PyTorch Lightning:通过分布式训练扩展深度学习工作流

一、介绍
欢迎来到我们关于 PyTorch Lightning 系列的第二篇文章!在上一篇文章中,我们向您介绍了 PyTorch Lightning,并探讨了它在简化深度学习模型开发方面的主要功能和优势。我们了解了 PyTorch Lightning 如何为组织和构建 PyTorch 代码提供高级抽象,使研究人员和从业者能够更多地关注模型设计和实验,而不是样板代码。
在本文中,我们将深入研究 PyTorch Lightning,并探索它如何通过分布式训练实现深度学习工作流的扩展。分布式训练对于在海量数据集上训练大型模型至关重要,因为它允许我们利用多个 GPU 或机器的强大功能来加速训练过程。然而,分布式训练往往伴随着一系列挑战和复杂性。
二、安装 Pytorch Lightning & Torchvision
pip install torch torchvision pytorch-lightning 三、实现
首先,我们需要从 PyTorch 和 PyTorch Lightning 导入必要的模块:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision import transformsimport pytorch_lightning as pl 接下来,我们使用 PyTorch 的类定义我们的神经网络架构。在这个例子中,我们使用一个简单的卷积神经网络,其中包含两个卷积层和三个全连接层:nn.Module
class Net(pl.LightningModule):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(nn.functional.relu(self.conv1(x)))x = self.pool(nn.functional.relu(self.conv2(x)))x = torch.flatten(x, 1)x = nn.functional.relu(self.fc1(x))x = nn.functional.relu(self.fc2(x))x = self.fc3(x)return x 然后,我们为 .在该方法中,我们接收一批输入和标签,将它们通过我们的神经网络来获取 logits,计算交叉熵损失,并使用该方法记录训练损失。在该方法中,我们执行与 相同的操作,但不记录损失:LightningModuletraining_stepxyself.logvalidation_steptraining_step
def training_step(self, batch, batch_idx):x, y = batchlogits = self(x)loss = nn.functional.cross_entropy(logits, y)self.log("train_loss", loss)return lossdef validation_step(self, batch, batch_idx):x, y = batchlogits = self(x)loss = nn.functional.cross_entropy(logits, y)self.log("val_loss", loss)return loss 我们还在方法中定义了优化器和学习率调度器:configure_optimizers
def configure_optimizers(self):optimizer = torch.optim.Adam(self.parameters(), lr=0.001)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)return [optimizer], [scheduler] 接下来,我们使用 PyTorch 和 定义数据加载和预处理步骤:DataLoadertransforms
def prepare_data(self):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])CIFAR10(root='./data', train=True, download=True, transform=transform)CIFAR10(root='./data', train=False, download=True, transform=transform)def train_dataloader(self):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])train_dataset = CIFAR10(root='./data', train=True, download=False, transform=transform)return DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=8)def val_dataloader(self):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])val_dataset = CIFAR10(root='./data', train=False, download=False, transform=transform)return DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=8)prepare_data(self):此函数负责在训练模型之前准备数据。它首先使用该类定义一系列转换。转换包括将数据转换为张量并对其进行规范化。定义转换后,该函数将下载用于训练和测试拆分的 CIFAR10 数据集。数据集将下载到目录,并将指定的转换应用于数据。transforms.Compose'./data'train_dataloader(self):此函数为训练数据集创建数据加载器。它首先定义与函数中相同的转换。接下来,它为训练拆分创建 CIFAR10 数据集的实例。从目录中加载数据集,并应用指定的转换。最后,使用训练数据集创建一个对象。数据加载程序配置为 64 的批大小,对数据进行随机排序,并使用 8 个工作线程进行数据加载。它返回数据加载器。prepare_data'./data'DataLoaderval_dataloader(self):此函数为验证数据集创建数据加载器。它遵循与函数类似的结构。它首先使用 定义转换,这些转换与前面的函数相同。然后,为验证拆分创建 CIFAR10 数据集的实例。从目录中加载数据集,并应用指定的转换。最后,使用验证数据集创建一个对象。数据加载器配置为 64 的批大小,无需随机处理数据,并使用 8 个工作线程进行数据加载。它返回数据加载器。train_dataloadertransforms.Compose'./data'DataLoader
该函数将模型作为输入,并对测试数据集执行评估。它首先对测试数据应用转换,将其转换为张量并规范化。然后,它为测试数据集创建数据加载程序。模型将移动到相应的设备(GPU,如果可用)。评估标准设置为交叉熵损失。evaluate_model
def evaluate_model(model):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=8)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = model.to(device)criterion = nn.CrossEntropyLoss()model.eval()test_loss = 0.0correct = 0total = 0with torch.no_grad():for data in test_loader:inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100.0 * correct / totalaverage_loss = test_loss / len(test_loader)print(f"Test Loss: {average_loss:.4f}")print(f"Test Accuracy: {accuracy:.2f}%")将模型置于评估模式,并初始化测试损失、正确预测和总数据点的变量。在无梯度上下文中,该函数遍历测试数据加载器,通过模型转发成批的输入,计算损失并累积测试损失。它还计算正确预测的数量和数据点的总数。最后,它计算并打印平均测试损失和测试精度。
最后,我们实例化我们的模型和来自 PyTorch Lightning,指定用于分布式训练的所需数量的 GPU 或机器:NetTrainer
net = Net()trainer = pl.Trainer(num_nodes=1, # Change to the number of machines in your distributed setupaccelerator="auto", # Distributed Data Parallel, Available names are: auto, cpu, cuda, hpu, ipu, mps, tpu.max_epochs=5, devices=1 # Change to the desired number of GPUs or use `None` for CPU training
)trainer.fit(net)evaluate_model(net)num_nodes:它指定分布式设置中的计算机数量。在这种情况下,它设置为 ,表示单台计算机设置。1accelerator:它确定训练的加速器类型。该值允许 PyTorch Lightning 根据硬件和软件环境自动选择适当的加速器。其他可能的值包括 、 和 ,它们对应于特定的硬件加速器。"auto""cpu""cuda""hpu""ipu""mps""tpu"max_epochs:它设置用于训练模型的最大周期数(通过训练数据集的完整遍历)。在本例中,它设置为 。5devices:它指定用于训练的 GPU 数量。将其设置为 表示使用单个 GPU 进行训练。如果要在 CPU 上进行训练,可以将其设置为 。1None
这些选项允许您控制训练过程的各个方面,例如分布式训练、加速器选择以及用于训练的周期数和设备数。
设置好所有内容后,我们只需调用对象的方法,传入我们的模型、训练数据加载器和验证数据加载器。fitTrainerNet
四、输出
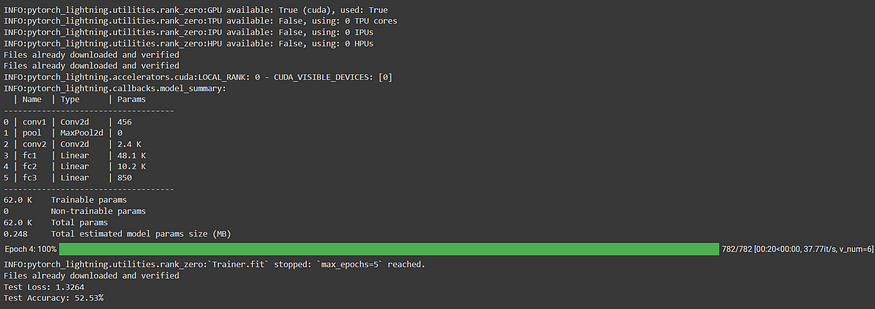
五、结论
PyTorch Lightning 通过分布式训练简化了扩展深度学习工作流的过程。通过抽象化分布式训练的复杂性,PyTorch Lightning 使我们能够专注于设计和实现我们的深度学习模型,而不必担心低级细节。在本文中,我们演练了一个使用 PyTorch Lightning 进行分布式训练的示例代码实现。通过利用多个GPU或机器的强大功能,我们可以显著减少大型深度学习模型的训练时间。
六、引用
- PyTorch Lightning: Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 2.1.0.rc0 documentation
- PyTorch: PyTorch
- torchvision.datasets.CIFAR10: Datasets — Torchvision 0.15 documentation
- torch.utils.data.DataLoader: torch.utils.data — PyTorch 2.0 documentation
- 火炬亚当:Adam — PyTorch 2.0 documentation
- torch.optim.lr_scheduler。步长:StepLR — PyTorch 2.0 documentation
- Torch.nn.CrossEntropyLoss: CrossEntropyLoss — PyTorch 2.0 documentation
- torch.cuda.is_available:torch.cuda — PyTorch 2.0 documentation
阿奈·东格雷
皮托奇
分布式系统
相关文章:
PyTorch Lightning:通过分布式训练扩展深度学习工作流
一、介绍 欢迎来到我们关于 PyTorch Lightning 系列的第二篇文章!在上一篇文章中,我们向您介绍了 PyTorch Lightning,并探讨了它在简化深度学习模型开发方面的主要功能和优势。我们了解了 PyTorch Lightning 如何为组织和构建 PyTorch 代码提…...

无涯教程-Perl - splice函数
描述 此函数从LENGTH元素的OFFSET元素中删除ARRAY元素,如果指定,则用LIST替换删除的元素。如果省略LENGTH,则从OFFSET开始删除所有内容。 语法 以下是此函数的简单语法- splice ARRAY, OFFSET, LENGTH, LISTsplice ARRAY, OFFSET, LENGTHsplice ARRAY, OFFSET返回值 该函数…...
归并排序:从二路到多路
前言 我们所熟知的快速排序和归并排序都是非常优秀的排序算法。 但是快速排序和归并排序的一个区别就是:快速排序是一种内部排序,而归并排序是一种外部排序。 简单理解归并排序:递归地拆分,回溯过程中,将排序结果进…...

【Vue】运行项目报错 This dependency was not found
背景 运行Vue 项目报错,提示This dependency was not found;然后我根据提示 执行 npm install --save vue/types/umd ,执行后发现错误,我一开始一直以为是我本地装不上这个依赖。后来找了资料后,看到应该是自己的代码里面随意的i…...

Shell编程之正则表达式
文本处理器:三剑客:grep查找sed awk shell正则表达式由一类特殊字符以及文本字符所编写的一种模式,处理文本当中的内容,其中的一些字符不表示字符的字面含义表示一种控制或者通配的功能 通配符:匹配文件名和目录名&a…...
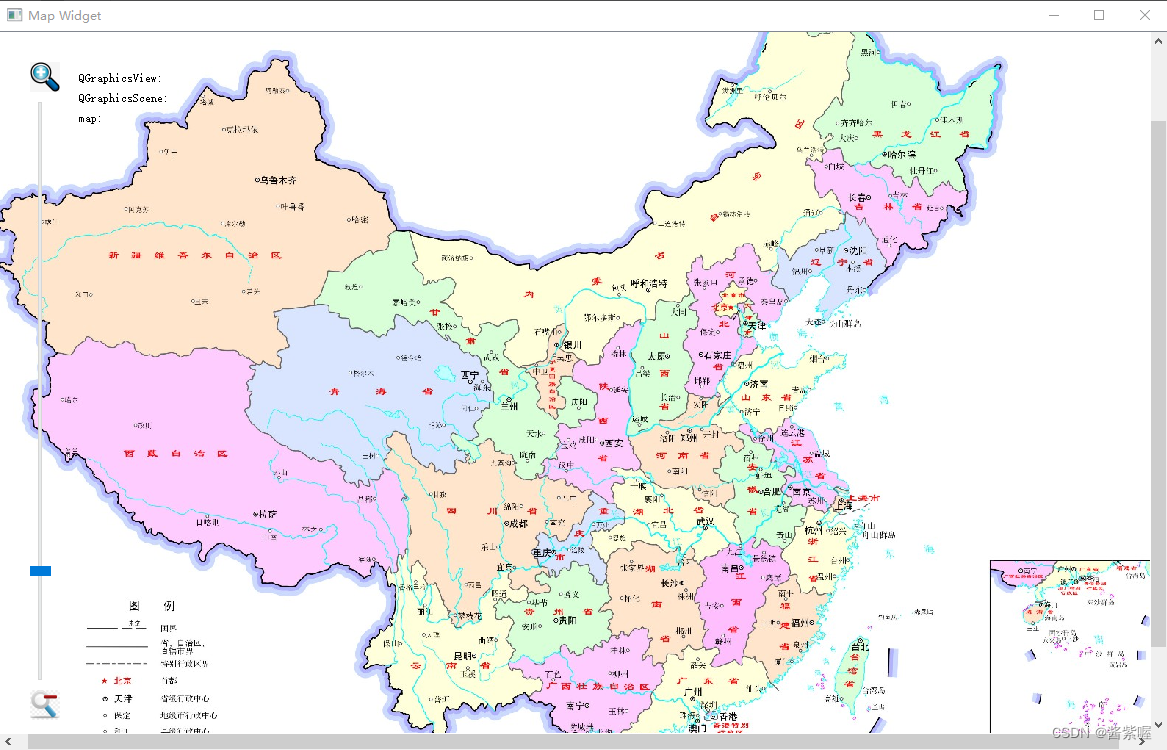
QGraphicsView 实例3地图浏览器
主要介绍Graphics View框架,实现地图的浏览、放大、缩小,以及显示各个位置的视图、场景和地图坐标 效果图: mapwidget.h #ifndef MAPWIDGET_H #define MAPWIDGET_H #include <QLabel> #include <QMouseEvent> #include <QGraphicsView&…...
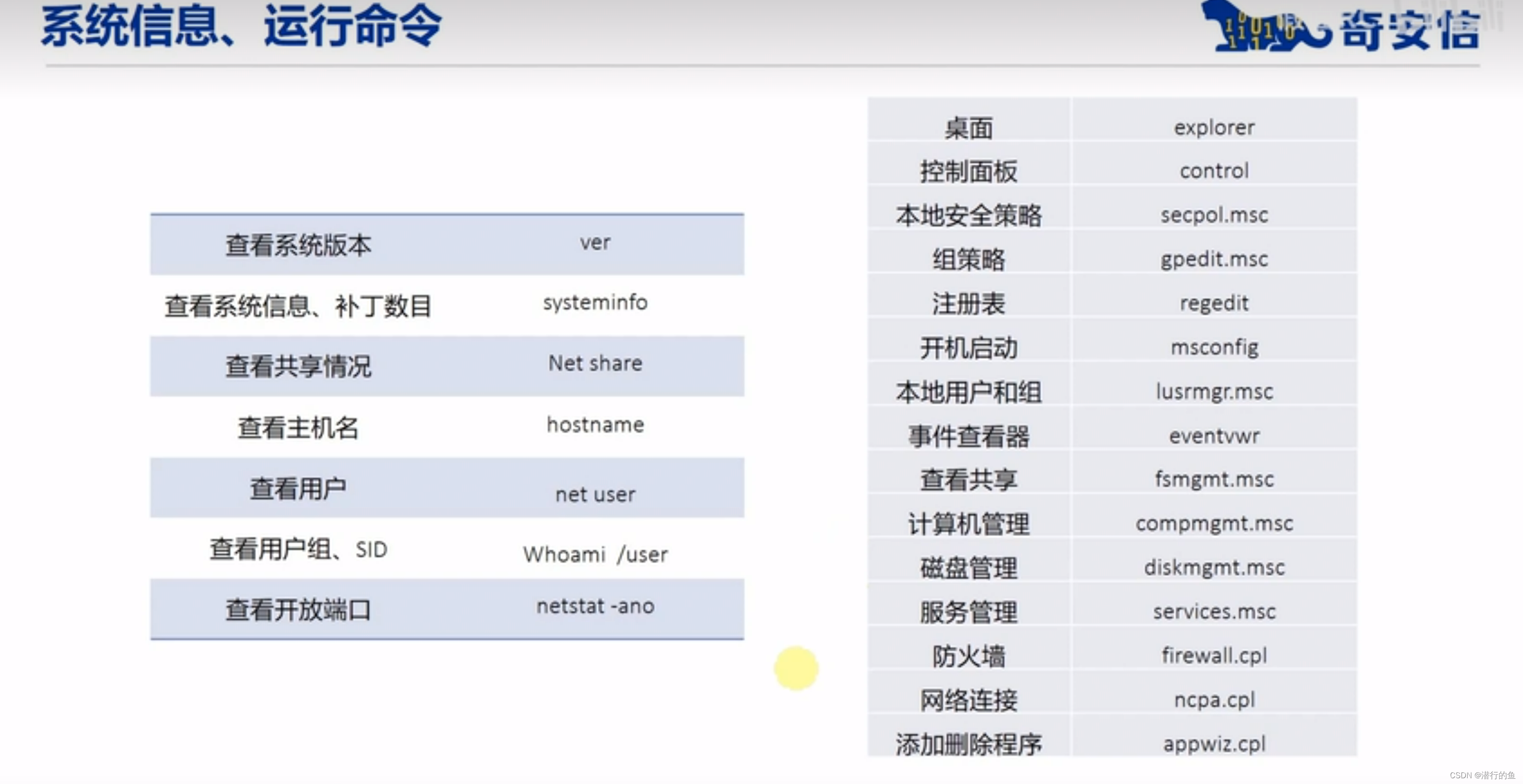
Windows基础安全知识
目录 常用DOS命令 ipconfig ping dir cd net user 常用DOS命令 内置账户访问控制 Windows访问控制 安全标识符 访问控制项 用户账户控制 UAC令牌 其他安全配置 本地安全策略 用户密码策略复杂性要求 强制密码历史: 禁止密码重复使用 密码最短使用期限…...

自定义注解和自定义注解处理器来扫描所有带有某个特定注解的Controller层
在Spring Boot中,您可以使用自定义注解和自定义注解处理器来扫描所有带有某个特定注解的Controller层。 以下是一个简单的示例,演示如何实现这个功能: 首先,创建自定义注解 CustomAnnotation ,用于标记需要被扫描的C…...

浏览器渲染原理 - 输入url 回车后发生了什么
目录 渲染时间点渲染流水线1,解析(parse)HTML1.1,DOM树1.2,CSSOM树1.3,解析时遇到 css 是怎么做的1.4,解析时遇到 js 是怎么做的 2,样式计算 Recalculate style3,布局 la…...

大文本的全文检索方案附件索引
一、简介 Elasticsearch附件索引是需要插件支持的功能,它允许将文件内容附加到Elasticsearch文档中,并对这些附件内容进行全文检索。本文将带你了解索引附件的原理和使用方法,并通过一个实际示例来说明如何在Elasticsearch中索引和检索文件附…...
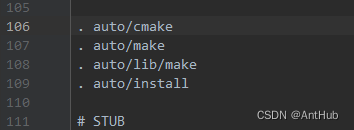
35_windows环境debug Nginx 源码-CLion配置CMake和启动
文章目录 生成 CMakeLists.txt 组态档35_windows环境debug Nginx 源码-CLion配置CMake和启动生成 CMakeLists.txt 组态档 修改auto目录configure文件,在 . auto/make 上边增加 . auto/cmake, 大概在 106 行。在 auto 目录下创建cmake 文件其内容如下: #!/usr/bin/env bash NG…...

收集的一些比较好的git网址
1、民间故事 https://github.com/folkstory/lingqiu/blob/master/%E4%BC%A0%E8%AF%B4%E9%83%A8%E5%88%86/%E4%BA%BA%E7%89%A9%E4%BC%A0%E8%AF%B4/%E2%80%9C%E6%B5%B7%E5%BA%95%E6%8D%9E%E6%9C%88%E2%80%9D%E7%9A%84%E6%AD%A6%E4%B8%BE.md 2、童话故事 https://gutenberg.org/c…...
容斥原理 博弈论(多种Nim游戏解法)
目录 容斥原理容斥原理的简介能被整除的数(典型例题)实现思路代码实现扩展:用DPS实现 博弈论博弈论中的相关性质博弈论的相关结论先手必败必胜的证明Nim游戏(典型例题)代码实现 台阶-Nim游戏(典型例题&…...
【C++】函数指针
2023年8月18日,周五上午 今天在B站看Qt教学视频的时候遇到了 目录 语法和typedef或using结合我的总结 语法 返回类型 (*指针变量名)(参数列表)以下是一些示例来说明如何声明不同类型的函数指针: 声明一个不接受任何参数且返回void的函数指针…...

VBA技术资料MF45:VBA_在Excel中自定义行高
【分享成果,随喜正能量】可以不光芒万丈,但不要停止发光。有的人陷入困境,不是被人所困,而是自己束缚自己,这时"解铃还须系铃人",如果自己无法放下,如何能脱困? 。 我给V…...

【Git】Git中的钩子
Git Book——Git的自定义钩子 Git中的钩子分为两大类: 1、客户端钩子:由诸如提交和合并这样的操作所调用 2、服务端钩子:由诸如接收被推送的提交这样的联网操作 客户端钩子: 提交工作流钩子 pre-commit:在提交信息前…...
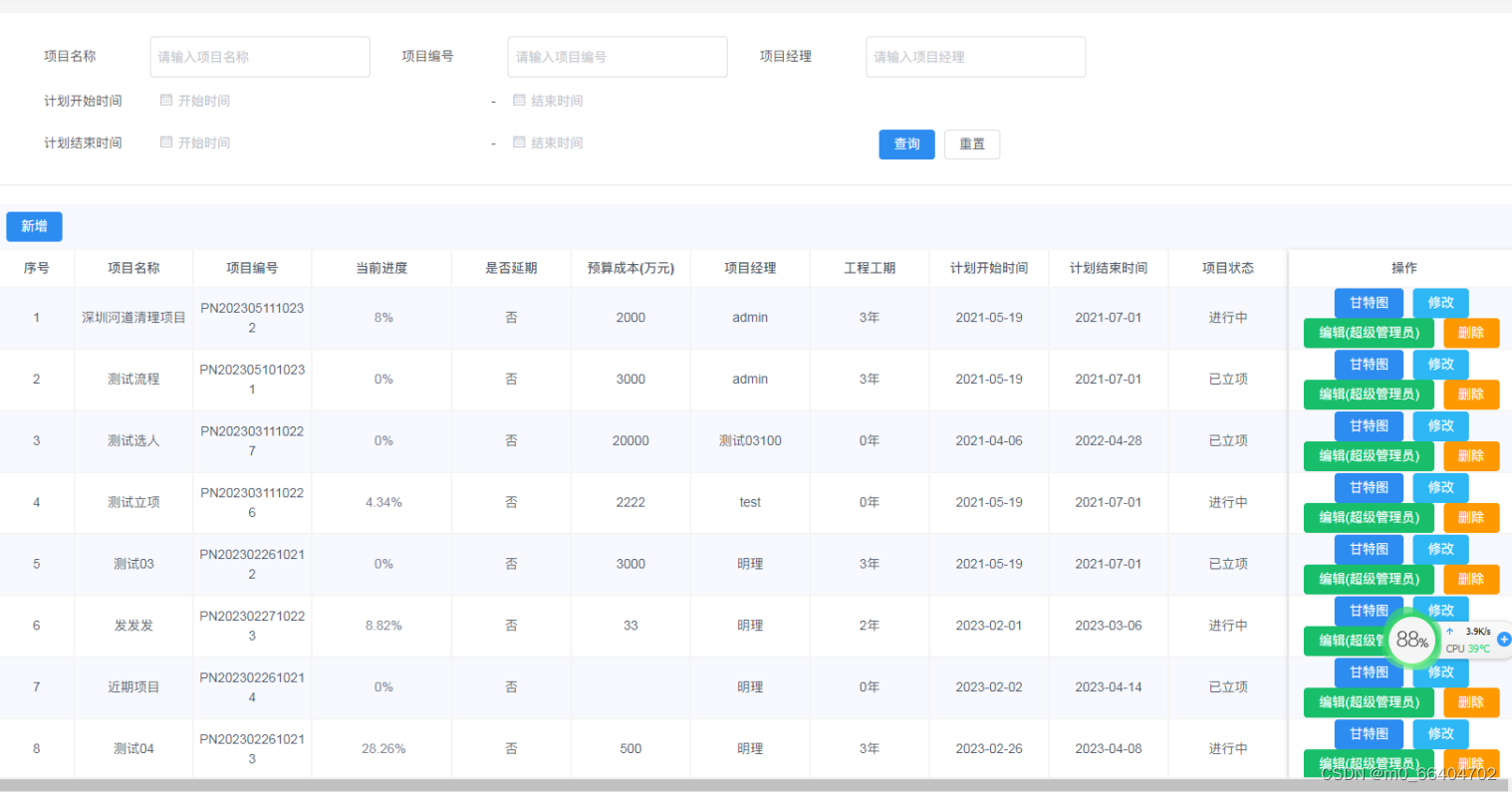
java 工程管理系统源码+项目说明+功能描述+前后端分离 + 二次开发 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显…...

Java # JVM
一、1.8之前 运行时数据区(进程共享) 运行时常量池为什么要有方法区: jvm完成类装载后,需要将class文件中的常量池转入内存,保存在方法区中为什么是常量: 常量对象操作较多,为了避免频繁创建和…...
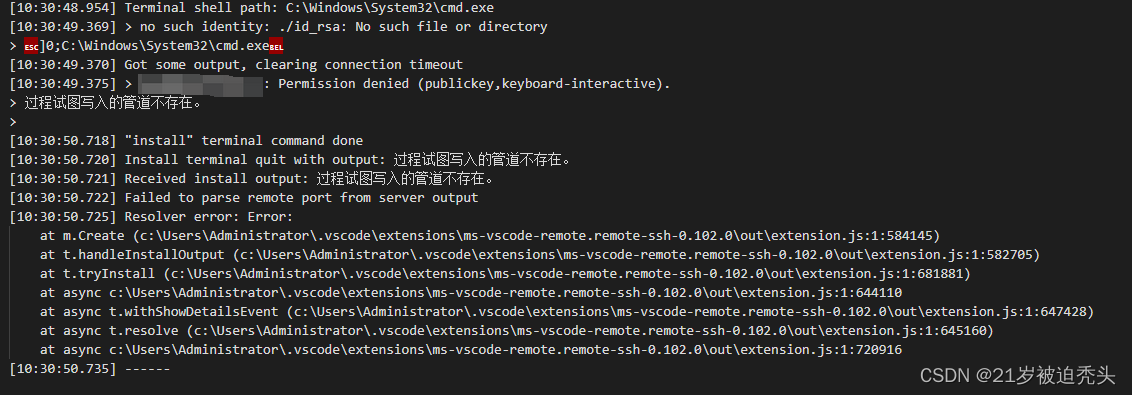
vscode远程连接Linux失败,提示过程试图写入的管道不存在(三种解决办法)
vscode报错如下: 一、第一种情况 原因是本地的known_hosts文件记录服务器信息与现服务器的信息冲突了,导致连接失败。 解决方案就是把本地的known_hosts的原服务器信息全部删掉,然后重新连接。 二、第二种情况 在编写配置文件config时&…...
elaticsearch(1)
1.简介 Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引…...

3步完成Android Studio中文界面配置:告别英文困扰,提升开发效率
3步完成Android Studio中文界面配置:告别英文困扰,提升开发效率 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack…...

别再傻傻分不清了!Numpy里ndarray和array到底啥区别?新手避坑指南
别再傻傻分不清了!Numpy里ndarray和array到底啥区别?新手避坑指南 刚接触Numpy的Python开发者,几乎都会在ndarray和array()这两个概念上栽跟头。明明看起来都能创建数组,为什么文档里一会儿用np.array(),一会儿又冒出个…...
)
ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段) ElevenLabs 自 2024 年起正式支持泰米尔语(ta-IN&a…...

AI写专著高效途径:选对工具,一键生成20万字专著不是梦!
一、新手研究者撰写学术专著的困境 对于首次尝试撰写学术专著的研究者来说,写作的过程就像是在“摸石头过河”,其中充满了各种未知的障碍。选题上常常感到迷茫,难以在“有意义”与“可行性”之间找到合适的平衡,选题要么过于宏大…...
:从注册到语音生成的7个生死节点)
ElevenLabs免费额度使用全攻略(2024年Q2实测版):从注册到语音生成的7个生死节点
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度的核心机制与边界认知 ElevenLabs 的免费层并非基于“每月固定时长”,而是采用动态配额(Dynamic Quota)模型,其核心由三重维度共同约束…...

OpenMetadata企业级元数据平台:智能化数据治理的架构革新与实践路径
OpenMetadata企业级元数据平台:智能化数据治理的架构革新与实践路径 【免费下载链接】OpenMetadata OpenMetadata is a unified metadata platform for data discovery, data observability, and data governance powered by a central metadata repository, in-dep…...

FontForge入门指南:从零开始设计你的第一套字体
FontForge入门指南:从零开始设计你的第一套字体 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾想过亲手设计一套属于自己的字体?Fon…...

深度解析Beyond Compare 5密钥生成:从逆向工程到高效激活的实用指南
深度解析Beyond Compare 5密钥生成:从逆向工程到高效激活的实用指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件授权验证领域,Beyond Compare 5的RSA加密机制一…...

给操作系统爱好者的RISC-V中断实战指南:从SiFive Unleashed开发板到Xv6内核代码
RISC-V中断机制深度解析:从硬件触发到Xv6内核实战 1. RISC-V中断体系架构全景 RISC-V中断系统采用分层设计理念,硬件与软件协同构成了完整的异常处理框架。作为开源指令集架构,RISC-V的中断设计既保持了精简性,又通过可扩展机制满…...

ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析
ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾渴望拥有额外的屏幕空间,却受限于物理显示…...