es1.7.2 按照_type先聚合,再按照时间二次聚合
// 设置查询条件if (this.query != null) {this.searchbuilder.setQuery(this.query);}TermsBuilder typeAggregation = AggregationBuilders.terms("agg_type").field("_type");DateHistogramBuilder dateTermsBuilder = AggregationBuilders.dateHistogram("agg_pubtime").field("pubtime");dateTermsBuilder.format("yyyy-MM-dd");dateTermsBuilder.interval(DateHistogram.Interval.days(1));dateTermsBuilder.subAggregation(typeAggregation);searchbuilder.addAggregation(dateTermsBuilder);SearchResponse sr = searchbuilder.execute().actionGet();Map<String, Aggregation> aggMap = sr.getAggregations().asMap();DateHistogram classTerms = (DateHistogram)aggMap.get("agg_pubtime");Iterator<org.elasticsearch.search.aggregations.bucket.histogram.DateHistogram.Bucket> classBucketIt = (Iterator<Bucket>) classTerms.getBuckets().iterator();List<Map<String,Object>> dataList = new ArrayList<Map<String,Object>>();List<String[]> result = new ArrayList();while(classBucketIt.hasNext()){Map<String,Object> res = new HashMap<String, Object>();org.elasticsearch.search.aggregations.bucket.histogram.DateHistogram.Bucket classBucket = classBucketIt.next();//System.out.println("时间"+classBucket.getKey());StringTerms agg_type = (StringTerms) classBucket.getAggregations().asMap().get("agg_type");List<Terms.Bucket> buckets = (List<Terms.Bucket>) agg_type.getBuckets();List<String[]> list = new ArrayList<String[]>();for (Terms.Bucket bucket : buckets) {String[] str = new String[2];str[0] = bucket.getKey().trim();//日期str[1] = String.valueOf(bucket.getDocCount());//数量
// list.add(str);//System.out.println( str[0] +"======" + str[1] );}}参考:gpt
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.histogram.DateHistogramInterval;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.common.unit.TimeValue;import java.io.IOException;
import java.util.concurrent.TimeUnit;public class AggregationExample {public static void main(String[] args) throws IOException {// 创建 Elasticsearch 客户端RestHighLevelClient client = createClient();// 创建聚合请求SearchRequest searchRequest = new SearchRequest("your_index_name");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 设置查询条件searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 设置第一级聚合,按照 _type 字段进行聚合Terms.AggregationBuilder typeAggregation = AggregationBuilders.terms("by_type").field("_type");// 设置第二级聚合,按照时间进行聚合,这里使用日期直方图(Histogram)聚合Terms.BucketOrder termsOrder = Terms.BucketOrder.key(true);typeAggregation.subAggregation(AggregationBuilders.dateHistogram("by_time").field("your_time_field").dateHistogramInterval(DateHistogramInterval.DAY).subAggregation(AggregationBuilders.terms("top_hits").size(10).order(termsOrder)));// 添加聚合请求到搜索源中searchSourceBuilder.aggregation(typeAggregation);// 设置分页和超时时间searchSourceBuilder.size(0);searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));// 发起搜索请求并获取响应searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 解析聚合结果Terms byTypeAggregation = searchResponse.getAggregations().get("by_type");for (Terms.Bucket typeBucket : byTypeAggregation.getBuckets()) {System.out.println("Type: " + typeBucket.getKeyAsString());Terms byTimeAggregation = typeBucket.getAggregations().get("by_time");for (Terms.Bucket timeBucket : byTimeAggregation.getBuckets()) {System.out.println("Time: " + timeBucket.getKeyAsString());Terms topHitsAggregation = timeBucket.getAggregations().get("top_hits");for (Terms.Bucket hitBucket : topHitsAggregation.getBuckets()) {System.out.println("Hit: " + hitBucket.getKeyAsString());}}}// 关闭 Elasticsearch 客户端client.close();}private static RestHighLevelClient createClient() {// 创建和配置 Elasticsearch 客户端RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}
}相关文章:

es1.7.2 按照_type先聚合,再按照时间二次聚合
// 设置查询条件if (this.query ! null) {this.searchbuilder.setQuery(this.query);}TermsBuilder typeAggregation AggregationBuilders.terms("agg_type").field("_type");DateHistogramBuilder dateTermsBuilder AggregationBuilders.dateHistogram(…...

pyqt5 如何修改QplainTextEdit 背景色和主窗口的一样颜色
如果您希望将 QPlainTextEdit 的背景颜色设置为与窗口背景相似的灰色,您可以使用窗口的背景颜色作为基准来设置 QPlainTextEdit 的背景颜色。以下是一个示例代码,展示如何实现这一点: from PyQt5.QtWidgets import QApplication, QMainWindo…...

解决使用element ui时el-input的属性type=number,仍然可以输入e的问题。
使用element ui时el-input的属性typenumber,仍然可以输入e, 其他的中文特殊字符都不可以输入,但是只有e是可以输入的,原因是e也输入作为科学计数法的时候,e是可以被判定为数字的, 但是有些场景是需要把e这种…...

ShardingSphere 可观测 SQL 指标监控
ShardingSphere并不负责如何采集、存储以及展示应用性能监控的相关数据,而是将SQL解析与SQL执行这两块数据分片的最核心的相关信息发送至应用性能监控系统,并交由其处理。 换句话说,ShardingSphere仅负责产生具有价值的数据,并通过…...

Redisson实现分布式锁示例
一、引入依赖 <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.16.0</version></dependency>二、配置类 import org.redisson.Redisson; import org.redisson.api.RedissonClient;…...

使用Nginx作为一个普通代理服务器
使用Nginx作为一个普通代理服务器, 请不要用于违法用途哦 nginx作为一个反向代理工具,除了可以进行反向代理之外,还可以用来作为代理工具来使用,作为代理工具使用的步骤如下,这个配置目前支持80端口 Windows系统代理设置对应IP, …...
chatglm2-6b模型在9n-triton中部署并集成至langchain实践 | 京东云技术团队
一.前言 近期, ChatGLM-6B 的第二代版本ChatGLM2-6B已经正式发布,引入了如下新特性: ①. 基座模型升级,性能更强大,在中文C-Eval榜单中,以51.7分位列第6; ②. 支持8K-32k的上下文;…...

Shell编程之正则表达式(非常详细)
正则表达式 1.通配符和正则表达式的区别2.基本正则表达式2.1 元字符 (字符匹配)2.2 表示匹配次数2.4 位置锚定2.5 分组 和 或者 3.扩展正则表达式4.部分文本处理工具4.1 tr 命令4.2 cut命令4.3 sort命令4.4 uniq命令 1.通配符和正则表达式的区别 通配符一般用于文件…...
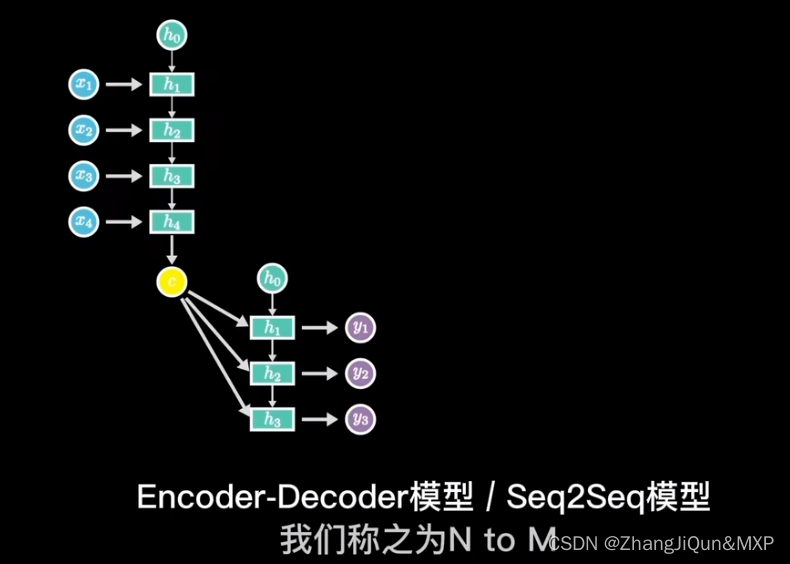
RNN模型简单理解和CNN区别
目录 神经网络:水平方向延伸,数据不具有关联性 RNN:在神经网络的基础上加上了时间顺序,语义理解 RNN: 训练中采用梯度下降,反向传播 长短期记忆模型 输出关系:1 toN,N to N 单入…...
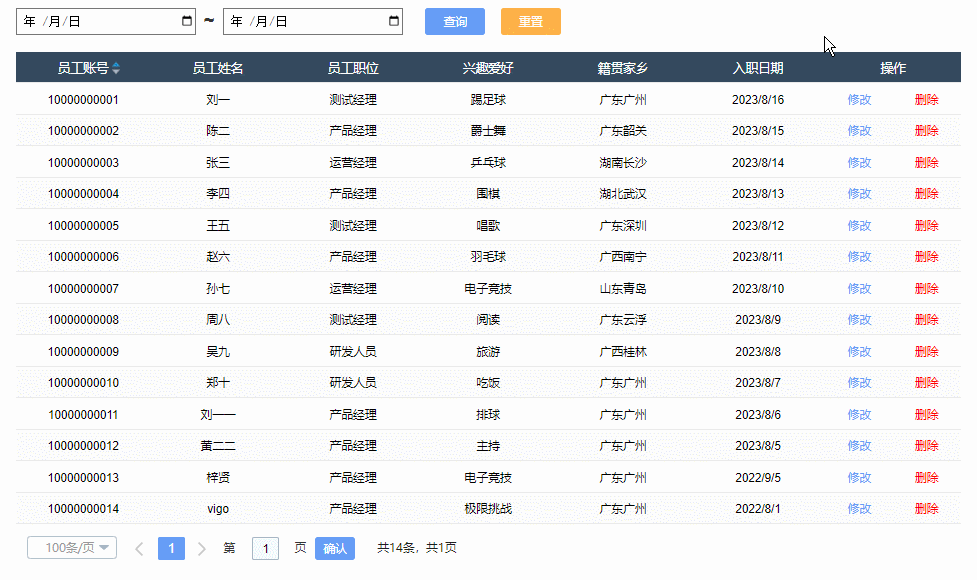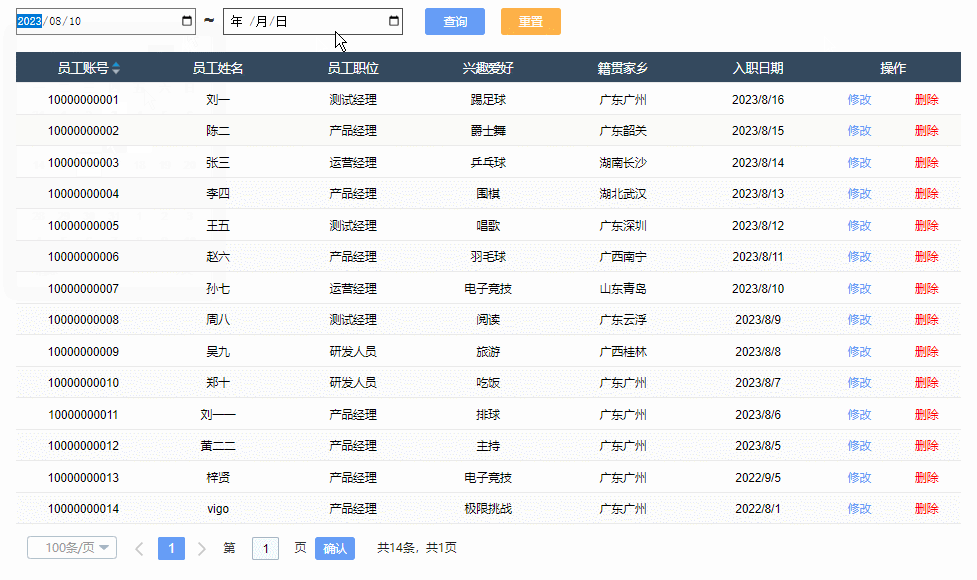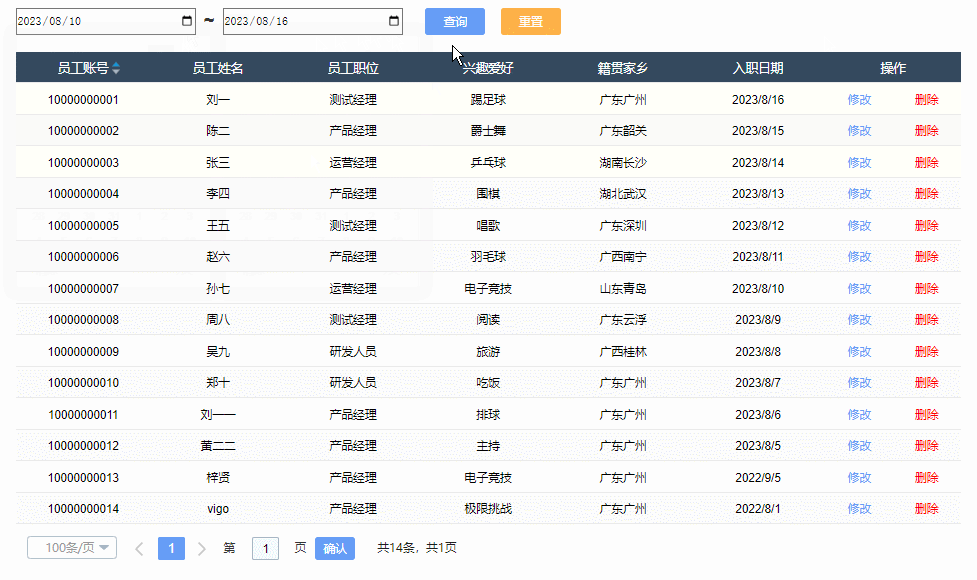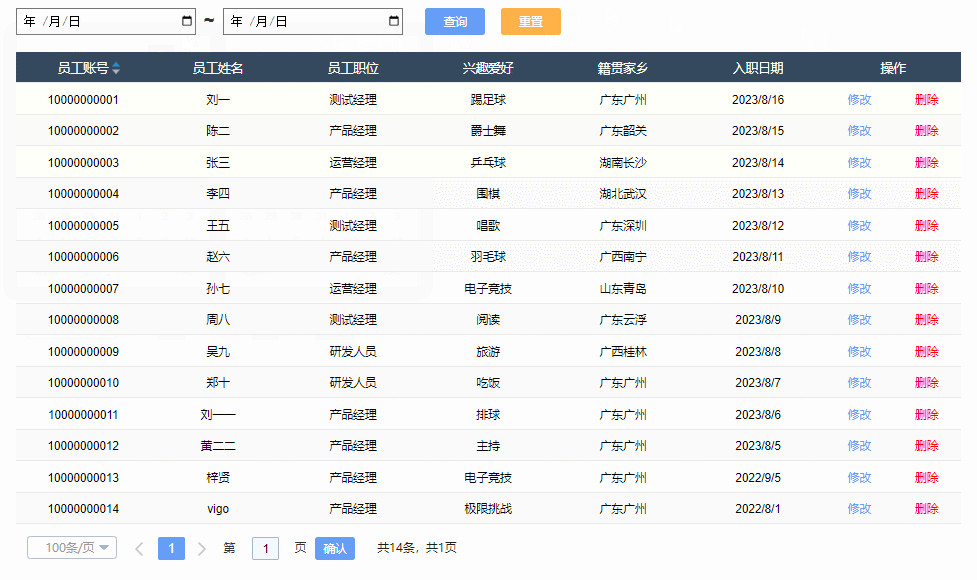
【Axure高保真原型】JS日期选择器筛选中继器表格
今天和大家分享JS日期选择器筛选中继器表格的原型模板,通过调用浏览器的日期选择器,所以可以获取真实的日历效果,具体包括哪一年二月份有29天,几号对应星期几,都是真实的,获取日期值后,通过交互…...

android bp脚本
一。android大约从7.0开始引入 .bp文件代替以前的.mk文件,用于帮助android项目的编译配置文件。 二。mk文件转化为bp文件,可以使用下面命令转化,注意命令中>,这是写入文件。androidmk是android源码自带的工具,他可…...
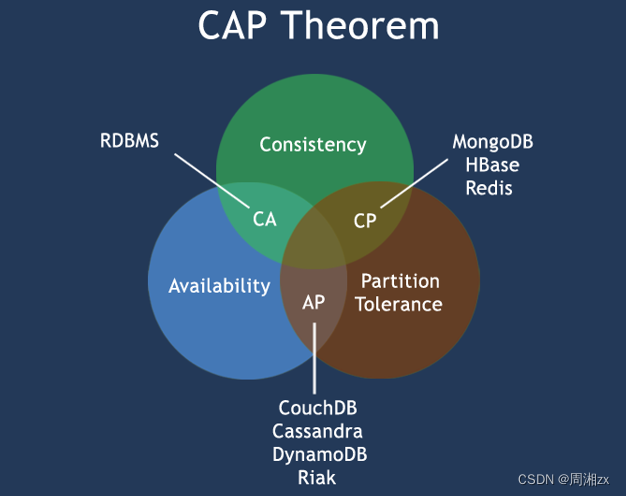
Redis 数据库 NoSQL
目录 一、NoSQL 二、为什么会出现NoSQL技术 三、NoSQL的类别 键值(Key-Value)存储数据库 列存储数据库 文档型数据库 图形(Graph)数据库 四、NoSQL适应场景 五、在分布式数据库中CAP原理 1、CAP 2、BASE 一、NoSQL NoS…...

RN 项目异常问题整理
常见问题 无法找到 CardStackStyleInterpolator StackViewStyleInterpolator 这个方法集来代替 CardStackStyleInterpolator的,这个方法集的路径也需要注意一下,在2.12.1版本之前, 该文件在react-navigation/src/views/StackView/中…...

STM8编程[TIM1多路PWM输出选项字节(Option Byte)操作和IO复用]
TIM1多路PWM输出选项字节(Option Byte)操作和IO复用 本文摘录于:https://blog.csdn.net/freeape/article/details/47008033只是做学习备份之用,绝无抄袭之意,有疑惑请联系本人! 代码上要使用TIME1输出3路PWM,代码如下: void tim…...
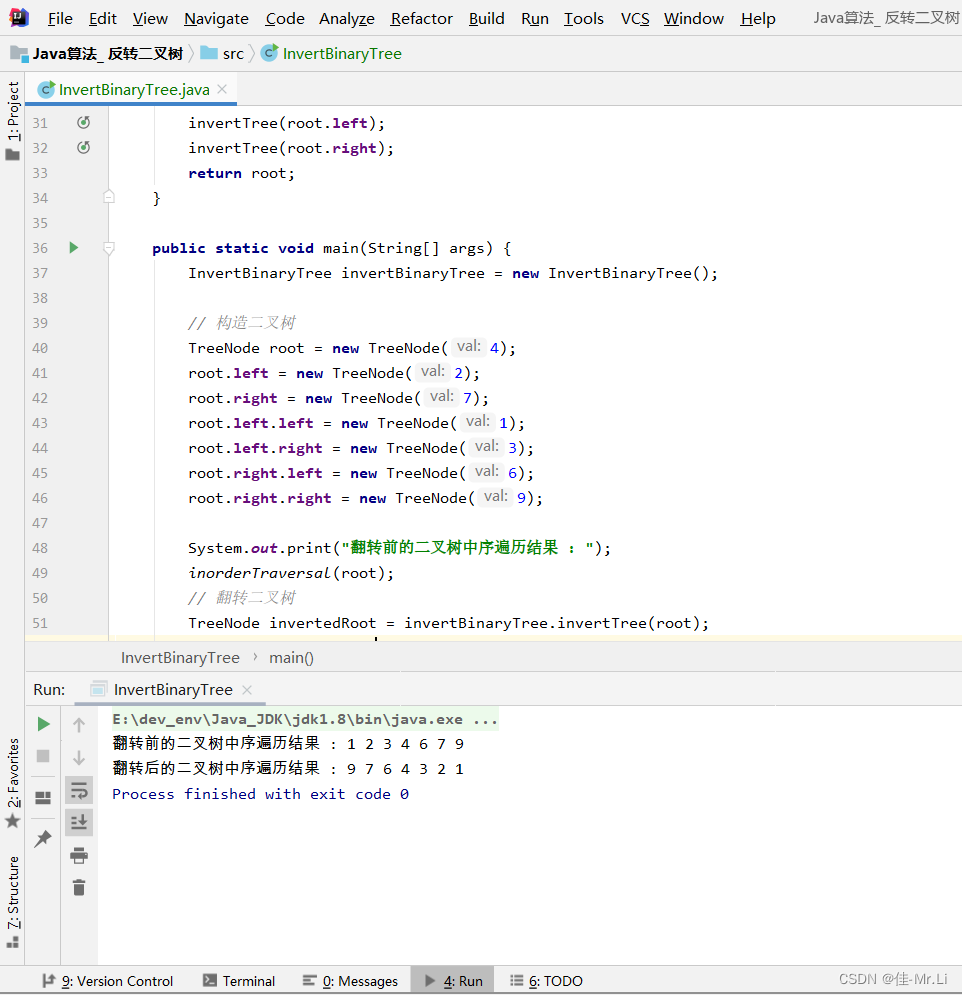
Java算法_ 反转二叉树(LeetCode_Hot100)
题目描述:给你一棵二叉树的根节点 ,翻转这棵二叉树,并返回其根节点。root。 获得更多?算法思路:代码文档,算法解析的私得。 运行效果 完整代码 /*** 2 * Author: LJJ* 3 * Date: 2023/8/16 13:18* 4*/public class In…...
)
C/C++ 标准模版库STL(持续更新版)
标准模版库STL 目录 算法库 栈 队列 向量 映射 列表 双向链表 集合 Iterator 送代器 <algorithm> 算法库 max, min 用于找出一组值中的最大值和最小值 swap 用于交换两个变量的值 sort 用于对一个范围内的元素进行排序 lower_bound, upper_bound 用于在已排序的容器…...
ARM(实验二)
uart4.h #ifndef __H__ #define __H__#include "stm32mp1xx_rcc.h" #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_uart.h"//RCC/GPIO/UART4章节初始化 void hal_uart4_init();//发送一个字符函数 void hal_put_char(const char str);//发…...

由“美”出发 听艺术家林曦关于美育与智慧的探讨
不久前,林曦老师与我们的老朋友「十点读书」进行了一次线上直播,有关林曦老师十余年的书法教学,和传统美育的心得,以及因此诞生的新书《无用之美》。 这一次的直播,由“美”的主题出发,延伸出美育…...

Serial与Parallel GC之间的不同之处是什么?
Serial GC(串行垃圾回收器)和Parallel GC(并行垃圾回收器)都是Java虚拟机(JVM)中用于进行垃圾回收的两种基本算法。它们在性能、资源利用和回收效率等方面存在一些不同之处。下面是它们之间的详细比较: 1.工作方式 Serial GC:它是一种单线程的垃圾回收器…...
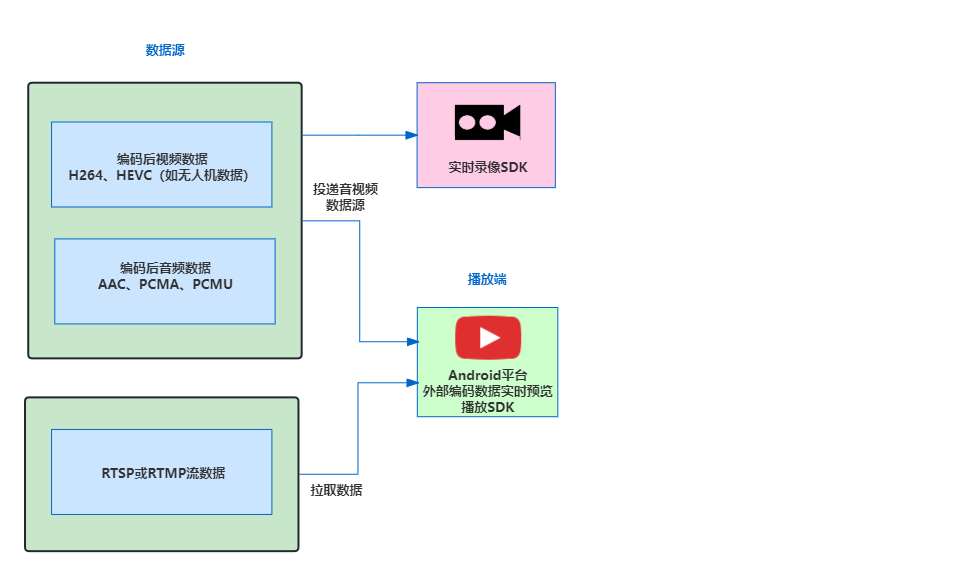
GB28181设备接入侧如何对接外部编码后音视频数据并实现预览播放
技术背景 我们在对接GB28181设备接入模块的时候,遇到这样的技术诉求,好多开发者期望能提供编码后(H.264/H.265、AAC/PCMA)数据对接,确保外部采集设备,比如无人机类似回调过来的数据,直接通过模…...

网安工具系列python系列【仅供参考】:Python实战:利用fofa API高效搜索网络资产
Python实战:利用fofa API高效搜索网络资产 Python实战:利用fofa API高效搜索网络资产 1. 从零开始:为什么你需要一个自动化的资产搜索工具? 2. 动手前的准备:你的fofa账户和Python环境 2.1 获取你的fofa API凭证 2.2 搭建Python脚本环境 3. 核心代码拆解:一行行理解搜索脚…...

AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案
AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

基于LLM的代码仓库智能分析:RepoMap-AI实现架构可视化与认知图谱
1. 项目概述:当AI成为你的代码库“活地图”最近在折腾一个老旧的Java项目,里面模块套模块,依赖关系复杂得像一团乱麻。想找个特定的工具类,得在十几个包里翻来覆去地搜;想理清某个核心服务的调用链路,光靠I…...
到底是什么)
FiveM 新手服主必看:开源与托管(闭源)到底是什么
大家好,我是难言,你们的老朋友了。在 FiveM 生态深耕多年,我发现许多新手服主对开源与托管(闭源)插件的概念认知模糊,甚至无法区分二者的核心差异。更不合理的是,圈内逐渐形成鄙视链,…...

Vivado里写状态机总出警告?聊聊三段式、二段式的选择与那些让人头疼的Latch和Combinatorial Loop
Vivado状态机设计实战:从三段式优化到Latch消除全攻略 状态机设计中的典型痛点与EDA工具特性 第一次在Vivado中看到"Inferring Latch"警告时,我盯着综合报告发了半小时呆——明明代码逻辑完全正确,为什么工具非要"自作主张&qu…...

紫光同创PGL22G开发板DDR3读写实验:从IP核安装到上板验证的保姆级避坑指南
紫光同创PGL22G开发板DDR3读写实验全流程实战解析 第一次接触国产FPGA平台进行DDR3内存控制实验时,很多开发者都会遇到各种"坑"。本文将基于紫光同创PGL22G开发板,从IP核安装到最终上板验证,手把手带你避开那些容易出错的关键环节。…...

预训练+微调实现TVA模型快速部署
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

2026 及下一阶段 工业 AI 与企业级 Agent 布局
JBoltAI 作为面向企业 Java 技术团队的 AI 应用开发框架,围绕 工业 AI 与企业级 Agent 领域的向量空间应用,明确了 2026 年及下一阶段的核心布局方向,聚焦产业实际需求推进技术落地。工业场景的 AI 落地,核心难点并非技术本身&…...

图像边缘检测算法全解析:从Sobel到Canny的实战指南
1. 项目概述:从“看见”到“看懂”的第一步在机器视觉的世界里,让计算机“看见”只是第一步,真正的挑战在于让它“看懂”。而“看懂”一幅图像,往往始于识别其轮廓与边界。这就是“边缘检测”的核心价值所在——它如同视觉系统的“…...

快速开发AI应用原型时Taotoken分钟级接入的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速开发AI应用原型时Taotoken分钟级接入的价值 在黑客松、内部创新日或产品早期原型开发阶段,时间是最宝贵的资源。开…...