单机模型并行最佳实践
单机模型并行最佳实践
模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用 DataParallel 在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程,但不适用于某些模型太大而无法放入单个 GPU 的用例。 这篇文章展示了如何通过使用模型并行解决该问题,与DataParallel相比,该模型将单个模型拆分到不同的 GPU 上,而不是在每个 GPU 上复制整个模型(具体来说, 假设模型m包含 10 层:使用DataParallel时,每个 GPU 都具有这 10 层中每个层的副本,而当在两个 GPU 上并行使用模型时,每个 GPU 可以承载 5 层)。
模型并行化的高级思想是将模型的不同子网放置在不同的设备上,并相应地实现forward方法以在设备之间移动中间输出。 由于模型的一部分仅在任何单个设备上运行,因此一组设备可以共同为更大的模型服务。 在本文中,我们不会尝试构建庞大的模型并将其压缩到有限数量的 GPU 中。 相反,本文着重展示并行模型的概念。 读者可以将这些想法应用到实际应用中。
Note
对于模型跨越多个服务器的分布式模型并行训练,请参见分布式 RPC 框架入门,以获取示例和详细信息。
基本用法
让我们从包含两个线性层的玩具模型开始。 要在两个 GPU 上运行此模型,只需将每个线性层放在不同的 GPU 上,然后移动输入和中间输出以匹配层设备。
import torch
import torch.nn as nn
import torch.optim as optimclass ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.net1 = torch.nn.Linear(10, 10).to('cuda:0')self.relu = torch.nn.ReLU()self.net2 = torch.nn.Linear(10, 5).to('cuda:1')def forward(self, x):x = self.relu(self.net1(x.to('cuda:0')))return self.net2(x.to('cuda:1'))请注意,除了五个to(device)调用将线性层和张量放置在适当的设备上之外,上述ToyModel看起来非常类似于在单个 GPU 上实现它的方式。 那是模型中唯一需要更改的地方。 backward()和torch.optim将自动处理渐变,就像模型在一个 GPU 上一样。 调用损失函数时,只需确保标签与输出位于同一设备上。
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()将模型并行应用于现有模块
只需进行几行更改,就可以在多个 GPU 上运行现有的单 GPU 模块。 以下代码显示了如何将torchvision.models.reset50()分解为两个 GPU。 这个想法是继承现有的ResNet模块,并在构建过程中将层拆分为两个 GPU。 然后,通过相应地移动中间输出,覆盖forward方法来缝合两个子网。
from torchvision.models.resnet import ResNet, Bottlenecknum_classes = 1000class ModelParallelResNet50(ResNet):def __init__(self, *args, **kwargs):super(ModelParallelResNet50, self).__init__(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)self.seq1 = nn.Sequential(self.conv1,self.bn1,self.relu,self.maxpool,self.layer1,self.layer2).to('cuda:0')self.seq2 = nn.Sequential(self.layer3,self.layer4,self.avgpool,).to('cuda:1')self.fc.to('cuda:1')def forward(self, x):x = self.seq2(self.seq1(x).to('cuda:1'))return self.fc(x.view(x.size(0), -1))对于模型太大而无法放入单个 GPU 的情况,上述实现解决了该问题。 但是,您可能已经注意到,如果您的模型合适,它将比在单个 GPU 上运行它要慢。 这是因为在任何时间点,两个 GPU 中只有一个在工作,而另一个在那儿什么也没做。 由于中间输出需要在layer2和layer3之间从cuda:0复制到cuda:1,因此性能进一步恶化。
让我们进行实验以更定量地了解执行时间。 在此实验中,我们通过运行随机输入和标签来训练ModelParallelResNet50和现有的torchvision.models.reset50()。 训练后,模型将不会产生任何有用的预测,但是我们可以对执行时间有一个合理的了解。
import torchvision.models as modelsnum_batches = 3
batch_size = 120
image_w = 128
image_h = 128def train(model):model.train(True)loss_fn = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.001)one_hot_indices = torch.LongTensor(batch_size) \.random_(0, num_classes) \.view(batch_size, 1)for _ in range(num_batches):# generate random inputs and labelsinputs = torch.randn(batch_size, 3, image_w, image_h)labels = torch.zeros(batch_size, num_classes) \.scatter_(1, one_hot_indices, 1)# run forward passoptimizer.zero_grad()outputs = model(inputs.to('cuda:0'))# run backward passlabels = labels.to(outputs.device)loss_fn(outputs, labels).backward()optimizer.step()上面的train(model)方法使用nn.MSELoss作为损失函数,并使用optim.SGD作为优化器。 它模拟了对128 X 128图像的训练,这些图像分为 3 批,每批包含 120 张图像。 然后,我们使用timeit来运行train(model)方法 10 次,并绘制带有标准偏差的执行时间。
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
import numpy as np
import timeitnum_repeat = 10stmt = "train(model)"setup = "model = ModelParallelResNet50()"
# globals arg is only available in Python 3\. In Python 2, use the following
# import __builtin__
# __builtin__.__dict__.update(locals())
mp_run_times = timeit.repeat(stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)setup = "import torchvision.models as models;" + \"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)def plot(means, stds, labels, fig_name):fig, ax = plt.subplots()ax.bar(np.arange(len(means)), means, yerr=stds,align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)ax.set_ylabel('ResNet50 Execution Time (Second)')ax.set_xticks(np.arange(len(means)))ax.set_xticklabels(labels)ax.yaxis.grid(True)plt.tight_layout()plt.savefig(fig_name)plt.close(fig)plot([mp_mean, rn_mean],[mp_std, rn_std],['Model Parallel', 'Single GPU'],'mp_vs_rn.png')结果表明,模型并行实现的执行时间比现有的单 GPU 实现长4.02/3.75-1=7%。 因此,我们可以得出结论,在 GPU 之间来回复制张量大约有 7%的开销。 有改进的余地,因为我们知道两个 GPU 之一在整个执行过程中处于空闲状态。 一种选择是将每个批次进一步划分为拆分管道,这样,当一个拆分到达第二个子网时,可以将下一个拆分馈入第一个子网。 这样,两个连续的拆分可以在两个 GPU 上同时运行。
通过流水线输入加速
在以下实验中,我们将每批次120张图像,进一步划分为 20 张图像的均分。 当 PyTorch 异步启动 CUDA 操作时,该实现无需生成多个线程即可实现并发。
class PipelineParallelResNet50(ModelParallelResNet50):def __init__(self, split_size=20, *args, **kwargs):super(PipelineParallelResNet50, self).__init__(*args, **kwargs)self.split_size = split_sizedef forward(self, x):splits = iter(x.split(self.split_size, dim=0))s_next = next(splits)s_prev = self.seq1(s_next).to('cuda:1')ret = []for s_next in splits:# A. s_prev runs on cuda:1s_prev = self.seq2(s_prev)ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))# B. s_next runs on cuda:0, which can run concurrently with As_prev = self.seq1(s_next).to('cuda:1')s_prev = self.seq2(s_prev)ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))return torch.cat(ret)setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)plot([mp_mean, rn_mean, pp_mean],[mp_std, rn_std, pp_std],['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],'mp_vs_rn_vs_pp.png')请注意,设备到设备的张量复制操作在源设备和目标设备上的当前流上同步。 如果创建多个流,则必须确保复制操作正确同步。 在完成复制操作之前写入源张量或读取/写入目标张量可能导致不确定的行为。 上面的实现仅在源设备和目标设备上都使用默认流,因此没有必要强制执行其他同步。
实验结果表明,对并行 ResNet50 进行建模的流水线输入可将训练过程大约加快3.75/2.51-1=49%的速度。 距理想的 100%加速仍然相去甚远。 由于我们在管道并行实现中引入了新参数split_sizes,因此尚不清楚新参数如何影响整体训练时间。 直观地讲,使用较小的split_size会导致许多小的 CUDA 内核启动,而使用较大的split_size会导致在第一次和最后一次拆分期间出现较长的空闲时间。 都不是最佳选择。 对于此特定实验,可能会有最佳的split_size配置。 让我们尝试通过使用几个不同的split_size值进行实验来找到它。
means = []
stds = []
split_sizes = [1, 3, 5, 8, 10, 12, 20, 40, 60]for split_size in split_sizes:setup = "model = PipelineParallelResNet50(split_size=%d)" % split_sizepp_run_times = timeit.repeat(stmt, setup, number=1, repeat=num_repeat, globals=globals())means.append(np.mean(pp_run_times))stds.append(np.std(pp_run_times))fig, ax = plt.subplots()
ax.plot(split_sizes, means)
ax.errorbar(split_sizes, means, yerr=stds, ecolor='red', fmt='ro')
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xlabel('Pipeline Split Size')
ax.set_xticks(split_sizes)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig("split_size_tradeoff.png")
plt.close(fig)结果表明,将split_size设置为 12 可获得最快的训练速度,从而导致3.75/2.43-1=54%加速。 仍有机会进一步加快训练过程。 例如,对cuda:0的所有操作都放在其默认流上。 这意味着下一个拆分的计算不能与上一个拆分的复制操作重叠。 但是,由于上一个和下一个拆分是不同的张量,因此将一个计算与另一个副本重叠是没有问题的。 实现需要在两个 GPU 上使用多个流,并且不同的子网结构需要不同的流管理策略。 由于没有通用的多流解决方案适用于所有模型并行用例,因此在本教程中将不再讨论。
注意:
这篇文章显示了几个性能指标。 当您在自己的计算机上运行相同的代码时,您可能会看到不同的数字,因为结果取决于底层的硬件和软件。 为了使您的环境获得最佳性能,一种正确的方法是首先生成曲线以找出最佳分割尺寸,然后将该分割尺寸用于管道输入。
相关文章:

单机模型并行最佳实践
单机模型并行最佳实践 模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用 DataParallel 在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程&…...
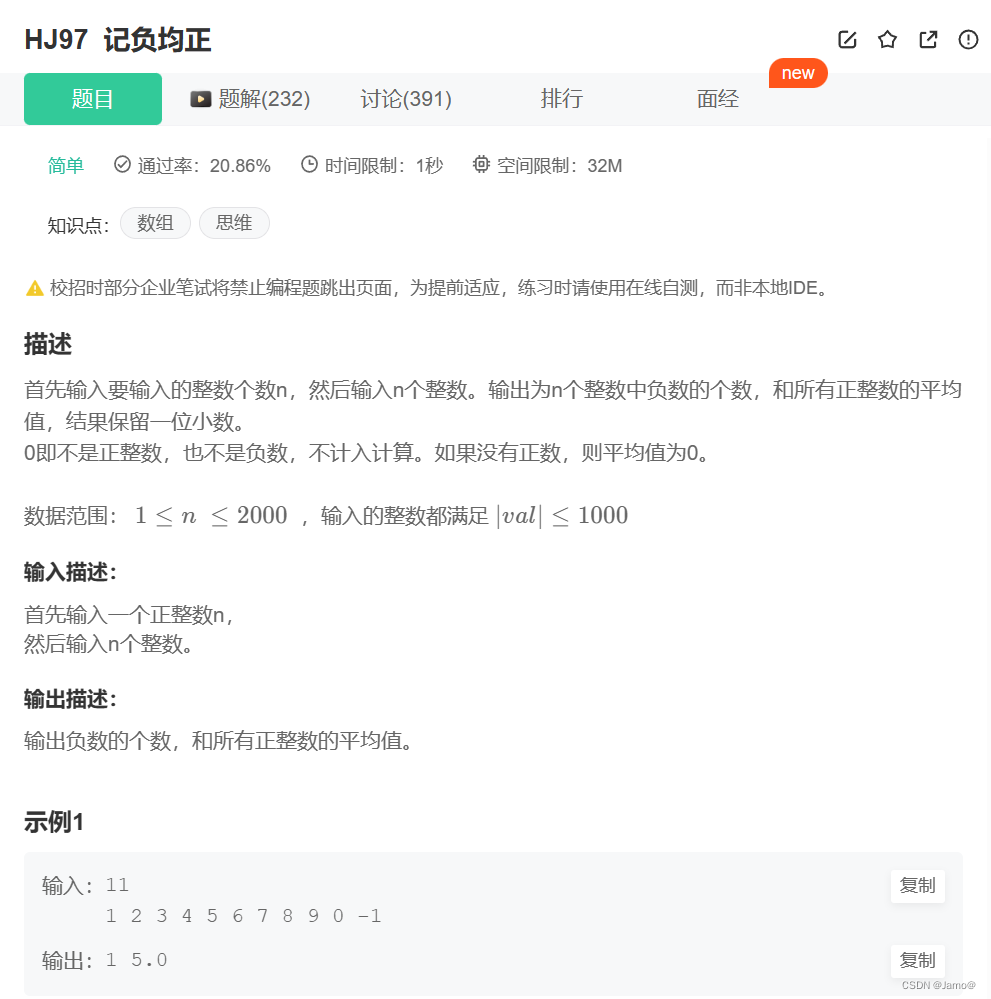
编程练习(3)
一.选择题 第一题: 函数传参的两个变量都是传的地址,而数组名c本身就是地址,int型变量b需要使用&符号,因此答案为A 第二题: 本题考察const修饰指针变量,答案为A,B,C,D 第三题: 注意int 型变…...
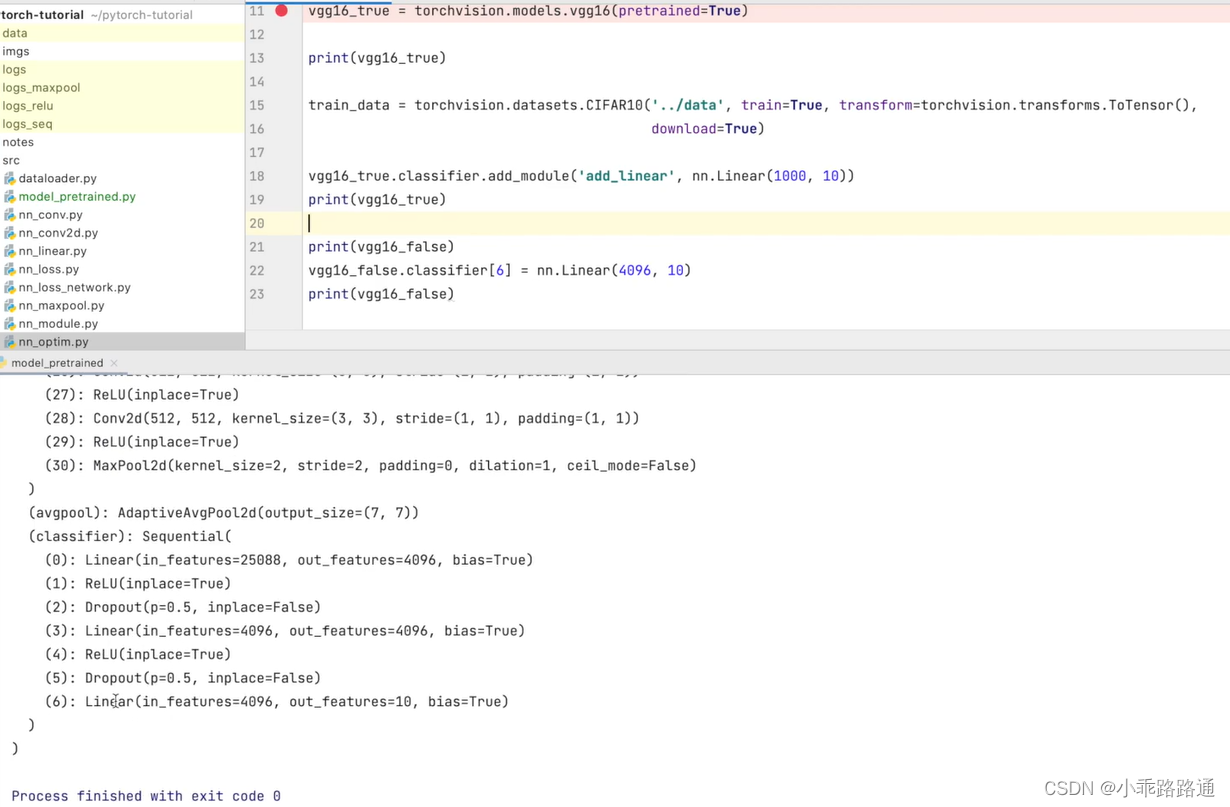
PyTorch学习笔记(十三)——现有网络模型的使用及修改
以分类模型的VGG为例 vgg16_false torchvision.models.vgg16(weightsFalse) vgg16_true torchvision.models.vgg16(weightsTrue) 设置为 False 的情况,相当于网络模型中的参数都是初始化的、默认的设置为 True 时,网络模型中的参数在数据集上是训练好…...
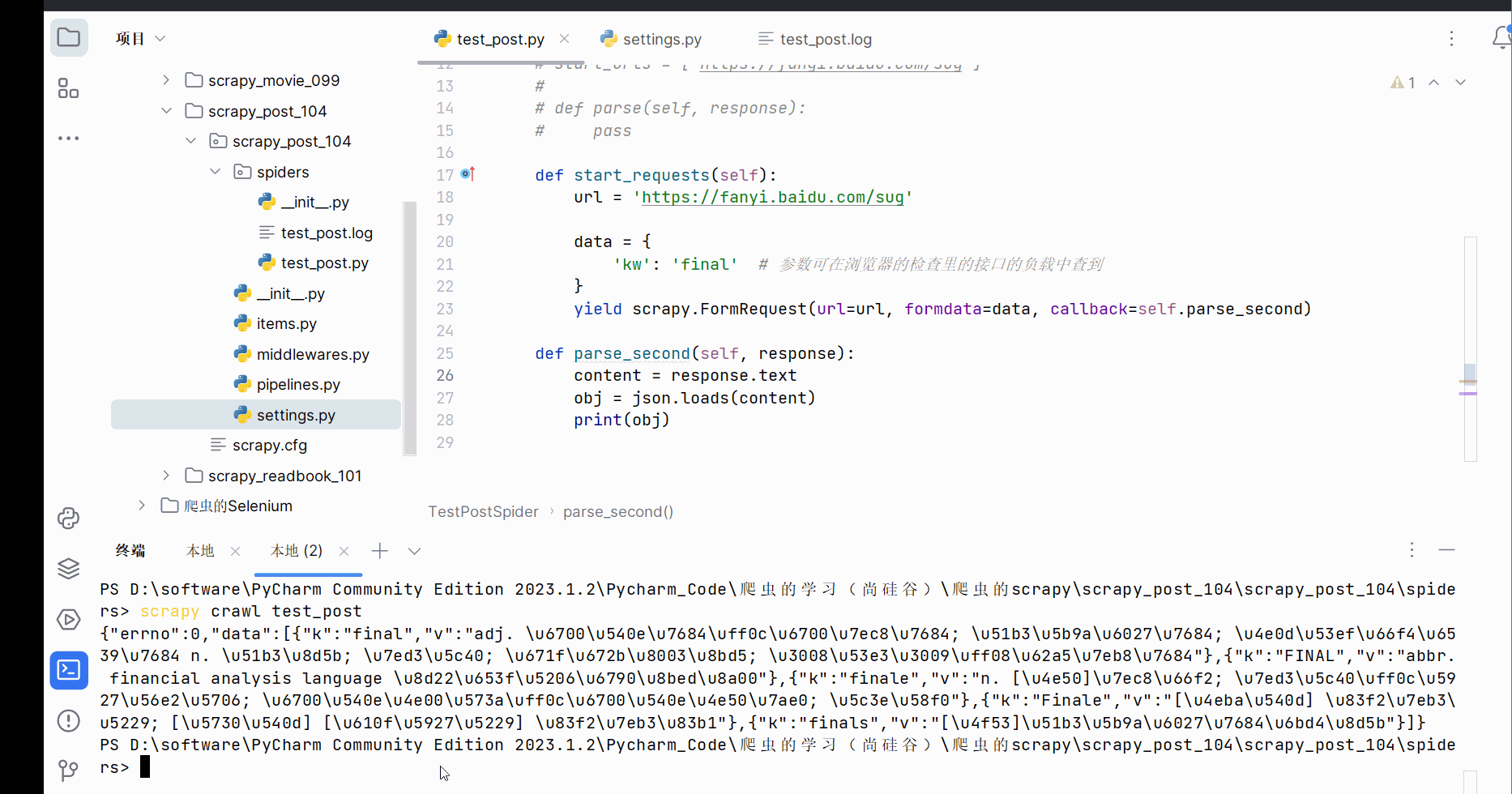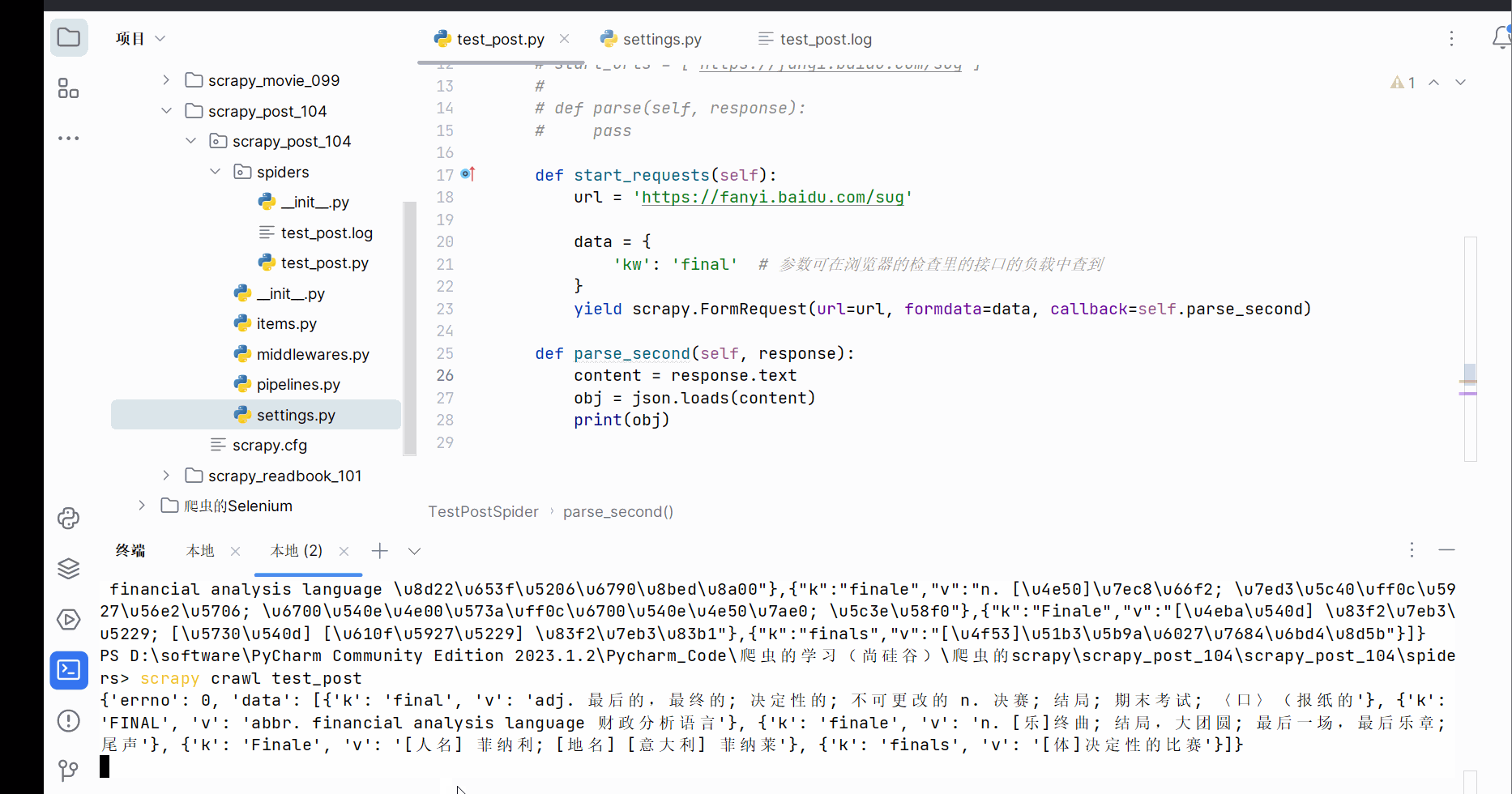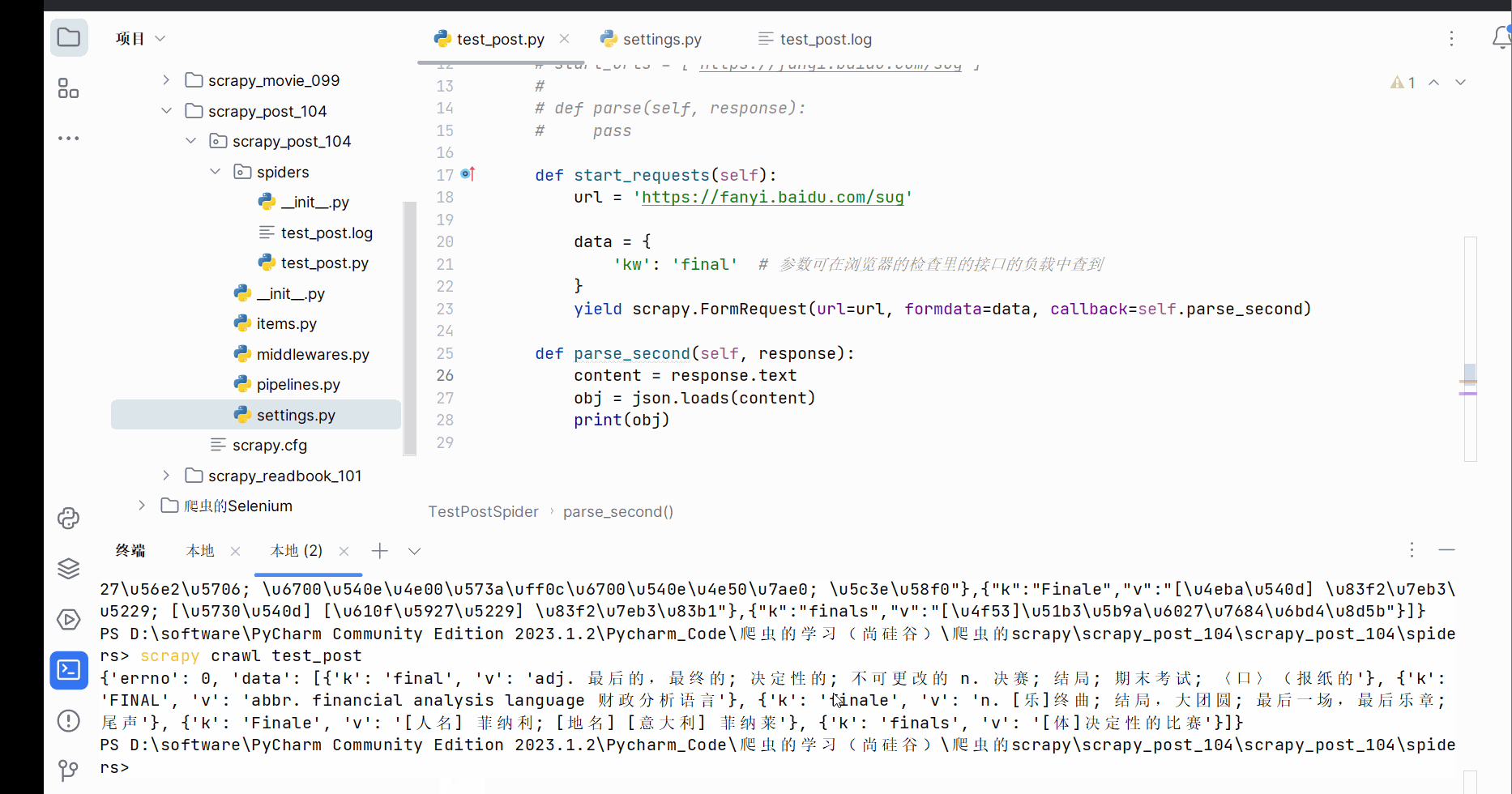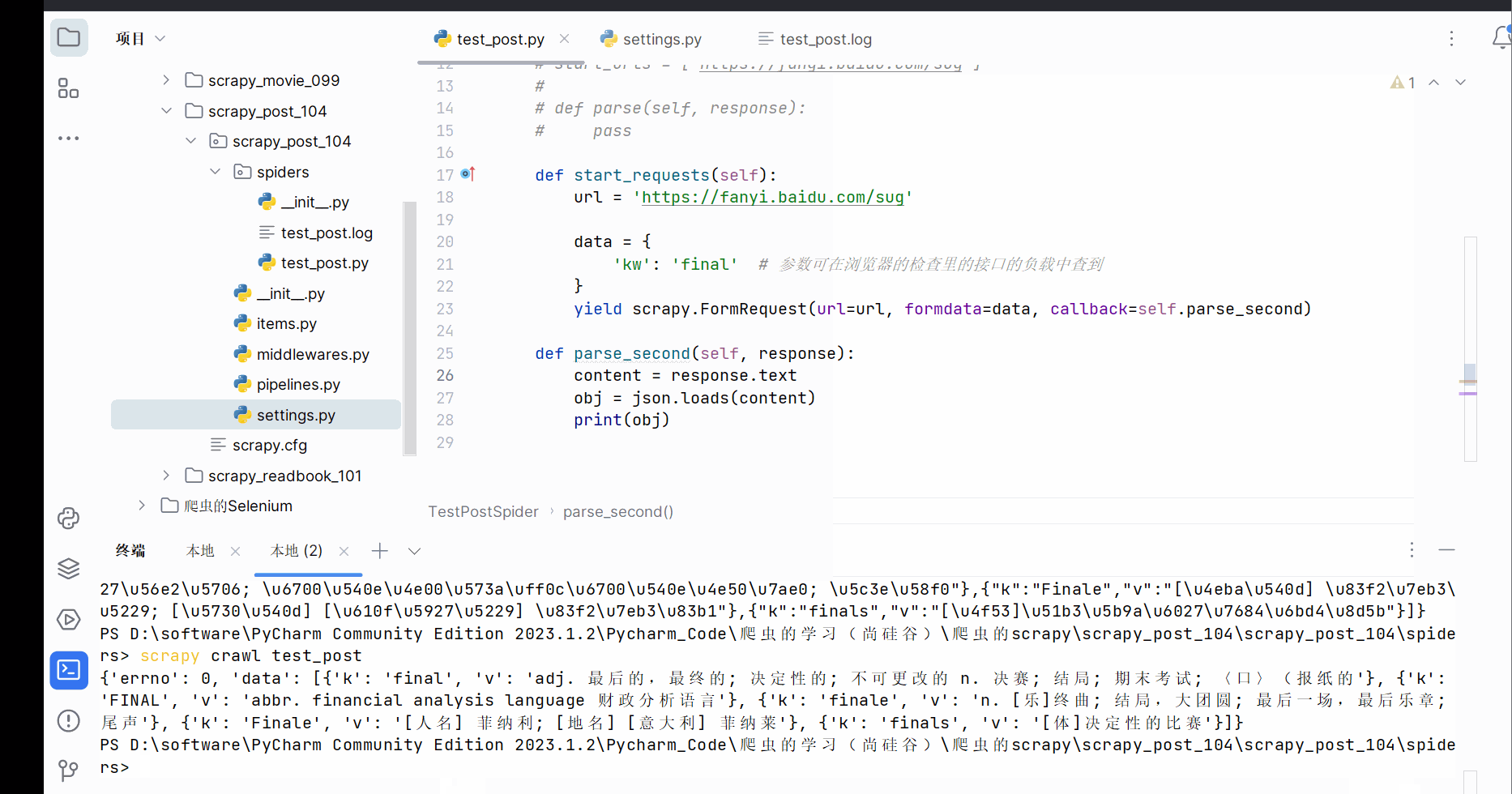
Python爬虫的scrapy的学习(学习于b站尚硅谷)
目录 一、scrapy 1. scrapy的安装 (1)什么是scrapy (2)scrapy的安装 2. scrapy的基本使用 (1)scrap的使用步骤 (2)代码的演示 3. scrapy之58同城项目结构和基本方法&…...

“深入解析JVM:揭秘Java虚拟机的工作原理“
标题:深入解析JVM:揭秘Java虚拟机的工作原理 摘要:本文将深入解析Java虚拟机(JVM)的工作原理,探讨其内部结构和运行机制。我们将介绍JVM的组成部分、类加载过程、内存管理、垃圾回收、即时编译等关键概念&…...

【数据结构与算法】十大经典排序算法-归并排序
🌟个人博客:www.hellocode.top 🏰Java知识导航:Java-Navigate 🔥CSDN:HelloCode. 🌞知乎:HelloCode 🌴掘金:HelloCode ⚡如有问题,欢迎指正&#…...

基于深度学习创建-表情符号--附源码
表情符号深度学习概述 如今,我们使用多种表情符号或头像来表达我们的心情或感受。它们充当人类的非语言线索。它们成为情感识别、在线聊天、品牌情感、产品评论等的关键部分。针对表情符号驱动的故事讲述的数据科学研究不断增加。 从图像中检测人类情绪非常流行,这可能是由…...
.netcore grpc的proto文件字段详解
一、.proto文件字段概述 grpc的接口传输参数都是根据.proto文件约定的字段格式进行传输的grpc提供了多种类型字段;主要包括标量值类型(基础类型)、日期时间、可为null类型、字节、列表、字典、Any类型(任意类型)、One…...

带你了解建堆的时间复杂度
目录 用向上调整建堆的时间复杂度 1.向上调整建堆的时间复杂度O(N*logN) 2.数学论证 3.相关代码 用向下调整建堆的时间复杂度 1.建堆的时间复杂度为O(N) 2.数学论证 3.相关代码 完结撒花✿✿ヽ(▽)ノ✿✿ 博主建议:面试的时候可能会被面试官问到建堆时间复杂度的证明过…...
人工智能原理(6)
目录 一、机器学习概述 1、学习和机器学习 2、学习系统 3、机器学习发展简史 4、机器学习分类 二、归纳学习 1、归纳学习的基本概念 2、变型空间学习 3、归纳偏置 三、决策树 1、决策树组成 2、决策树的构造算法CLS 3、ID3 4、决策树的偏置 四、基于实例的学习…...

单片机模块化编程文件创建流程
一、在工程文件夹下创建一个新的文件夹,命名为“ModulesCodesFiles”,译为“模块化代码文件”,用于存放所有模块化代码文件。 二、在“ModulesCodesFiles”文件夹下为每个模块创建一个新的文件夹,命名为模块的名称,例…...

docker image
docker image 1. 由来 docker image是Docker容器管理工具中的一个命令,用于管理和操作Docker镜像。 2. 常见五种示例命令和说明 以下是docker image的常见示例命令及其说明: 示例一:列出所有镜像 docker image ls描述:使用d…...

力扣75——单调栈
总结leetcode75中的单调栈算法题解题思路。 上一篇:力扣75——区间集合 力扣75——单调栈 1 每日温度2 股票价格跨度1 - 2 解题总结 1 每日温度 题目: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer &…...

Webpack和Parcel详解
构建工具和打包器是在开发过程中帮助组织、优化和打包项目的工具。它们可以处理依赖管理、资源优化、代码转换等任务,从而使开发流程更高效。以下是关于构建工具和打包器的一些指导: **Webpack:** Webpack 是一个功能强大的模块打包器&#…...
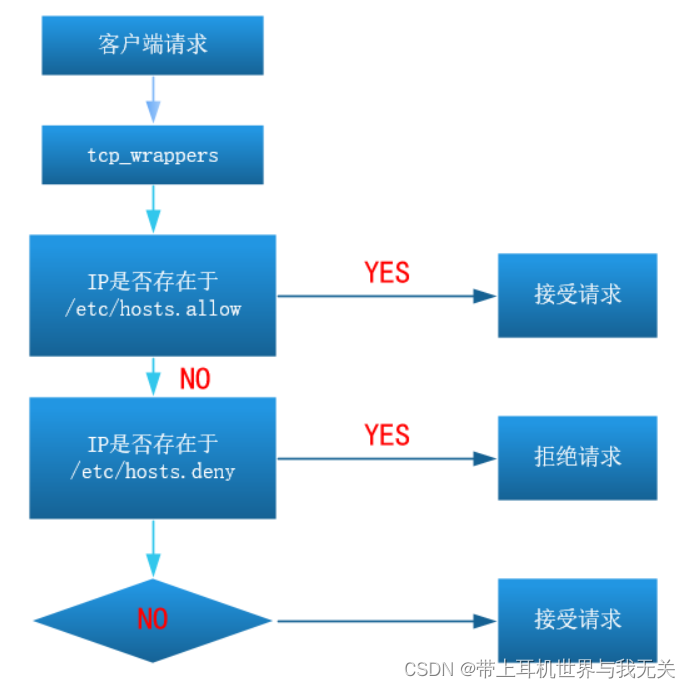
linux系统服务学习(六)FTP服务学习
文章目录 FTP、NFS、SAMBA系统服务一、FTP服务概述1、FTP服务介绍2、FTP服务的客户端工具3、FTP的两种运行模式(了解)☆ 主动模式☆ 被动模式 4、搭建FTP服务(重要)5、FTP的配置文件详解(重要) 二、FTP任务…...

7.原 型
7.1原型 【例如】 另外- this指向: 构造函数和原型对象中的this都指向实例化的对象 7.2 constructor属性 每个原型对象里面都有个constructor属性( constructor构造函数) 作用:该属性指向该原型对象的构造函数 使用场景: 如果有多个对象的方法&#…...
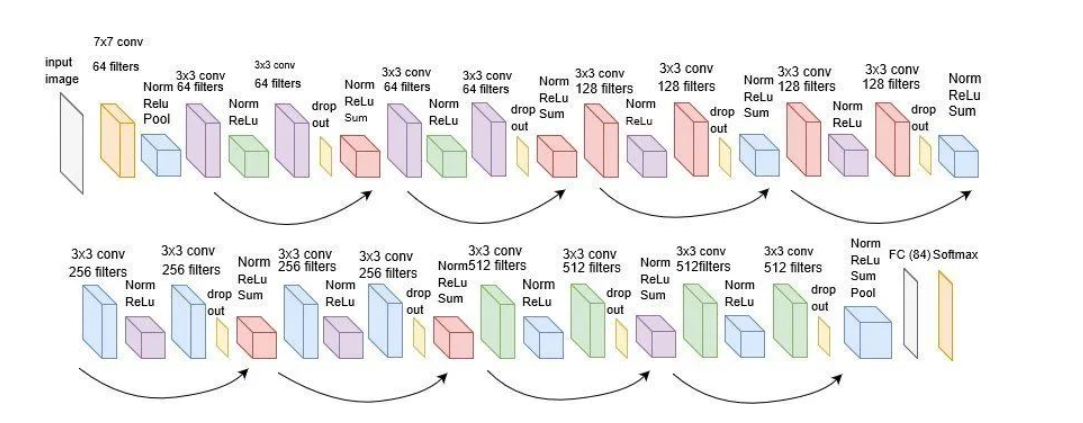
【图像分类】理论篇(2)经典卷积神经网络 Lenet~Resenet
目录 1、卷积运算 2、经典卷积神经网络 2.1 Lenet 网络构架 代码实现 2.2 Alexnet 网络构架 代码实现 2.3 VGG VGG16网络构架 代码实现 2.4 ResNet ResNet50网络构架 代码实现 1、卷积运算 在二维卷积运算中,卷积窗口从输入张量的左上角开始ÿ…...

C++系列-内存模型
内存模型 内存模型四个区代码区全局区栈区堆区内存开辟和释放在堆区开辟数组 内存模型四个区 不同区域存放的数据生命周期是不同的,更为灵活。 代码区:存放函数体的二进制代码,操作系统管理。全局区:存放全局变量,常…...

[管理与领导-30]:IT基层管理者 - 人的管理 - 向上管理,管理好你的上司,职业发展事半功倍。什么样的上司不值得跟随?
目录 前言: 一、什么是向上管理 二、为什么要向上管理 三、如何进行向上管理 四、向上管理的注意事项 五、向上管理的忌讳 六、向上管理常犯的错 七、如何帮助上司解决他关心的问题 7.1 如何帮助上司解决他关心的问题 7.2 如何帮助上司降低压力 八、什么…...
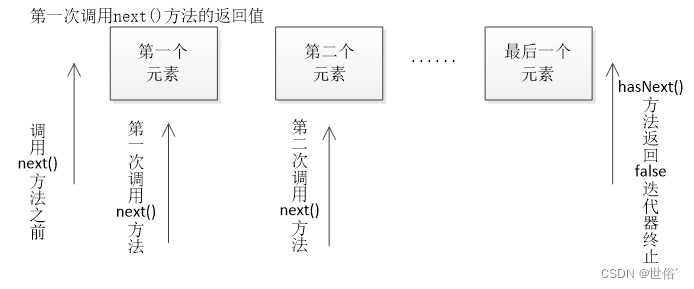
Java进阶篇--迭代器模式
目录 同步迭代器(Synchronous Iterator): Iterator 接口 常用方法: 注意: 扩展小知识: 异步迭代器(Asynchronous Iterator): 常用的方法 注意: 总结:…...

如何智能批量添加EXIF水印:摄影师的自动化参数标注解决方案
如何智能批量添加EXIF水印:摄影师的自动化参数标注解决方案 【免费下载链接】semi-utils 一个批量添加相机机型和拍摄参数的工具,后续「可能」添加其他功能。 项目地址: https://gitcode.com/gh_mirrors/se/semi-utils 摄影爱好者和专业摄影师都面…...

DSP开发环境搭建实战:从CCSv3.3安装到XDS510仿真器配置全解析
1. CCSv3.3安装全流程详解 第一次接触DSP开发的朋友,安装CCSv3.3这个"老前辈"可能会遇到各种意想不到的问题。我当年在实验室安装时,光是补丁问题就折腾了一整天。下面就把这些年积累的实战经验分享给大家。 首先需要准备的是安装文件。虽然现…...

DeepMind CEO 访谈:人类离 AGI 只剩 4 年,只差最后 3 块拼图
作者:老纪的技术唠嗑局 楔子 前几天(4 月 29 日),Google DeepMind CEO、2024 年诺贝尔化学奖得主 Demis Hassabis 在一期播客节目《Agents, AGI & The Next Big Scientific Breakthrough》[1] 中,预测 AGI&#…...

ARM TLB机制与虚拟化加速:TLBIP指令与TLBID域深度解析
1. ARM TLB机制与虚拟化加速 在现代ARM架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,其性能直接影响虚拟地址转换效率。随着虚拟化技术的普及,ARMv8/v9架构引入了…...

RK3568开发板Android 11系统移植实战:从内核驱动到HAL适配
1. 项目概述与学习路径规划拿到一块像迅为iTOP-RK3568这样的开发板,想把最新的Android 11系统跑起来,这个想法听起来挺酷,但很多朋友一看到“系统移植”四个字就有点发怵,感觉这是大神才能玩转的领域。其实,只要你熟悉…...

MQTT 协议 超详细精讲
一、MQTT 协议简介全称:Message Queuing Telemetry Transport(消息队列遥测传输协议)定位:专为物联网、嵌入式设备、低带宽、弱网环境设计的轻量级发布 / 订阅式消息传输协议,是数字孪生、智能家居、工业物联网最常用的…...

如何用淘金币自动化脚本每天节省20分钟?完整指南揭秘
如何用淘金币自动化脚本每天节省20分钟?完整指南揭秘 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 淘金币…...

3步搞定!MoviePilot智能批量重命名让你的媒体库整齐划一
3步搞定!MoviePilot智能批量重命名让你的媒体库整齐划一 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot 还在为杂乱的媒体文件名头疼吗?"The.Matrix.1999.1080p.BluRay.x264…...

跨境直播进入“下半场”:2026年值得关注的几个新方向
很多人提到跨境直播,第一反应还是“流量”和“带货”。但如果这两年持续关注行业变化,会发现一个明显趋势:跨境直播正在从“内容竞争”转向“技术能力竞争”。尤其从2025年开始,行业越来越卷的不只是主播,而是整个直播…...

集成三相桥驱动的MCU:AiP8F7201电机控制方案解析
1. 项目概述:为什么我们需要“集成三相桥式驱动的微控制器”?在电机控制领域,尤其是消费电子、家电、工业自动化这些我们每天都会接触到的场景里,工程师们一直在和一堆“麻烦”作斗争。想象一下,你要设计一个驱动无刷直…...