2023国赛数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录
- 算法介绍
- FP树表示法
- 构建FP树
- 实现代码
- 建模资料
## 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
算法介绍
FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,他与Apriori算法一样也是用来挖掘频繁项集的,不过不同的是,FP-Tree算法是Apriori算法的优化处理,他解决了Apriori算法在过程中会产生大量的候选集的问题,而FP-Tree算法则是发现频繁模式而不产生候选集。但是频繁模式挖掘出来后,产生关联规则的步骤还是和Apriori是一样的。
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth。Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下。FPGrowth不同于Apriori的“试探”策略,算法只需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。
FP代表频繁模式(Frequent Pattern) ,算法主要分为两个步骤:FP-tree构建、挖掘频繁项集。
FP树表示法
FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造。由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠。路径相互重叠越多,使用FP树结构获得的压缩效果越好;如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据。
一颗FP树如下图所示:
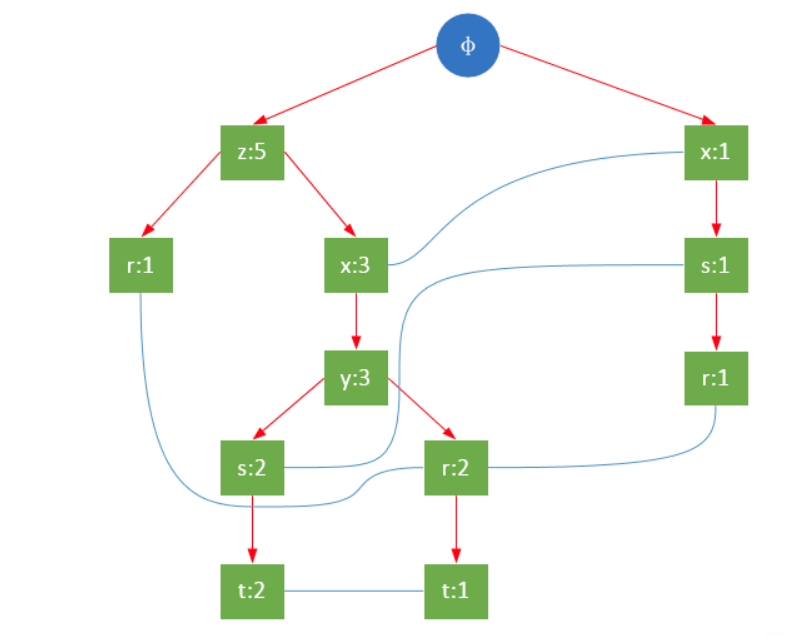
通常,FP树的大小比未压缩的数据小,因为数据的事务常常共享一些共同项,在最好的情况下,所有的事务都具有相同的项集,FP树只包含一条节点路径;当每个事务都具有唯一项集时,导致最坏情况发生,由于事务不包含任何共同项,FP树的大小实际上与原数据的大小一样。
FP树的根节点用φ表示,其余节点包括一个数据项和该数据项在本路径上的支持度;每条路径都是一条训练数据中满足最小支持度的数据项集;FP树还将所有相同项连接成链表,上图中用蓝色连线表示。
为了快速访问树中的相同项,还需要维护一个连接具有相同项的节点的指针列表(headTable),每个列表元素包括:数据项、该项的全局最小支持度、指向FP树中该项链表的表头的指针。
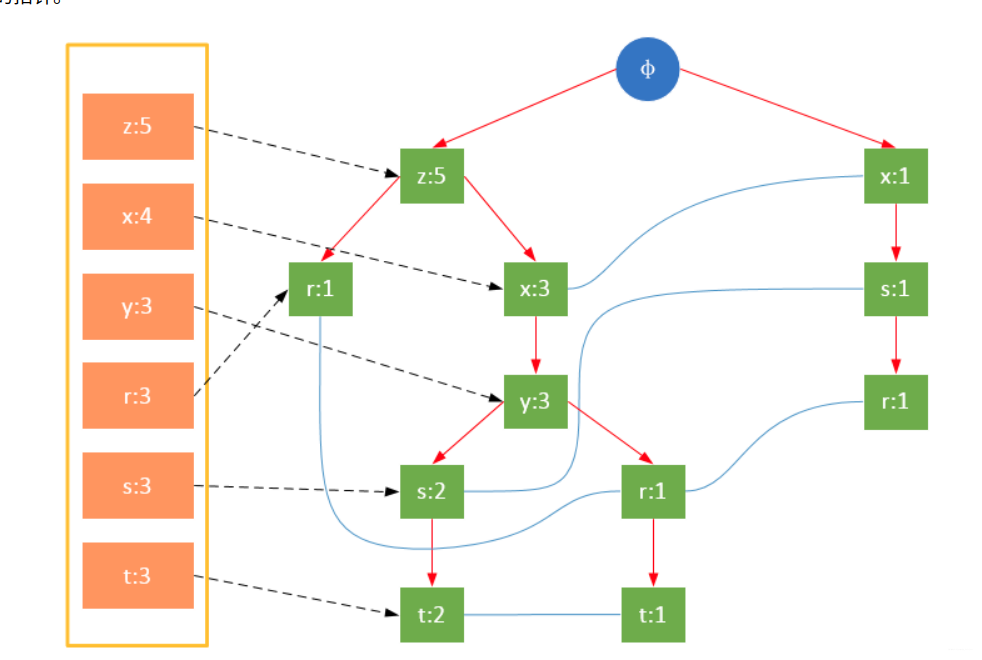
构建FP树
现在有如下数据:
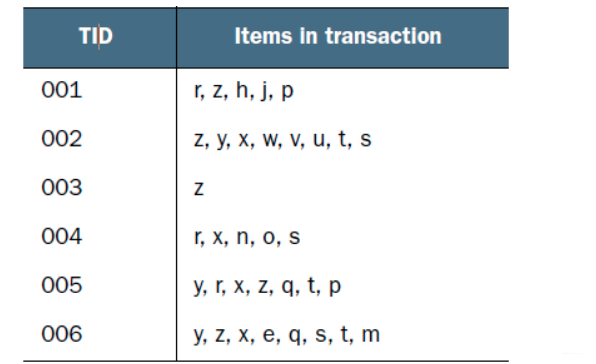
FP-growth算法需要对原始训练集扫描两遍以构建FP树。
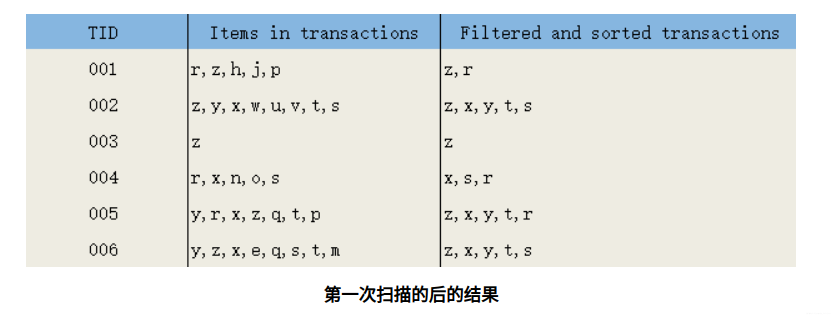
第一次扫描,过滤掉所有不满足最小支持度的项;对于满足最小支持度的项,按照全局最小支持度排序,在此基础上,为了处理方便,也可以按照项的关键字再次排序。
第二次扫描,构造FP树。
参与扫描的是过滤后的数据,如果某个数据项是第一次遇到,则创建该节点,并在headTable中添加一个指向该节点的指针;否则按路径找到该项对应的节点,修改节点信息。具体过程如下所示:
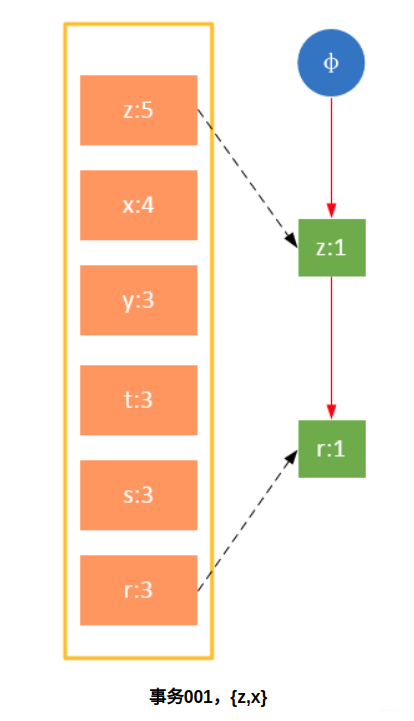
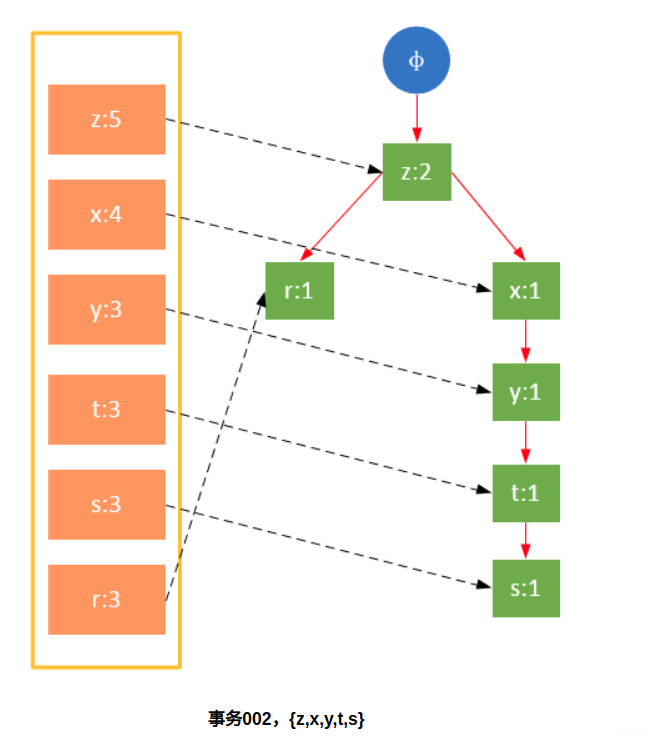
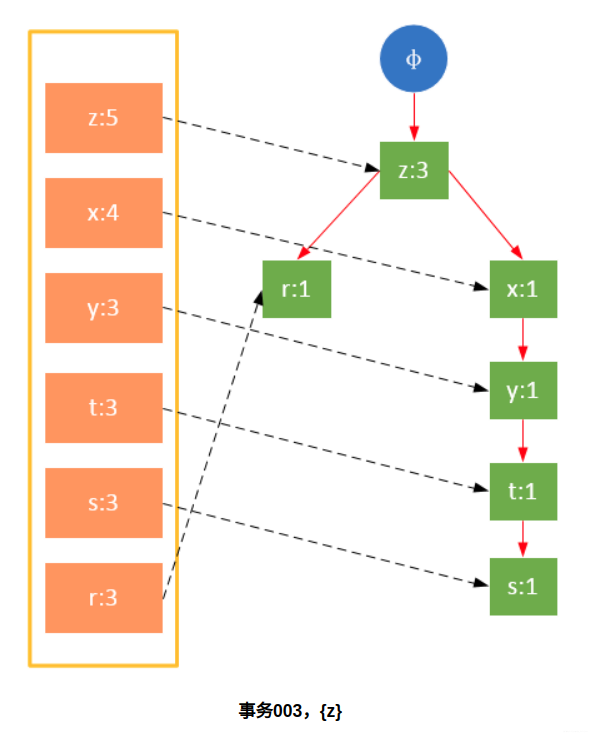
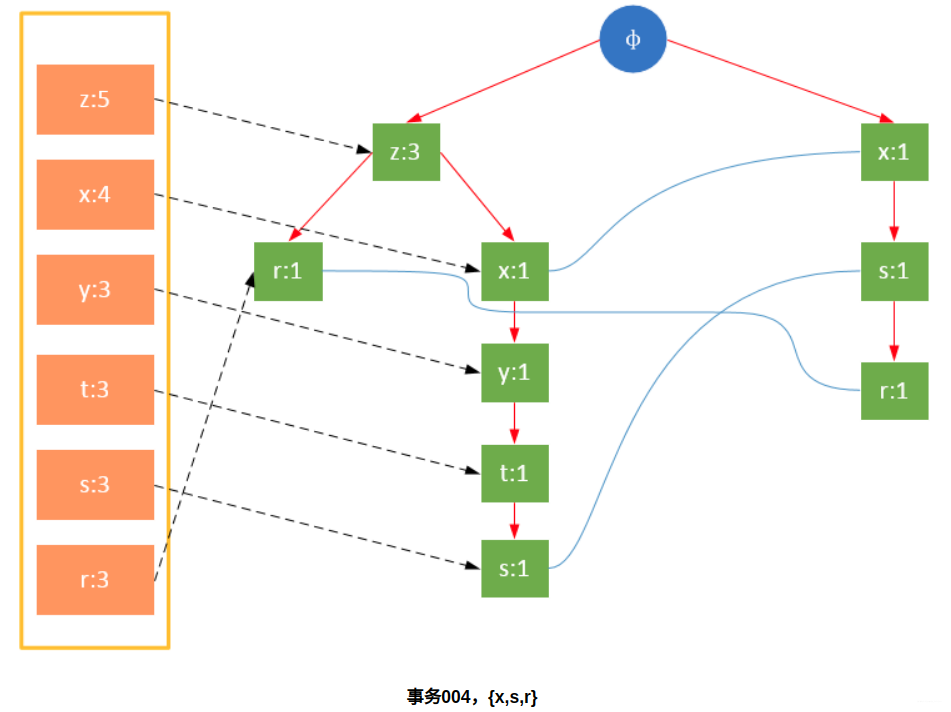
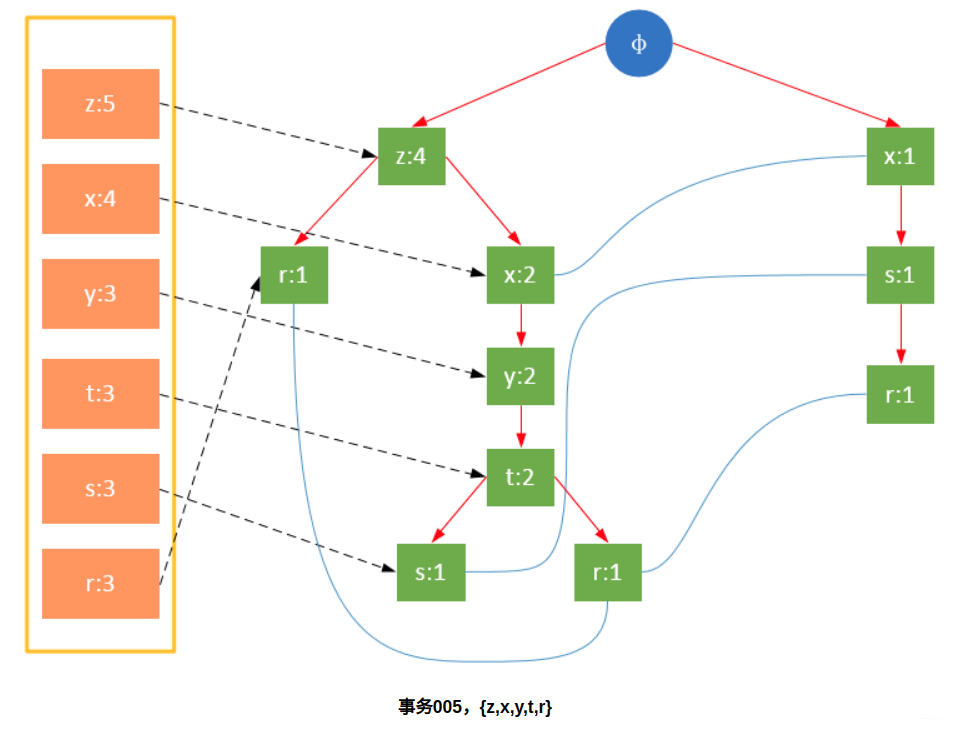
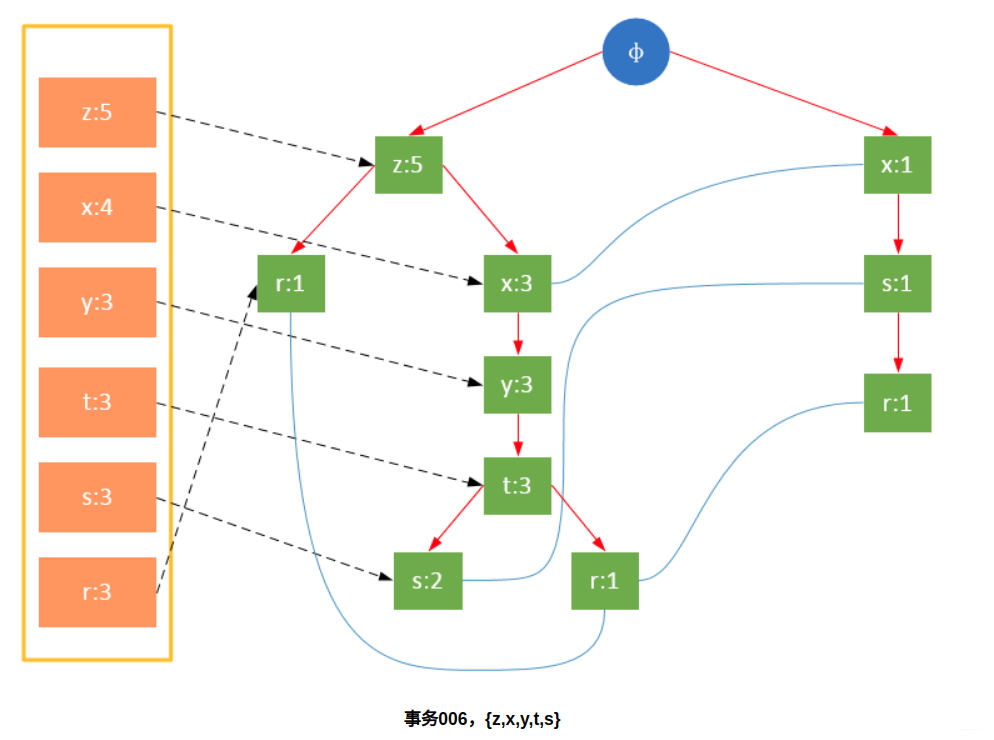
从上面可以看出,headTable并不是随着FPTree一起创建,而是在第一次扫描时就已经创建完毕,在创建FPTree时只需要将指针指向相应节点即可。从事务004开始,需要创建节点间的连接,使不同路径上的相同项连接成链表。
实现代码
def loadSimpDat():simpDat = [['r', 'z', 'h', 'j', 'p'],['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],['z'],['r', 'x', 'n', 'o', 's'],['y', 'r', 'x', 'z', 'q', 't', 'p'],['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]return simpDatdef createInitSet(dataSet):retDict = {}for trans in dataSet:fset = frozenset(trans)retDict.setdefault(fset, 0)retDict[fset] += 1return retDictclass treeNode:def __init__(self, nameValue, numOccur, parentNode):self.name = nameValueself.count = numOccurself.nodeLink = Noneself.parent = parentNodeself.children = {}def inc(self, numOccur):self.count += numOccurdef disp(self, ind=1):print(' ' * ind, self.name, ' ', self.count)for child in self.children.values():child.disp(ind + 1)def createTree(dataSet, minSup=1):headerTable = {}#此一次遍历数据集, 记录每个数据项的支持度for trans in dataSet:for item in trans:headerTable[item] = headerTable.get(item, 0) + 1#根据最小支持度过滤lessThanMinsup = list(filter(lambda k:headerTable[k] < minSup, headerTable.keys()))for k in lessThanMinsup: del(headerTable[k])freqItemSet = set(headerTable.keys())#如果所有数据都不满足最小支持度,返回None, Noneif len(freqItemSet) == 0:return None, Nonefor k in headerTable:headerTable[k] = [headerTable[k], None]retTree = treeNode('φ', 1, None)#第二次遍历数据集,构建fp-treefor tranSet, count in dataSet.items():#根据最小支持度处理一条训练样本,key:样本中的一个样例,value:该样例的的全局支持度localD = {}for item in tranSet:if item in freqItemSet:localD[item] = headerTable[item][0]if len(localD) > 0:#根据全局频繁项对每个事务中的数据进行排序,等价于 order by p[1] desc, p[0] descorderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: (p[1],p[0]), reverse=True)]updateTree(orderedItems, retTree, headerTable, count)return retTree, headerTabledef updateTree(items, inTree, headerTable, count):if items[0] in inTree.children: # check if orderedItems[0] in retTree.childreninTree.children[items[0]].inc(count) # incrament countelse: # add items[0] to inTree.childreninTree.children[items[0]] = treeNode(items[0], count, inTree)if headerTable[items[0]][1] == None: # update header tableheaderTable[items[0]][1] = inTree.children[items[0]]else:updateHeader(headerTable[items[0]][1], inTree.children[items[0]])if len(items) > 1: # call updateTree() with remaining ordered itemsupdateTree(items[1:], inTree.children[items[0]], headerTable, count)def updateHeader(nodeToTest, targetNode): # this version does not use recursionwhile (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!nodeToTest = nodeToTest.nodeLinknodeToTest.nodeLink = targetNodesimpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
上面的代码在第一次扫描后并没有将每条训练数据过滤后的项排序,而是将排序放在了第二次扫描时,这可以简化代码的复杂度。
控制台信息:

建模资料
资料分享: 最强建模资料


相关文章:
2023国赛数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录 算法介绍FP树表示法构建FP树实现代码 建模资料 ## 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,…...

GPT系列总结
1.GPT1 无监督预训练有监督的子任务finetuning https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf 1.1 Unsupervised pre-training (1)基于一个transformer decoder,通过一个窗口的输入得…...

【福建事业单位-综合基础知识】05民法典
这里写自定义目录标题 一、民法概述概念原则总结 二、自然人概念总结 三、民事法律行为总结 民法考察2-4题(重点总则篇) 一、民法概述 概念原则 总结 二、自然人 概念 总结 三、民事法律行为 总结...

微服务篇
微服务篇 springcloud 常见组件有哪些 面试官: Spring Cloud 5大组件有哪些? 候选人: 早期我们一般认为的Spring Cloud五大组件是 Eureka:注册中心Ribbon:负载均衡Feign:远程调用Hystrix:…...
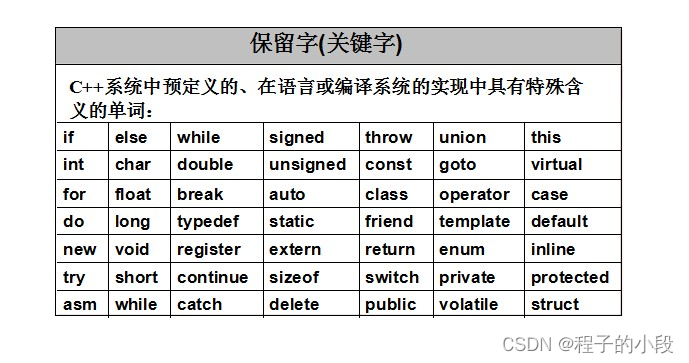
C++ 的关键字(保留字)完整介绍
1. asm asm (指令字符串):允许在 C 程序中嵌入汇编代码。 2. auto auto(自动,automatic)是存储类型标识符,表明变量"自动"具有本地范围,块范围的变量声明(如for循环体内的变量声明…...
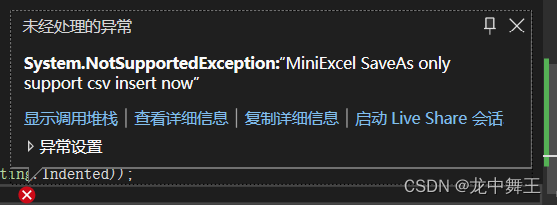
C#小轮子:MiniExcel,快速操作Excel
文章目录 前言环境安装功能测试普通读写读新建Excel表格完全一致测试:成功大小写测试:严格大小写别名读测试:成功 写普通写别名写内容追加更新模板写 其它功能xlsx和CSV互转 前言 Excel的操作是我们最常用的操作,Excel相当于一个…...

Ribbon负载均衡
Ribbon与Eureka的关系 Eureka的服务拉取与负载均衡都是由Ribbon来实现的。 当服务发送http://userservice/user/xxxhtt://userservice/user/xxx请求时,是无法到达userservice服务的,会通过Ribbon会把这个请求拦截下来,通过Eureka-server转换…...
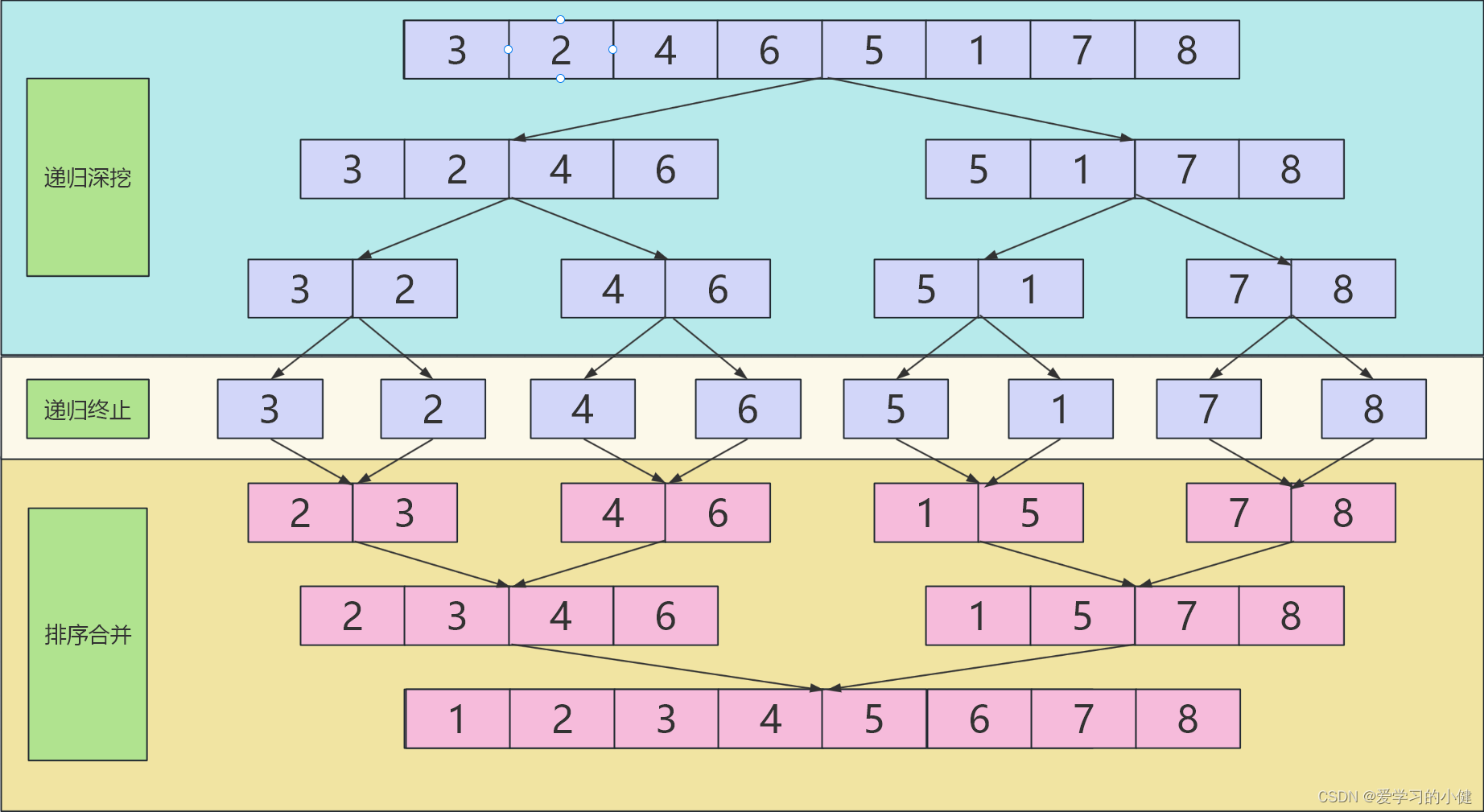
LeetCode--HOT100题(33)
目录 题目描述:148. 排序链表(中等)题目接口解题思路代码 PS: 题目描述:148. 排序链表(中等) 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 LeetCode做题链接࿱…...

【docker练习】
1.安装docker服务,配置镜像加速器 看这篇文章https://blog.csdn.net/HealerCCX/article/details/132342679?spm1001.2014.3001.5501 2.下载系统镜像(Ubuntu、 centos) [rootnode1 ~]# docker pull centos [rootnode1 ~]# docker pull ubu…...
韦东山-电子量产工具项目:业务系统
代码结构 所有代码都已通过测试跑通,其中代码结构如下: 一、include文件夹 1.1 common.h #ifndef _COMMON_H #define _COMMON_Htypedef struct Region {int iLeftUpX; //区域左上方的坐标int iLeftUpY; //区域左下方的坐标int iWidth; //区域宽…...
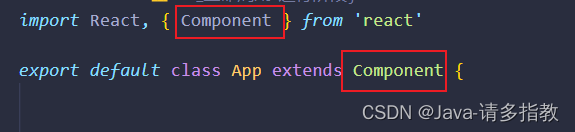
React(6)
1.React插槽 import React, { Component } from react import Child from ./compoent/Childexport default class App extends Component {render() {return (<div><Child><div>App下的div</div></Child></div>)} }import React, { Compon…...
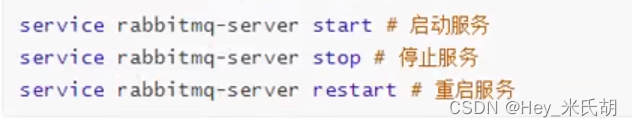
RabbitMq-2安装与配置
Rabbitmq的安装 1.上传资源 注意:rabbitmq的版本必须与erlang编译器的版本适配 2.安装依赖环境 //打开虚拟机 yum install build-essential openssl openssl-devel unixODBC unixODBC-devel make gcc gcc-c kernel-devel m4 ncurses-devel tk tc xz3.安装erlan…...
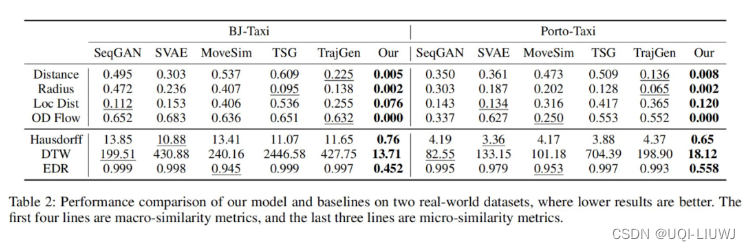
论文笔记:Continuous Trajectory Generation Based on Two-Stage GAN
2023 AAAI 1 intro 1.1 背景 建模人类个体移动模式并生成接近真实的轨迹在许多应用中至关重要 1)生成轨迹方法能够为城市规划、流行病传播分析和交通管控等城市假设分析场景提供仿仿真数据支撑2)生成轨迹方法也是目前促进轨迹数据开源共享与解决轨迹数…...

redis实战-缓存数据解决缓存与数据库数据一致性
缓存的定义 缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。防止过高的数据访问猛冲系统,导致其操作线程无法及时处理信息而瘫痪,这在实际开发中对企业讲,对产品口碑,用户评价都是致命的;所以企业非常重视缓存…...

【排序】选择排序
文章目录 选择排序时间复杂度空间复杂度稳定性 代码 选择排序 以从小到大为例进行说明。 选择排序就是定义出一个最小值下标,然后遍历整个剩下的数组选择出最小的放进最小值下标的位置。 时间复杂度 O(N) 遍历一次即可 空间复杂度 O(1) 稳定性 不稳定 代码 p…...

深入浅出Pytorch函数——torch.nn.init.trunc_normal_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

探索高级UI、源码解析与性能优化,了解开源框架及Flutter,助力Java和Kotlin筑基,揭秘NDK的魅力!
课程链接: 链接: https://pan.baidu.com/s/13cR0Ip6lzgFoz0rcmgYGZA?pwdy7hp 提取码: y7hp 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v4的分享 课程介绍: 📚【01】Java筑基:全方位指…...

国外服务器怎么有效降低延迟
国外服务器怎么有效降低延迟?在全球化网络环境下,越来越多的企业和个人选择使用国外服务器来托管网站、应用程序或数据。然而,由于地理位置、网络连接等因素,使用国外服务器时可能会遇到延迟较高的问题。高延迟不仅影响用户体验,…...
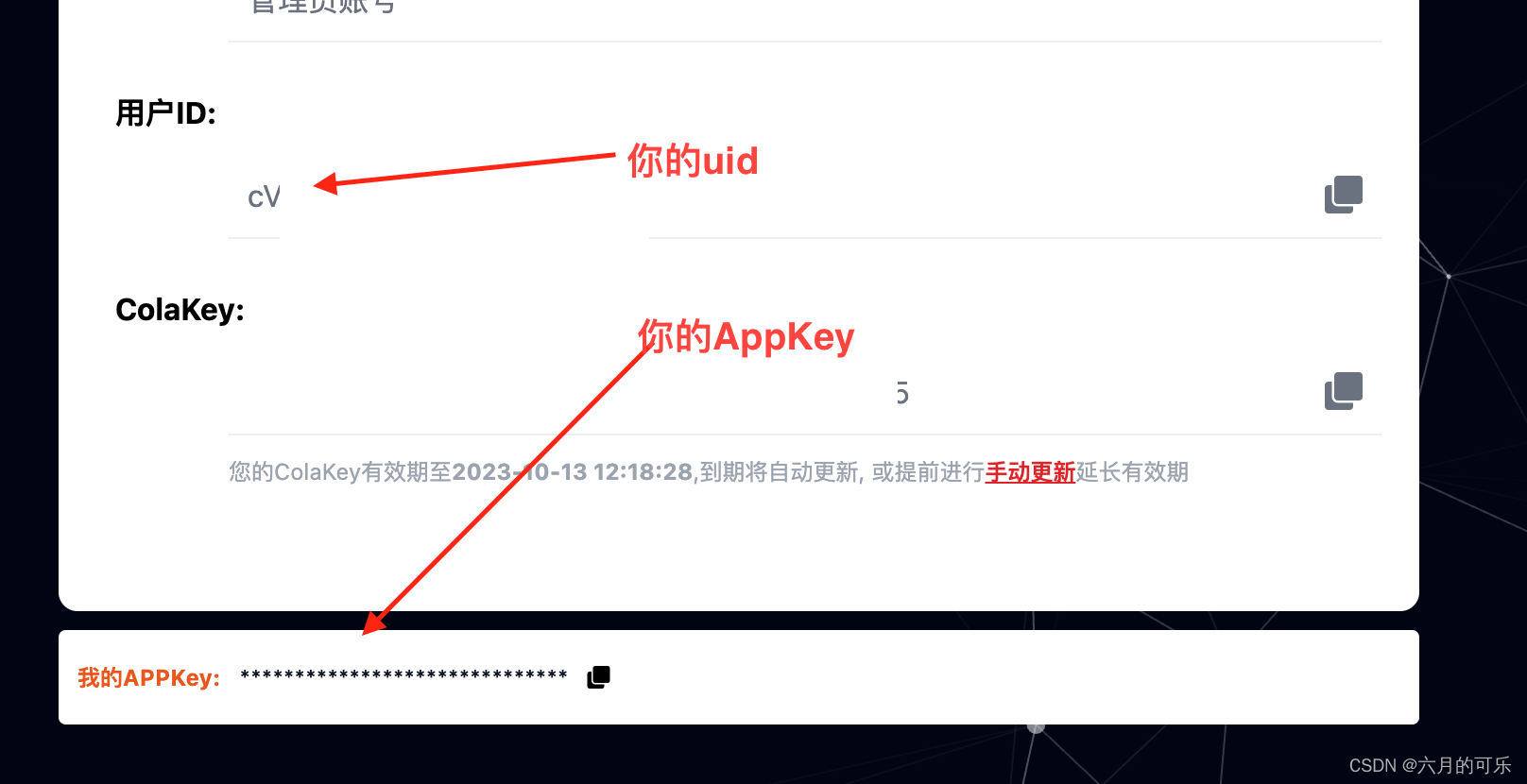
AI百度文心一言大语言模型接入使用(中国版ChatGPT)
百度文心一言接入使用(中国版ChatGPT) 一、百度文心一言API二、使用步骤1、接口2、请求参数3、请求参数示例4、接口 返回示例 三、 如何获取appKey和uid1、申请appKey:2、获取appKey和uid 四、重要说明 一、百度文心一言API 基于百度文心一言语言大模型…...
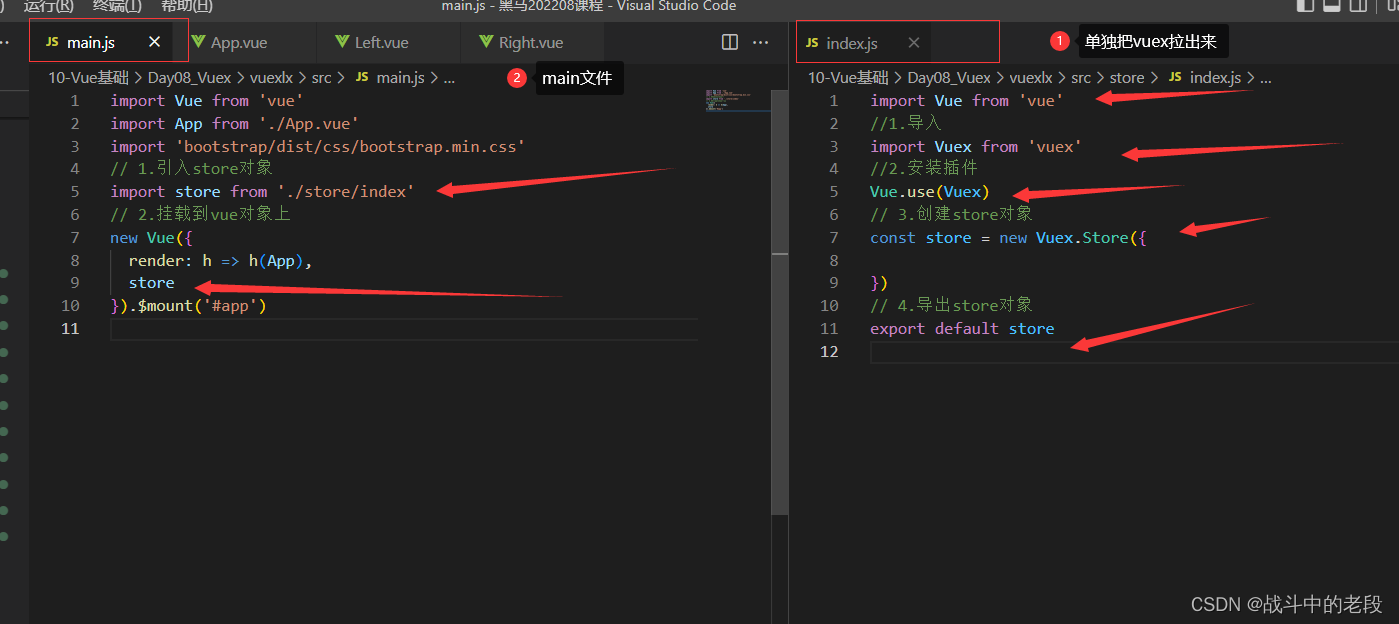
vue 安装并配置vuex
1.安装vuex命令:npm i vuex3.6.2 2.全局配置 在main文件里边导入-安装-挂载 main.js页面配置的 import Vue from vue import App from ./App.vue import Vuex from vuex//导入 Vue.use(Vuex)//安装插件 // 创建store对象 const store new Vuex.Store({ }) // 挂载到vue对象上…...

【第四周】论文精读:Frustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks
极简检索即可大幅刷新高难度推理基准主流观点认为简单RAG无法提升MMLU、MATH、GPQA等高难度推理任务,甚至会损害性能;本文推翻这一共识,证明核心瓶颈并非检索范式,而是缺少高质量、广覆盖、可单机部署的检索库;提出COM…...

AI时代开发格局剧变:TypeScript在AI辅助开发中超越Python,登顶GitHub榜首
2026年3月,GitHub《Octoverse 2025》报告数据在技术圈彻底引爆——TypeScript首次超越Python,成为GitHub月活跃贡献者最多的编程语言,而这一历史性转折的核心推手,正是AI辅助开发的全面普及。这不是简单的语言热度更迭,…...

告别VirtualBox默认20G!保姆级教程:从创建到动态扩容,打造你的专属开发环境
从零规划VirtualBox磁盘空间:开发环境搭建的黄金法则 刚接触VirtualBox的新手开发者们,是否曾在项目进行到一半时突然发现磁盘空间不足?那种被迫中断工作流程去处理存储问题的体验,足以毁掉一天的开发效率。本文将带你从源头规避这…...

终极防撤回解决方案:RevokeMsgPatcher完全攻略
终极防撤回解决方案:RevokeMsgPatcher完全攻略 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHu…...

三驾马车驱动:OpenRGB如何重塑跨平台RGB灯光统一控制体验
三驾马车驱动:OpenRGB如何重塑跨平台RGB灯光统一控制体验 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. Rel…...

Qwen3-0.6B-FP8效果对比:与Phi-3-mini、Gemma-2B在低资源设备上的实测PK
Qwen3-0.6B-FP8效果对比:与Phi-3-mini、Gemma-2B在低资源设备上的实测PK 想在小显存的电脑上跑个大模型,体验一下AI对话的乐趣,是不是总被“显存不足”的提示劝退?别急,今天我们就来一场专为“小显存”设备准备的AI模…...

保姆级避坑指南:在Ubuntu 20.04上搞定Carla 0.9.15与ROS Noetic的联合仿真环境
保姆级避坑指南:Ubuntu 20.04下Carla 0.9.15与ROS Noetic联合仿真环境搭建全攻略 搭建自动驾驶仿真环境就像在雷区跳舞——稍有不慎就会触发依赖冲突、版本不兼容或环境变量错误。本文将带你用最短时间穿越这片雷区,特别针对那些官方文档没写、论坛讨论含…...

Granite TimeSeries FlowState R1赋能Java应用:商品销量预测微服务开发实录
Granite TimeSeries FlowState R1赋能Java应用:商品销量预测微服务开发实录 最近在做一个电商后台的优化项目,其中一个核心需求就是希望能提前知道商品未来一段时间的销量走势。老板想备货,运营想搞活动,都离不开这个数据。传统的…...
Pixel Mind Decoder 效果惊艳展示:多语言文本情绪解码对比
Pixel Mind Decoder 效果惊艳展示:多语言文本情绪解码对比 1. 情绪解码技术的新突破 在数字沟通日益频繁的今天,准确理解文字背后的情绪成为AI领域的重要挑战。Pixel Mind Decoder作为新一代多语言情绪分析工具,通过深度学习模型实现了对文…...

内核热补丁和function trace的兼容性浅析
本文代码基于linux内核4.19.195. 之前的文章简要讲解了内核热补丁的原理,也提到了热补丁是基于ftrace框架实现的。平时我们在用ftrace时,最常用的功能当属function tracer了。这天一个有趣的问题突然浮现在我的脑海里: 如果我对同一个函数&am…...