REC 系列 Visual Grounding with Transformers 论文阅读笔记
REC 系列 Visual Grounding with Transformers 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- 3.1 视觉定位
- 3.2 视觉 Transformer
- 四、方法
- 4.1 基础的视觉和文本编码器
- 4.2 定位编码器
- 自注意力的文本分支
- 文本引导自注意力的视觉分支
- 4.3 定位解码器
- 定位 query 自注意力
- 编码器-解码器自注意力
- 4.4 预测头和训练目标
- 五、实验
- 5.1 数据集
- 5.2 实施细节
- 超参数的设置
- 训练和评估细节
- 5.3 与 SOTA 方法的比较
- 5.4 消融实验
- 每部分的贡献
- 文本引导自注意力的有效性
- 层的数量
- 5.5 定性分析
- 六、结论
写在前面
Hello,马上又是一周过去了,快要开学了,不知道小伙伴们状态都调整过来了吗?加油噢~
这同样是一篇关于 REC 的文章,文章时间比较早了,但也是属于那种入门必看的文章。
- 论文地址:VISUAL GROUNDING WITH TRANSFORMERS
- 代码地址:https://github.com/usr922/vgtr
- 收录于:ICME 2022
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
本文提出基于 Transformer 的方法用于视觉定位。不像现有的先取出 proposals 后排序的方法,极度依赖于预训练的目标检测器,或者无 proposal 的框架方法,通过融合文本化的 embedding 更新一组离线的单阶段检测器。本文提出的方法 Visual Grounding with TRansformers VGTR 建立在 Transformer 框架之上,独立于预训练检测器和 word embedding 之外,用于学习语义区分性的视觉特征。实验达到了 SOTA 的性能。
二、引言
首先指出视觉定位的定义,应用,难点。早期的方法将视觉定位视为基于文本的图像检索的特例,并将其塑造为:在给定图像中,从一组候选区域中检索指代目标的任务。这些方法极度依赖于预训练的目标检测器,且经常忽略目标的视觉上下文。此外,大多数方法需要额外的计算成本来产生和处理候选 proposals。
最近的一些工作去除了 Proposals 的生成过程,直接定位到目标,但视觉和文本化的特征仍然彼此独立。为减轻这一问题,本文提出端到端的基于 Transformer 的网络 VGTR,在不产生目标 proposals 的情况下,能够捕捉全局视觉和语言上下文。与那些建立在离线检测器或 grid 特征的方法相比,VGTR 将视觉定位视为基于 query sentence 的目标 bounding box 的坐标回归问题。

如上图所示,VGTR 由四个模块组成:基础编码器,用于计算基础的图文对 tokens;一个双流的定位编码器,用于执行视觉语言的共同推理和跨模态交互;一个定位解码器,将文本 toknes 视为定位 queries,从编码后的视觉 tokens 中提出目标的相关特征;一个预测头,用于执行 bounding box 的坐标回归。此外,设计一种新的自注意力机制来替代原有的而应用到视觉 tokens 上,在没有降低定位能力的情况下建立起两种模态间的关联并学习文本引导的视觉特征。
贡献总结如下:
- 提出一种端到到的框架 VGTR 用于视觉定位,无需预训练的检测器和预训练的语言模型;
- 提出文本引导的注意力模块来学习语言描述引导下的视觉特征;
- 方法达到了 SOTA。
三、相关工作
3.1 视觉定位
本文将视觉定位分为两类:proposal-rank,proposal-free。前者首先通过离线的检测器或 proposal 生成器从输入的图像中生成一组候选目标 proposals,然后关联语言描述并对这些候选 proposals 打分,从中选出最高得分的一个作为定位目标。这些方法非常依赖预训练的检测器或 proposal 生成器的性能。
Proposal-free 的方法关注于直接定位指代目标,在精度和推理速度上潜力很足。
3.2 视觉 Transformer
Transformer 最近在目标检测、图像分割很火。DETR 系列将视觉特征图变换为一组 tokens,实现了 SOTA。
四、方法
4.1 基础的视觉和文本编码器
给定图像和参考表达式对 ( I , E ) (I,E) (I,E),视觉定位任务旨在用 Bounding box 定位到由目标表达式描述的目标实例上。
首先调整图像尺寸为 w × h w\times h w×h,然后送入 ResNet backbone 中提取图像特征图 F ∈ R w s × h s × d F\in \mathbb{R}^{\frac ws\times\frac hs \times d} F∈Rsw×sh×d,其中 s s s 为 backbone 输出的步长, d d d 为通道数量。之后将视觉特征图 F F F 变形为视觉 tokens X v = { v i } i = 1 T v X_v=\{{{v}_i}\}_{i=1}^{T_v} Xv={vi}i=1Tv,其中 T v = w s × h s T_v=\frac ws\times\frac hs Tv=sw×sh 为 tokens 的数量, v i v_i vi 的尺寸为 d d d。
使用基于 RNN 的 soft-parser 提取文本 tokens:对给定的表达式 E = { e t } t = 1 T E=\{e_t\}^{T}_{t=1} E={et}t=1T,其中 T T T 表示单词个数, 首先用可学习的 embedding 层,即 u t = Embedding ( e t ) u_t=\text{Embedding}(e_t) ut=Embedding(et) 将每个单词 e t e_t et 转变为向量 u t u_t ut。然后应用双向 LSTM 编码每个单词的上下文。之后计算第 k k k 个文本 token 在第 t t t 个单词上的注意力:
h t = Bi-LSTM ( u t , h t − 1 ) a k , t = exp ( f k T h t ) ∑ i = 1 T exp ( f k T h i ) \begin{aligned} h_{t}& =\operatorname{Bi-LSTM}(u_{t},h_{t-1}) \\ a_{k,t}& =\frac{\exp(f_k^Th_t)}{\sum_{i=1}^T\exp(f_k^Th_i)} \end{aligned} htak,t=Bi-LSTM(ut,ht−1)=∑i=1Texp(fkThi)exp(fkTht)之后第 k k k 个文本 token 定义为 word embedding 的权重求和:
l k = ∑ t = 1 T a k , t u t \boldsymbol{l}_k=\sum_{t=1}^Ta_{k,t}\boldsymbol{u}_t lk=t=1∑Tak,tut最后的文本 tokens 表示为 X l = { l k } k = 1 T l X_{l}=\{l_{k}\}_{k=1}^{T_{l}} Xl={lk}k=1Tl,其中 T l T_l Tl 为 tokens 的数量, l k l_k lk 的尺寸为 d d d。
4.2 定位编码器
定位编码器由堆叠的 N N N 个独立层组成,每层包含两个独立的视觉+语言分支,用于处理视觉和文本 tokens。和 Transformer 层相同,每个分支包含三个子层:Norm Layer,多头自注意力层 multi-head self-attention layer,全连接前向层 FFN。
自注意力的文本分支
给定 queries q l q_l ql,从第 i i i 层的文本 tokens X l i X_l^i Xli 中得出 keys k l k_l kl 和 values v l v_l vl,文本自注意力层的输出为:
T-Attn ( q l , k l , v l ) = softmax ( q l k l T d ) ⋅ v l \operatorname{T-Attn}(\boldsymbol{q}_l,\boldsymbol{k}_l,\boldsymbol{v}_l)=\operatorname{softmax}\left(\frac{\boldsymbol{q}_l\boldsymbol{k}_l^T}{\sqrt d}\right)\cdot\boldsymbol{v}_l T-Attn(ql,kl,vl)=softmax(dqlklT)⋅vl之后应用 FFN,定义为 FFN l \text{FFN}_l FFNl 得到文本特征 X l i + 1 X_l^{i+1} Xli+1:
X l i + 1 = FFN l (T-Attn ( q l , k l , v l ) ) X_l^{i+1}=\text{FFN}_l\text{ (T-Attn}(q_l,k_l,v_l)) Xli+1=FFNl (T-Attn(ql,kl,vl))
文本引导自注意力的视觉分支
视觉分支的结构同文本分支类似,但有一个额外的组件称之为文本引导的自注意力,旨在文本描述的引导下提取显著性的视觉特征。具体来说,给定 queries q v q_v qv, 从第 i i i 层的视觉 tokens X v i X_v^i Xvi 中得出 keys k v k_v kv 和 values v v v_v vv。接下来文本特征 X l i + 1 X_l^{i+1} Xli+1 作为额外的引导信息来补充视觉 queries。为顺利实现,通过特定 token 对文本 tokens X l i + 1 X_l^{i+1} Xli+1 的权重求和,再添加上视觉 queries q v q_v qv。其中权重通过 q v q_v qv 和 X l i + 1 X_l^{i+1} Xli+1 的点乘得到:
V − A t t n ( q ^ v , k v , v v ) = s o f t m a x ( q ^ v k v T d ) ⋅ v v q ^ v = q v + s o f t m a x ( q v ( X l i + 1 ) T d ) ⋅ X l i + 1 \mathrm{V-Attn}(\hat{\boldsymbol{q}}_v,\boldsymbol{k}_v,\boldsymbol{v}_v)=\mathrm{softmax}\left(\frac{\hat{\boldsymbol{q}}_vk_v^T}{\sqrt{d}}\right)\cdot\boldsymbol{v}_v \\ \\ \begin{aligned}\hat{q}_v&=\boldsymbol{q}_v+\mathrm{softmax}\left(\frac{\boldsymbol{q}_v(X_l^{i+1})^T}{\sqrt d}\right)\cdot X_l^{i+1}\end{aligned} V−Attn(q^v,kv,vv)=softmax(dq^vkvT)⋅vvq^v=qv+softmax(dqv(Xli+1)T)⋅Xli+1类似的,应用 FFN,表示为 FFN v \text{FFN}_v FFNv 得到视觉 tokens X v i + 1 X_v^{i+1} Xvi+1:
X v i + 1 = F F N v ( V − A t t n ( q ^ v , k v , v v ) ) X_v^{i+1}=\mathrm{FFN}_v(\mathrm{V-Attn}(\hat{q}_v,k_v,v_v)) Xvi+1=FFNv(V−Attn(q^v,kv,vv))
下图为跨模态注意力和本文提出的文本引导的注意力机制示意图:

一个典型的多模态自注意力机制的 Queries 来源于一个模态,而 Keys,Values 则源于另一个模态来执行标准的自注意力操作,类似 Transformer 解码器中的自注意力操作。但以这种方式融合文本信息到图像特征中可能会损害定位能力,于是本文提出通过文本 tokens 引导视觉特征,从而实现更高的性能。
4.3 定位解码器
解码器同样由 N N N 个独立的层堆叠组成。其中每层有 4 个子层:Norm Layer,定位 query 自注意力层 grounding query self-attention layer,编码器-解码器自注意力层,全连接前项层 fully connected feed-forward (FFN) layer。
定位解码器的输入为修改后的文本 tokens X l N X_l^N XlN,之后为定位 queries G G G 服务,此外还有视觉 tokens X v N X_v^N XvN 的参与。在定位 queries 的引导、定位 query 自注意力、编码器-解码器自注意力机制下,将文本引导的视觉特征解码。
定位 query 自注意力
给定 queries q g q_g qg,从第 i i i 层的定位 queries G i G^i Gi 中得出 keys k g k_g kg 和 values v g v_g vg。然后应用标准的自注意力机制执行 query 增强:
G-Attn ( q g , k g , v g ) = softmax ( q g k g T d ) ⋅ v g \text{G-Attn}(q_g,k_g,v_g)=\text{softmax}\left(\frac{q_gk_g^T}{\sqrt{d}}\right)\cdot v_g G-Attn(qg,kg,vg)=softmax(dqgkgT)⋅vg之后通过层归一化 layer normalization (LN) 得到修改后的定位 queries:
G i + 1 = L N ( G − A t t n ( q g , k g , v g ) ) G^{i+1}=\mathrm{LN}(\mathrm{G-Attn}(q_g,k_g,v_g)) Gi+1=LN(G−Attn(qg,kg,vg))
编码器-解码器自注意力
编码器-解码器自注意力将定位 queries G i + 1 G^{i+1} Gi+1 视为 queries f g q f_g^q fgq,从编码后的视觉 tokens X v N X_v^N XvN 中得到 keys f v k f_v^k fvk 和 values f v v f^v_v fvv 作为输入,输出提取后的文本相关特征:
ED-Attn ( q g , k v , v v ) = softmax ( q g k v T d ) ⋅ v v \operatorname{ED-Attn}(q_g,k_v,v_v)=\operatorname{softmax}\left(\frac{q_gk_v^T}{\sqrt d}\right)\cdot v_v ED-Attn(qg,kv,vv)=softmax(dqgkvT)⋅vv最后,应用 FFN,表示为 FFN e d \text{FFN}_{ed} FFNed 得到最终的 embeddings Z Z Z:
Z = FFN e d ( ED-Attn ( q g , k v , v v ) ) Z=\text{FFN}_{ed}(\text{ED-Attn}(q_g,k_v,v_v)) Z=FFNed(ED-Attn(qg,kv,vv))
4.4 预测头和训练目标
本文将指代目标定位任务视为 bounding box 坐标回归问题。从定位解码器中得到变换后的 embedding Z = { z i } i = 1 K ∈ R K × d Z=\{z_{\boldsymbol{i}}\}_{i=1}^{K}\in\mathbb{R}^{K\times d} Z={zi}i=1K∈RK×d,然后拼接所有变换后的向量,之后使用预测头来回归中心点的坐标以及指代目标的宽高。预测头由两个全连接层后跟 ReLU 激活层组成。
训练目标为 L1 损失和通用 IoU(GIoU) 损失 L i o u ( ⋅ ) \mathcal{L}_{iou}(\cdot) Liou(⋅) 的线性组合:
L o s s = λ L 1 ∣ ∣ b − b ^ ∣ ∣ 1 + λ L i o u L i o u ( b , b ^ ) Loss=\lambda_{L_1}||b-\hat{b}||_1+\lambda_{L_{iou}}\mathcal{L}_{iou}(b,\hat{b}) Loss=λL1∣∣b−b^∣∣1+λLiouLiou(b,b^)其中 b ^ \hat b b^ 表示预测目标的 bounding box, b b b 为 GT, λ L 1 \lambda_{L_1} λL1、 λ L i o u ∈ R \lambda_{L_{iou}}\in \mathbb{R} λLiou∈R 为平衡两种损失的超参数。
五、实验
5.1 数据集
Flickr30k Entities、RefCOCO/RefCOCO+/RefCOCOg。
5.2 实施细节
超参数的设置
输入图像尺寸 512 × 512 512\times512 512×512,句子的最大长度 20,Backbone 的输出步长 s = 32 s=32 s=32。对于所有的数据集,提取 4 个文本 tokens。多头注意力中头的数量为 8,隐藏层尺寸 d = 256 d=256 d=256,VGTR 的层数 N = 2 N=2 N=2, λ L 1 = 5 \lambda_{L_1}=5 λL1=5, λ L i o u = 2 \lambda_{L_{iou}}=2 λLiou=2.
训练和评估细节
AdamW 优化器,初始学习率 1 e − 4 1e-4 1e−4,权重衰减 1 e − 5 1e-5 1e−5,CNN backbone:ResNet50/101,初始化权重采用预训练在 MSCOCO 数据上的权重。总共训练 120 个 epoch,在第 70 个和第 90 个 epoch 时,学习率衰减 10 % 10\% 10%。采用 Accuracy@0.5 作为评估指标、
5.3 与 SOTA 方法的比较

5.4 消融实验
每部分的贡献

文本引导自注意力的有效性

层的数量
同上表 3。
5.5 定性分析

六、结论
本文提出单阶段的基于 Transformer 的框架 VGTR 用于视觉定位任务,实验表明方法有效。
写在后面
这篇论文比较简短啊,但也算是对 Transformer 的一个很好的应用和改进了吧,在 2021 年的时候。现在看效果就没那么炸裂了。而且论文里面作者这个写作水平也得提高一下,很多概念都是点一下,没有深究。此外浪费了一部分篇章在 Transformer 结构上,这是不太合适的。
相关文章:
REC 系列 Visual Grounding with Transformers 论文阅读笔记
REC 系列 Visual Grounding with Transformers 论文阅读笔记 一、Abstract二、引言三、相关工作3.1 视觉定位3.2 视觉 Transformer 四、方法4.1 基础的视觉和文本编码器4.2 定位编码器自注意力的文本分支文本引导自注意力的视觉分支 4.3 定位解码器定位 query 自注意力编码器-解…...

Linux常用命令总结
Linux是一种自由和开放源代码的操作系统,它被广泛用于服务器和其他大型系统中。然而,如果你刚开始使用Linux,可能会对如何有效地操作感到困惑。这篇文章将介绍一些常用的Linux命令,帮助你更好地理解和使用这个强大的系统。 文件和…...
Scratch 之 制作超丝滑 FNF 推条
这个教程是不用画笔的,所以不用担心推条是最后一层了! 导入素材 你以为真是这样吗?NO,NO,NO,其实是这样的 没错,中间是空的!中间是空的!中间是空的!…...

java通过反射,动态调用指定注解的方法
SpringBootTest RunWith(SpringRunner.class) public class AnnoTest {Autowiredprivate ApplicationContext applicationContext;Testpublic void test(){// 获取有指定注解的BeanMap<String, Object> annotationMap applicationContext.getBeansWithAnnotation(CacheC…...

QT学习方法
1 .类的学习方法 第一步:从UI文件中,找到界面的类—QMainWindow第二步:在Qt Creator工具中,找到“帮助”按钮,进入到帮助菜单界面,在选择"索引",在Look for:输入类名,找到类名,双击条目中的类名,在右侧会显示出来类的详细内容第三步:在右侧,可根据内容目录…...

C++中的类型擦除技术
文章目录 一、C类型擦除Type Erasure技术1.虚函数2.模板和函数对象 二、任务队列1.基于特定类型的方式实现2.基于任意类型的方式实现 参考: 一、C类型擦除Type Erasure技术 C中的类型擦除(Type Erasure)是一种技术,用于隐藏具体类…...

激光雷达 01 线数
一、线数 对于 360 旋转式和一维转镜式架构的激光雷达来说,有几组激光收发模块,垂直方向上就有几条线,被称为线数。这种情况下,线数就等同于激光雷达内部激光器的数量[参考]。 通俗来讲,线数越高,激光器的…...
PHP 公交公司充电桩管理系统mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP 公交公司充电桩管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 源码下载 https://download.csdn.net/download/qq_41221322/88220946 论文下…...

HTML <strong> 标签
定义和用法 以下元素都是短语元素。虽然这些标签定义的文本大多会呈现出特殊的样式,但实际上,这些标签都拥有确切的语义。 我们并不反对使用它们,但是如果您只是为了达到某种视觉效果而使用这些标签的话,我们建议您使用样式表&a…...

机器学习笔记 - 使用 ResNet-50 和余弦相似度的基于图像的推荐系统
一、简述 这里的代码主要是基于图像的推荐系统,该系统利用 ResNet-50 深度学习模型作为特征提取器,并采用余弦相似度来查找给定输入图像的最相似嵌入。 该系统旨在根据所提供图像的视觉内容为用户提供个性化推荐。 二、所需环境 Python 3.x tensorflow ==2.5.0 numpy==1.21.…...
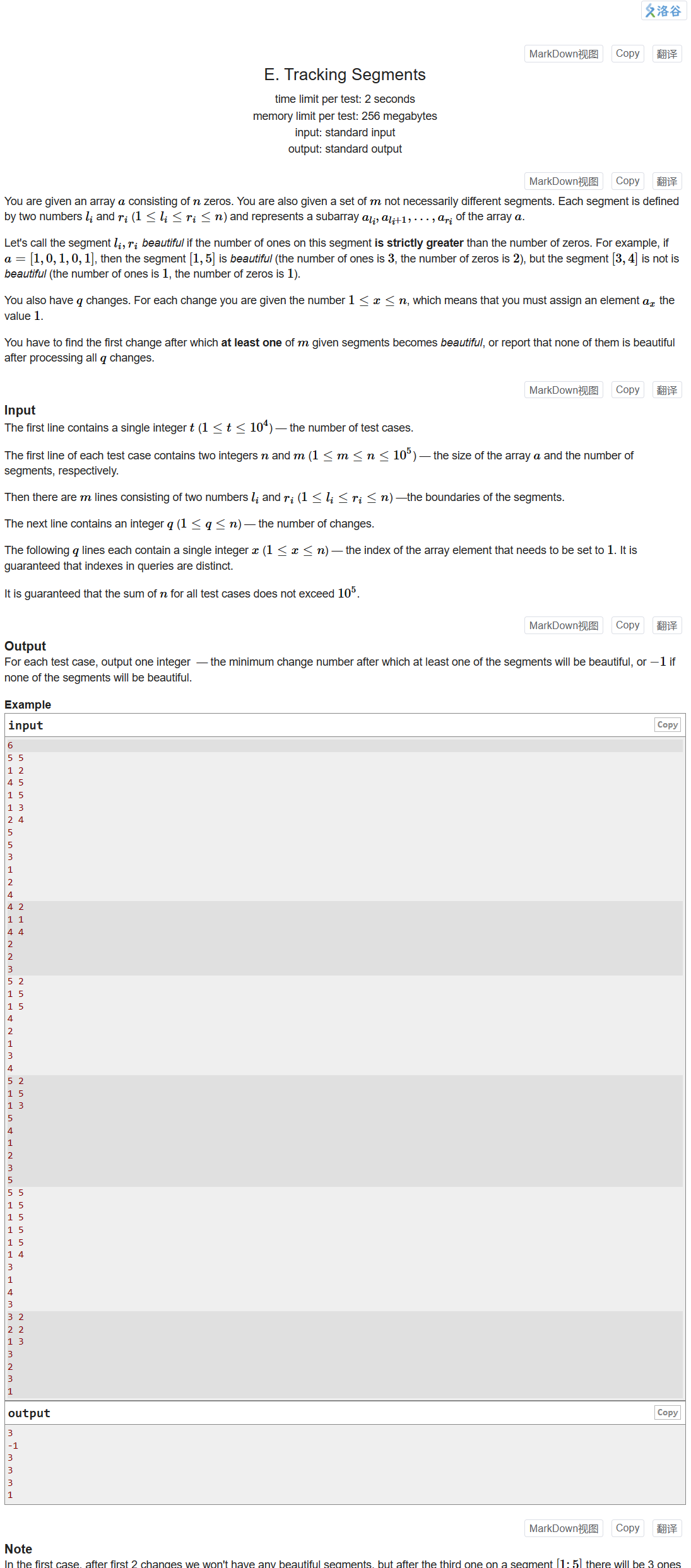
Codeforces Round 881 Div.3
文章目录 贪心:A. Sasha and Array Coloring结论:B. Long Long性质:C. Sum in Binary Treedfs求叶子数量:D. Apple Tree二分与前缀和:E. Tracking Segments 贪心:A. Sasha and Array Coloring Problem - A…...
从入门到精通系列之十六:linux服务器安装minikube的详细步骤)
Kubernetes(K8s)从入门到精通系列之十六:linux服务器安装minikube的详细步骤
Kubernetes K8s从入门到精通系列之十六:linux服务器安装minikube的详细步骤 一、安装Docker二、创建启动minikube用户三、下载minikube四、安装minikube五、将minikube命令添加到环境变量六、启动minikube七、查看pods,自动安装kubectl八、重命名minikube kubectl --为kubect…...
JDBC配置文件抽取-spring11
改成context,到这里我们context命名空间就引入完毕,加载我们外部properties配置文件: 用它:第一个属性,第二个类型 在未加载路径下: 现在我已经把spring加载到配置文件里了。 现在我需要在这个位置引入proper…...

el-form组件相关的一些基础使用
el-checkbox 01.description 多选单选框 02.场景举例 需要对每一条数据展示她的某些状态是否存在 03.代码展示 <el-checkbox v-model"query.isAutoAccptncsign" true-label1 false-label0 :disabled"ifReview?true:false">自动发起承兑应答</…...
全新 – Amazon EC2 M1 Mac 实例
去年,在 re: Invent 2021 大会期间,我写了一篇博客文章,宣布推出 EC2 M1 Mac 实例的预览版。我知道你们当中许多人请求访问预览版,我们尽了最大努力,却无法让所有人满意。不过,大家现在已经无需等待了。我很…...

java # Servlet
一、什么是Servlet? Servlet是javaEE规范之一。规范就是接口。JavaWeb三大组件分别是:Servlet程序、Filter过滤器、Listener监听器。Servlet是运行在服务器上的一个Java小程序,它可以接收客户端发送来的请求,并响应数据给客户端。…...

Linux内核的两种安全策略:基于inode的安全与基于文件路径的安全
实现系统安全的策略 在Linux中,一切且为文件,实现系统安全的策略主要可分为两种:基于inode的安全、基于文件路径的安全。 基于inode的安全 为文件引入安全属性,安全属性不属于文件内容,它是文件的元数据,…...

有哪些前端开发工具推荐? - 易智编译EaseEditing
在前端开发中,有许多工具可以帮助你更高效地进行开发、调试和优化。以下是一些常用的前端开发工具推荐: 代码编辑器/集成开发环境(IDE): Visual Studio Code:功能强大、轻量级的代码编辑器,支…...

【JAVA】抽象类与接口
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈Java 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 抽象类与接口 1. 抽象类1.1 抽象类的概念…...

人脸图像处理
1,人脸图像与特征基础 人脸图像的特点 规律性: 人的两只眼睛总是对称分布在人脸的上半部分,鼻子和嘴唇中心点的连线基本与两眼之间的连线垂直,嘴绝对不会超过眼镜的两端点(双眼为d,则双眼到嘴巴的垂直距离一般在0.8-1.25) 唯一性 非侵扰与便利性 可扩展性 人脸图像的应用 身份…...

Illustrator脚本合集:设计师的10倍效率提升神器
Illustrator脚本合集:设计师的10倍效率提升神器 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否厌倦了在Adobe Illustrator中重复繁琐的操作?是否渴望…...

基于MCP与多准则决策的数据中心智能选址系统设计与实践
1. 项目概述:数据中心选址智能决策的现代解法最近在做一个挺有意思的项目,客户是一家大型互联网公司,他们计划在海外新建一个大型数据中心,但面对全球几十个潜在选址,从土地成本、电力供应、网络延迟到政策风险&#x…...


auto-rednote:自动化信息整理工具的设计原理与实战应用
1. 项目概述与核心价值 最近在整理个人笔记和知识库时,我遇到了一个几乎所有内容创作者和开发者都会头疼的问题:如何高效地将散落在各处的、格式不一的“红色笔记”(比如微信收藏、网页剪藏、临时备忘录)自动整理成结构化的、可检…...

2026年最值得投入的5款AI Agent工具:Gartner认证+生产环境压测数据全公开
更多请点击: https://intelliparadigm.com 第一章:2026年最佳AI Agent工具推荐 2026年,AI Agent 已从概念原型迈入企业级生产部署阶段。开发者不再满足于单任务自动化,而是追求具备长期记忆、跨平台协调与自主目标分解能力的智能…...

羽毛球每天必练的基本功:拉吊四方球战术、吊杀结合战术
文章目录 引言 I 羽毛球每天必练的基本功 1. 握拍练习 2. 挥拍动作 3. 步法训练 4. 球感练习 5. 发力技巧 II 发力 正确发力 握拍 反手发力 III 羽毛球单打战术 拉吊四方球战术 直线变斜线战术 重复落点战术 吊杀结合战术 追身球压制战术 防守反击战术 引言 打球前必须热身(活…...

客户受电工程图纸审核|全网独家复现,多模态+知识图谱创新改进篇 引入MM-KG融合架构,多模态感知+知识关联助力图纸全检、隐患精准定位、审核效率翻倍
目录 一、行业痛点:人工抽检模式的致命瓶颈(附真实场景痛点) 1.1 审核效率极低,无法适配规模化需求 1.2 漏判误判率高,审核质量依赖个人经验 1.3 审核标准不统一,追溯难度大 1.4 人力成本高昂,专业人才缺口大 二、创新突破:多模态+知识图谱融合架构(核心改进解析…...

阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏
阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师繁琐的日常任务而烦恼吗&#…...

零基础避坑指南什么工具可以录音转待办
还在手动把面试录音扒成文字再摘待办?做HR的谁没踩过这个坑:整理一小时,漏了候选人关键信息,还把待办记错,今天直接讲能直接上手的方法,零基础也不会踩坑。我做HR那几年,光整理录音待办就熬了无…...

WordPress AI内容创作栈:基于Claude API的自动化写作与运维实践
1. 项目概述:一个为WordPress量身定制的AI内容创作栈最近在折腾一个内容站,发现内容创作和日常运维的重复性工作实在太多了。从构思文章大纲、撰写初稿,到批量处理图片、优化SEO元数据,再到回复评论、生成周报,这些工作…...