分布式唯一ID实战
目录
- 一、UUID
- 二、数据库方式
- 1、数据库生成之简单方式
- 2、数据库生成 - 多台机器和设置步长,解决性能问题
- 3、Leaf-segment 方案实现
- 4、双 buffer 优化
- 5、Leaf高可用容灾
- 三、基于Redis实现分布式ID
- 四、雪花算法
- 1、雪花算法介绍
- 2、 雪花算法生产环境架构:
- 3、==雪花算法的时钟回拨问题==
- 4、美团 Leaf-snowflake 方案
一、UUID
UUID的标准形式包含32个16进制数字,以 “ - ” 进行分割,形式为 8-4-4-4-12的32个字符,实例
550e8400-e29b-41d4-a716-446655440000。
优点:
- 性能高,本地生成,没有网络消耗
缺点:
- 不易存储,长度太长,32个16进制数字,128位
- 不安全,会暴露MAC地址
- UUID作为MySQL主键,会导致索引页分页,插入慢;长度太长,导致每个索引页存放的索引变少,索引效率降低
二、数据库方式
1、数据库生成之简单方式
利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号作为业务的唯一ID
begin;
// 如果表中存在相同的数据,则将表中的数据删除,然后重新插入一条数据
2 REPLACE INTO Tickets64 (stub) VALUES ('a');
3 SELECT LAST_INSERT_ID();
4 commit;
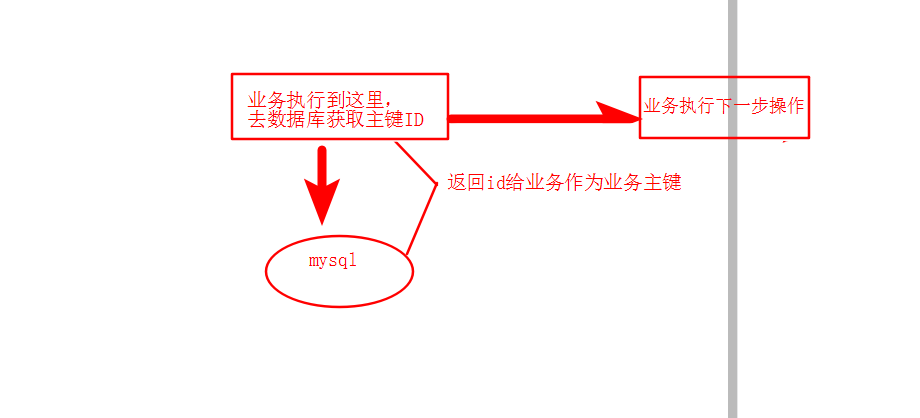
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小
- ID单调递增,可以实现一些对ID有特殊要求的业务
缺点
- 强依赖DB,当DB异常时,整个系统不可使用,属于致命问题。应该配置主从复制以尽可能增加可用性(但是主从切换时可能会导致重复发号)
- ID发号,性能瓶颈限制在单台MySQL的读写性能
2、数据库生成 - 多台机器和设置步长,解决性能问题
在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等
比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)、TicketServer2的初始值为2(2,4,6,8,10…)
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2…N-1那么整个架构就变成了如下图所示:
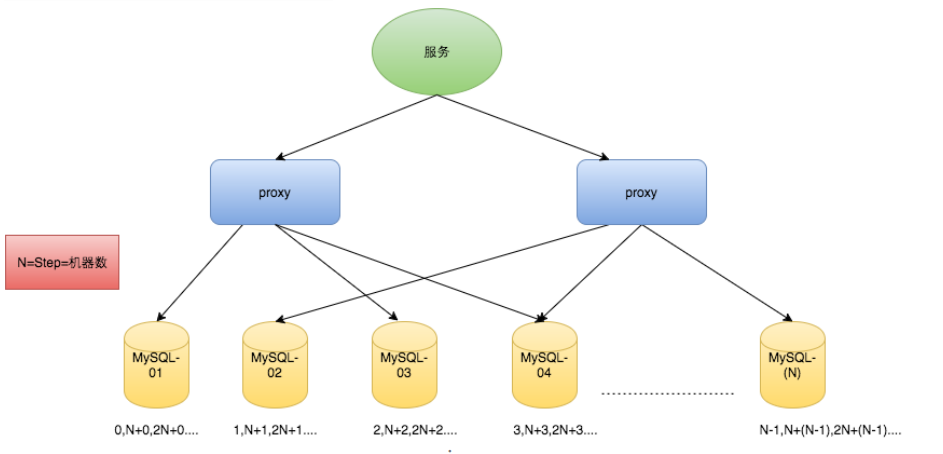
这种架构貌似能够满足性能的需求,但有以下几个缺点:
-
系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么
做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可
以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之
内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶
数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合
我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来
复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?
简直是噩梦。所以系统水平扩展方案复杂难以实现。 -
ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍
-
数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能
3、Leaf-segment 方案实现
Leaf-segment方案,在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大
- 改为利用批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力
- 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。
如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
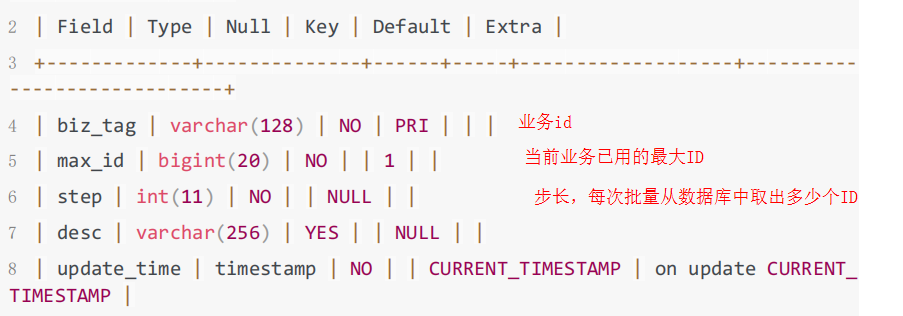
重要字段说明:
- biz_tag用来区分业务
- max_id表示该biz_tag目前所被分配的ID号段的最大值
- step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step
系统架构

优缺点:
优点:
- 将分配ID的压力由数据库转移到web服务(Leaf), Leaf服务可以很方便的进行线程扩展,性能完全能够支撑大多数业务场景
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全
- TP999数据波动大(当一个号段的ID使用完全后,leaf服务去mysql取号段,在此过程中应用服务如果有很大的并发过来,就会导致没有ID进行分配,从而导致响应时间变长,出现尖刺)
- DB宕机的话,整个系统不可使用
4、双 buffer 优化
对于第二个缺点(响应存在峰值),Leaf-segment做了一些优化,简单的说就是:
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的TP999指标。
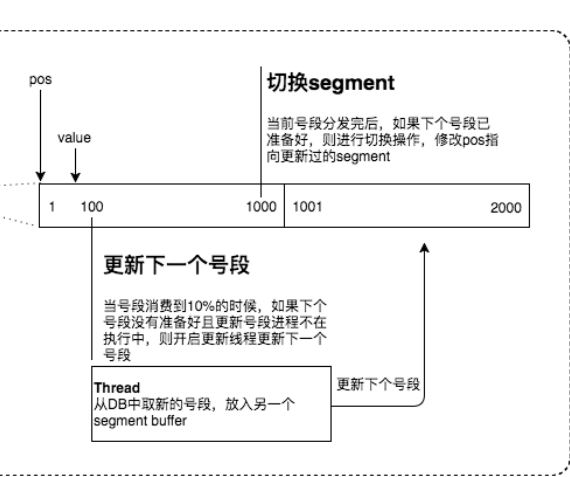
采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响
5、Leaf高可用容灾
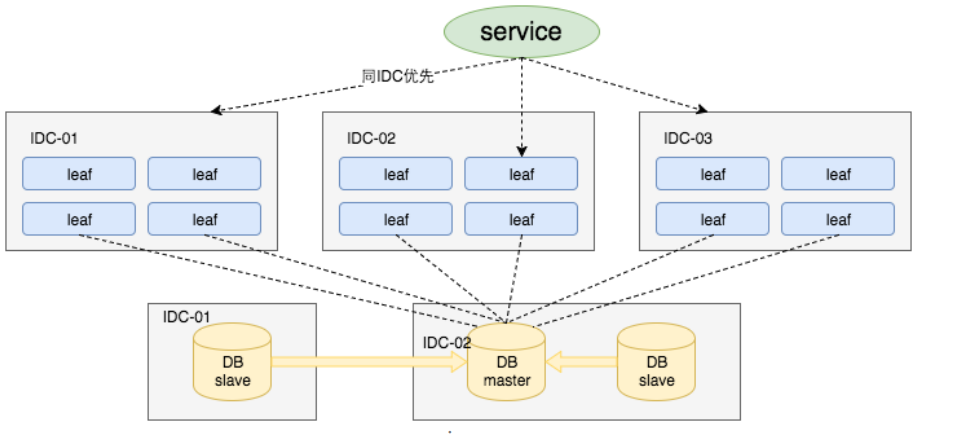
对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据
这里,我其实是没怎么听懂的 !即使使用了主从,在数据同步过程不是还会有ID重复吗
三、基于Redis实现分布式ID
四、雪花算法
1、雪花算法介绍
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
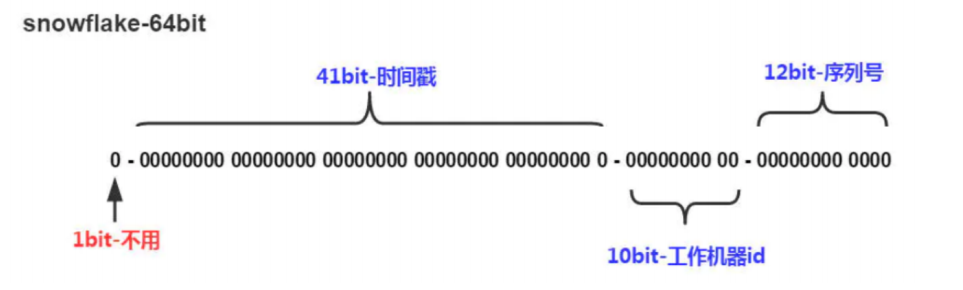
- 第1位:占用1bit,第一位为符号位,不使用。
- 第1部分:41位的时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可
用的时间年限是(2^41)/(1000606024365)=69 年的时间 - 第2部分:10-bit位可表示机器数,即2^10 = 1024台机器,通常不会部署这么多台机器。也可以划分为多个(比如前5位可以作为机房ID 0-31个机房,后5位作为每个机房的机器ID)
- 第3部分:12-bit位是自增序列,可表示2^12 = 4096个数。
41位时间戳是固定的,时间戳转二进制的长度是41位,后面两个部分都可以灵活调正,只要注意后面位运算的位数就行
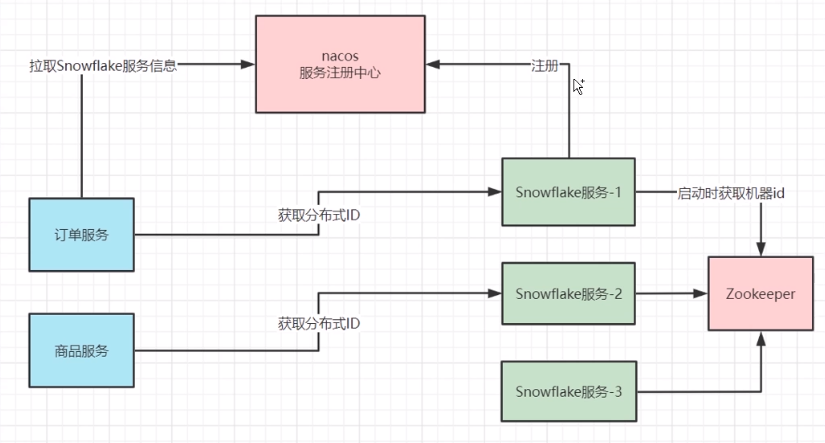
2、 雪花算法生产环境架构:
3、雪花算法的时钟回拨问题
回拨时间很短( <= 100ms)
让当前循环一段时间进行等待
回拨时间适中 (100ms < < 1s)
在内存中维护最近 每个 1ms 内的最大值
回拨时间较长 (1s < <= 5s)
结合雪花算法生产环境架构,当客户端段捕获到时钟回拨异常后,由客户端进行重试
时钟回拨时间很长 (> 5s)
直接将出问题的机器下线,然后发送短信告诉运维人员,这台机器出现问题
4、美团 Leaf-snowflake 方案
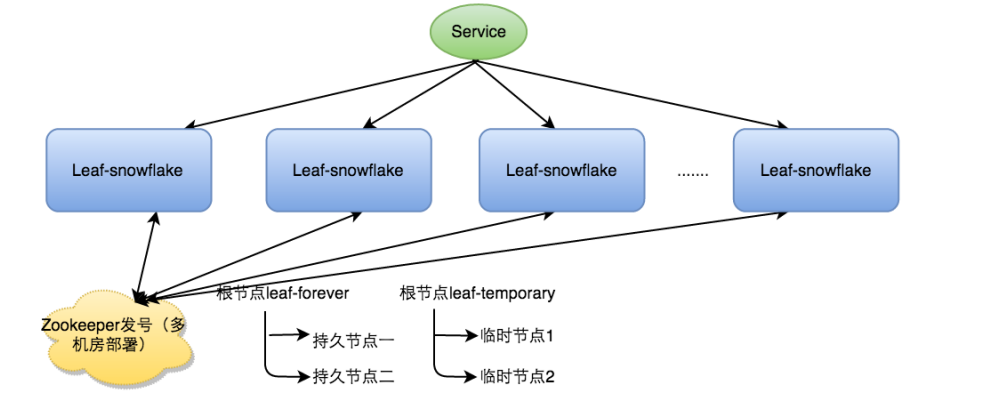
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
Leafsnowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
这一部分暂时没看懂,等会回来补充下!!!
相关文章:
分布式唯一ID实战
目录 一、UUID二、数据库方式1、数据库生成之简单方式2、数据库生成 - 多台机器和设置步长,解决性能问题3、Leaf-segment 方案实现4、双 buffer 优化5、Leaf高可用容灾 三、基于Redis实现分布式ID四、雪花算法1、雪花算法介绍2、 雪花算法生产环境架构:3…...

el-element日期时间组件限制可选时间范围
<el-date-pickerv-model"formData.meetingTime"type"datetime"value-format"yyyy-MM-dd HH:mm:ss"style"width: 100%"placeholder"请选择日期"clearable:picker-options"pickerOptions"></el-date-picke…...

【李沐】3.3线性回归的简洁实现
1、生成数据集 import numpy as np import torch from torch.utils import data from d2l import torch as d2l true_w torch.tensor([2, -3.4]) # 定义真实权重 true_w,其中 [2, -3.4] 表示两个特征的权重值 true_b 4.2 # 定义真实偏差 true_b,表示…...

Ghost-free High Dynamic Range Imaging withContext-aware Transformer
Abstract 高动态范围(HDR)去鬼算法旨在生成具有真实感细节的无鬼HDR图像。 受感受野局部性的限制,现有的基于CNN的方法在大运动和严重饱和度的情况下容易产生重影伪影和强度畸变。 本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态…...

过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!
[原文连接:来自给点知识](过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!) 再唱不出那样的歌曲 听到都会红着脸躲避 虽然会经常忘了我依然爱着你 …...

Cadence+硬件每日学习十个知识点(38)23.8.18 (Cadence的使用,界面介绍)
文章目录 1.Cadence有共享数据库的途径2.Cadence启动3.Cadence界面菜单简介(file、edit、view、place、options)4.Cadence界面的图标简介5.我的下载资源有三本书 1.Cadence有共享数据库的途径 答: AD缺少共享数据库的途径,目前我…...
React Native Expo项目,复制文本到剪切板
装包: npx expo install expo-clipboard import * as Clipboard from expo-clipboardconst handleCopy async (text) > {await Clipboard.setStringAsync(text)Toast.show(复制成功, {duration: 3000,position: Toast.positions.CENTER,})} 参考链接:…...
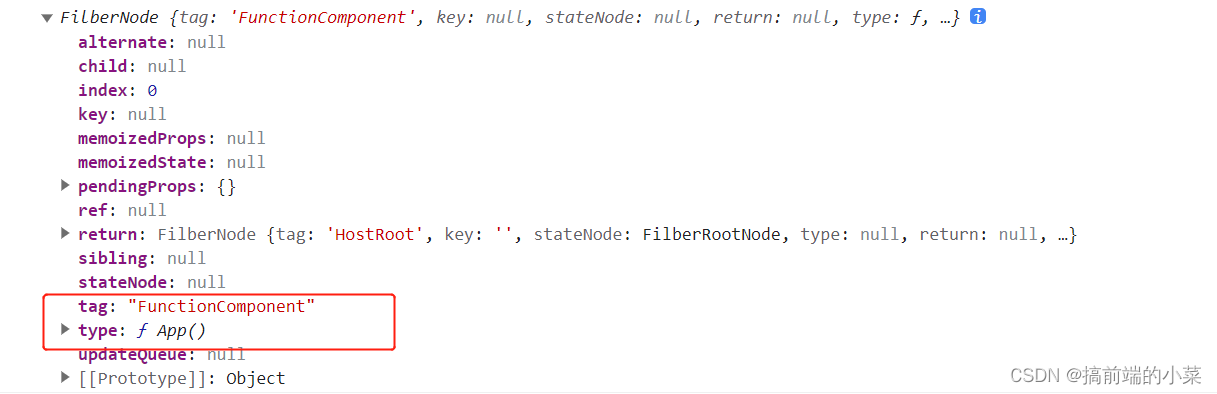
React源码解析18(5)------ 实现函数组件【修改beginWork和completeWork】
摘要 经过之前的几篇文章,我们实现了基本的jsx,在页面渲染的过程。但是如果是通过函数组件写出来的组件,还是不能渲染到页面上的。 所以这一篇,主要是对之前写得方法进行修改,从而能够显示函数组件,所以现…...
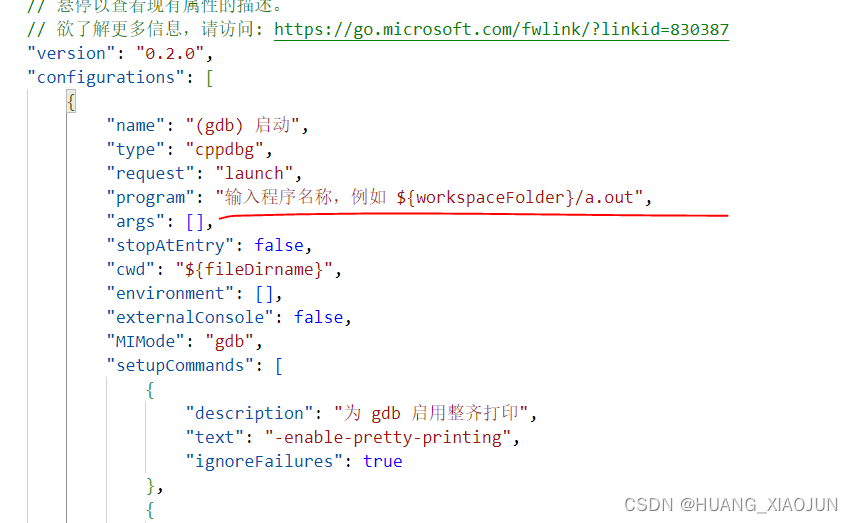
vscode ssh 远程 gdb 调试
一、点运行与调试,生成launch.json 文件 二、点添加配置,选择GDB 三、修改启动程序路径...
云原生 AI 工程化实践之 FasterTransformer 加速 LLM 推理
作者:颜廷帅(瀚廷) 01 背景 OpenAI 在 3 月 15 日发布了备受瞩目的 GPT4,它在司法考试和程序编程领域的惊人表现让大家对大语言模型的热情达到了顶点。人们纷纷议论我们是否已经跨入通用人工智能的时代。与此同时,基…...
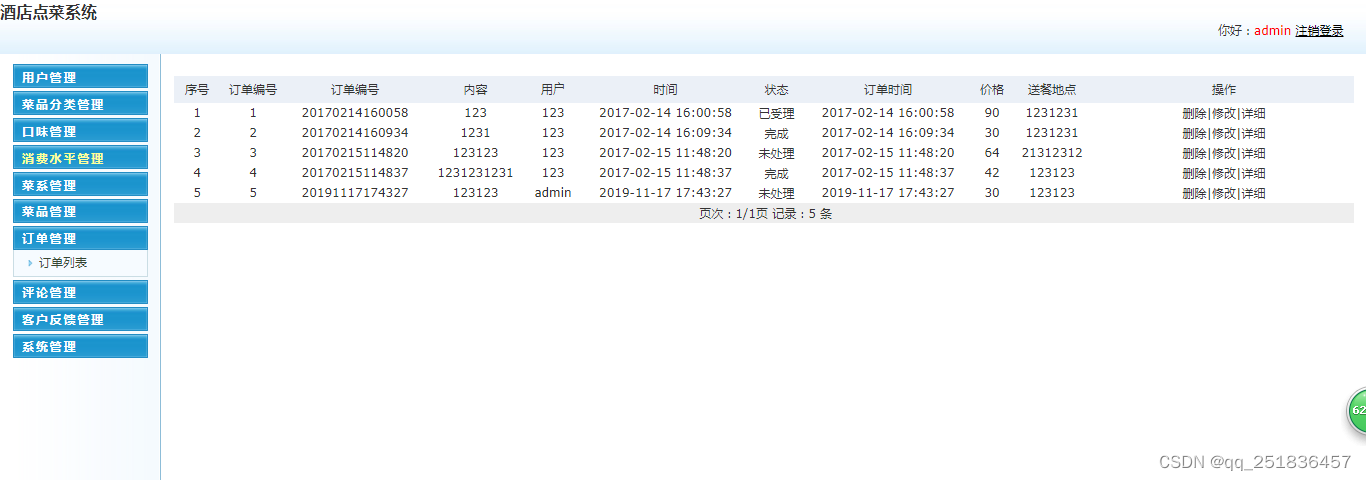
PHP酒店点菜管理系统mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP 酒店点菜管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 代码下载 https://download.csdn.net/download/qq_41221322/88232051 论文 https://…...

【面试复盘】知乎暑期实习算法工程师二面
来源:投稿 作者:LSC 编辑:学姐 1. 自我介绍 2. 介绍自己的项目 3. 编程题 判断一个链表是不是会文链表class ListNode: def __init__(self, val, nextNone):self.val valself.next nextdef reverse(head):pre Nonep headwhile p ! No…...

内网穿透和服务器+IP 实现公网访问内网的区别
内网穿透和服务器IP 实现公网访问内网的区别在于实现方式和使用场景。 内网穿透(Port Forwarding):内网穿透是一种通过网络技术将公网用户的请求通过中转服务器传输到内网设备的方法。通过在路由器或防火墙上进行配置,将公网请求…...

JAVA权限管理 助力企业精细化运营
在企业的日常经营中,企业人数达到一定数量之后,就需要对企业的层级和部门进行细分,建立企业的树形组织架构。围绕着树形组织架构,企业能够将权限落实到个人,避免企业内部出现管理混乱等情况。权限管理是每个企业管理中…...
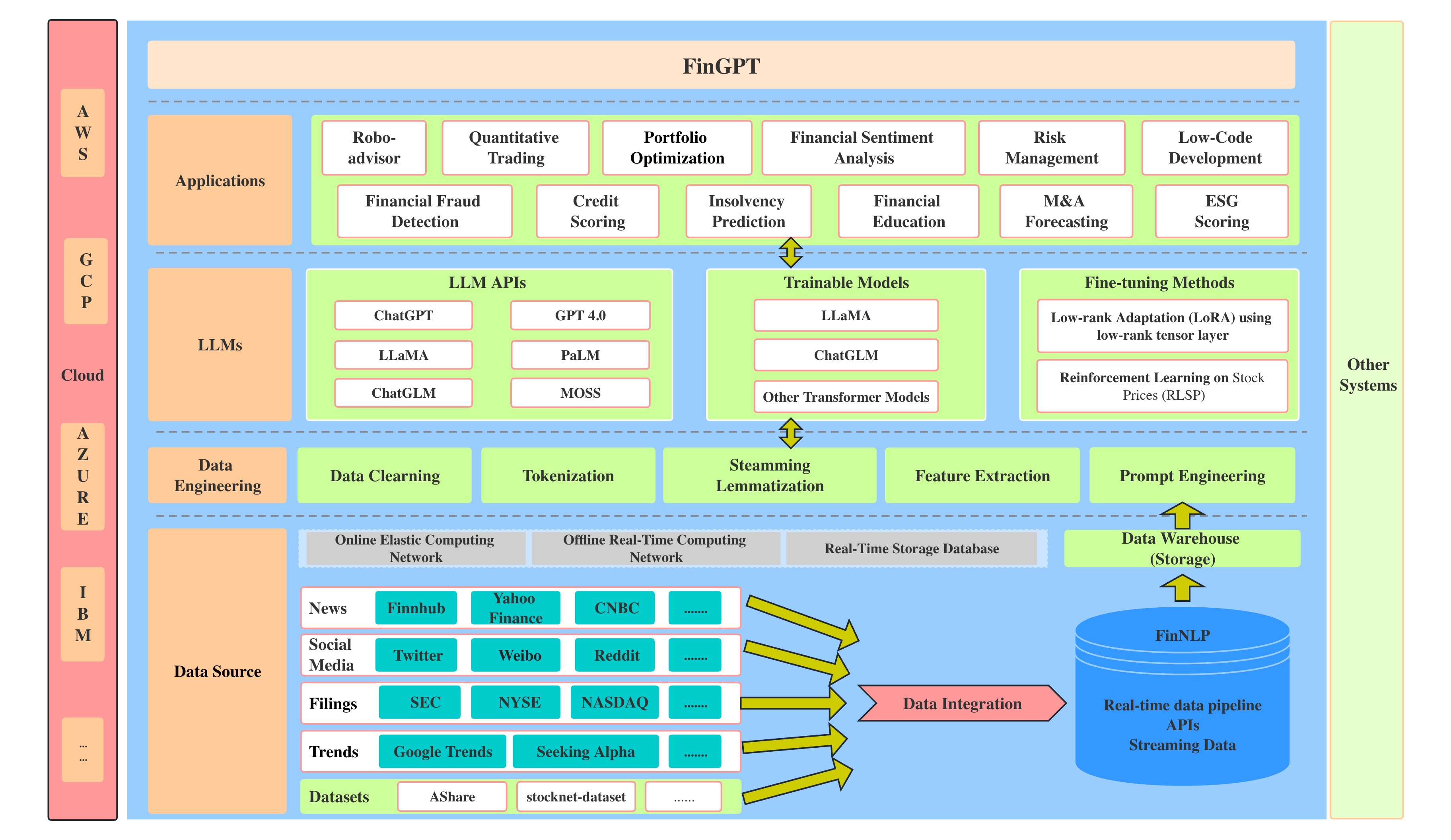
金融语言模型:FinGPT
项目简介 FinGPT是一个开源的金融语言模型(LLMs),由FinNLP项目提供。这个项目让对金融领域的自然语言处理(NLP)感兴趣的人们有了一个可以自由尝试的平台,并提供了一个与专有模型相比更容易获取的金融数据。…...

LeetCode--HOT100题(30)
目录 题目描述:24. 两两交换链表中的节点(中等)题目接口解题思路代码 PS: 题目描述:24. 两两交换链表中的节点(中等) 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节…...
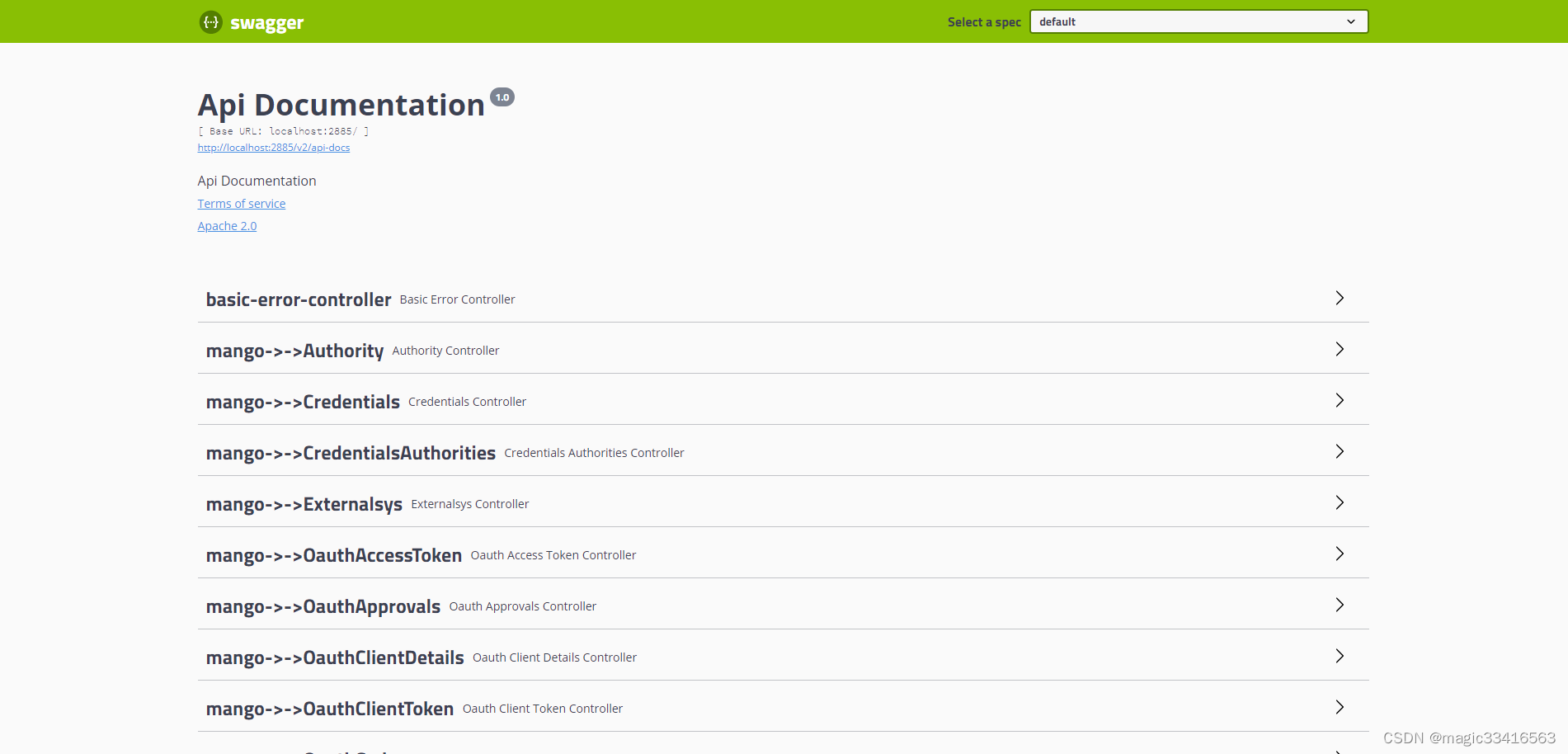
Springboot 实践(3)配置DataSource及创建数据库
前文讲述了利用MyEclipse2019开发工具,创建maven工程、加载springboot、swagger-ui功能。本文讲述创建数据库,为项目配置数据源,实现数据的增删改查服务,并通过swagger-ui界面举例调试服务控制器 创建数据库 项目使用MySQL 8.0.…...

【问题整理】Ubuntu 执行 apt-get install xxx 报错
Ubuntu 执行 apt-get install xxx 报错 一、问题描述: 执行apt-get install fcitx时,报如下错误 grub-pc E: Sub-process /usr/bin/dpkg returned an error code (1)二、解决方法: 尝试修复依赖问题: sudo apt-get -f install这个命令会尝试修复系统…...

Java课题笔记~ SpringBoot简介
1. 入门案例 问题导入 SpringMVC的HelloWord程序大家还记得吗? SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的初始搭建以及开发过程 原生开发SpringMVC程序过程 1.1 入门案例开发步骤 ①:创建新模块&#…...
)
一种基于springboot、redis的分布式任务引擎的实现(一)
总体思路是,主节点接收到任务请求,将根据任务情况拆分成多个任务块,将任务块标识的主键放入redis。发送redis消息,等待其他节点运行完毕,结束处理。接收到信息的节点注册本节点信息到redis、开启多线程、获取任务块、执…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...

[具身智能-766]:机器人在运动过程中需要实时定位,AMCL 每一次都需要全局撒粒子重搜吗?还是一旦定位后,后续的移动过程中,只需要局部匹配?
直白结论完全不需要每次全局撒粒子重搜定位成功稳定后,机器人全程只做局部小范围匹配,只有丢位置、被挪动时,才会重新全局撒粒子搜索。一、分两种状态1. 正常行走(已定位成功)粒子只聚集在机器人真实位置周边很小一片区…...

解密Jsxer:如何高效反编译Adobe JSXBIN二进制脚本
解密Jsxer:如何高效反编译Adobe JSXBIN二进制脚本 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一个快速准确的JSXBIN反编译器,专门用于将Adobe ExtendScript的二进…...