常见排序算法--Java实现
常见排序算法--Java实现
- 插入排序
- 直接插入排序
- 折半插入排序
- 希尔排序
- 交换排序
- 冒泡排序
- 快速排序
- 选择排序
- 直接选择排序
- 堆排序
- 归并排序
- 基数排序
- 各种排序方法比较
在网上找了些排序算法的资料。此篇笔记本人总结比较,简单注释,觉得比较好理解,且相对简短方便记忆。
插入排序
直接插入排序
- 默认第0个有序,后面挨个插入前面有序的数中(像打扑克插牌一样)
/***(直接)插入排序* 默认第0个有序,后面挨个插入前面有序的数中(像打扑克插牌一样)*/
public static void ChaRu(int a[], int n){int i,j;// 第0个有序,从第1个开始for(i = 1; i < n; i++){int temp = a[i]; // 要插入的元素保存起来// 在前面i-1个有序数组中,找插入的下标for(j = i - 1; j >= 0 && temp < a[j]; j--){a[j + 1] = a[j]; // 移动,覆盖}a[j + 1] = temp; // 找到位置了,插入,继续把后面的插入,循环}
}
折半插入排序
- 折半插入排序(增加二分查找)
/*** 折半插入排序(增加二分查找)*/
public static void ZheBanCha(int a[], int n){int i, j;for(i = 1; i < n; i++){int temp = a[i]; // 待插入的元素// 二分查找法,找插入的位置int left = 0, right = i - 1; // 0开始while(left <= right){int mid = (left + right) / 2;if(temp < a[mid]) right = mid - 1;else left = mid + 1;} // right + 1 为插入的位置// 统一后移元素,空出插入位置for(j = i - 1; j >= right + 1; j--){ // >=a[j + 1] = a[j];}a[right + 1] = temp; // right + 1 插入}
}
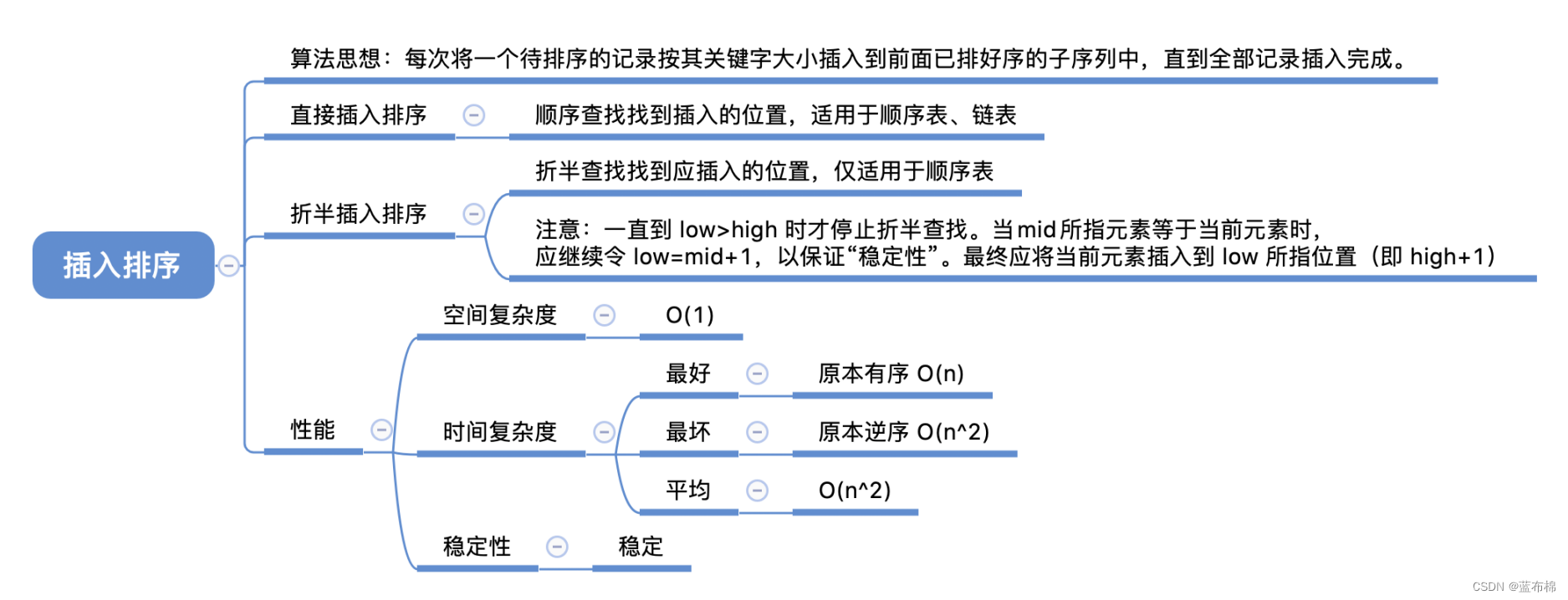
希尔排序
- 希尔排序(新增for循环,步长为有序增量表:4,2,1)[把1变成d]
/*** 希尔排序(新增for循环,步长为有序增量表:4,2,1)[把1变成d]*/
public static void shell(int[] a, int n) {int d, i, j;// 步长变化,每次减半,直到为1for(d = n / 2; d >= 1; d = d / 2){ // 新增for步骤for(i = d; i < n; i++){ // 1 -> dint temp = a[i];for(j = i - d; j >= 0 && temp < a[j]; j -= d){a[j + d] = a[j];}a[j + d] = temp;}}
}
交换排序
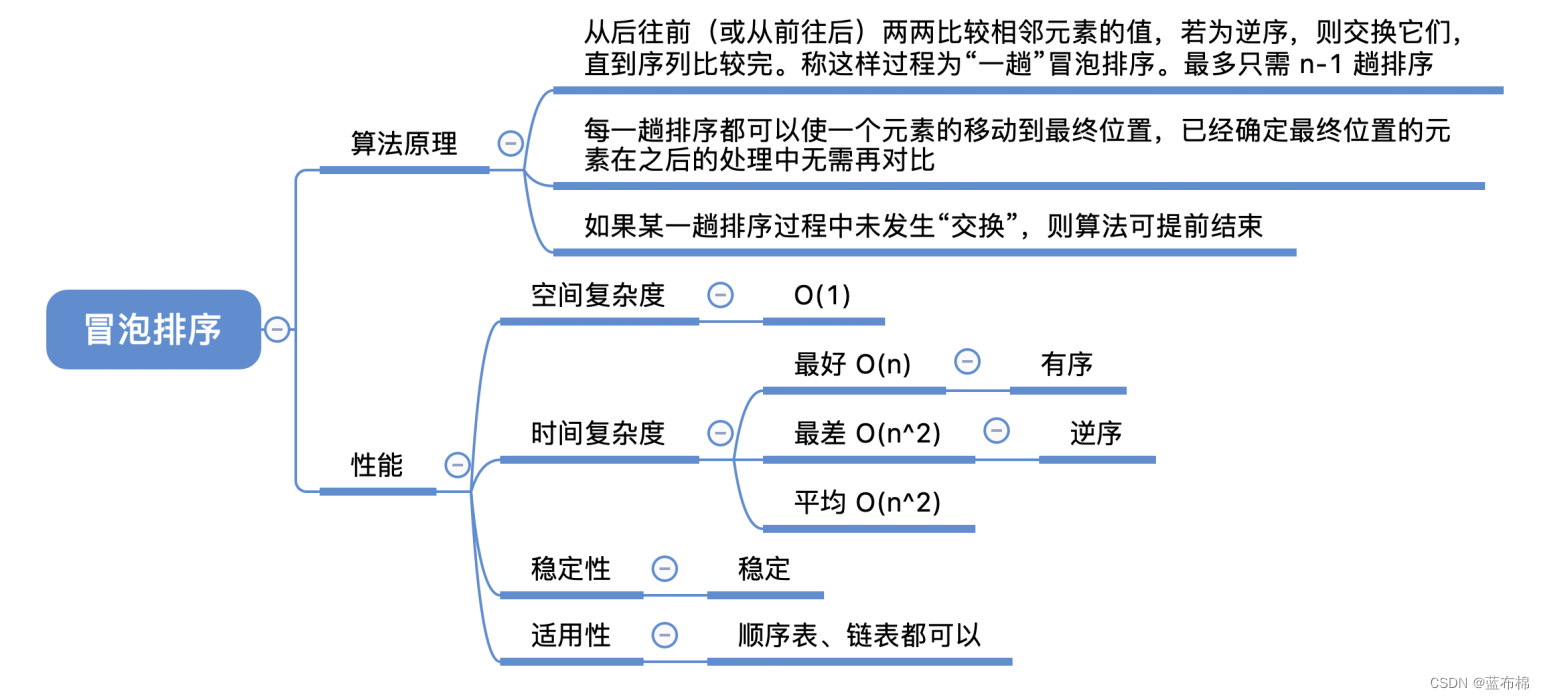
冒泡排序
- 每一趟都会把最大的数排到最后,然后继续看前面的,不管最后的了(因为后面有序了)
/*** 冒泡排序(加了flag优化)* 每一趟都会把最大的数排到最后,然后继续看前面的,不管最后的了(因为后面有序了)*/
public static void MaoPao(int[] a, int n) {for(int i = 0; i < n; i++){ // i趟数boolean flag = false; // 提前退出冒泡循环的标志位for(int j = 0; j < n - i - 1; j++){if(a[j] > a[j+1]){ // 比后面大,就交换int temp = a[j];a[j] = a[j+1];a[j+1] = temp;flag = true; // 表示有数据交换}}if(flag == false) return; // 本趟没有数据交换,提前退出}
}
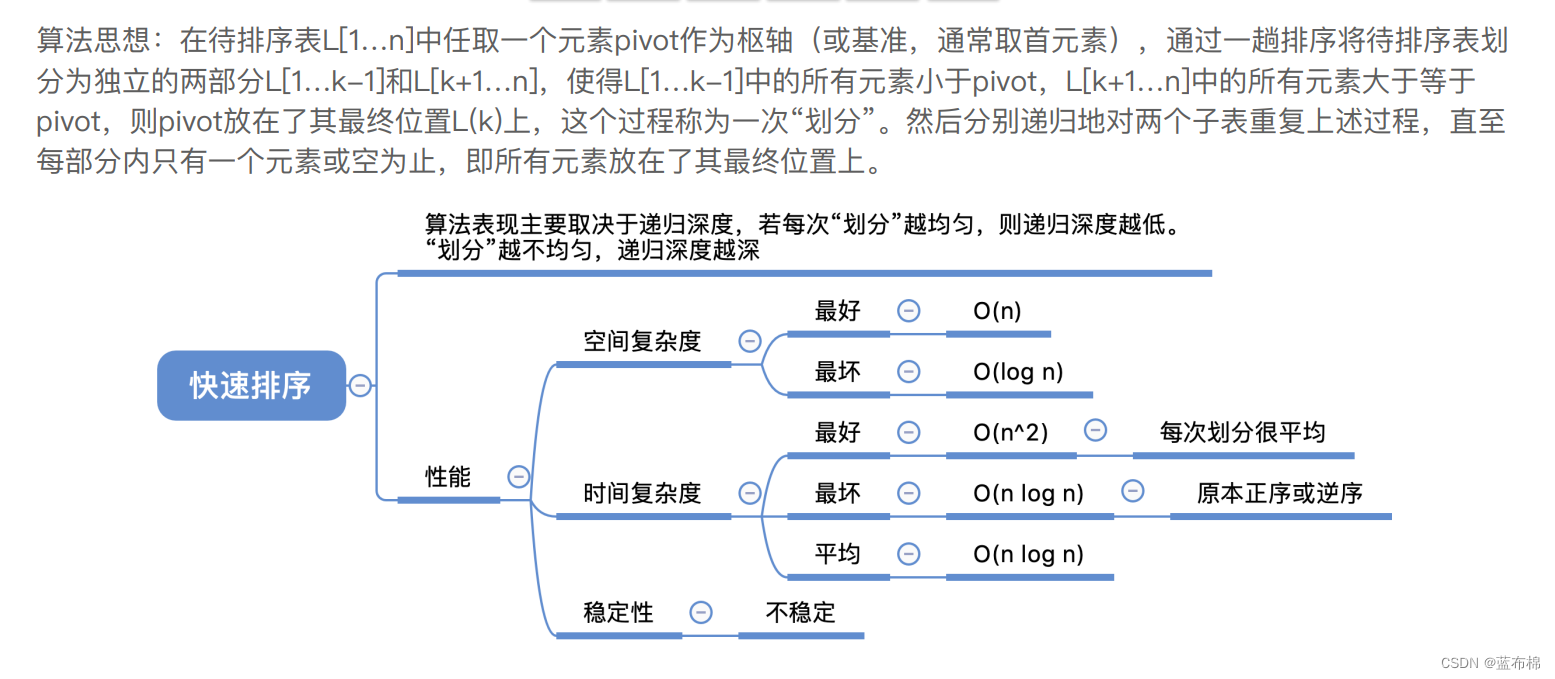
快速排序
- 快速排序(递归,轴,划分左右){ 轴元素放到最终位置,[比轴小,轴,比轴大] }
- 与其他排序算法相反的是:元素越有序,快排时间复杂度越高
/*** 快速排序(递归,轴,划分左右){轴元素放到最终位置,[比轴小,轴,比轴大]}* 与其他排序算法相反的是:元素越有序,快排时间复杂度越高*/
public static void QuickSort(int[] a, int low, int high) {if(low < high) { // 递归跳出的条件int pivot = patition(a, low, high); // 划分函数QuickSort(a, low, pivot - 1); // 划分左子表QuickSort(a, pivot + 1, high); // 划分右子表}
}// 用第一个元素将待排序列划分为左右两个部分(比轴小,比轴大)
public static int patition(int[] a, int low, int high) {int pivot = a[low]; // (暂存)第一个元素作为轴while(low < high) { // 用low,high寻找轴的最终位置while(low < high && a[high] >= pivot) high--;a[low] = a[high]; // 比轴小的移到左端while(low < high && a[low] < pivot) low++;a[high] = a[low]; // 比轴大的移到右端}a[low] = pivot; // 轴元素放到最终位置*return low; // 返回存放轴的最终位置
}
选择排序
直接选择排序
- 简单选择排序(每趟选一个最小的元素,交换到前面)
/*** 简单选择排序(每趟选一个最小的元素,交换到前面)*/
public static void JianDanXuanZe(int[] a, int n) {for(int i = 0; i < n -1; i++){ // 总共n-1趟,最后一次就不用了int min = i; // 记录此趟最小元素位置for(int j = i + 1; j < n; j++) { // 再a[i..n-1]中选择最小元素if(a[j] < a[min]) min = j; // 更新最小元素位置}if(min != i) { // 交换,把最小值放到i的位置int temp = a[i];a[i] = a[min];a[min] = temp;}}
}
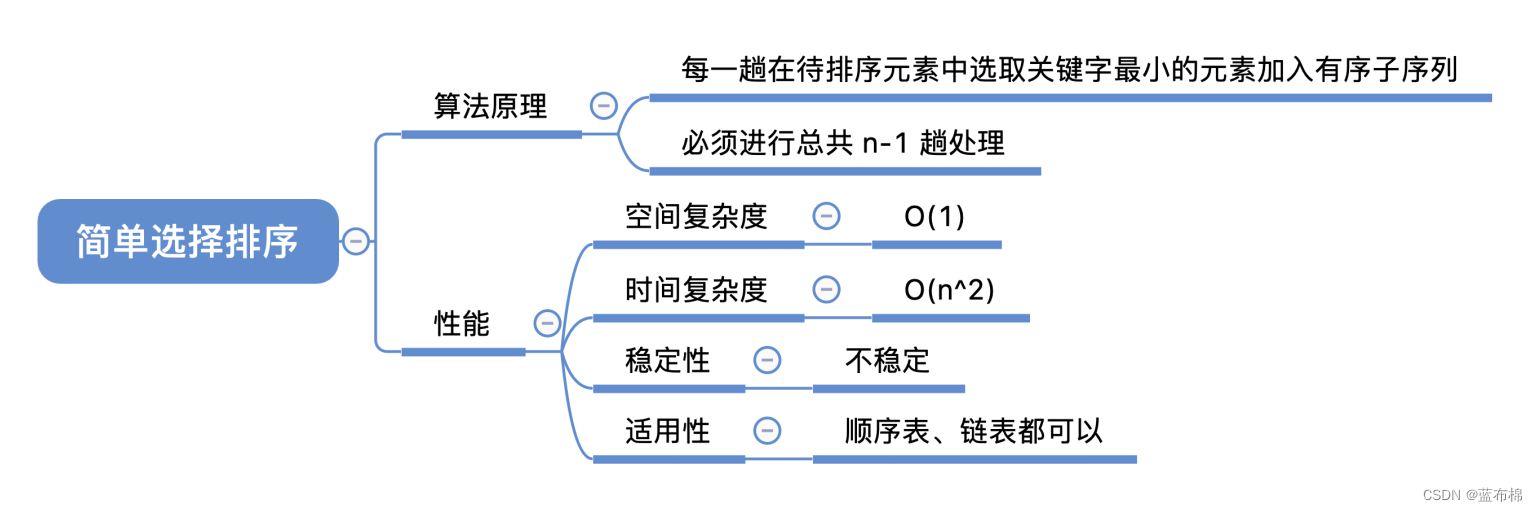
堆排序
/*** 堆排序(从小到大)*/
public static void heapSortAsc(int[] a, int n) {int i,tmp;// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。for (i = n / 2 - 1; i >= 0; i--)maxHeapDown(a, i, n-1);// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素for (i = n - 1; i > 0; i--) {// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。tmp = a[0];a[0] = a[i];a[i] = tmp;// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。// 即,保证a[i-1]是a[0...i-1]中的最大值。maxHeapDown(a, 0, i-1);}
}/*** (最大)堆的向下调整算法** 注: 数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。** 参数说明:* a -- 待排序的数组* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)* end -- 截至范围(一般为数组中最后一个元素的索引)*/
public static void maxHeapDown(int[] a, int start, int end) {int c = start; // 当前(current)节点的位置int l = 2*c + 1; // 左(left)孩子的位置int tmp = a[c]; // 当前(current)节点的大小for (; l <= end; c=l,l=2*l+1) {// "l"是左孩子,"l+1"是右孩子if ( l < end && a[l] < a[l+1])l++; // 左右两孩子中选择较大者,即m_heap[l+1]if (tmp >= a[l])break; // 调整结束else { // 交换值a[c] = a[l];a[l]= tmp;}}
}
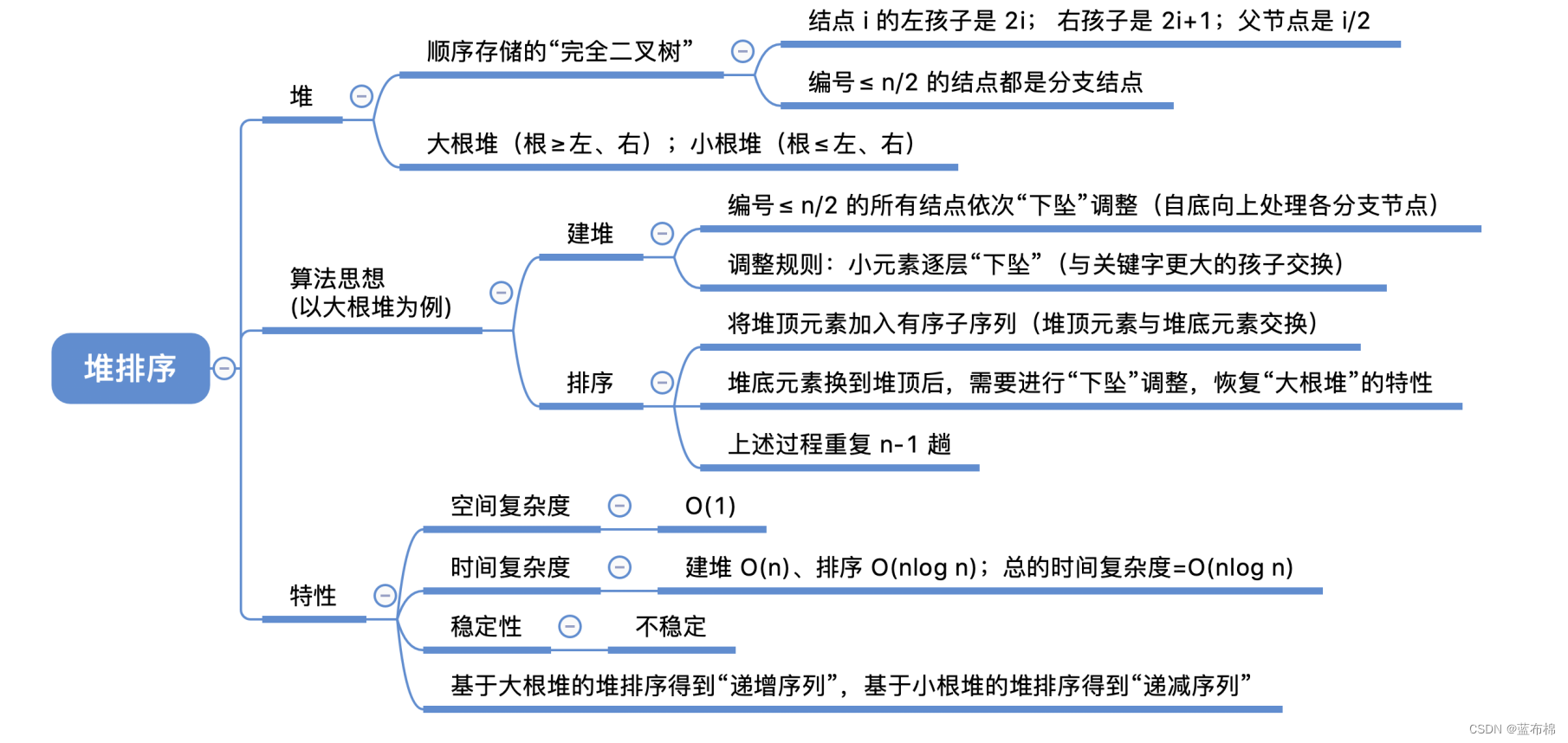
归并排序
- 归并排序(辅助数组,递归,分治,合并)
/*** 归并排序(辅助数组,递归,分治,合并)*/
int[] tmp = new int[a.length]; // 新建一个临时数组存放*public static void mergeSort(int[] a, int low, int high, int[] tmp) {if(low < high){int mid = (low + high) / 2; // 从中间划分mergeSort(a, low, mid, tmp); // 对左半部分归并排序mergeSort(a, mid + 1, high, tmp); // 对右边部分归并排序// (上面两步递归,一直划分到每个子序列只含有一个元素)merge(a, low, mid, high, tmp); // 合并两个有序序列(归并)}
}// a[low..mid] 和 a[mid+1..high] 将两个部分归并(合并)
public static void merge(int[] a, int low, int mid, int high, int[] tmp) {int i, j, k;// 将a[] 中所有元素复制到 tmp[]辅助数组for(k = low; k <= high; k++) {tmp[k] = a[k];}// 两个区间,两个指针 i,j;比较,将较小值复制到 a[]中for(i = low, j = mid + 1, k = i; i <= mid && j <= high; k++){if(tmp[i] < tmp[j])a[k] = tmp[i++];elsea[k] = tmp[j++];}// 若左右序列还有剩余,则将其全部拷贝进 a[]中while(i <= mid) a[k++] = tmp[i++];while(j <= high) a[k++] = tmp[j++];
}
基数排序
- 基数排序(分配,收集)
*** 基数排序(分配,收集)* 个位分配,收集;十位分配,收集;...*/
public static void radixSort(int[] a){int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10// 获取数组a中最大值int max = a[0];for(int i = 1; i < a.length; i++){if(a[i] > max) max = a[i];}// 从个位开始,对数组a按"指数"进行排序(个位,十位,百位。。。)for(exp = 1; max / exp > 0; exp *= 10){int[] output = new int[a.length]; // 存储"被排序数据"的临时数组int[] buckets = new int[10]; // 桶 0-9// 将数据出现的次数存储在buckets[]中for(int i = 0; i < a.length; i++){buckets[(a[i] / exp) % 10]++;}// 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。for(int i = 1; i < 10; i++){buckets[i] += buckets[i - 1];}// 将数据存储到临时数组output[]中for(int i = a.length - 1; i >= 0; i--){output[buckets[(a[i] / exp) % 10] - 1] = a[i];buckets[(a[i] / exp) % 10]--;}// 将排序好的数据赋值给a[]for (int i = 0; i < a.length; i++) {a[i] = output[i];}}
}

各种排序方法比较
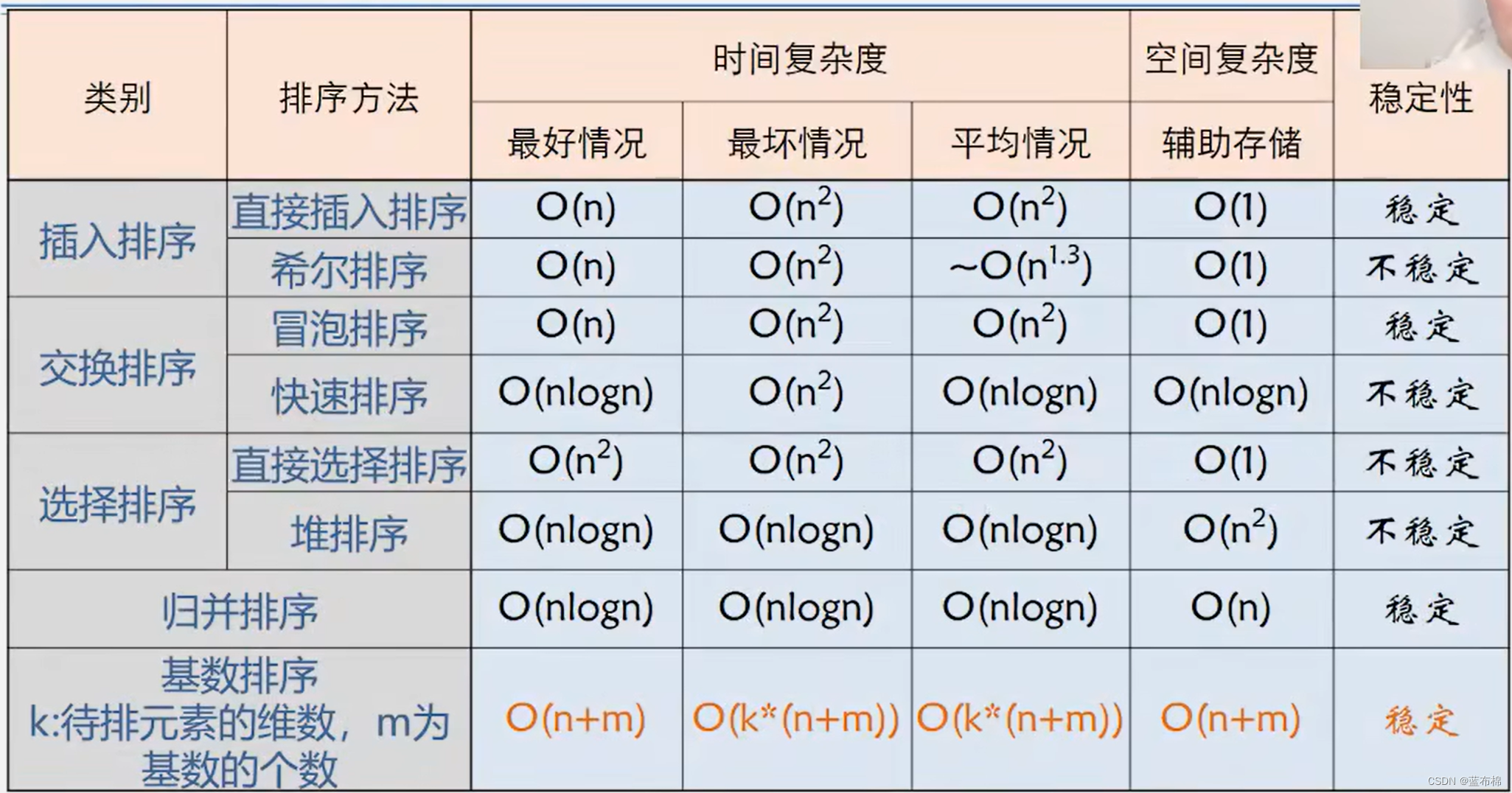
引用:
代码后面附的总结PPT为王道数据结构课件截图
排序方法比较图片为青岛大学王卓老师的数据结构课件截图
相关文章:
常见排序算法--Java实现
常见排序算法--Java实现插入排序直接插入排序折半插入排序希尔排序交换排序冒泡排序快速排序选择排序直接选择排序堆排序归并排序基数排序各种排序方法比较在网上找了些排序算法的资料。此篇笔记本人总结比较,简单注释,觉得比较好理解,且相对…...

算法笔记(九)—— 暴力递归
暴力递归(尝试) 1. 将问题转化为规模缩小了的同类问题子问题 2. 有明确的不需要的继续递归的条件 3. 有当得到子问题结果之后的决策过程 4. 不记录每一个子问题的解 Question:经典汉诺塔问题 1. 理解清楚,基础三个圆盘的移动…...

Flask框架学习记录
Flask项目简要 项目大致结构 flaskDemo1 ├─static ├─templates └─app.py app.py # 从flask这个包中导入Flask类 from flask import Flask# 使用Flask类创建一个app对象 # __name__:代表当前app.py这个模块 # 1.以后出现bug,可以帮助快速定位 # 2.对于寻找…...

【Opencv 系列】 第6章 人脸检测(Haar/dlib) 关键点检测
本章内容 1.人脸检测,分别用Haar 和 dlib 目标:确定图片中人脸的位置,并画出矩形框 Haar Cascade 哈尔级联 核心原理 (1)使用Haar-like特征做检测 (2)Integral Image : 积分图加速特征计算 …...

信源分类及数学模型
本专栏包含信息论与编码的核心知识,按知识点组织,可作为教学或学习的参考。markdown版本已归档至【Github仓库:information-theory】,需要的朋友们自取。或者公众号【AIShareLab】回复 信息论 也可获取。 文章目录信源分类按照信源…...
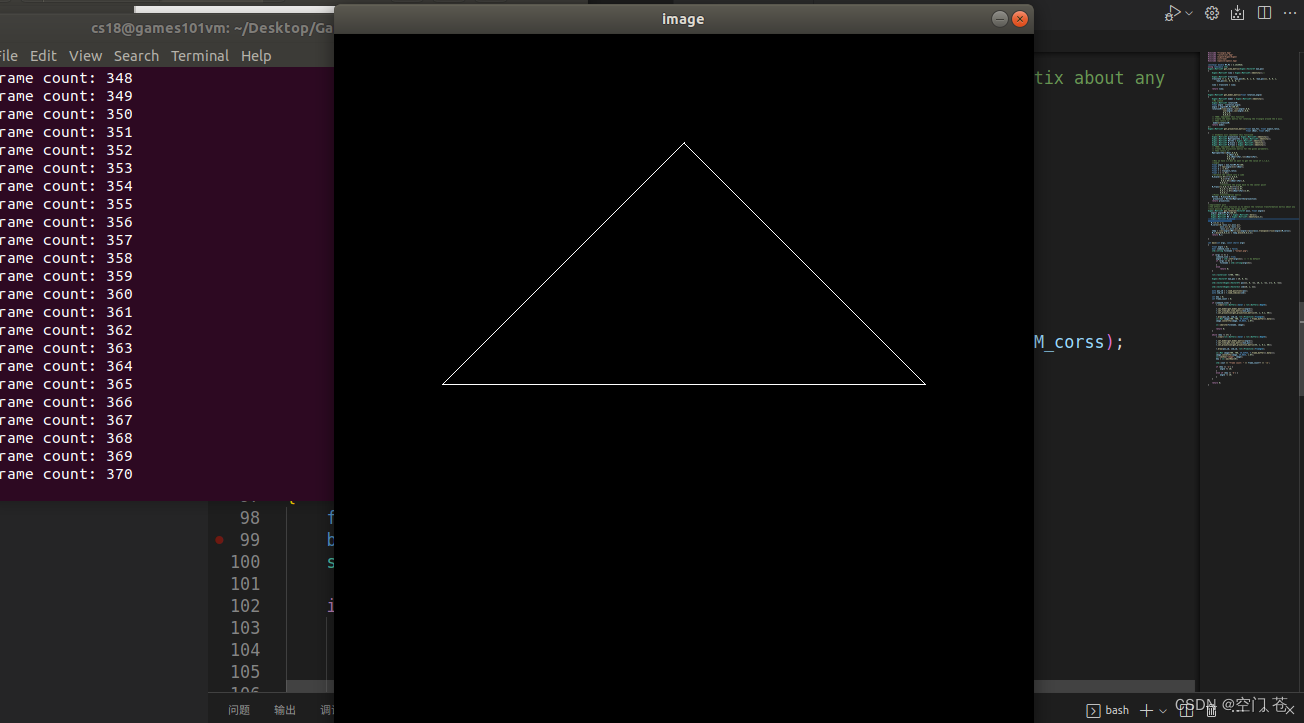
Games101-202作业1
一. 将模型从模型空间变换到世界空间下 在这个作业下,我们主要进行旋转的变换。 二.视图变换 ,将相机移动到坐标原点,同时保证物体和相机进行同样的变换(这样对形成的图像没有影响) 在这个作业下我们主要进行摄像机的平移变换&am…...
Linux系统之终端管理命令的基本使用
Linux系统之终端管理命令的基本使用一、检查本地系统环境1.检查系统版本2.检查系统内核版本二、终端介绍1.终端简介2.Linux终端简介3.终端的发展三、终端的相关术语1.终端模拟器2.tty终端3.pts终端4.pty终端5.控制台终端四、终端管理命令ps1.直接使用ps命令2.列出登录详细信息五…...

【Mongoose笔记】MQTT 服务器
【Mongoose笔记】MQTT 服务器 简介 Mongoose 笔记系列用于记录学习 Mongoose 的一些内容。 Mongoose 是一个 C/C 的网络库。它为 TCP、UDP、HTTP、WebSocket、MQTT 实现了事件驱动的、非阻塞的 API。 项目地址: https://github.com/cesanta/mongoose学习 下面…...

数据结构概述
逻辑结构 顺序存储 随机访问是可以通过下标取到任意一个元素,即数组的起始位置下标 链式存储 链式存储是不连续的,比如A只保留了当前的指针,那么怎么访问到B和C呢 每个元素不仅存储自己的值还使用额外的空间存储指针指向下一个元素的地址&a…...
【前端】Vue3+Vant4项目:旅游App-项目总结与预览(已开源)
文章目录项目预览首页Home日历:日期选择开始搜索位置选择上搜索框热门精选-房屋详情1热门精选-房屋详情2其他页面项目笔记项目代码项目数据项目预览 启动项目: npm run dev在浏览器中F12: 首页Home 热门精选滑动到底部后会自动加载新数据&a…...
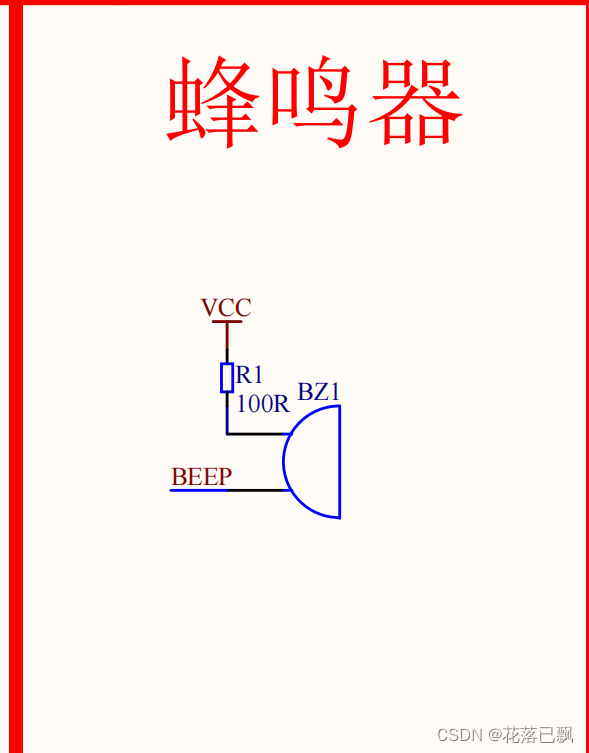
51单片机蜂鸣器的使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、有源蜂鸣器和无源蜂鸣器的区别二、代码编写总结前言 本文旨在介绍如何使用51单片机驱动蜂鸣器。 一、有源蜂鸣器和无源蜂鸣器的区别 有源蜂鸣器是一种电子…...

算法练习-链表(二)
算法练习-链表(二) 文章目录算法练习-链表(二)1. 奇偶链表1.1 题目1.2 题解2. K 个一组翻转链表2.1 题目2.2 题解3. 剑指 Offer 22. 链表中倒数第k个节点3.1 题目3.2 题解3.2.1 解法13.2.2 解法24. 删除链表的倒数第 N 个结点4.1 …...
LabVIEW使用实时跟踪查看器调试多核应用程序
LabVIEW使用实时跟踪查看器调试多核应用程序随着多核CPU的推出,开发人员现在可以在LabVIEW的帮助下充分利用这项新技术的功能。并行编程在为多核CPU开发应用程序时提出了新的挑战,例如同步多个线程对共享内存的并发访问以及处理器关联。LabVIEW可自动处理…...

【go语言grpc之client端源码分析二】
go语言grpc之server端源码分析二DialContextparseTargetAndFindResolvergetResolvernewCCResolverWrapperccResolverWrapper.UpdateStatecc.maybeApplyDefaultServiceConfigccBalancerWrapper.updateClientConnState上一篇文章分析了ClientConn的主要结构体成员,然后…...

centos7安装RabbitMQ
1、查看本机基本信息 查看Linux发行版本 uname -a # Linux VM-0-8-centos 3.10.0-1160.11.1.el7.x86_64 #1 SMP Fri Dec 18 16:34:56 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux cat /etc/redhat-release # CentOS Linux release 7.9.2009 (Core)2、创建创建工作目录 mkdir /…...
node基于springboot 口腔卫生防护口腔牙科诊所管理系统
目录 1 绪论 1 1.1课题背景 1 1.2课题研究现状 1 1.3初步设计方法与实施方案 2 1.4本文研究内容 2 2 系统开发环境 4 2.1 JAVA简介 4 2.2MyEclipse环境配置 4 2.3 B/S结构简介 4 2.4MySQL数据库 5 2.5 SPRINGBOOT框架 5 3 系统分析 6 3.1系统可行性分析 6 3.1.1经济可行性 6 3.…...
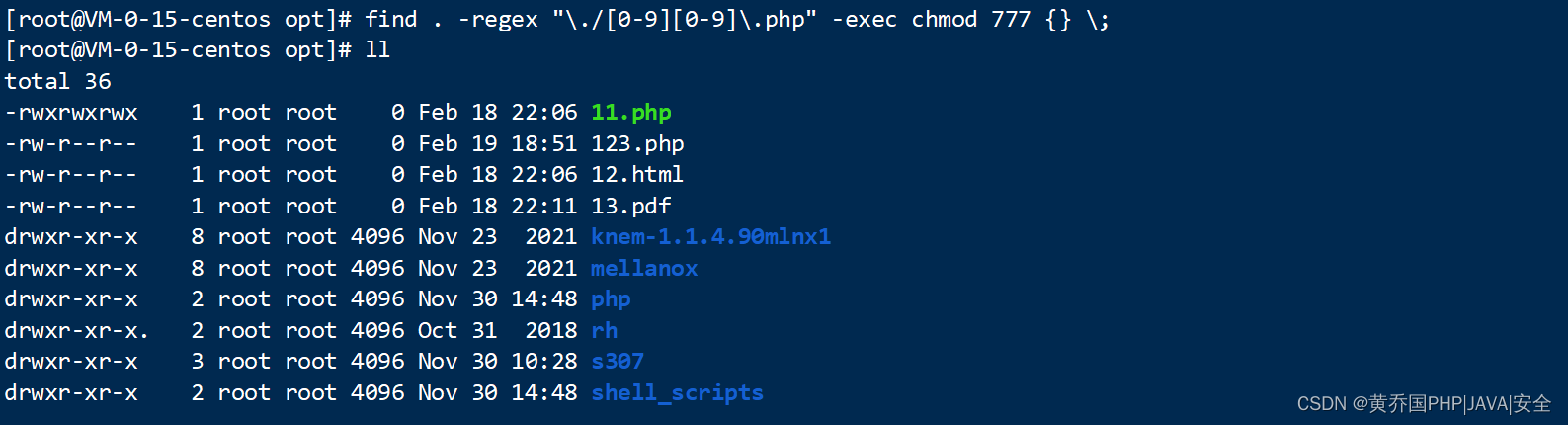
Linux常用命令之find命令详解
简介 find命令主要用于:用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。 如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。 是我们在…...

CMake 入门学习4 软件包管理
CMake 入门学习4 软件包管理一、Linux下的软件包管理1. 检索已安装的软件包2. 让自己编译软件支持pkg-config搜索3. 在CMakeLists查找已安装的软件包二、适合Windows下的包管理工具1. vcpkg2. Conan(1) 安装Conan(2) 配置Conan(3) 创建工程(4) 安装依赖库(5) 使用依赖库三、CMa…...

【数据库数据乱码错误】存进去的数据乱码(???)
目录 1.当我新增一条数据的时候,成功后查看数据库中的数据时,竟然变成???乱码格式了: 2.那么问题有3处需要注意: 第一:settings配置 第二:POM文件 第三:…...
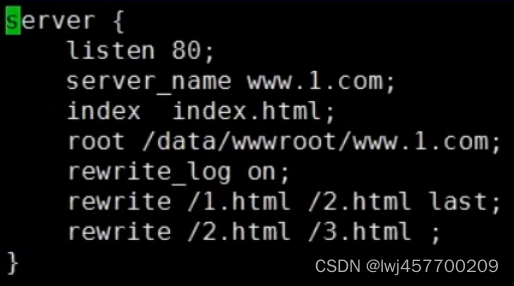
rewrite中的if、break、last
目录 rewrite 作用: 依赖: 打开重定向日志: if 判断: location {} 本身有反复匹配执行特征 在 location 中加入 break 和 last (不一样) 加了break后,立刻停止向下 且 跳出。 加了last…...
)
别再手动汇总了!锐捷BGP路由聚合实战:用aggregate-address优化你的路由表(含as-set、suppress-map详解)
锐捷BGP路由聚合实战:优化网络架构的智能选择 在大型企业网络架构中,BGP路由表规模的膨胀常常成为网络工程师的噩梦。当路由条目突破十万级别时,设备内存占用激增、路由收敛速度下降、网络稳定性面临严峻挑战。传统的手工汇总方式不仅效率低下…...

OpenAshare:开源AI应用平台的设计理念与实战指南
1. 项目概述:一个开源的AI应用分享与协作平台最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“OpenAshare”。光看名字,你大概能猜到它和“分享”有关,但它的野心远不止于此。这不是一个简单的代码仓库,而…...

ARM AMU寄存器架构与性能监控实战指南
1. ARM AMU寄存器架构解析在ARMv8.4及后续架构中,Activity Monitor Unit(AMU)作为性能监控单元的重要扩展,为开发者提供了更精细化的硬件事件监控能力。与传统的PMU相比,AMU引入了多组专用寄存器,能够在不显…...

罗博特科冲刺港股:年营收9.5亿同比降14% 市值一度超千亿 宁波科骏套现超6亿 高管李伟彬套现1230万
雷递网 雷建平 5月14日罗博特科智能科技股份有限公司(简称:“罗博特科”)日前更新招股书,准备在港交所上市。罗博特科2019年在深交所上市,2020年收购ficonTEC 的少数权益,并开始向硅光领域扩展,…...

陈,嵌入式生物医学电子实验箱 电子创新生物医学试验箱 生物医学工程电子试验箱
由硬件、软件、附件、实验教材四部分组成,模块独立、组合灵活,安徽正华,生物,露硬件覆盖主流模拟与数字电路:模拟电路:集成运放、心电放大、滤波、信号发生等典型电路;数字电路:AVR/…...

【C++】C/C++ 内存管理从入门到进阶
【相关题目】 代码语言:javascript AI代码解释 int globalVar 1;static int staticGlobalVar 1;void Test(){static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";const char* pChar3 "abcd";int*…...
编辑文件,总提示Permission Denied?可能是这个共享文件夹权限问题)
VSCode连接Ubuntu虚拟机(VMware/VirtualBox)编辑文件,总提示Permission Denied?可能是这个共享文件夹权限问题
VSCode连接Ubuntu虚拟机编辑文件时Permission Denied的深度解决方案 跨平台开发已经成为现代开发者的标配工作流,而VSCode配合虚拟机更是常见的开发环境组合。但当你兴致勃勃地在Windows或macOS上通过VSCode连接到Ubuntu虚拟机,准备大展拳脚时࿰…...
)
别再只会按回车了!ChatGPT换行、分段、写代码的3种正确姿势(含移动端技巧)
ChatGPT高效输入指南:从换行技巧到结构化表达的艺术 在数字创作与AI交互的时代,每个按键背后都藏着提升效率的秘密。当大多数人还在用原始的单行输入与ChatGPT对话时,掌握格式化输入技巧的用户已经获得了截然不同的交互体验——他们的代码保持…...

m4s-converter:如何将B站缓存视频无损转换为通用MP4格式?
m4s-converter:如何将B站缓存视频无损转换为通用MP4格式? 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到…...

点云配准算法进化史:从ICP的‘硬匹配’到CT-ICP的‘连续时空’,理解GICP背后的概率模型
点云配准算法进化史:从ICP的刚性匹配到CT-ICP的时空连续性 在三维感知技术领域,点云配准算法的发展犹如一部浓缩的技术进化史。从早期简单的几何匹配到如今融合概率模型与时空连续性的复杂系统,每一次算法迭代都对应着实际应用场景中亟待解决…...