【100天精通python】Day41:python网络爬虫开发_爬虫基础入门
目录
专栏导读
1网络爬虫概述
1.1 工作原理
1.2 应用场景
1.3 爬虫策略
1.4 爬虫的挑战
2 网络爬虫开发
2.1 通用的网络爬虫基本流程
2.2 网络爬虫的常用技术
2.3 网络爬虫常用的第三方库
3 简单爬虫示例
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1网络爬虫概述
网络爬虫(Web Crawler),也称为网络蜘蛛、网络机器人,是一种自动化程序,用于在互联网上浏览和抓取信息。爬虫可以遍历网页,收集数据,提取信息,以便于进一步处理和分析。网络爬虫在搜索引擎、数据采集、信息监测等领域发挥着重要作用。
1.1 工作原理
初始URL选择: 爬虫从一个或多个初始URL开始,这些URL通常是你希望开始爬取的网站的主页或其他页面。
发送HTTP请求: 对于每个初始URL,爬虫会发送HTTP请求以获取网页内容。请求可以包括GET、POST等不同的HTTP方法,也可以设置请求头、参数和Cookies等。
接收HTTP响应: 服务器将返回一个HTTP响应,其中包含网页的HTML代码和其他资源,如图片、CSS、JavaScript等。
解析网页内容: 爬虫使用HTML解析库(如Beautiful Soup或lxml)解析接收到的HTML代码,将其转换为文档对象模型(DOM)结构。
数据提取和处理: 通过DOM结构,爬虫从网页中提取所需的信息,如标题、正文、链接、图片等。这可以通过CSS选择器、XPath等方法实现。
存储数据: 爬虫将提取的数据存储到本地文件、数据库或其他存储系统中,以供后续分析和使用。
发现新链接: 在解析网页时,爬虫会找到新的链接,并将其加入待爬取的URL队列中,以便继续爬取更多页面。
重复流程: 爬虫循环执行上述步骤,从初始URL队列中取出URL,发送请求,接收响应,解析网页,提取信息,处理和存储数据,发现新链接,直到完成爬取任务。
控制和维护: 爬虫需要设置适当的请求频率和延时,以避免对服务器造成过大负担。还需要监控爬虫的运行情况,处理错误和异常。
1.2 应用场景
搜索引擎:搜索引擎使用爬虫来抓取网页内容,建立索引,以便用户搜索时能够快速找到相关信息。
数据采集:企业、研究机构等可以使用爬虫从互联网上采集数据,用于市场分析、舆情监测等。
新闻聚合:爬虫可以从各个新闻网站抓取新闻标题、摘要等,用于新闻聚合平台。
价格比较:电商网站可以使用爬虫抓取竞争对手的产品价格和信息,用于价格比较分析。
科研分析:研究人员可以使用爬虫来获取科学文献、学术论文等信息。
1.3 爬虫策略
通用爬虫(General Crawler)和聚焦爬虫(Focused Crawler)是两种不同的网络爬虫策略,用于在互联网上获取信息。它们的工作方式和应用场景有所不同。
通用爬虫(General Crawler): 通用爬虫是一种广泛用途的爬虫,它的目标是尽可能地遍历互联网上的大量网页,以收集和索引尽可能多的信息。通用爬虫会从一个起始URL开始,然后通过链接跟踪、递归爬取等方式探索更多的网页,构建一个广泛的网页索引。
通用爬虫的特点:
- 目标是收集尽可能多的信息。
- 开始于一个或多个起始URL,然后通过链接跟踪扩展。
- 适用于搜索引擎和大型数据索引项目。
- 需要考虑网站的robots.txt文件和反爬虫机制。
聚焦爬虫(Focused Crawler): 聚焦爬虫是一种专注于特定领域或主题的爬虫,它选择性地爬取与特定主题相关的网页。与通用爬虫不同,聚焦爬虫只关注某些特定的网页,以满足特定需求,如舆情分析、新闻聚合等。
聚焦爬虫的特点:
- 专注于特定主题或领域。
- 根据特定的关键词、内容规则等选择性地爬取网页。
- 适用于定制化需求,如舆情监控、新闻聚合等。
- 可以更精准地获取特定领域的信息。
在实际应用中,通用爬虫和聚焦爬虫有各自的优势和用途。通用爬虫适合用于构建全面的搜索引擎索引,以及进行大规模数据分析和挖掘。聚焦爬虫则更适合于定制化需求,能够针对特定领域或主题获取精准的信息。
1.4 爬虫的挑战
网站结构变化:网站结构和内容可能随时变化,需要对爬虫进行调整和更新。
反爬虫机制:一些网站采取了反爬虫措施,如限制请求频率、使用验证码等。
数据清洗:从网页中提取的数据可能包含噪音,需要进行清洗和整理。
法律和道德问题:爬虫需要遵守法律法规,尊重网站规则,不要滥用和侵犯他人权益。
总结: 网络爬虫是一种自动化程序,用于从互联网上获取信息。它通过发送请求、解析网页、提取信息等步骤,实现数据的采集和整理。在不同的应用场景中,爬虫发挥着重要的作用,但也需要面对各种挑战和合规性问题。
2 网络爬虫开发
2.1 通用的网络爬虫基本流程
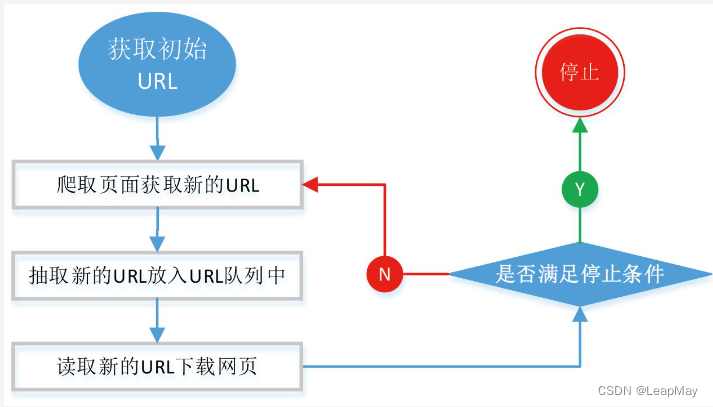
2.2 网络爬虫的常用技术
网络爬虫是一种自动化的程序,用于从互联网上收集数据。常用的网络爬虫技术和第三方库包括以下内容:
1. 请求和响应处理:
- Requests: 用于发送HTTP请求和处理响应的库,方便爬虫获取网页内容。
- httpx: 类似于
requests,支持同步和异步请求,适用于高性能爬虫。2. 解析和提取数据:
- Beautiful Soup: 用于解析HTML和XML文档,并提供简单的方法来提取所需数据。
- lxml: 高性能的HTML和XML解析库,支持XPath和CSS选择器。
- PyQuery: 基于jQuery的解析库,支持CSS选择器。
3. 动态渲染网页:
- Selenium: 自动化浏览器库,用于处理动态渲染的网页,如JavaScript加载内容。
4. 异步处理:
- asyncio和aiohttp: 用于异步处理请求,提高爬虫的效率。
5. 数据存储:
- SQLite、MySQL、MongoDB: 数据库用于存储和管理爬取的数据。
- CSV、JSON: 简单格式用于导出和导入数据。
6. 反爬虫和IP代理:
- User-Agent设置: 设置请求的User-Agent头部来模拟不同浏览器和操作系统。
- 代理服务器: 使用代理IP来隐藏真实IP地址,避免IP封禁。
- 验证码处理: 使用验证码识别技术来处理需要验证码的网站。
7. Robots.txt和网站政策遵守:
- robots.txt: 检查网站的
robots.txt文件,遵循网站的规则。- 爬虫延迟: 设置爬虫请求的延迟,避免对服务器造成过大负担。
8. 爬虫框架:
- Scrapy: 一个强大的爬虫框架,提供了许多功能来组织爬取过程。
- Splash: 一个JavaScript渲染服务,适用于处理动态网页。
2.3 网络爬虫常用的第三方库
网络爬虫使用多种技术和第三方库来实现对网页的数据获取、解析和处理。以下是网络爬虫常用的技术和第三方库:
1. 请求库: 网络爬虫的核心是发送HTTP请求和处理响应。以下是一些常用的请求库:
- Requests: 简单易用的HTTP库,用于发送HTTP请求和处理响应。
- httpx: 现代化的HTTP客户端,支持异步和同步请求。
2. 解析库: 解析库用于从HTML或XML文档中提取所需的数据。
- Beautiful Soup: 用于从HTML和XML文档中提取数据的库,支持灵活的查询和解析。
- lxml: 高性能的XML和HTML解析库,同时支持XPath和CSS选择器。
3. 数据存储库: 存储爬取到的数据是爬虫的重要环节之一。
- SQLAlchemy: 强大的SQL工具包,用于在Python中操作关系数据库。
- Pandas: 数据分析库,可用于数据清洗和分析。
- MongoDB: 非关系型数据库,适合存储和处理大量的非结构化数据。
- SQLite: 轻量级的嵌入式关系数据库。
4. 异步库: 使用异步请求可以提高爬虫的效率。
- asyncio: Python的异步IO库,用于编写异步代码。
- aiohttp: 异步HTTP客户端,支持异步请求。
5. 动态渲染处理: 有些网页使用JavaScript进行动态渲染,需要使用浏览器引擎进行处理。
- Selenium: 自动化浏览器操作库,用于处理JavaScript渲染的页面。
6. 反爬虫技术应对: 一些网站采取反爬虫措施,需要一些技术来绕过。
- 代理池: 使用代理IP来避免频繁访问同一IP被封禁。
- User-Agent随机化: 更改User-Agent以模拟不同的浏览器和操作系统。
这只是网络爬虫常用的一些技术和第三方库。根据实际项目需求,您可以选择合适的技术和工具来实现高效、稳定和有用的网络爬虫。
3 简单爬虫示例
创建一个简单的爬虫,例如爬取一个静态网页上的文本信息,并将其输出。
import requests
from bs4 import BeautifulSoup# 发送GET请求获取网页内容
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8' # 指定编码为UTF-8
html_content = response.text# 使用Beautiful Soup解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')# 提取网页标题
title = soup.title.text# 提取段落内容
paragraphs = soup.find_all('p')
paragraph_texts = [p.text for p in paragraphs]# 输出结果
print("Title:", title)
print("Paragraphs:")
for idx, paragraph in enumerate(paragraph_texts, start=1):print(f"{idx}. {paragraph}")
相关文章:
【100天精通python】Day41:python网络爬虫开发_爬虫基础入门
目录 专栏导读 1网络爬虫概述 1.1 工作原理 1.2 应用场景 1.3 爬虫策略 1.4 爬虫的挑战 2 网络爬虫开发 2.1 通用的网络爬虫基本流程 2.2 网络爬虫的常用技术 2.3 网络爬虫常用的第三方库 3 简单爬虫示例 专栏导读 专栏订阅地址:https://blog.csdn.net/…...

开源和自研——机器人
双足机器人: MPC技术:封闭性非常高。没有开源方案可抄。 因为开源,不需要从0构建。 这也是前两年,国外一开源华为就遥遥领先。 射频芯片/射频天线:技术封闭。华为虽然做通信,但却没有攻破。 鸿蒙&#…...

【AIGC 讯飞星火 | 百度AI|ChatGPT| 】智能对比
AI智能对比 🍸 前言🍺 概念类对比🍵 讯飞🍵 百度AI🍵 chatGPT 🍹 功能类对比☕ 讯飞☕ 百度AI☕ chatGPT 🥃 可输入字数对比🥤 百度AI🥤 讯飞🥤 chatGPT &…...
Wazuh安装及使用
环境配置 官方网址Quickstart Wazuh documentation 可以选择Elastic Stack安装,也可以选择下载虚拟机(OVA)安装 这里展示虚拟机安装 下载好文档中提供的文件 虚拟机配置要求 在VM左上角 文件->打开->刚刚下载的.ova文件,…...
docker pull 设置代理 centos
On CentOS the configuration file for Docker is at: /etc/sysconfig/docker 用 root 权限打开 text editor sudo gedit 注意 加引号 Adding the below line helped me to get the Docker daemon working behind a proxy server: HTTP_PROXY“http://<proxy_host>:&…...
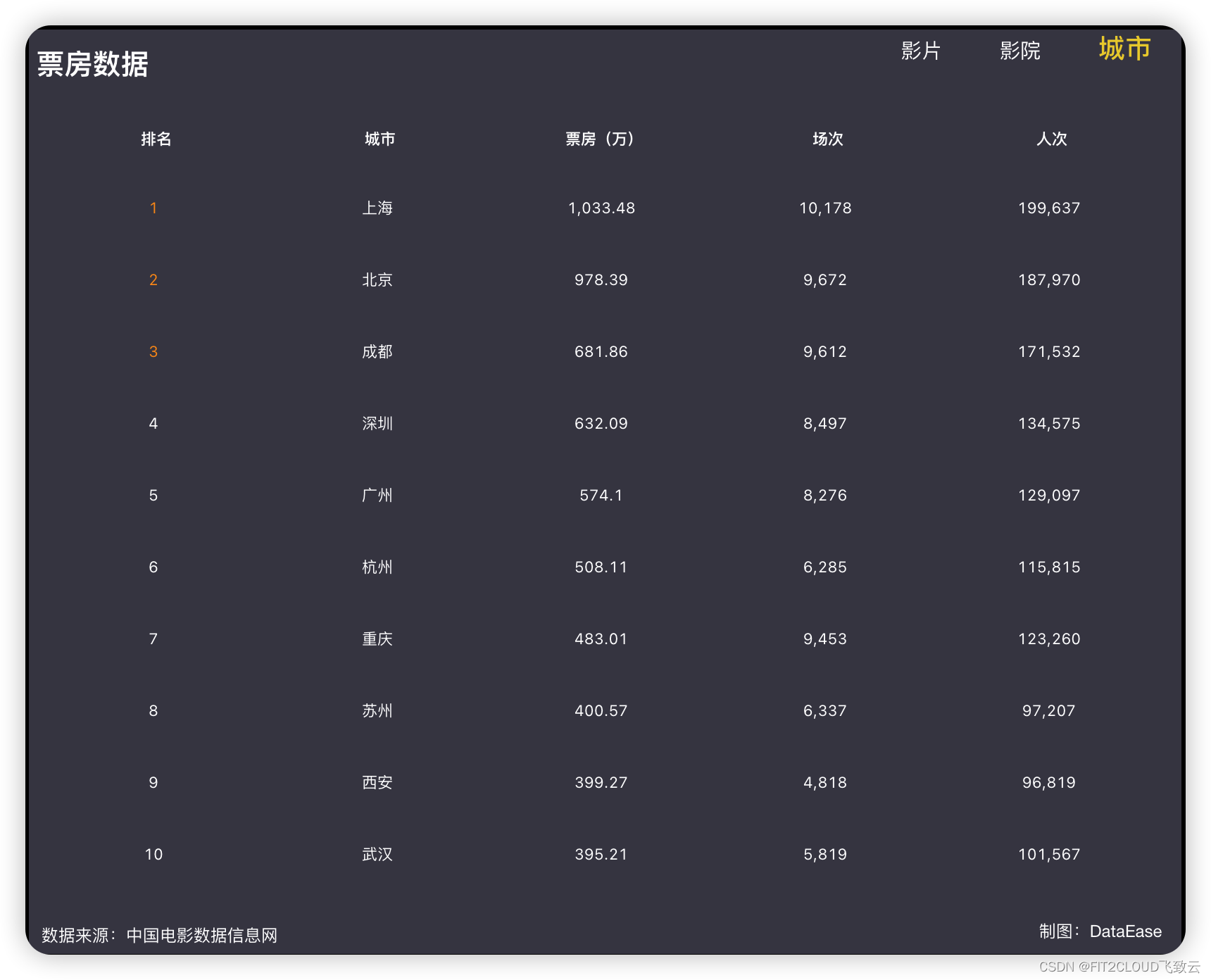
仪表板展示 | DataEase看中国:2023年中国电影市场分析
背景介绍 随着《消失的她》、《变形金刚:超能勇士崛起》、《蜘蛛侠:纵横宇宙》、《我爱你》等国内外影片的上映,2023年上半年的电影市场也接近尾声。据国家电影专资办初步统计,上半年全国城市院线票房达262亿元,已经超…...

在APP中如何嵌入小游戏?
APP内嵌游戏之所以能火爆,主要是因为互联网对流量的追求是无止境的,之前高速增长的红利期后,获取新的流量成为各大厂商的挑战,小游戏的引入,就是这个目的,为已有的产品赋能,抢占用户注意力和使用…...
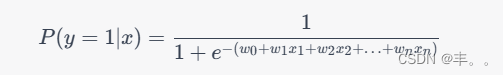
神经网络基础-神经网络补充概念-02-逻辑回归
概念 逻辑回归是一种用于二分分类问题的统计学习方法,尽管名字中带有"回归"一词,但实际上它用于分类任务。逻辑回归的目标是根据输入特征来预测数据点属于某个类别的概率,然后将概率映射到一个离散的类别标签。 逻辑回归模型的核…...

DICOM图像的常用一些参数解析
医学图像DICOM医学影像文件格式详解 Dicom文件基本操作 DICOM图像参数? 像素:构成图片的小色点。图像每个维度的像素个数——该维度一共有多少个均匀分布的像素点。 分辨率(单位DPI):每英寸(Inch…...

Java虚拟机(JVM):虚拟机栈溢出
一、概念 Java虚拟机栈溢出(Java Virtual Machine Stack Overflow)是指在Java程序中,当线程调用的方法层级过深,导致栈空间溢出的情况。 Java虚拟机栈是每个线程私有的,用于存储方法的调用和局部变量的内存空间。每当…...
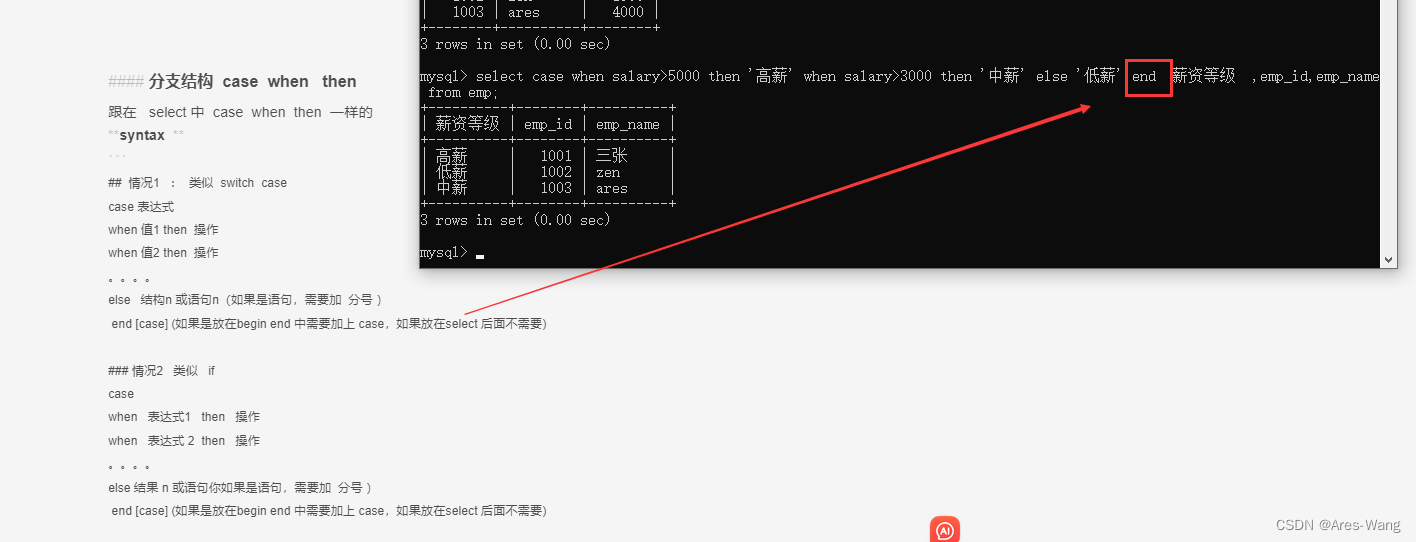
MySQL流程控制
流程控制 顺序结构: 程序从上往下依次执行分支结构: 程序按条件进行选择执行,从两条或多条路径中选择一条执行。循环结构: 程序满足一定条件下,重复执行一组语句 针对于MySQL的流程控制语句主要有3类。注意ÿ…...

智安网络|深入比较:Sass系统与源码系统的差异及选择指南
随着前端开发的快速发展,开发人员需要使用更高效和灵活的工具来处理样式表。在这个领域,Sass系统和源码系统是两个备受关注的选项。 Sass系统 Sass(Syntactically Awesome Style Sheets)是一种CSS预处理器,它扩展了CS…...
Day14 01-Shell脚本编程详解
文章目录 第一章 Shell编程【重点】1.1. Shell的概念介绍1.1.1. 命令解释器4.1.1.2. Shell脚本 1.2. Shell编程规范1.2.1. 脚本文件的结构1.2.2. 脚本文件的执行 1.3. Shell的变量1.3.1. 变量的用法1.3.2. 变量的分类1.3.3. 局部变量1.3.4. 环境变量1.3.5. 位置参数变量1.3.6. …...

NVIDIA GPU驱动和CUDA工具包 Linux CentOS 7 在线安装指南
挑选指定系统和对应的GPU型号下载驱动和CUDA工具包: Linux CentOS安装NVIDIA GPU驱动程序和NVIDIA CUDA工具包_centos安装显卡驱动和cuda_Entropy-Go的博客-CSDN博客 相比之下,本文是在线安装NVIDIA GPU驱动和CUDA工具包方式,省去挑选对应正确安装包的烦…...

Php“牵手”拼多多商品详情页数据采集方法,拼多多API接口申请指南
拼多多详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用。 一、拼…...

未来公文的智能化进程
随着技术的飞速发展,公文——这个有着悠久历史的官方沟通方式,也正逐步走向智能化的未来。自动化、人工智能、区块链...这些现代科技正重塑我们的公文制度,让其变得更加高效、安全和智慧。 1.语义理解与自动生成 通过深度学习和NLPÿ…...

C语言:深度学习知识储备
目录 数据类型 每种类型的大小是多少呢? 变量 变量的命名: 变量的分类: 变量的作用域和生命周期 作用域: 生命周期: 常量 字符串转义字符注释 字符串: 转义字符 操作符: 算术操作符…...

探索大模型时代下的算法工程师前景与发展路径
文章目录 大模型时代的挑战与机遇从算法到工程:技能升级的必要性发展路径与职业规划路径一:深耕研究领域路径二:工程实践与部署路径三:跨界合作与解决复杂问题路径四:教育培训和技术普及 不断学习与更新知识结论 &…...

【福建事业单位-综合基础知识】03行政法
【福建事业单位-综合基础知识】03行政法 1.行政法概述(原则重点)行政主体范围 行政行为总结 二.行政处罚2.1行政处罚的种类总结 行政法框架 1.行政法概述(原则重点) 行政法的首要原则是合法;自由裁量——合理行政&…...

CSS 背景属性
前言 背景属性 属性说明background-color背景颜色background-image背景图background-repeat背景图平铺方式background-position背景图位置background-size背景图缩放background-attachment背景图固定background背景复合属性 背景颜色 可以使用background-color属性来设置背景…...
)
卷积神经网络在图像分类中的历史(1989 年至今)
原文:towardsdatascience.com/the-history-of-convolutional-neural-networks-for-image-classification-1989-today-5ea8a5c5fe20?sourcecollection_archive---------5-----------------------#2024-06-28 深度学习和计算机视觉领域最伟大创新的视觉之旅。 https…...
)
避坑指南:HugeGraph-Server 0.12.0 用MySQL做后端存储,配置文件到底怎么改?(附完整流程)
HugeGraph-Server 0.12.0 MySQL后端配置深度解析与实战避坑指南 当选择MySQL作为HugeGraph-Server的后端存储时,配置文件的细微差异往往成为项目落地的"拦路虎"。本文将深入剖析hugegraph.properties中MySQL相关配置的每一个关键参数,结合典型…...

在视频剪辑工作流中集成Taotoken大模型以辅助创意构思
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在视频剪辑工作流中集成Taotoken大模型以辅助创意构思 视频创作的前期策划阶段,尤其是分镜头脚本构思和文案草稿撰写&a…...

BLE AT指令实战:从GAP广播到GATT服务构建的嵌入式蓝牙开发指南
1. 项目概述与BLE AT指令核心价值如果你正在捣鼓物联网设备、可穿戴硬件或者任何需要无线连接的嵌入式项目,蓝牙低功耗(BLE)技术大概率是你绕不开的一环。它功耗低、连接快,非常适合那些需要长时间运行、间歇性传输少量数据的场景…...

告别风扇噪音与高温:FanControl让你的Windows电脑安静又冷静
告别风扇噪音与高温:FanControl让你的Windows电脑安静又冷静 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...

iOS 27 开放 AI 生态@ACP#小型化扩展黄金风口,IX8008全面超越 ASM2806,铸就嵌入式 AI 扩展核心
苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 成为全球最大 AI 流量入口。这一变革引爆小型 AI 扩展坞、嵌入式 AI 终端、便携存储扩展、迷你主机、车载 AI五大硬件新机遇。作为连接…...

深度解析DS4Windows:让PS4手柄在Windows平台重获新生
深度解析DS4Windows:让PS4手柄在Windows平台重获新生 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾经为PS4手柄在PC上的兼容性问题而烦恼?游戏无法识别、…...
CircuitPython驱动NeoPixel与DotStar:从原理到炫彩动画实战
1. 项目概述与核心价值在嵌入式开发和物联网项目中,灯光不仅仅是简单的“亮”与“灭”,它更是设备与用户沟通的语言,是项目灵魂的直观体现。无论是智能家居的氛围灯带、可穿戴设备的动态提示,还是艺术装置的视觉表达,可…...

Prometheus外置抓取器:扩展监控能力与复杂场景适配方案
1. 项目概述:一个为Prometheus量身定制的“数据抓取器”如果你正在使用Prometheus监控你的微服务、Kubernetes集群或者任何需要被度量的系统,那你一定对scrape_configs这个配置项不陌生。Prometheus的核心工作模式就是“拉取”(Pullÿ…...

口碑好的芯片老化座选哪家?
芯片测试和老化是确保产品质量的关键环节。选择一款性能稳定、可靠性高的芯片老化座对于企业来说至关重要。本文将对比分析几家知名品牌的芯片老化座,并推荐其中的佼佼者——鸿怡电子。1. 鸿怡电子:国产优质IC测试座领军者产品特点设计结构:鸿…...