同步jenkinsfile流水线(sync-job)
环境
- 变量:env(环境变量:sit/dev/simulation/prod/all),job(job-name/all)
- 目录:/var/lib/jenkins/jenkinsfile
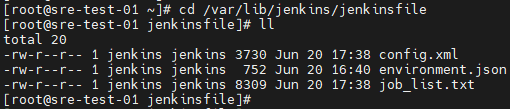
- environment.json:
[root@test-01 jenkinsfile]# cat environment.json | jq .
{"environment": [{"sit": "http://xxxx.xx.xx.com/|test:xxxxxxxxxxxxxxxx","dev": "http://xxxx.xx.xx.com/|test:xxxxxxxxxxxxxxxx","simulation": "http://xxxx.xx.xx.com/|test:xxxxxxxxxxxxxxxx","prod": "http://xxxx.xx.xx.com/|test:xxxxxxxxxxxxxxxx",}]
}
设计思路
- 以sit环境的url和token作为基准baseUrl/baseToken
- 若env=all则表示同步至所有环境
-
- 循环获取env的环境变量,获取url和token
- 若job=all则表示同步所有job
-
-
- 获取当前基准环境下的job_list,循环获取jobname
- 判断当前的job是否有config.xml的文件
-
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
-
- 若job=jobname则同步单个job
- 判断当前的job是否有config.xml的文件
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
- 若env=env则表示同步至单个环境
-
- 获取目标环境的url和token
- 若job=all则表示同步所有job
-
-
- 获取当前基准环境下的job_list,循环获取jobname
- 判断当前的job是否有config.xml的文件
-
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
-
- 若job=jobname则同步单个job
- 判断当前的job是否有config.xml的文件
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
完整代码
pipeline {agent anyoptions {disableConcurrentBuilds()}parameters {string(name: "env", defaultValue: '', description: '')string(name: "job", defaultValue: '', description: '')}stages {stage("Sync job") {steps {script {dir("/var/lib/jenkins/jenkinsfile") {baseUrl = "http://xxx.xx.xx.com/"baseToken = "test:xxxxxxxxxxxxxxxxxxxxxxxxxx"def env = "${params.env}"if ( env == "all" ) {getEnvNumber = "cat environment.json | jq -r .environment[][] | wc -l"def envNumber = sh(script: "$getEnvNumber", returnStdout:true).trim()for ( i=2; i<=jobNumber.toInteger(); i++ ) {getAllUrlCommand = "cat environment.json | jq -r .environment[][] | sed -n $i'p' | awk -F \"|\" '{print\$1}'"getAllTokenCommand = "cat environment.json | jq -r .environment[][] | sed -n $i'p' | awk -F \"|\" '{print\$2}'"def url = sh(script: "$getAllUrlCommand", returnStdout:true).trim()def token = sh(script: "$getAllTokenCommand", returnStdout:true).trim()def job = "${params.job}"if ( job== "all" ) {sh "sudo curl -X GET $baseUrl/api/json?pretty=true -u $baseToken > job_list.txt"getJobNumber = "cat job_list.txt | jq -r .jobs[].name | wc -l"def jobNumber = sh(script: "$getJobNumber", returnStdout:true).trim()for (j=1; j<=jobNumber.toInteger(); j++) {def jobname = sh(script: "cat job_list.txt | jq -r .jobs[].name | sed -n $j'p'", returnStdout:true).trim()sh "sudo curl -X GET $baseUrl/job/$jobname/config.xml -u $baseToken -o config.xml"getCRUMBCommand= "sudo curl -s '$url/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)' -u $token"def CRUMB = sh(script: "$getCRUMBCommand", returnStdout:true).trim()def str = sh(script: "curl -sX GET $url/job/$jobname/config.xml -u $token | sed -n 1p", returnStdout:true).trim()if( str == "<html>") {sh "sudo curl -s -XPOST '$url/createItem?name=$jobname' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}else {sh "sudo curl -s -XPOST '$url/job/$jobname/config.xml' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}}}else {sh "sudo curl -X GET $baseUrl/api/json?pretty=true -u $baseToken > job_list.txt"sh "sudo curl -X GET $baseUrl/job/$job/config.xml -u $baseToken -o config.xml"getCRUMBCommand= "sudo curl -s '$url/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)' -u $token"def CRUMB = sh(script: "$getCRUMBCommand", returnStdout:true).trim()def str = sh(script: "curl -sX GET $url/job/$job/config.xml -u $token | sed -n 1p", returnStdout:true).trim()if( str == "<html>") {sh "sudo curl -s -XPOST '$url/createItem?name=$job' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}else {sh "sudo curl -s -XPOST '$url/job/$job/config.xml' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}}}}else {getUrlCommand = "cat environment.json | jq -r .environment[].$env | awk -F \"|\" '{print\$1}'"getTokenCommand = "cat environment.json | jq -r .environment[].$env | awk -F \"|\" '{print\$2}'"def url = sh(script: "$getUrlCommand", returnStdout:true).trim()def token = sh(script: "$getTokenCommand", returnStdout:true).trim()def job = "${params.job}"if ( job== "all" ) {sh "sudo curl -X GET $baseUrl/api/json?pretty=true -u $baseToken > job_list.txt"getJobNumber = "cat job_list.txt | jq -r .jobs[].name | wc -l"def jobNumber = sh(script: "$getJobNumber", returnStdout:true).trim()for (j=1; j<=jobNumber.toInteger(); j++) {def jobname = sh(script: "cat job_list.txt | jq -r .jobs[].name | sed -n $j'p'", returnStdout:true).trim()sh "sudo curl -X GET $baseUrl/job/$jobname/config.xml -u $baseToken -o config.xml"getCRUMBCommand= "sudo curl -s '$url/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)' -u $token"def CRUMB = sh(script: "$getCRUMBCommand", returnStdout:true).trim()def str = sh(script: "curl -sX GET $url/job/$jobname/config.xml -u $token | sed -n 1p", returnStdout:true).trim()if( str == "<html>") {sh "sudo curl -s -XPOST '$url/createItem?name=$jobname' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}else {sh "sudo curl -s -XPOST '$url/job/$jobname/config.xml' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}}}else {sh "sudo curl -X GET $baseUrl/api/json?pretty=true -u $baseToken > job_list.txt"sh "sudo curl -X GET $baseUrl/job/$job/config.xml -u $baseToken -o config.xml"getCRUMBCommand= "sudo curl -s '$url/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)' -u $token"def CRUMB = sh(script: "$getCRUMBCommand", returnStdout:true).trim()def str = sh(script: "curl -sX GET $url/job/$job/config.xml -u $token | sed -n 1p", returnStdout:true).trim()if( str == "<html>") {sh "sudo curl -s -XPOST '$url/createItem?name=$job' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}else {sh "sudo curl -s -XPOST '$url/job/$job/config.xml' -u $token --data-binary @config.xml -H \"$CRUMB\" -H \"Content-Type:text/xml\""}}}}}}}}
}ide思路:
每个环境不同
- 进入code目录中,进入jenkins-pipeline/目录
- ls -l获取目录下所有的子目录及文件,count所有子目录及文件的数量
- for循环整个Jenkins-pipeline下的子目录和文件
-
- 获取子目录或文件的name
- 判断是否为目录
-
-
- 若为目录则cd $name
-
-
-
-
- ls -l获取目录下的所有文件,dircount所有文件的数量
-
-
-
-
-
-
- for循环整个name下的所有文件
-
-
-
-
-
-
-
-
- 获取jobname
- 获取jobname所对应job的config.xml文件
- 判断当前的job是否有config.xml的文件
-
-
-
-
-
-
-
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
-
-
-
-
-
- 若为文件则
-
-
-
-
- 获取jobname
- 获取jobname所对应job的config.xml文件
- 判断当前的job是否有config.xml的文件
-
-
-
-
-
-
- 若第一行=<html>则无xml文件,在目标环境创建job
- 若存在xml文件,则更新job
-
-
-
相关文章:
同步jenkinsfile流水线(sync-job)
环境 变量:env(环境变量:sit/dev/simulation/prod/all),job(job-name/all)目录:/var/lib/jenkins/jenkinsfile environment.json: [roottest-01 jenkinsfile]# cat env…...

STM32单片机WIFI-APP智能温室大棚系统CO2土壤湿度空气温湿度补光
实践制作DIY- GC0161--智能温室大棚系统 基于STM32单片机设计---智能温室大棚系统 二、功能介绍: 电路组成:STM32F103CXT6最小系统LCD1602显示器DHT11空气温度湿度光敏电阻光强土壤湿度传感器SGP30二氧化碳传感器 1个继电器(空气加湿&#x…...
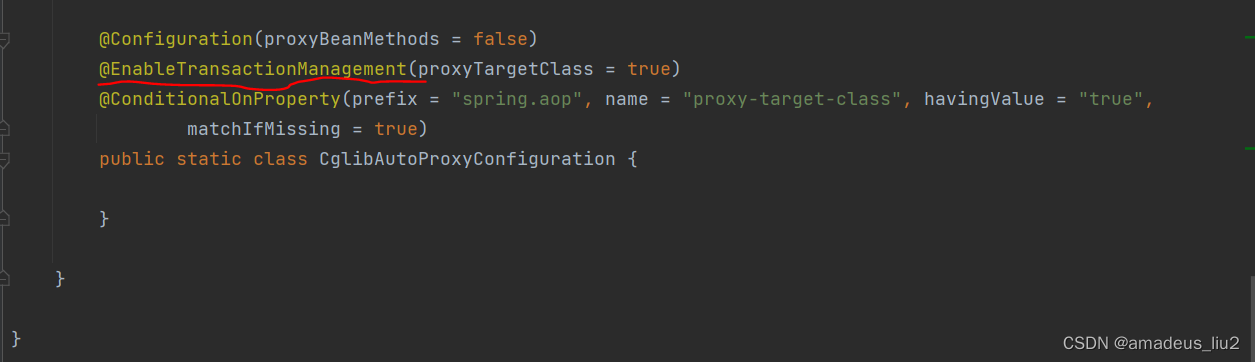
SpringBoot复习:(52)不再需要使用@EnableTransactionManagement的原因
在Spring项目中,要用事务,需要EnableTransactionManagement注解加Transactional注解。而在SpringBoot项目,有事务的自动配置类TransactionAutoConfiguration,代码如下: 可以在其内部类EnableTransactionManagementConfiguratio…...
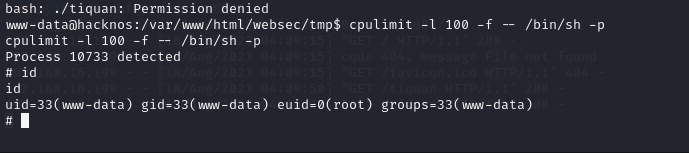
HackNos 3靶场
配置 进入控制面板配置网卡 第一步:启动靶机时按下 shift 键, 进入以下界面 第二步:选择第二个选项,然后按下 e 键,进入编辑界面 将这里的ro修改为rw single init/bin/bash,然后按ctrlx,进入…...

【办公自动化】使用Python批量生成PPT版荣誉证书
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

【C++深入浅出】初识C++中篇(引用、内联函数)
目录 一. 前言 二. 引用 2.1 引用的概念 2.2 引用的使用 2.3 引用的特性 2.4 常引用 2.5 引用的使用场景 2.6 传值、传引用效率比较 2.7 引用和指针的区别 三. 内联函数 3.1 内联函数的概念 3.2 内联函数的特性 一. 前言 上期说道,C是在C的基础之上&…...
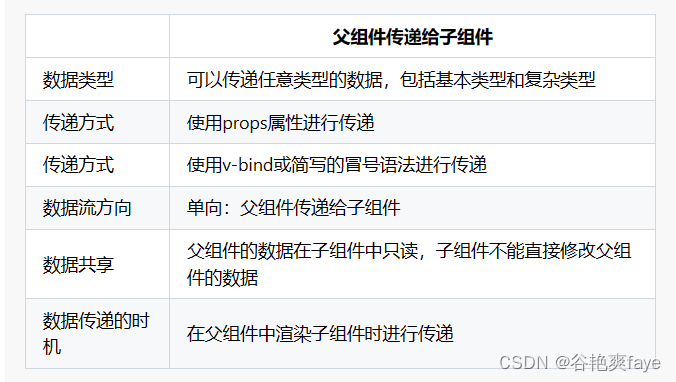
前端:VUE2中的父子传值
文章目录 一、背景什么是父子传值二、业务场景子传父1、在父页面中引入子页面2、子传父:父组件标识3、子传父:子组件标识 父传子父组件调用子组件中的方法 总结: 一、背景 最近做项目中需要使用到流工作,在这里流工作需要用到父子…...
_网络编程与打包发布)
【100天精通python】Day40:GUI界面编程_PyQt 从入门到实战(完)_网络编程与打包发布
目录 8 网络编程 8.1 使用PyQt 网络模块进行网络通信 服务器端示例 客户端示例 8.2 处理网络请求和响应 9 打包和发布 9.1 创建可执行文件或安装程序 9.2 解决依赖问题 9.3 发布 PyQt 应用到不同平台 9.3.1 发布到 Windows 9.3.2 发布到 macOS 9.3.3 发布到 Linux 9…...

Redis——set类型详解
概要 Set(集合),将一些有关联的数据放到一起,集合中的元素是无序的,并且集合中的元素是不能重复的 之前介绍的list就是有序的,对于列表来说[1, 2, 3] 和 [2, 1, 3]是两个不同的列表,而对于集合…...

redis---》高级用法之慢查询/pipline与事务/发布订阅/bitmap位图/HyperLogLog/GEO地理位置信息/持久化
高级用法之慢查询 # 配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询 # 配置的慢查询,只在命令执行阶段# 慢查询演示-设置慢查询---》只要超过某个时间的命令---》都会保存起来# 设置记录所有命令CONFIG SET slowl…...

Find My资讯|苹果Vision Pro开发者需将设备配对 AirTag
最近苹果Vision Pro获开发者申请,苹果要求获批的申请者使用 Measure and Fit 应用确认合适的佩戴尺寸,并会根据申请者提交的信息,定制不同的 Vision Pro 开发者套件,以便于契合申请者的面部特征,提供更好的佩戴体验。 …...

Go 语言中排序的 3 种方法
原文链接: Go 语言中排序的 3 种方法 在写代码过程中,排序是经常会遇到的需求,本文会介绍三种常用的方法。 废话不多说,下面正文开始。 使用标准库 根据场景直接使用标准库中的方法,比如: sort.Intsso…...

12----Emoji表情
本节我们主要讲解markdown的Emoji 在 Markdown 里使用 Emoji 表情有两种方法:一种是直接输入 Emoji 表情,另一种是使用 Emoji 表情短码(emoji shartcodes)。 一、打印方式: 直接输入 Emoji 表情:在 Markdown 中,可以直接输入 Em…...

C++四种强制类型转换
一、C强制转换与C强制转换 c语言强制类型转换主要用于基础的数据类型间的转换,语法为: (type-id)expression//转换格式1 type-id(expression)//转换格式2c除了能使用c语言的强制类型转换外,还新增了四种强制类型转换:static_cas…...

git仓库新建上传记录
新建git仓会出现版本分支问题,解决过程: 其他的前期绑定之类的传送:https://blog.csdn.net/qq_37194189/article/details/130767397 大概思路:新建一个分支,上传,合并,删除分支 git branch …...

flutter调用so
lutter是一种基于Dart语言的跨平台开发框架,通常用于开发Android和iOS应用程序。如果您想要在Flutter应用程序中调用一个SO库,您可以按照以下步骤进行操作: 首先,将您的SO库文件复制到Flutter项目的“lib”目录下。 接下来&…...

c#依赖注入
依赖注入(Dependency Injection,简称 DI)是一种设计模式,用于将对象的创建和管理责任从使用它的类中分离出来,从而实现松耦合和易于测试的代码。在 C# 中,依赖注入通常通过以下方式实现: 构造函数注入(Constructor Injection): 这是最常见的依赖注入方式,通过类的构…...

Django框架使用定时器-APScheduler实现定时任务:django实现简单的定时任务
一、系统环境依赖 系统:windows10 python: python3.9.0 djnago3.2.0 APScheduler3.10.1 二、django项目配置 1、创建utils包,在包里面创建schedulers包 utils/schedulers/task.py #1、设置 Django 环境,就可以导入项目的模型类这些了 …...

Go学习笔记之数据类型
文章目录 GO数据类型数组array切片slice集合map结构体make和new GO数据类型 在go语言中,定义的全局数据结构不使用不会报错,定义的局部数据结构必须使用,否则报错;建议定义的数据类型就要使用,要么不定义。 数组array …...

Spring Cloud 微服务
前言 Spring Cloud 中的所有子项目都依赖Spring Boot框架,所以Spring Boot 框架的版本号和Spring CLoud的版本号之间也存在以来及兼容关系。 Spring Cloud生态下的服务治理的解决方案主要有两个: Spring Cloud Netfix 和 Spring Cloud Alibaba。这两个…...

Win11Debloat:如何用5分钟让Windows 11回归纯净本质?
Win11Debloat:如何用5分钟让Windows 11回归纯净本质? 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declut…...

避坑指南:STM32驱动DHT11温湿度传感器,为什么你的读数总是不准?
STM32驱动DHT11温湿度传感器的五大实战避坑指南 1. 单总线时序的精确控制 DHT11作为典型的单总线设备,对时序控制的要求极为严苛。许多开发者遇到的第一个坑就是未能准确实现协议要求的时序。根据实测数据,DHT11的启动信号需要主机拉低至少18msÿ…...

Golang怎么实现HTTP请求取消_Golang如何用context取消正在进行的HTTP请求【实战】
HTTP客户端默认不取消请求是设计选择,需显式通过context.Context传递取消信号;必须用NewRequestWithContext、禁用Client.Timeout、确保Transport组件响应同一ctx。为什么 http.Client 默认不取消请求?Go 的 http.Client 本身不自动响应外部中…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...

抖音无水印视频批量下载终极指南:三步搞定海量内容采集
抖音无水印视频批量下载终极指南:三步搞定海量内容采集 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

实战解析:如何通过显卡频率优化解决CUDA/TensorRT推理速度骤降问题
1. 从异常现象到问题定位 最近在部署一个基于YOLOv5的工业检测系统时,遇到了一个让人头疼的问题:当系统从连续检测模式切换到条件触发模式后,原本飞快的CUDA推理速度突然下降了近5倍。更诡异的是,降低相机帧率后,推理…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...