LLM - 大模型评估指标之 BLEU

目录
一.引言
二.BLEU 简介
1.Simple BLEU
2.Modified BLEU
3.Modified n-gram precision
4.Sentence brevity penalty
三.BLEU 计算
1.计算句子与单个 reference
2.计算句子与多个 reference
四.总结
一.引言
机器翻译的人工评价广泛而昂贵,且人工评估可能需要持续数月才能完成且涉及到无法重复使用的人工劳动。BLEU - bilingual evaluation understudy 字面直译意思为'双语评估替身',它的诞生意在提供一种双语互译的质量评估辅助。该方法快速、廉价且独立于语言,且与人类评估高度相关。该评估方法最早应用于机器翻译与人工翻译的快速效果评估,当下 LLM 火热但很多生成的答案由于需要人工评估效果好坏从而导致没有量化指标衡量其好坏,这里简单介绍下 BLEU 的计算与使用。
二.BLEU 简介
Bleu 实现的主要编程任务是将候选者的 n-gram 与参考翻译的 n-gram 进行比较并计算匹配的数量。这些匹配与位置无关。匹配越多,候选翻译越好。为简单起见,我们首先专注于计算 unigram 匹配。
1.Simple BLEU

以一元组即单个单词为例:
◆ Reference 1、2 为参考输出,MT output 为机器翻译输出
◆ MT output 输出三个词均为 the,分母为 7
◆ the 在参考译文中均出现,所以分子为 7
此时 P = 7 / 7 = 1,显然与我们的直观感受不匹配。
2.Modified BLEU
前面这种简单的判断候选翻译词是否在参考语句中出现的 contains 方法显然不够理想,所以提出了 Modified BLEU,Modified 主要修改了上述分子不合理的计算方式,这里有如下定义:
修剪即修改后的单词 Wi 在 Reference J 中的 Count 计算为上式,其中:
◆ 代表单词 wi 的个数,上文中 wi = the,其在 MT output 中个数为 7
◆代表 wi 在 参考 j 中出现的次数,the 在 R1 中出现了 2 次,在 R2 中出现了 1 次
◆ 该指标定义了对于第 j 个参考,wi 的截断计数,对于 R1 该值为 min(7, 2) = 2,R2 为 1
◆ wi 在所有参考翻译里的综合截断计数,以 the 为例,这里 max(1, 2) = 2
修改后的方法分母不变仍未 7,分子为 2,所以 BELU Score = 2 / 7,修改后的分数相对合理。
3.Modified n-gram precision
上面只考虑了单个单词的情况,虽然我们调整了分子的计算方法,分数虽然相对合理,但是由于翻译是重复的单个单词,所以实际观感依然很差。基于这种情况,算法考虑引入 N-Gram,针对不同的词组进行 BLEU 分数的评估,一般 N = 4,以下面语句为例:

我们分别基于 MT output 计算 1-gram 到 4-gram:
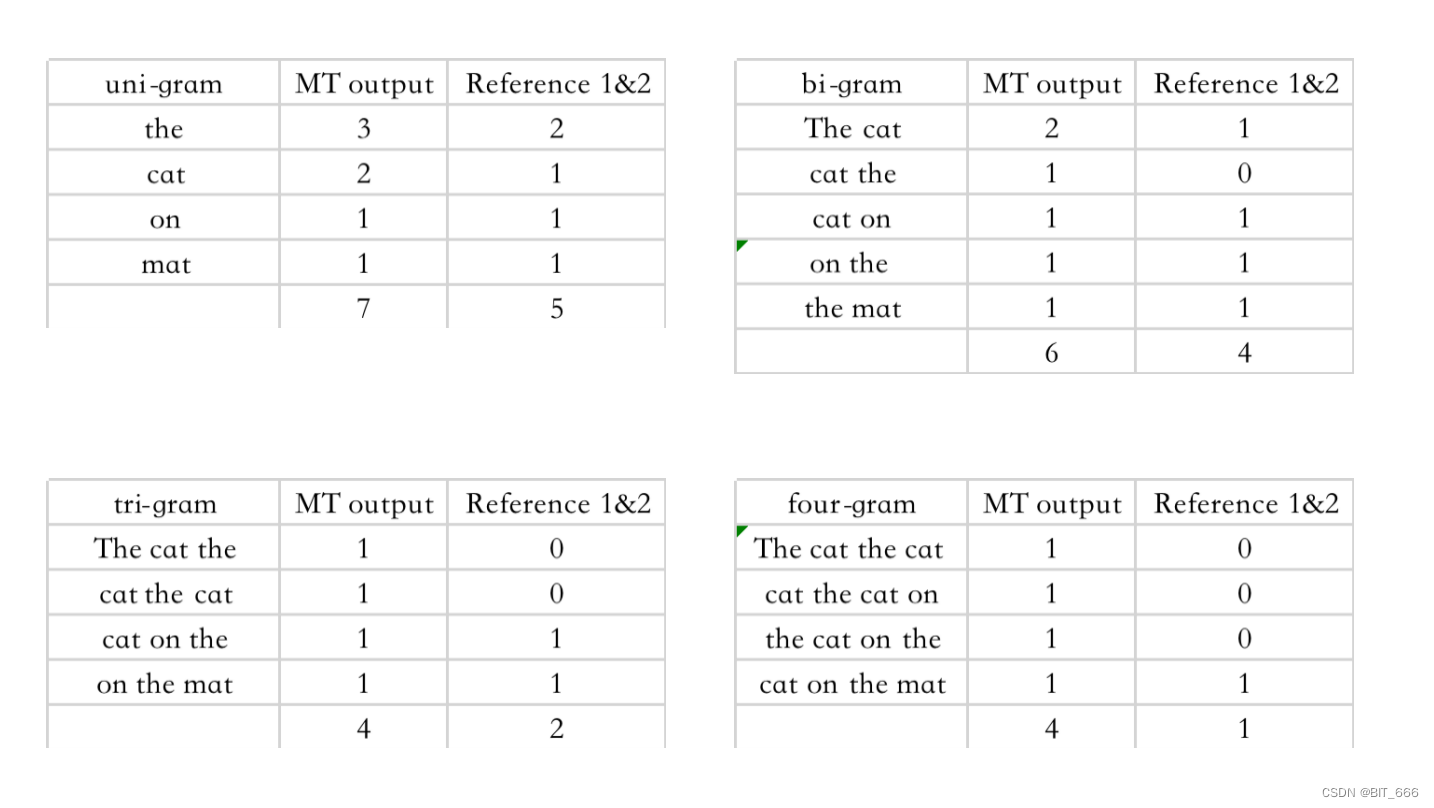
对于更长的段落,我们可以将其理解为更大的句子:

这里使用句子级修改精度的单词加权平均值,而不是句子加权平均值。
4.Sentence brevity penalty

译句较短时,计算得到的 BLEU 分数会有一定失真,为此引入了 Sentence brevity penalty 翻译短句惩罚,对于译句相对参考翻译较短的情况通过引入 BP 对短句进行惩罚:
修改前的 BLEU 计算公式:
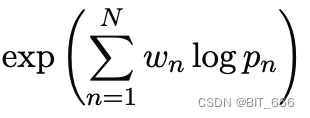
这里采用加权求和的方式,针对不同 n-gram 的概率进行计算,修改后的 BELU 公式为:

c 代表 candidate 候选翻译,r 代表 reference 参考翻译,对于 c ≤ r 的情况,会针对分数进行一些惩罚,其中 BP 的计算基于 r、c 和 exp 指数函数。论文中 baseline 的 n-gram 选择为 N=4,Wn 选择为 1/N。
三.BLEU 计算
python 通过 nltk 库可以计算 output 与 reference 之间的 BLEU 分数,多个 reference 可以通过 reference 的列表传递。BLEU 分数的范围通常在 0-1 之间,其中 1 表示完美匹配,分数越高匹配程度越高。
1.计算句子与单个 reference
from nltk.translate.bleu_score import sentence_bleu# 参考句子列表
reference = [['The', 'cat', 'is', 'on', 'the' ,'mat']]
# 候选句子
candidate = ['the', 'the', 'the', 'the', 'the', 'the', 'the']# 计算BLEU分数
bleu_score = sentence_bleu(reference, candidate)print("BLEU分数:", bleu_score)以上面 7 个 'the' 为例 BLEU分数: 1.1200407237786664e-231。

2.计算句子与多个 reference
from nltk.translate.bleu_score import sentence_bleu# 参考句子列表
reference = [['The', 'cat', 'is', 'on', 'the' ,'mat'],['There', 'is', 'a', 'cat', 'on', 'the', 'mat']]
# 候选句子
candidate = ['The', 'cat', 'the', 'cat', 'on', 'the', 'mat']# 计算BLEU分数
bleu_score = sentence_bleu(reference, candidate)print("BLEU分数:", bleu_score)以 'the cat the cat on the mat' 为例 BLEU分数: 0.4671379777282001。
四.总结
BLEU 最早用于评估机器翻译结果,其主要考虑 n-gram 词组的匹配程度,并引入了 BP 惩罚系数。BLEU 的优点是计算快速,定义简单,结果具有一定参考价值;缺点是只考虑单词的简单组合,未考虑更复杂的语法或近似表达。
提起 n-gram 不得不想起 embedding 的鼻祖 word2vec,本质上 BLEU 其实也是在计算共现的频率,并针对长短句的情况进行了一定的加权优化。所以在 LLM 领域,我们一方面可以基于 NLTK API 快速计算生成效果的硬性指标,另一方面也可以基于 n-gram 进行指标的修改适配自己的业务特点。
相关文章:
LLM - 大模型评估指标之 BLEU
目录 一.引言 二.BLEU 简介 1.Simple BLEU 2.Modified BLEU 3.Modified n-gram precision 4.Sentence brevity penalty 三.BLEU 计算 1.计算句子与单个 reference 2.计算句子与多个 reference 四.总结 一.引言 机器翻译的人工评价广泛而昂贵,且人工评估可…...

http学习笔记3
第 11 章 Web 的攻击技术 11.1 针对 Web 的攻击技术 简单的 HTTP 协议本身并不存在安全性问题,因此协议本身几乎不会成为攻击的对象。应用 HTTP 协议的服务器和客户端,以及运行在服务器上的 Web 应用等资源才是攻击目标。目前,来自互联网的攻…...
【Redis】Redis 的主从同步
【Redis】Redis 的主从同步 很多企业都没有使用 Redis 的集群,但是至少都做了主从。有了主从,当主节点(Master) 挂掉的时候,运维让从节点 (Slave) 过来接管,服务就可以继续,否则主节点需要经过数据恢复和重启的过程&a…...
文本图片怎么转Excel?分享一些好用的方法
在处理数据时,Excel 是一个非常强大的工具,但有时候需要将文本和图片转换为 Excel 格式,这可能会让人感到困惑。在本文中,我们将介绍一些好用的方法,以便您能够轻松地将文本和图片转换成 Excel 格式。 将文本图片为Exc…...
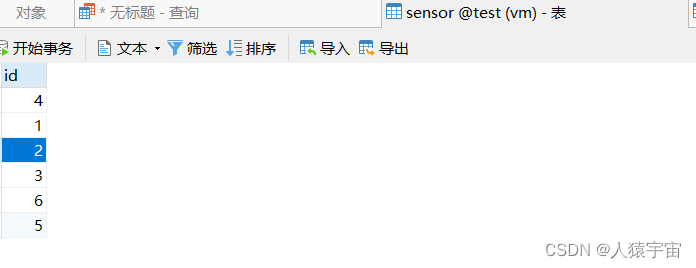
大数据-玩转数据-Flink 自定义Sink(Mysql)
一、说明 如果Flink没有提供给我们可以直接使用的连接器,那我们如果想将数据存储到我们自己的存储设备中,mysql 的安装使用请参考 mysql-玩转数据-centos7下mysql的安装 创建表 CREATE TABLE sensor (id int(10) ) ENGINEInnoDB DEFAULT CHARSETutf8二…...

linux17 线程安全 线程同步
1、线程安全: 多线程程序无论调度顺序如何,都能保证程序 的正确性,就说该程序处于线程安全的状态 1)、同步 2)、线程安全函数//有的函数不适合多线程使用,是函数自身的原因。 2、线程安全函数 1&#…...
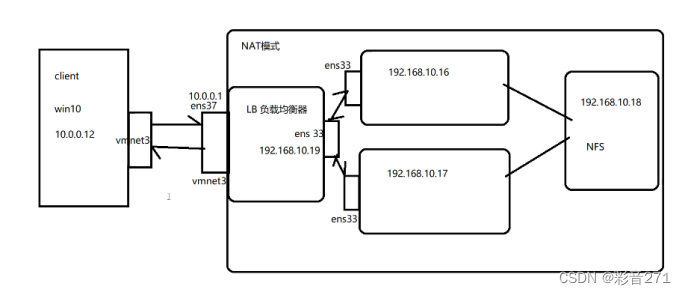
lvs集群与nat模式
一,什么是集群: 集群,群集,Cluster,由多台主机构成,但是对外只表现为一个整体,只提供一个访问入口(域名与ip地址),相当于一台大型计算机。 二,集…...
【开源分享】在线客服系统搭建-基于php和swoole客服系统CRMchat(附源码完整搭建教程)...
CRMChat是一款开源的在线客服系统,后台管理使用thinkphp框架,消息通讯使用swoole扩展,现在我来部署搭建一下。 这是一款不可商用的开源客服系统,如果有商用需求可以访问我的网站:gofly.v1kf.com 域名解析 以阿里云为例…...

Webpact学习笔记记录
Webpact学习笔记记录 一.初始化项目1.生成package.json2.安装webpack3.执行webpack体验 二、webpack的配置文件三、less-loader解析less1.安装loader2.配置 四、eslint-loader语法检查1.安装loader2.配置loader3.在package.json中加入 五、js语法转换1.安装loader2.配置loader …...

Python代码实现解析MULTIPOLYGON几何对象类型数据为嵌套列表
MULTIPOLYGON MULTIPOLYGON是一种地理信息系统(GIS)中的几何对象类型,用于表示由多个多边形组成的复杂地理区域。它是一种多边形的集合,每个多边形可以是简单的凸多边形或复杂的凹多边形。 MULTIPOLYGON类型的几何对象通常用于描…...

SSH连接工具汇总
xshell 这是个熟悉的软件啦,目前我正在使用Xshell_7 链接:https://www.xshell.com/zh/xshell/ FinalShell 国产软件,有windows和MAC版本;使用方便而且免费,但是软件比较占用内存。但是都2021年了,笔记本…...
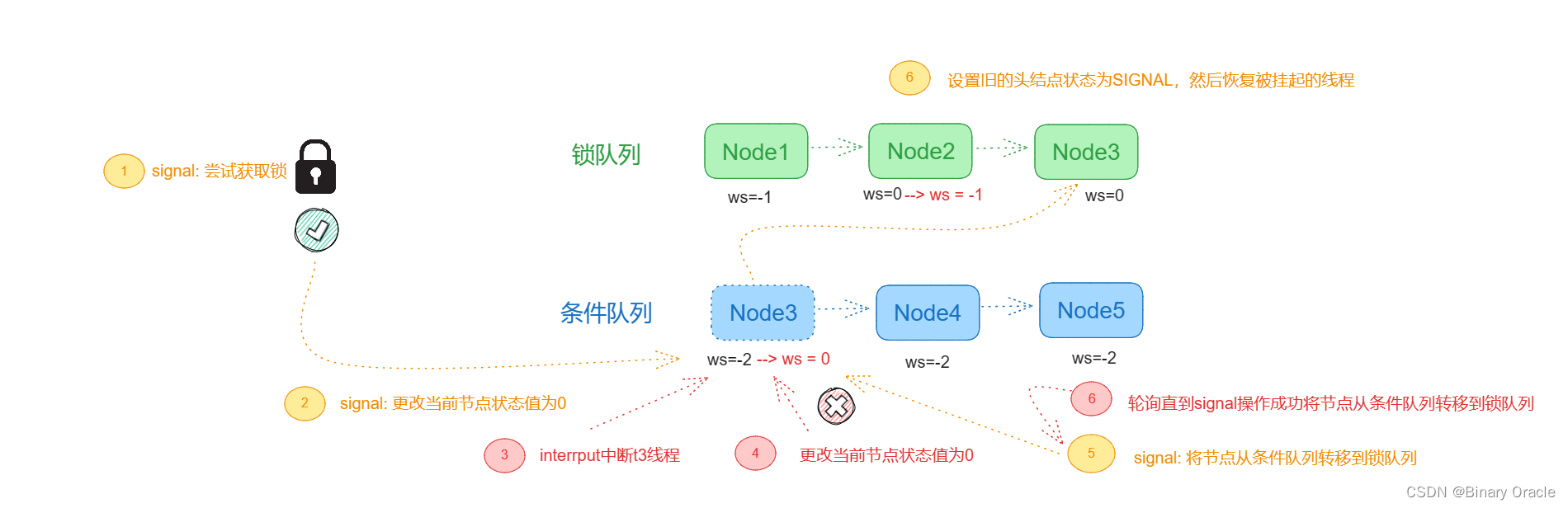
Java的AQS框架是如何支撑起整个并发库的
如何设计一个抽象队列同步器 引言AQS需要解决哪些场景下的问题互斥模式获取锁抢锁失败入队 释放锁小总结 共享模式获取共享资源释放共享资源唤醒丢失问题 小总结 混合模式获取写锁释放写锁获取读锁读锁是否应该阻塞 释放读锁小总结 栅栏模式等待递减计数 条件变量模式等待条件成…...
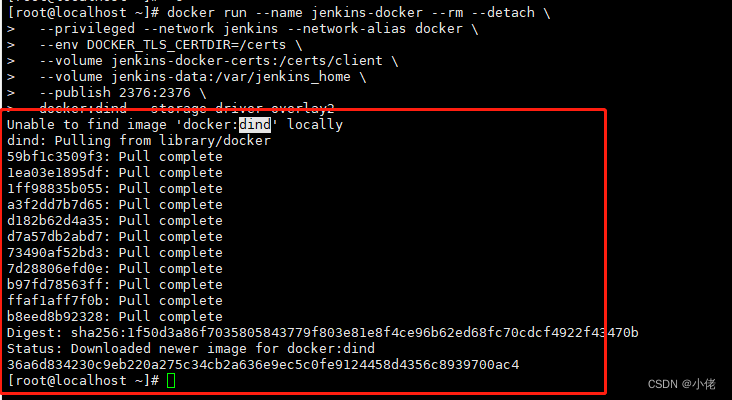
一.net core 自动化发布到docker (Jenkins安装)
目录 1.安装Jenkins 参考资料:https://www.jenkins.io/doc/book/installing/docker/#downloading-and-running-jenkins-in-docker 1.Open up a terminal window.(打开一个终端窗口。) 2.Create a bridge network in Docker using the following docker network create comma…...
,必会题,思维题)
二刷LeetCode--148. 排序链表(C++版本),必会题,思维题
思路,本题其实考察了两个点:合并链表、链表切分。首先从1开始,将链表切成一段一段,因为需要使用归并,所以下一次的切分长度应该是当前切分长度的二倍,每次切分,我们拿出两段,然后将第…...

css flex 上下结构布局
display: flex; flex-flow: column; justify-content: space-between;...

win下qwidget全屏弹窗后其他窗口鼠标样式无法更新的问题
在win平台下,实现截取选桌面执行推理功能,用一个qwidget(j对象名为m_selectWidget)来显示选取范围的边框,但这个qwidget显示后,其他窗口在他下面可以接受鼠标相应的事件,但原来的鼠标形状功能失效(mac正常&…...
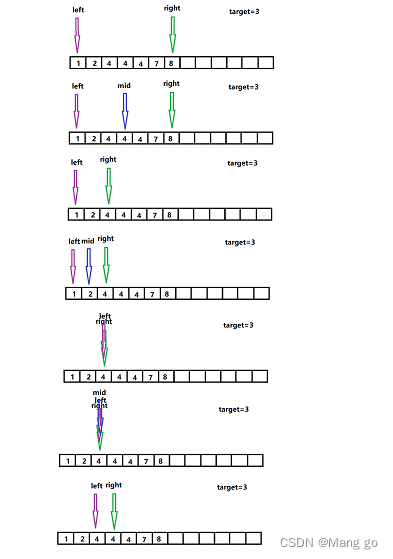
Java【数据结构】二分查找
🌞 题目: 🌏在有序数组A中,查找目标值target 🌏如果找到返回索引 🌏如果找不到返回-1 算法描述解释前提给定一个内含n个元素的有序数组A,满足A0<A1<A2<<An-1,一个待查值target1设…...

数据库技术--数据库引擎,数据访问接口及其关系详解(附加形象的比喻)
目录 背景数据库引擎Jet数据库:ISAM:ODBC(Open Database Connectivity): 数据访问接口ADO(ActiveX Data Objects)DAO(Data Access Objects)RDO(Remote Data O…...
)
【BASH】回顾与知识点梳理(三十三)
【BASH】回顾与知识点梳理 三十三 三十三. 认识系统服务 (daemons)33.1 什么是 daemon 与服务 (service)早期 System V 的 init 管理行为中 daemon 的主要分类 (Optional)systemd 使用的 unit 分类systemd 的配置文件放置目录systemd 的 unit 类型分类说明 33.2 透过 systemctl…...
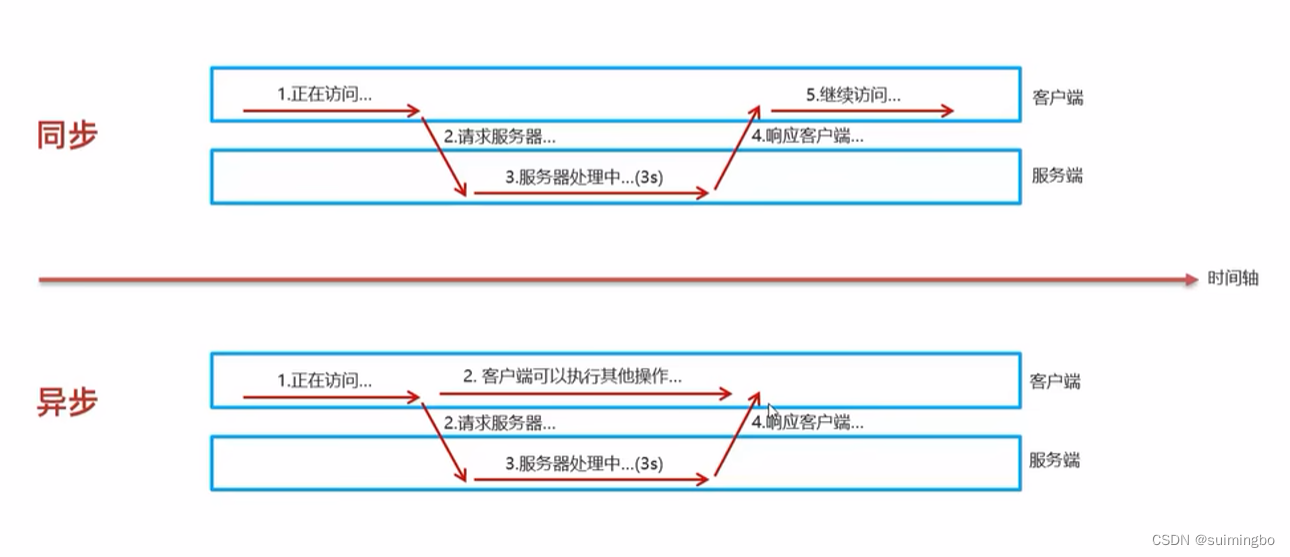
同步请求和异步请求
同步请求和异步请求是在网络编程中常用的两种通信模式,它们有以下区别: 同步请求: 在发送一个请求后,程序会一直等待服务器返回响应,期间无法进行其他操作。请求发出后,程序会阻塞在请求处,直…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...

免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南
免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...