云原生 AI 工程化实践之 FasterTransformer 加速 LLM 推理
作者:颜廷帅(瀚廷)
01 背景
OpenAI 在 3 月 15 日发布了备受瞩目的 GPT4,它在司法考试和程序编程领域的惊人表现让大家对大语言模型的热情达到了顶点。人们纷纷议论我们是否已经跨入通用人工智能的时代。与此同时,基于大语言模型的应用也如雨后春笋般出现,为我们带来了协同办公、客服对话、语言翻译、内容生成等方面前所未有的畅快体验。
然而,当我们享受着大语言模型带来的普惠 AI 能力时,它也给开发者们带来了前所未有的挑战。随着模型不断增大,计算量也达到了空前的高度,直接导致推理时间变长。为了解决大语言模型推理的延迟问题,业界已经提供了一些解决方案,比如 Tensorrt、FasterTransformer 和 vllm。为了帮助用户解决云原生系统中的大语言模型推理加速问题,云原生 AI 套件引入了 FasterTransformer 推理加速方案。
本文将在 ACK 容器服务上,以 Bloom7B1 模型为例展示如何使用 FasterTransformer 进行推理加速。本例中会使用以下组件:
- Arena
Arena 是基于 Kubernetes 的机器学习轻量级解决方案,支持数据准备、模型开发,模型训练、模型预测的完整生命周期,提升数据科学家工作效率。同时和阿里云的基础云服务深度集成,支持 GPU 共享、CPFS 等服务,可以运行阿里云优化的深度学习框架,最大化使用阿里云异构设备的性能和成本的效益。更多 arena 信息,可以参考云原生 AI 套件开发者使用指南 [ 1] 。
- Triton Server
Triton Server为Nvidia 提供了机器学习推理引擎,可以支持 Tensorflow、Pytorch、Tensorrt 和 Fastertransformer 多种 backend。云原生 AI 套件已经将 Triton Server 加入到 Arena 中,用户可以通过简单的命令行或 SDK 来在云原生系统中完成 Triton Server 服务的拉起、运维和监控。更多 AI 套件中使用 Triton Server 信息,可以参考部署 PyTorch 模型推理服务 [ 2] 。
- FasterTransformer
FasterTransformer 是真对于 Transofrmer 类型模型(也包括 encoder-only、decoder-only)的推理加速方案,其提供了 Kernel Fuse、Memory reuse、kv cache、量化等多种优化方案,同时也提供了 Tensor Parallel 和 Pipeline Parallel 两种分布式推理方案。本文将介绍如何在云原生 AI 套件中使用 FasterTransformer 进行模型的推理加速。
02 环境准备
环境准备分为两个部分,第一个部分是创建包含 GPU 的 Kubernetes 集群 [ 3] 和安装云原生 AI 套件 [ 4] ,第二个部分是从 huggingface 官网下载 bloom-7b1 模型。
模型的下载命令如下:
git lfs install
git clone git@hf.co:bigscience/bloom-7b1
通过上面的命令,可以将 huggingface repo 中的文件下载到本地:
下载完成后,我们将 bloom-71 文件夹上传到 OSS 中,作为推理时的共享存储,OSS 的使用可以参考开始使用 OSS [ 5] 。
上传到 OSS 之后,分别创建名称为 bloom7b1-pv 和 bloom7b1-pvc 的 PV 和 PVC,以用于推理服务的容器挂载。具体操作,请参见使用 OSS 静态存储卷 [ 6] 。
03 模型转换
FasterTransformer 本质上是对模型的重写,它通过 CUDA、cuDNN 和 cuBLAS 重写了 Transformer 模型结构,因此其具有自己的模型结构和模型参数的描述方式。而我们的模型一般是通过 Pytorch、Tesorflow、Megatron 或 huggingface 这样的训练框架产出,其往往又具有自己单独的一套模型结构和参数的表达,因此在使用FasterTransformer时,就需要将模型原有的 checkpoint 转换为 FasterTransformer 的结构。
FasterTransformer 中已经支持了多种类型的转换脚本,这里我们使用 FasterTransofrmer 提供的 examples/pytorch/gpt/utils/huggingface_bloom_convert.py。
云原生 AI 套件已经接入了上述的转换逻辑,因此,通过如下脚本即可完成一次模型的转换。
arena submit pytorchjob\--gpus=1\--image ai-studio-registry.cn-beijing.cr.aliyuncs.com/kube-ai/fastertransformer:torch-0.0.1\--name convert-bloom\--workers 1\--namespace default-group\--data bloom-pvc:/mnt\'python /FasterTransformer/examples/pytorch/gpt/utils/huggingface_bloom_convert.py -i /mnt/model/bloom-7b1 -o /mnt/model/bloom-7b1-ft-fp16 -tp 2 -dt fp16 -p 64 -v'
通过 arena log 来观察转换的日志:
$arena logs -n default-group convert-bloom
======================= Arguments =======================- input_dir...........: /mnt/model/bloom-7b1- output_dir..........: /mnt/model/bloom-7b1-ft-fp16- tensor_para_size....: 2- data_type...........: fp16- processes...........: 64- verbose.............: True- by_shard............: False
=========================================================
loading from pytorch bin format
model file num: 2- model.pre_decoder_layernorm.bias................: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.pre_decoder_layernorm.bias.bin- model.layers.0.input_layernorm.weight...........: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.input_layernorm.weight.bin- model.layers.0.attention.dense.bias.............: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.attention.dense.bias.bin- model.layers.0.input_layernorm.bias.............: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.input_layernorm.bias.bin- model.layers.0.attention.query_key_value.bias...: shape (3, 2048) s | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.attention.query_key_value.bias.0.bin (0/2)- model.layers.0.post_attention_layernorm.weight..: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.post_attention_layernorm.weight.bin- model.layers.0.post_attention_layernorm.bias....: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.post_attention_layernorm.bias.bin- model.layers.0.mlp.dense_4h_to_h.bias...........: shape (4096,) | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.mlp.dense_4h_to_h.bias.bin- model.layers.0.mlp.dense_h_to_4h.bias...........: shape (8192,) s | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.mlp.dense_h_to_4h.bias.0.bin (0/2)- model.layers.0.attention.query_key_value.bias...: shape (3, 2048) s | saved at /mnt/model/bloom-7b1-ft-fp16/2-gpu/model.layers.0.attention.query_key_value.bias.1.bin (1/2)
通过 arena list 命令查看转换是否执行结束:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE
convert-bloom SUCCEEDED PYTORCHJOB 3m 1 N/A 192.168.123.35
转换完成后,会在 OSS 上创建一个 model/arena/bloom-7b1-ft-fp16 文件夹,文件中会存储 FasterTransofrmer 所对应的 checkpoint。
04 性能对比
此时,我们的 OSS 上已经有两份 bloom-7b1 checkpoint,一份是 bloom-7b 文件夹存储了 huggingface 原生的 checkpoint,另一份是 bloom-7b-ft-fp16 文件夹存储了转换后的 FasterTransformer 的 checkpoint。我们将使用这两份 checkpoint 进行性能对比,看一下来 FasterTransformer 是否能够带来性能的提升。
性能对比使用 Fastertransformer 提供的 examples/pytorch/gpt/bloom_lambada.py,我们也已经集成到了 AI 套件中。这里我们分别提交两个性能评测命令。对 Huggingface Bloom-7b1 评测的命令:
arena submit pytorchjob\--gpus=2\--image ai-studio-registry.cn-beijing.cr.aliyuncs.com/kube-ai/fastertransformer:torch-0.0.1\--name perf-hf-bloom \--workers 1\--namespace default-group\--data bloom7b1-pvc:/mnt\'python /FasterTransformer/examples/pytorch/gpt/bloom_lambada.py \--tokenizer-path /mnt/model/bloom-7b1 \--dataset-path /mnt/data/lambada/lambada_test.jsonl \--batch-size 16 \--test-hf \--show-progress'
查看 HuggingFace 的结果:
$arena -n default-group logs -t 5 perf-hf-bloom
Accuracy: 57.5587% (2966/5153) (elapsed time: 173.2149 sec)
对 Fastertransformer Blooom-7b 评测的命令:
arena submit pytorchjob\--gpus=2\--image ai-studio-registry.cn-beijing.cr.aliyuncs.com/kube-ai/fastertransformer:torch-0.0.1\--name perf-ft-bloom \--workers 1\--namespace default-group\--data bloom7b1-pvc:/mnt\'mpirun --allow-run-as-root -n 2 python /FasterTransformer/examples/pytorch/gpt/bloom_lambada.py \--lib-path /FasterTransformer/build/lib/libth_transformer.so \--checkpoint-path /mnt/model/2-gpu \--batch-size 16 \--tokenizer-path /mnt/model/bloom-7b1 \--dataset-path /mnt/data/lambada/lambada_test.jsonl \--show-progress'
查看 FasterTransformer 的结果,可以看见带来了 2.5 倍的性能提升。
$arena -n default-group logs -t 5 perf-ft-bloom
Accuracy: 57.6363% (2970/5153) (elapsed time: 68.7818 sec)
通过结果对比可以看见,Fastertransformer 与原生的 Huggingface 相比有比较明显的性能提升。
05 模型部署
在这一小节,我们使用 Triton Server 对 FasterTransformer 进行部署,Triton Server 中原生并不支持 FasterTransformer 的 backend,需要我们配合 Nvidia 提供的 Fastertransformer backend 来使用。通过使用 FasterTransformer backend,Triton Server 不再进行 GPU 资源的分配,FasterTransformer backend 会根据 CUDA_VISIBLE_DEVICES 判断当前可用 GPU 资源,并分配给对应的 RANK 来执行分布式的推理。
FasterTransformer 对应的模型 Repo 目录如下所示:
├── model_repo
│ └── fastertransformer
│ ├── 1
│ │ └── config.ini
│ └── config.pbtxt
使用功能 Arena 的如下命令来启动 FasterTransformer:
arena serve triton \--namespace=default-group \--version=1 \--data=bloom7b1-pvc:/mnt \--name=ft-triton-bloom \--allow-metrics \--gpus=2 \--replicas=1 \--image=ai-studio-registry.cn-beijing.cr.aliyuncs.com/kube-ai/triton_with_ft:22.03-main-2edb257e-transformers \--model-repository=/mnt/triton_repo
通过 kubectl logs,我们可以看到 triton server 的部署日志,通过日志可以看到,triton server 启动了两个 gpu 来进行分布式推理。
I0721 08:57:28.116291 1 pinned_memory_manager.cc:240] Pinned memory pool is created at '0x7fd264000000' with size 268435456
I0721 08:57:28.118393 1 cuda_memory_manager.cc:105] CUDA memory pool is created on device 0 with size 67108864
I0721 08:57:28.118403 1 cuda_memory_manager.cc:105] CUDA memory pool is created on device 1 with size 67108864
I0721 08:57:28.443529 1 model_lifecycle.cc:459] loading: fastertransformer:1
I0721 08:57:28.625253 1 libfastertransformer.cc:1828] TRITONBACKEND_Initialize: fastertransformer
I0721 08:57:28.625307 1 libfastertransformer.cc:1838] Triton TRITONBACKEND API version: 1.10
I0721 08:57:28.625315 1 libfastertransformer.cc:1844] 'fastertransformer' TRITONBACKEND API version: 1.10
I0721 08:57:28.627137 1 libfastertransformer.cc:1876] TRITONBACKEND_ModelInitialize: fastertransformer (version 1)
I0721 08:57:28.628304 1 libfastertransformer.cc:372] Instance group type: KIND_CPU count: 1
I0721 08:57:28.628326 1 libfastertransformer.cc:402] Sequence Batching: disabled
I0721 08:57:28.628334 1 libfastertransformer.cc:412] Dynamic Batching: disabled
I0721 08:57:28.661657 1 libfastertransformer.cc:438] Before Loading Weights:
+-------------------+-----------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Backend | Path | Config |
+-------------------+-----------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| fastertransformer | /opt/tritonserver/backends/fastertransformer/libtriton_fastertransformer.so | {"cmdline":{"auto-complete-config":"true","min-compute-capability":"6.000000","backend-directory":"/opt/tritonserver/backends","default-max-batch-size":"4"}} |
+-------------------+-----------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+I0721 09:01:19.653743 1 server.cc:633]
+-------------------+---------+--------+
| Model | Version | Status |
after allocation : free: 7.47 GB, total: 15.78 GB, used: 8.31 GB
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+I0721 09:01:19.668137 1 metrics.cc:864] Collecting metrics for GPU 0: Tesla V100-SXM2-16GB
I0721 09:01:19.668167 1 metrics.cc:864] Collecting metrics for GPU 1: Tesla V100-SXM2-16GB
I0721 09:01:19.669954 1 metrics.cc:757] Collecting CPU metrics
I0721 09:01:19.670150 1 tritonserver.cc:2264]
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.29.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics trace logging |
| model_repository_path[0] | /mnt/triton_repo |
| model_control_mode | MODE_NONE |
| strict_model_config | 0 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| cuda_memory_pool_byte_size{1} | 67108864 |
| response_cache_byte_size | 0 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+I0721 09:01:19.672326 1 grpc_server.cc:4819] Started GRPCInferenceService at 0.0.0.0:8001
I0721 09:01:19.672597 1 http_server.cc:3477] Started HTTPService at 0.0.0.0:8000
I0721 09:01:19.714356 1 http_server.cc:184] Started Metrics Service at 0.0.0.0:8002
06 服务请求
启动 forward 进行验证:
# 使用 kubectl 启动port-forward
kubectl -n default-group port-forward svc/ft-triton-bloom-1-tritoninferenceserver 8001:8001
这里我们使用 Triton Server 提供的 python SDK 所编写的脚本来向 Triton Server 发起请求。脚本中主要完成三件事情:
- 通过 huggingface 中 bloom-7b1 对应的分词器对 query 进行分词和 token 转换
- 通过 triton server SDK 向 triton server 发起请求
- 通过分词器对 output token 进行转换,拿到最终的结果
import os, sys
#from tkinter import _Padding
import numpy as np
import json
import torch
#import tritongrpcclient
import argparse
import time
from transformers import AutoTokenizer
import tritonclient.grpc as grpcclient# create tokenizer
tokenizer = AutoTokenizer.from_pretrained('/mnt/model/bloom-7b1', padding_side='right')
tokenizer.pad_token_id = tokenizer.eos_token_iddef load_image(img_path: str):"""Loads an encoded image as an array of bytes."""return np.fromfile(img_path, dtype='uint8')def tokeninze(query):# encodeencoded_inputs = tokenizer(query, padding=True, return_tensors='pt')input_token_ids = encoded_inputs['input_ids'].int()input_lengths = encoded_inputs['attention_mask'].sum(dim=-1, dtype=torch.int32).view(-1, 1)return input_token_ids.numpy().astype('uint32'), input_lengths.numpy().astype('uint32')if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--model_name",type=str,required=False,default="fastertransformer",help="Model name")parser.add_argument("--url",type=str,required=False,default="localhost:8001",help="Inference server URL. Default is localhost:8001.")parser.add_argument('-v',"--verbose",action="store_true",required=False,default=False,help='Enable verbose output')args = parser.parse_args()# 1.创建clienttry:triton_client = grpcclient.InferenceServerClient(url=args.url, verbose=args.verbose)except Exception as e:print("channel creation failed: " + str(e))sys.exit(1)output_name = "OUTPUT"# 2) 设置inputinputs = []## 2.1) input_idsquery="deepspeed is"input_ids, input_lengths = tokeninze(query)inputs.append(grpcclient.InferInput("input_ids", input_ids.shape, "UINT32"))inputs[0].set_data_from_numpy(input_ids)## 2.2) input_lengthinputs.append(grpcclient.InferInput("input_lengths", input_lengths.shape, "UINT32"))inputs[1].set_data_from_numpy(input_lengths)## 2.3) output lengthoutput_len=32output_len_np = np.array([[output_len]], dtype=np.uintc)inputs.append(grpcclient.InferInput("request_output_len", output_len_np.shape, "UINT32"))inputs[2].set_data_from_numpy(output_len_np)# 3) 设置outputoutputs = []outputs.append(grpcclient.InferRequestedOutput("output_ids"))# 4) 发起请求start_time = time.time()results = triton_client.infer(model_name=args.model_name, inputs=inputs, outputs=outputs)latency = time.time() - start_time# 5) 结果处理:转化为numpy 类型,计算max,转化labeloutput0_data = results.as_numpy("output_ids")print(output0_data.shape)result = tokenizer.batch_decode(output0_data[0])print(result)
发起 client 请求命令如下:
$python3 bloom_7b_client.py
(1, 1, 36)
['deepspeed is the speed of the ship at the time of the collision, and the\ndeepspeed of the other ship is the speed of the other ship
at the time']
07 总结
本文我们通过 Bloom-7b1 模型展示了如何在云原生 AI 套件中使用 FasterTransformer 对大语言模型进行加速,通过与 HuggingFace 的版本对比可以带来 2.5 倍的性能提升。后续我们会逐步推出更多大模型相关的推理加速方案,以满足不同的业务需求,大家敬请期待。
如果您对 Bloom 模型的微调训练感兴趣,您也可以点击阅读原文,参与实验场景,体验一键训练大模型及部署 GPU 共享推理服务。
另外,欢迎加入云原生 AI 套件客户交流钉钉群同我们一起探讨(群号:33214567)。
相关链接:
[1] 云原生 AI 套件开发者使用指南
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/getting-started/cloud-native-ai-component-set-user-guide
[2] 部署 PyTorch 模型推理服务
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/deploy-a-pytorch-model-as-an-inference-service?spm=a2c4g.11186623.0.0.2267225carYzgA
[3] 创建包含 GPU 的 Kubernetes 集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/use-gpu-scheduling-in-ack-clusters#task-1664343
[4] 安装云原生 AI 套件
https://help.aliyun.com/document_detail/212117.htm#task-1917487
[5] 开始使用 OSS
https://help.aliyun.com/zh/oss/getting-started/getting-started-with-oss
[6] 使用 OSS 静态存储卷
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/mount-statically-provisioned-oss-volumes
点击此处,体验一键训练大模型及部署 GPU 共享推理服务。
相关文章:
云原生 AI 工程化实践之 FasterTransformer 加速 LLM 推理
作者:颜廷帅(瀚廷) 01 背景 OpenAI 在 3 月 15 日发布了备受瞩目的 GPT4,它在司法考试和程序编程领域的惊人表现让大家对大语言模型的热情达到了顶点。人们纷纷议论我们是否已经跨入通用人工智能的时代。与此同时,基…...
PHP酒店点菜管理系统mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP 酒店点菜管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 代码下载 https://download.csdn.net/download/qq_41221322/88232051 论文 https://…...

【面试复盘】知乎暑期实习算法工程师二面
来源:投稿 作者:LSC 编辑:学姐 1. 自我介绍 2. 介绍自己的项目 3. 编程题 判断一个链表是不是会文链表class ListNode: def __init__(self, val, nextNone):self.val valself.next nextdef reverse(head):pre Nonep headwhile p ! No…...

内网穿透和服务器+IP 实现公网访问内网的区别
内网穿透和服务器IP 实现公网访问内网的区别在于实现方式和使用场景。 内网穿透(Port Forwarding):内网穿透是一种通过网络技术将公网用户的请求通过中转服务器传输到内网设备的方法。通过在路由器或防火墙上进行配置,将公网请求…...

JAVA权限管理 助力企业精细化运营
在企业的日常经营中,企业人数达到一定数量之后,就需要对企业的层级和部门进行细分,建立企业的树形组织架构。围绕着树形组织架构,企业能够将权限落实到个人,避免企业内部出现管理混乱等情况。权限管理是每个企业管理中…...
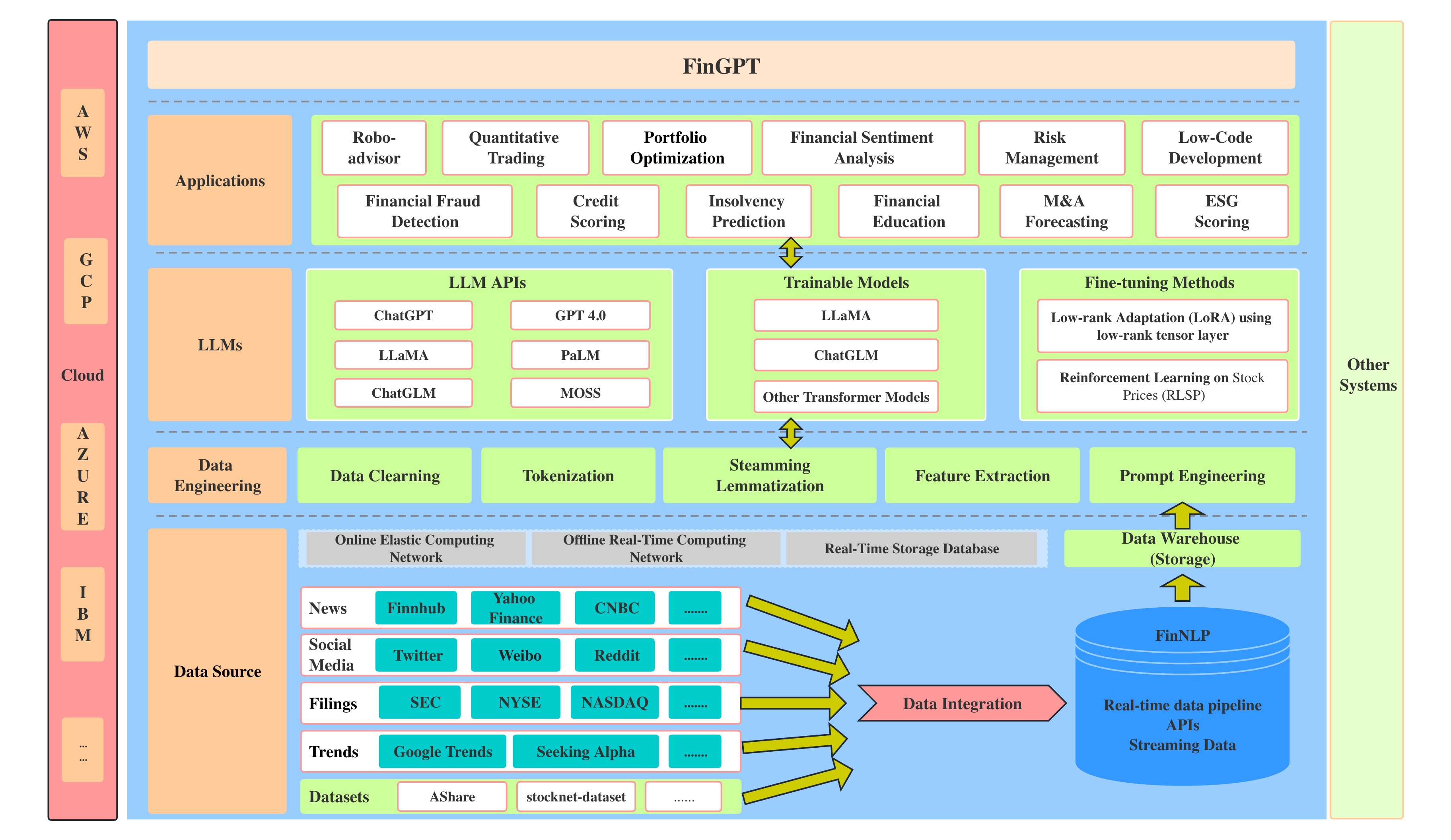
金融语言模型:FinGPT
项目简介 FinGPT是一个开源的金融语言模型(LLMs),由FinNLP项目提供。这个项目让对金融领域的自然语言处理(NLP)感兴趣的人们有了一个可以自由尝试的平台,并提供了一个与专有模型相比更容易获取的金融数据。…...

LeetCode--HOT100题(30)
目录 题目描述:24. 两两交换链表中的节点(中等)题目接口解题思路代码 PS: 题目描述:24. 两两交换链表中的节点(中等) 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节…...
Springboot 实践(3)配置DataSource及创建数据库
前文讲述了利用MyEclipse2019开发工具,创建maven工程、加载springboot、swagger-ui功能。本文讲述创建数据库,为项目配置数据源,实现数据的增删改查服务,并通过swagger-ui界面举例调试服务控制器 创建数据库 项目使用MySQL 8.0.…...

【问题整理】Ubuntu 执行 apt-get install xxx 报错
Ubuntu 执行 apt-get install xxx 报错 一、问题描述: 执行apt-get install fcitx时,报如下错误 grub-pc E: Sub-process /usr/bin/dpkg returned an error code (1)二、解决方法: 尝试修复依赖问题: sudo apt-get -f install这个命令会尝试修复系统…...

Java课题笔记~ SpringBoot简介
1. 入门案例 问题导入 SpringMVC的HelloWord程序大家还记得吗? SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的初始搭建以及开发过程 原生开发SpringMVC程序过程 1.1 入门案例开发步骤 ①:创建新模块&#…...
)
一种基于springboot、redis的分布式任务引擎的实现(一)
总体思路是,主节点接收到任务请求,将根据任务情况拆分成多个任务块,将任务块标识的主键放入redis。发送redis消息,等待其他节点运行完毕,结束处理。接收到信息的节点注册本节点信息到redis、开启多线程、获取任务块、执…...
基于IDE Eval Resetter延长IntelliJ IDEA等软件试用期的方法(包含新版本软件的操作方法)
本文介绍基于IDE Eval Resetter插件,对集成开发环境IntelliJ IDEA等JetBrains公司下属的多个开发软件,加以试用期延长的方法。 我们这里就以IntelliJ IDEA为例,来介绍这一插件发挥作用的具体方式。不过,需要说明使用IDE Eval Rese…...

RocketMQ消费者可以手动消费但无法主动消费问题,或生成者发送超时
1.大多数是配置问题 修改rocketmq文件夹broker.conf 2.配置与集群IP或本地IPV4一样 重启 在RocketMQ独享实例中支持IPv4和IPv6双栈,主要是通过在网络层面上同时支持IPv4和IPv6协议栈来实现的。RocketMQ的Broker端、Namesrv端和客户端都需要支持IPv4和IPv6协议&…...

【数据库系统】--【2】DBMS架构
DBMS架构 01DBMS架构概述02 DBMS的物理架构03 DBMS的运行和数据架构DBMS的运行架构DBMS的数据架构PostgreSQL的体系结构RMDB的运行架构 04DBMS的逻辑和开发架构DBMS的层次结构DBMS的开发架构DBMS的代码架构 05小结 01DBMS架构概述 02 DBMS的物理架构 数据库系统的体系结构 数据…...
第三章 图论 No.13拓扑排序
文章目录 裸题:1191. 家谱树差分约束拓扑排序:1192. 奖金集合拓扑序:164. 可达性统计差分约束拓扑序:456. 车站分级 拓扑序和DAG有向无环图联系在一起,通常用于最短/长路的线性求解 裸题:1191. 家谱树 119…...

喜报 | 擎创再度入围IDC中国FinTech 50榜单
8月16日,2023年度“IDC中国FinTech 50”榜单正式揭晓,擎创科技继2022年入选该榜单后,再次以创新者姿态成功入选,并以技术赋能业务创新,成为中国金融科技领域创新与活力的重要贡献者。 “IDC中国FinTech 50”旨在评选出…...

【C++ 记忆站】引用
文章目录 一、引用概念二、引用特性1、引用在定义时必须初始化2、一个变量可以有多个引用3、引用一旦引用一个实体,再不能引用其他实体 三、常引用四、使用场景1、做参数1、输出型参数2、大对象传参 2、做返回值1、传值返回2、传引用返回 五、传值、传引用效率比较六…...

Hlang--用Python写个编程语言-变量的实现
文章目录 前言语法规则表示次幂实现变量实现优先级实现步骤解析关键字语法解析解释器总结前言 先前的话,我们终于是把我们整个架子搭起来了,这里重复一下我们的流程,那就是,首先,我们通过解析文本,然后呢遍历文本当中的我们定义的合法关键字,然后呢,把他们封装为一个T…...

多维时序 | MATLAB实现PSO-CNN-BiLSTM多变量时间序列预测
多维时序 | MATLAB实现PSO-CNN-BiLSTM多变量时间序列预测 目录 多维时序 | MATLAB实现PSO-CNN-BiLSTM多变量时间序列预测基本介绍模型特点程序设计参考资料 基本介绍 本次运行测试环境MATLAB2021b,MATLAB实现PSO-CNN-BiLSTM多变量时间序列预测。代码说明:…...

实现Java异步调用的高效方法
文章目录 为什么需要异步调用?Java中的异步编程方式1. 使用多线程2. 使用Java异步框架 异步调用的关键细节结论 🎉欢迎来到Java学习路线专栏~实现Java异步调用的高效方法 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...

开源技能图谱工具SkillPort:Go语言构建的知识管理利器
1. 项目概述:一个技能图谱与知识管理的开源利器 最近在整理个人技术栈和团队知识库时,我一直在寻找一个能直观展示技能关联、又能深度管理学习路径的工具。市面上的笔记软件要么太“平”,只能线性记录;要么太“重”,像…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

Linux光标主题管理工具x-cursor-help:从原理到实战
1. 项目概述:一个被低估的鼠标光标辅助工具如果你在Linux桌面环境下工作,尤其是使用像GNOME、KDE Plasma这类现代化的桌面环境,你可能会遇到一个不大不小但很恼人的问题:鼠标光标主题的安装和管理。从网上下载了一个漂亮的.tar.gz…...

边缘计算赋能工业智能化:重大危险源监测+产线控制+视觉分析一体化解决方案
在工业 4.0 与智能制造深度融合的今天,工业现场产生的数据量呈指数级增长。传统的 "云端集中式" 数据处理架构在面对毫秒级实时控制、海量视觉数据传输、高危场景 724 小时不间断监测等需求时,逐渐暴露出延迟高、带宽成本大、网络依赖强、数据…...

AI Agent在科学研究中的辅助作用
AI Agent在科学研究中的辅助作用 关键词:AI Agent, 科学研究辅助, 自主代理架构, 多模态推理, 文献挖掘, 实验设计, 未来展望 摘要:本文将像给小学生讲魔法实验室故事一样,深入浅出地拆解AI Agent这个“超级科研小助手天团”的核心原理、架构…...
)
ElevenLabs匈牙利语音合成效果深度测评(实测12种场景+WAV/MP3/SSML对比数据)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利语音合成技术概览 ElevenLabs 自 2023 年起逐步扩展其多语言支持能力,匈牙利语(hu-HU)作为东欧高复杂度音系语言的代表,于 v2.5 API 版本…...

使用taotoken聚合api后模型响应延迟的实际体感观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken聚合api后模型响应延迟的实际体感观察 作为一名日常需要调用多种大模型API的开发者,将多个供应商的API接入…...
)
保姆级教程:用沁恒CH34xSerCfg工具自定义你的USB转串口设备(VID/PID/序列号)
从零玩转沁恒CH34x芯片:深度定制你的USB转串口设备全攻略 每次插入相同的USB转TTL模块,电脑却分配不同的COM端口号?团队协作时多个同型号设备互相干扰?这些困扰硬件开发者多年的痛点,其实通过沁恒CH34x系列芯片的深度配…...