AI 媒人:为什么图形神经网络比 MLP 更好?
一、说明
现在,为什么这些GNN如此重要,你问?好吧,在现实生活中,一切似乎都是相互关联的。我们谈论的是社交网络、万维网、粒子网络,甚至是分子⚛的同构舞蹈(问沃尔特怀特)。这是一个令人难以置信的启示:即使是文本、图像和表格格式等“直截了当”的数据结构也可以被赋予一个疯狂的扭曲,以表示为图形! 🧲这就像把你无聊的贪睡数据派对变成尤里卡时刻!相信我,可能性是无穷无尽的。
但是等等,是什么让这些新人从人工智能人群中脱颖而出?嗯,他们就像卷积和顺序机器学习(ML)模型的酷表亲。他们的架构灵感来自这个词,所以他们把自己扭曲成一个漏斗蛋糕(如果漏斗蛋糕是数据结构),只是为了解码错综复杂的关系并解决连夏洛克🕵都羡慕的问题。flexible
二、内容
在本文中,我们将讨论图形数据结构和基于图形的 ML 架构的基础知识。详细的解释超出了这项工作的范围,我尽可能提供了有用的链接。此外,我们将使用PyTorch Geometric(PyG)(我们的超人斗篷)构建一些模型,并遵循以下路线图:
- 图数据集的低谷并介绍类行星数据集。此外,我们将在此处定义我们的 ML 问题陈述。
- 凭空打开GNN架构和一些聪明的公式。
- 不,我们不是逃课!因此,需要介绍带有定制 Python 类的 PyTorch 模型。
- 接下来,我们训练模型并测试我们的创作。我们的GNN将与数据集战斗的终极对决。
- 总结一下事情和关键要点。
系好安全带,这将是一次图形品尝之旅!🚀📊
一个好吧,让我们谈谈图形数据集——一个数字游乐场,数据点在这里闲逛,分享故事,有时甚至是八卦。把它们想象成你在聚会上发现的那些相互关联的社交圈,但你不是人,而是节点,信息通过边缘在他们之间共享。现在,节点和边缘不仅仅是站着向上展示它们的虚拟拇指👍 👎。他们是节目的主角⭐,每个人都有自己的一套功能和属性。
但是等等,我们不会从头开始编织整个事情。不,我们没有那么雄心勃勃。让我们欢迎来自 PyTorch Geometric 的 Planetoid 软件包来拯救我们并减少样板文件。它就像构建梦想图而不费吹灰之力的蓝图。乐高积木,供研究人员控制图形的大小、连接和执行数据拆分。
CORA,来自论文“用图嵌入重访半监督学习”的经典基准引文网络数据集。在这个数据集中,每篇研究论文都是一个节点,边缘呢?啊,它们就像一条看不见的线,通过引文📚🤓连接论文
现在,这些纸上的客人中的每一个都带着礼物来了——具体来说,就是一袋代表其内容的文字。这是一场词汇盛宴,每个节点特征向量从总共 1 个选项中揭示特定单词的存在 (0) 或不存在 (1433)。让我告诉你,这些报纸是尖峰食客;他们只关心某些词。
在科学领域,Cora 是评估节点分类和链路预测等任务中的 GNN 和其他方法的首选。请记住,在这个派对中,引文()是最终的破冰船!➡️edges

科拉数据集的输出
科拉的喜悦
x=[2708, 1433]是节点特征矩阵。想象一下:有 2708 个文档,每个文档都用一个 1433 维的特征向量表示,全部是 one-hot 编码的。edge_index=[2, 10556]表示图形连通性。这告诉谁和谁一起出去玩,形状为(2,定向边缘的数量)。📩y=[2708]是真实标签。每个节点都被分配到一个类,没有尴尬的时刻——“那么,你研究什么?😆train_mask[2708]、 是可选属性,可帮助将数据集分别拆分为训练集、验证集和测试集。其中存在的布尔值断言正确的节点在正确的位置混合。val_mask[2708]test_mask[2708]
让我们停下来思考一下。使用1433个单词的特征向量,人们可以轻松地在MLP模型👷上进行一些好的老式节点/文档分类。但是,嘿,我们不是满足于普通🔎的人.我们将越过边缘,一头扎进这些关系,🤾以增强我们的预测。因此,让我们在这里认真地相互联系!🤝
edge_index
# Let us talk more about edge index/graph connectivity
print(f"Shape of graph connectivity: {cora[0].edge_index.shape}")
print(cora[0].edge_index)
Cora 数据集的边缘索引
这很有趣,因为它包含两个列表,第一个列表低声说源节点 ID,而第二个列表将 bean 溢出到它们的目的地。此设置有一个奇特的名字:坐标列表 (COO)。这是一种高效存储稀疏矩阵的漂亮方法,例如当您的节点与房间中的每个人都不完全聊天时。edge_index
现在,我知道你在想什么。为什么不使用简单的邻接矩阵?好吧,在图数据领域,并非每个节点都是社交蝴蝶。那些邻接矩阵?他们将在零的海洋中游泳,这不是最节省内存的设置。这就是为什么首席运营官是我们的首选方法🧩,而 PyG 确保边缘本质上是定向的。
# The adjacency matrix can be inferred from the edge_index with a utility function.adj_matrix = torch_geometric.utils.to_dense_adj(cora[0].edge_index)[0].numpy().astype(int)
print(f'Shape: {adj_matrix.shape}\nAdjacency matrix: \n{adj_matrix}')# Some more PyG utility functions
print(f"Directed: {cora[0].is_directed()}")
print(f"Isolated Nodes: {cora[0].has_isolated_nodes()}")
print(f"Has Self Loops: {cora[0].has_self_loops()}")
该对象具有许多壮观的实用程序函数,让我们通过三个示例先睹为快:Data
is_directed告诉图是否是有向的,即邻接矩阵不是对称的。has_isolated_edges嗅出那些孤独的节点,与熙熙攘攘的人群脱节。这些脱节的灵魂就像没有完整画面的拼图,使下游的ML任务成为真正的挠头问题。has_self_loops通知节点是否与自身❣处于关系中
让我们简要谈谈可视化。将 PyG 对象转换为 图形对象并绘制它们就像小菜一碟。但是,抓住你的马!我们的客人列表(节点数量)超过 2k 长,因此尝试可视化它就像将足球场挤进您的客厅一样。是的,你不想要那个⛔.所以,虽然我们不参与情节派对,但只要知道这张图已经准备好并准备好进行一些严肃的网络行动,即使这一切都发生在幕后。 🌐🕵️ ♀️
DataNetworkX
C伊特西尔是来自普拉特诺伊德家族的科拉的学术🎓兄弟姐妹。它站在舞台上,有3,327篇科学论文,每个节点正好具有6个精英类别(类标签)中的一个。现在,让我们谈谈数据统计,其中 CiteSeer 宇宙中的每个论文/节点都由一个具有 3703/0 值的 1 维词向量定义。渴望了解更多详情?你可以更深入地挖掘兔子洞🐇
citeseer = load_planetoid(name=<span style="color:#c41a16">'CiteSeer' 
引用Seer引文网络统计
print(f"Directed: {citeseer[0].is_directed()}")
print(f"Isolated Nodes: {citeseer[0].has_isolated_nodes()}")
print(f"Has Self Loops: {citeseer[0].has_self_loops()}")
随着引文网络数据二人组已经登上舞台,我们在学术传奇中略有转折。CiteSeer 数据集并不全是阳光;它有孤立的节点(记住我们的孤独者❓)。现在,对于游戏中的这些家伙来说,分类任务将有点困难。
这里有一个问题:这些孤立的节点对GNN的聚合(我们稍后会讨论它)魔术构成了挑战。我们仅限于对这些孤立的节点使用特征向量表示,多层感知器(MLP)模型就是这样做的。
缺少邻接矩阵信息可能会降低准确性。虽然我们无法做太多事情来解决这个问题,但我们将尽最大努力阐明它们的影响 无连接 📚🔍 .
# Node degree distributionnode_degrees = torch_geometric.utils.degree(citeseer.edge_index[0]).numpy()
node_degrees = Counter(node_degrees) # convertt to a dictionary object# Bar plot
fig, ax = plt.subplots(figsize=(18, 6))
ax.set_xlabel('Node degree')
ax.set_ylabel('Number of nodes')
ax.set_title('CiteSeer - Node Degree Distribution')
plt.bar(node_degrees.keys(),node_degrees.values(),color='#0A047A')
CiteSeer 具有大多数节点,具有 1 或 2 个邻居。现在你可能会想,“有什么大不了的?好吧,让我告诉你,这就像只和几个朋友一起举办派对——很舒适,但没有狂欢。关于他们与社区联系的全球信息将缺乏。与Cora相比,这可能是GNN的另一个挑战。
三、问题定义
我们的使命现在非常明确:有了每个节点的节点特征表示及其与相邻节点的连接,我们正在寻求预测给定图形中每个节点的正确类标签。
注意:我们不仅依赖于表层节点特征矩阵,而且深入研究数据结构,分析每个交互,并破译每个耳语。它更多的是关于理解数据集,而不是基于模式进行简单的原始预测。
四、解开图神经网络
我们即将揭开GNN背后的魔力。它们将节点、边或图形表示为数值向量,以便每个节点与其传出边共振。但是GNN背后的秘密武器是什么?抢走聚光灯的技术:“消息传递、聚合和更新”操作经常应用。一个类比可以举办一个邻里街区派对,每个节点与邻居聚合信息,转换和更新自己,然后与其他人群分享其更新的见解。这是关于迭代更新它们的特征向量,为它们注入来自n-hop邻居的本地化智慧。 看看这个宝石:GNN介绍,它清楚地解释了每个概念。
GNN 由层组成,每层扩展其跃点以访问来自邻居的信息。例如,一个节点有 2 层的 GNN 将考虑距离来收集见解并更新其表示。请记住,知识世界只需点击🖱一下即可,只要您准备好,互联网就准备好成为您的向导。这项工作的范围不是在这里的一个博客中解释它们,而是让我们亲自动手编码⌨ 💻。friend-of-firend
五、基本GNN
我们正在创建一个基类,为我们的实际GNN模型奠定基础。它是训练、评估和统计方法的工具箱。这里没有代码重复!
我们还设置了私有方法来初始化与动画相关的统计信息。基类稍后将由 GCN 和 GAT 模型继承,以轻松利用共享功能。轻松的效率触手可及🛠️📊🏗️。
# Base GNN Moduleclass BaseGNN(torch.nn.Module):"""Base class for Graph Neural Network models."""def __init__(self,):super().__init__()torch.manual_seed(48)# Initialize lists to store animation-related statisticsself._init_animate_stats()self.optimizer = Nonedef _init_animate_stats(self) -> None:"""Initialize animation-related statistics."""self.embeddings = []self.losses = []self.train_accuracies = []self.val_accuracies = []self.predictions = []def _update_animate_stats(self,embedding: torch.Tensor,loss: torch.Tensor,train_accuracy: float,val_accuracy: float,prediction: torch.Tensor,) -> None:# Update animation-related statistics with new dataself.embeddings.append(embedding)self.losses.append(loss)self.train_accuracies.append(train_accuracy)self.val_accuracies.append(val_accuracy)self.predictions.append(prediction)def accuracy(self, pred_y: torch.Tensor, y: torch.Tensor) -> float:"""Calculate accuracy between predicted and true labels.:param pred (torch.Tensor): Predicted labels.:param y (torch.Tensor): True labels.:returns: Accuracy value."""return ((pred_y == y).sum() / len(y)).item()def fit(self, data: Data, epochs: int) -> None:"""Train the GNN model on the provided data.:param data: The dataset to use for training.:param epochs: Number of training epochs."""# Use CrossEntropyLoss as the criterion for trainingcriterion = torch.nn.CrossEntropyLoss()optimizer = self.optimizerself.train()for epoch in range(epochs + 1):# Trainingoptimizer.zero_grad()_, out = self(data.x, data.edge_index)loss = criterion(out[data.train_mask], data.y[data.train_mask])acc = self.accuracy(out[data.train_mask].argmax(dim=1), data.y[data.train_mask])loss.backward()optimizer.step()# Validationval_loss = criterion(out[data.val_mask], data.y[data.val_mask])val_acc = self.accuracy(out[data.val_mask].argmax(dim=1), data.y[data.val_mask])kwargs = {"embedding": out.detach().cpu().numpy(),"loss": loss.detach().cpu().numpy(),"train_accuracy": acc,"val_accuracy": val_acc,"prediction": out.argmax(dim=1).detach().cpu().numpy(),}# Update animation-related statisticsself._update_animate_stats(**kwargs)# Print metrics every 10 epochsif epoch % 25 == 0:print(f"Epoch {epoch:>3} | Train Loss: {loss:.3f} | Train Acc: "f"{acc * 100:>6.2f}% | Val Loss: {val_loss:.2f} | "f"Val Acc: {val_acc * 100:.2f}%")@torch.no_grad()def test(self, data: Data) -> float:"""Evaluate the model on the test set and return the accuracy score.:param data: The dataset to use for testing.:return: Test accuracy."""# Set the model to evaluation modeself.eval()_, out = self(data.x, data.edge_index)acc = self.accuracy(out.argmax(dim=1)[data.test_mask], data.y[data.test_mask])return acc六、多层感知器网络
香草多层感知器网络来了!从理论上讲,我们可以通过查看文档/节点的特征来预测其类别。不需要关系信息 - 只需要旧的词袋表示。为了验证该假设,我们定义了一个简单的 2 层 MLP,它仅适用于输入节点特征。
七、图卷积网络
卷积神经网络 (CNN) 凭借其巧妙的参数共享技巧和有效提取潜在特征的能力,在 ML 领域掀起了一场风暴。但图像不也是图表吗?困惑!让我们将每个像素视为一个节点,将 RGB 值视为节点特征。那么一个问题就出现了:这些CNN的技巧能否在不规则图形领域实现?
这并不像复制粘贴那么简单。图形有自己的怪癖:
* **缺乏一致性**:灵活性很好,但它带来了一些混乱。想想具有相同公式但结构不同的分子。图表可能会像这样棘手。
* **节点顺序之谜**:图形没有固定的顺序,不像文本或图像。节点就像聚会上的客人——没有固定的位置。算法需要对这种缺乏节点层次结构的态度保持冷静🕳。
* **扩展问题**:图形可能会变大。想象一下拥有数十亿用户和数万亿条边缘的社交网络。以这种规模运营不是在公园里散步。拆分和组合图形是一个难题,传统的沐浴(操作)不能直接转移。
我们通过扩展 BaseGNN 类(面向对象编程中的常见做法,以确保继承)来组合一个 GCN。构造函数设置输入、隐藏和输出维度,以调整我们网络的步骤。我们正在对参数更新的优化器进行亚当化。正向方法采用节点特征和图连通性 (edge_index),执行图卷积,这些卷积是节点的舞蹈例程,灵感来自它们的邻居。ReLU激活给了它一个刺激,导致最后一幕:log_softmax类概率的函数。
class GCN(BaseGNN):"""Graph Convolutional Network model for node classification."""def __init__(self, input_dim: int, hidden_dim: int, output_dim: int):super().__init__()self.gcn1 = GCNConv(input_dim, hidden_dim)self.gcn2 = GCNConv(hidden_dim, output_dim)self.optimizer = torch.optim.Adam(self.parameters(), lr=0.01, weight_decay=5e-4)def forward(self, x: torch.Tensor, edge_index: torch.Tensor) -> torch.Tensor:"""Forward pass of the Graph Convolutional Network model.:param (torch.Tensor): Input feature tensor.:param (torch.Tensor): Graph connectivity information:returns torch.Tensor: Output tensor."""h = F.dropout(x, p=0.5, training=self.training)h = self.gcn1(h, edge_index).relu()h = F.dropout(h, p=0.5, training=self.training)h = self.gcn2(h, edge_index)return h, F.log_softmax(h, dim=1)class GAT(BaseGNN):def __init__(self, input_dim: int, hidden_dim: int, output_dim: int,heads: int=8):super().__init__()torch.manual_seed(48)self.gcn1 = GATConv(input_dim, hidden_dim, heads=heads)self.gcn2 = GATConv(hidden_dim * heads, output_dim, heads=1)self.optimizer = torch.optim.Adam(self.parameters(), lr=0.01, weight_decay=5e-4)def forward(self, x: torch.Tensor, edge_index: torch.Tensor) -> torch.Tensor:"""Forward pass of the Graph Convolutional Network model.:param (torch.Tensor): Input feature tensor.:param (torch.Tensor): Graph connectivity information:returns torch.Tensor: Output tensor."""h = F.dropout(x, p=0.6, training=self.training)h = self.gcn1(h, edge_index).relu()h = F.dropout(h, p=0.6, training=self.training)h = self.gcn2(h, edge_index).relu()return h, F.log_softmax(h, dim=1)
八、模型训练
让我们看看图中节点的潜在表示如何随着时间的推移而演变,因为模型正在接受节点分类任务的训练。
num_epochs = 200
def train_and_test_model(model, data: Data, num_epochs: int) -> tuple:"""Train and test a given model on the provided data.:param model: The PyTorch model to train and test.:param data: The dataset to use for training and testing.:param num_epochs: Number of training epochs.:return: A tuple containing the trained model and the test accuracy."""model.fit(data, num_epochs)test_acc = model.test(data)return model, test_accmlp = MLP(input_dim=cora.num_features,hidden_dim=16,out_dim=cora.num_classes,
)
print(f"{mlp}\n", f"-"*88)
mlp, test_acc_mlp = train_and_test_model(mlp, data, num_epochs)
print(f"-"*88)
print(f"\nTest accuracy: {test_acc_mlp * 100:.2f}%\n")
MLP 训练循环和性能
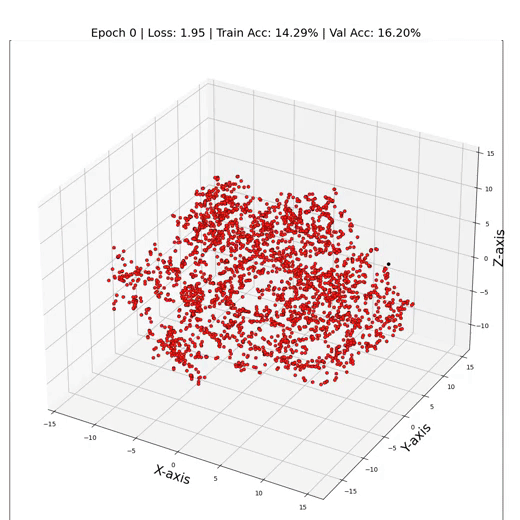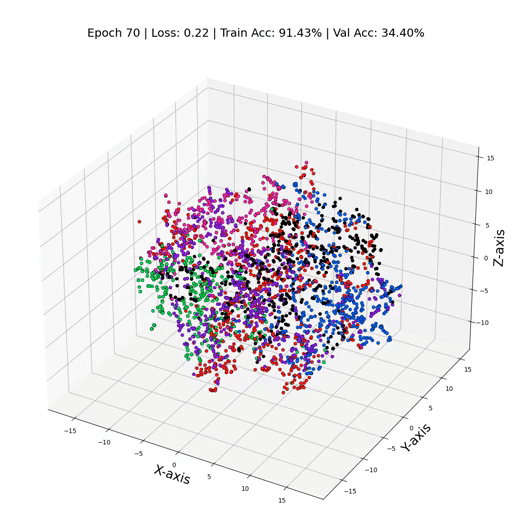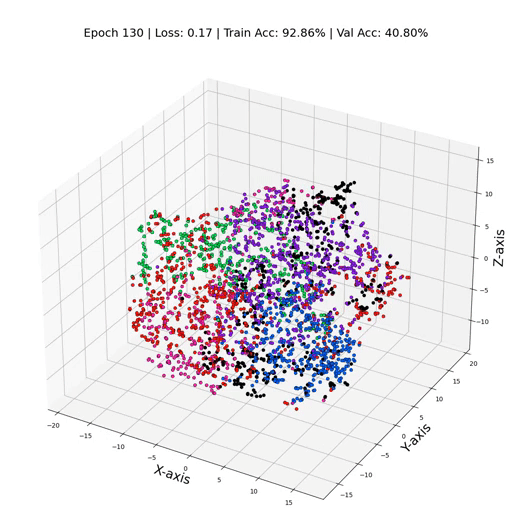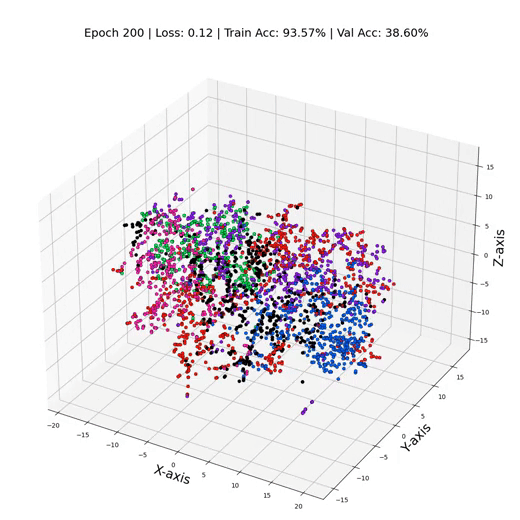
MLP 训练期间的三维节点表示
正如人们所看到的,我们的MLP似乎在聚光灯下挣扎,只有大约55%的测试准确率。但是为什么MLP的表现没有更好呢?罪魁祸首就是过度拟合——模型对训练数据变得过于舒适,在面对新的节点表示时毫无头绪。这就像闭着一只眼睛预测标签一样。它也没有将重要的偏差纳入模型。这正是GNN发挥作用的地方,可以帮助提高我们模型的性能。
gcn = GCN(input_dim=cora.num_features,hidden_dim=16,output_dim=cora.num_classes,
)
print(f"{gcn}\n", f"-"*88)
gcn, test_acc_gcn = train_and_test_model(gcn, data, num_epochs)
print(f"-"*88)
print(f"\nTest accuracy: {test_acc_gcn * 100:.2f}%\n")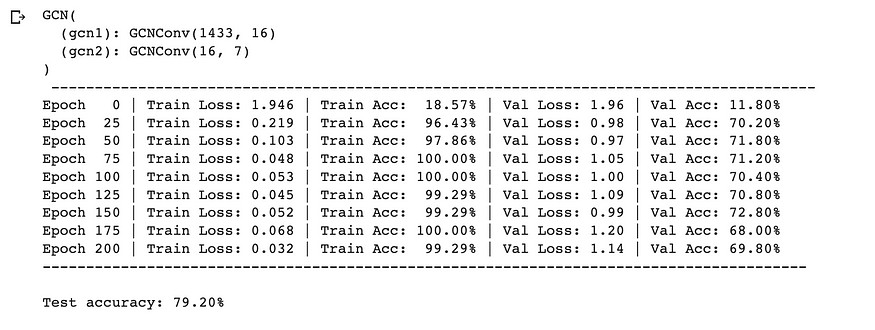
GCN 训练循环和性能
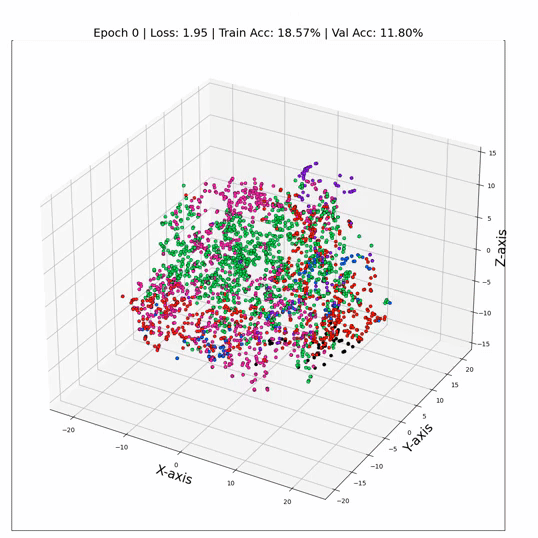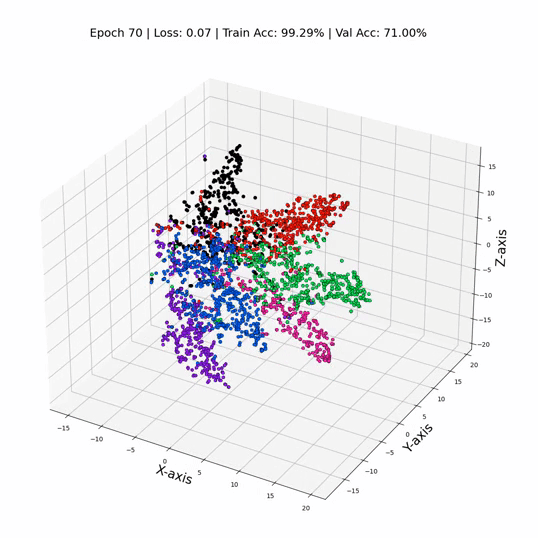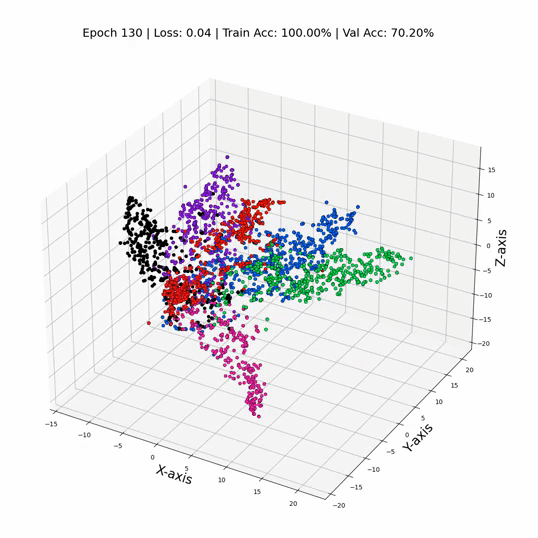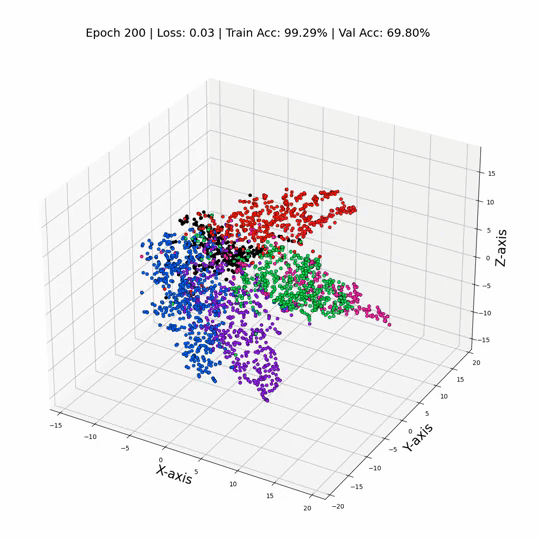
GCN 训练期间的 3 维节点表示
这就是它 - 只需更换那些线性层GCN层,我们就可以飙升到令人眼花缭乱的79%的测试精度! ✨ 证明了节点之间关系信息的力量。这就像我们打开了数据聚光灯,揭示了以前在阴影中丢失的隐藏模式和联系。数字不会说谎——GNN 不仅仅是算法;他们是数据窃窃私语者。
同样,即使是 GAT 由于其多头注意力功能,其准确性也更高 (81%)。
gat = GAT(input_dim=cora.num_features,hidden_dim=8,output_dim=cora.num_classes,heads=6,
)
print(f"{gat}\n", f"-"*88)
gat, test_acc_gat = train_and_test_model(gat, data, num_epochs)
print(f"-"*88)
print(f"\nTest accuracy: {test_acc_gat * 100:.2f}%\n")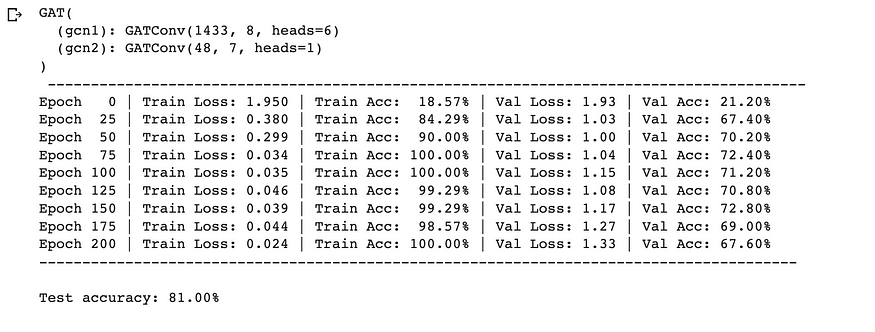
GAT 训练循环和性能

GAT 训练期间的三维节点表示

CiteSeer 数据集上的模型性能
L让我们看看使用TSNE降维技术来查看我们的CiteSeer数据集的潜在表示。我们使用“matplotlib”和“seaborn”来绘制图形的节点。
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import seaborn as sns# Get embeddings
embeddings, _ = gat(citeseer[0].x, citeseer[0].edge_index)# Train TSNE
tsne = TSNE(n_components=2, learning_rate='auto',init='pca').fit_transform(embeddings.detach())# Set the Seaborn theme
sns.set_theme(style="whitegrid")# Plot TSNE
plt.figure(figsize=(10, 10))
plt.axis('off')
sns.scatterplot(x=tsne[:, 0], y=tsne[:, 1], hue=data.y, palette="viridis", s=50)
plt.legend([], [], frameon=False)
plt.show()
来自训练的 GAT 模型的引用Seer 潜在表示
数据画布描绘了一幅发人深省的画面:同一类的节点相互吸引,形成六个类标签中每个标签的集群。然而,异常值孤立节点在这场戏剧中发挥了作用,因为它们给我们的准确性分数带来了扭曲。
还记得我们最初对毫秒边缘影响的猜测吗?好吧,这个假设有发言权。我们正在进行另一项测试,我的目标是通过计算按节点度分类的精度来计算 GAT 模型的性能,从而揭示连接的重要性。
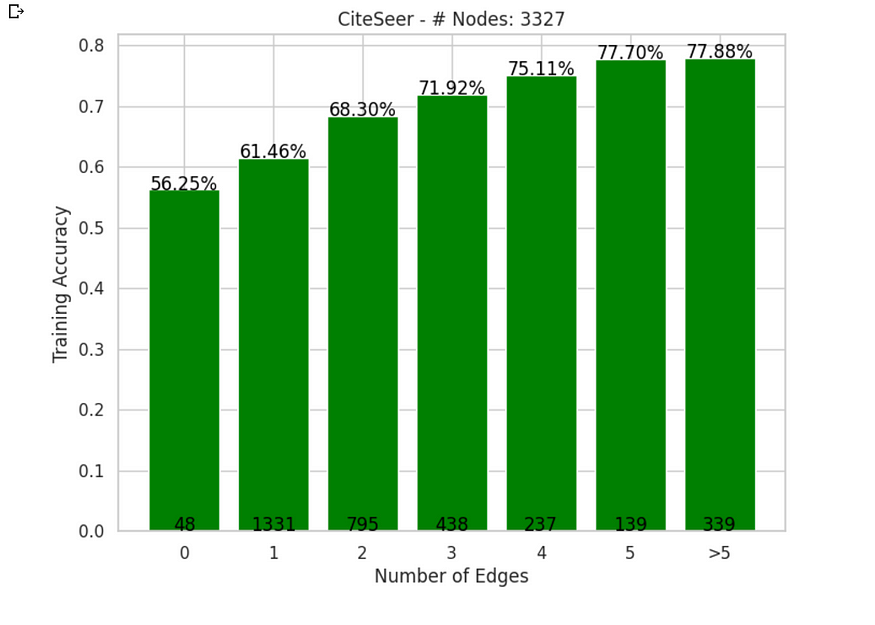
在 CiteSeer 上按节点度分类的 GAT 性能
九、总结
有了这个,我们进入最后一部分,我想总结一下关键要点:
- 我们已经看到了为什么GNN胜过MLP,并强调了节点关系的关键作用。
- 由于自我注意的动态权重,GAT的性能通常优于GCN,从而产生更好的嵌入。
- 小心层叠;过多的层会导致过度平滑,嵌入会收敛并失去多样性。
我们几乎没有触及表面。我们遇到的算法——图卷积网络(GCN)或图注意力网络(GAT)——只是一个开始。图中的边、节点嵌入和数据交响乐有待进一步探索。具体来说,可伸缩性至关重要,我喜欢在即将发表的文章中深入研究迷你批处理的主题。洛克什·夏尔马
相关文章:
AI 媒人:为什么图形神经网络比 MLP 更好?
一、说明 G拉夫神经网络(GNN)!想象他们是人工智能世界的媒人,通过探索他们的联系,不知疲倦地帮助数据点找到朋友和人气。数字派对上的终极僚机。 现在,为什么这些GNN如此重要,你问?好…...

信息学奥赛一本通 1984:【19CSPJ普及组】纪念品 | 洛谷 P5662 [CSP-J2019] 纪念品
【题目链接】 ybt 1984:【19CSPJ普及组】纪念品 洛谷 P5662 [CSP-J2019] 纪念品 【题目考点】 1. 动态规划:完全背包 【解题思路】 由于小伟每天都可以买卖物品无限次,我们可以假想每天开始时,他把所有的商品都卖出ÿ…...

JVM——JVM参数指南
文章目录 1.概述2.堆内存相关2.1.显式指定堆内存–Xms和-Xmx2.2.显式新生代内存(Young Ceneration)2.3.显示指定永久代/元空间的大小 3.垃圾收集相关3.1.垃圾回收器3.2.GC记录 1.概述 在本篇文章中,你将掌握最常用的 JVM 参数配置。如果对于下面提到了一些概念比如…...

马上七夕到了,用各种编程语言实现10种浪漫表白方式
目录 1. 直接表白:2. 七夕节表白:3. 猜心游戏:4. 浪漫诗句:5. 爱的方程式:6. 爱心Python:7. 心形图案JavaScript 代码:8. 心形并显示表白信息HTML 页面:9. Java七夕快乐:…...
Spring Clould 注册中心 - Eureka,Nacos
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) Eureka 微服务技术栈导学(P1、P2) 微服务涉及的的知识 认识微服务-服务架构演变(P3、P4) 总结: 认识微服务-微服务技…...

使用appuploader工具发布证书和描述性文件教程
使用APPuploader工具发布证书和描述性文件教程 之前用AppCan平台开发了一个应用,平台可以同时生成安卓版和苹果版,想着也把这应用上架到App Store试试,于是找同学借了个苹果开发者账号,但没那么简单,还要用到Mac电脑的…...
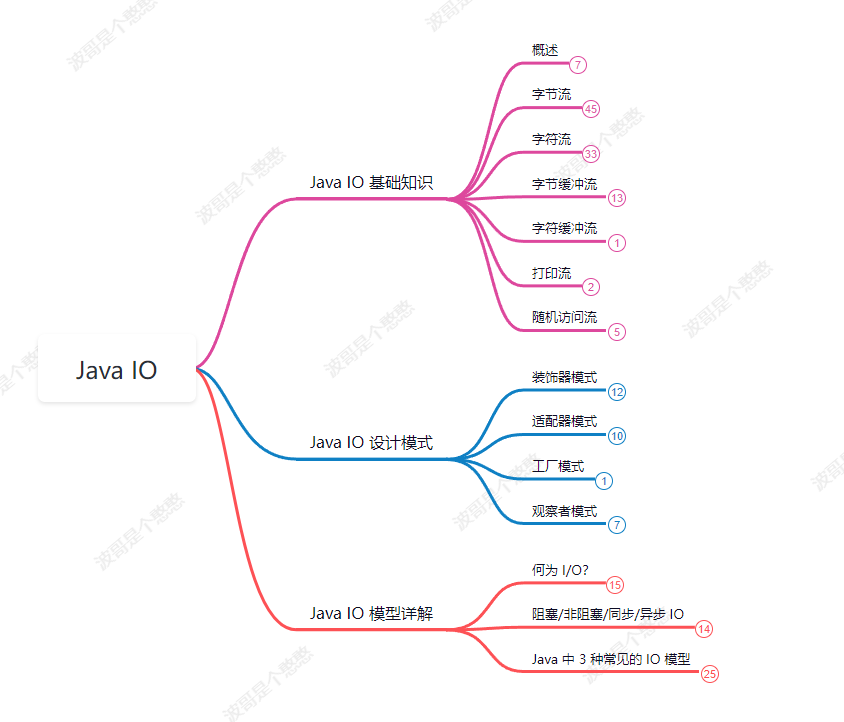
【面试八股文】每日一题:谈谈你对IO的理解
谈谈你对IO的理解 每日一题-Java核心-谈谈你对对IO的理解【面试八股文】 1.Java基础知识 Java IO(Input/Output)是Java编程语言中用于处理输入和输出的一组类和接口。它提供了一种在Java程序中读取和写入数据的方法。 Java IO包括两个主要的部分&#x…...

200. 岛屿数量
思路:遍历整个矩阵,对每个格子执行以下操作: 如果格子是陆地(‘1’),则将其标记为已访问(‘0’),并从当前位置开始进行深度优先搜索,将与当前格子相邻的陆地都…...

【LeetCode】581.最短无序连续子数组
题目 给你一个整数数组 nums ,你需要找出一个 连续子数组 ,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。 请你找出符合题意的 最短 子数组,并输出它的长度。 示例 1: 输入:nums [2,6…...

曲面(弧面、柱面)展平(拉直)瓶子标签识别ocr
瓶子或者柱面在做字符识别的时候由于变形,识别效果是很不好的 或者是检测瓶子表面缺陷的时候效果也没有展平的好 下面介绍两个项目,关于曲面(弧面、柱面)展平(拉直) 项目一:通过识别曲面的6个点…...
知识继承概述
文章目录 知识继承第一章 知识继承概述1.背景介绍第一页 背景第二页 大模型训练成本示例第三页 知识继承的动机 2.知识继承的主要方法 第二章 基于知识蒸馏的知识继承预页 方法概览 1.知识蒸馏概述第一页 知识蒸馏概述第二页 知识蒸馏第三页 什么是知识第四页 知识蒸馏的核心目…...

深度剖析数据在内存中的存储
目录 一、数据类型介绍 类型的基本归类 1.整形家族 2.浮点数家族 3.构造类型 (自定义类型) 4.指针类型 5.空类型 二、整形在内存中的存储 1.原码、反码、补码 1.1原码 1.2反码 1.3补码 1.4计算规则 2 .大小端介绍 三、浮点型在内存中的存…...

【ARM Linux 系统稳定性分析入门及渐进10 -- GDB 初始化脚本介绍及使用】
文章目录 gdb 脚本介绍gdb 初始化脚本使用启动 gdb 的时候自动执行脚本gdb运行期间执行命令脚本 gdb 脚本介绍 GDB脚本是一种使用GDB命令语言编写的脚本,可以用来自动化一些常见的调试任务。这些脚本可以直接在GDB中运行,也可以通过GDB的-x参数或source…...
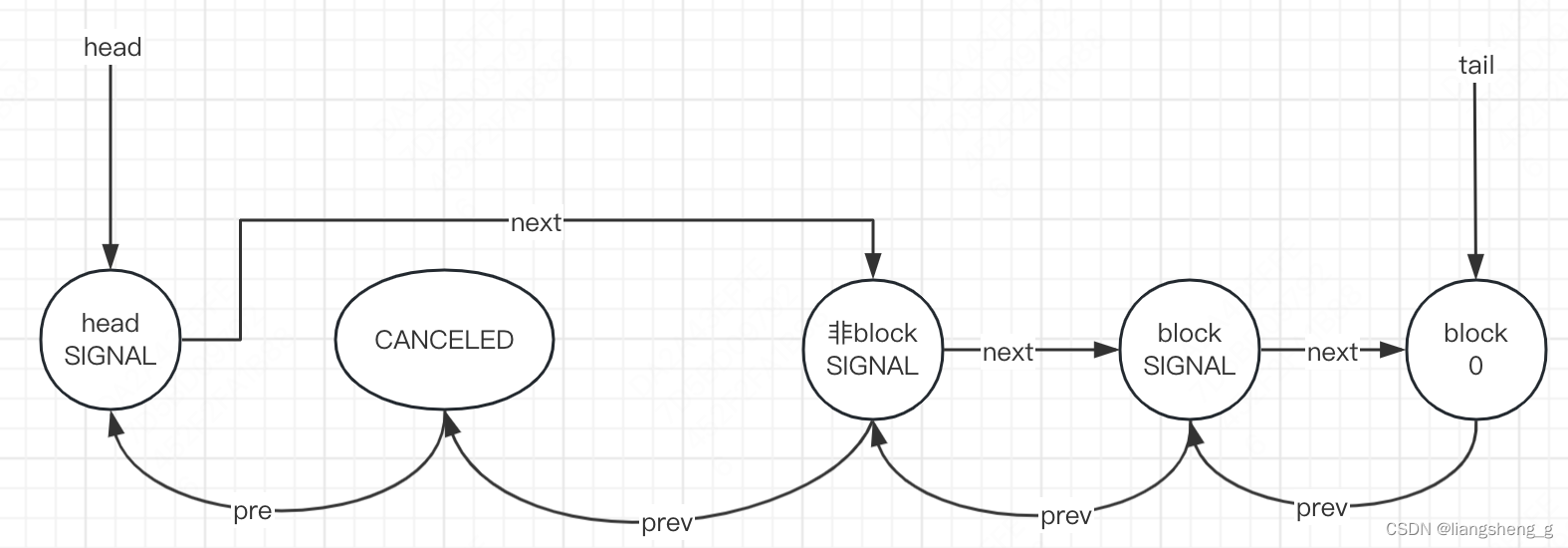
AQS源码解读
文章目录 前言一、AQS是什么?二、解读重点属性statehead、tail 同步变量竞争acquire 同步变量释放 总结 前言 AQS是AbstractQueuedSynchronizer的缩写,也是大神Doug Lea的得意之作。今天我们来进行尽量简化的分析和理解性的代码阅读。 一、AQS是什么&am…...
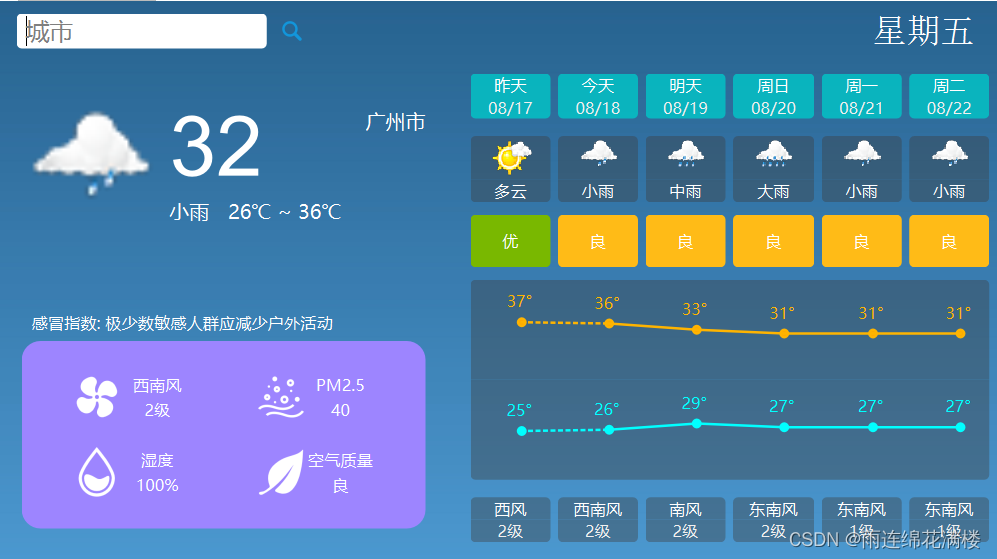
QT实现天气预报
1. MainWindow类设计的成员变量和方法 public: MainWindow(QWidget* parent nullptr); ~MainWindow(); protected: 形成文本菜单来用来右键关闭窗口 void contextMenuEvent(QContextMenuEvent* event); 鼠标被点击之后此事件被调用 void mousePressEvent(QMouseEv…...

【马蹄集】第二十三周——进位制专题
进位制专题 目录 MT2186 二进制?不同!MT2187 excel的烦恼MT2188 单条件和MT2189 三进制计算机1MT2190 三进制计算机2 MT2186 二进制?不同! 难度:黄金 时间限制:1秒 占用内存:128M 题目…...

[足式机器人]Part3 变分法Ch01-1 数学预备知识——【读书笔记】
本文仅供学习使用 本文参考: 《变分法基础-第三版》老大中 《变分学讲义》张恭庆 《Calculus of Variations of Optimal Control Theory》-变分法和最优控制论-Daneil Liberzon Ch01-1 数学基础-预备知识1 1 数学基础-预备知识1.1 泰勒公式1.1.1 一元函数的泰勒公式…...

计算机网络----CRC冗余码的运算
目录 1. 冗余码的介绍及原理2. CRC检验编码的例子3. 小练习 1. 冗余码的介绍及原理 冗余码是用于在数据链路层的通信链路和传输数据过程中可能会出错的一种检错编码方法(检错码)。原理:发送发把数据划分为组,设每组K个比特&#…...
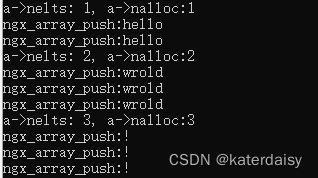
将Nginx源码数组结构(ngx_array.c)和内存池代码单独编译运行,附代码
在上面一篇的基础上把Nginx源码数组结构也摘录下来,也增加了测试代码,编译运行。 https://blog.csdn.net/katerdaisy/article/details/132358883 《将nginx内存池代码单独编译运行,了解nginx内存池工作原理,附代码》 核心代码&…...
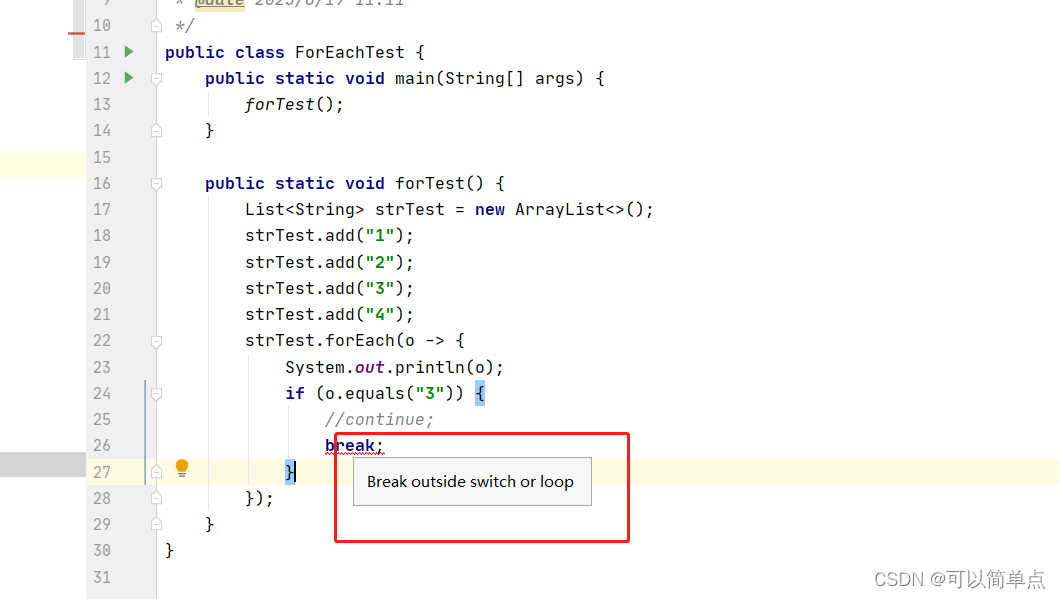
java forEach中不能使用break和continue的原因
1.首先了解break和continue的使用范围和作用 1.1使用范围 break适用范围:只能用于switch或者是循环语句中。当然可以用于增强for循环。 continue适用范围: 用于循环语句中。 1.2作用 break: 1. break用于switch语句的作用是结束一个switch语句。 2. break用于循…...
)
ElevenLabs语音合成效果翻倍的秘密(行业未公开的声学参数调优矩阵)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音合成效果翻倍的核心洞察 关键瓶颈在于语音上下文建模粒度 ElevenLabs 的高质量语音合成并非单纯依赖更大模型参数量,而是通过细粒度的语义-韵律联合编码实现自然度跃升。…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...