初识Hadoop,走进大数据世界
文章目录
- 数据!数据!
- 遇到的问题
- Hadoop的出现
- 相较于其他系统的优势
- 关系型数据库
- 网格计算
本文章属于Hadoop系列文章,分享Hadoop相关知识。后续文章中会继续分享Hadoop的组件、MapReduce、HDFS、Hbase、Flume、Pig、Spark、Hadoop集群管理系统以及案例项目等。想学习大数据的同学希望可以点赞、收藏、持续关注不迷路。
在古时候,人们用牛来拉重物,当一头牛拉不动一根圆木时,人们从来没有考虑过要想方设法培育出一种更强壮的牛。同理,我们也不该想方设法打造什么超级计算机,而应该千方百计综合利用更多计算机来解决问题。
数据!数据!

我们生活在这个数据大爆炸的时代,很难估算全球的电子设备存储量。根据国际数据公司(IDC)曾经发布的报告,2013年统计出全球数据总量为4.4ZB,预测到2020年数据量将会达到44ZB,1ZB等于1000EB,等于1 000 000PB,等于大家所熟悉的10亿TB,这远远超过了全世界任意一块硬盘所能保存的数据量。
数据“洪流”有很多来源,以下面列出为例:
- 纽约证交所每天产生的交易数据大约的4TB到5TB之间。
- FaceBook存储的照片超过2400亿张,并以每月至少7PB的速度增长。
- 互联网档案馆存储的数据约为18PB。
- 瑞士日内瓦附近的大型强子对撞机每年产生数据越30PB。
还有其他大量的数据,比如作为物联网一部分的机器设备产生的日志、RFID读卡器、车载GPS等等。
组织或企业要想在未来取得成功,不仅需要管理好自己的数据,更需要从其他渠道获取有价值的信息。现在得益于开放的互联网,我们已经可以从各个地方获取到需要的数据,这是个好消息,但不幸的是,我们必须想方设法好好的存储和分析这些数据。
遇到的问题
我们遇到的问题很简单,在硬盘存储容量多年来不断提升的同时,硬盘数据读取的速度却没有与时俱进。1990年,一个普通的硬盘可以存储1370MB的数据,传输速度为4.4 MB/s,因此只需要5分钟就可以读完整个硬盘的数据。20年过去了,1TB的硬盘成为主流,但其数据传输速度约为100 MB/s,读完整个硬盘至少需要花费2.5个小时。
一个很简单减少读取时间的办法是同时从多个硬盘上读数据。试想,如果有100个硬盘,每个硬盘存储1%的数据,并行读取,那么不到两分钟就可以读完所有数据。仅使用硬盘容量的1%似乎很浪费,但是我们可以存储100个数据集,每个数据集1TB,并实现共享硬盘的读取。
Hadoop的出现

虽然如此,但要对多个硬盘中的数据并行进行读/写数据,还有很多问题要解决。
第一个需要解决的是硬件故障问题。一旦开始使用多个硬件,其中个别硬件就很有可能发生故障。为了避免数据丢失,最常见的做法是复制:系统保存数据的副本,一旦有系统发生故障,就可以用另外保存的副本。例如,冗余硬盘阵列(RAID)就是按这个原理实现的,另外,Hadoop的文件系统(HDFS)也是这一类。
第二个问题是大多数分析任务需要结合大部分数据共同完成分析,即从一个硬盘读取的数据可能需要从另外99个硬盘的数据结合使用,保证其正确性是一个非常大的挑战,MapReduce提出一个编程模型,该模型抽象出这些硬盘读/写问题,并转换为对一个数据集(由键-值对组成)的计算,有很高的可靠性。
简而言之,Hadoop为我们提供了一个可靠的且可扩展的存储与分析平台。此外,由于Hadoop运行在商用硬件上且是开源的,所以使用成本是在可接受范围内的。
相较于其他系统的优势
Hadoop不是历史上第一个用于数据存储和分析的分布式系统,但是Hadoop的一些特性将它和类似的系统区别开来。
关系型数据库
为什么不能用配有大量硬盘的数据库来进行大规模数据分析?为什么用Hadoop?
这两个问题的答案来自于计算机硬盘的发展趋势:寻址时间的提升远远不敌传输速率的提升,寻址是将磁头移动到硬盘的某个位置进行读/写操作的过程,它是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽。
如果数据访问中包含大量的硬盘寻址,那么读取大量数据必然会花更长的时间。另一方面,如果数据库系统只更新一小部分记录,那么传统的B树更有优势。但数据库系统如果有大量的数据更新,B树的效率就明显落后于MapReduce了。在很多情况下,可以将MapReduce作为关系型数据库的补充,两个系统之间差异如下
| 关系型数据库 | MapReduce | |
|---|---|---|
| 数据大小 | GB | PB |
| 数据存取 | 交互式和批处理 | 批处理 |
| 更新 | 多次读/写 | 一次写入,多次读取 |
| 事务 | ACID | 无 |
| 结构 | 写时模式 | 读时模式 |
| 完整性 | 高 | 低 |
| 横向扩展 | 非线性 | 线性 |
网格计算
高性能计算和网格计算组织多年来一直在研究大规模数据处理,主要使用类似于消息传递接口的API。广义上讲,高性能计算采用的方法是将作业分散到集群的各个机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统,如果节点需要访问的数据量更庞大,很多节点就会因为网络带宽的瓶颈问题而不得不闲下来等数据。
Hadoop尽量在计算节点上存储数据,以实现数据的本地快速访问。数据本地化是Hadoop数据处理的核心,并因此获得良好的性能。
相关文章:
初识Hadoop,走进大数据世界
文章目录数据!数据!遇到的问题Hadoop的出现相较于其他系统的优势关系型数据库网格计算本文章属于Hadoop系列文章,分享Hadoop相关知识。后续文章中会继续分享Hadoop的组件、MapReduce、HDFS、Hbase、Flume、Pig、Spark、Hadoop集群管理系统以及…...
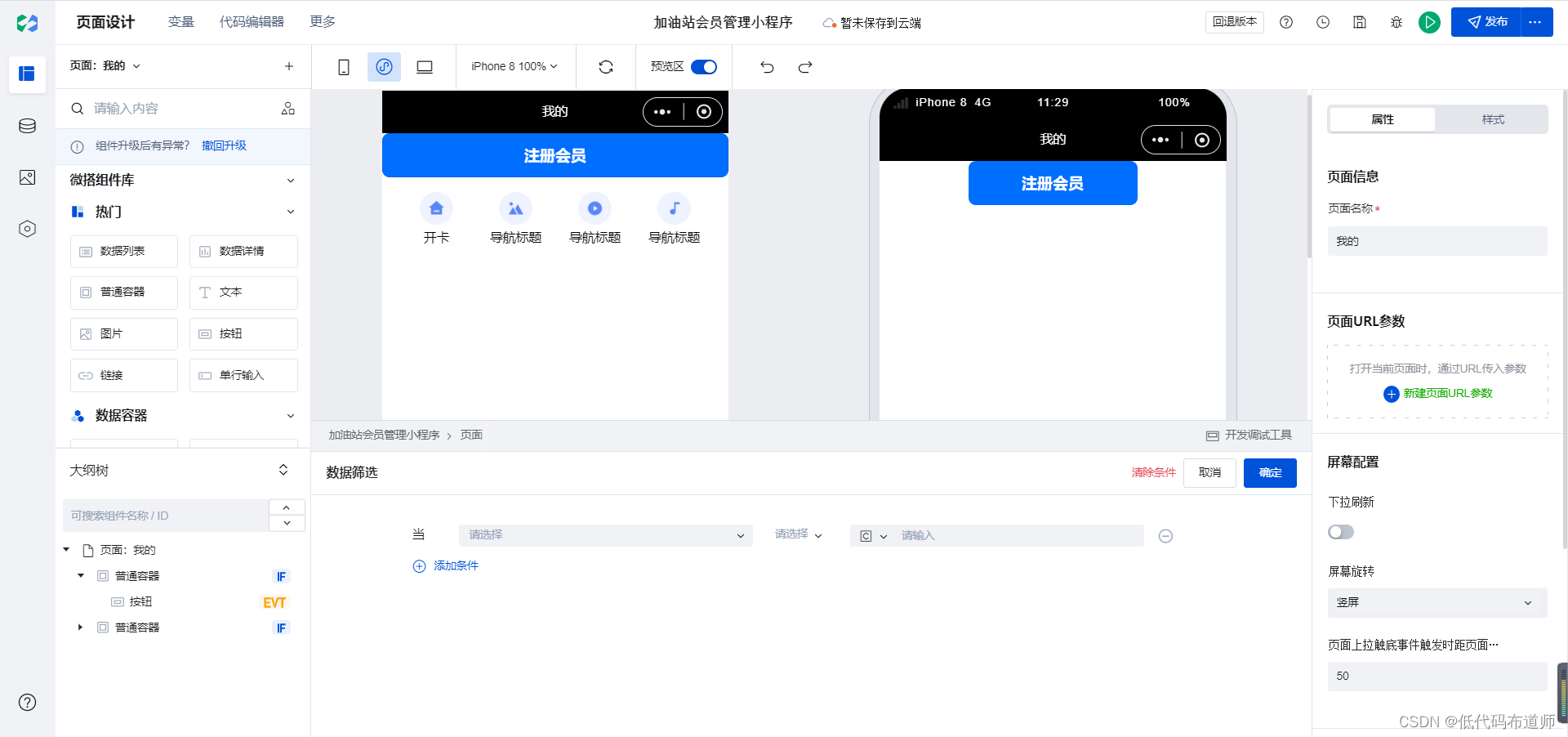
加油站会员管理小程序实战开发教程14 会员充值
我们上篇介绍了会员开卡的业务,开卡是为了创建会员卡的信息。有了会员卡信息后我们就可以给会员进行充值。当然了充值这个业务是由会员自主发起的。 按照我们的产品原型,我们在我的页面以轮播图的形式循环展示当前会员的所有卡信息。这个会员卡信息需要先用变量从数据源读取…...

leetcode 1792. 最大平均通过率
一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali 个学生,其中只有 passi 个学…...

15-基础加强-2-xml(约束)枚举注解
文章目录1.xml1.1概述【理解】(不用看)1.2标签的规则【应用】1.3语法规则【应用】1.4xml解析【应用】1.5DTD约束【理解】1.5.1 引入DTD约束的三种方法1.5.2 DTD语法(会阅读,然后根据约束来写)1.6 schema约束【理解】1.6.1 编写schema约束1.6.…...
)
13:高级篇 - CTK 事件管理机制(signal/slot)
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 在《12:高级篇 - CTK 事件管理机制(sendEvent/postEvent)》一文中,我们介绍了如何进行插件间通信 - sendEvent()/postEvent() + ctkEventHandler。然而,除了这种方式之外,EventAdmin 还提供了另一种方…...
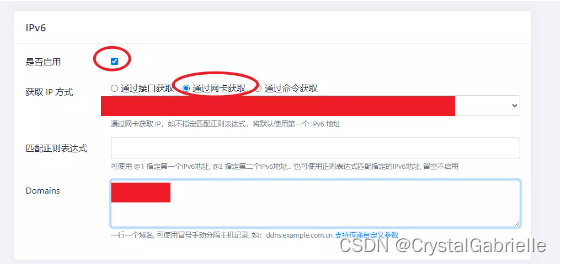
群晖-第1章-IPV6的DDNS
群晖-第1章-IPV6的DDNS 方案:腾讯云群晖DS920 本文参考群晖ipv6 DDNS-go教程-牧野狂歌,感谢原作者的分享。 这篇文章只记录了我需要的部分,其他的可以查看原文,原文还记录了更多的内容,可能帮到你。 一、购买域名 …...
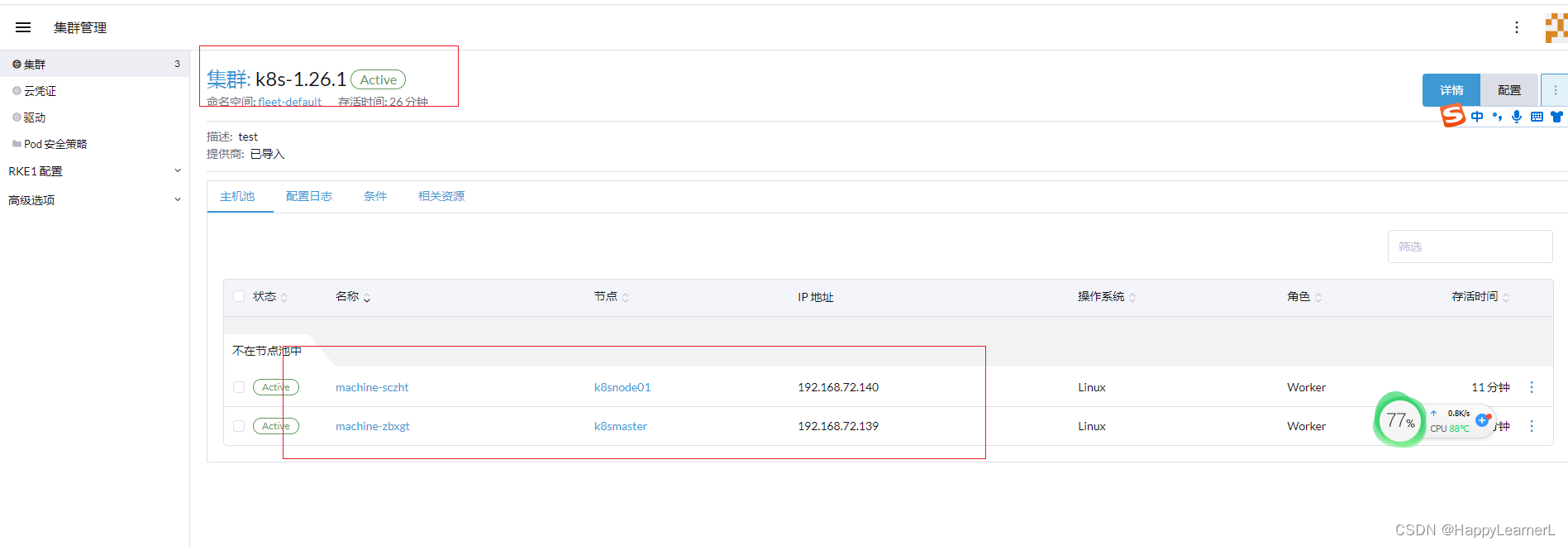
centos7系统-kubeadm安装k8s集群(v1.26版本)亲测有效,解决各种坑可供参考
文章目录硬件要求可省略的步骤配置虚拟机ip设置阿里镜像源各服务器初始化配置配置主节点的主机名称配置从节点的主机名称配置各节点的Host文件关闭各节点的防火墙关闭selinux永久禁用各节点的交换分区同步各节点的时间将桥接的IPv4流量传递到iptables的链(三台都执行…...
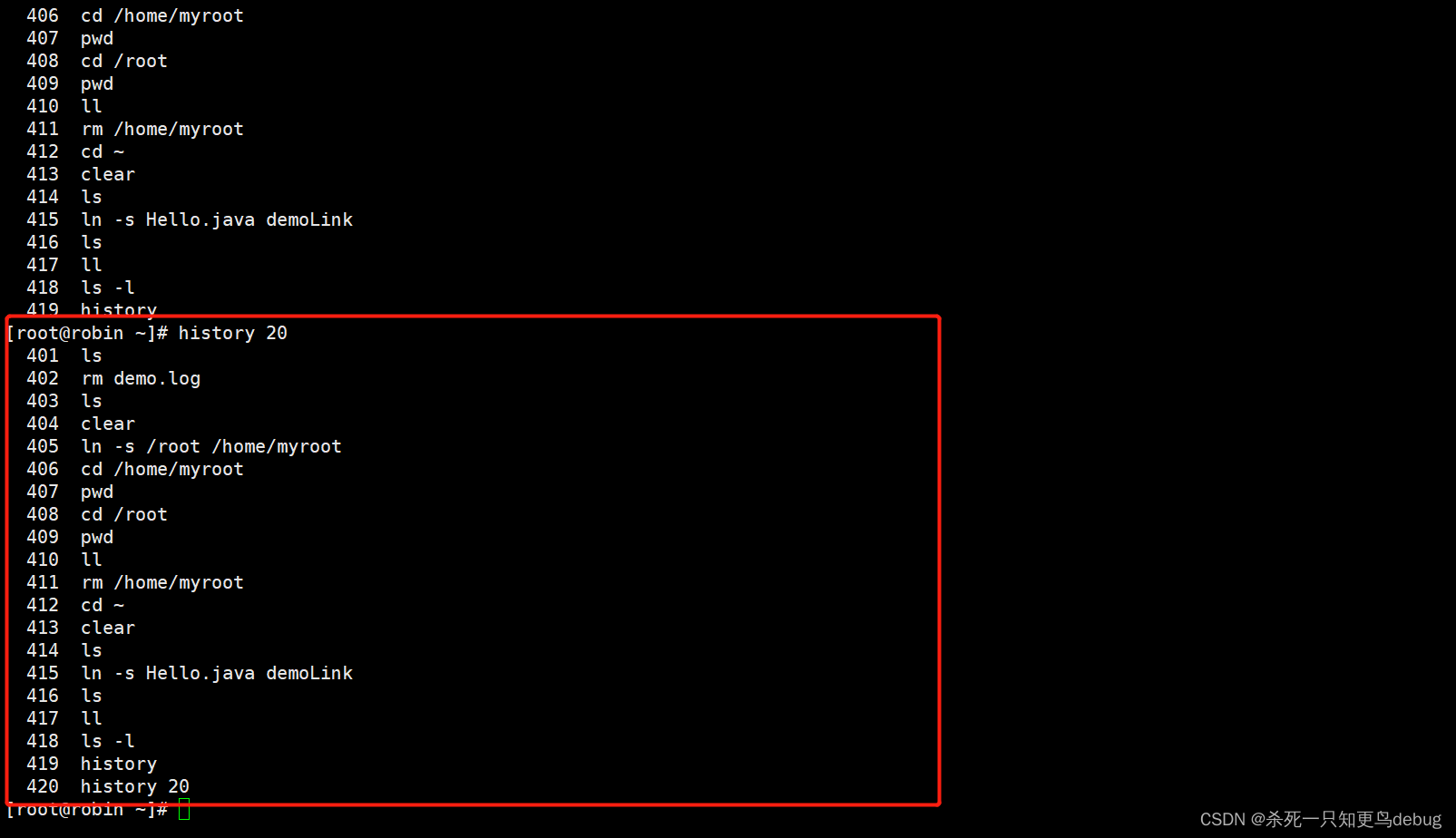
帮助指令 man ,help及文档常用管理指令
帮助指令 man,help 1. man 当我们想要了解某个命令如何使用,及选项的含义是什么以及配置文件的帮助信息时,可以使用 man [命令或配置文件],这样便可以获得到帮助提示信息了。 语法格式:man [命令或者配置文件] 比如…...
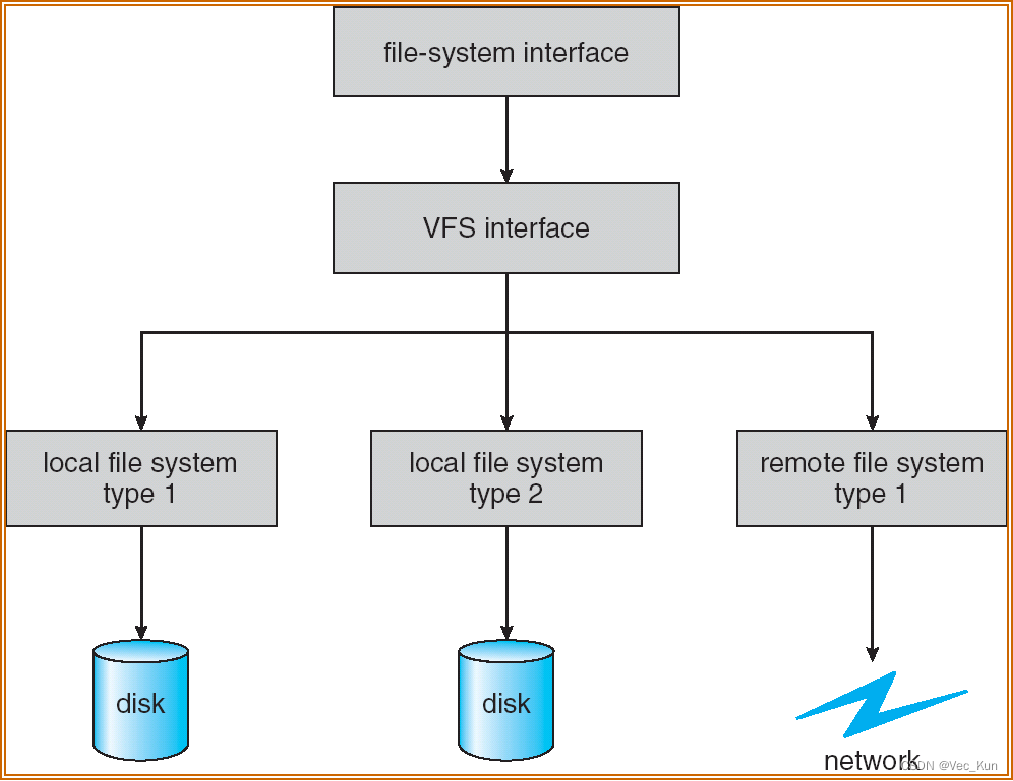
电子科技大学操作系统期末复习笔记(五):文件管理
目录 前言 文件管理:基础 基本概念 文件 文件系统 文件系统的实现模型 文件的组成 文件名 文件分类 文件结构 逻辑结构 物理结构 练习题 文件管理:目录 文件控制块FCB FCB:File Control Block FCB信息 目录 基本概念 目…...
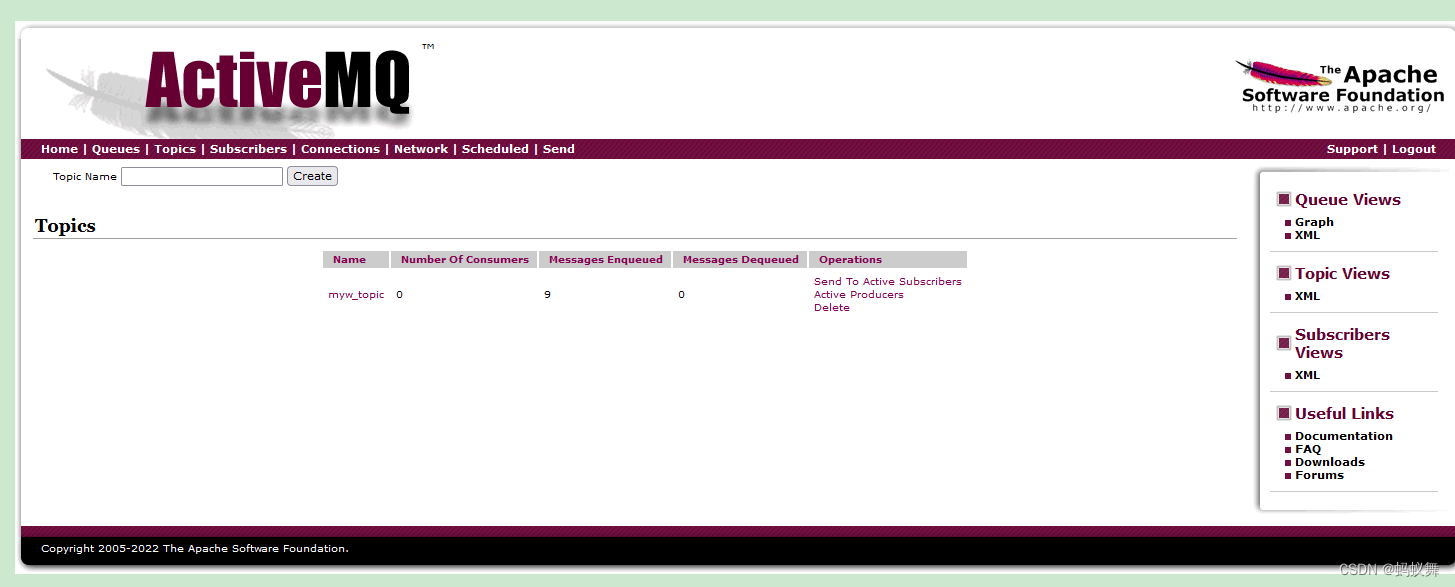
SpringBoot+ActiveMQ-发布订阅模式(生产端)
SpringBootActiveMQ-发布订阅模式(生产端)Topic 主题* 消息消费者(订阅方式)消费该消息* 消费生产者将发布到topic中,同时有多个消息消费者(订阅)消费该消息* 这种方式和点对点方式不同…...
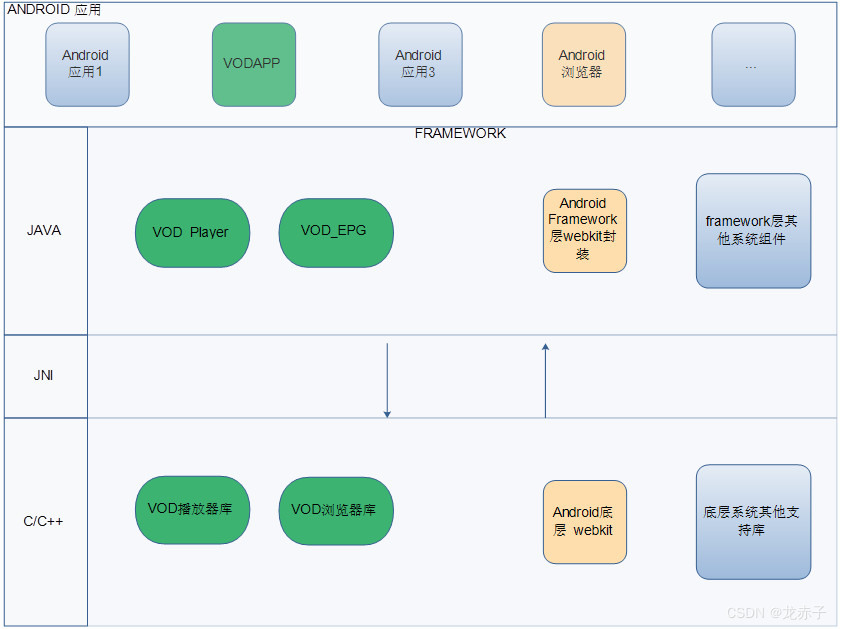
Android实例仿真之三
目录 四 Android架构探究 五 大骨架仿真 六 Android实例分析思路拓展 四 Android架构探究 首先,Android系统所带来的好处,就在于它本身代码的开放性,这提供了一个学习、借鉴的平台。这对分析仿真而言,本身就是一大利好…...
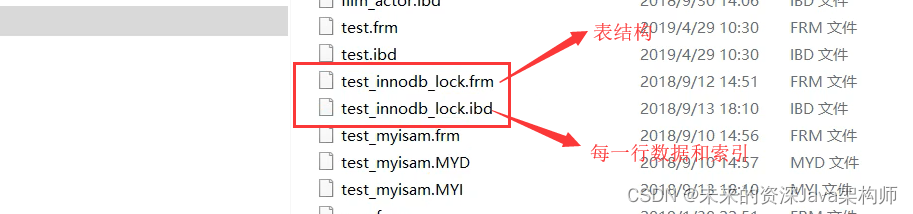
关于MySQL的limit优化
1、前提 提示:只适用于InnoDB引擎 2、InnoDB存储特点 它把索引和数据放在了一个文件中,就是聚集索引。这与MyISAM引擎是不一样的。 3、SQL示例 -- 给cve字段建立索引 select * from cnnvd where cveCVE-2022-24808 limit 300000,10;由于M…...

Java-Stream流基本使用
collection.stream将会破坏原有的数据结构,可以通过collect方法收集,可以用Collectors提供的构造器,add等方法构造形成新的数据结构。 HashSet<List<Integer>> rs new HashSet<>(); rs.stream().toList();Collection集合转…...

Liunx(狂神课堂笔记)
一.常用命令 1. cd 切换目录 cd ./* 当前目录cd /* 绝对路径cd .. 返回上一级目录cd ~ 回到当前目录pwd …...

【史上最全面esp32教程】点灯大师篇
文章目录前言ESP32简介认识arduino的两个函数点灯步骤函数介绍LED灯闪烁流水灯总结前言 esp32有很多的功能,例如wifi,蓝牙等,这节我们学习最简单的点灯。 提示:以下是本篇文章正文内容,下面案例可供参考 ESP32简介 …...
【Java 面试合集】内存中为什么要区分栈和堆
内存中为什么要区分栈和堆 1. 概述 嗨,大家好Java 面试合集又来了,今天我们分享的主题很大众化以及普通。无论是Java 语言本身还是别的语言都会有所涉及,但是今天我们从Java角度来讲下 2. 分析 今天我们会从多个方向来分享这个话题 2.1 栈是…...
【NLP实战】Python字符串处理
一、Python字符串基本操作 1. 去掉前后的特殊字符(strip) Python的strip操作可以去除字符串前后的空格(不改变原串)下例将前后的空格均删掉👇 str 人工智能 str.strip() # OUT:人工智能rstrip删除右边的空格&a…...
17.CSS伪类
举一个简单的例子来说明什么是伪类? 从之前的代码中,如下图,我们像给这两个列表中的某一列单独设置样式,我们该如何做呢? 我们肯定会选择在li标签上添加class去实现,如下 开始标记结束标记实际元素 <…...

数据链路层
一.以太网数据链路层考虑的是相邻两个节点(通过网线/光纤、无线直接相连的两个设备)之间的传输,这里的典型协议中最知名的就是“以太网”这个协议了数据链路层,也规定了物理层的内容以太网帧格式:IP地址用来描述整个传…...

投票需要什么流程微信投票互助平台的免费投票平台搭建
“最美家政人”网络评选投票_免费小程序投票推广_小程序投票平台好处手机互联网给所有人都带来不同程度的便利,而微信已经成为国民的系统级别的应用。现在很多人都会在微信群或朋友圈里转发投票,对于运营及推广来说找一个合适的投票小程序能够提高工作效…...

别再对着示波器数NOP了!用STM32的SPI+DMA驱动WS2812灯带,一个CubeMX配置就搞定
用STM32的SPIDMA高效驱动WS2812灯带:告别手动调时序的工程化方案 在嵌入式开发中,驱动WS2812灯带一直是个让人又爱又恨的挑战。这种智能RGB灯带以其简单的单线控制和丰富的色彩表现广受欢迎,但精确的时序要求也让不少开发者头疼不已。传统方法…...

车载以太网之要火系列 - 第43篇:郭大侠学SOME/IP :服务写死痛点多,SD出山更灵活
写在开篇蓉儿挖新坑上回说到,郭靖搞清楚了SOME/IP的报文头、Service ID、Instance ID、Method、Event、Field……学了一大堆。郭靖合上笔记本,信心满满:“蓉儿,SOME/IP我算是学完了!车窗服务用0x0300,左前窗…...

用STM32 HAL库和MPU6050 DIY平衡小车:PID参数整定实战与小车‘站起来’的调试日记
STM32平衡小车PID调参实战:从剧烈抖动到稳定站立的调试手记 1. 平衡小车的核心挑战 当我第一次按下电源开关,看着这个小家伙像醉汉一样左右摇摆然后轰然倒下时,才真正理解到平衡控制的精妙之处。基于STM32和MPU6050的平衡小车项目,…...

智能休息提醒扩展:基于上下文感知的开发者健康管理工具
1. 项目概述:一个为开发者设计的“代码暂停”利器如果你和我一样,每天大部分时间都泡在代码编辑器里,那你肯定经历过这样的时刻:盯着一段复杂的逻辑或者一个棘手的Bug,大脑高速运转了半小时,却感觉毫无进展…...
)
告别毛边!保姆级教程:在Unity里完美播放Pr导出的WebM透明视频(附完整参数)
告别毛边!Unity中完美播放Pr导出WebM透明视频的终极指南 透明视频在游戏特效、UI动画和AR应用中越来越常见,但许多开发者都遇到过令人抓狂的"毛边"问题——那些不该出现的半透明像素像顽固污渍一样破坏视觉效果。本文将彻底解决这个痛点&#…...

别熬大夜改 PPT 了!Paperxie AI PPT,一键搞定毕业论文答辩
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 论文终稿刚定稿,答辩 PPT 的空白页面就开始让人焦虑。打开 PowerPoint,对着 “新建幻灯片” 发愣&am…...

VCF 9.1 Consumption CLI 插件同步失败解决方法
一、问题现象 在 VCF 9.1 环境执行 vcf plugin sync 同步插件时,系统尝试下载 9.0.1 版本插件(环境实际为 9.1),出现以下错误: [i] Installing plugins from plugin group vmware-vcfcli/essentials:v9.0.1 [x] Fail…...

Spinning Up模型保存终极指南:checkpoint管理完整教程
Spinning Up模型保存终极指南:checkpoint管理完整教程 【免费下载链接】spinningup An educational resource to help anyone learn deep reinforcement learning. 项目地址: https://gitcode.com/gh_mirrors/sp/spinningup 深度强化学习训练过程中ÿ…...

重新定义游戏体验:Atmosphere稳定版如何重塑Switch生态系统
重新定义游戏体验:Atmosphere稳定版如何重塑Switch生态系统 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 🔍 传统方案的三大痛点与Atmosphere的突破性解决方案 对…...

PotPlayer终极画质调校:深入MadVR渲染器设置,让你的显示器发挥100%潜力
PotPlayer终极画质调校:深入MadVR渲染器设置,让你的显示器发挥100%潜力 当4K HDR内容逐渐成为主流,普通播放器的画质处理能力已经无法满足追求极致视觉体验的用户需求。MadVR作为目前Windows平台上最强大的视频渲染器,配合PotPlay…...