C++快速回顾(二)
前言
在Android音视频开发中,网上知识点过于零碎,自学起来难度非常大,不过音视频大牛Jhuster提出了《Android 音视频从入门到提高 - 任务列表》,结合我自己的工作学习经历,我准备写一个音视频系列blog。C/C++是音视频必备编程语言,我准备用几篇文章来快速回顾C++。本文是音视频系列blog的其中一个, 对应的要学习的内容是:快速回顾C++的类,IO库,顺序容器,泛型算法。
音视频系列blog
音视频系列blog: 点击此处跳转查看
目录

1 类
1.1 定义抽象数据类型
1.1.1 定义一个简单的类
当定义一个简单的C++类时,通常需要考虑类的成员变量(属性)和成员函数(方法)。以下是一个简单的示例,演示如何定义一个表示矩形的类:
#include <iostream>class Rectangle {
private:double width;double height;public:// 构造函数Rectangle(double w, double h) : width(w), height(h) {}// 成员函数:计算矩形的面积double calculateArea() {return width * height;}// 成员函数:获取矩形的宽度double getWidth() {return width;}// 成员函数:获取矩形的高度double getHeight() {return height;}
};int main() {// 创建一个矩形对象Rectangle myRectangle(5.0, 3.0);// 计算并输出矩形的面积std::cout << "Rectangle Area: " << myRectangle.calculateArea() << std::endl;// 获取并输出矩形的宽度和高度std::cout << "Width: " << myRectangle.getWidth() << std::endl;std::cout << "Height: " << myRectangle.getHeight() << std::endl;return 0;
}
在上面的示例中,定义了一个名为Rectangle的类,其中包含私有成员变量width和height,以及公有成员函数用于计算面积、获取宽度和获取高度。在main函数中,创建了一个Rectangle对象,并演示了如何使用成员函数来操作对象的属性和行为。这只是一个简单的示例,实际的类可以包含更多复杂的功能和属性。
1.1.2 定义类相关的非成员函数
在C++中,可以定义与类相关的非成员函数。这些函数不是类的成员,但可以用于操作类的对象或与类的属性和方法交互。以下是一个例子,演示如何在C++中定义一个与之前矩形类相关的非成员函数:
#include <iostream>class Rectangle {
private:double width;double height;public:Rectangle(double w, double h) : width(w), height(h) {}double calculateArea() {return width * height;}double getWidth() {return width;}double getHeight() {return height;}// 声明友元函数friend double calculatePerimeter(const Rectangle& rect);
};// 定义与类相关的非成员函数
double calculatePerimeter(const Rectangle& rect) {return 2 * (rect.width + rect.height);
}int main() {Rectangle myRectangle(5.0, 3.0);std::cout << "Rectangle Area: " << myRectangle.calculateArea() << std::endl;std::cout << "Rectangle Perimeter: " << calculatePerimeter(myRectangle) << std::endl;return 0;
}
在上面的示例中,定义了一个名为calculatePerimeter的非成员函数,用于计算矩形的周长。为了让这个非成员函数能够访问私有成员变量width和height,在Rectangle类中使用了friend关键字将其声明为友元函数。
然后,在main函数中,创建了一个Rectangle对象并使用类的成员函数计算面积,同时使用非成员函数计算周长。请注意,友元函数允许非成员函数访问类的私有成员,但过度使用友元函数可能破坏封装性。在实际使用中,应该仔细考虑何时使用友元函数。
1.1.3 构造函数
C++中的构造函数是一种特殊类型的成员函数,用于初始化类的对象。构造函数在创建对象时自动调用,以确保对象的正确初始化。构造函数的名称与类名相同,没有返回类型,甚至没有void。以下是关于C++构造函数的一些重要信息:
- 默认构造函数(Default Constructor):如果没有显式定义构造函数,编译器会自动生成一个默认构造函数。默认构造函数不接受任何参数,仅用于执行对象的默认初始化。例如:
class MyClass {
public:// 默认构造函数MyClass() {// 初始化代码}
};
- 带参数的构造函数(Parameterized Constructor):可以定义带参数的构造函数,用于在创建对象时传递初始值。例如:
class Student {
private:int id;std::string name;public:// 带参数的构造函数Student(int studentId, const std::string& studentName) : id(studentId), name(studentName) {// 初始化代码}
};
- 拷贝构造函数(Copy Constructor):拷贝构造函数用于创建一个对象,并将其初始化为已有对象的副本。它通常在对象传递、返回和初始化时自动调用。如果没有定义拷贝构造函数,编译器会提供默认的拷贝构造函数。
class MyString {
private:char* str;public:// 拷贝构造函数MyString(const MyString& other) {// 进行深拷贝操作}
};
- 析构函数(Destructor):析构函数在对象被销毁时自动调用,用于释放对象分配的资源(如内存、文件句柄等)。
class Resource {
private:// 资源的指针或句柄public:// 析构函数~Resource() {// 释放资源}
};
构造函数的使用例子:
int main() {// 使用默认构造函数MyClass obj1;// 使用带参数的构造函数Student student1(123, "Alice");// 使用拷贝构造函数MyString str1("Hello");MyString str2 = str1; // 调用拷贝构造函数// 对象销毁时会自动调用析构函数{Resource res; // 在作用域内创建对象} // 超出作用域,析构函数被调用,资源被释放return 0;
}
构造函数在类的实例化过程中非常重要,它确保对象的正确初始化和资源管理。可以根据需要定义不同类型的构造函数,以适应各种场景。
1.1.4 拷贝、赋值和析构
在C++中,拷贝、赋值和析构是与对象生命周期和管理资源相关的重要概念。
-
拷贝构造函数(Copy Constructor):拷贝构造函数用于创建一个对象,并将其初始化为已有对象的副本。它通常在以下情况下自动调用:
- 通过值传递函数参数时,会生成传递对象的副本。
- 在函数返回对象时,会生成函数返回值的副本。
- 通过初始化语句创建新对象。
如果没有显式定义拷贝构造函数,编译器会提供默认的拷贝构造函数,但它只会执行浅拷贝(复制指针,而不是创建新的资源)。
class MyString {
private:char* str;public:MyString(const MyString& other) {// 执行深拷贝操作}
};
- 赋值运算符重载(Copy Assignment Operator):赋值运算符(
=)用于将一个对象的值赋给另一个对象。可以通过运算符重载来自定义赋值行为。如果没有自定义赋值运算符,编译器会提供默认的成员对成员的逐一赋值。
class MyString {
private:char* str;public:// 赋值运算符重载MyString& operator=(const MyString& other) {if (this != &other) {// 执行资源释放和深拷贝}return *this;}
};
- 析构函数(Destructor):析构函数在对象被销毁时自动调用,用于释放对象分配的资源(如内存、文件句柄等)。它通常用于清理对象所拥有的资源,以防止内存泄漏或资源泄漏。
class Resource {
private:// 资源的指针或句柄public:~Resource() {// 释放资源}
};
下面是一个示例,展示了这些概念的使用:
int main() {MyString str1("Hello");MyString str2 = str1; // 调用拷贝构造函数MyString str3("World");str2 = str3; // 调用赋值运算符重载{Resource res; // 在作用域内创建对象} // 超出作用域,析构函数被调用,资源被释放return 0;
}
请注意,在使用指针或动态分配内存等情况下,确保正确实现拷贝构造函数、赋值运算符和析构函数,以避免内存泄漏和资源泄漏。
1.2 访问控制与封装
1.2.1 友元
C++中的友元(Friend)是一种机制,允许一个非成员函数或另一个类访问另一个类的私有成员。友元关系打破了类的封装性,但在某些情况下是必要的,例如在实现操作符重载、迭代器等特定功能时。
- 友元函数(Friend Function):可以在一个类中声明一个非成员函数为友元函数,从而使其能够访问该类的私有成员。这样的函数可以访问类的私有成员,但它不是类的成员函数。
class MyClass {
private:int secretValue;public:MyClass(int value) : secretValue(value) {}// 声明友元函数friend void showSecret(const MyClass& obj);
};// 友元函数的定义
void showSecret(const MyClass& obj) {std::cout << "Secret value: " << obj.secretValue << std::endl;
}int main() {MyClass obj(42);showSecret(obj); // 调用友元函数return 0;
}
- 友元类(Friend Class):可以将一个类声明为另一个类的友元类,使其能够访问该类的私有成员。友元类的成员函数可以访问另一个类的私有成员。
class FriendClass {
public:void accessPrivate(const MyClass& obj) {std::cout << "Accessing secret value from FriendClass: " << obj.secretValue << std::endl;}
};class MyClass {
private:int secretValue;// 声明友元类friend class FriendClass;public:MyClass(int value) : secretValue(value) {}
};int main() {MyClass obj(42);FriendClass fc;fc.accessPrivate(obj); // 通过友元类访问私有成员return 0;
}
尽管友元提供了访问私有成员的方式,但要慎重使用,因为它会破坏类的封装性。只在必要的情况下使用友元,并在可能的情况下使用其他技术(如访问函数、成员函数等)来实现所需的功能。
1.3 类的其他特性
1.3.1 返回*this 的成员函数
在C++中,*this是一个指向当前对象的指针,可以在类的成员函数中使用。通过返回*this,可以实现链式调用,即在一系列函数调用中使用同一个对象。这在某些情况下可以增加代码的可读性和灵活性。
下面是一个示例,展示了如何在成员函数中返回*this来实现链式调用:
#include <iostream>class Calculator {
private:double result;public:Calculator() : result(0.0) {}Calculator& add(double value) {result += value;return *this;}Calculator& subtract(double value) {result -= value;return *this;}Calculator& multiply(double value) {result *= value;return *this;}Calculator& divide(double value) {if (value != 0.0) {result /= value;}return *this;}double getResult() const {return result;}
};int main() {Calculator calc;double finalResult = calc.add(10.0).multiply(2.0).subtract(5.0).divide(3.0).getResult();std::cout << "Final Result: " << finalResult << std::endl;return 0;
}
在上面的示例中,Calculator 类具有一系列可以链式调用的成员函数(add、subtract、multiply、divide)。每个成员函数都返回 *this,使得它们可以按照链式顺序调用。最终,通过调用 getResult 函数获取计算的最终结果。
这种技术在实际编程中非常有用,特别是在创建类似于流式 API 的库或构建复杂的对象初始化过程时。但要注意,为了确保链式调用的正确性,确保每个成员函数返回 *this,并遵循良好的代码风格和可读性。
1.4 类的作用域
C++中的类具有作用域(scope),这意味着类定义的成员(成员变量、成员函数)只在特定的范围内可见和访问。以下是有关C++类作用域的详细信息:
- 成员变量的作用域:类的成员变量(属性)具有类作用域,可以在类的任何成员函数中直接访问。成员变量也可以在类的构造函数、析构函数以及其他成员函数中使用。
class MyClass {
public:int publicVar;private:int privateVar;void privateMethod() {// 在类的成员函数中可以直接访问 privateVar}
};
- 成员函数的作用域:类的成员函数(方法)同样具有类作用域,可以在类的其他成员函数中直接调用。类的成员函数可以通过类的对象进行调用。
class MyClass {
public:void publicMethod() {// 在类的成员函数中可以直接调用其他成员函数privateMethod();}private:void privateMethod() {// 在类的成员函数中可以直接调用 privateMethod}
};
- 作用域解析操作符:如果在类的作用域外部需要引用类的成员,可以使用作用域解析操作符
::。这样可以显式地指明成员所属的类,从而在类的作用域外部访问成员。
class MyClass {
public:int myVar;
};int main() {MyClass obj;obj.myVar = 42; // 通过对象访问成员// 在类的作用域外部访问成员需要使用作用域解析操作符obj::myVar = 24;return 0;
}
总之,C++类的作用域规则遵循普通的作用域规则。类的成员在类的范围内是直接可见的,而在类的外部需要使用作用域解析操作符来访问。这种作用域规则有助于保持代码的封装性和可维护性。
1.5 构造函数详解
1.5.1 构造函数初始值列表
C++中的构造函数初始值列表(Constructor Initialization List)是一种在构造函数中初始化类成员变量的有效方法。它允许你在构造函数的参数列表之后,使用冒号(:)来初始化成员变量,而不是在构造函数体内部执行赋值操作。构造函数初始值列表可以提高代码效率和性能。
以下是使用构造函数初始值列表的示例:
class MyClass {
private:int x;double y;public:// 构造函数初始值列表MyClass(int valX, double valY) : x(valX), y(valY) {// 构造函数体(如果有的话)}// 成员函数和其他定义
};
在上面的示例中,MyClass 类的构造函数使用了构造函数初始值列表,通过冒号 : 后面的初始化语句初始化成员变量 x 和 y。这样可以直接在构造函数的参数列表之后,用更高效的方式进行初始化。
构造函数初始值列表的优势包括:
- 性能优化:通过直接在构造函数初始值列表中进行初始化,避免了创建临时对象和额外的赋值操作,提高了性能和效率。
- 初始化常量成员:构造函数初始值列表允许你初始化类的常量成员,因为常量成员只能在初始化列表中初始化,而不能在构造函数体内。
- 初始化引用成员:引用成员只能通过构造函数初始值列表进行初始化,因为引用在创建后必须指向一个有效的对象。
构造函数初始值列表对于类的初始化是一种强大的工具,特别是在需要处理成员对象、常量成员和引用成员的情况下。使用构造函数初始值列表可以提高代码的效率和可读性。
1.5.2 委托构造函数
C++11引入了委托构造函数(Delegating Constructors)的概念,允许一个构造函数调用同一类的另一个构造函数来执行共同的初始化工作。这可以减少代码重复,提高可维护性和可读性。
以下是委托构造函数的示例:
class MyClass {
private:int x;double y;public:// 委托构造函数MyClass(int valX) : MyClass(valX, 0.0) {}// 主构造函数MyClass(int valX, double valY) : x(valX), y(valY) {// 初始化代码}// 成员函数和其他定义
};
在上面的示例中,MyClass 类具有一个主构造函数和一个委托构造函数。主构造函数初始化了类的成员变量 x 和 y,而委托构造函数则通过调用主构造函数来执行共同的初始化工作。这样,当调用委托构造函数时,实际上是调用了主构造函数,避免了代码重复。
使用委托构造函数的好处包括:
- 减少冗余代码:通过共享构造函数初始化逻辑,可以减少代码冗余,提高代码的可维护性。
- 易于修改:如果需要更改构造函数的初始化逻辑,只需更改一个地方即可。
- 避免错误:减少了手动拷贝构造函数初始化代码的机会,降低了出错的可能性。
需要注意的是,委托构造函数只能在构造函数的初始化列表中调用另一个构造函数。不能在构造函数体内调用其他构造函数。委托构造函数可以帮助你更好地组织代码,提高代码的可读性和可维护性。
1.5.3 默认构造函数的作用
C++中的默认构造函数是一个无参数的构造函数,它在没有显式定义构造函数时由编译器自动生成。默认构造函数的作用是执行对象的默认初始化,将对象的成员变量设置为适当的初始值。
以下是默认构造函数的一些作用和特点:
- 对象初始化:默认构造函数用于创建对象时的初始化。当你声明一个类的对象但没有显式调用构造函数时,编译器会自动调用默认构造函数,确保对象被正确初始化。
- 成员变量初始化:默认构造函数初始化对象的成员变量,将它们设置为适当的默认值。对于内置类型,成员变量通常会被初始化为零或空值。
- 派生类调用基类的默认构造函数:在派生类中,如果没有显式调用基类的构造函数,派生类的默认构造函数会自动调用基类的默认构造函数。
- 用户自定义构造函数覆盖:如果你显式定义了一个或多个构造函数,编译器不会再生成默认构造函数。这意味着你可以通过定义自己的构造函数来控制对象的初始化过程。
默认构造函数示例:
class MyClass {
private:int x;double y;public:// 默认构造函数,由编译器自动生成MyClass() : x(0), y(0.0) {}// 成员函数和其他定义
};
在上面的示例中,当创建 MyClass 类的对象时,如果没有提供参数,编译器会自动调用默认构造函数,将成员变量 x 和 y 初始化为零或空值。
总之,默认构造函数的作用是确保对象被适当地初始化,以防止未定义的行为和错误。当你需要确保对象的成员变量在创建时有默认值时,可以使用默认构造函数。
1.5.4 隐式的类类型转换
C++中的隐式类类型转换(Implicit Class Type Conversion)是一种自动进行的类型转换,它允许编译器在某些上下文中自动将一个类的对象转换为另一个类的对象,而无需显式地调用类型转换运算符或构造函数。
隐式类类型转换通常发生在以下情况下:
- 构造函数调用:当一个构造函数可以将一种类类型转换为另一种类类型时,编译器可以自动调用该构造函数。
class Celsius {
private:double temperature;public:Celsius(double temp) : temperature(temp) {}
};class Fahrenheit {
private:double temperature;public:Fahrenheit(double temp) : temperature(temp) {}// 构造函数允许从Celsius到Fahrenheit的隐式转换Fahrenheit(const Celsius& celsius) : temperature(celsius.temperature * 9.0 / 5.0 + 32.0) {}
};int main() {Celsius celsius(25.0);Fahrenheit fahrenheit = celsius; // 隐式调用 Fahrenheit 的构造函数return 0;
}
- 操作符重载:当你在类中重载操作符,例如赋值运算符或加法运算符,可以通过隐式类类型转换允许操作数之间的自动转换。
class Length {
private:double value;public:Length(double val) : value(val) {}// 加法运算符重载Length operator+(const Length& other) const {return Length(value + other.value);}
};int main() {Length length1(5.0);Length length2(3.0);Length result = length1 + length2; // 隐式调用 operator+return 0;
}
尽管隐式类类型转换可以提供方便,但它可能会导致意外的行为和歧义。因此,应该谨慎使用隐式转换,确保其不会引起不明确或混淆的情况。为了增强代码的清晰性和可读性,可以使用explicit关键字来禁止隐式类类型转换,只允许显式调用构造函数进行类型转换。
1.5.5 聚合类
C++中的聚合类是一种特殊的类类型,具有特定的初始化要求和属性。一个聚合类是一个满足以下条件的类:
- 所有成员变量都是公有的。
- 没有定义任何构造函数,析构函数和基类。
- 没有类内初始化(如
int x = 0;)。 - 没有使用
virtual、private、protected等访问修饰符。
聚合类的一个重要特性是它可以使用花括号初始化列表进行初始化,这在C++11之后变得更加方便。
以下是一个聚合类的示例:
struct Point {double x;double y;
};int main() {Point p = {2.5, 4.0}; // 使用花括号初始化列表return 0;
}
在上面的示例中,Point 是一个聚合类,它具有两个公有成员变量 x 和 y。我们可以使用花括号初始化列表直接初始化 Point 对象。
需要注意的是,C++20引入了一种新的聚合类定义形式,允许使用类内初始化,并且可以具有私有或受保护的成员变量,同时仍然保持聚合类的性质。这样的类被称为带有成员初始化的聚合类。
struct Point {double x = 0.0;double y = 0.0;
};int main() {Point p; // 成员变量将自动初始化为默认值return 0;
}
无论使用旧的聚合类定义还是新的带有成员初始化的聚合类定义,聚合类都具有一些特殊的初始化和属性,可以用于简单的数据容器或数据传输对象。
1.5.6 字面值常量类
C++17引入了一种新的特性,即字面值类型(Literal Type)和字面值常量类(Literal Type Classes)。字面值类型是一种在编译时具有确定值的类型,字面值常量类则是满足特定条件的类,其对象可以在编译时求值并用于常量表达式。
要使一个类成为字面值常量类,它必须满足以下要求:
- 所有非静态成员变量必须是字面值类型。
- 类必须至少具有一个
constexpr构造函数。 - 类必须具有一个析构函数,可以是隐式生成的默认析构函数。
- 所有基类必须是字面值类型。
- 如果类具有虚函数或虚基类,它不是字面值常量类。
以下是一个简单的字面值常量类的示例:
class Circle {
private:double radius;public:constexpr Circle(double r) : radius(r) {}constexpr double getArea() const {return 3.14159 * radius * radius;}
};int main() {constexpr Circle c(2.0);static_assert(c.getArea() == 12.56636, "Invalid area");return 0;
}
在上面的示例中,Circle 类是一个字面值常量类,它满足字面值常量类的要求。constexpr构造函数允许在编译时初始化对象,并且getArea()函数也被声明为constexpr,使得可以在编译时求值。我们在main()函数中使用了static_assert来验证计算的面积是否正确。
字面值常量类的主要用途是在编译时进行计算和优化,以及在常量表达式中使用。它们可以帮助提高程序的性能和效率,特别是在需要进行编译时计算的场景下。
1.6 类的静态成员
C++中的静态成员(Static Members)是类的成员,它们与类的实例对象无关,而与整个类相关联。静态成员在类的所有实例之间共享,可以用于存储类级别的信息或在不创建对象的情况下执行操作。静态成员包括静态成员变量和静态成员函数。
以下是有关C++静态成员的详细信息:
- 静态成员变量:静态成员变量是类的所有实例共享的变量。它们存储在类本身而不是实例对象中,并且在所有对象之间保持相同的值。静态成员变量在类声明内部声明,并在类的外部进行定义和初始化。
class MyClass {
public:static int count; // 静态成员变量声明MyClass() {count++;}
};int MyClass::count = 0; // 静态成员变量定义和初始化int main() {MyClass obj1;MyClass obj2;std::cout << "Count: " << MyClass::count << std::endl; // 访问静态成员变量return 0;
}
- 静态成员函数:静态成员函数是属于类本身而不是实例对象的函数。它们可以通过类名或对象来调用。静态成员函数不能访问非静态成员变量,也不能使用
this指针。
class MathUtility {
public:static int square(int num) {return num * num;}
};int main() {int result = MathUtility::square(5); // 调用静态成员函数std::cout << "Square: " << result << std::endl;return 0;
}
静态成员的主要特点包括:
- 静态成员在编译时分配内存,而不是在运行时。
- 静态成员可以通过类名访问,也可以通过对象访问(不推荐)。
- 静态成员在程序启动时初始化,程序结束时销毁。
静态成员在许多场景下都很有用,例如记录对象的数量、实现单例模式、提供类级别的功能等。但要谨慎使用,确保在适当的情况下使用静态成员。
2 IO库
2.1 IO类
在C++中,I/O (输入/输出) 对象有一些特殊的行为和性质,包括无法直接拷贝或赋值、条件状态以及管理输出缓冲。
-
I/O对象无拷贝或赋值:
C++标准库中的输入流(istream)和输出流(ostream)对象是被禁止拷贝和赋值的。这是因为拷贝和赋值操作可能会引起状态混乱,比如在多次写入或读取的情况下,缓冲区的状态可能不一致。为了避免这些问题,I/O对象通常被设计成无法拷贝或赋值。#include <iostream>int main() {std::cout << "Hello, World!" << std::endl;// 错误!不允许拷贝或赋值// std::ostream copy = std::cout;return 0; } -
条件状态:
I/O对象具有条件状态(State)来表示它们的状态,比如文件是否打开、是否到达文件末尾等等。你可以通过特定的成员函数(如good()、fail()、eof()、bad()等)来检查这些条件状态,以便在程序中进行适当的错误处理和决策。#include <iostream>int main() {std::ifstream file("example.txt");if (!file) {std::cerr << "File not found." << std::endl;return 1;}int value;while (file >> value) {// 读取整数并处理}if (file.eof()) {std::cout << "End of file reached." << std::endl;}if (file.fail()) {std::cerr << "Input failed." << std::endl;}return 0; } -
管理输出缓冲:
C++标准库通过缓冲来提高I/O操作的效率。输出流(ostream)通常将数据写入到缓冲区中,而不是立即写入设备。可以使用std::flush来强制刷新缓冲区,或者在需要时缓冲会自动刷新(例如在缓冲区填满时或在程序结束时)。#include <iostream>int main() {std::cout << "Hello, ";std::cout << "World!" << std::endl; // 自动刷新缓冲std::cout << "This will be flushed immediately: " << std::flush;return 0; }
2.2 文件输入输出
在C++中,可以使用文件流对象(File Stream Objects)来进行文件的输入和输出操作。文件流对象是C++标准库提供的用于文件 I/O 的类,它们可以方便地打开、读取和写入文件。你可以使用<fstream>头文件来包含文件流相关的类和函数。
以下是一些常用的文件流类和文件模式:
- ifstream(输入文件流):用于从文件中读取数据。
#include <iostream>
#include <fstream>int main() {std::ifstream inputFile("example.txt"); // 打开文件if (!inputFile) {std::cerr << "File not found." << std::endl;return 1;}int value;while (inputFile >> value) {std::cout << value << " ";}inputFile.close(); // 关闭文件return 0;
}
- ofstream(输出文件流):用于向文件中写入数据。
#include <iostream>
#include <fstream>int main() {std::ofstream outputFile("output.txt"); // 打开文件if (!outputFile) {std::cerr << "Failed to open file." << std::endl;return 1;}outputFile << "Hello, World!" << std::endl;outputFile << "This is a line of text." << std::endl;outputFile.close(); // 关闭文件return 0;
}
- fstream(文件流):既可以读取也可以写入文件。
#include <iostream>
#include <fstream>int main() {std::fstream file("data.txt", std::ios::in | std::ios::out); // 读写文件if (!file) {std::cerr << "Failed to open file." << std::endl;return 1;}int value;while (file >> value) {value *= 2; // 修改数据file.seekg(-sizeof(int), std::ios::cur); // 移动读取位置file << value; // 写入修改后的数据}file.close(); // 关闭文件return 0;
}
- 文件模式:文件流对象的构造函数可以接受一个参数,指定文件的打开模式。常用的文件模式包括:
std::ios::in:打开文件用于读取。std::ios::out:打开文件用于写入。std::ios::app:在文件末尾追加写入。std::ios::binary:以二进制模式打开文件。
你可以将这些模式组合起来使用,例如std::ios::in | std::ios::out用于读写文件。
在使用文件流对象时,要确保在操作结束后关闭文件,以释放资源。如果文件操作可能出现错误,应该检查文件流的状态,以便进行错误处理。
总之,文件流对象是进行文件输入和输出操作的重要工具,在C++中使用它们可以方便地读取和写入文件数据。
2.3 string 流
在C++中,istringstream和ostringstream是用于处理字符串流的类,它们分别用于将字符串转换为输入流和将数据输出到字符串流。这些类位于<sstream>头文件中。
以下是关于如何使用istringstream和ostringstream的示例:
- istringstream(Input String Stream):用于从字符串中读取数据,模拟从输入流读取数据的过程。
#include <iostream>
#include <sstream>int main() {std::string inputString = "123 45.67 hello";std::istringstream iss(inputString);int intValue;double doubleValue;std::string stringValue;iss >> intValue >> doubleValue >> stringValue;std::cout << "Int: " << intValue << std::endl;std::cout << "Double: " << doubleValue << std::endl;std::cout << "String: " << stringValue << std::endl;return 0;
}
- ostringstream(Output String Stream):用于将数据输出到字符串流中,模拟将数据输出到输出流的过程。
#include <iostream>
#include <sstream>int main() {int intValue = 42;double doubleValue = 3.14;std::string stringValue = "Hello, World!";std::ostringstream oss;oss << "Int: " << intValue << ", ";oss << "Double: " << doubleValue << ", ";oss << "String: " << stringValue;std::string outputString = oss.str();std::cout << outputString << std::endl;return 0;
}
istringstream和ostringstream类的使用方式类似于标准输入输出流,但是它们是基于字符串的流,允许你在内存中处理文本数据,而不需要实际的文件或设备。这些类对于数据格式化、解析和生成字符串都非常有用。
要注意的是,istringstream和ostringstream都是基于字符串的流,因此在使用过程中要确保操作字符串的格式和数据类型的匹配,以避免出现意外的错误。
3 顺序容器
3.1 顺序容器简介
C++标准库提供了多种顺序容器(Sequential Containers),用于存储和管理一组有序的元素。这些容器具有不同的特性和适用场景,可以根据需求选择合适的容器。以下是一些常见的顺序容器:
- vector:动态数组,支持快速随机访问,适用于需要高效随机访问的情况。
#include <vector>std::vector<int> myVector = {1, 2, 3, 4, 5};
- list:双向链表,支持快速插入和删除操作,适用于频繁的插入和删除操作。
#include <list>std::list<int> myList = {10, 20, 30, 40, 50};
- deque:双端队列,支持在两端进行插入和删除操作,适用于需要在前后两端频繁操作的情况。
#include <deque>std::deque<int> myDeque = {100, 200, 300, 400, 500};
- array:固定大小的数组,支持快速随机访问,适用于元素数量已知且不会变化的情况。
#include <array>std::array<int, 5> myArray = {1, 2, 3, 4, 5};
- forward_list:单向链表,与
list类似但只支持单向遍历,适用于需要频繁插入和删除且只需单向遍历的情况。
#include <forward_list>std::forward_list<int> myForwardList = {1000, 2000, 3000};
- stack:栈,后进先出(LIFO)的数据结构,支持压栈(push)和出栈(pop)操作。
#include <stack>std::stack<int> myStack;
myStack.push(10);
myStack.pop();
- queue:队列,先进先出(FIFO)的数据结构,支持入队(push)和出队(pop)操作。
#include <queue>std::queue<int> myQueue;
myQueue.push(20);
myQueue.pop();
- priority_queue:优先队列,按照优先级进行插入和删除操作,适用于需要按照特定优先级处理元素的情况。
#include <queue>std::priority_queue<int> myPriorityQueue;
myPriorityQueue.push(30);
myPriorityQueue.pop();
这些顺序容器提供了不同的性能和特性,你可以根据需求选择合适的容器来满足程序的要求。同时,标准库还提供了丰富的操作和算法,可以方便地对这些容器进行遍历、查找、排序等操作。
3.2 容器库
- 迭代器(Iterators):迭代器是一种用于遍历容器中元素的对象,它允许你访问容器的元素并进行操作。不同类型的容器可以有不同类型的迭代器,如begin和end迭代器。
- 容器类型成员:C++容器库中有多种容器类型,如vector、list、map等。每种容器都有自己的特点和适用场景。
- begin 和 end 成员:
begin()函数返回指向容器中第一个元素的迭代器,end()函数返回指向容器中最后一个元素之后位置的迭代器。它们通常用于遍历容器的元素。 - 容器定义和初始化:可以通过定义容器对象来创建容器,并使用初始化列表或其他容器来初始化新容器。
#include <vector>
#include <list>int main() {std::vector<int> myVector = {1, 2, 3, 4, 5};std::list<double> myList(myVector.begin(), myVector.end());return 0;
}
- 赋值和 swap:容器可以使用
=运算符进行赋值,或者使用swap()函数交换两个容器的内容。
#include <vector>int main() {std::vector<int> vec1 = {1, 2, 3};std::vector<int> vec2 = {4, 5, 6};vec2 = vec1; // 赋值操作vec1.swap(vec2); // 交换内容return 0;
}
- 容器大小操作:可以使用
size()函数获取容器中元素的数量,以及empty()函数检查容器是否为空。
#include <list>
#include <iostream>int main() {std::list<int> myList = {1, 2, 3, 4, 5};std::cout << "Size: " << myList.size() << std::endl;std::cout << "Is empty: " << (myList.empty() ? "Yes" : "No") << std::endl;return 0;
}
- 关系运算符:C++容器支持关系运算符(如
==、!=、<、>等),用于比较两个容器的内容。
#include <vector>
#include <iostream>int main() {std::vector<int> vec1 = {1, 2, 3};std::vector<int> vec2 = {1, 2, 3};if (vec1 == vec2) {std::cout << "Vectors are equal." << std::endl;}return 0;
}
通过理解和使用上面概念,可以更好地利用C++容器库来管理和操作数据。容器是C++中非常重要和常用的工具,用于处理各种不同的数据结构和算法问题。
3.3 顺序容器操作
C++顺序容器的各种操作如下:
- 向顺序容器添加元素:
#include <vector>
#include <list>int main() {std::vector<int> vec;vec.push_back(10); // 向vector尾部添加元素std::list<double> myList;myList.push_front(3.14); // 向list头部添加元素return 0;
}
- 访问元素:
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};int value = vec[2]; // 通过下标访问元素int first = vec.front(); // 访问首元素int last = vec.back(); // 访问尾元素return 0;
}
- 删除元素:
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};vec.pop_back(); // 删除尾部元素vec.erase(vec.begin() + 2); // 删除指定位置的元素return 0;
}
- 特殊的forward_list操作:
#include <forward_list>int main() {std::forward_list<int> myList = {1, 2, 3, 4, 5};myList.push_front(0); // 在头部添加元素myList.insert_after(myList.begin(), 6); // 在指定位置之后插入元素myList.remove(3); // 移除特定值的元素return 0;
}
- 改变容器大小:
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};vec.resize(3); // 缩小容器大小vec.resize(7, 0); // 扩大容器大小并用0填充return 0;
}
- 容器操作可能使迭代器失效:在对容器进行添加、删除操作时,会导致迭代器失效,不能再继续使用。需要小心处理迭代器的有效性。
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};std::vector<int>::iterator it = vec.begin();vec.erase(it); // 删除元素会使迭代器失效return 0;
}
3.4 vector对象是如何增长的
在C++中,std::vector 是一个动态数组,它在内部管理着一个连续的存储空间来存放元素。当你向 std::vector 添加元素时,它会动态地管理存储空间的增长。
std::vector 的增长策略通常是指数增长(exponential growth)。这意味着当 std::vector 需要增加存储空间时,它会分配比当前容量更大的一块新存储空间,而不是每次添加元素都重新分配存储空间。
具体来说,以下是 std::vector 增长的一般过程:
- 当你首次创建一个空的
std::vector对象时,它通常会分配一个初始容量的存储空间,这个容量可能是 0 或其他小值,具体取决于实现。 - 当你开始向
std::vector添加元素时,它会逐渐填充这些元素到已分配的存储空间中。 - 当
std::vector的元素数量达到当前容量时,它需要分配更多的存储空间来容纳更多的元素。为了避免频繁的内存分配和复制,std::vector会分配一个新的容量,通常是当前容量的两倍(不同实现可能有所不同)。 std::vector会将现有的元素从旧的存储空间复制到新的存储空间,并释放旧的存储空间。- 这个过程会保持
std::vector的内存分配和复制次数相对较少,从而提高性能。
这种增长策略可以确保 std::vector 在添加元素时能够高效地管理内存。但需要注意,尽管 std::vector 的增长策略很好地平衡了内存分配和复制的开销,但在大量添加元素的情况下,仍然可能会有一些性能开销。
3.5 容器适配器
C++标准库中提供了容器适配器(Container Adapters)作为特殊类型的容器,它们基于已有的容器类型提供了不同的接口和功能。容器适配器允许你使用不同的数据结构来满足不同的需求,而无需直接操作底层容器。标准库中提供了三种常见的容器适配器:stack、queue 和 priority_queue。
下面是每种容器适配器的简要介绍:
- stack(栈):
stack是一个基于 LIFO(Last-In-First-Out)策略的容器适配器,它封装了底层容器,提供了push、pop、top等操作。
#include <stack>int main() {std::stack<int> myStack;myStack.push(10);myStack.push(20);myStack.push(30);while (!myStack.empty()) {std::cout << myStack.top() << " ";myStack.pop();}return 0;
}
- queue(队列):
queue是一个基于 FIFO(First-In-First-Out)策略的容器适配器,封装了底层容器,提供了push、pop、front、back等操作。
#include <queue>int main() {std::queue<int> myQueue;myQueue.push(10);myQueue.push(20);myQueue.push(30);while (!myQueue.empty()) {std::cout << myQueue.front() << " ";myQueue.pop();}return 0;
}
- priority_queue(优先队列):
priority_queue是一个基于优先级的容器适配器,封装了底层容器,提供了按照一定的优先级排序的push、pop、top操作。
#include <queue>int main() {std::priority_queue<int> myPriorityQueue;myPriorityQueue.push(30);myPriorityQueue.push(10);myPriorityQueue.push(20);while (!myPriorityQueue.empty()) {std::cout << myPriorityQueue.top() << " ";myPriorityQueue.pop();}return 0;
}
这些容器适配器提供了不同的数据结构,适用于不同的问题和场景。通过使用容器适配器,可以轻松地使用标准库提供的功能来处理栈、队列和优先队列相关的操作。
4 泛型算法
4.1 泛型算法简介
C++标准库提供了丰富的泛型算法,用于操作不同类型的容器和序列,无需关心容器的具体类型。这些算法可以分为几个类别,包括只读算法、写容器元素的算法以及重排容器元素的算法。以下是这些算法的简要介绍和示例用法:
只读算法:
std::for_each:对序列中的每个元素应用一个函数。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};std::for_each(nums.begin(), nums.end(), [](int num) {std::cout << num << " ";});return 0;
}
std::count:计算序列中等于给定值的元素个数。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums = {1, 2, 2, 3, 2, 4};int count = std::count(nums.begin(), nums.end(), 2);std::cout << "Count: " << count << std::endl;return 0;
}
写容器元素的算法:
std::fill:将指定的值赋给一个范围内的所有元素。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums(5);std::fill(nums.begin(), nums.end(), 42);return 0;
}
std::copy:从一个范围复制元素到另一个范围。
#include <algorithm>
#include <vector>int main() {std::vector<int> source = {1, 2, 3, 4, 5};std::vector<int> target(5);std::copy(source.begin(), source.end(), target.begin());return 0;
}
重排容器元素的算法:
std::sort:对序列中的元素进行排序。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums = {3, 1, 4, 1, 5, 9, 2, 6, 5};std::sort(nums.begin(), nums.end());return 0;
}
std::reverse:颠倒序列中的元素顺序。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};std::reverse(nums.begin(), nums.end());return 0;
}
以上这些只是泛型算法中的一些例子。C++标准库中还有许多其他的泛型算法,用于执行各种操作,例如查找、转换、累积等。这些算法为处理不同类型的容器提供了方便、高效且易于理解的方式。
4.2 定制操作
在C++中,可以通过向泛型算法传递函数、使用 lambda 表达式、进行捕获和返回以及参数绑定等方式来定制算法的操作。这些技术可以让你更灵活地自定义算法的行为,适应不同的需求。
向算法传递函数:
可以通过函数指针、函数对象或者 C++11 之后的 lambda 表达式将自定义的函数传递给泛型算法,从而在算法内部进行操作。
#include <algorithm>
#include <vector>bool isEven(int num) {return num % 2 == 0;
}int main() {std::vector<int> nums = {1, 2, 3, 4, 5};int countEven = std::count_if(nums.begin(), nums.end(), isEven);return 0;
}
lambda 表达式:
Lambda 表达式是 C++11 引入的一种匿名函数语法,可以用于内联地定义函数,非常适合向泛型算法传递简单的操作。
#include <algorithm>
#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};int countEven = std::count_if(nums.begin(), nums.end(), [](int num) {return num % 2 == 0;});return 0;
}
lambda 捕获和返回:
Lambda 表达式可以通过捕获列表捕获外部变量,允许你在 lambda 内部使用这些变量。还可以使用尾随返回类型来指定 lambda 表达式的返回类型。
#include <algorithm>
#include <vector>int main() {int threshold = 3;std::vector<int> nums = {1, 2, 3, 4, 5};int countAboveThreshold = std::count_if(nums.begin(), nums.end(), [threshold](int num) -> bool {return num > threshold;});return 0;
}
参数绑定:
通过 C++11 引入的标准库 std::bind 函数,可以绑定函数的参数,以便在调用时传递少于所需参数数量的参数。
#include <algorithm>
#include <vector>
#include <functional>bool checkThreshold(int num, int threshold) {return num > threshold;
}int main() {int threshold = 3;std::vector<int> nums = {1, 2, 3, 4, 5};int countAboveThreshold = std::count_if(nums.begin(), nums.end(), std::bind(checkThreshold, std::placeholders::_1, threshold));return 0;
}
4.3 迭代器
C++标准库中的泛型算法可以与各种类型的迭代器一起使用,以操作不同类型的容器和序列。以下是一些常见的迭代器类型以及与泛型算法的结合使用示例:
插入迭代器:
插入迭代器允许在容器中插入元素,包括 back_inserter、front_inserter 和 inserter。这些迭代器通常与泛型算法一起使用,用于向容器中添加元素。
#include <algorithm>
#include <vector>
#include <list>
#include <iterator>int main() {std::vector<int> source = {1, 2, 3, 4, 5};std::list<int> target;std::copy(source.begin(), source.end(), std::back_inserter(target));return 0;
}
iostream 迭代器:
iostream 迭代器允许你将流中的数据当作迭代器来处理,用于与标准输入输出流(cin、cout、cerr 等)交互。
#include <iostream>
#include <algorithm>
#include <iterator>int main() {std::istream_iterator<int> input_begin(std::cin);std::istream_iterator<int> input_end;std::ostream_iterator<int> output(std::cout, " ");std::copy(input_begin, input_end, output);return 0;
}
反向迭代器:
反向迭代器允许你从容器的末尾向前遍历容器中的元素。
#include <algorithm>
#include <vector>
#include <iostream>
#include <iterator>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};std::vector<int>::reverse_iterator rit;for (rit = nums.rbegin(); rit != nums.rend(); ++rit) {std::cout << *rit << " ";}return 0;
}
这些迭代器类型可以与泛型算法结合使用,用于实现不同类型的操作,如数据复制、插入、遍历等。
如果需要转载,请加上本文链接:https://blog.csdn.net/a13027629517/article/details/132394932?spm=1001.2014.3001.5501
相关文章:
C++快速回顾(二)
前言 在Android音视频开发中,网上知识点过于零碎,自学起来难度非常大,不过音视频大牛Jhuster提出了《Android 音视频从入门到提高 - 任务列表》,结合我自己的工作学习经历,我准备写一个音视频系列blog。C/C是音视频必…...

【LVS】1、LVS负载均衡群集
1.群集的含义: Cluster、群集、集群 由多台主机构成并作为一个整体,只提供一个访问入口(域名与IP地址);可伸缩 2.集群使用的场景: 高并发 3.企业群集的分类: 根据群集所针对的目标差异&a…...

el-tree 懒加载树
el-tree 懒加载树 添加自定义图标指定叶子节点懒加载 <template><div><el-treeclass"filter-tree":data"treeData":props"defaultProps"ref"tree"lazy:load"loadTree":expand-on-click-node"true"…...

到江西赣州ibm维修服务器之旅-联想X3850 x6黄灯故障
2023年08月15日,一位江西赣州工厂客户通过朋友介绍与冠峰售前工程师取得联系,双方对产品故障前后原因沟通的大致情况如下: 服务器型号:Lenovo system x3850 x6 为用户公司erp仓库服务器 服务器故障:正常使用过程中业…...
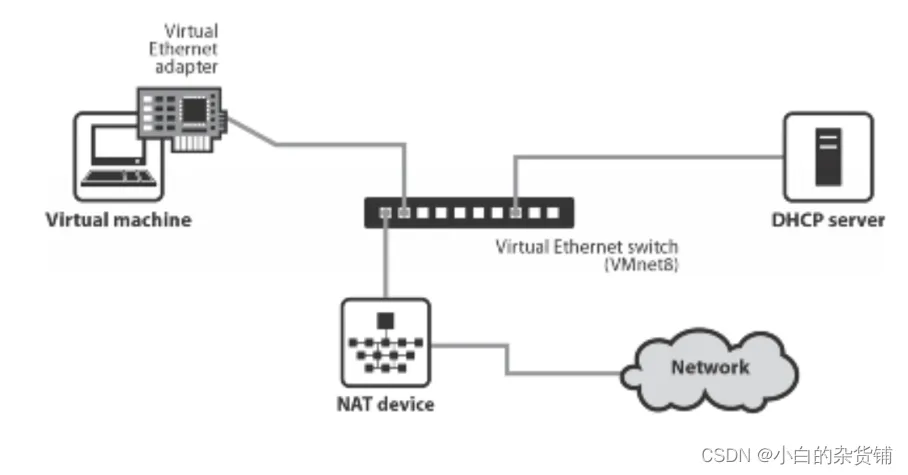
VMware 虚拟机三种网络模式详解
文章目录 前言桥接模式(Bridged)桥接模式特点: 仅主机模式 (Host-only)仅主机模式 (Host-only)特点: NAT网络地址转换模式(NAT)网络地址转换模式(NAT 模式)特点: 前言 很多同学在初次接触虚拟机的时候对 VMware 产品的三种网络模式不是很理解,本文就 VMware 的三种网络模式进行…...

ASP.NET指定变量数据类型,速度提高了100倍
ASP.NET指定变量数据类型,速度提高了100倍由自动编程人工智能 发表在专区 10亿次求余数为0的计算: ASP运行速度130秒左右 ASP.NET Dim i, c, max 如果不指定数据类型,运行要120秒左右 Dim i, c, max As Integer 指定数据类型,运…...

PyArmor 一键加密
使用: pyarmor obfuscate main.py 参考:Python代码加密方案_python加密代码_wgr_1009的博客-CSDN博客 一 简介 PyArmor是用于保护Python代码的工具,它可以将Python脚本编译成加密的字节码,以增加代码的保护性。它的主要目的是防…...

redis--持久化
redis持久化 在 Redis 中,持久化是一种将数据从内存写入到磁盘的机制,以便在服务器重启或崩溃时能够恢复数据。Redis 提供了两种主要的持久化方式:RDB(Redis Database Snapshot)和AOF(Append-Only File&am…...

管理外部表
官方文档地址:Managing Tables 关于外部表 Oracle 数据库允许您对外部表中的数据进行只读访问。外部表定义为不驻留在数据库中的表,通过向数据库提供描述外部表的元数据,数据库能够公开外部表中的数据,就好像它是驻留在常规数据…...

数字图像处理-AWB跳变
1、自动白平衡(AWB)算法是相机中常用的图像处理技术,它能够自动调整图像中的白平衡,使得图像中的颜色更加真实、自然。然而,在实际应用中,AWB算法也存在着一些问题,例如AWB跳变(Whit…...

DNNGP、DeepGS 和 DLGWAS模型构成对比
一、DNNGP DNNGP 是基于深度卷积神经网络,这个结构包括一个输入层,三个卷积层,一个批标准化层,两个dropout层,一个平坦化层,一个 dense层。 dropout层:在神经网络中,dropout层是一个非常有效的正…...

postgresSQL 配置文件设置
postgres.conf 是 PostgreSQL 数据库的主要配置文件,其中包含了许多关于数据库行为的设置。以下是一些常见的配置项: listen_addresses: 这个参数定义了 PostgreSQL 服务监听的网络地址。默认值是 ‘localhost’,这意味着只有本机的客户端才能…...
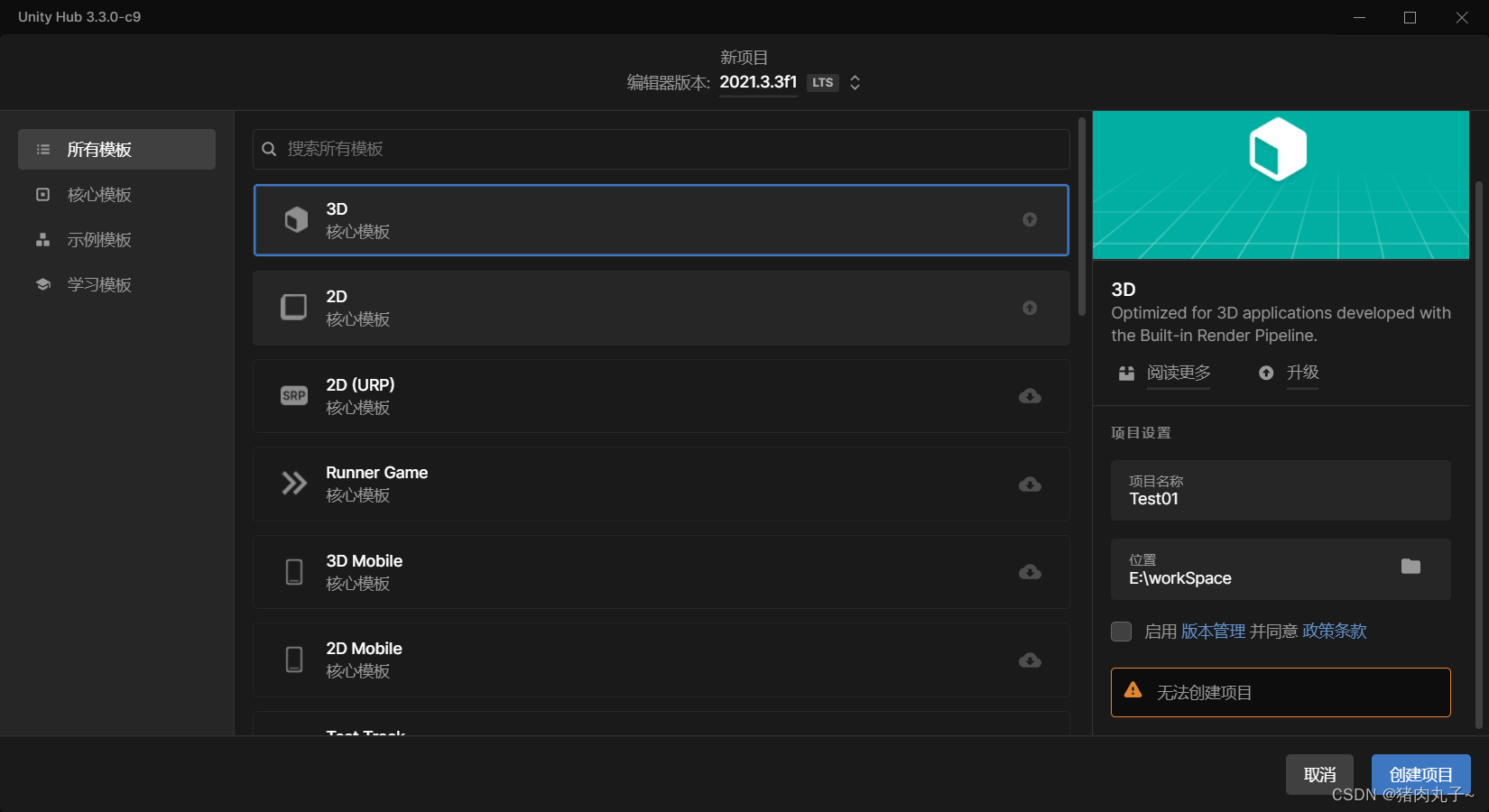
【bug】Unity无法创建项目
bug UnityHub无法创建项目 UnityHub无法创建项目 出现的问题:在创建新项目时弹出来一个 无法创建项目 尝试的方法: 刷新许可证 ❌没用退出账号重新登陆 ❌没用重启电脑 ❌没用 最后发现是什么问题呢? 2021.3.3这个版本我之前在资源管理器中…...

跨境外贸业务,选择动态IP还是静态IP?
在跨境业务中,代理IP是一个关键工具。它们提供了匿名的盾牌,有助于克服网络服务器针对数据提取设置的限制。无论你是需要经营管理跨境电商店铺、社交平台广告投放,还是独立站SEO优化,代理IP都可以让你的业务程度更加丝滑ÿ…...

Hlang社区-社区导航栏实现
文章目录 前言项目结构导航实现创作中心移动小球消息提示完整代码前言 okey,这里的话是我们社区导航栏的实现: 废话不多说,看看效果: 我甚至为此用New Bing生成了一个Logo。 项目结构 废话不多说,先来看到我们的项目结构: 在这里导航栏是一个组件。 在App.vue里面直…...
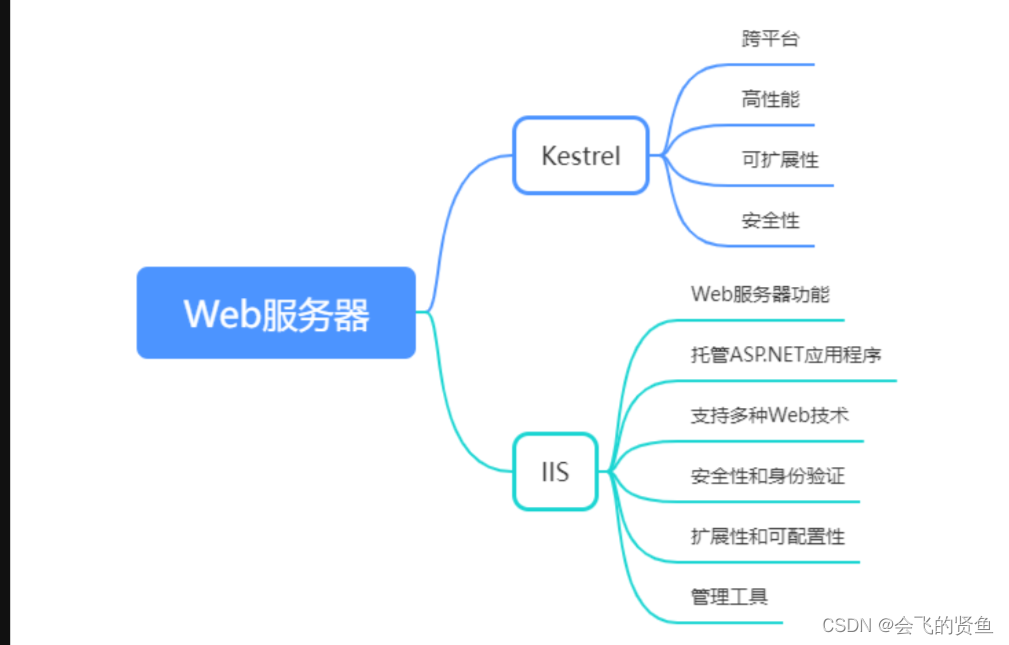
Kestrel和ISS服务器下的配置
一、Kestrel服务器 Kestrel是ASP.NET Core框架中的一个跨平台的Web服务器。它是ASP.NET Core应用程序默认的HTTP服务器,并且可作为独立的Web服务器来托管ASP.NET Core应用程序。 Kestrel具有以下特点和功能 1、跨平台 Kestrel是完全跨平台的,可以在Wind…...

uniapp选择只选择月份demo效果(整理)
<template><view style"margin-top: 200rpx;"><!-- mode"multiSelector" 多列选择器 --><view><picker :range"years" :value"echoVal" change"yearChange" mode"multiSelector">{…...

微信ipad协议8.0.40 加好友功能
友情链接 geweapi.com 点击即可访问! 好友请求验证 小提示: v_3 v_4 可以参考 搜索接口 请求URL: http://域名地址/api/contacts/verifyuser 请求方式: POST 请求头: Content-Type:application/js…...
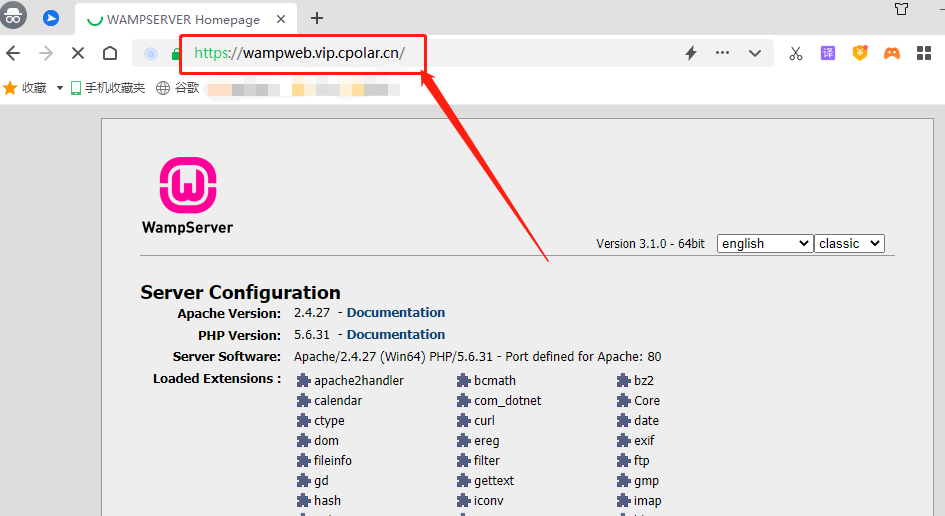
如何通过本地搭建wamp服务器并实现无公网IP远程访问
文章目录 前言1.Wamp服务器搭建1.1 Wamp下载和安装1.2 Wamp网页测试 2. Cpolar内网穿透的安装和注册2.1 本地网页发布2.2 Cpolar云端设置2.3 Cpolar本地设置 3. 公网访问测试4. 结语 前言 软件技术的发展日新月异,各种能方便我们生活、工作和娱乐的新软件层出不穷&…...
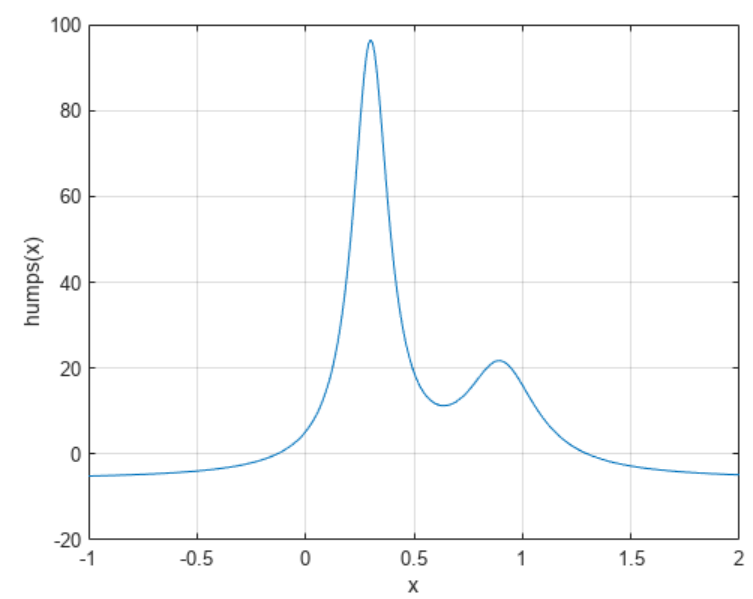
matlab使用教程(19)—曲线拟合与一元方程求根
1.多项式曲线拟合 此示例说明如何使用 polyfit 函数将多项式曲线与一组数据点拟合。您可以按照以下语法,使用 polyfit 求出以最小二乘方式与一组数据拟合的多项式的系数 p polyfit(x,y,n), 其中: • x 和 y 是包含数据点的 x 和 y 坐标的向量 …...

图像修复效率提升:设计师与开发者必备的7个开源AI模型应用技巧
图像修复效率提升:设计师与开发者必备的7个开源AI模型应用技巧 【免费下载链接】ComfyUI-BrushNet ComfyUI BrushNet nodes 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-BrushNet 在数字创作与内容修复领域,如何快速高效地消除图像瑕疵…...

Notepad2终极指南:轻量级文本编辑器的完整使用教程
Notepad2终极指南:轻量级文本编辑器的完整使用教程 【免费下载链接】notepad2 Notepad2-zufuliu is a light-weight Scintilla based text editor for Windows with syntax highlighting, code folding, auto-completion and API list for many programming languag…...

Retinaface+CurricularFace在网络安全领域的创新应用
RetinafaceCurricularFace在网络安全领域的创新应用 1. 引言 想象一下这样的场景:一家金融机构的服务器机房,只有授权人员才能进入;一个远程办公系统,确保登录者确实是员工本人;一个高安全性的数据平台,每…...

解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南
解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南 【免费下载链接】openkore A free/open source client and automation tool for Ragnarok Online 项目地址: https://gitcode.com/gh_mirrors/op/openkore 在MMORPG游戏领域,重复刷怪、繁琐…...

告别Windows AI困扰:RemoveWindowsAI工具全方位解决方案
告别Windows AI困扰:RemoveWindowsAI工具全方位解决方案 【免费下载链接】RemoveWindowsAI Force Remove Copilot and Recall in Windows 项目地址: https://gitcode.com/GitHub_Trending/re/RemoveWindowsAI 在数字时代的隐私保卫战中,Windows系…...

Codesys电子凸轮Cam表两种设置方法对比:可视化拖拽 vs 程序动态配置
Codesys电子凸轮Cam表设置方法深度对比:可视化拖拽与程序动态配置实战解析 在工业自动化领域,电子凸轮技术正逐步取代传统机械凸轮,成为运动控制系统的核心组件。作为Codesys平台下的重要功能,Cam表的设置方法直接关系到运动轨迹…...

3个变革性步骤:用163MusicLyrics彻底解决歌词获取难题
3个变革性步骤:用163MusicLyrics彻底解决歌词获取难题 【免费下载链接】163MusicLyrics Windows 云音乐歌词获取【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 在数字化音乐时代,歌词已不再是简单的文字附…...

告别电台收听难题:foobox-cn网络电台收听方案
告别电台收听难题:foobox-cn网络电台收听方案 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn foobox-cn作为foobar2000的DUI皮肤(桌面用户界面定制方案)࿰…...

龙虾为啥越养越贵,越用越蠢?极客老王揭秘Agent落地真相
进入2026年3月,科技圈的舆论风向标发生了一次剧烈偏移。曾经被誉为开启“AI代驾”时代的超级智能体OpenClaw(俗称“龙虾”),在经历了一年的野蛮生长后,正陷入一场空前的信任危机。根据最新的行业调研数据显示ÿ…...

3大颠覆:Umi-OCR如何重新定义离线文字识别体验?
3大颠覆:Umi-OCR如何重新定义离线文字识别体验? 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com…...