时需要全表扫描。而 MyISAM 用一个变量记录了整个表的行数,速度相当快(注意不能有 WHERE 子句)。
那为什么 InnoDB 没有使用这样的变量呢?因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的。
5)InnoDB 支持表、行(默认)级锁,而 MyISAM 支持表级锁。
InnoDB 的行锁是基于索引实现的,而不是物理行记录上。即访问如果没有命中索引,则也无法使用行锁,将要退化为表锁。
6)InnoDB 必须有唯一索引(如主键),如果没有指定,就会自动寻找或生产一个隐藏列 Row_id 来充当默认主键,而 Myisam 可以没有主键。
MyISAM和InnoDB使用的锁?
MyISAM使用表级锁。
InnoDB支持行级锁和表级锁,默认为行级锁。
从锁的分类来说,MySQL都有哪些锁?
从锁的类别来讲,有共享锁和排他锁。
共享锁
又叫读锁。当用户要进行数据读取时,对数据加上共享锁。共享锁可以同时加上多个。
排他锁
又叫写锁。当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,它和其它排他锁、共享锁都互斥。
行级锁和表级锁对比 ?
行级锁
行级锁是MySQL中锁定粒度最细的一种锁,表示只针对当前操作的行(Row)进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突概率最低,并发度也最高。
表级锁
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常用的MyISAM与InnoDB都支持表级锁。表级锁分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
什么是死锁?如何解决?
死锁是指两个或多个事务在同一资源上向胡战勇,并请求锁定对方的资源,从而导致恶性循环。
解决方案:
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低发生死锁的风险。
2、同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率。
3、对于非常容易产生死锁的业务部分,可以尝试升级锁定粒度,通过表级锁定来减少死锁产生的概率。
数据库的乐观锁和悲观锁是什么?怎么实现的?
数据库管理系统中的并发控制的任务是确保在多个事务同时存取数据库中同一份数据时不破坏事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
悲观锁
假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁起来,直到提交事务。
实现方式:使用数据库中的锁机制。
乐观锁
假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过版本控制的方式来进行锁定。
实现方式:一般会使用版本号机制或CAS算法实现。
乐观锁和悲观锁的使用场景 ?
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写操作比较少的情况下(多读场景,也就是并发写操作较低的场景),即冲突真的很少发生的时候,这样可以省去加锁的开销,加大了整个系统的吞吐量。
但如果是并发写操作较多的情况下,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样的话使用乐观锁反而是降低了性能,所以一般并发写操作较多的场景下使用悲观锁比较合适
索引的三种常见底层数据结构以及优缺点 ?
三种常见的索引底层数据结构:分别是哈希表、有序数组和搜索树。
哈希表这种适用于等值查询的场景,比如 memcached 以及其它一些 NoSQL 引擎,不适合范围查询。
有序数组索引只适用于静态存储引擎,等值和范围查询性能好,但更新数据成本高。
N 叉树由于读写上的性能优点以及适配磁盘访问模式以及广泛应用在数据库引擎中。
扩展(以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200。棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿了。考虑到树根的数据块总是在内存中的,一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问 3 次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。)
什么是redo log日志 ?
redo log(重做日志)是InnoDB存储引擎独有的,它让MySQL拥有了崩溃恢复能力。比如 MySQL 实例挂了或宕机了,重启时,InnoDB存储引擎会使用redo log恢复数据,保证数据的持久性与完整性。
什么是binlog日志 ?
binlog是记录所以数据表结构变更以及表数据修改的二进制日志,不会记录select和show这类操作。binlog是以事件形式记录,还包括语句所执行的消耗时间。Binlog是MySql Server自己的日志,但是Redo Log是基于InnoDB引擎所特有的日志。
MySQL数据库的 数据备份、主备、主主、主从都离不开binlog,需要依靠binlog来同步数据,保证数据一致性。
什么是undo log日志 ?
数据库事务四大特性中有一个是 原子性 ,具体来说就是 原子性是指对数据库的一系列操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。 我们知道如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚,在 MySQL 中,恢复机制是通过 回滚日志(undo log) 实现的,所有事务进行的修改都会先先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,我们直接利用 回滚日志 中的信息将数据回滚到修改之前的样子即可!并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
什么是 MVCC 以及实现 ?
MVCC 的英文全称是 Multiversion Concurrency Control,中文意思是多版本并发控制,可以做到读写互相不阻塞,主要用于解决不可重复读和幻读问题时提高并发效率。
其原理是通过数据行的多个版本管理来实现数据库的并发控制,简单来说就是保存数据的历史版本。可以通过比较版本号决定数据是否显示出来。读取数据的时候不需要加锁可以保证事务的隔离效果。
什么是主从复制 ?
主从复制是用来建立一个与主数据库完全一样的数据库环境,即从数据库。主数据库一般是准实时的业务数据库。
主从复制的作用 ?
读写分离,使数据库能支撑更大的并发。
高可用,做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
相关文章:
MySQL相关面试题
文章目录union 和 unionAll 的区别?drop、delete与truncate的区别 ?sql 语句如何优化 ?什么是事务 ?事务的四个特性(ACID) ?事务的隔离级别?索引主要有哪几种分类 ?什么时候适合添加索引&#x…...
Python创意作品说明怎么写,python创意编程作品集
大家好,小编来为大家解答以下问题,Python创意作品说明怎么写,python创意编程作品集,现在让我们一起来看看吧! 1、有哪些 Python 经典书籍 书名:深度学习入门 作者:[ 日] 斋藤康毅 …...
icomoon字体图标的使用
很久之前就学习过iconfont图标的使用,今天又遇到一个用icomoon字体图标写的案例,于是详细学习了一下,现整理如下。 一、下载 1.网址: https://icomoon.io/#home 2.点击IcoMoon App。 3.点击 https://icomoon.io/app 4.进入IcoM…...
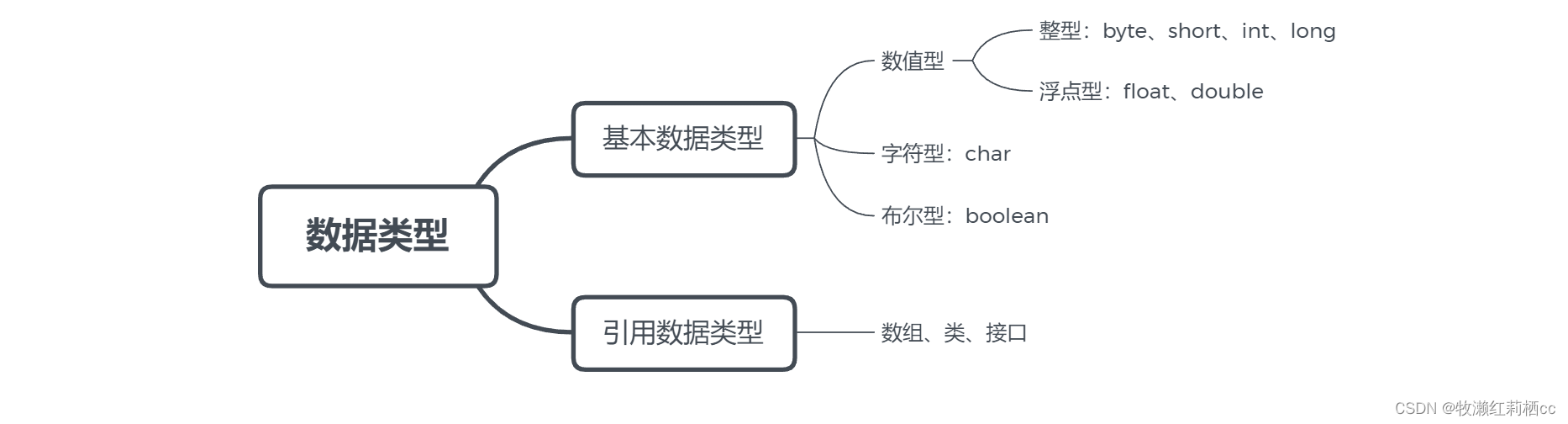
Java · 常量介绍 · 变量类型转换 · 理解数值提升 · int 和 Stirng 之间的相互转换
书接上回 Java 变量介绍 我们继续学习以下内容. 四、常量字面值常量final 关键字修饰的常量五、理解类型转换int 和 long/double 相互赋值int 和 boolean 相互赋值int 字面值常量给 byte 赋值强制类型转换类型转换小结六、理解数值提升int 和 long 混合运算byte 和 byte 的运算…...
JVM从跨平台到跨专业 Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

ucore的字符输出
ucore的字符输出有cga,lpt,和串口。qemu模拟出来显示器连接到cga中。 cga cga的介绍网站:https://en.wikipedia.org/wiki/Color_Graphics_Adapter cga是显示卡,内部有个叫6845的芯片。cga卡把屏幕划分成一个一个单元格,每个单元格显示一个a…...

【ESP 保姆级教程】玩转emqx数据集成篇① ——认识数据集成
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-10 ❤️❤️ 本篇更新记录 2023-02-10 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...
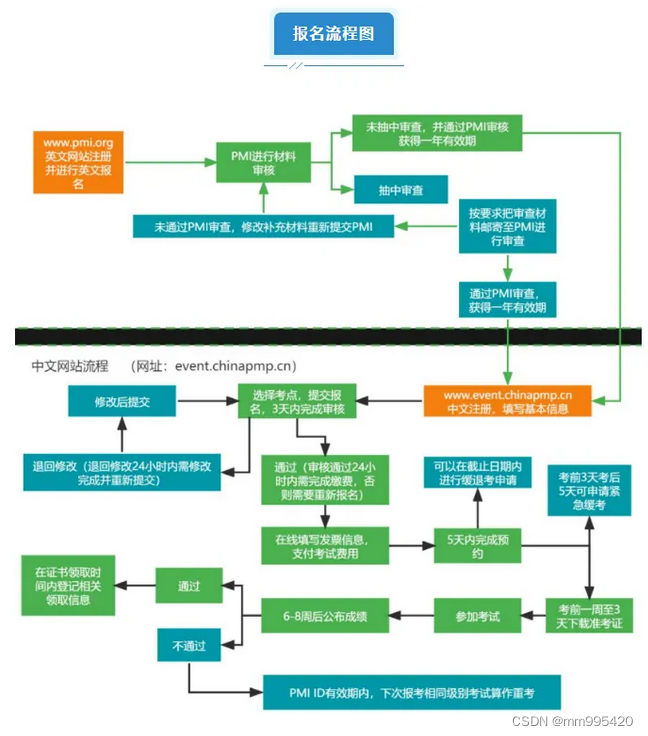
PMP报考条件?
PMP已经被认为是项目管理专业身份的象征,项目经理人取得的重要资质。 PMP考试一般每年在中国大陆地区,会进行四次考试,今天就来详细说一说PMP考试的时间线。 01考试时间PMP考试在中国大陆一年开展四次,分别在每年的3月、6月、9月…...
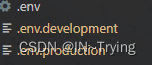
Vite+Vue3实现版本更新检查,实现页面自动刷新
ViteVue3实现版本更新检查,实现页面自动刷新1、使用Vite插件打包自动生成版本信息2、Vite.config.ts配置3、配置环境变量4、路由配置现有一个需求就是实现管理系统的版本发版,网页实现自动刷新页面获取最新版本 搜索了一下,轮询的方案有点浪费…...

LeetCode刷题模版:292、295、297、299-301、303、304、309、310
目录 简介292. Nim 游戏295. 数据流的中位数297. 二叉树的序列化与反序列化【未理解】299. 猜数字游戏300. 最长递增子序列301. 删除无效的括号【未理解】303. 区域和检索 - 数组不可变304. 二维区域和检索 - 矩阵不可变309. 最佳买卖股票时机含冷冻期310. 最小高度树【未理解】…...

20、CSS中单位:【px和%】【em和rem】【vw|vh|vmin|vmax】的区别
CSS中的px 和 % px (pixels) 是固定单位,也可以叫基本单位,代表像素,可以确保元素的大小不受屏幕分辨率的影响。 % (percentage) 是相对单位,代表元素大小相对于其父元素或视口(viewport)的大小的百分比。使用百分比可…...

第五节 字符设备驱动——点亮LED 灯
通过字符设备章节的学习,我们已经了解了字符设备驱动程序的基本框架,主要是掌握如何申请及释放设备号、添加以及注销设备,初始化、添加与删除cdev 结构体,并通过cdev_init 函数建立cdev 和file_operations 之间的关联,…...
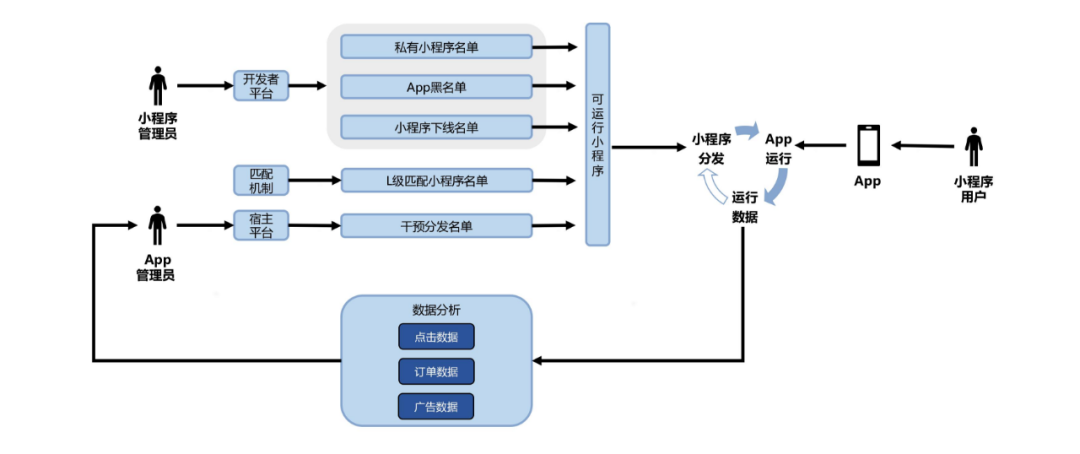
浅谈小程序开源业务架构建设之路
一、业务介绍 1.1 小程序开源整体介绍 百度从做智能小程序的第一天开始就打造真正开源开放的生态,我们的愿景是:定义移动时代最佳体验,建设智能小程序行业标准,打破孤岛,共建开源、开放、繁荣的小程序行业生态。百度…...
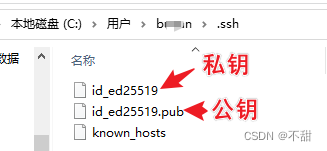
git、gitee、github关系梳理及ssh不对称加密大白话解释
温馨提示:本文不会讲解如何下载、安装git,也不会讲解如何注册、使用gitee或GitHub,这些内容网上一大把,B站上的入门课程也很多,自己看看就好了。 本文仅对 git、gitee、github的关系梳理及ssh公钥私钥授权原理用白话讲…...

UDP协议详解
目录 前言: 再谈协议 UDP协议 比较知名的校验和 小结: 前言: UDP和TCP作为传输层非常知名的两个协议,那么将数据从应用层到传输层数据是怎样进行打包的?具体都会增加一些什么样的报头,下面内容详细介绍…...
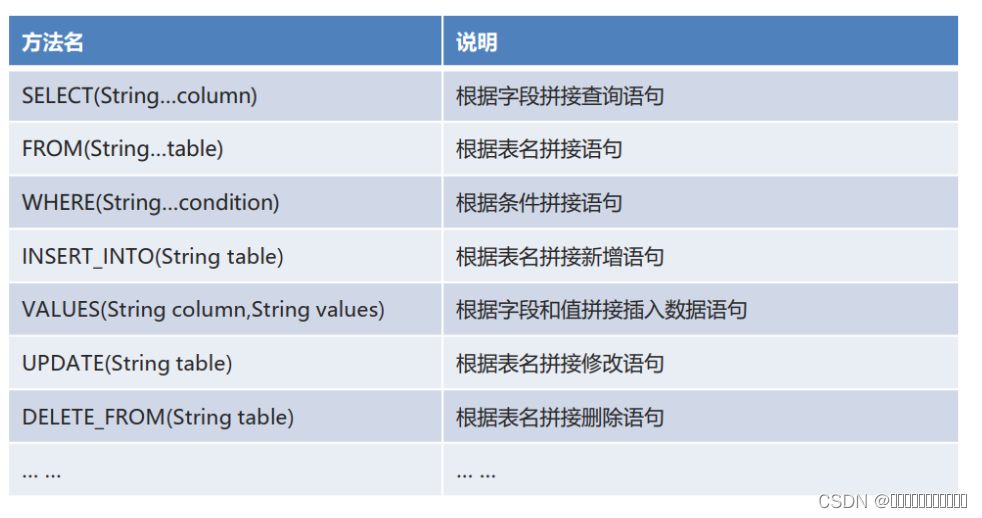
Myb atis基础3
Mybatis注解开发单表操作Mybatis的常用注解Mybatis的增删改查MyBatis注解开发的多表操作MyBatis的注解实现复杂映射开发一对一查询一对多查询多对多查询构建sqlsql构建对象介绍查询功能的实现新增功能的实现修改功能的实现删除功能的实现Mybatis注解开发单表操作 Mybatis的常用…...

VHDL语言基础-时序逻辑电路-寄存器
目录 寄存器的设计: 多位寄存器: 多位寄存器的VHDL描述: 移位寄存器: 串进并出的移位寄存器的VHDL描述: 寄存器的设计: 多位寄存器: 一个D触发器就是一位寄存器,如果需要多位寄存器&…...

高通开发系列 - linux kernel更新msm-3.18升至msm-4.9
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 linux kernel更新msm-3.18升至msm-4.9第一周处理的内容:第二周处理的内容第三周处理的内容linux kernel更新msm-3.18升至msm-4.9 第…...

【Tensorflow2.0】tensorflow中的Dense函数解析
目录1 作用2 例子3 与torch.nn.Linear的区别4 参考文献1 作用 注意此处Tensorflow版本是2.0。 由于本人是Pytorch用户,对Tensorflow不是很熟悉,在读到用tf写的代码时就很是麻烦。如图所示,遇到了如下代码: h Dense(unitsadj_di…...

PyTorch学习笔记:data.RandomSampler——数据随机采样
PyTorch学习笔记:data.RandomSampler——数据随机采样 torch.utils.data.RandomSampler(data_source, replacementFalse, num_samplesNone, generatorNone)功能:随即对样本进行采样 输入: data_source:被采样的数据集合replace…...

IP2366至为芯支持C口双向快充的140W多串锂电池充放电SOC芯片
英集芯IP2366是一款应用于移动电源、电动工具、智能家居、储能电源等方案的多串锂电池充电SOC芯片。支持高达140W的双向同步升降压充放电,充电电流可达5A。支持2至6节锂电池/磷酸铁锂电池串联,集成PD3.1、QC3.0等多种快充协议。内置14bit ADC,…...

Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题
Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的…...
人工智能的发展历程)
图解人工智能(10)人工智能的发展历程
人工智能自20世纪50年代发展至今,经历了若干次高潮和低谷。每到陷入困境的时候,总有一些科学家勇敢地打破传统思想的束缚,创造出新理论、新方法,使人工智能重现生机。例如,在符号主义陷入危机的时候,费根鲍…...
)
Codex入门10-Goal自主任务(进阶必学:设定目标就不管了,AI自己干活到完成)
🎯 本文目标 掌握 /goal 持久化任务系统,让 Codex 自主完成复杂的大型工作。 🤔 /goal 和普通对话有什么区别? 对比 普通对话 /goal 任务 交互方式 一问一答 设定目标后AI自主工作 持久性 关终端就中断 关终端也能继续 适合任务 小任务、即时反馈 大任务、长期执行 计划…...

OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖
OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖 问&am…...

can消息的大小端对源码的影响
下图为小端intel型信号,其dbc文件部分源码为:BO_ 1 id_0x1: 8 Vector__XXXSG_ aaa : 0|121 (1,0) [0|0] "" Vector__XXX,这里的0代表的是起始位置为0(起始0->7,8->12为高位)如果将该信号改为大端motorola型&#…...

EmbBERT架构解析:面向TinyML的革新设计与优化
1. EmbBERT架构解析:面向TinyML的革新设计在边缘计算设备上部署自然语言处理模型一直面临内存和计算资源的双重限制。传统BERT模型即使经过压缩,其2MB版本在TinyNLP基准测试中平均准确率仅为83.93%,且激活内存占用高达1.5MB。EmbBERT通过三大…...

AI赋能医院物流:基于PDCA循环的智能供应链韧性提升实践
1. 项目概述:当医院物流遇上AI与PDCA医院物流,听起来可能有点“幕后”,但它绝对是现代医疗体系顺畅运转的“大动脉”。从高值耗材、药品、检验试剂,到被服布草、医疗废物,甚至是一日三餐,这条链条上任何一个…...

AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧
AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧 【免费下载链接】ajv The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) 项目地址: https://gitcode.com/gh_mirror…...

[具身智能-653]:人的大脑神经网络就是天然的模拟电路,还是数字电路?
结论先给:人脑神经网络,本质是【天然模拟电路】,不是数字电路这和前面聊的模拟电路频域特性、硬件隐式频域滤波完全同逻辑。一、先分清:数字电路 vs 模拟电路 核心区别数字电路只有0、1两种离散电平,跳变是阶跃式&…...