spark的使用
spark的使用
spark是一款分布式的计算框架,用于调度成百上千的服务器集群。
安装pyspark
# os.environ['PYSPARK_PYTHON']='解析器路径' pyspark_python配置解析器路径
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
pip install pyspark # 原始国外安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark #网址安装
java安装
前置安装软件java包
java官网下载地址
一键下一步安装,配置环境变量
首先创建一个JAVA_HOME的全局变量然后在path中通过%%引入执行下面的bin 路径%JAVA_HOME%\bin


执行成功
from pyspark import SparkConf,SparkContext# 创建sparkConf 类对象
conf= SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc =SparkContext(conf=conf)
# 打印pySpark的运行脚本
print(sc.version)
# 停止sparkContext对象的运行(停止pySpark程序)
sc.stop()
PySpark的数据计算,都是基于RDD对象来进行的,RDD对象内置丰富的:成员方法(算子)
map算子
功能:map算子,是将RDD的数据一条条处理,处理的逻辑基于map算子中接收的处理函数,返回新的RDD语法:

# 简单执行map将数据乘以10返回,如果不引入python解析器的路径引入就会报错,
from pyspark import SparkConf, SparkContext
# 指定spark的python解析器路径
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5, 6])def func(data):return data * 10# map传入一个参数有返回值,是函数或者是值
rdd2 = rdd.map(func)
print(rdd2.collect())

flatMap
flatMap跟map差不多就是在最后做了一个解除嵌套的功能
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(['中石科技 时间还复活甲 如今房价','慰问金 咖啡机 姐夫哥','格很高 客服管家二恶烷 可归结为'])rdd2 = rdd.flatMap(lambda x:x.split(' '))print(rdd2.collect())
map的结果

reduceByKey
reduceByKey对数据进行分组可以两两计算
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = "D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([('男', 11), ('男', 22), ('女', 21), ('男', 31), ('女', 99)])
# 把男女进行分组value值进行计算
rdd2 = rdd.reduceByKey(lambda a, b:a+b)print(rdd2.collect()) # [('女', 120), ('男', 64)]reduce
与reduce的区别就是没有进行分组
take
取出前几个数据
...
rdd = sc.parallelize([1,2,3,4,5]).take(3) # [1,2,3]
count
计算rdd中的数据个数
filter

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']='D:/dev/python/python3.11.4/python.exe'conf=SparkConf().setMaster('local[*]').setAppName('test_spark')
sc=SparkContext(conf=conf)rdd=sc.parallelize([1,2,3,4,5])rdd2=rdd.filter(lambda a:a%2==0)
print(rdd2.collect()) # [2,4]distinct
进行数据去重
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']='D:/dev/python/python3.11.4/python.exe'conf=SparkConf().setMaster('local[*]').setAppName('test_spark')
sc=SparkContext(conf=conf)add= sc.parallelize([1,2,3,4,5,6,73,3,2,4,56,3,5])add2=add.distinct()
print(add2.collect()) # [56, 1, 73, 2, 3, 4, 5, 6]
sortBy排序
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python3.11.4/python.exe'conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
sc = SparkContext(conf=conf)add = sc.textFile('D:/wordText.txt')word_rdd = add.flatMap(lambda x: x.split(' '))
word_with_rdd = word_rdd.map(lambda word: (word, 1))
result_rdd =word_with_rdd.reduceByKey(lambda a,b:a+b)
result_num=result_rdd.sortBy(lambda x:x[1],ascending=False,numPartitions=1) # 1.根据什么排序,2.True 升序 False降序 3.分布式分区
print(result_num.collect())
collect
将rdd内容变成list,从而就可以打印出来
spark写入文件
首先安装
- 下载Hadoop安装包Hadoop安装包
- 然后把hadoop.dll放入指定文件夹内
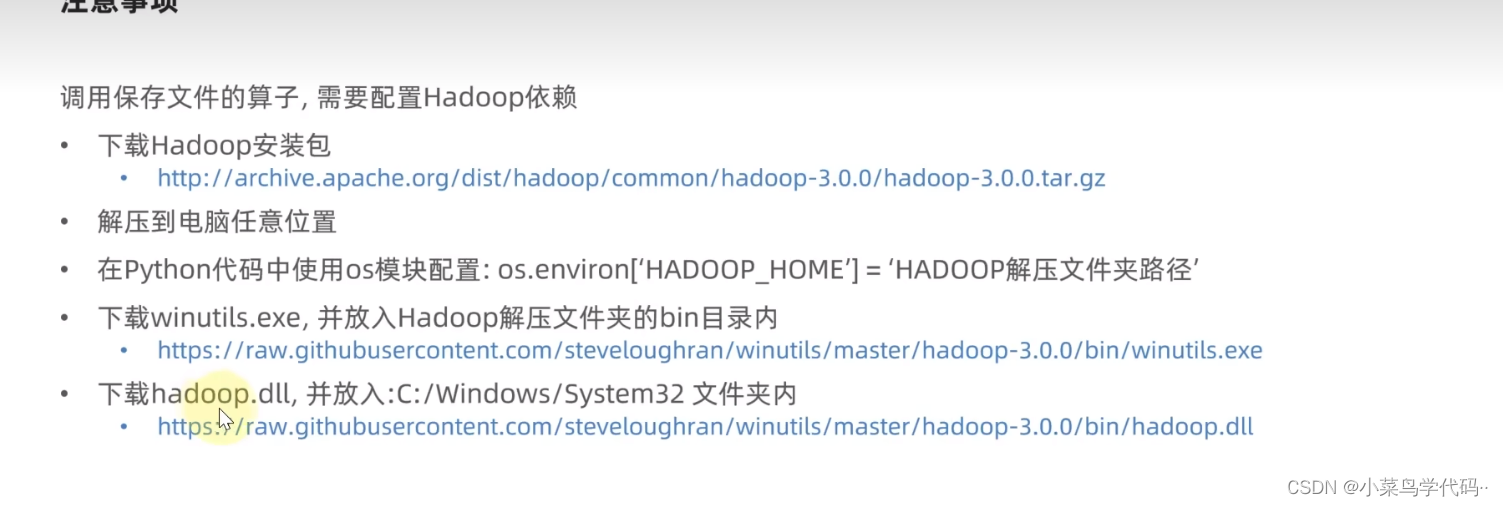
os.environ['HADOOP_HOME']='D:/dev/hadoop/hadoopjob3.0'
conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
sc = SparkContext(conf=conf)rdd2=sc.parallelize([[1,3,5],[6,7,9]])
rdd2.saveAsTextFile('D:/output1')
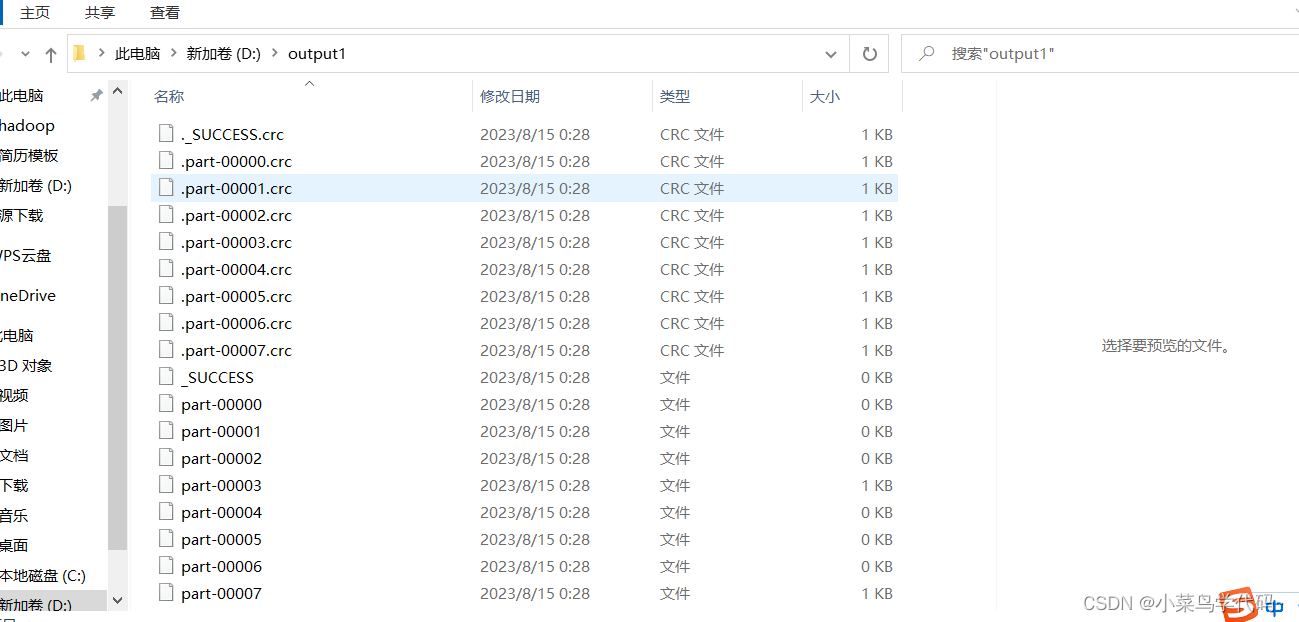
这样创建出来的文件就有16个分区,因为我的是16内核
如果想要在一个分区就要设置参数
import ...
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python3.11.4/python.exe'
os.environ['HADOOP_HOME']='D:/dev/hadoop/hadoopjob3.0'
conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
# 第一种
conf.set("spark.default.parallelism",'1') # 设置一个分区
sc = SparkContext(conf=conf)# rdd2=sc.parallelize([[1,3,5],[6,7,9]])
# 第二种设置一个分区
rdd2=sc.parallelize([[1,3,5],[6,7,9]],1) # numSlices=1 参数可以不写直接传1
rdd2.saveAsTextFile('D:/output1')
相关文章:
spark的使用
spark的使用 spark是一款分布式的计算框架,用于调度成百上千的服务器集群。 安装pyspark # os.environ[PYSPARK_PYTHON]解析器路径 pyspark_python配置解析器路径 import os os.environ[PYSPARK_PYTHON]"D:/dev/python/python3.11.4/python.exe"pip inst…...
)
力扣:66. 加一(Python3)
题目: 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数不会以零开头。 来源:力扣…...

Go的标准库Context理解
作为一个才入门的菜鸟,还没写过真正的 go 项目,要理解这个 Context 还是有点难,不过还是要尝试一下。在 Go http包的Server中,每一个请求在都有一个对应的 goroutine 去处理。请求处理函数通常会启动额外的 goroutine 用来访问后端…...
Nuxt3_1_路由+页面+组件+资源+样式 使用及实例
1、 简介 1.1 开发必备 node版本 v16.10.0 我使用的是16.14.0编辑器推荐使用Volar Extension 的VS code插件Terminal 运行nuxt指令 1.2 环境搭建 安装项目: npx nuxilatest init [first_nuxt3]进入项目目录: cd [first_nuxt3]安装依赖:n…...

Kafka第三课
Flume 由三部分 Source Channel Sink 可以通过配置拦截器和Channel选择器,来实现对数据的分流, 可以通过对channel的2个存储容量的的设置,来实现对流速的控制 Kafka 同样由三大部分组成 生产者 服务器 消费者 生产者负责发送数据给服务器 服务器存储数据 消费者通过从服务器取…...

elasticsearch修改es集群的索引副本数量
前言 最近es集群进行调整,从2节点变成了单节点。所以需要将集群模式改为单点模式,并需要将es 集群的全部索引副本个数改为0,不然会有很多未分配的分片,导致集群状态为 yellow。 具体实践 1. 先将现有的index的副本数量为0个 此…...

【SpringCloud】Ribbon定制化配置
文章目录 使用Ribbon自带负载均衡算法添加负载均衡算法ConfigurationRestTemplate使用上面负载均衡算法 自定义负载均衡算法负载均衡算法实现RestTemplate在Controller中使用该负载均衡算法ServiceIInstance解释 使用Ribbon自带负载均衡算法 添加负载均衡算法Configuration /…...

Mac terminal 每次打开都要重新配置文件
1. 问题描述 每次打开 Terminal,base_profile文件中配置的内容就不生效,需要重新执行source ~/.bash_profile才可以使用。 2. 原因分析 zsh加载的是~/.zshrc文件,而.zshrc 文件中并没有定义任务环境变量。 3. 解决办法 在~/.zshrc文件末尾添…...

el-button实现按钮,鼠标移入显示,移出隐藏
2023.8.18今天我学习了 如何实现鼠标移入显示按钮,鼠标移出隐藏按钮。 效果如图: 鼠标移入时: 鼠标移出时: mouseover //鼠标移入事件 mouseleave //鼠标移出事件 原本我是想直接在el-button写入这两个方法,但是elem…...
uniapp+uview封装小程序请求
提要: uniapp项目引入uview库 此步骤不再阐述 1.创建环境文件 env.js: let BASE_URL;if (process.env.NODE_ENV development) {// 开发环境BASE_URL 请求地址; } else {// 生产环境BASE_URL 请求地址; }export default BASE_URL; 2.创建请求文件 该…...
idea常见错误大全之:解决全局搜索失效+搜索条件失效(条件为空)+F8失灵
问题一:全局搜索快捷键ctrlshiftf 突然失灵了,键盘敲烂了 都没反应,这是为什么呢? 肯定不是idea本身的原因,那么就是其它外在因素影响到了idea的快捷键,那么其它的快捷键为什么没失效呢,原因只有…...

【论文阅读】基于深度学习的时序预测——LTSF-Linear
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…...

02.FFMPEG的安装和添加硬件加速自编译
说一个极其郁闷的事情,就在昨天收到3399的一块板子后,往电脑上面一插,然后悲剧的事情就发生了,我的电脑蓝屏重启了,这下好了,我写到一半的帖子也不见了,我的SSH里面的记录全部消失了,…...

elementUI 的上传组件<el-upload>,自定义上传按钮样式
方法一: 原理:调用<el-upload>组件的方法唤起选择文件事件 效果: 页面代码: 1、选择图片按钮 <div class"flex_row_spacebetween btn" click"chooseImg"><span class"el-icon-plus ic…...
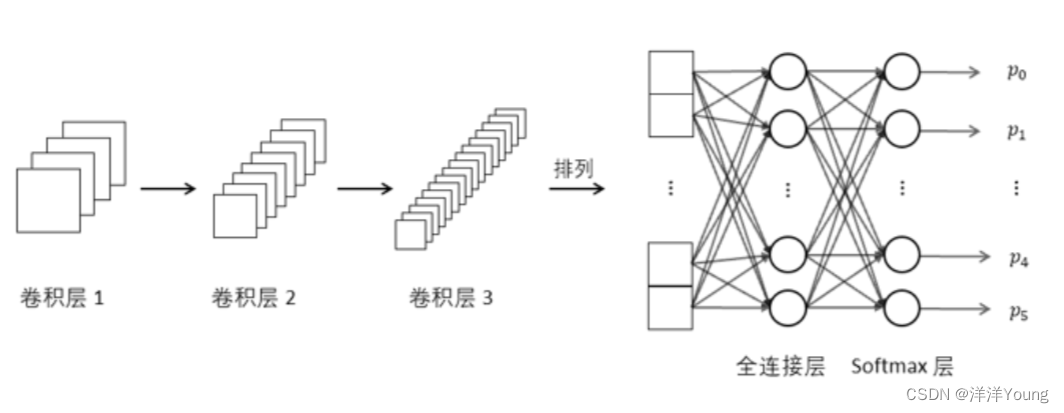
【卷积神经网络】卷积,池化,全连接
随着计算机硬件的升级与性能的提高,运算量已不再是阻碍深度学习发展的难题。卷积神经网络(Convolution Neural Network,CNN)是深度学习中一项代表性的工作,CNN 是受人脑对图像的理解过程启发而提出的模型,其…...

【SA8295P 源码分析】76 - Thermal 功耗 之 /dev/thermalmgr 相关调试命令汇总
【SA8295P 源码分析】76 - Thermal 功耗 之 /dev/thermalmgr 相关调试命令汇总 1、配置文件:/mnt/etc/system/config/thermal-engine.conf2、获取当前SOC所有温度传感器的温度:cat /dev/thermalmgr3、查看所有 Thermal 默认配置和自定义配置:echo query config > /dev/th…...

以太网(一):PoE供电
一、定义: PoE系统包括供电端设备(PSE)和受电端设备(PD)两部分PoE(Power over Ethernet):是一种可以在以太网中透过双绞线来传输电力与数据到设备上的技术PSE(Power S…...

骨传导耳机游泳能戴吗?骨传导游泳耳机哪个牌子好?
溽热的夏日,如果能够跳入水中畅游一番,那真的是再好不过了,既能强身健体,又能降温解暑。公共的游泳场馆人声鼎沸,像我这种“社恐”患者,如果在场馆中要待好几个小时,难免会觉得时间漫长…...
18万字应急管理局智慧矿山煤矿数字化矿山技术解决方案WORD
导读:原文《18万字应急管理局智慧矿山煤矿数字化矿山技术解决方案WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 目 录 第一章 项目概述 1.1项目…...

【mysql】MySQL CUP过高如何排查?
文章目录 一. 问题锁定二. QPS激增会导致CPU飘高三. 慢SQL会导致CPU飘高四. 大量空闲连接会导致CPU飘高五. MySQL问题排查常用命令 一. 问题锁定 通过top命令查看服务器CPU资源使用情况,明确CPU占用率较高的是否是mysqld进程,如果是则可以明确CUP飘高的原…...

你知道AI时代的我们如何用好AI吗?
如何用AI写文案看起来更像真人写的呢?给AI这个指令:1. “翻译”术语,换成“人话”:把那些抽象的、正确的套话,“翻译”成生活中能摸得着的场景。比如“优化流程”不如说“省下喝咖啡的时间”。多用这种场景感强的表达&…...

保姆级教程:在Ubuntu上复现‘easy溯源’靶场,手把手教你分析反弹Shell和内网穿透痕迹
在Ubuntu上复现‘easy溯源’靶场:从环境搭建到痕迹分析实战指南 当你第一次接触应急响应时,是否曾被各种专业术语和复杂场景搞得晕头转向?本文将带你从零开始,在Ubuntu系统上完整复现一个名为easy溯源的靶场环境。这不是简单的解题…...

提示工程架构师用Agentic AI,为智能城市提升品质生活
提示工程架构师:借助Agentic AI提升智慧城市品质生活 一、引言 (Introduction) 钩子 (The Hook) 想象一下,你生活在这样一个城市:每天清晨,你的智能设备会根据当天的天气、你的日程安排,精准推荐最适宜的衣物和出行方式…...

别再死记硬背了!用Halcon的vector_angle_to_rigid算子搞定视觉定位,附完整代码
视觉定位实战:用Halcon的vector_angle_to_rigid算子避开几何变换的三大误区 在工业视觉项目中,刚体变换是坐标转换的核心技术,但许多工程师在使用Halcon的vector_angle_to_rigid算子时,常陷入三个致命误区:误认为旋转…...

PCB布局设计规范与工程实践要点
PCB布局设计思路与工程实践指南1. 布局设计基本原则1.1 结构约束优先原则在PCB布局初期,必须优先考虑机械结构约束条件:定位安装孔、连接器等结构件需严格按照外壳设计文件放置连接器1脚方向必须与结构设计匹配,避免装配错误元件高度不得超过…...

揭秘APP签名信息:如何快速获取MD5、SHA1和SHA256值
1. 为什么需要获取APP签名信息? 当你下载一个APP时,有没有想过如何确认它真的是官方发布的版本?或者作为开发者,如何确保自己打包的APK没有被篡改?这些问题的答案都藏在APP的签名信息里。签名信息就像APP的"身份证…...
)
CMake vs. MsBuild vs. Ninja:C++编译工具链全解析(附Windows平台实战示例)
CMake vs. MsBuild vs. Ninja:C编译工具链全解析(附Windows平台实战示例) 在C开发的世界里,构建工具的选择往往决定了项目的可维护性和跨平台能力。当你在Windows平台上打开Visual Studio时,背后默默工作的可能是MsBui…...

UE5 GAS调试技巧:巧用ASC的‘Attribute Test’面板,5分钟搞定角色属性配置与验证
UE5 GAS高效调试指南:利用Attribute Test面板快速验证角色属性配置 在虚幻引擎5的游戏开发中,Gameplay Ability System (GAS)作为构建复杂角色能力与属性的核心框架,其调试效率直接影响着RPG类项目的开发进度。本文将深入探讨如何利用Ability…...

BiliTools:跨平台B站资源管理工具的全方位应用指南
BiliTools:跨平台B站资源管理工具的全方位应用指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliToo…...

零基础玩转OpenClaw:ollama GLM-4-7-Flash镜像入门十步曲
零基础玩转OpenClaw:ollama GLM-4-7-Flash镜像入门十步曲 1. 为什么选择OpenClawGLM-4-7-Flash组合 去年我在整理个人知识库时,每天要花2小时重复处理Markdown文档和截图。直到发现OpenClaw这个能像真人一样操作电脑的开源智能体,配合ollam…...