【机器学习 深度学习】通俗讲解集成学习算法
目录:集成学习
- 一、机器学习中的集成学习
- 1.1 定义
- 1.2 分类器(Classifier)
- 1.2.1 决策树分类器
- 1.2.2 朴素贝叶斯分类器
- 1.2.3 AdaBoost算法
- 1.2.4 支持向量机
- 1.2.5 K近邻算法
- 1.3 集成学习方法
- 1.3.1 自助聚合(Bagging)
- 1.3.2 提升法(Boosting)
- 1.3.2.1 自适应adaboost
- 1.3.3 堆叠法(Stacking)
- 1.4 十折交叉验证
- 二、深度学习中的集成学习
- 2.1 丢弃法Dropout
- 2.2 测试集数据扩增TTA
- 2.3 Snapshot
一、机器学习中的集成学习
1.1 定义
集成学习,即分类器集成,通过构建并结合多个学习器来完成学习任务。
一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。
结合策略主要有平均法、投票法和学习法等。
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)。
集成学习是这样一个过程,按照某种算法生成多个模型,如分类器或者称为专家,再将这些模型按照某种方法组合在一起来解决某个智能计算问题。
集成学习主要用来提高模型(分类,预测,函数估计等)的性能,或者用来降低模型选择不当的可能性。
集成算法本身是一种监督学习算法,因为它可以被训练然后进行预测,组合的多个模型作为整体代表一个假设(hypothesis)。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting) 或改进预测(stacking) 的效果。
1.2 分类器(Classifier)
分类器是数据挖掘中对样本进行分类的方法的统称,包含决策树、逻辑回归、朴素贝叶斯、神经网络等算法。分类是数据挖掘的一种非常重要的方法。分类的概念是在已有数据的基础上学会一个分类函数或构造出一个分类模型(即分类器)。该函数或模型能够把数据库中的数据纪录映射到给定类别中的某一个,从而可以应用于数据预测。
分类器的构造和实施大体会经过以下几个步骤:
- 选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分
- 在训练样本上执行分类器算法,生成分类模型
- 在测试样本上执行分类模型,生成预测结果
- 根据预测结果,计算必要的评估指标,评估分类模型的性能
1.2.1 决策树分类器
构造这个分类器不需要任何领域的知识,也不需要任何的参数设置。因此它特别适合于探测式的知识发现。此外,这个分类器还可以处理高维数据,而且采用的是类似于树这种形式,也特别直观和便于理解。因此,决策树是许多商业规则归纳系统的基础。
1.2.2 朴素贝叶斯分类器
朴素贝叶斯分类器是假设数据样本特征完全独立,以贝叶斯定理为基础的简单概率分类器。
1.2.3 AdaBoost算法
AdaBoost算法的自适应在于前一个分类器产生的错误分类样本会被用来训练下一个分类器,从而提升分类准确率,但是对于噪声样本和异常样本比较敏感。
1.2.4 支持向量机
支持向量机是用过构建一个或者多个高维的超平面来将样本数据进行划分,超平面即为样本之间的分类边界。
1.2.5 K近邻算法
基于k近邻的K个样本作为分析从而简化计算提升效率,K近邻算法分类器是基于距离计算的分类器。
1.3 集成学习方法
集成学习有许多集成模型,例如自助法、自助聚合(Bagging)、随机森林、提升法(Boosting)、 堆叠法(stacking) 以及许多其它的基础集成学习模型。
集成方法的思想是通过将这些个体学习器(个体学习器称为“基学习器”,基学习器也被称为弱学习器。)的偏置和/或方差结合起来,从而创建一个 强学习器(或 集成模型),从而获得更好的性能。
我们可以用三种主要的旨在组合弱学习器的元算法:
- 自助聚合(Bagging),该方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来
- 提升法(Boosting),该方法通常考虑的也是同质弱学习器。它以一种高度自适应的方法顺序地学习这些弱学习器(每个基础模型都依赖于前面的模型),并按照某种确定性的策略将它们组合起来
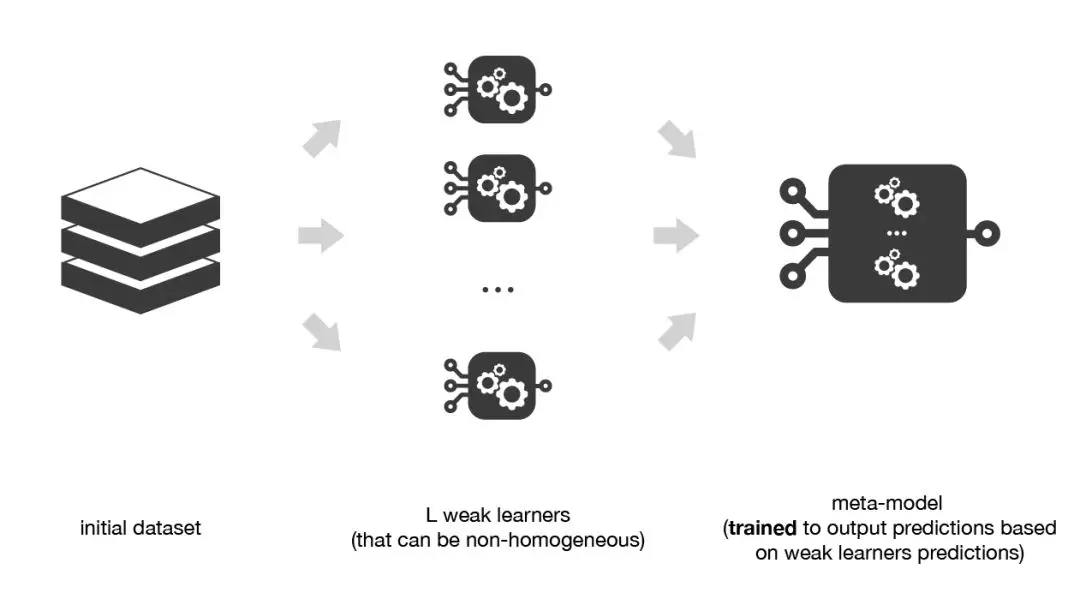
- 堆叠法(Stacking),该方法通常考虑的是异质弱学习器,并行地学习它们,并通过训练一个 元模型 将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果
非常粗略地说,我们可以说Bagging的重点在于获得一个方差比其组成部分更小的集成模型,而Boosting和Stacking则将主要生成偏置比其组成部分更低的强模型(即使方差也可以被减小)。
1.3.1 自助聚合(Bagging)
在并行化的方法 中,我们单独拟合不同的学习器,因此可以同时训练它们。最著名的方法是自助聚合(Bagging),它的目标是生成比单个模型更棒的集成模型。Bagging的方法实现。
自助法:这种统计技术先随机抽取出作为替代的BBB个观测值,然后根据一个规模为NNN的初始数据集生成大小为BBB的样本(称为自助样本)。
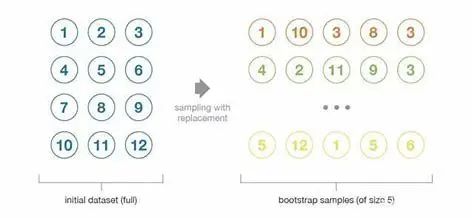
在某些假设条件下,这些样本具有非常好的统计特性:在一级近似中,它们可以被视为是直接从真实的底层(并且往往是未知的)数据分布中抽取出来的,并且彼此之间相互独立。因此,它们被认为是真实数据分布的代表性和独立样本(几乎是独立同分布的样本)。
为了使这种近似成立,必须验证两个方面的假设:
- 初始数据集的大小N应该足够大,以捕获底层分布的大部分复杂性。这样,从数据集中抽样就是从真实分布中抽样的良好近似(代表性)
- 与自助样本的大小B相比,数据集的规模N应该足够大,这样样本之间就不会有太大的相关性(独立性)。注意,接下来我可能还会提到自助样本的这些特性(代表性和独立性),但读者应该始终牢记:这只是一种近似
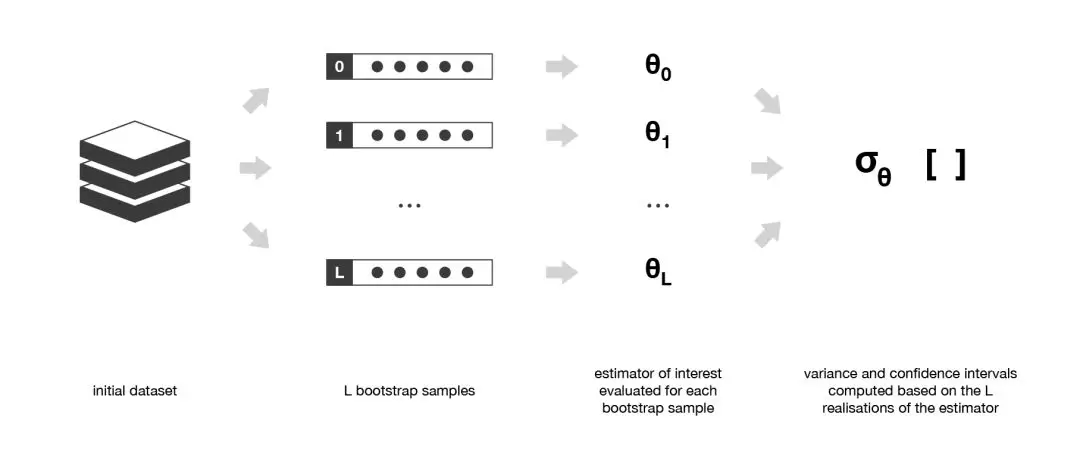
举例而言,自助样本通常用于评估统计估计量的方差或置信区间。根据定义,统计估计量是某些观测值的函数。因此,随机变量的方差是根据这些观测值计算得到的。为了评估这种估计量的方差,我们需要对从感兴趣分布中抽取出来的几个独立样本进行估计。
在大多数情况下,相较于实际可用的数据量来说,考虑真正独立的样本所需要的数据量可能太大了。然而,我们可以使用自助法生成一些自助样本,它们可被视为最具代表性以及最具独立性(几乎是独立同分布的样本)的样本。这些自助样本使我们可以通过估计每个样本的值,近似得到估计量的方差。
1.3.2 提升法(Boosting)
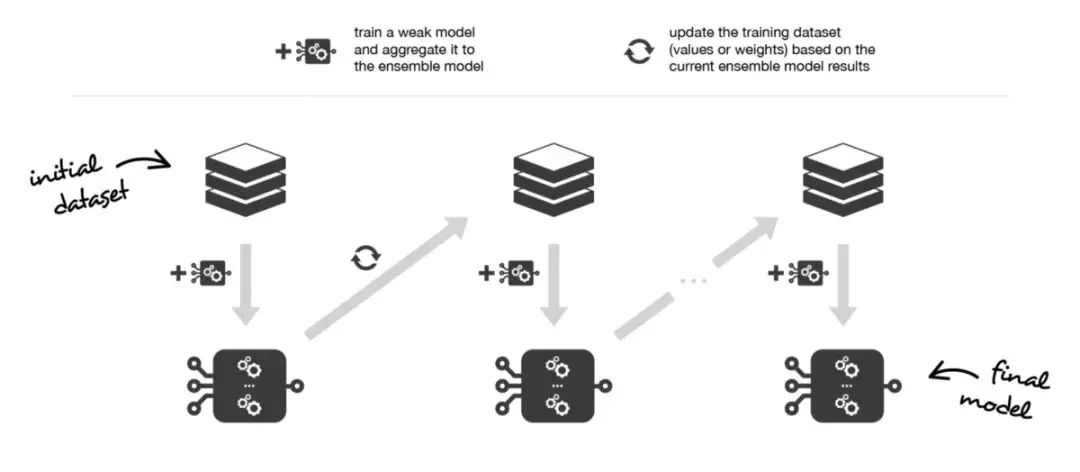
在顺序化的方法中,组合起来的不同弱模型之间不再相互独立地拟合。其思想是迭代地拟合模型,使模型在给定步骤上的训练依赖于之前的步骤上拟合的模型。提升法(Boosting) 是这些方法中最著名的一种,它生成的集成模型通常比组成该模型的弱学习器偏置更小。
Boosting和Bagging的工作思路是一样的:我们构建一系列模型,将它们聚合起来得到一个性能更好的强学习器。然而,与重点在于减小方差的Bagging不同,Boosting着眼于以一种适应性很强的方式顺序拟合多个弱学习器:序列中每个模型在拟合的过程中,会更加重视那些序列中之前的模型处理地很糟糕的观测数据。
直观地说,每个模型都把注意力集中在目前最难拟合的观测数据上。这样一来,在这个过程的最后,我们就获得了一个具有较低偏置的强学习器(我们会注意到,Boosting也有减小方差的效果)。和Bagging 一样,Boosting也可以用于回归和分类问题。由于其重点在于减小偏置,用于Boosting 的基础模型通常是那些低方差高偏置的模型。例如,如果想要使用树作为基础模型,我们将主要选择只有少许几层的较浅决策树。而选择低方差高偏置模型作为Boosting 弱学习器的另一个重要原因是:这些模型拟合的计算开销较低(参数化时自由度较低)。实际上,由于拟合不同模型的计算无法并行处理(与Bagging 不同),顺序地拟合若干复杂模型会导致计算开销变得非常高。
一旦选定了弱学习器,我们仍需要定义它们的拟合方式和聚合方式。介绍两个重要的Boosting算法:自适应提升(adaboost)和梯度提升(gradient boosting)。
简而言之,这两种元算法在顺序化的过程中创建和聚合弱学习器的方式存在差异。自适应提升算法会更新附加给每个训练数据集中观测数据的权重,而梯度提升算法则会更新这些观测数据的值。这里产生差异的主要原因是:两种算法解决优化问题(寻找最佳模型——弱学习器的加权和)的方式不同。
1.3.2.1 自适应adaboost
在自适应adaboost中,我们将集成模型定义为L个弱学习器的加权和:
sL(.)=∑l=1Lcl×wl(.)s_L(.)=\sum_{l=1}^Lc_l \times w_l(.) sL(.)=l=1∑Lcl×wl(.)
其中clc_lcl为系数,wlw_lwl为弱学习器。寻找这种最佳集成模型是一个困难的优化问题。因此,我们并没打算一次性地解决该问题(找到给出最佳整体加法模型的所有系数和弱学习器),而是使用了一种更易于处理的迭代优化过程(即使它有可能导致我们得到次优解)。
另外,我们将弱学习器逐个添加到当前的集成模型中,在每次迭代中寻找可能的最佳组合(系数、弱学习器)。换句话说,我们循环地将sls_lsl定义如下:
sl(.)=sl−1(.)+cl×wl(.)s_l(.)=s_{l-1}(.)+c_l \times w_l(.) sl(.)=sl−1(.)+cl×wl(.)
其中,clc_lcl和wlw_lwl被挑选出来,使得sls_lsl是最适合训练数据的模型,因此这是对sl−1s_{l-1}sl−1的最佳可能改进。我们可以进一步将其表示为:
(cl,wl(.))=argc,w(.)minE(sl−1(.)+c×w(.))=argc,w(.)min∑n=1Ne(yn,sl−1(xn)+c×w(xn))(c_l,w_l(.))=\arg_{c,w(.)}\min E(s_{l-1}(.)+c\times w(.))\\ =\arg_{c,w(.)}\min \sum_{n=1}^Ne(y_n,s_{l-1}(x_n)+c\times w(x_n)) (cl,wl(.))=argc,w(.)minE(sl−1(.)+c×w(.))=argc,w(.)minn=1∑Ne(yn,sl−1(xn)+c×w(xn))
其中,E(.)E(.)E(.)是给定模型的拟合误差,e(.,.)e(.,.)e(.,.)是损失/误差函数。因此,我们并没有在求和过程中对所有LLL个模型进行全局优化,而是通过局部优化来近似最优解并将弱学习器逐个添加到强模型中。
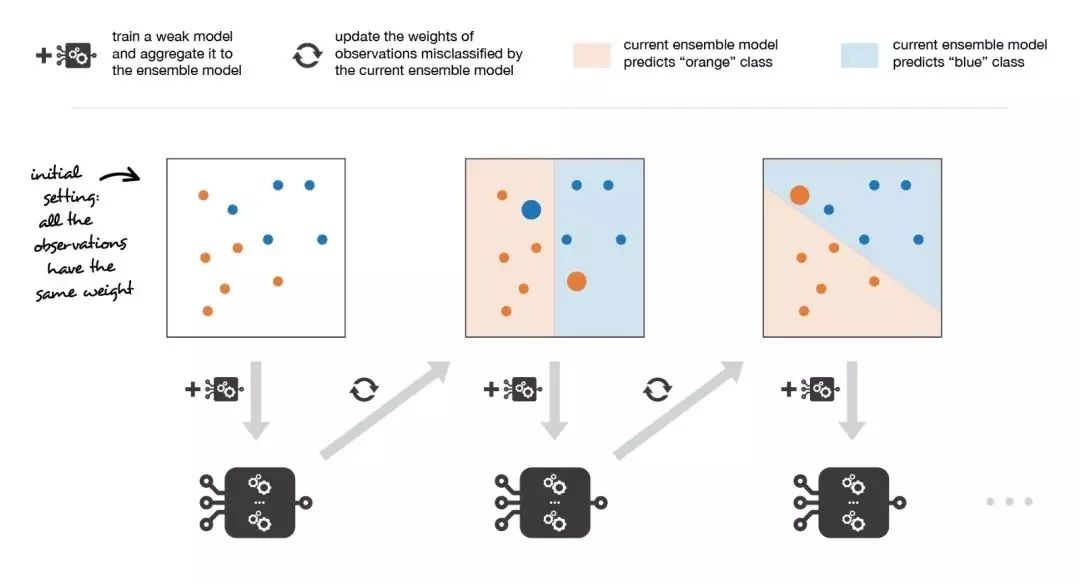
更特别的是,在考虑二分类问题时,我们可以将 adaboost 算法重新写入以下过程:首先,它将更新数据集中观测数据的权重,训练一个新的弱学习器,该学习器重点关注当前集成模型误分类的观测数据。其次,它会根据一个表示该弱模型性能的更新系数,将弱学习器添加到加权和中:弱学习器的性能越好,它对强学习器的贡献就越大。
因此,假设我们面对的是一个二分类问题:数据集中有N个观测数据,我们想在给定一组弱模型的情况下使用adaboost算法。在算法的起始阶段(序列中的第一个模型),所有的观测数据都拥有相同的权重1/N。然后,我们将下面的步骤重复L次(作用于序列中的L个学习器):
- 用当前观测数据的权重拟合可能的最佳弱模型
- 计算更新系数的值,更新系数是弱学习器的某种标量化评估指标,它表示相对集成模型来说,该弱学习器的分量如何
- 通过添加新的弱学习器与其更新系数的乘积来更新强学习器计算新观测数据的权重,该权重表示我们想在下一轮迭代中关注哪些观测数据(聚和模型预测错误的观测数据的权重增加,而正确预测的观测数据的权重减小)
重复这些步骤,我们顺序地构建出L个模型,并将它们聚合成一个简单的线性组合,然后由表示每个学习器性能的系数加权。注意,初始adaboost算法有一些变体,比如LogitBoost(分类)或L2Boost(回归),它们的差异主要取决于损失函数的选择。
1.3.3 堆叠法(Stacking)
堆叠法Stacking与Bagging和Boosting主要存在两方面的差异。首先,堆叠法通常考虑的是异质弱学习器(不同的学习算法被组合在一起),而Bagging和Boosting主要考虑的是同质弱学习器。其次,stacking堆叠法学习用元模型组合基础模型,而Bagging和Boosting则根据确定性算法组合弱学习器。
正如上文已经提到的,堆叠法的概念是学习几个不同的弱学习器,并通过训练一个元模型来组合它们,然后基于这些弱模型返回的多个预测结果输出最终的预测结果。
因此,为了构建Stacking模型,我们需要定义两个东西:想要拟合的L个学习器以及组合它们的元模型。例如,对于分类问题来说,我们可以选择KNN分类器、logistic回归和SVM作为弱学习器,并决定学习神经网络作为元模型。然后,神经网络将会把三个弱学习器的输出作为输入,并返回基于该输入的最终预测。所以,假设我们想要拟合由L个弱学习器组成的Stacking集成模型。我们必须遵循以下步骤:
- 将训练数据分为两组
- 选择 L 个弱学习器,用它们拟合第一组数据
- 使 L 个学习器中的每个学习器对第二组数据中的观测数据进行预测
- 在第二组数据上拟合元模型,使用弱学习器做出的预测作为输入
在前面的步骤中,我们将数据集一分为二,因为对用于训练弱学习器的数据的预测与元模型的训练不相关。因此,将数据集分成两部分的一个明显缺点是,我们只有一半的数据用于训练基础模型,另一半数据用于训练元模型。
为了克服这种限制,我们可以使用某种k-折交叉训练方法(类似于 k-折交叉验证中的做法)。这样所有的观测数据都可以用来训练元模型:对于任意的观测数据,弱学习器的预测都是通过在k-1折数据(不包含已考虑的观测数据)上训练这些弱学习器的实例来完成的。换句话说,它会在k-1折数据上进行训练,从而对剩下的一折数据进行预测。迭代地重复这个过程,就可以得到对任何一折观测数据的预测结果。这样一来,我们就可以为数据集中的每个观测数据生成相关的预测,然后使用所有这些预测结果训练元模型。
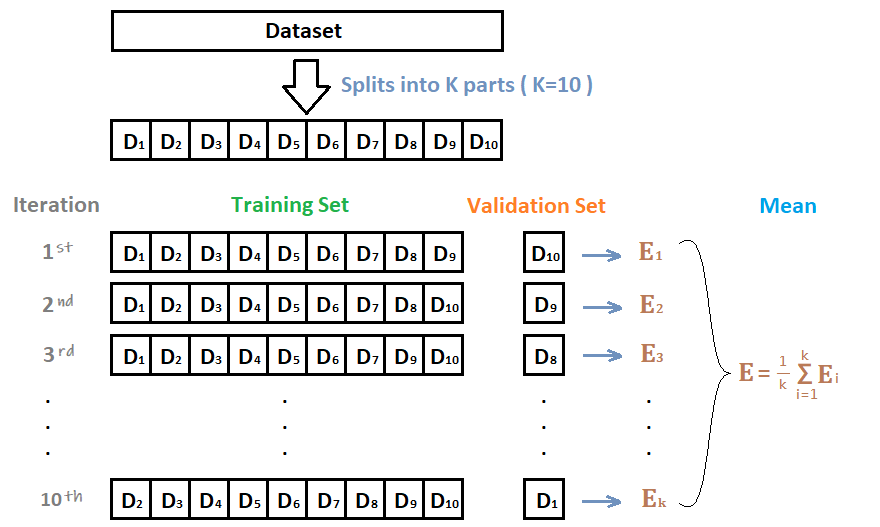
1.4 十折交叉验证
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交叉验证的方法。
十折交叉验证用来测试算法准确性。将数据集分成十份,轮流将其中九份作为训练数据,一份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。十次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次十折交叉验证(例如十次十折交叉验证),再求其均值,作为对算法准确性的估计。
下面假设构建了十折交叉验证,训练得到十个CNN模型。
那么在十个CNN模型可以使用如下方式进行集成:
- 对预测的结果的概率值进行平均,然后解码为具体字符
- 对预测的字符进行投票,得到最终字符
二、深度学习中的集成学习
此外在深度学习中本身还有一些集成学习思路的做法,值得借鉴学习:
- 丢弃法Dropout
- 测试集数据扩增TTA
- Snapshot
2.1 丢弃法Dropout
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。
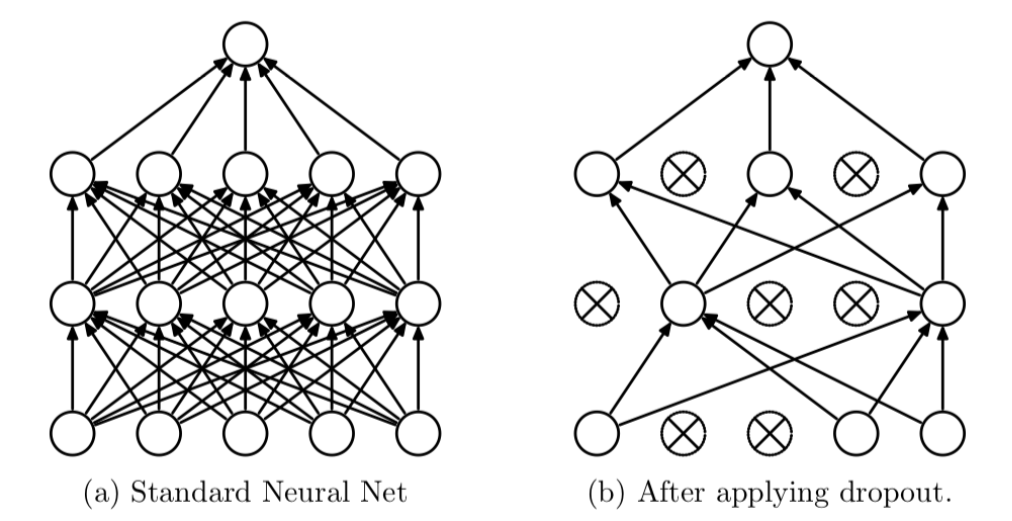
Dropout经常出现在在先有的CNN网络中,可以有效的缓解模型过拟合的情况,也可以在预测时增加模型的精度。加入Dropout后的网络结构如下:
# 定义模型
class SVHN_Model1(nn.Module):def __init__(self):super(SVHN_Model1, self).__init__()# CNN提取特征模块self.cnn = nn.Sequential(nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),)#self.fc1 = nn.Linear(32*3*7, 11)self.fc2 = nn.Linear(32*3*7, 11)self.fc3 = nn.Linear(32*3*7, 11)self.fc4 = nn.Linear(32*3*7, 11)self.fc5 = nn.Linear(32*3*7, 11)self.fc6 = nn.Linear(32*3*7, 11)def forward(self, img):feat = self.cnn(img)feat = feat.view(feat.shape[0], -1)c1 = self.fc1(feat)c2 = self.fc2(feat)c3 = self.fc3(feat)c4 = self.fc4(feat)c5 = self.fc5(feat)c6 = self.fc6(feat)return c1, c2, c3, c4, c5, c6
2.2 测试集数据扩增TTA
测试集数据扩增(Test Time Augmentation,简称TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。

def predict(test_loader, model, tta=10):model.eval()test_pred_tta = None# TTA 次数for _ in range(tta):test_pred = []with torch.no_grad():for i, (input, target) in enumerate(test_loader):c0, c1, c2, c3, c4, c5 = model(data[0])output = np.concatenate([c0.data.numpy(), c1.data.numpy(),c2.data.numpy(), c3.data.numpy(),c4.data.numpy(), c5.data.numpy()], axis=1)test_pred.append(output)test_pred = np.vstack(test_pred)if test_pred_tta is None:test_pred_tta = test_predelse:test_pred_tta += test_predreturn test_pred_tta
2.3 Snapshot
本章的开头已经提到,假设我们训练了10个CNN则可以将多个模型的预测结果进行平均。但是加入只训练了一个CNN模型,如何做模型集成呢?
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。
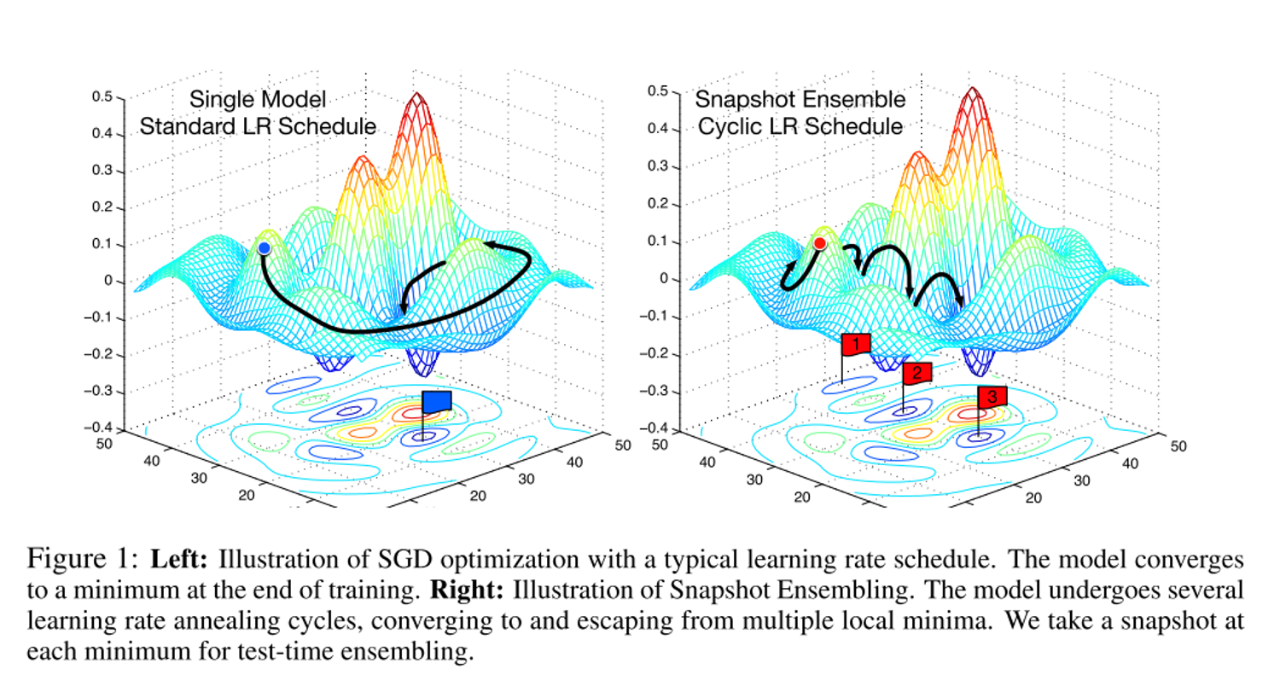
由于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。
相关文章:
【机器学习 深度学习】通俗讲解集成学习算法
目录:集成学习一、机器学习中的集成学习1.1 定义1.2 分类器(Classifier)1.2.1 决策树分类器1.2.2 朴素贝叶斯分类器1.2.3 AdaBoost算法1.2.4 支持向量机1.2.5 K近邻算法1.3 集成学习方法1.3.1 自助聚合(Bagging)1.3.2 提升法(Boosting)1.3.2.1 自适应adaboost1.3.3 …...

汉字----dgfont
Abstract 字符生成是一个具有挑战性的问题,特别是对于一些由大量字符组成的书写系统,近年来受到了广泛的关注。然而,现有的字体生成方法通常是在监督学习中。它们需要大量的配对数据,这是劳动密集型和昂贵的收集。此外,常见的图像到图像转换模型通常将风格定义为纹理和颜…...

C# chart绘图 鼠标响应
1、图形自动滚动设置 chart1.ChartAreas[0].AxisX.Maximum 横坐标显示区域最大值 chart1.ChartAreas[0].AxisX.Minimum 横坐标显示区域最小值 显示宽度 chart1.ChartAreas[0].AxisX.Maximum - chart1.ChartAreas[0].AxisX.Minimum chart1.ChartAreas[0].AxisX.Maximum x_d…...
结构体与引用
1.结构体基本概念结构体属于用户自定义的数据类型,允许用户存储不同的数据类型2.结构体定义和使用语法: struct 结构体 { 结构体成员列表 };通过结构体创建变量的方式有三种:struct 结构体名 变量名struct 结构体名 变量名 { 成员1值,成员2值...}定义结构…...

13.罗马数字转整数
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值I 1V 5X 10L 50C 100D 500M 1000例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X II 。 27 写做 XX…...

JVM垃圾回收机制
垃圾回收机制(GC) 内存管理 Java的内存管理很大程度指的就是对象的管理,其中包括对象空间的分配和释放。 对象空间的分配:使用new关键字创建对象即可 对象空间的释放:将对象赋值null即可。垃圾回收器将负责所有“不…...
Java File类、IO流、Properties属性类
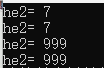
文章目录一、补充二、File类File类的含义创建多级文件File类的常见方法三、IO流IO流分类输入输出流FileOutputStreamInputStreamInputStream与OutputStream的实例ReaderWriterFileReader和FileWriter的实例缓冲流转换流序列化与ObjectInputStream、ObjectOutputStream打印流Pro…...

MySQL备份恢复(十二)
文章目录1. MySQL数据损坏类型1.1 物理损坏1.2 逻辑损坏2. DBA运维人员备份/恢复职责2.1 设计备份/容灾策略2.1.1 备份策略2.1.2 容灾策略2.2 定期的备份/容灾检查2.3 定期的故障恢复演练2.4 数据损坏时的快速准确恢复2.5 数据迁移工作3. MySQL常用备份工具3.1 逻辑备份方式3.2…...

【Java|golang】1792. 最大平均通过率---封装最小堆
一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali 个学生,其中只有 passi 个学…...

PHP 页面静态化
前言随着网站的内容的增多和用户访问量的增多,网站加载会越来越慢,受限于带宽和服务器同一时间的请求次数的限制,,我们往往需要在此时对我们的网站进行代码优化和服务器配置的优化。一、页面静态化概念静态化定义静态化就是指把原…...

【Python】进制、计算机中的单位、编码、数据类型、索引、字符串切片、字符串的功能方法
一、进制计算机中底层所有的数据都是以 010101 的形式存在(图片、文本、视频等)。二进制八进制十进制(也就是我们熟知的阿拉伯数字)十六进制进制转换v1 bin(25) # 十进制转换为二进制 print(v1) # "0b11001"v2 oct(23…...

基于android的无人健身房
需求信息: 1:客户登录:首次登陆必须注册,用户注册完成后可以进入软件查看自己的金额、会员等级、消费和健身时长。 2:计费功能:用户通过软件扫描二维码后即可进入健身房,软件显示欢迎进入健身房…...

带你Java基础入门
首先我们都知道的,Java是一种高级计算机语言,是可以编写跨平台应用软件、完全面向对象的程序设计语言。相对于零基础小白如何更加快速的入门java?小编给大家整理了java300集自学教程视频,非常适合零基础的小伙伴,一周时间实现快速…...
VNCTF 2023 - Web 象棋王子|电子木鱼|BabyGo Writeups
象棋王子 签到题,jsfuck解密 丢到console得到flag 电子木鱼 后面两道都是代码审计,这题是rust,题目给出了源码,下载下来看 关键代码: 由于限制,quantity只能为正数 功德也只能是正数(负数的…...
)
「JVM 编译优化」插入式注解处理器(自定义代码编译检查)
JDK 的编译子系统暴露给用户直接控制的功能相对很少,除了虚拟机即时编译的若干参数,便只有 JSR-296 中定义的插入式注解处理器 API; 文章目录1. 目标2. 实现3. 运行与测试4. 其他应用案例1. 目标 前端编译器在讲 Java 源码编译成字节码时对源…...

一文彻底理解大小端和位域 BIGENDIAN LITTLEENDIAN
一文彻底理解大小端和位域 为什么有大小端 人们一直认为大道至简,就好像物理学上的世界追求使用一个理论来统一所有的现象。为什么cpu存在大小端之分,一言以蔽之,这两种模式各有各的优点,其各自的优点就是对方的缺点,…...
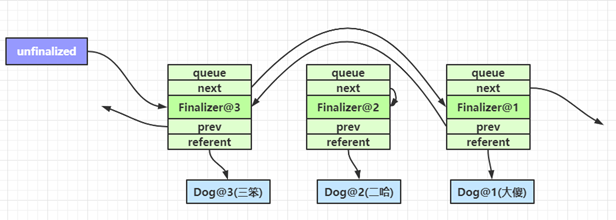
面试准备知识点与总结——(虚拟机篇)
目录JVM的内存结构JVM哪些部分会发生内存溢出方法区、永久代、元空间三者之间的关系JVM内存参数JVM垃圾回收算法1.标记清除法2.标记整理3.标记复制说说GC和分代回收算法三色标记与并发漏标的问题垃圾回收器项目中什么时候会内存溢出,怎么解决类加载过程三个阶段何为…...
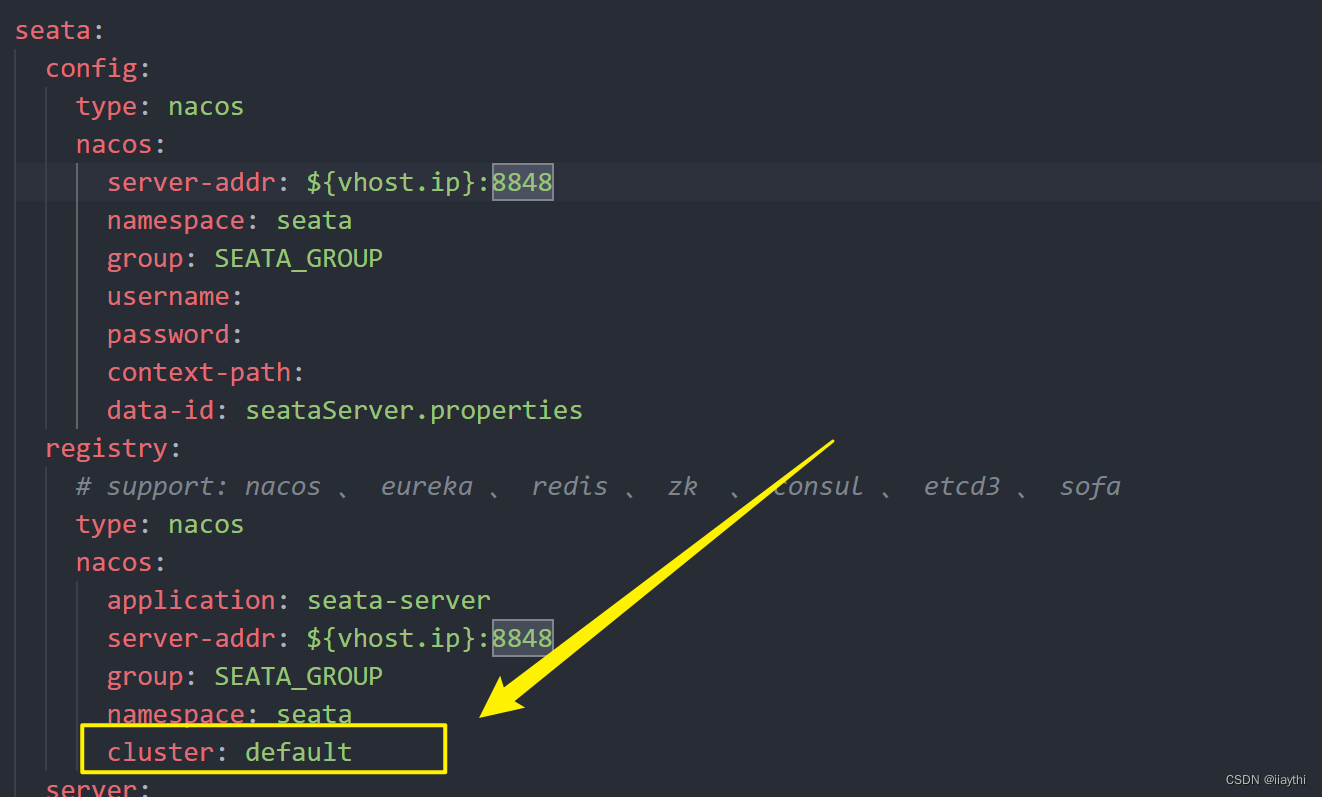
spring cloud 集成 seata 分布式事务
spring cloud 集成 seata 分布式事务 基于 seata-server 1.6.x 序言 下载 seata-server 准备一个数据库 seata 专门为 seata-server 做存储,如, 可以指定 branch_tabledistributed_lockglobal_tablelock_table 准备一个业务库,比如存放定单ÿ…...
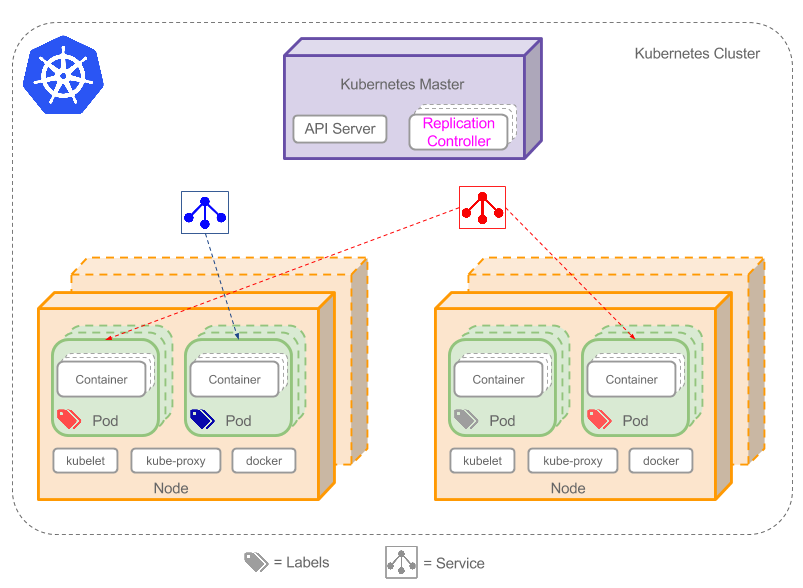
k8s篇之概念介绍
文章目录时光回溯什么是K8SK8S不是什么一、K8S构成组件控制平面组件(Control Plane Components)kube-apiserveretcdkube-schedulerkube-controller-managercloud-controller-managerNode 组件kubeletkube-proxy容器运行时(Container Runtime&…...

JavaScript学习第1天:浏览器组成、JS的组成、变量、数据类型转化、运算符、while和do...while循环
目录一、浏览器的组成二、JS的组成三、变量1、同时声明多个变量2、声明变量特殊情况四、数据类型1、数据类型2、 isNaN()方法3、字符串转义符4、字符串拼接5、特殊拼接五、数据类型转换1、转化为字符串2、转化为数字型3、转化为布尔值六、运算符1、递增和递减运算符2、逻辑运算…...

Display-Lock:窗口状态锁定技术原理与C#实战
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫Stateford/Display-Lock。乍一看这个名字,可能有点摸不着头脑,Stateford听起来像个人名或者组织名,Display-Lock直译是“显示锁定”。但当你深入进去,会发现…...

软考资料全集
距离2026年上半年软考(5月开考)已不算遥远,现在正是着手准备的好时机。回顾这几年的备考历程,我也曾为找资料花费不少时间。趁着这次整理,我把手头积累的各科目复习资料——全部来自互联网公开渠道——系统地归拢了一下…...

Lobe Icons:现代AI与工具类应用的SVG图标系统设计与工程实践
1. 项目概述:一套为现代数字界面而生的图标系统如果你和我一样,常年混迹在各类开源项目、独立开发社区,或者自己动手搭建过一些Web应用、设计系统,那你一定对“找图标”这件事深有体会。从Material Design到Font Awesomeÿ…...

AI智能体安全审计实战:构建可插拔的安全技能库
1. 项目概述:一个面向AI智能体的安全审计技能库最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的现象:大家把大量精力都花在了让智能体“更聪明”上,比如提升其推理能力、扩展工具调用范围,…...

OptimiLabs velocity:轻量级模型服务化部署实战指南
1. 项目概述与核心价值最近在开源社区里,OptimiLabs 推出的 velocity 项目引起了我的注意。这名字起得挺有意思,直译过来就是“速度”,一听就知道是冲着提升效率去的。作为一个长期在数据科学和机器学习工程化领域摸爬滚打的人,我…...

2026年度成都App开发推荐榜单专业又靠谱,让你轻松选择最佳应用
在2026年度成都APP开发推荐榜单中,我们为您提供了一系列专业的开发团队。这些团队均具备丰富的行业经验,专注于满足用户需求和优化用户体验。不论是功能开发还是市场推广,推荐的企业都能提供高效且可靠的解决方案,确保您的项目能够…...

基于MCP协议构建AI工具调用客户端:原理、实践与Node.js实现
1. 项目概述:MCP生态中的客户端实践最近在折腾AI智能体开发,发现一个挺有意思的现象:大家把大模型的能力吹得天花乱坠,但真要让它们去操作一个具体的系统、查询实时的数据,或者调用一个私有API,往往就卡壳了…...

vue基于springboot框架的内部服务器销售信息管理平台
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分技术实现要点系统交互设计扩展功能规划项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用…...
)
Sora 2 × YouTube双平台协同工作流:自动生成多尺寸横竖版+智能章节标记+CC字幕同步(仅需1次Prompt)
更多请点击: https://intelliparadigm.com 第一章:Sora 2 YouTube双平台协同工作流全景概览 Sora 2 作为新一代多模态生成引擎,已原生支持高保真视频结构化输出与语义时间轴标注;YouTube 则通过 Creator Studio API 和 Data API…...

【ElevenLabs地铁语音实战指南】:0代码接入、3步定制多语言报站,已验证上线北京/深圳12条线路
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs地铁站播报语音 ElevenLabs 提供的高保真语音合成 API,正被广泛应用于城市轨道交通的智能广播系统中。其多语言、低延迟、情感可调的 TTS(Text-to-Speech)…...