Java进阶篇--数据结构
目录
一.数组(Array):
1.1 特点:
1.2 基本操作:
1.3 使用数组的好处包括:
1.4 数组也有一些限制:
二.集合框架(Collections Framework):
2.1 列表(List):
2.1.1 数组列表(ArrayList):
扩展知识:
方法:
ArrayList的遍历方式
ArrayList使用泛型
Arrays工具类
2.1.2 链表(LinkedList):
常用方法:
2.1.3 使用选择:
2.1.4 示例代码:
2.2 集(Set):
2.2.1 哈希集(HashSet):
基本类型对应的包装类表如下:
HashSet的常用方法包括:
2.2.2 树集(TreeSet):
TreeSet的常用方法包括:
2.2.3 使用选择:
2.2.4 示例代码:
2.3 映射(Map):
2.3.1 哈希映射(HashMap):
2.3.2 树映射(TreeMap):
2.3.3 使用选择
2.3.4 示例代码
三.栈(Stack)和队列(Queue):
3.1方法
3.2示例代码
四.树(Tree):
4.1 二叉树(Binary Tree):
4.2二叉搜索树(Binary Search Tree):
4.3 操作方法
4.4 树的遍历
4.4.1树的遍历包括两种主要方式:
4.4.2 树的两种基本遍历方式:
4.5 示例代码
五.图(Graph):
六.堆(Heap):
七.链表(LinkedList):
八.MAP:
Java 提供了多种数据结构来有效地组织和处理数据。以下是一些常见的 Java 数据结构:
一.数组(Array):
数组(Array)是一种线性数据结构,用于存储固定大小的相同类型元素的连续序列,可以通过索引快速访问和修改元素。。在 Java 中,数组可以包含基本类型(如 int、double、char 等)或引用类型(如对象、字符串等)的元素。
1.1 特点:
- 元素类型必须相同,即数组是同一类型的项的集合。
- 长度固定,在创建数组时需要指定大小,后续无法改变。
- 内存中分配连续的空间,元素之间存储紧密,通过索引快速访问和修改元素。
1.2 基本操作:
-
初始化:创建一个数组,并为其赋初值。
-
遍历:使用循环遍历数组中的每个元素。
-
打印:将数组中的元素依次输出。
-
最大值:遍历数组,通过比较找到数组中的最大值。
-
最大值下标:遍历数组,记录当前最大值的下标。
- 使用增强for循环(foreach):对于数组中的每个元素,可以使用增强for循环进行遍历并执行相应的操作。
- 复制数组有三种方法:
- 遍历原数组,逐个复制到新数组。
- 使用
System.arraycopy() - 使用数组的
clone()方法复制数组。
- 线性查找::从数组的第一个元素开始逐个比较,直到找到目标元素或遍历完整个数组。时间复杂度为O(n),其中n为数组长度。
- 二分查找:要求在已排序的数组中进行查找。首先确定数组的中间元素,将目标值与中间元素进行比较,若相等则返回该位置,若小于中间元素,则在左半部分继续查找,若大于中间元素,则在右半部分继续查找。重复以上步骤,直到找到目标值或查找范围为空。时间复杂度为O(logn),其中n为数组长度。
- 选择排序:每次遍历找到当前范围内的最小(或最大)元素,并将其放置在已排序的部分的末尾。通过不断选择最小(或最大)的元素,逐步完成整个数组的排序。注意,选择排序的时间复杂度为O(n^2),其中n为数组的长度。虽然简单易实现,但对于较大规模的数据可能效率较低。
以下的Java代码示例,包含数组的初始化、遍历、打印、最大值、最大值下标、使用增强for循环遍历、复制数组以及线性查找、二分查找和选择排序算法的实现。
import java.util.Arrays;public class myClass {public static void main(String[] args) {// 初始化数组int[] arr = {5, 3, 9, 1, 7};// 遍历数组for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();// 打印数组System.out.println(Arrays.toString(arr));// 最大值int max = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}System.out.println("最大值:" + max);// 最大值下标int maxIndex = 0;for (int i = 1; i < arr.length; i++) {if (arr[i] > arr[maxIndex]) {maxIndex = i;}}System.out.println("最大值下标:" + maxIndex);// 使用增强for循环遍历for (int num : arr) {System.out.print(num + " ");}System.out.println();// 复制数组方法一(遍历原数组,逐个复制到新数组)int[] copyArr1 = new int[arr.length];for (int i = 0; i < arr.length; i++) {copyArr1[i] = arr[i];}// 复制数组方法二(使用System.arraycopy()方法)int[] copyArr2 = new int[arr.length];System.arraycopy(arr, 0, copyArr2, 0, arr.length);// 复制数组方法三(使用数组的clone()方法)int[] copyArr3 = arr.clone();System.out.println("复制后的数组:" + Arrays.toString(copyArr3));// 线性查找int target = 9;int linearSearchIndex = -1;for (int i = 0; i < arr.length; i++) {if (arr[i] == target) {linearSearchIndex = i;break;}}System.out.println("线性查找:" + (linearSearchIndex != -1 ? linearSearchIndex : "未找到"));// 二分查找(前提是数组必须有序)Arrays.sort(arr); // 先排序int binarySearchIndex = Arrays.binarySearch(arr, target);System.out.println("二分查找:" + (binarySearchIndex >= 0 ? binarySearchIndex : "未找到"));// 选择排序selectionSort(arr);System.out.println("选择排序后的数组:" + Arrays.toString(arr));}// 选择排序算法实现public static void selectionSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {int minIndex = i;for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}if (minIndex != i) {int temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}}
}
运行结果:
5 3 9 1 7
[5, 3, 9, 1, 7]
最大值:9
最大值下标:2
5 3 9 1 7
复制后的数组:[5, 3, 9, 1, 7]
线性查找:2
二分查找:4
选择排序后的数组:[1, 3, 5, 7, 9]1.3 使用数组的好处包括:
- 快速随机访问:由于元素在内存中连续存储,所以可以通过索引快速定位和访问元素。
- 内存效率:数组在创建时需要指定长度,适用于已知固定数量的元素存储场景,不需要额外的指针或链接信息。
- 数组操作简单:Java 提供了一些便利的方法和属性,使得数组的操作更加简单和高效。
1.4 数组也有一些限制:
- 长度固定:一旦创建,长度无法改变,需要事先确定好所需的元素个数。
- 内存浪费:如果数组长度过大或未充分利用,会造成内存浪费。
- 数据类型:数组只能存储一种类型的数据;
- 插入和删除困难:在数组中插入或删除元素可能需要移动其他元素,开销较大。
二.集合框架(Collections Framework):
提供了一系列接口和类,用于存储和操作对象的集合。常用的集合类包括:
2.1 列表(List):
有序、可重复的集合,例如 ArrayList、LinkedList。
2.1.1 数组列表(ArrayList):
- ArrayList是基于数组实现的动态数组,内部通过数组来存储元素。
- 它可以自动扩容以适应元素的增加
- 它支持随机访问元素,即可以通过索引快速访问指定位置的元素。
- 数组列表适用于频繁读取和随机访问元素的场景,因为它内部使用数组存储,可以根据索引直接计算出元素的内存地址。
- ArrayList实现了List接口,继承了AbstractList类,并且还实现了RandomAccess(随机访问)、Cloneable(克隆)和Serializable(可序列化)这些接口。
- 与Vector不同,ArrayList不是线程安全的。因此,在单线程环境下建议使用ArrayList,在多线程环境下可以选择Vector或CopyOnWriteArrayList。
扩展知识:
Vector是Java中的一个旧的类,它与ArrayList具有相似的用法,但在性能和使用上存在一些差异。虽然Vector是线程安全的,但在大多数情况下,推荐使用更现代的替代方案。
一个常见的替代方案是使用Collections工具类提供的synchronizedList方法,该方法可以将ArrayList转换为线程安全的List。以下是示例代码:
List<String> lst = new ArrayList<>();
// 往lst中添加元素List<String> synList = Collections.synchronizedList(lst);
通过将原始的ArrayList通过synchronizedList方法包装,我们可以获得一个在并发环境下安全使用的List。
需要注意的是,在大多数情况下,如果不需要线程安全的特性,推荐使用ArrayList而不是Vector,因为ArrayList在性能上通常更优。只有在确实需要线程安全时,才会考虑使用Vector或通过Collections工具类获得线程安全的List。
方法:
Collection相关方法:
这些方法属于Collection类的一部分,可以被List和Set等子类继承并使用。以下是一些常见的Collection类方法:
- boolean add(E element):向集合中添加一个元素。
- boolean addAll(Collection<? extends E> collection):将一个集合中的所有元素添加到当前集合中。
- void clear():清空集合中的所有元素。
- boolean contains(Object object):判断集合是否包含指定对象。
- boolean containsAll(Collection<?> collection):判断集合是否包含给定集合中的所有元素。
- boolean isEmpty():判断集合是否为空。
- Iterator<E> iterator():返回一个用于迭代集合元素的迭代器。
- boolean remove(Object object):从集合中移除指定的对象。
- boolean removeAll(Collection<?> collection):从集合中移除给定集合中的所有元素。
- boolean retainAll(Collection<?> collection):仅保留集合中在给定集合中出现的元素,移除其他元素。
- int size():返回集合中的元素个数。
- Object[] toArray():将集合转化为数组。
- <T> T[] toArray(T[] array):将集合转化为指定类型的数组。
List接口:
List是Collection接口的子接口,拥有Collection所有方法外,还有一些对索引操作的方法。
- void add(int index, E element):在索引index处插入元素element。
- boolean addAll(int index, Collection<? extends E> c):将集合c中的所有元素插入到索引index处。
- E remove(int index):移除并返回索引index处的元素。
- int indexOf(Object o):返回对象o在ArrayList中第一次出现的索引。
- int lastIndexOf(Object o):返回对象o在ArrayList中最后一次出现的索引。
- E set(int index, E element):将索引index处的元素替换为新的element对象,并返回被替换的旧元素。
- E get(int index):返回索引index处的元素。
- List<E> subList(int fromIndex, int toIndex):返回从索引fromIndex(包含)到索引toIndex(不包含)的子列表。
- void sort(Comparator<? super E> c):根据指定的Comparator对ArrayList中的元素进行排序。
- void replaceAll(UnaryOperator<E> operator):使用指定的计算规则operator重新设置ArrayList的所有元素。
- ListIterator<E> listIterator():返回一个ListIterator对象,该接口继承了Iterator接口,在Iterator接口基础上增加了以下方法,允许向前迭代并添加元素。
- bookean hasPrevious():返回迭代器关联的集合是否还有上一个元素;
- E previous();:返回迭代器上一个元素;
- void add(E e);:在指定位置插入元素;
更多 API 方法可以查看:ArrayList
ArrayList的遍历方式
- 使用for循环和索引:
for (int i = 0; i < arrayList.size(); i++) {E element = arrayList.get(i);// 处理元素 } - 使用for-each循环:
for (E element : arrayList) {// 处理元素 } - 使用迭代器(Iterator)进行遍历:
Iterator<E> iterator = arrayList.iterator(); while (iterator.hasNext()) {E element = iterator.next();// 处理元素 }
ArrayList<E>使用泛型
泛型数据类型,用于设置 objectName(对象名) 的数据类型,只能为引用数据类型。
对于ArrayList的泛型使用,可以通过在定义ArrayList时指定泛型类型来确保集合中只能存储指定类型的元素。例如:
ArrayList<String> stringList = new ArrayList<>();
stringList.add("Hello");
stringList.add("World");
// 只能添加String类型的元素String element = stringList.get(0);
System.out.println(element); // 输出: Hello
通过使用泛型,可以提供类型安全,并且在编译期间就能够捕获类型不匹配的错误。
Arrays工具类
Arrays工具类是Java提供的用于操作数组的工具类,以下是一些常用的方法:
- boolean equals(a, b):比较两个数组是否相等。
- void fill(array, value):将指定的值填充到数组中的所有元素。
- void sort(array):对数组进行排序。
- int binarySearch(array, key):在已排序的数组中使用二分查找来查找指定的元素。
- void arraycopy(src, srcPos, dest, destPos, length):将源数组中的某个范围的元素复制到目标数组的指定位置。
2.1.2 链表(LinkedList):
- LinkedList是基于链表实现的双向链表,内部通过节点(Node)来存储元素并连接起来。
- 节点中包含了当前元素的值,以及指向前一个节点和后一个节点的引用。
- 链表支持快速插入和删除操作,因为只需要修改节点的引用关系即可,不涉及移动其他元素。
- 链表适用于频繁插入和删除元素的场景,因为在链表中插入和删除元素的开销相对较小。
- 由于链表的存储方式不同于数组,因此在访问某个位置的元素时需要遍历链表,因此随机访问的效率较低。
常用方法:
- void addFirst(E element):在链表的开头插入元素。
- void addLast(E element):在链表的末尾插入元素。
- E getFirst():获取链表中的第一个元素。
- E getLast():获取链表中的最后一个元素。
- E removeFirst():移除并返回链表中的第一个元素。
- E removeLast():移除并返回链表中的最后一个元素。
- boolean contains(Object element):判断链表是否包含指定元素。
- int size():返回链表中的元素个数。
- void clear():清空链表中的所有元素。
更多 API 方法可以查看:LinkedList
2.1.3 使用选择:
根据具体需求,选择ArrayList还是LinkedList有以下一些考虑因素:
- 如果需要频繁读取和随机访问元素,可以选择ArrayList。
- 如果需要频繁插入和删除元素,尤其是在列表的中间位置,可以选择LinkedList。
- 如果对内存空间的利用比较敏感,LinkedList可能会占用更多的内存,而ArrayList使用的内存通常较为紧凑。
总的来说,ArrayList适用于读取和随机访问操作更多的场景,而LinkedList适用于插入和删除操作更频繁的场景。
2.1.4 示例代码:
下面一个简单的示例代码,展示了如何使用ArrayList和LinkedList进行基本操作:
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;public class ListExample {public static void main(String[] args) {// 使用ArrayListList<String> arrayList = new ArrayList<>();// 添加元素arrayList.add("Apple");arrayList.add("Banana");arrayList.add("Orange");// 获取元素String firstElement = arrayList.get(0);System.out.println("ArrayList中第一个元素:" + firstElement);// 遍历元素System.out.println("ArrayList的元素:");for (String element : arrayList) {System.out.println(element);}// 删除元素arrayList.remove("Banana");// 使用LinkedListList<Integer> linkedList = new LinkedList<>();// 添加元素linkedList.add(10);linkedList.add(20);linkedList.add(30);// 获取元素int lastElement = linkedList.get(linkedList.size() - 1);System.out.println("LinkedList中最后一个元素:" + lastElement);// 遍历元素System.out.println("LinkedList的元素:");for (int element : linkedList) {System.out.println(element);}// 删除元素linkedList.remove(0);}
}
运行结果:
ArrayList中第一个元素:Apple
ArrayList的元素:
Apple
Banana
Orange
LinkedList中最后一个元素:30
LinkedList的元素:
10
20
302.2 集(Set):
集是一种无序的集合,不允许重复元素,例如 HashSet、TreeSet。
2.2.1 哈希集(HashSet):
- HashSet是基于哈希表实现的集合,具有快速查找性能。
- 哈希集不保证元素的顺序,且不允许重复元素。如果试图插入重复元素,插入操作将被忽略。
- 它还继承了Set接口和Collection接口的其他方法
- HashSet允许存储null元素。
- 添加、删除和查找元素的平均时间复杂度为O(1)。
HashSet 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类。
基本类型对应的包装类表如下:
| 基本类型 | 引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
HashSet的常用方法包括:
- boolean add(E element):向集合中添加指定元素,如果元素已经存在,则返回false。
- boolean remove(Object element):从集合中移除指定元素,如果元素存在并成功移除,则返回true。
- boolean contains(Object element):检查集合中是否包含指定元素,如果包含则返回true。
- int size():返回集合中元素的数量。
- void clear():清空集合中的所有元素。
更多 API 方法可以查看:HashSet
2.2.2 树集(TreeSet):
- TreeSet是基于红黑树(自平衡二叉搜索树)实现的有序集合。
- 树集中的元素按照自然顺序或自定义比较器进行排序,默认情况下按照元素的自然排序方式进行排序。
- 它还继承了Set接口和Collection接口的其他方法
- 树集不允许插入null元素。
- 插入、删除和查找元素的时间复杂度为O(log N),其中N为树集中的元素个数。
TreeSet的常用方法包括:
- boolean add(E element):向集合中添加指定元素,如果元素已经存在,则返回false。
- boolean remove(Object element):从集合中移除指定元素,如果元素存在并成功移除,则返回true。
- boolean contains(Object element):检查集合中是否包含指定元素,如果包含则返回true。
- int size():返回集合中元素的数量。
- void clear():清空集合中的所有元素。
- E first():返回集合中的第一个(最小)元素。
- E last():返回集合中的最后一个(最大)元素。
- Iterator<E> iterator():返回在此集合上进行迭代的迭代器。
2.2.3 使用选择:
- 使用HashSet时,你可以快速添加、删除和查找元素,并且元素的顺序可能不同。
- 如果你希望元素有一定的顺序,你可以使用TreeSet,它会根据元素的排序规则保持元素的有序性。
2.2.4 示例代码:
下面一个简单的示例代码,展示了如何使用HashSet和TreeSet进行基本操作:
import java.util.HashSet;// 引入 HashSet 类
import java.util.TreeSet;// 引入 TreeSet 类public class myClass {public static void main(String[] args) {// 使用HashSetHashSet<String> hashSet = new HashSet<>();// 添加元素hashSet.add("Apple");hashSet.add("Banana");hashSet.add("Orange");hashSet.add("Grape");// 输出集合中的元素System.out.println("HashSet:");for (String fruit : hashSet) {System.out.println(fruit);}// 检查元素是否存在System.out.println("HashSet contains 'Apple': " + hashSet.contains("Apple")); // true// 删除元素hashSet.remove("Orange");// 输出修改后的集合System.out.println("HashSet after removal:");for (String fruit : hashSet) {System.out.println(fruit);}// 使用TreeSetTreeSet<Integer> treeSet = new TreeSet<>();// 添加元素treeSet.add(5);treeSet.add(10);treeSet.add(3);treeSet.add(8);// 输出集合中的元素System.out.println("TreeSet:");for (int num : treeSet) {System.out.println(num);}// 获取最小元素和最大元素System.out.println("Min element: " + treeSet.first()); // 3System.out.println("Max element: " + treeSet.last()); // 10}
}
运行结果:
HashSet:
Apple
Grape
Orange
Banana
HashSet contains 'Apple': true
HashSet after removal:
Apple
Grape
Banana
TreeSet:
3
5
8
10
Min element: 3
Max element: 10
2.3 映射(Map):
由键值对组成的集合,每个键唯一,例如 HashMap、TreeMap。
2.3.1 哈希映射(HashMap):
- 它是基于哈希表实现的映射结构。
- HashMap是一个散列表,它存储的内容是键值对(key-value)映射。
- HashMap使用键的哈希码来确定存储位置,实现了 Map 接口,通过键快速查找值。
- 它具有较快的插入和查找操作,但不保证元素的顺序。
常用方法:
- put(key, value): 将键值对插入到哈希映射中。
- get(key): 根据键获取对应的值。
- containsKey(key): 检查哈希映射中是否包含指定的键。
- remove(key): 移除哈希映射中指定键的键值对。
- size(): 返回哈希映射中键值对的数量。
更多 API 方法可以查看:HashMap
2.3.2 树映射(TreeMap):
- 它是基于红黑树实现的有序映射结构。
- TreeMap将键按照自然顺序或通过自定义的比较器进行排序,并在内部维护一个有序的键值对集合。因此,可以根据键的顺序快速检索、遍历和范围查找元素。
常用方法:
- put(key, value): 将键值对插入到树映射中。
- get(key): 根据键获取对应的值。
- containsKey(key): 检查树映射中是否包含指定的键。
- remove(key): 移除树映射中指定键的键值对。
- size(): 返回树映射中键值对的数量。
- firstKey(): 返回树映射中最小的键。
- lastKey(): 返回树映射中最大的键。
- subMap(fromKey, toKey): 返回树映射中键的一个子集,范围从 fromKey(包括)到 toKey(不包括)。
除了上述方法,哈希映射和树映射还提供了其他一些类似的方法,如获取所有键的集合、清空映射等。具体的方法使用可以参考Java的官方文档或相关教程。
2.3.3 使用选择
这两种映射都是非常常用的数据结构,在不同的场景下使用。
- HashMap适用于需要快速查找和插入元素的情况,并且不关心元素的顺序。
- TreeMap适用于需要有序性的场景,可以按照键的顺序进行操作和遍历,在维护有序性的同时支持各种基本操作。
2.3.4 示例代码
下面一个简单的示例代码,展示了如何使用HashMap和TreeMap进行基本操作:
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;public class myClass {public static void main(String[] args) {// 使用HashMapMap<String, Integer> hashMap = new HashMap<>();// 添加键值对到HashMaphashMap.put("Apple", 1);hashMap.put("Banana", 2);hashMap.put("Orange", 3);// 获取指定键的值int appleValue = hashMap.get("Apple");System.out.println("Apple的值为:" + appleValue);// 检查HashMap是否包含指定键boolean containsKey = hashMap.containsKey("Banana");System.out.println("HashMap是否包含Banana:" + containsKey);// 移除指定键的键值对hashMap.remove("Orange");// 遍历HashMap的键值对for (String key : hashMap.keySet()) {int value = hashMap.get(key);System.out.println("键:" + key + ",值:" + value);}System.out.println("----------------------");// 使用TreeMapMap<String, Integer> treeMap = new TreeMap<>();// 添加键值对到TreeMaptreeMap.put("Apple", 1);treeMap.put("Banana", 2);treeMap.put("Orange", 3);// 获取最小的键String firstKey = ((TreeMap<String, Integer>) treeMap).firstKey();System.out.println("最小的键:" + firstKey);// 获取最大的键String lastKey = ((TreeMap<String, Integer>) treeMap).lastKey();System.out.println("最大的键:" + lastKey);// 遍历TreeMap的键值对for (String key : treeMap.keySet()) {int value = treeMap.get(key);System.out.println("键:" + key + ",值:" + value);}}
}
运行结果:
Apple的值为:1
HashMap是否包含Banana:true
键:Apple,值:1
键:Banana,值:2
----------------------
最小的键:Apple
最大的键:Orange
键:Apple,值:1
键:Banana,值:2
键:Orange,值:3三.栈(Stack)和队列(Queue):
栈是一种后进先出(LIFO)的数据结构,常用操作有入栈和出栈;队列是一种先进先出(FIFO)的数据结构,常用操作有入队和出队。Java 提供了 Stack 类和 Queue 接口,并有相关实现类如 LinkedList。
- 栈(Stack):是一种后进先出(LIFO)的数据结构,只允许在栈顶进行插入(入栈)和删除(出栈)操作。相当于把元素放在一个类似于竖起的桶中,每次插入和删除只能在桶的顶部进行。
- 队列(Queue):是一种先进先出(FIFO)的数据结构,从队尾插入元素(入队),从队头删除元素(出队)。可以理解为排队,先进来的人先出去。
在Java中,可以使用Stack类表示栈,它是Vector的子类。而Queue接口是Java集合框架的一部分,它定义了队列的基本操作,如入队、出队、获取队头元素等。Java提供了多个Queue接口的实现类,其中常用的是LinkedList,它既实现了List接口,又实现了Deque接口,可以作为队列或双端队列使用。
3.1方法
Stack的常用方法包括:
- push(element):将元素压入栈顶。
- pop():弹出并返回栈顶的元素。
- peek():返回栈顶的元素,但不会将其从栈中移除。
- isEmpty():判断栈是否为空。
- size():返回栈中元素的个数。
Queue的常用方法包括:
- add(element):将元素添加到队尾。
- offer(element):将元素添加到队尾,并返回是否成功。
- remove():移除并返回队头的元素。
- poll():移除并返回队头的元素,如果队列为空则返回null。
- peek():返回队头的元素,但不会将其从队列中移除。
- element():返回队头的元素,如果队列为空则抛出异常。
- isEmpty():判断队列是否为空。
- size():返回队列中元素的个数。
3.2示例代码
下面一个简单的示例代码,展示了如何使用Stack和Queue进行基本操作:
import java.util.Stack;
import java.util.LinkedList;
import java.util.Queue;public class myClass {public static void main(String[] args) {// 使用StackStack<Integer> stack = new Stack<>();// 入栈操作stack.push(1);stack.push(2);stack.push(3);// 出栈操作int poppedElement = stack.pop();System.out.println("出栈元素:" + poppedElement);// 获取栈顶元素int topElement = stack.peek();System.out.println("栈顶元素:" + topElement);// 判断栈是否为空boolean empty = stack.isEmpty();System.out.println("栈是否为空:" + empty);System.out.println("----------------------");// 使用QueueQueue<String> queue = new LinkedList<>();// 入队操作queue.offer("Apple");queue.offer("Banana");queue.offer("Orange");// 出队操作String polledElement = queue.poll();System.out.println("出队元素:" + polledElement);// 获取队头元素String peekedElement = queue.peek();System.out.println("队头元素:" + peekedElement);// 判断队列是否为空boolean emptyQueue = queue.isEmpty();System.out.println("队列是否为空:" + emptyQueue);}
}
运行结果:
出栈元素:3
栈顶元素:2
栈是否为空:false
----------------------
出队元素:Apple
队头元素:Banana
队列是否为空:false
四.树(Tree):
树是一种非线性的数据结构,由节点和边组成,用于表示具有层级关系的数据结构。常见的树结构包括二叉树、平衡树、红黑树等。Java 提供了 TreeSet 和 TreeMap 来实现树结构。
4.1 二叉树(Binary Tree):
是一种特殊的树结构,每个节点最多有两个子节点:左子节点和右子节点。一个节点可以没有子节点,也可以只有一个子节点。
4.2二叉搜索树(Binary Search Tree):
也称为二叉查找树或排序二叉树,是一种特殊的二叉树。它具有以下性质:
- 对于任意节点,其左子树上的所有节点的值都小于该节点的值。
- 对于任意节点,其右子树上的所有节点的值都大于该节点的值。
- 左子树和右子树都必须是二叉搜索树。
由于二叉搜索树的性质,我们可以利用它来高效地进行查找、插入和删除操作。对于任意节点,其左子树的节点值都小于该节点,因此在查找、插入或删除时,可以通过比较节点的值,有选择性地在左子树或右子树中进行操作,从而提高效率。
Java中可以使用TreeSet和TreeMap来实现二叉搜索树。它们基于红黑树(Red-Black Tree)实现,红黑树是一种自平衡的二叉搜索树,保持了良好的平衡性能。
- TreeSet是一个基于红黑树实现的有序集合,它存储的元素按照自然顺序或者指定的比较器进行排序,并且不允许出现重复元素。
- TreeMap是一个基于红黑树实现的有序映射,它存储键值对,并按照键的自然顺序或者指定的比较器进行排序。与TreeSet类似,TreeMap也不允许出现重复的键。
通过使用TreeSet和TreeMap,我们可以方便地操作二叉搜索树的相关操作,如插入、删除、查找等,并保持元素的有序性。
4.3 操作方法
- 创建树IntTree(&T):创建1个空树T。
- 销毁树DestroyTree(&T)
- 构造树CreatTree(&T,deinition)
- 置空树ClearTree(&T):将树T置为空树。
- 判空树TreeEmpty(T)
- 求树的深度TreeDepth(T)
- 获得树根Root(T)
- 获取结点Value(T,cur_e,&e):将树中结点cur_e存入e单元中。
- 数据赋值Assign(T,cur_e,value):将结点value,赋值于树T的结点cur_e中。
- 获得双亲Parent(T,cur_e):返回树T中结点cur_e的双亲结点。
- 获得最左孩子LeftChild(T,cur_e):返回树T中结点cur_e的最左孩子。
- 获得右兄弟RightSibling(T,cur_e):返回树T中结点cur_e的右兄弟。
- 插入子树InsertChild(&T,&p,i,c):将树c插入到树T中p指向结点的第i个子树之前。
- 删除子树DeleteChild(&T,&p,i):删除树T中p指向结点的第i个子树。
- 遍历树TraverseTree(T,visit())
4.4 树的遍历
4.4.1树的遍历包括两种主要方式:
-
深度优先遍历(DFS):
- 先序遍历(Preorder):根节点 -> 左子树 -> 右子树
- 中序遍历(Inorder):左子树 -> 根节点 -> 右子树
- 后序遍历(Postorder):左子树 -> 右子树 -> 根节点
-
广度优先遍历(BFS): 从根节点开始,按层级顺序逐层遍历树的节点,从左到右依次访问每个节点。
无论是深度优先遍历还是广度优先遍历,都有各自的应用场景。可以根据具体需求选择适合的遍历方式来处理树中的节点。
4.4.2 树的两种基本遍历方式:
- 先序遍历(Preorder traversal):
- 访问根节点。
- 递归地对左子树进行先序遍历。
- 递归地对右子树进行先序遍历。
先序遍历的顺序是先访问根节点,然后按照从左到右的顺序依次访问左子树和右子树。
- 中序遍历(Inorder traversal):
- 递归地对左子树进行中序遍历。
- 访问根节点。
- 递归地对右子树进行中序遍历。
中序遍历的顺序是先按照从左到右的顺序递归访问左子树,然后访问根节点,最后按照从左到右的顺序递归访问右子树。
这两种遍历方法都是通过递归实现的,可以用来遍历二叉树或其他类型的树结构。它们在不同的情况下有各自的应用,具体取决于问题的需求。
4.5 示例代码
下面一个简单的示例代码,展示了如何使用Binary Tree和Binary Search Tree进行基本操作:
// 定义二叉树节点类
class TreeNode {int val;TreeNode left;TreeNode right;public TreeNode(int val) {this.val = val;this.left = null;this.right = null;}
}// 二叉树类
class BinaryTree {TreeNode root;public BinaryTree() {root = null;}// 插入节点public void insert(int val) {root = insertNode(root, val);}private TreeNode insertNode(TreeNode node, int val) {if (node == null) {return new TreeNode(val);}// 如果值小于当前节点,则插入左子树if (val < node.val) {node.left = insertNode(node.left, val);}// 如果值大于等于当前节点,则插入右子树else {node.right = insertNode(node.right, val);}return node;}// 先序遍历public void preOrderTraversal() {preOrder(root);}private void preOrder(TreeNode node) {if (node == null) {return;}System.out.print(node.val + " ");preOrder(node.left);preOrder(node.right);}
}// 二叉搜索树类
class BinarySearchTree {TreeNode root;public BinarySearchTree() {root = null;}// 插入节点public void insert(int val) {root = insertNode(root, val);}private TreeNode insertNode(TreeNode node, int val) {if (node == null) {return new TreeNode(val);}// 如果值小于当前节点,则插入左子树if (val < node.val) {node.left = insertNode(node.left, val);}// 如果值大于等于当前节点,则插入右子树else {node.right = insertNode(node.right, val);}return node;}// 中序遍历public void inOrderTraversal() {inOrder(root);}private void inOrder(TreeNode node) {if (node == null) {return;}inOrder(node.left);System.out.print(node.val + " ");inOrder(node.right);}
}// 测试代码
public class myClass {public static void main(String[] args) {// 创建二叉树,并插入节点BinaryTree binaryTree = new BinaryTree();binaryTree.insert(5);binaryTree.insert(3);binaryTree.insert(7);binaryTree.insert(2);binaryTree.insert(4);binaryTree.insert(6);binaryTree.insert(8);// 先序遍历二叉树System.out.print("二叉树 -先序遍历: ");binaryTree.preOrderTraversal();System.out.println();// 创建二叉搜索树,并插入节点BinarySearchTree binarySearchTree = new BinarySearchTree();binarySearchTree.insert(5);binarySearchTree.insert(3);binarySearchTree.insert(7);binarySearchTree.insert(2);binarySearchTree.insert(4);binarySearchTree.insert(6);binarySearchTree.insert(8);// 中序遍历二叉搜索树System.out.print("二叉搜索树 - 中序遍历: ");binarySearchTree.inOrderTraversal();System.out.println();}
}
运行结果:
二叉树 -先序遍历: 5 3 2 4 7 6 8
二叉搜索树 - 中序遍历: 2 3 4 5 6 7 8
五.图(Graph):
图(Graph)是由节点(Vertex)和边(Edge)组成的一种非线性数据结构,用于表示对象之间的关联关系。可以将节点视为图中的元素,并且节点可以与其他节点通过边相连接。
在实际应用中,图可用于解决各种问题,如社交网络分析、路径搜索、最短路径算法等。在 Java 中,可以自行实现图的数据结构和相关算法,或使用第三方库(如JGraphT、Java Universal Network/Graph Framework等)来操作和处理图结构。
- 有向图(Directed Graph):也称为有向图、定向图或有向网络。有向图中的边具有方向性,表示节点之间的单向关系。如果节点 A 到节点 B 之间存在一条有向边,那么从节点 A 出发可以到达节点 B,但反过来不行。
- 无向图(Undirected Graph):也称为无向图、非定向图或无向网络。无向图中的边没有方向,表示节点之间的双向关系。如果节点 A 和节点 B 之间有一条边相连,则可以从节点 A 到节点 B 或者从节点 B 到节点 A。
六.堆(Heap):
堆是一种特殊的树形数据结构,满足堆属性。用于有效地找到最大值或最小值的数据结构。Java 提供了优先级队列(PriorityQueue)来实现堆。
- 最大堆(Max Heap):每个父节点的值都大于或等于其子节点的值。
- 最小堆(Min Heap):每个父节点的值都小于或等于其子节点的值。
七.链表(LinkedList):
链表是一种线性数据结构,也叫动态数据结构,但是并不会按线性的顺序存储数据,由节点和指针组成,每个节点包含数据和指向下一个节点的指针。
链表可分为单向链表和双向链表。
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。
![]()
一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。
![]()
八.MAP:
Map是一种用于存储键值对的接口。它提供了一种将键映射到值的方式,可以通过键快速查找对应的值。在Map中,键是唯一的,每个键最多只能映射到一个值。常见的Map实现类包括HashMap、TreeMap、LinkedHashMap等。这些实现类提供了不同的性能特点和迭代顺序,可以根据具体需求选择适合的实现类。使用Map可以方便地进行数据检索、插入、删除和更新操作,非常适合处理需要快速查找的场景。
相关文章:

Java进阶篇--数据结构
目录 一.数组(Array): 1.1 特点: 1.2 基本操作: 1.3 使用数组的好处包括: 1.4 数组也有一些限制: 二.集合框架(Collections Framework): 2.1 列表…...
使用Facebook Pixel 埋点
在投放广告的时候,一般需要知道广告的产生的效益,所以就需要通过埋点去记录,这里使用到的是Facebook Pixel。 首先安装 npm install --save react-facebook-pixel然后进行封装了一下 /*** * param {事件类型默认为标准事件} eventType * pa…...
)
《Go 语言第一课》课程学习笔记(七)
代码块与作用域:如何保证变量不会被遮蔽? 什么是变量遮蔽呢?package mainimport ("fmt""github.com/google/uuid""github.com/sirupsen/logrus" )func main() {fmt.Println("hello, world")logrus.…...

Docker Nginx 运行前端项目
运行Nginx容器: docker run -itd --name nginx -p 80:80 nginx:latest--name是容器名称变量,nginx是创建容器的名称 copy 打包后的前端项目到容器的/usr/share/nginx目录下,拷贝后的目录一定要是:/usr/share/nginx/html否则无法运…...
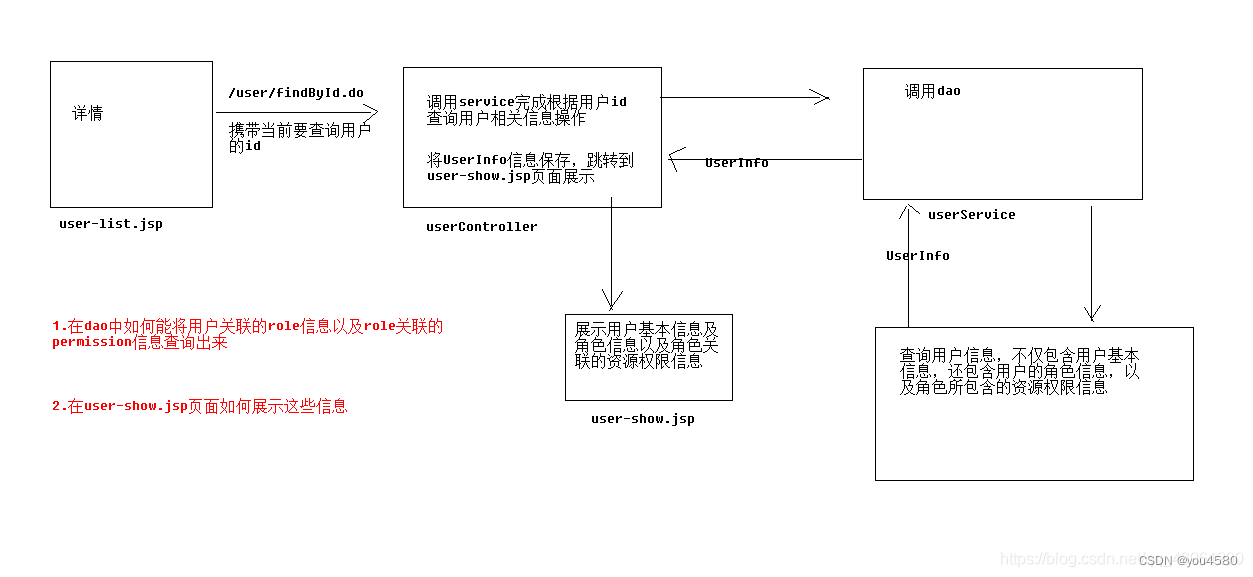
企业权限管理(十)-用户详情
用户详情 UserController findById方法 Controller RequestMapping("/user") public class UserController {Autowiredprivate IUserService userService;//查询指定id的用户RequestMapping("/findById.do")public ModelAndView findById(String id) thro…...
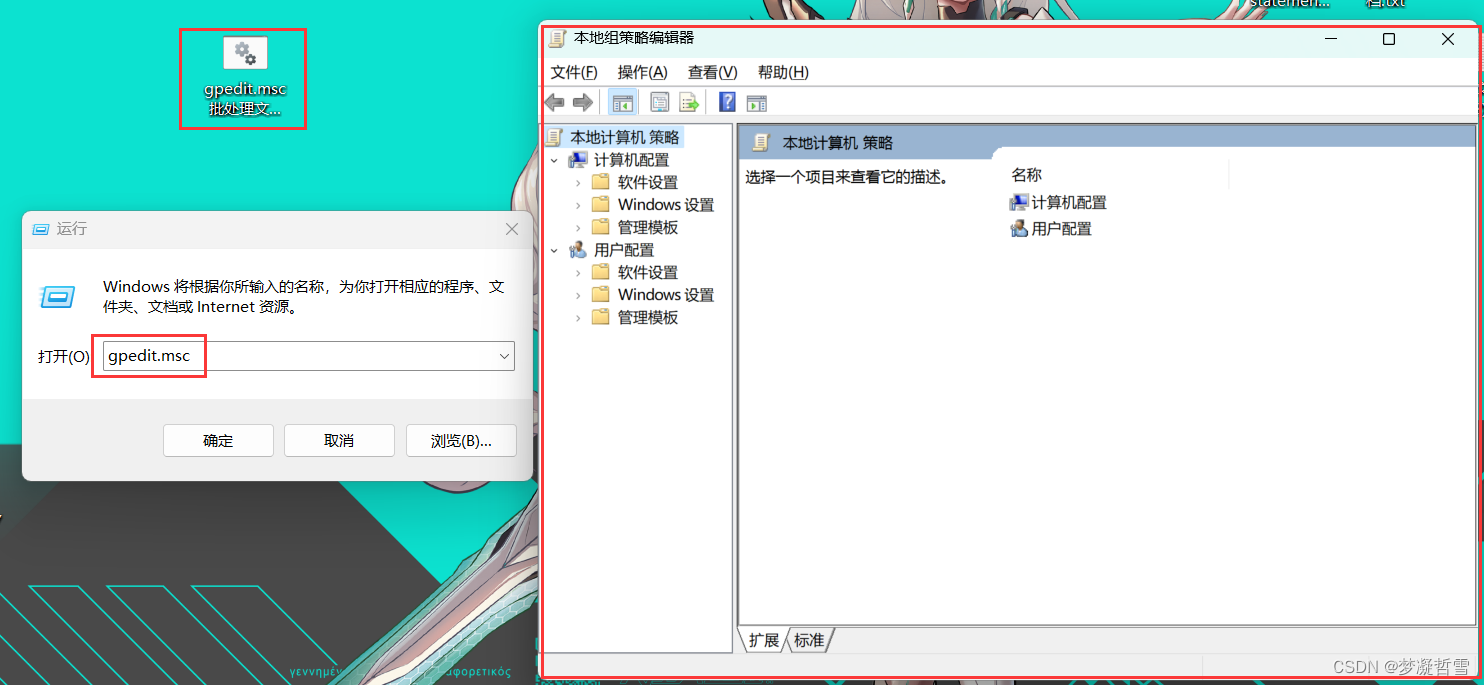
Windows 11 家庭中文版找不到组策略文件gpedit.msc
最近因为调整日期问题需要用到组策略文件gpedit.msc,但是发现找不到文件 在按键盘 winR 打开运行界面输入 gpedit.msc 回车 Windows找不到文件’gpedit.msc’。请确定文件名是否正确后,再试-次。 检查电脑Windows系统版本 是 Windows 11 家庭中文版 果断早网上搜…...

vue3项目中structuredClone报错
报错:Failed to execute structuredClone on Window: #<Object> could not be cloned 代码: const formData ref({"content": "", // string"id": "", // string"title": "", // …...
Android漏洞之战——整体加壳原理和脱壳技巧详解
一、前言 为了帮助更加方便的进行漏洞挖掘工作,前面我们通过了几篇文章详解的给大家介绍了动态调试技术、过反调试技术、Hook技术、过反Hook技术、抓包技术等,掌握了这些可以很方便的开展App漏洞挖掘工作,而最后我们还需要掌握一定的脱壳技巧…...

网络
mcq Java 传输层:拆分和组装,完成端到端的消息传递,流量控制,差错控制等 网络层: 寻址、路由,复用,拥塞控制,完成源到宿的传递。 显然A选项是错误的,有流量控制的是传输层…...

一直往下get的map
一直往下get的map 文档:一直往下get的map.note 链接:http://note.youdao.com/noteshare?id7b6d315d86ce9e5f8d7cac9be8e924b8&sub95F9FFDA8EB447BBA506286E261F4C88 添加链接描述 package com.example.demo.entity;import org.bson.Document; impo…...
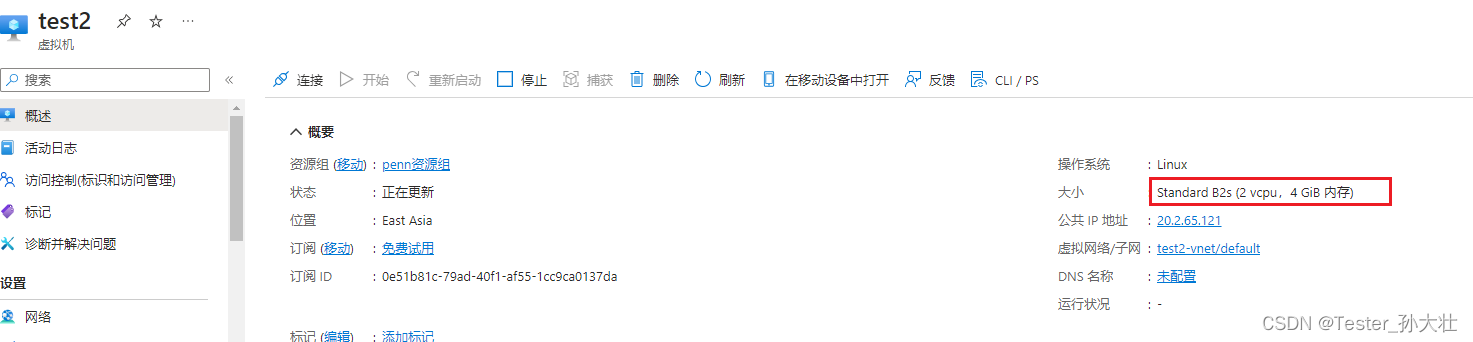
Azure如何调整虚拟机的大小
参考 https://blog.csdn.net/m0_48468018/article/details/132267096 创建虚拟机进入资源,点击大小选项,并对大小进行调整 点击如下图的cloud shell,进入Azure CLI,使用az vm resize 进行大小调整 命令中的g对应资源组,n对应虚拟机名称&am…...
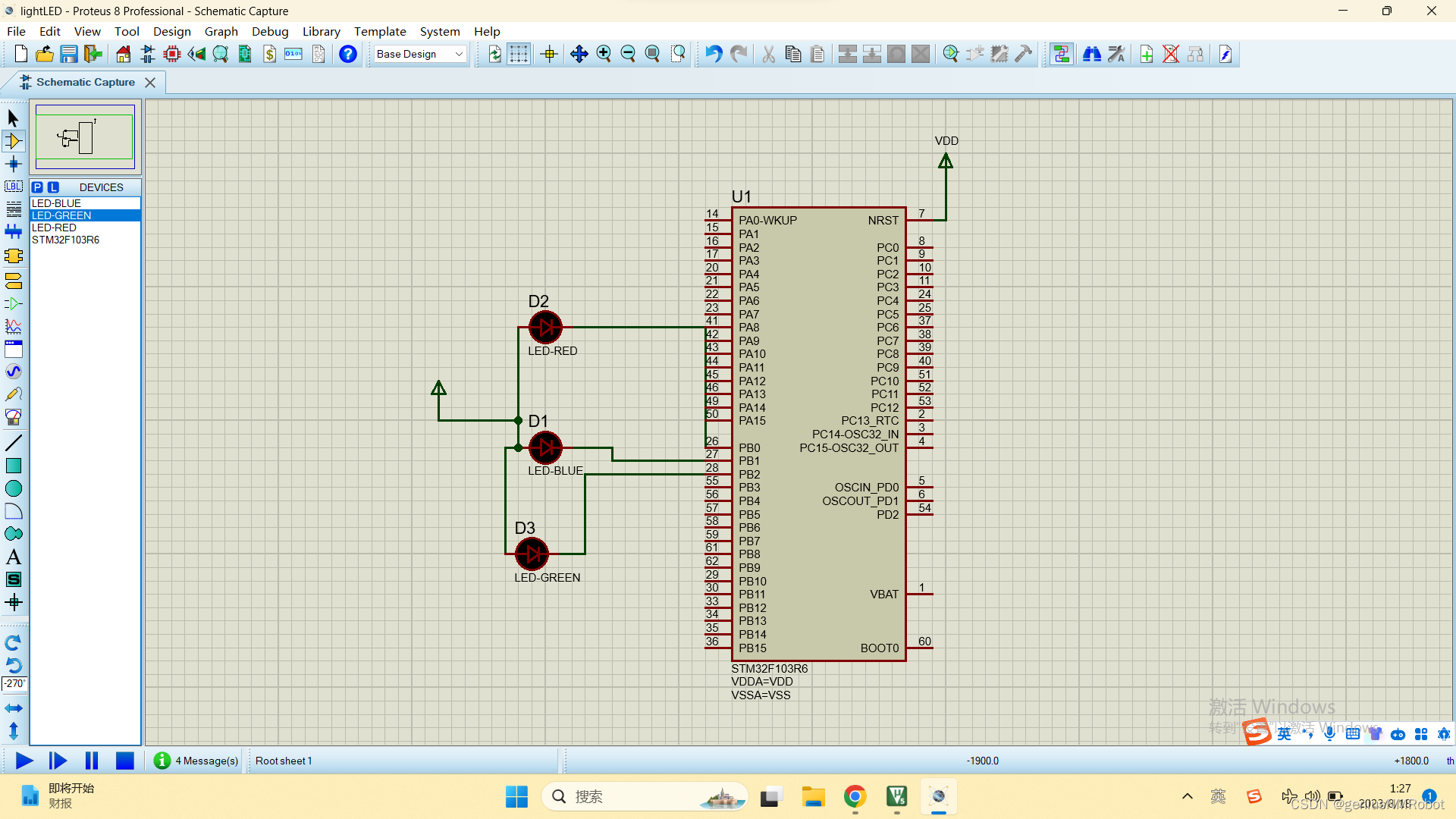
stm32F103R6实现流水灯参考源代码
#include "main.h" #include "gpio.h" void SystemClock_Config(void); void sleep(int a) {int i0,j0;for(i0;i<a;i){for(j0;j<2000;j);}} 真正发挥效果的是这个main函数// int main(void) {int i0;HAL_Init();SystemClock_Config();MX_GPIO_Init()…...
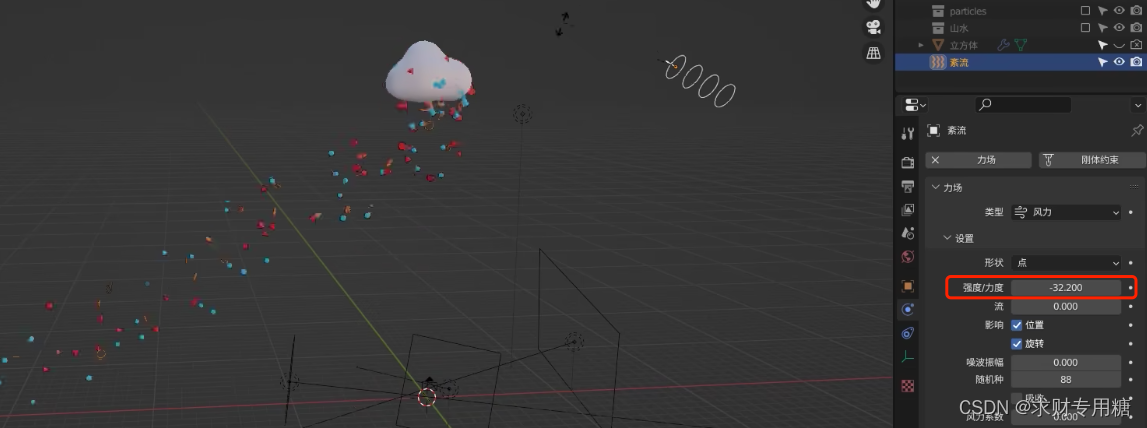
blender 发射体粒子
发射体粒子的基础设置 选择需要添加粒子的物体,点击右侧粒子属性,在属性面板中,点击加号,物体表面会出现很多小点点,点击空格键,粒子会自动运动,像下雨一样; bender 粒子系统分为两…...

你真的掌握了 Python 的七种参数了吗?
不知道为什么网上总有人说 Python 的参数类型有 4 种啊,5 种啊,殊不知其实有 7 种。Python 的 7 种参数分别是 默认参数、位置参数、关键字参数、可变长位置参数、可变长关键字参数、仅位置参数 和 仅关键字参数。小白可能没见过“可变长参数”ÿ…...
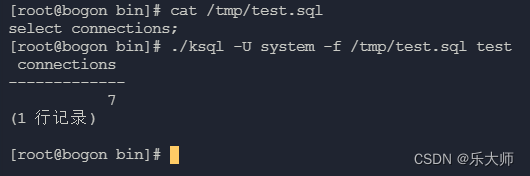
人大进仓数据库ksql命令基础
测试环境信息: 系统为银河麒麟V10 数据库为Kingbase ES V8 数据库安装目录为/opt/Kingbase/ES/V8 ksql命令位于/opt/Kingbase/ES/V8/Server/bin下 使用--help获取帮助 续上图 1.查看数据库列表 ./ksql -U system -l 2.查看数据库版本 ./ksql -V 3.连接指定的数据库tes…...

网站上的网页,无法通过百度和bing搜索引擎来搜索
最近搜索某公司网站上的技术资料,百度/bing都不能工作,纳闷 看了下该网站的robots.txt 明白了 User-Agent: * Disallow: / 参考: 网站 robots.txt 文件配置方法,如何禁止搜索引擎收录指定网页内容 - 知乎...

Redis与MySQL的比较:什么情况下使用Redis更合适?什么情况下使用MySQL更合适?
Redis和MySQL是两种不同类型的数据库,各有自己的特点和适用场景。下面是Redis和MySQL的比较以及它们适合使用的情况: Redis适合的场景: 高性能读写:Redis是基于内存的快速Key-Value存储,读写性能非常高。它适用于需要…...

34_windows环境debug Nginx 源码-配置WSL和CLion
文章目录 WSL 中安装 编译构建使用的相关软件重装默认的 ssh创建 libstdc++.so 软链接34_windows环境debug Nginx 源码-配置WSL和CLionWSL 中安装 编译构建使用的相关软件 sudo apt-get update sudo apt-get install libstdc++6 dpkg -L libstdc++6sudo apt-get install libpc…...
)
单词倒排(C语言详解)
题目:单词倒排 描述:对字符串中的所有单词进行倒排。 说明: 1、构成单词的字符只有26个大写或小写英文字母; 2、非构成单词的字符均视为单词间隔符; 3、要求倒排后的单词间隔符以一个空格表示;如果原字…...

一、数学建模之线性规划篇
1.定义 2.例题 3.使用软件及解题 一、定义 1.线性规划(Linear Programming,简称LP)是一种数学优化技术,线性规划作为运筹学的一个重要分支,专门研究在给定一组线性约束条件下,如何找到一个最优的决策&…...

OpenCode效果实测:基于Qwen3-4B的代码生成质量与速度展示
OpenCode效果实测:基于Qwen3-4B的代码生成质量与速度展示 1. 项目概览与技术背景 OpenCode是2024年开源的AI编程助手框架,采用Go语言开发,主打"终端优先、多模型、隐私安全"的设计理念。该项目将大语言模型(LLM)包装成可插拔的Ag…...

Java实现海康萤石摄像头实时监控与视频流获取全攻略
1. 海康萤石摄像头接入前的准备工作 第一次接触海康萤石摄像头开发时,我花了整整两天时间才搞明白整个接入流程。这里把踩过的坑都总结出来,让你少走弯路。首先需要明确的是,萤石开放平台提供了完整的API文档和SDK支持,但实际开发…...

收藏!阿里后端转大模型应用层,2年Agent/RAG经验,斩获字节30%涨幅offer|小白程序员必看学习路径
作为一名从传统后端开发起步的程序员,我毕业后顺利入职阿里,做了一年后端开发工作后,敏锐捕捉到大模型应用层的爆发趋势,果断转型深耕。经过两年的Agent、RAG相关开发实践,最终成功拿到字节跳动Agent开发岗位offer&…...

从大疆NAZA换到匿名P2飞控:一个DIY玩家的真实体验与参数调试避坑指南
从大疆NAZA到匿名P2飞控:一位DIY玩家的深度迁移指南 当我的F450机架在狭小卧室里显得笨拙不堪时,我意识到需要一次彻底的"瘦身计划"。这不是简单的机架更换,而是一次从商业飞控到开源系统的完整迁移——将大疆NAZA积累的经验移植到…...

如何通过开源数据集创造商业价值:Awesome Public Datasets全攻略
如何通过开源数据集创造商业价值:Awesome Public Datasets全攻略 【免费下载链接】awesome-public-datasets A topic-centric list of HQ open datasets. 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-public-datasets 在数据驱动决策的时代&a…...

工程仿真平台OpenRocket:从物理试验到数字孪生的技术跃迁
工程仿真平台OpenRocket:从物理试验到数字孪生的技术跃迁 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 在现代工程设计领域,物理…...

从工作流到超级智能体,Claude Code 重构AI应用底层逻辑
从工作流到超级智能体,Claude Code 重构AI应用底层逻辑 当AI应用从简单的对话交互,逐步演进到复杂的自动化工作流,再到如今的自主智能体时代,行业始终在探寻更高效、更智能的系统架构范式。Anthropic推出的Claude Code,…...

AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案
AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn yo…...

OpCore-Simplify:突破性黑苹果EFI配置革命,15分钟完成专业级系统搭建 [特殊字符]
OpCore-Simplify:突破性黑苹果EFI配置革命,15分钟完成专业级系统搭建 🚀 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify…...

避坑指南:微信支付V3 SDK自动更新证书失败的5种常见原因及修复方法
微信支付V3证书自动更新失败排查手册:从原理到实战修复 微信支付的V3版本SDK以其自动证书更新机制著称,但不少开发者在集成过程中都遭遇过AutoUpdateCertificatesVerifier的失败问题。证书更新失败不仅会导致支付功能中断,还可能引发验签错误…...