微服务中间件-分布式缓存Redis
分布式缓存
- a.Redis持久化
- 1) RDB持久化
- 1.a) RDB持久化-原理
- 2) AOF持久化
- 3) 两者对比
- b.Redis主从
- 1) 搭建主从架构
- 2) 数据同步原理(全量同步)
- 3) 数据同步原理(增量同步)
- c.Redis哨兵
- 1) 哨兵的作用
- 2) 搭建Redis哨兵集群
- 3) RedisTemplate的哨兵模式
- d.Redis分片集群
- 1) 搭建分片集群
- 2) 散列插槽
- 3) 集群伸缩
- 4) 故障转移
- 5) RedisTemplate访问分片集群
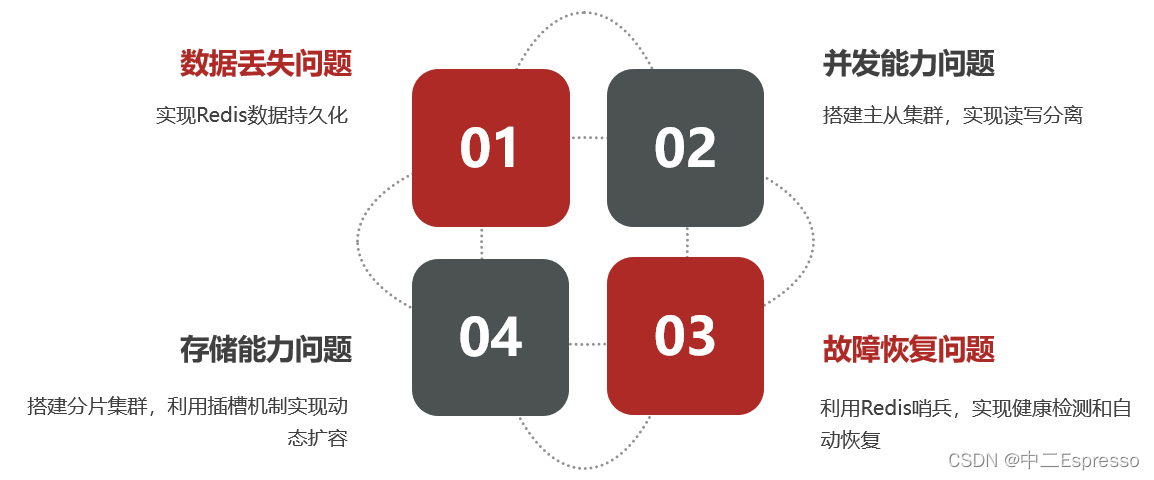
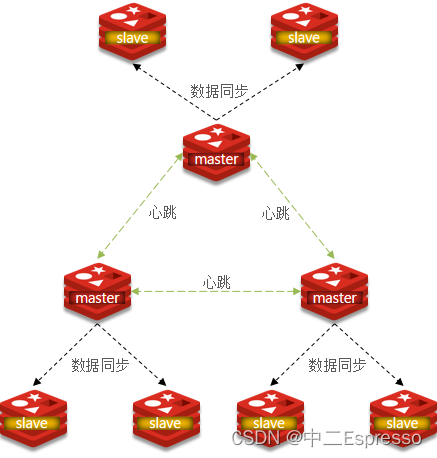
– 基于Redis集群解决单机Redis存在的问题
单机的Redis存在四大问题:
- 1.数据丢失问题: Redis是内存存储,服务重启可能会丢失数据
- 2.并发能力问题: 单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景
- 3.故障恢复问题: 如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段
- 4.存储能力问题: Redis基于内存,单节点能存储的数据量难以满足海量数据需求
a.Redis持久化
1) RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件称为RDB文件,默认是保存在当前运行目录。
Redis停机时会执行一次RDB。
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

RDB的其它配置也可以在redis.conf文件中设置:

1.a) RDB持久化-原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9auWz7oi-1692354289144)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817140743459.png)]
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?
- 默认是服务停止时。
- 也可以设置在60秒内至少执行1000次修改则触发RDB (自修改)
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
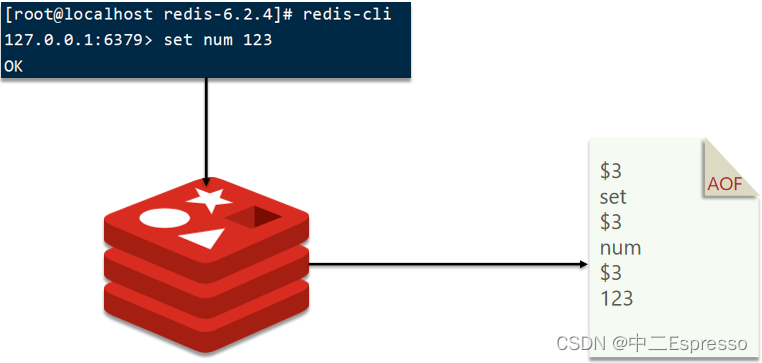
2) AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF的命令记录的频率也可以通过redis.conf文件来配:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pkPcdXYV-1692354289145)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817144856449.png)]
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

3) 两者对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
b.Redis主从
1) 搭建主从架构
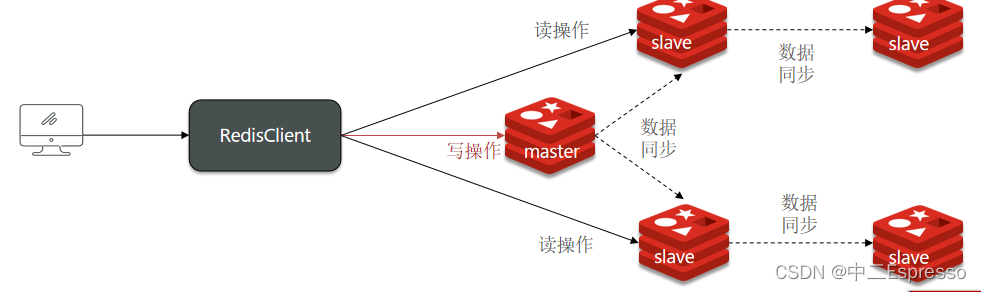
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
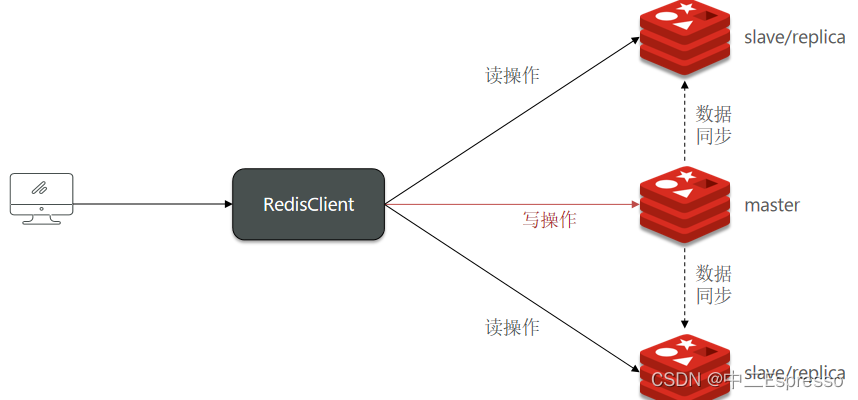
共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003
如图:
2)恢复原始配置
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000# 关闭AOF
appendonly no
3)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis实例的声明 IP
replica-announce-ip 192.168.150.101
每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
# 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf# 或者一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf
启动后:
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof 192.168.150.101 7001
通过redis-cli命令连接7003,执行下面命令:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001
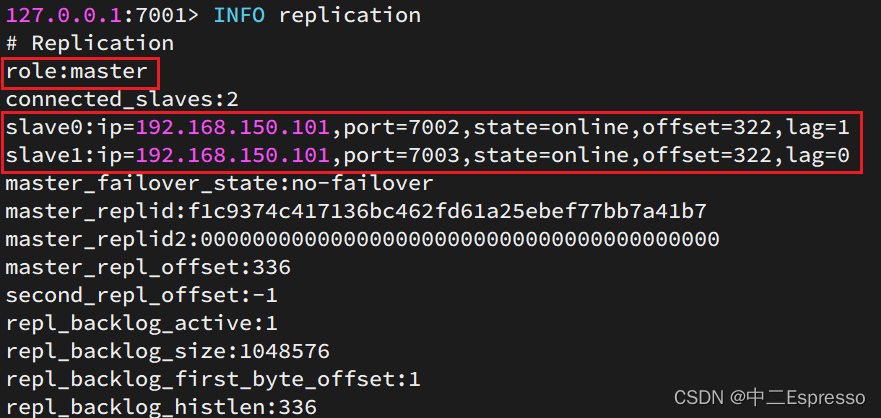
然后连接 7001节点,查看集群状态:
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
结果:
测试
执行下列操作以测试:
-
利用redis-cli连接7001,执行
set num 123 -
利用redis-cli连接7002,执行
get num,再执行set num 666 -
利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
2) 数据同步原理(全量同步)
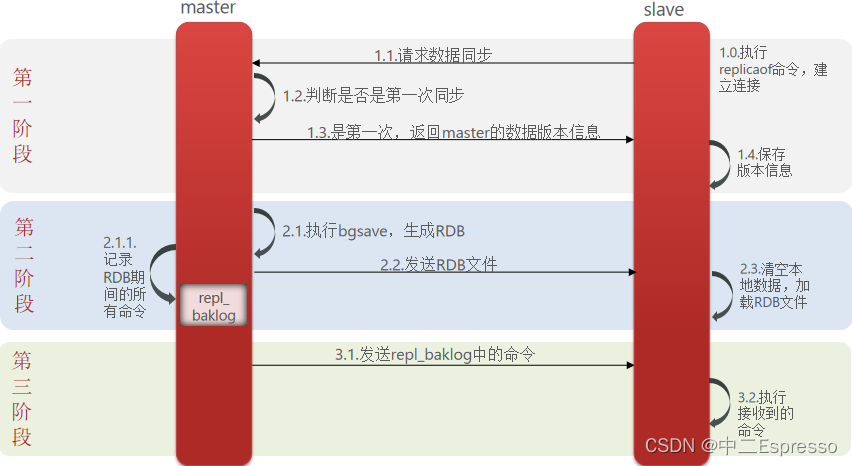
主从第一次同步是全量同步:
master如何判断slave是不是第一次来同步数据?
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据
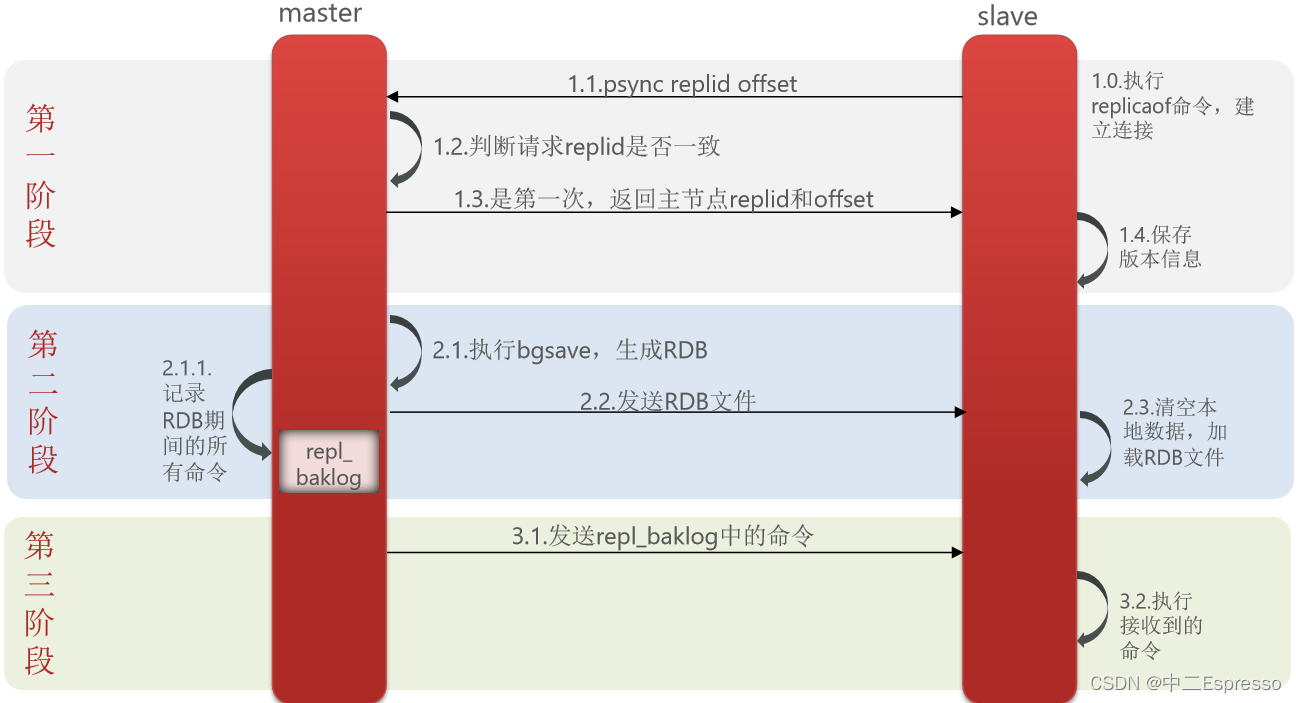
简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步,执行全量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
3) 数据同步原理(增量同步)
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qv8gWjxp-1692354289145)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817161911269.png)]
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
可以从以下几个方面来优化Redis主从集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制(写入网络的IO中),避免全量同步时的磁盘IO
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
c.Redis哨兵
1) 哨兵的作用
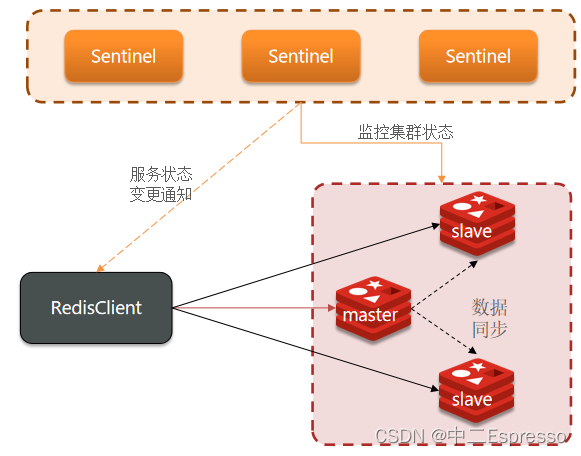
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- **主观下线:**如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高
如何实现故障转移
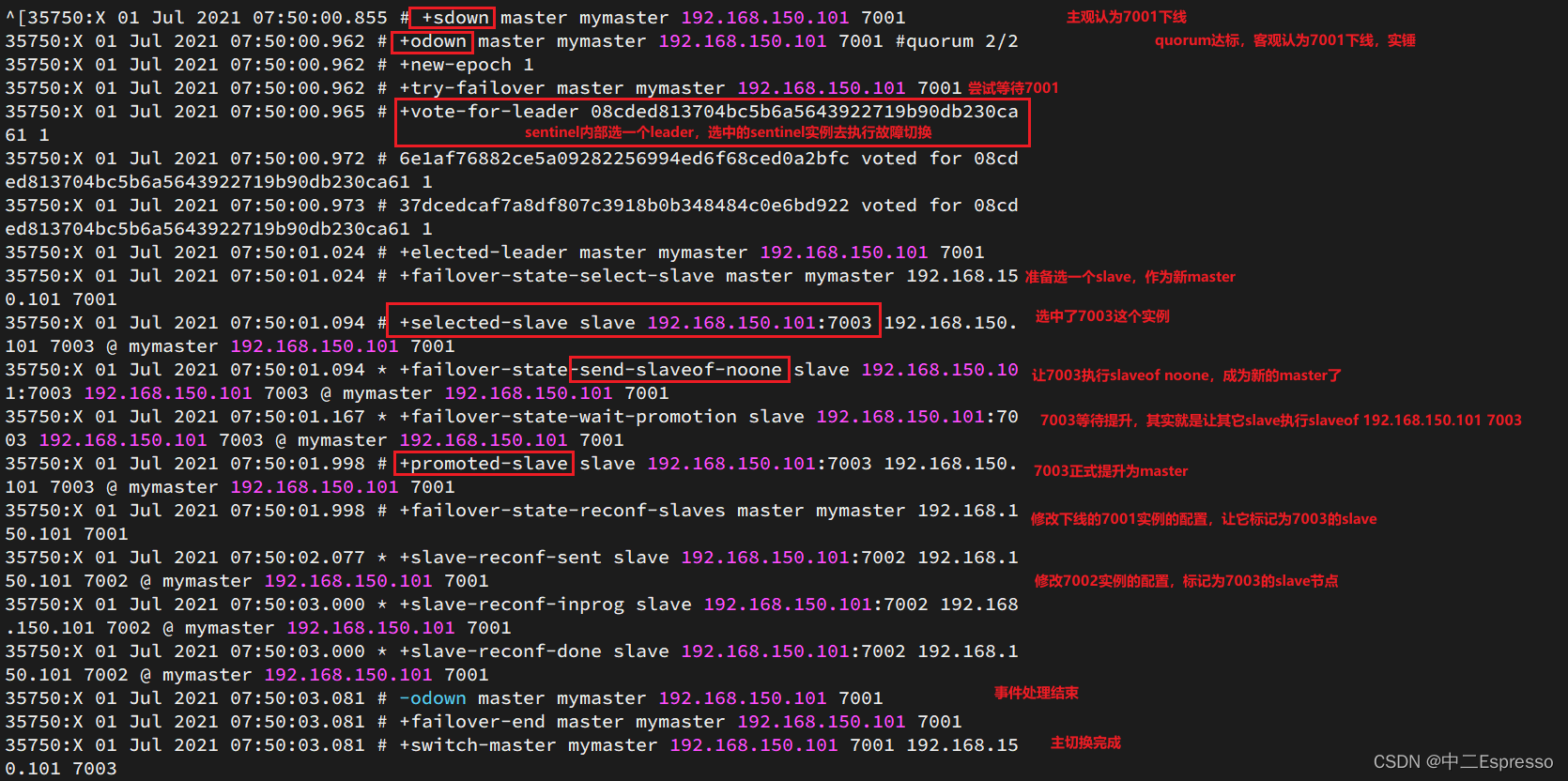
当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下:
- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
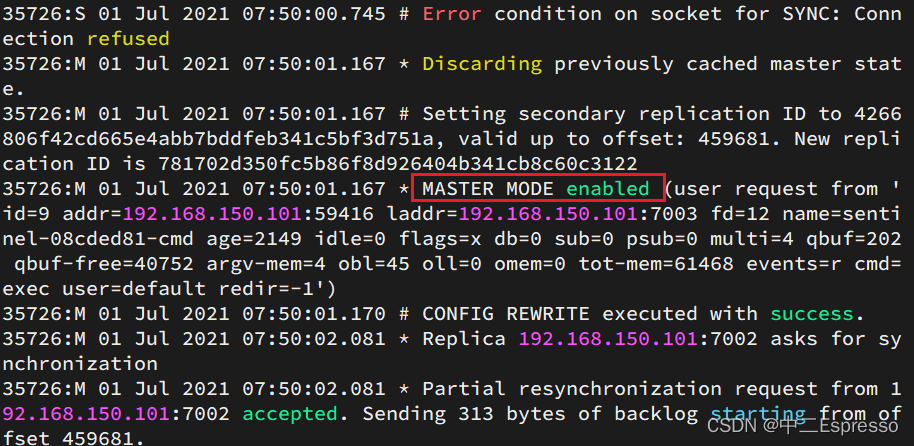
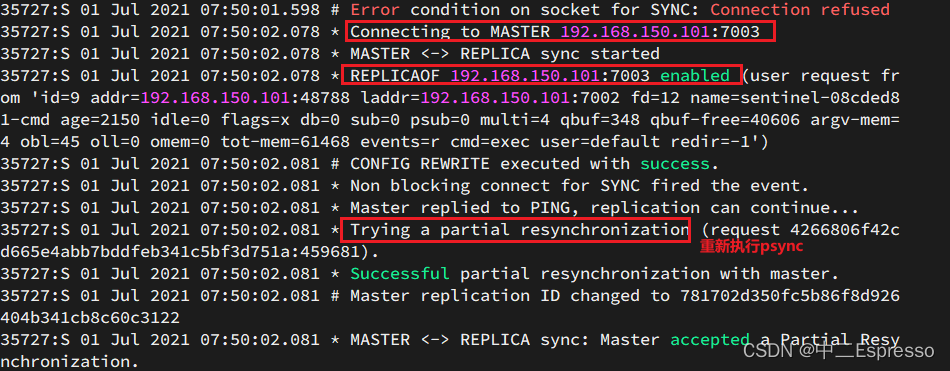
- sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
2) 搭建Redis哨兵集群
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir s1 s2 s3
如图:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf
启动后:
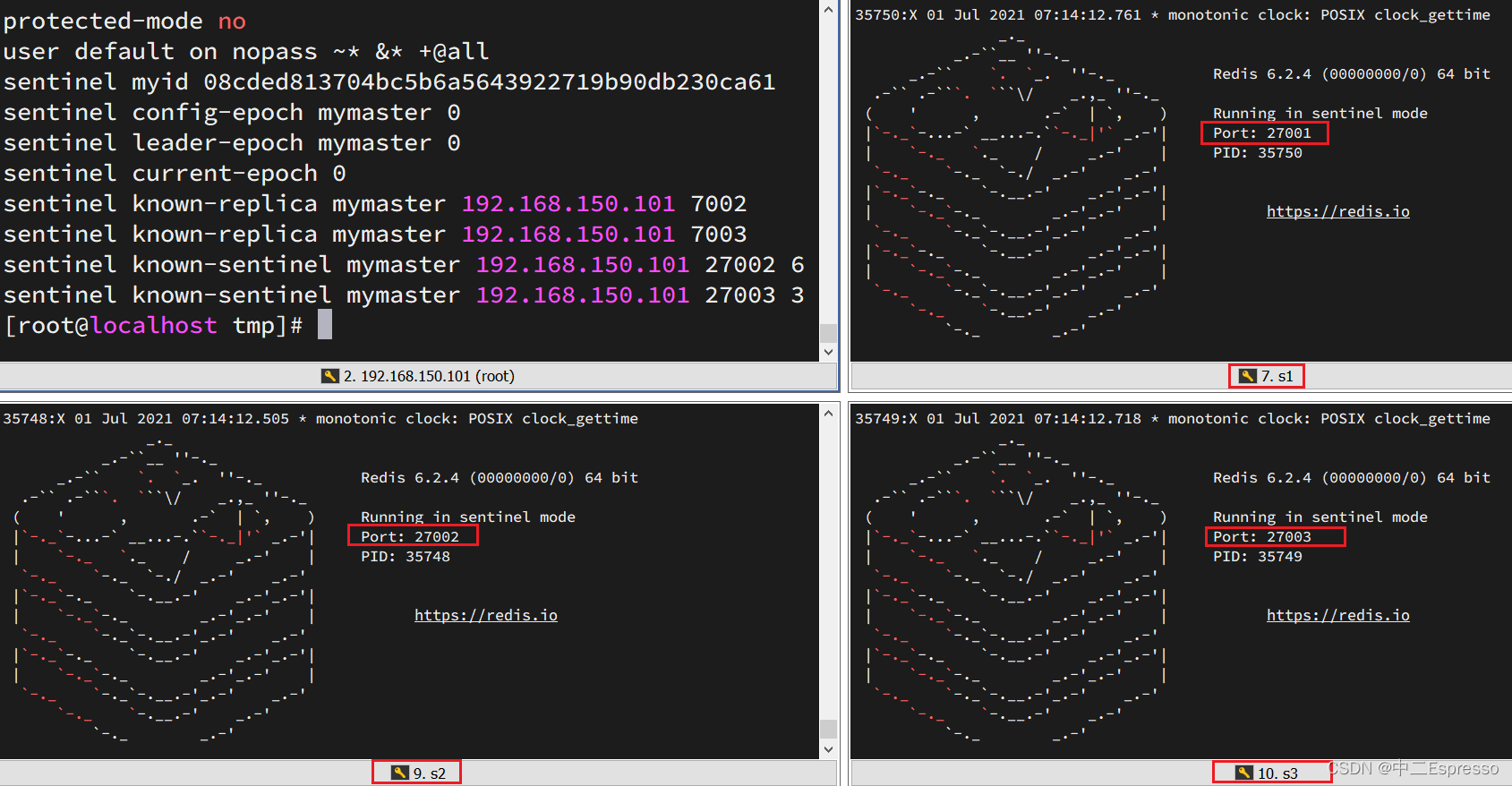
测试
尝试让master节点7001宕机,查看sentinel日志:
查看7003的日志:
查看7002的日志:
3) RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
1.在pom文件中引入redis的starter依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.然后在配置文件application.yml中指定sentinel相关信息:
spring:redis:sentinel:master: mymasternodes:- 192.168.200.128:27001- 192.168.200.128:27002- 192.168.200.128:27003
3.配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer() {return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
d.Redis分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
1) 搭建分片集群
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
准备实例和配置
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
# 进入/tmp目录
cd /tmp
# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003
在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log
将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
启动
因为已经配置了后台启动模式,所以可以直接启动服务:
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
通过ps查看状态:
ps -ef | grep redis
发现服务都已经正常启动:

如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill
或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
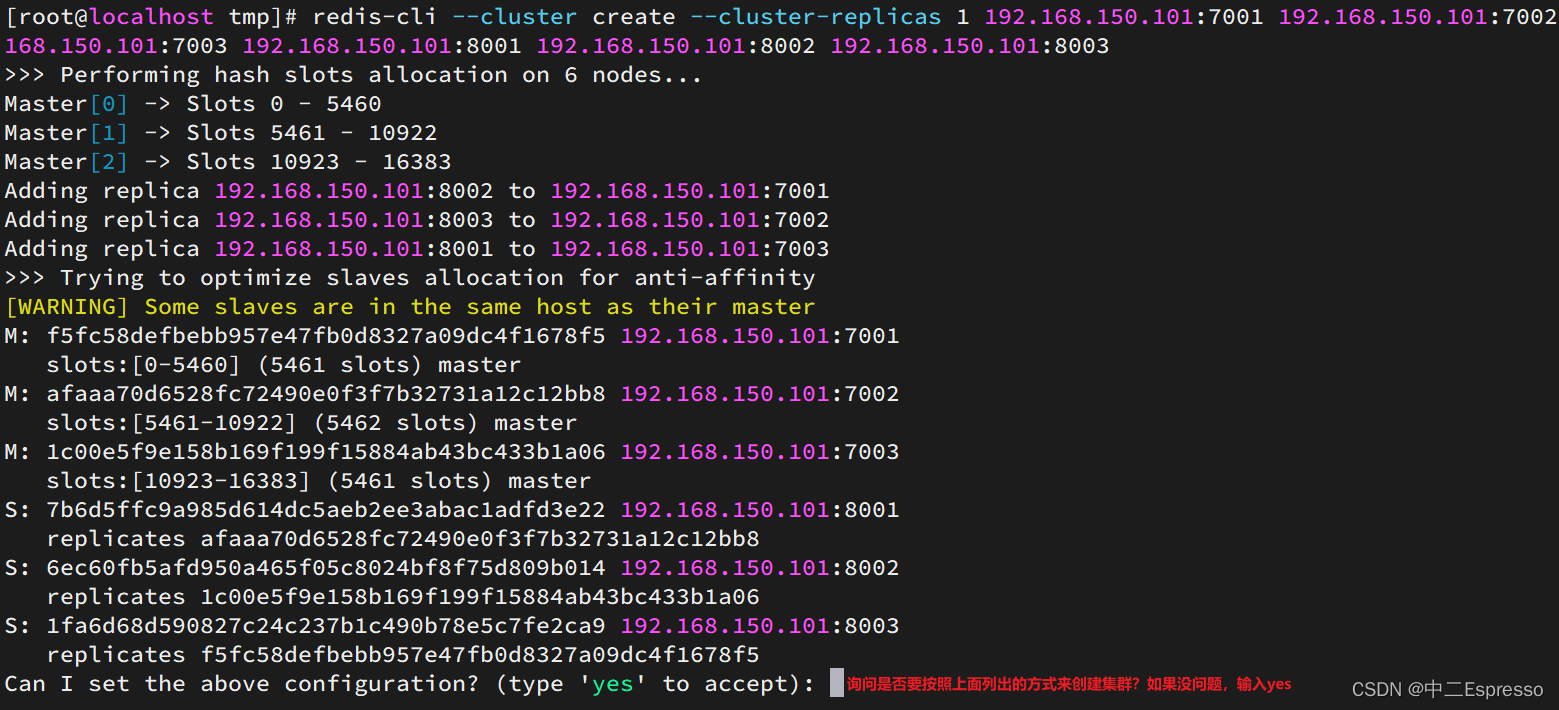
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2)Redis5.0以后
集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.200.128:7001 192.168.200.128:7002 192.168.200.128:7003 192.168.200.128:8001 192.168.200.128:8002 192.168.200.128:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:
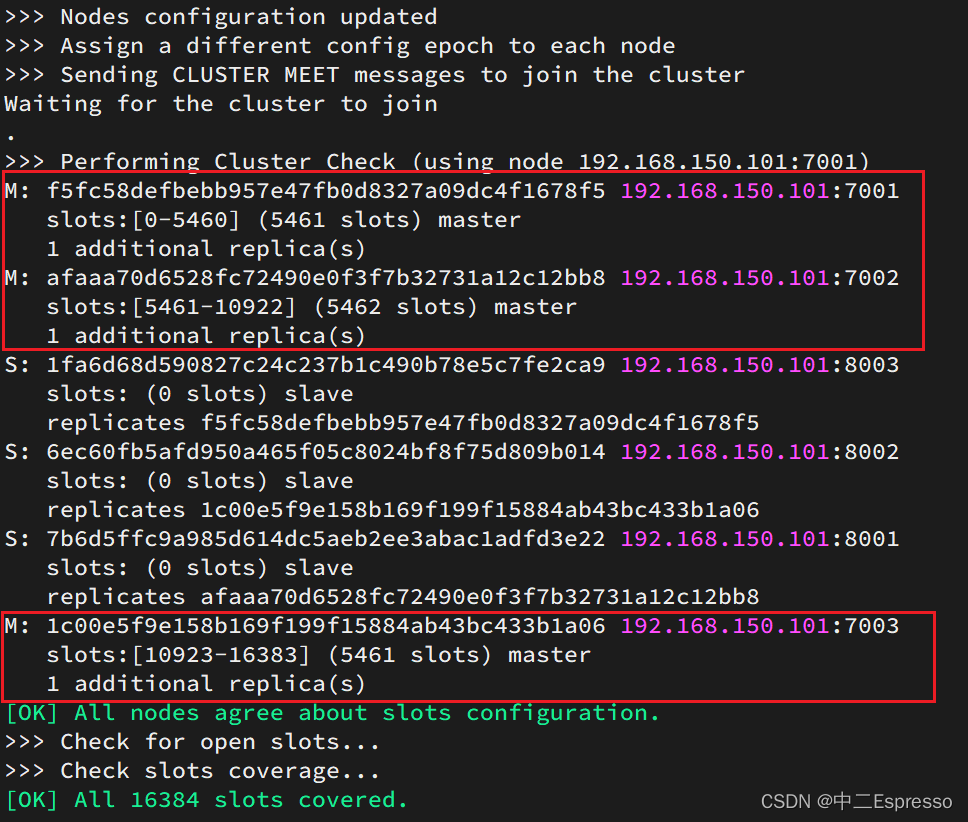
这里输入yes,则集群开始创建:
通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes

测试
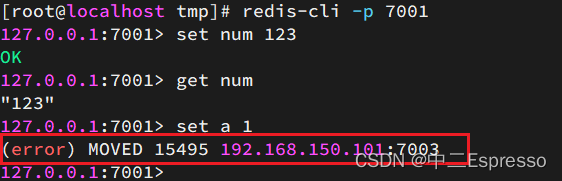
尝试连接7001节点,存储一个数据:
# 连接
redis-cli -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1
结果悲剧了:
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001
这次可以了:
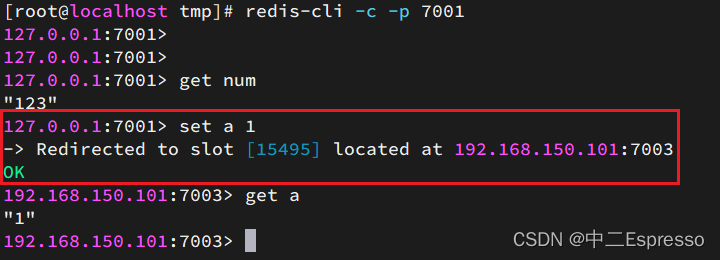
2) 散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
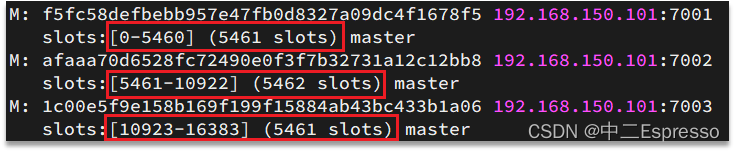
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
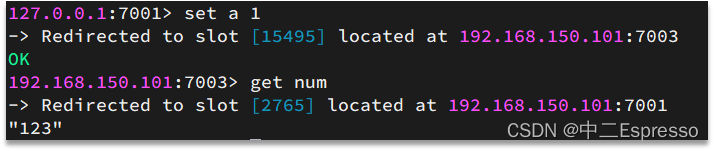
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
3) 集群伸缩
添加一个节点到集群
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:
比如,添加节点的命令:
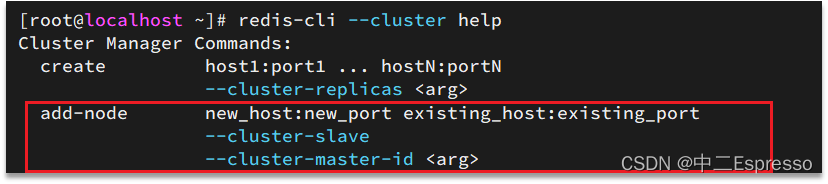
案例:向集群中添加一个新的master节点,并向其中存储 num = 10
需求:
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
# 在tmp目录下,创建新的7004目录
mkdir 7004
# 拷贝redis.conf到7004目录下
cp redis.conf 7004
# 将redis.conf的端口号全部替换成7004
sed -i s/6379/7004/g 7004/redis.conf
# 启动7004的redis
redis-server 7004/redis.conf
# 添加7004到之前的集群中
redis-cli --cluster add-node 192.168.200.128:7004 192.168.200.128:7001
# 将7001的部分插槽移至7004
redis-cli --cluster reshard 192.168.200.128:7001# 提示输入要移动多少个插槽:3000# 提示输入接收插槽的id:输入7004 redis的id# 提示输入从那个插槽移动:输入7001 redis的id# 输入 done# 输入 yes
# 查看插槽,是否移动成功
redis-cli -p 7001 cluster nodes
# 将num存入redis中
redis-cli -c -p 7004# set num 10
案例:删除集群中的一个节点
需求:删除7004这个实例
# 将7004的全部插槽移至7001
redis-cli --cluster reshard 192.168.200.128:7001# 提示输入要移动多少个插槽:3000# 提示输入接收插槽的id:输入7001 redis的id# 提示输入从那个插槽移动:输入7004 redis的id# 输入 done# 输入 yes
# 查看插槽,是否移动成功。并获取7004的id
redis-cli -p 7001 cluster nodes
# 删除7004节点:redis-cli --cluster del-node nodeId
redis-cli --cluster del-node 192.168.200.128:7004 08af8f1fedc0d211bbb94225d3cef59efd75aa6a
4) 故障转移
Redis集群拥有自动主从切换的功能,无需使用哨兵
当集群中有一个master宕机会发生什么呢?
1.首先是该实例与其它实例失去连接
2.然后是疑似宕机:

3.最后是确定下线,自动提升一个slave为新的master:

数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
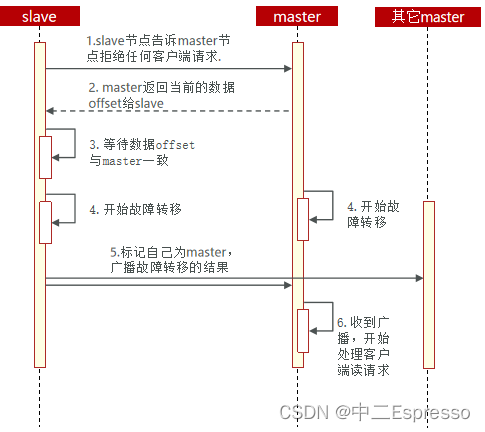
手动的Failover支持三种不同模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
案例:在7002这个slave节点执行手动故障转移,重新夺回master地位
步骤如下:
- 1.利用redis-cli连接7002这个节点
- 2.执行cluster failover命令
# 进入redis 7002的控制台
redis-cli -p 7002# 在控制台输入 cluster failover# 7002将成为master
5) RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
- 1.引入redis的starter依赖
- 2.配置分片集群地址
- 3.配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes:- 192.168.200.128:7001- 192.168.200.128:7002- 192.168.200.128:7003- 192.168.200.128:8001- 192.168.200.128:8002- 192.168.200.128:8003
相关文章:
微服务中间件-分布式缓存Redis
分布式缓存 a.Redis持久化1) RDB持久化1.a) RDB持久化-原理 2) AOF持久化3) 两者对比 b.Redis主从1) 搭建主从架构2) 数据同步原理(全量同步)3) 数据同步原理(增量同步) c.Redis哨兵1) 哨兵的作用2) 搭建Redis哨兵集群3) RedisTem…...

java面试强基(16)
目录 clone方法的保护机制 Java中由SubString方法是否会引起内存泄漏? Java中提供了哪两种用于多态的机制? 程序计数器(线程私有) 如何判断对象是否是垃圾? clone方法的保护机制 clone0方法的保护机制在Object中是被声明为 protected的。以User…...
Python可视化在量化交易中的应用(13)_Seaborn直方图
Seaborn中带核密度的直方图的绘制方法 seaborn中绘制直方图使用的是sns.histlot()函数: sns.histplot(data,x,y,hue,weights,stat‘count’,bins‘auto’,binwidth,binrange,discrete,cumulative,common_bins,common_norm,multiple‘layer’,element‘bars’,fill,…...

NOIP 2006 普及组 第二题 开心的金明
开心的金明 说明 金明今天很开心,家里购置的新房就要领钥匙了,新房里有一间他自己专用的很宽敞的房间。 更让他高兴的是,妈妈昨天对他说:“你的房间需要购买哪些物品,怎么布置,你说了算,只要不超…...

「UG/NX」Block UI 指定点SpecifyPoint
✨博客主页何曾参静谧的博客📌文章专栏「UG/NX」BlockUI集合📚全部专栏「UG/NX」NX二次开发「UG/NX」BlockUI集合「VS」Visual Studio「QT」QT5程序设计「C/C+&#...

Linux Shell如果ping失败就重启网卡(详解)
直接上脚本 -------------------------------------------------------------------------- #vi /tmp/ping_check.sh #!/bin/bash IP="1.1.1.1" PacketLoss=`ping -c 4 -w 4 1.1.1.1 | grep packet loss | awk -F packet loss {print $1} | awk {print $NF}|se…...
每天一道leetcode:剑指 Offer 13. 机器人的运动范围(中等广度优先遍历剪枝)
今日份题目: 地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0]的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之…...

TypeError: a bytes-like object is required, not ‘str‘
raceback (most recent call last): File "D:\pycharmcode\client.py", line 12, in <module> tcp_socket.send(send_data) TypeError: a bytes-like object is required, not str 使用socket进行ubuntu与windows通信时,发送数据时报了以上错…...

题解 | #1005.List Reshape# 2023杭电暑期多校9
1005.List Reshape 签到题 题目大意 按一定格式给定一个纯数字一维数组,按给定格式输出成二维数组。 解题思路 读入初始数组字符串,将每个数字分离,按要求输出即可 参考代码 参考代码为已AC代码主干,其中部分功能需读者自行…...
会声会影2023旗舰版电脑端视频剪辑软件
随着短视频、vlog等媒体形式的兴起,视频剪辑已经成为了热门技能。甚至有人说,不会修图可以,但不能不会剪视频。实际上,随着各种智能软件的发展,视频剪辑已经变得越来越简单。功能最全的2023新版,全新视差转…...

【linux基础(四)】对Linux权限的理解
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到开通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux权限 1. 前言2. shell命…...

maven项目指定数据源
springboot项目 直接在pom.xml文件中添加以下配置 <!--使用阿里云maven中央仓库--> <repositories><repository><id>aliyun-repos</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><ena…...

web3:使用Docker-compose方式部署blockscout
最近做的项目,需要blockscout来部署一个区块链浏览器,至于blockscout是什么,咱们稍后出一篇文章专门介绍下,本次就先介绍一下如何使用Docker-compose方式部署blockscout,以及过程中遇到的种种坑 目录 先决条件我的环境准备工作Docker-compose1.安装方式一:下载 Docker Co…...
泛型编程加载dll接口函数)
C++11实用技术(五)泛型编程加载dll接口函数
C11泛型编程简化加载dll代码 常见的加载dll方式: HMODULE m_hDataModule; m_hDataModule LoadLibrary("myDll.dll");typedef int (*PfunA)(int a, int b);//定义函数指针 PfunA fun (PfunA)(GetProcAddress(m_hDataModule , "funA"));//加载…...
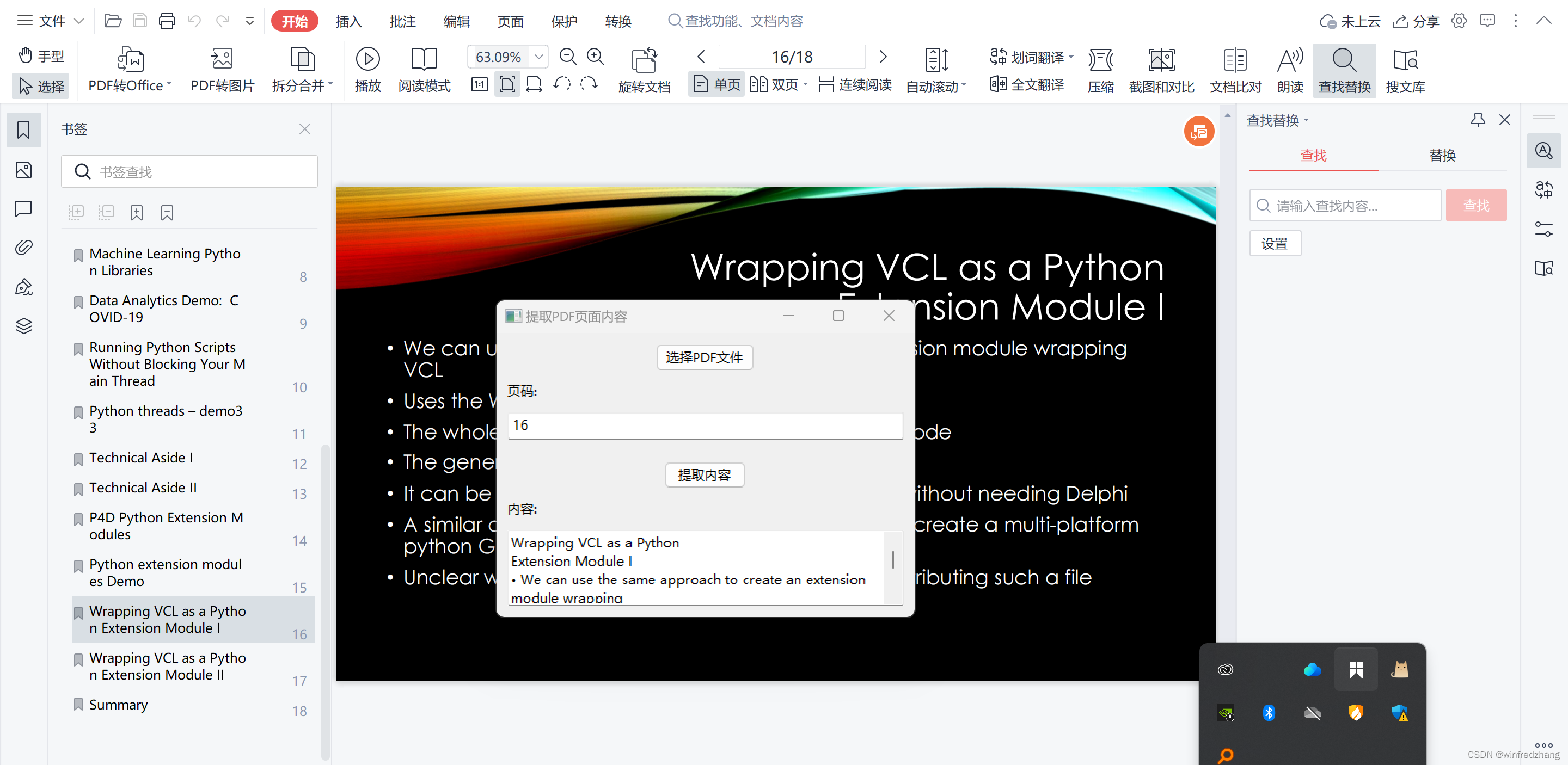
使用wxPython和PyMuPDF提取PDF页面指定页数的内容的应用程序
在本篇博客中,我们将探讨如何使用wxPython和PyMuPDF库创建一个简单的Bokeh应用程序,用于选择PDF文件并提取指定页面的内容,并将提取的内容显示在文本框中。 C:\pythoncode\new\pdfgetcontent.py 准备工作 首先,确保你已经安装了…...

k8s的pv和pvc创建
//NFS使用PV和PVC 1、配置nfs存储 2、定义PV 实现 下图的pv和pvc测试 pv的定义 这里定义5个PV,并且定义挂载的路径以及访问模式,还有PV划分的大小 vim /pv.yamlapiVersion: v1 kind: PersistentVolume metadata:name: pv001 spec:capacity:storage: …...

记K8S集群工作节点,AnolisOS 8.6部署显卡驱动集成Containerd运行时
1、安装gcc #安装编译环境 yum -y install make gcc gcc-c2、下载显卡驱动 点击 直达连接 nvidia高级搜索下载历史版本驱动程序(下载历史版本驱动) https://www.nvidia.cn/Download/Find.aspx?langcn3、安装驱动 安装显卡驱动 ./NVIDIA-Linux-x86…...

JavaScript 性能优化
优化JavaScript代码的性能是开发过程中的一个关键任务,它可以显著提升网站或应用的用户体验。以下是一些优化技巧,涵盖了减少重绘、减少内存占用和合并网络请求等方面: 1. **减少重绘和重排:** - **使用 CSS3 动画:…...
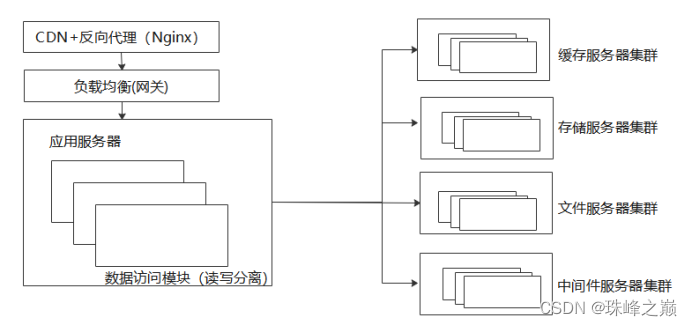
架构演进及常用架构
1架构演进及常用架构 1.1单体分层架构 1.2 多应用微服务架构 1.3 分布式集群部署 部署 CDN 节点: 用户访问量的增加意味着用户地域的分散请求,如果所有请求都直接发送中心服务器的话,距离越远,响应速度越差,这时就需…...

WinCC V7.5 中的C脚本对话框不可见,将编辑窗口移动到可见区域的具体方法
WinCC V7.5 中的C脚本对话框不可见,将编辑窗口移动到可见区域的具体方法 由于 Windows 系统更新或使用不同的显示器,在配置C动作时,有可能会出现C脚本编辑窗口被移动到不可见区域的现象。 由于该窗口无法被关闭,故无法进行进一步…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

3分钟掌握跨平台模组下载神器:WorkshopDL全攻略
3分钟掌握跨平台模组下载神器:WorkshopDL全攻略 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台的游戏无法使用Steam创意工坊模组而烦恼吗…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...

基于MCP与Apify构建AI驱动的投资另类数据研究工具
1. 项目概述:当投资研究遇上AI代理如果你是一名量化研究员、对冲基金分析师,或者只是一个对金融市场充满好奇、希望用数据驱动决策的独立投资者,那么你肯定对“另类数据”这个词不陌生。传统的财报、股价、宏观经济指标,这些“传统…...

从二维到三维:DIY LED视频立方体构建全攻略
1. 项目概述:从平面到立体的视觉革命几年前,当我第一次成功点亮一整面由32x32 RGB LED面板组成的视频墙时,那种由1024个像素点共同编织出的动态画面所带来的震撼,至今记忆犹新。但作为一个热衷于将技术推向边界的创作者࿰…...