机器学习——随机森林【手动代码】
随机森林这个内容,是目前来说。。。最最最简单,最好理解,应该也是最好实现的了!!!
先挖坑,慢慢填
随机森林,这个名字取得,果然深得该算法的核心精髓,既随机,又森林!
哇哦,以后如果要给阿猫阿狗取名,或是生个小孩儿取名,也最好是能参考随机森林的精髓
从名字来拆解随机森林的算法精髓。
首先是随机,随机地抽样+随机地选特征
其次是森林,为什么是森林呢?
妙了,因为算法的基本单元是一颗决策树
随机森林,其实就是由多个决策树进行预测分类,每棵决策树都有一个预测分类结果,那么采取少数服从多数的原则,
也就是,如果有A\B\C三个类别,绝大多数决策预测是A类,少部分决策树预测是B\C类,则最终判定为A类
之前已经做过决策树的设计,现在只需在决策树的基础上,进行些微的代码修改
首先,决策树作为一个类,生成每个决策树,就生成一个对象
每个决策树对象,都有各自随机抽取的数据量(样本)、预测结果
循环一定次数:建立多少棵树,就循环多少次随机获取一定数量的特征属性随机获取一定数量的样本数据创建一个决策树对象构建该对象的决策树应用该决策树对象,预测整个数据集分类结果
汇总所有决策树对象的预测结果,投票表决
import math
import numpy as np
import pandas as pd
import random
# 获取所需数据
datas = pd.read_excel('./datas1.xlsx')
important_features = ['推荐类型','推荐分值', '回复速度']
datas_1 = datas[important_features]
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
Y_feature = "推荐类型"# 构建一个树节点
class Node_1():def __init__(self,value):self.value = valueself.select_feat = Noneself.sons = {}
# 根据节点,构建一个树
class Tree():def __init__(self,datas_arg):self.root = Noneself.datas = datas_argself.Y_predict = []self.X = datas_arg.drop('推荐类型', axis=1)def get_value_1(self,datas_arg,node_arg=None):# 明确当前节点数据node = node_argif self.root == None:node = Node_1(datas_arg)self.root = node# 明确当前节点的划分特征、子节点们: 计算各特征划分后的信息增益,并选出信息增益最大的特征gain_dicts = {}for i in self.X.columns:groups = datas_arg.groupby(i)groups = [groups.get_group(j) for j in set(datas_arg[i])]if len(groups) > 1: # 特征可分gain_dicts[i] = self.get_gain(datas_arg,groups,Y_feature)# 明确停止划分的条件,即停止迭代的条件:无可划分的属性,或是最大的条件熵为0if (not gain_dicts) or max(gain_dicts.values()) == 0:returnselect_feat = max(gain_dicts,key=lambda x:gain_dicts[x])node.select_feat = select_featgroup_feat = datas_arg.groupby(select_feat)for j in set(datas_arg[select_feat]):node_son_value = group_feat.get_group(j)node_son = Node_1(node_son_value)node.sons[j] = node_sonfor key,node_single in node.sons.items():self.get_value_1(node_single.value,node_single)# 获取熵def get_ent(self,datas,feature):p_values = datas[feature].value_counts(normalize=True)p_updown = 1/p_valuesent = (p_values*(p_updown).apply(np.log2)).sum()return ent# 获取条件熵def get_condition_ent(self,datas_list,feature):proportions = [len(i) for i in datas_list]proportions = [i/sum(proportions) for i in proportions]ents = [self.get_ent(i,feature) for i in datas_list]condition_ent = np.multiply(ents,proportions).sum()return condition_ent# 获取信息增益def get_gain(self,datas_all,datas_group,feature):condition_ent = self.get_condition_ent(datas_group,feature)ent_all = self.get_ent(datas_all,feature)gain = ent_all - condition_entreturn gain# 探访决策树,并进行预测分类def predict(self,data,root):if not root.select_feat:p_values = root.value[Y_feature].value_counts(normalize=True)self.Y_predict.append(p_values.idxmax())returnfeat = root.select_feattry:if data[feat] not in root.sons.keys():self.Y_predict.append(None)returnnext_node = root.sons[data[feat]]except:print(data)print(root.sons)raise Exception("错了")self.predict(data,next_node)def pre_print(self, root):if root is None:returnfor key,node_son in root.sons.items():self.pre_print(node_son)def func(self,data):self.predict(data,self.root)max_tree_num = 10
max_feat_num = 3
max_data_num = 100
Y_feature = "推荐类型"data_index_list = [i for i in range(0,len(datas_1)-1)]
feat_index_list = [i for i in range(0,len(important_features)-1)]tree_list = []
all_Y_predict = []
# 循环一定次数:建立多少棵树,就循环多少次# 随机获取一定数量的特征属性# 随机获取一定数量的样本数据
for i in range(max_tree_num):data_index = random.sample(data_index_list, max_data_num-1)feat_index = random.sample(feat_index_list, max_feat_num-1)temp_feat = [important_features[index] for index in feat_index]temp1 = datas[temp_feat]temp_datas = pd.DataFrame([temp1.iloc[index] for index in data_index])# 创建一棵树tree = Tree(temp_datas)# breaktree.get_value_1(tree.datas)datas_1.apply(tree.func,axis=1)all_Y_predict.append(tree.Y_predict)
all_Y_predict = pd.DataFrame(all_Y_predict)
result = all_Y_predict.apply(pd.Series.value_counts)
Y_predict = result.idxmax() # 打印列最大值的行索引accurency = sum(Y_predict==Y)/len(Y)
print(f"分类准确率:{accurency*100}%")
相关文章:

机器学习——随机森林【手动代码】
随机森林这个内容,是目前来说。。。最最最简单,最好理解,应该也是最好实现的了!!! 先挖坑,慢慢填 随机森林,这个名字取得,果然深得该算法的核心精髓,既随机&a…...

Vue 2 处理边界情况
访问元素和组件 通过Vue 2 组件基础一文的学习,我们知道组件之间可以通过传递props或事件来进行通信。 但在一些情况下,我们使用下面的方法将更有用。 1.访问根实例 根实例可通过this.$root获取。 我们在所有子组件中都可以像上面那样访问根实例&…...

写一个mysql 正则表达式,每三个img标签图片后面添加<hr>
你可以使用MySQL的REGEXP_REPLACE函数来实现这个需求。下面是一个示例的正则表达式和SQL语句: sql UPDATE your_table SET your_column REGEXP_REPLACE(your_column, (<img[^>]*>){3}, $0<hr>) WHERE your_column REGEXP (<img[^>]*>){3}…...
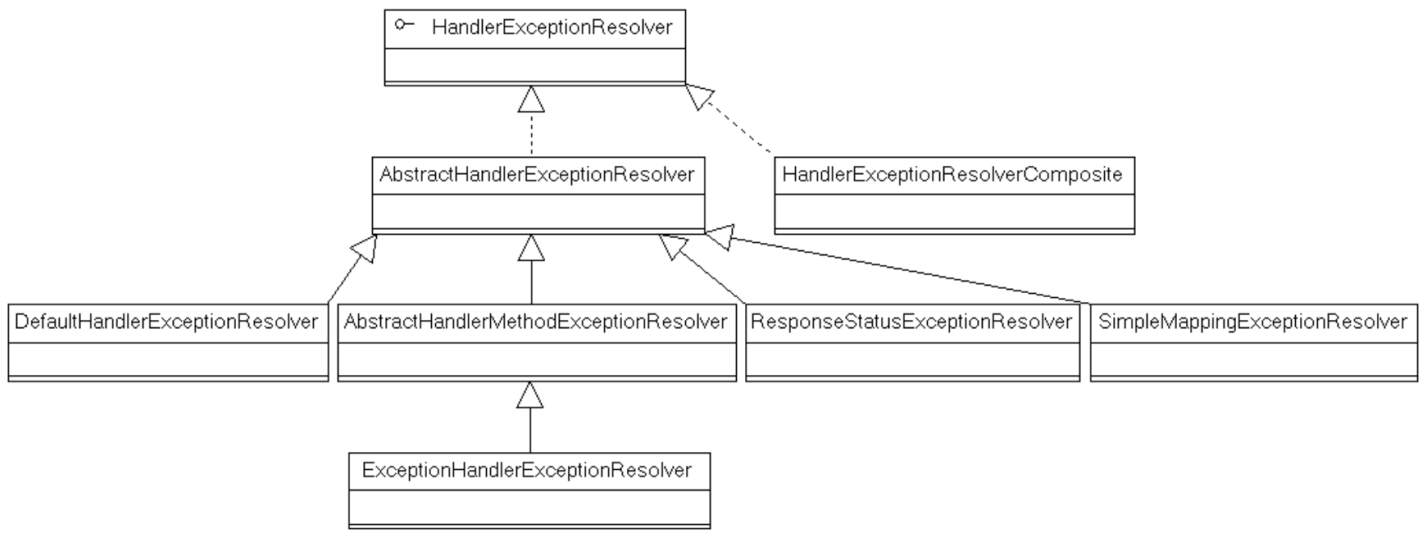
Spring MVC异常处理
Spring MVC异常处理 Spring MVC异常处理机制HandlerExceptionResolver的实现类DefaultHandlerExceptionResolver实现类DefaultHandlerExceptionResolver 在Controller的请求处理方法中手动使用try…catch块捕捉异常,当捕捉到指定的异常时,系统返回对应的…...

Centos7安装docker后默认开启docker0的网卡|卸载默认网卡
docker实战(一):centos7 yum安装docker docker实战(二):基础命令篇 docker实战(三):docker网络模式(超详细) docker实战(四):docker架构原理 docker实战(五):docker镜像及仓库配置 docker实战(六):docker 网络及数据卷设置 docker实战(七):docker 性质及版本选择 认知升…...
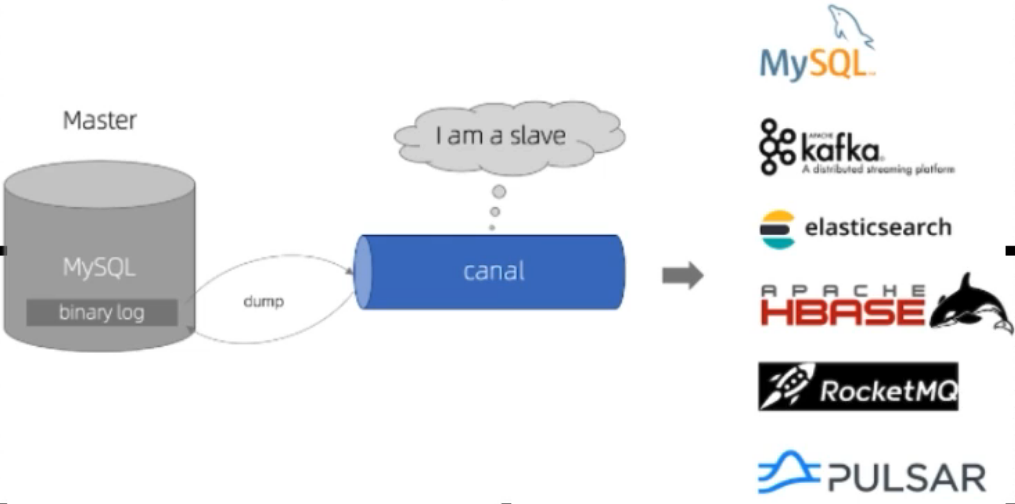
04_Redis与mysql数据双写一致性案例
04——redis与mysql数据双写一致性 一、canal 是什么 canal[ka’nel,中文翻译为水道/管道/沟渠/运河,主要用途是用于MySQL数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发; 历史背景是早期阿里巴巴因为杭州和…...

vue的开发者工具下载『保姆级别』
1.先进官网 极简插件_Chrome扩展插件商店_优质crx应用下载 (zzzmh.cn) 2.搜索vue devtools,点击进去 3.下载插件 4.下载到文件下你自己的文件下:我的是下载到E盘下。 5.压缩到当前目录下 6.电脑进入拓展程序(不同的浏览器操作不同ÿ…...
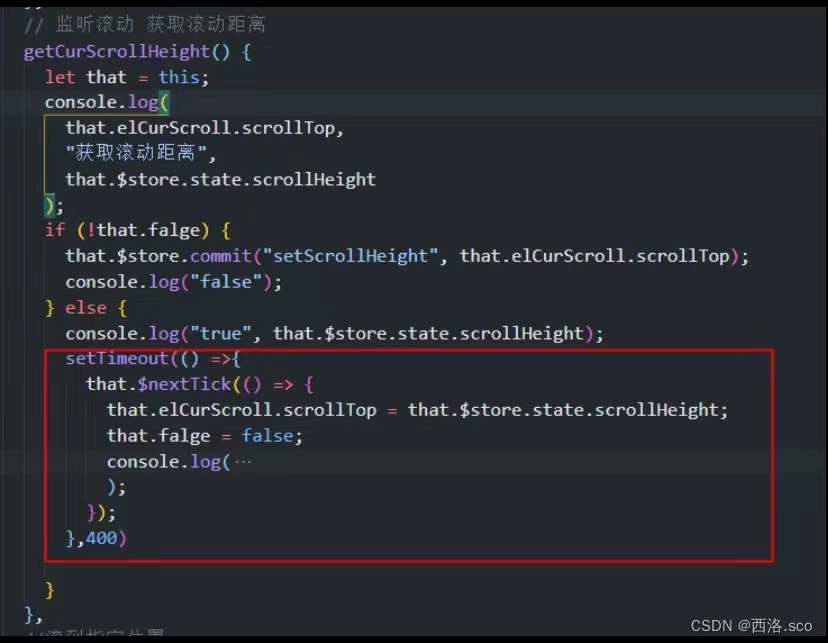
vue的scrollTop手机环境设置值失效,本地正常可以赋值
获取div盒子ref或者document获取都行 监听方法 一定要加this.$nexttick,在本地测试只用nexttick是没有问题的,但是到手机测试就不行了,原因是因为手机渲染比本地更快,所以结合setTimeout使用 如果有更好的处理方法,恳请大佬指点一…...

[前端系列第7弹]Vue:一个渐进式的 JavaScript 框架
Vue 是一个用于构建用户界面的 JavaScript 框架,它具有以下特点: 渐进式:Vue 可以根据不同的使用场景,灵活地选择使用库或者框架的方式,从而实现渐进式的开发。响应式:Vue 通过数据绑定和虚拟 DOM 技术&am…...
C#键盘按键对应Keys类大全
...
SpringBoot 学习(03): 弱语言的注解和SpringBoot注解的异同
弱语言代表:Hyperf,一个基于 PHP Swoole 扩展的常驻内存框架 注解概念的举例说明; 说白了就是,你当领导,破烂事让秘书帮你去安排,你只需要批注一下,例如下周要举办一场活动,秘书将方…...
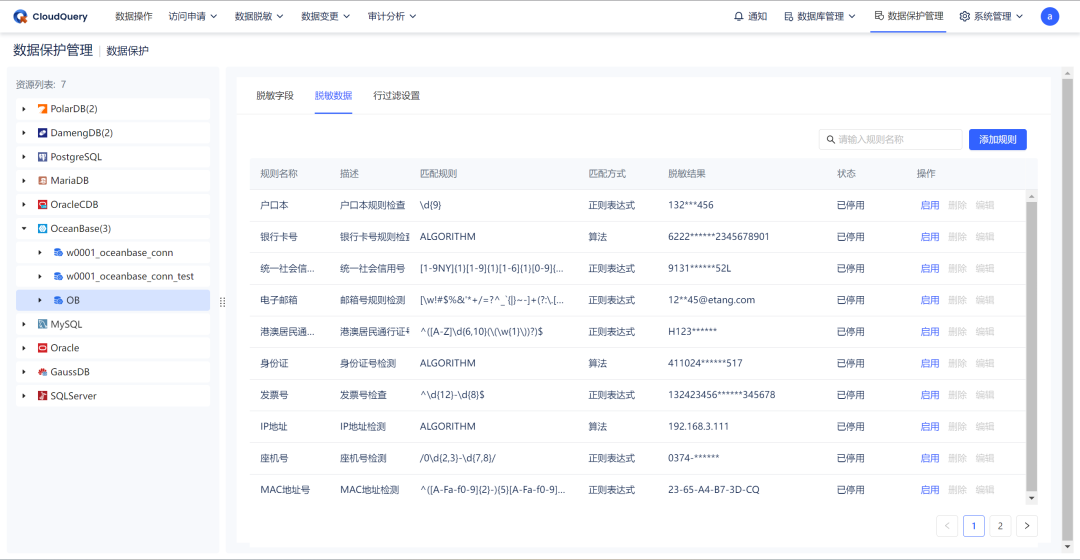
CloudQuery:更好地管理你的 OceanBase 数据库
前言:作为 OceanBase 的生态合作伙伴,CloudQuery(简称“CQ”) 最新发布的社区版 2.2.0 新增了 OceanBase 数据库,为企业使用 OceanBase 数据库提供全面的支持。包括连接与认证、查询与分析、数据安全与权限管理&#x…...

php的password_verify 和 password_hash密码验证
password_hash() 使用足够强度的单向散列算法创建密码的散列(hash)。 当前支持的算法: PASSWORD_DEFAULT - 使用 bcrypt 算法 (PHP 5.5.0 默认)。 注意,该常量会随着 PHP 加入更新更高强度的算法而改变。 所以,使用此常量生成结果的长度将在未…...

JAVA免杀学习与实验
1 认识Webshell 创建一个JSP文件: <% page import"java.io.InputStream" %> <% page import"java.io.BufferedReader" %> <% page import"java.io.InputStreamReader" %> <% page language"java" p…...

Apche Kafka + Spring的消息监听容器
目录 一、消息的接收1.1、消息监听器 二、消息监听容器2.1、 实现方法2.1.1、KafkaMessageListenerContainer2.1.1.1、 基本概念2.1.1.2、如何使用 KafkaMessageListenerContainer 2.1.2、ConcurrentMessageListenerContainer 三、偏移 四、监听器容器自动启动 一、消息的接收 …...

[JavaWeb]【五】web后端开发-Tomcat SpringBoot解析
目录 一 介绍Tomcat 二 基本使用 2.1 解压绿色版 2.2 启动TOMCAT 2.3 关闭TOMCAT 2.4 常见问题 2.5 修改端口号 2.6 部署应用程序 三 SpringBootWeb入门程序解析 前言:tomcat与SpringBoot解析 一 介绍Tomcat 二 基本使用 2.1 解压绿色版 2.2 启动TOMCAT 2…...

css 用过渡实现,鼠标离开li时,背景色缓慢消息的样式
要实现鼠标悬停时背景颜色变为黄色,鼠标离开时背景颜色慢慢消失并变回白色的效果, 可以使用CSS的过渡(transition)属性 li {background: #fff;color: #000;transition: background 0.5s ease-out; }li:hover {background: #fbb31…...

pytorch 线性层Linear详解
线性层就是全连接层,以一个输入特征数为2,输出特征数为3的线性层为例,其网络结构如下图所示: 输入输出数据的关系如下: 写成矩阵的形式就是: 下面通过代码进行验证: import torch.nn as nn …...

LeetCode 833. 字符串中的查找与替换
2235. 两整数相加 添加链接描述 给你两个整数 num1 和 num2,返回这两个整数的和。 示例 1: 输入:num1 12, num2 5 输出:17 解释:num1 是 12,num2 是 5 ,它们的和是 12 5 17 ,…...

Oracle故障案例之-19C时区补丁DSTV38更新
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA工作经验 一位上进心十足的【大数据领域博主】!😜ὡ…...

深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战
深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电…...

ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成
ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 想要在有限硬件条件下实现专业级AI视频生成吗?ComfyUI-Fram…...

Loop:基于Swift开发的macOS窗口管理框架解决方案
Loop:基于Swift开发的macOS窗口管理框架解决方案 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 在macOS桌面环境中,多窗口管理一直是效率工作流的关键瓶颈。传统的手动拖拽操作…...

OpenClaw集成xAI Grok模型:一键配置与API兼容性解析
1. 项目概述:为OpenClaw解锁xAI Grok模型支持 如果你和我一样,既是OpenClaw的忠实用户,又对xAI推出的Grok系列模型(特别是Grok 4.1)的强大推理能力垂涎已久,那么之前肯定也卡在了同一个地方:Ope…...

Emacs集成ChatGPT:AI助手无缝融入编辑器工作流
1. 项目概述:在Emacs中集成ChatGPT的魔法工具作为一名在Emacs生态里摸爬滚打了十多年的老用户,我对于在编辑器里“折腾”各种生产力工具一直乐此不疲。当ChatGPT这类大语言模型(LLM)横空出世时,我的第一反应就是&#…...

终极指南:如何快速筛选高质量免费股票资源的5大核心标准
终极指南:如何快速筛选高质量免费股票资源的5大核心标准 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-s…...

不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制
不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制 在汽车工程仿真领域,AVL Cruise与Matlab Simulink的联合仿真已成为动力系统开发的标准工具链。大多数教程停留在环境配置层面,而真正影响仿真效率与可靠性的,往…...

Multi-Agent 智能办公场景落地:财务、法务、人力的自动协作链路
Multi-Agent 智能办公场景落地:财务、法务、人力的自动协作链路 关键词 Multi-Agent 协作、业财法税一体化、智能办公自动化、大模型Agent编排、跨域规则引擎、RPA增强架构、企业数字员工 摘要 当前中大型企业普遍存在跨部门协作摩擦成本高、规则执行不一致、合规风险不可…...

工业现场故障排查:从温度敏感故障到CMOS浮空输入根因分析
1. 项目概述:一个“脾气暴躁”的堆垛起重机 在工业现场,最让人头疼的往往不是那些彻底罢工的设备,而是那些“时好时坏”、“看心情工作”的间歇性故障。它们像幽灵一样,在你想复现问题时消失得无影无踪,等你一离开又悄…...

专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率
专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 在Windows生态中,右键菜…...