自然语言处理从入门到应用——LangChain:索引(Indexes)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录
索引(Indexes)是指为了使LLM与文档更好地进行交互而对其进行结构化的方式。在链中,索引最常用于“检索”步骤中,该步骤指的是根据用户的查询返回最相关的文档:
- 索引不仅可用于检索,还可用于其他目的
- 检索可以使用除索引之外的其他逻辑来查找相关文档
因此,我们有一个称为Retriever的接口概念,这是大多数链所使用的接口。当我们谈论索引和检索时,通常是指索引和检索非结构化数据(如文本文档)。对于与结构化数据(例如SQL表等)或API的交互,请参阅相应的用例部分以获取相关功能的链接。
LangChain 主要关注于构建索引,目标是使用它们作为检索器。为了更好地理解这意味着什么,有必要突出显示基本检索器接口是什么。LangChain 的baseRetriever类如下:
from abc import ABC, abstractmethod
from typing import List
from langchain.schema import Documentclass BaseRetriever(ABC):@abstractmethoddef get_relevant_documents(self, query: str) -> List[Document]:"""Get texts relevant for a query.Args:query: string to find relevant texts forReturns:List of relevant documents"""
上述代码中的get_relevant_documents方法可以按照我们认为合适的方式实现。当然,我们也协助构建我们认为有用的检索器。我们主要关注的检索器类型是Vectorstore检索器。在本文的其余部分中,我们都将关注这一点。为了理解什么是向量库检索器,理解向量库是什么非常重要。默认情况下,LangChain使用Chroma作为向量存储来索引和搜索嵌入。要执行下面的代码,我们首先需要安装chromadb。
pip install chromadb
下面这个例子展示了对文档的问题回答。我们选择这个例子作为开始的例子,因为它很好地组合了许多不同的元素如(文本分割器、嵌入、向量存储等) ,还演示了如何在链中使用它们。通过文件回答问题包括四个步骤:
- 创建索引
- 从该索引创建检索器
- 创建一个问题回答链
- 提出问题
每个步骤都有多个子步骤和可能的配置。在本文中,我们将主要关注创建索引。我们将展示这样做的一行程序,然后分解实际发生的情况。首先,让我们导入一些无论如何都会使用的通用类:
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
接下来在通用设置中,让我们指定要使用的文档加载程序。我们可以在Github下载state_of_the_union.txt文件
from langchain.document_loaders import TextLoader
loader = TextLoader('../state_of_the_union.txt', encoding='utf8')
创建索引
为了尽快开始,我们可以使用VectorstoreIndexCreator。
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator().from_loaders([loader])
日志输出:
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
现在已经创建了索引,我们可以使用它来询问数据的问题。需要注意的是,在引擎盖下,这实际上也在执行一些步骤,我们将在本文后面介绍这些步骤。
query = "What did the president say about Ketanji Brown Jackson"
index.query(query)
输出:
" The president said that Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He also said that she is a consensus builder and has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
输入:
query = "What did the president say about Ketanji Brown Jackson"
index.query_with_sources(query)
输出:
{'question': 'What did the president say about Ketanji Brown Jackson','answer': " The president said that he nominated Circuit Court of Appeals Judge Ketanji Brown Jackson, one of the nation's top legal minds, to continue Justice Breyer's legacy of excellence, and that she has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.\n",'sources': '../state_of_the_union.txt'}
从VectorstoreIndexCreator返回的是VectorStoreIndexWrapper,它提供了这些优秀的查询和query_with_sources功能。如果我们只是想直接访问向量存储,我们也可以这样做:
index.vectorstore
输出:
<langchain.vectorstores.chroma.Chroma at 0x119aa5940>
如果我们想要访问VectorstoreRetriever,我们可以使用:
index.vectorstore.as_retriever()
输出:
VectorStoreRetriever(vectorstore=<langchain.vectorstores.chroma.Chroma object at 0x119aa5940>, search_kwargs={})
演练
VectorstoreIndexCreator在加载文件后有三个主要步骤:
- 将文档分割成块
- 为每个文档创建嵌入
- 在向量库中存储文档和嵌入
让我们用代码来演示一下:
documents = loader.load()
接下来,我们将把文档分割成块:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
然后,我们将选择要使用的嵌入:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
现在我们创建用作索引的向量存储:
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
日志输出:
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
这就是创建索引的过程,然后,我们在一个检索接口中公开这个索引“”
retriever = db.as_retriever()
然后,像之前一样,我们创建一个链,并使用它来回答问题:
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
输出:
" The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
VectorstoreIndexCreator只是所有这些逻辑的包装器。我们还可以使用文本分割器、嵌入以及向量存储中进行配置。例如,我们可以按以下方式配置它:
index_creator = VectorstoreIndexCreator(vectorstore_cls=Chroma, embedding=OpenAIEmbeddings(),text_splitter=CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
)
参考文献:
[1] LangChain官方网站:https://www.langchain.com/
[2] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[3] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[基础知识])
自然语言处理从入门到应用——LangChain:索引(Indexes)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 索引(Indexes)是指为了使LLM与文档更好地进行交互而对其进行结构化的方式。在链中,索引最常用于“检索”步骤中,该步骤指的是根据用户的查询返回最相关的文档:…...
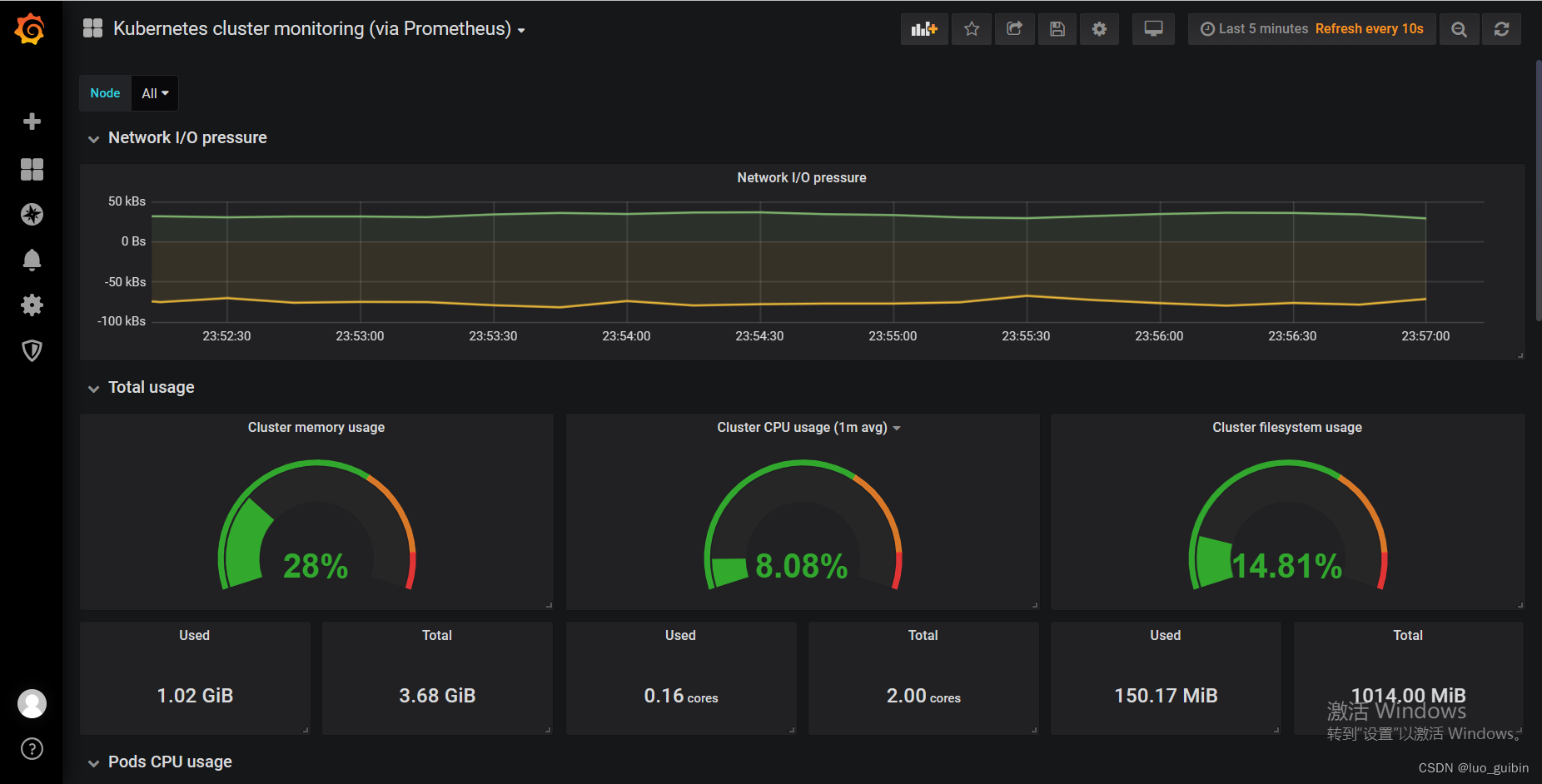
k8s集群监控方案--node-exporter+prometheus+grafana
目录 前置条件 一、下载yaml文件 二、部署yaml各个组件 2.1 node-exporter.yaml 2.2 Prometheus 2.3 grafana 2.4访问测试 三、grafana初始化 3.1加载数据源 3.2导入模板 四、helm方式部署 前置条件 安装好k8s集群(几个节点都可以,本人为了方便实验k8s集…...
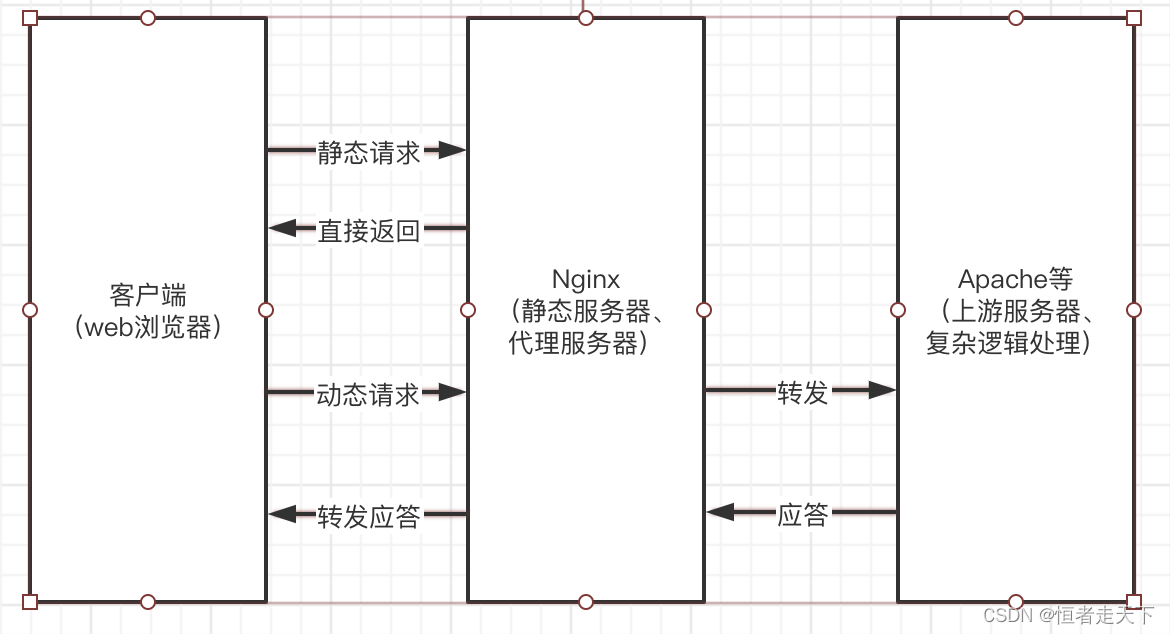
nginx反向代理流程
一、nginx反向代理流程 反向代理:使用代理服务器来接受internet上的连接请求,然后将请求转发给内部网络中的上游服务器,并将上游服务器得到的结果返回给请求连接的客户端,代理服务器对外表现就是一个web服务器。Nginx就经常拿来做…...

Java“牵手”根据店铺ID获取淘宝店铺所有商品数据方法,淘宝API实现批量店铺商品数据抓取示例
淘宝天猫商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取淘宝整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问淘宝商城的网页来获取店铺所有商品详情信息内的评论数据…...

从0开始yolov8模型目标检测训练
从0开始yolov8模型目标检测训练 1 大环境 首先有大环境,即已经准备好了python、nvidia驱动、cuda、cudnn等。 2 yolov8的虚拟环境 2.1 创建虚拟环境 conda create -n yolov8 python3.102.2 激活虚拟环境 注意:激活虚拟环境的时候,需要清…...

设计模式-抽象工厂模式
抽象工厂模式:该模式是对工厂模式的拓展,因为工厂模式中创建的产品都需要继承自同一个父类或接口,创建的产品类型相同,无法创建其他类型产品,所以抽象工厂模式对其进行拓展,使其可以创建其他类型的产品。 …...
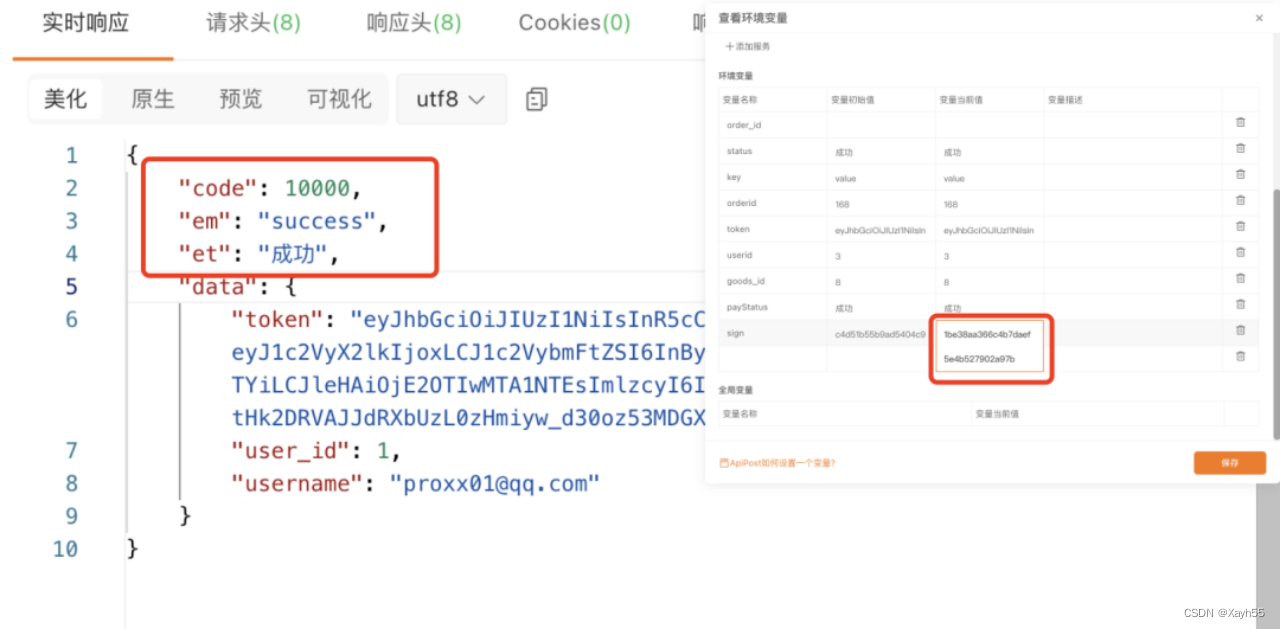
如何用Apipost实现sign签名?
我们平常对外的接口都会用到sign签名,对不同的用户提供不同的apikey ,这样可以提高接口请求的安全性,避免被人抓包后乱请求。 如何用Apipost实现sign签名? 可以在Apipost中通过预执行脚本调用内置的JS库去实现预执行脚本是在发送请求之前自…...
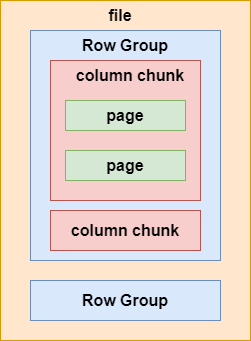
Hive底层数据存储格式
前言 在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。 一、三…...
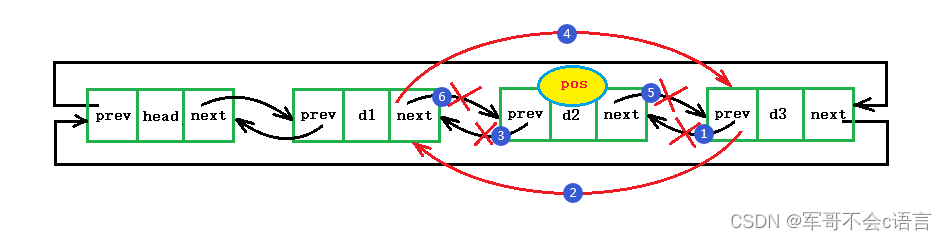
双向-->带头-->循环链表
目录 一、双向带头循环链表概述 1.什么是双向带头循环链表 2.双向带头循环链表的优势 3.双向带头循环链表简图 二、双向带头循环链表的增删查改图解及代码实现 1.双向带头循环链表的头插 2.双向带头循环链表的尾插 3.双向带头循环链表的头删 4.双向带头循环链表的尾删…...

Opencv4基于C++基础入门笔记:OpenCV环境配置搭建
文章目录: 一:软件安装 二:配置环境(配置完之后重启一下软件) 1.配置电脑系统环境变量 vs2012及其以下 vs2014及其以上 2.配置VS软件环境变量 vs2012及其以下 vs2014及其以上 三:测试 vs2012及其…...

JS基础之实现map方法
提示:内容虽少,但是里面也有好几个知识点。 step 1:实现函数 function mapTmp (fn){if(!Array.isArray(this) || !this?.length) return [];const arr [];this.forEach((item, index) > {const newItem fn(item, index, this);arr.pu…...
FPGA应用学习笔记-----复位电路(二)和小结
不可复位触发器若和可复位触发器混合写的话,不可复位触发器是由可复位触发器馈电的。 不应该出现的复位,因为延时导致了冒险,异步复位存在静态冒险 附加素隐含项,利用数电方法,消除静态冒险 这样多时钟区域还是算异步的…...
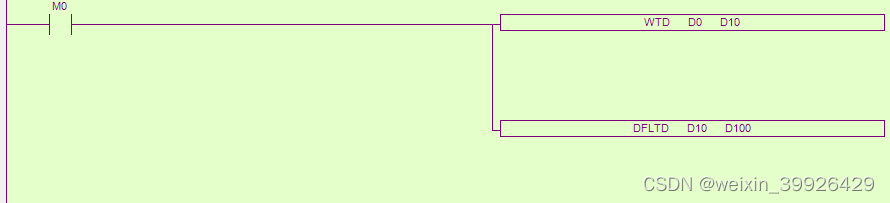
信捷 XD PLC 16位整数转换为双精度浮点数
完成16位整数转换为双精度浮点数,信捷XD PLC需要两个指令,逐步转换,一个指令搞不定。 具体的: 第1步:int16->int32 第2步:int32->Double 例子,比如说将D0转换成浮点数放到D100~D103...
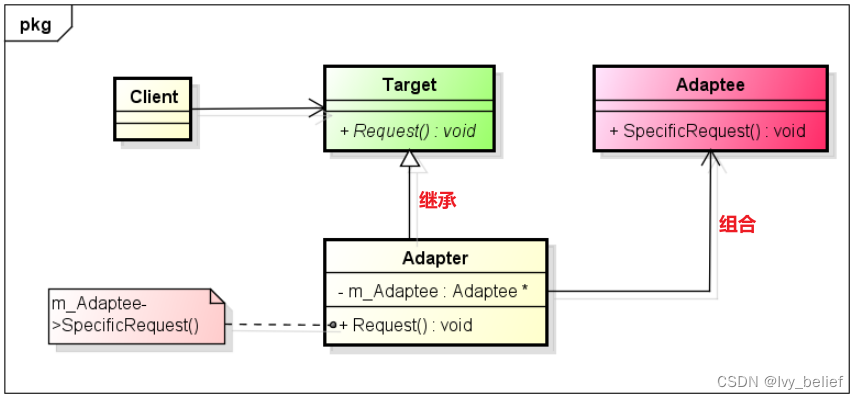
(二)结构型模式:1、适配器模式(Adapter Pattern)(C++实现示例)
目录 1、适配器模式(Adapter Pattern)含义 2、适配器模式应用场景 3、适配器模式的UML图学习 4、C实现适配器模式的示例 1、适配器模式(Adapter Pattern)含义 将一个接口转换为客户端所期待的接口,从而使两个接口…...
【编程二三事】ES究竟是个啥?
在最近的项目中,总是或多或少接触到了搜索的能力。而在这些项目之中,或多或少都离不开一个中间件 - ElasticSearch。 今天忙里偷闲,就来好好了解下这个中间件是用来干什么的。 ES是什么? ES全称ElasticSearch,是个基于Lucen…...
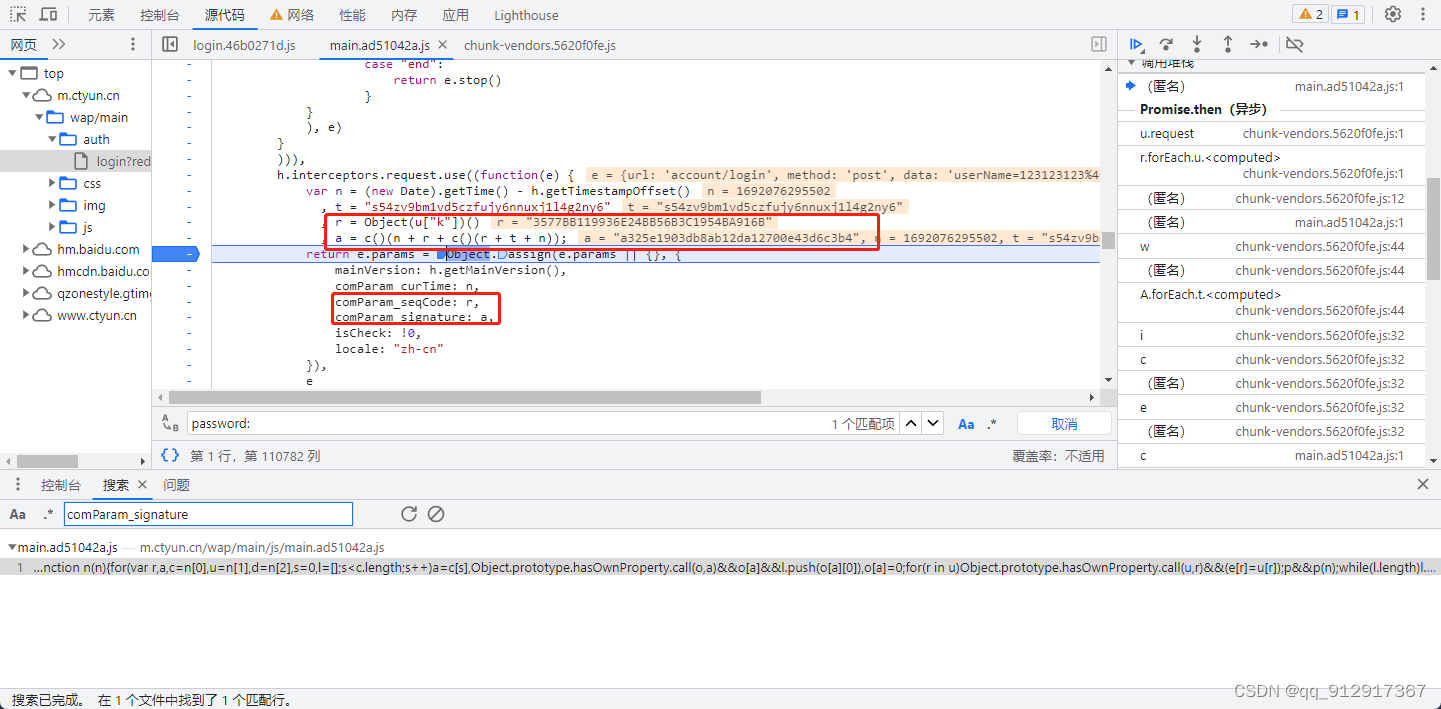
爬虫逆向实战(三)--天某云登录
一、数据接口分析 主页地址:天某云 1、抓包 通过抓包可以发现登录接口是account/login 2、判断是否有加密参数 请求参数是否加密? 通过“载荷”模块可以发现password、comParam_signature、comParam_seqCode是加密的 请求头是否加密? 无…...

不要过于迷恋软件架构,要重视如何设计根据简单和清晰的设计
1. 设计一个计算机系统的目标应该是简单性 。 系统越简单,理解起来就越简单,找到问题就越简单,实现它就越简单。描述的语言越清晰,设计就越容易理解。 干净的设计类似于干净的代码:它易于阅读且易于理解。 2. 如何编…...
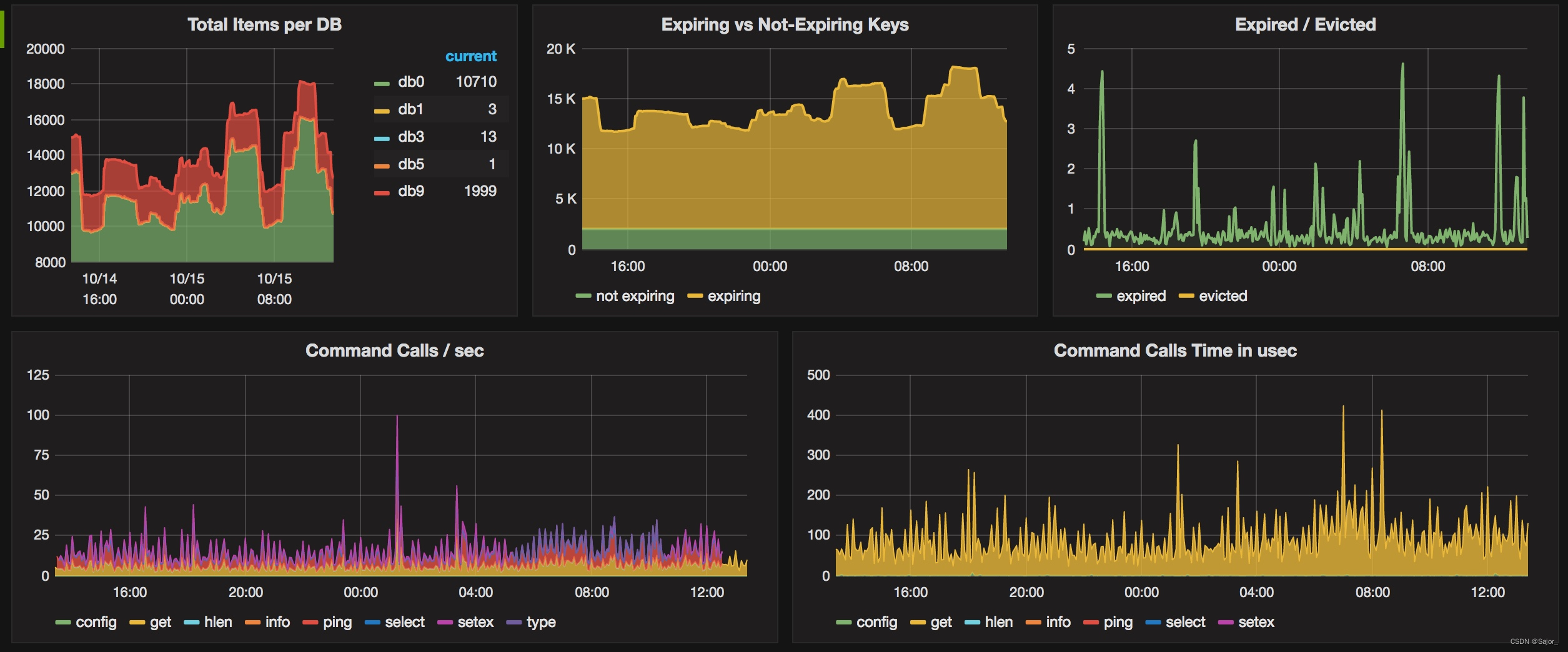
Grafana监控 Redis Cluster
Grafana监控 Redis Cluster 主要是使用grafana来实现监控,grafana可以对接多种数据源,在官网中可以找到Redis数据源,需要安装redis data source插件。当然也可以利用Prometheus来做数据源,下面分别记录一下这两种数据源的安装配置…...

k8s 认证和权限控制
k8s 的认证机制是啥? 说到 k8s 的认证机制,其实之前咋那么也有提到过 ServiceAccouont ,以及相应的 token ,证书 crt,和基于 HTTP 的认证等等 k8s 会使用如上几种方式来获取客户端身份信息,不限于上面几种…...

性能优化的重要性
性能优化的重要性 性能优化的重要性摘要引言注意事项代码示例及注释性能优化的重要性 性能优化的重要性在 Java 中的体现响应速度资源利用效率扩展性与可维护性并发性能合理的锁策略线程安全的数据结构并发工具类的应用避免竞态条件和死锁 总结代码示例 博主 默语带您 Go to Ne…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...