使用pytorch 的Transformer进行中英文翻译训练
下面是一个使用torch.nn.Transformer进行序列到序列(Sequence-to-Sequence)的机器翻译任务的示例代码,包括数据加载、模型搭建和训练过程。
import torch
import torch.nn as nn
from torch.nn import Transformer
from torch.utils.data import DataLoader
from torch.optim import Adam
from torch.nn.utils import clip_grad_norm_# 数据加载
def load_data():# 加载源语言数据和目标语言数据# 在这里你可以根据实际情况进行数据加载和预处理src_sentences = [...] # 源语言句子列表tgt_sentences = [...] # 目标语言句子列表return src_sentences, tgt_sentencesdef preprocess_data(src_sentences, tgt_sentences):# 在这里你可以进行数据预处理,如分词、建立词汇表等# 为了简化示例,这里直接返回原始数据return src_sentences, tgt_sentencesdef create_vocab(sentences):# 建立词汇表,并为每个词分配一个唯一的索引# 这里可以使用一些现有的库,如torchtext等来处理词汇表的构建word2idx = {}idx2word = {}for sentence in sentences:for word in sentence:if word not in word2idx:index = len(word2idx)word2idx[word] = indexidx2word[index] = wordreturn word2idx, idx2worddef sentence_to_tensor(sentence, word2idx):# 将句子转换为张量形式,张量的每个元素表示词语在词汇表中的索引tensor = [word2idx[word] for word in sentence]return torch.tensor(tensor)def collate_fn(batch):# 对批次数据进行填充,使每个句子长度相同max_length = max(len(sentence) for sentence in batch)padded_batch = []for sentence in batch:padded_sentence = sentence + [0] * (max_length - len(sentence))padded_batch.append(padded_sentence)return torch.tensor(padded_batch)# 模型定义
class TranslationModel(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, embedding_size, hidden_size, num_layers, num_heads, dropout):super(TranslationModel, self).__init__()self.embedding = nn.Embedding(src_vocab_size, embedding_size)self.transformer = Transformer(d_model=embedding_size,nhead=num_heads,num_encoder_layers=num_layers,num_decoder_layers=num_layers,dim_feedforward=hidden_size,dropout=dropout)self.fc = nn.Linear(embedding_size, tgt_vocab_size)def forward(self, src_sequence, tgt_sequence):embedded_src = self.embedding(src_sequence)embedded_tgt = self.embedding(tgt_sequence)output = self.transformer(embedded_src, embedded_tgt)output = self.fc(output)return output# 参数设置
src_vocab_size = 1000
tgt_vocab_size = 2000
embedding_size = 256
hidden_size = 512
num_layers = 4
num_heads = 8
dropout = 0.2
learning_rate = 0.001
batch_size = 32
num_epochs = 10# 加载和预处理数据
src_sentences, tgt_sentences = load_data()
src_sentences, tgt_sentences = preprocess_data(src_sentences, tgt_sentences)
src_word2idx, src_idx2word = create_vocab(src_sentences)
tgt_word2idx, tgt_idx2word = create_vocab(tgt_sentences)# 将句子转换为张量形式
src_tensor = [sentence_to_tensor(sentence, src_word2idx) for sentence in src_sentences]
tgt_tensor = [sentence_to_tensor(sentence, tgt_word2idx) for sentence in tgt_sentences]# 创建数据加载器
dataset = list(zip(src_tensor, tgt_tensor))
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)# 创建模型实例
model = TranslationModel(src_vocab_size, tgt_vocab_size, embedding_size, hidden_size, num_layers, num_heads, dropout)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs):total_loss = 0.0num_batches = 0for batch in dataloader:src_inputs, tgt_inputs = batch[:, :-1], batch[:, 1:]optimizer.zero_grad()output = model(src_inputs, tgt_inputs)loss = criterion(output.view(-1, tgt_vocab_size), tgt_inputs.view(-1))loss.backward()clip_grad_norm_(model.parameters(), max_norm=1) # 防止梯度爆炸optimizer.step()total_loss += loss.item()num_batches += 1average_loss = total_loss / num_batchesprint(f"Epoch {epoch + 1}/{num_epochs}, Loss: {average_loss}")# 在训练完成后,可以使用模型进行推理和翻译上述代码是一个基本的序列到序列机器翻译任务的示例,其中使用torch.nn.Transformer作为模型架构。首先,我们加载数据并进行预处理,然后为源语言和目标语言建立词汇表。接下来,我们创建一个自定义的TranslationModel类,该类使用Transformer模型进行翻译。在训练过程中,我们使用交叉熵损失函数和Adam优化器进行模型训练。代码中使用的collate_fn函数确保每个批次的句子长度一致,并对句子进行填充。在每个训练周期中,我们计算损失并进行反向传播和参数更新。最后,打印每个训练周期的平均损失。
请注意,在实际应用中,还需要根据任务需求进行更多的定制和调整。例如,加入位置编码、使用更复杂的编码器或解码器模型等。此示例可以作为使用torch.nn.Transformer进行序列到序列机器翻译任务的起点。
相关文章:
使用pytorch 的Transformer进行中英文翻译训练
下面是一个使用torch.nn.Transformer进行序列到序列(Sequence-to-Sequence)的机器翻译任务的示例代码,包括数据加载、模型搭建和训练过程。 import torch import torch.nn as nn from torch.nn import Transformer from torch.utils.data im…...

解决element的select组件创建新的选项可多选且opitions数据源中有数据的情况下,回车不能自动选中创建的问题
前言 最近开发项目使用element-plus库内的select组件,其中有提供一个创建新的选项的用法,但是发现一些小问题,在此记录 版本 “element-plus”: “^2.3.9”, “vue”: “^3.3.4”, 问题 1、在options数据源中无数据的时候,在输入框…...
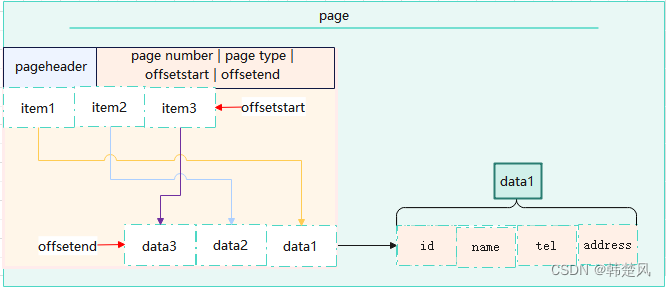
人工智能大模型加速数据库存储模型发展 行列混合存储下的破局
数据存储模型 专栏内容: postgresql内核源码分析手写数据库toadb并发编程toadb开源库 个人主页:我的主页 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 概述 在数据库的发展过程中,关…...
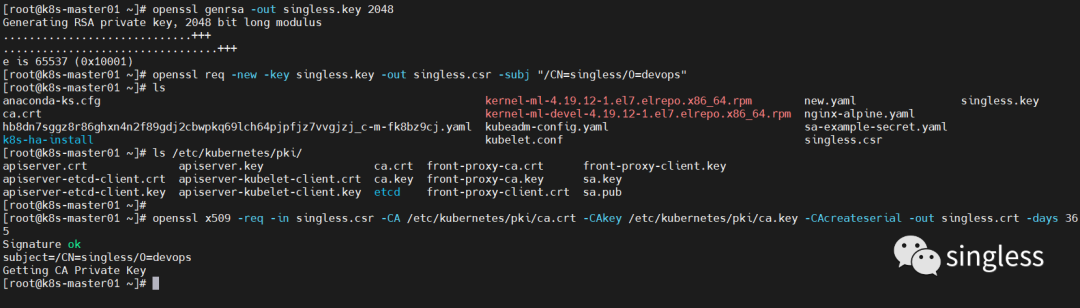
K8S用户管理体系介绍
1 K8S账户体系介绍 在k8s中,有两类用户,service account和user,我们可以通过创建role或clusterrole,再将账户和role或clusterrole进行绑定来给账号赋予权限,实现权限控制,两类账户的作用如下。 server acc…...
实现chatGPT 聊天样式
效果图 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Chat Example</title&g…...

day9 STM32 I2C总线通信
I2C总线简介 I2C总线介绍 I2C(Inter-Integrated Circuit)总线(也称IIC或I2C)是由PHILIPS公司开发的两线式串行总线,用于连接微控制器及其外围设备,是微电子通信控制领域广泛采用的一种总线标准。 它是同步通…...

终极Shell:Zsh(CentOS7 安装 zsh 及 配置 Oh my zsh)
CentOS7 安装 zsh 及 配置 Oh my zsh 我们在通过Shell操作linux终端时,配置、颜色区分、命令提示大都达不到我们预期的效果或者操作较为繁琐。 今天就来介绍一款终极一个及其好用的类Linux系统中的终端软件,江湖称之为马车中的跑车,跑车中的飞行车,史称『终极 Shell…...

Redis的数据持久化
前言 本文主要介绍Redis的三种持久化方式、AOF持久化策略等 什么是持久化 持久化是指将数据在内存中的状态保存到非易失性介质(如硬盘、固态硬盘等)上的过程。在计算机中,内存中的数据属于易失性数据,一旦断电或重启系统&#…...

CSS 选择器
前言 基础选择器 以下是几种常见的基础选择器。 标签选择器:通过HTML标签名称选择元素。 例如: p {color: red; } 上述样式规则将选择所有<p>标签 ,并将其文字颜色设置为红色。 类选择器:通过类名选择元素。使用类选择…...
)
上位机工作总结(2023.03-2023.08)
1.工作总结 不知不觉,已经从C#转为Qt开发快半年了。这半年内,也是学习了很多C相关的开发技能,同时自己的技术栈也是进一步丰富,以后跑路就更容易啦,哈哈!自己之前就有Winform和一些简单的Qt项目实践&#…...
APSIM模型参数优化 批量模拟丨气象数据准备、物候发育和光合生产、物质分配与产量模拟、土壤水分平衡算法、土壤碳氮平衡模块、农田管理模块等
随着数字农业和智慧农业的发展,基于过程的农业生产系统模型在模拟作物对气候变化的响应与适应、农田管理优化、作物品种和株型筛选、农田固碳和温室气体排放等领域扮演着越来越重要的作用。APSIM (Agricultural Production Systems sIMulator)模型是世界知名的作物生…...
Azure防火墙
文章目录 什么是Azure防火墙如何部署和配置创建虚拟网络创建虚拟机创建防火墙创建路由表,关联子网、路由配置防火墙策略配置应用程序规则配置网络规则配置 DNAT 规则 更改 Srv-Work 网络接口的主要和辅助 DNS 地址测试防火墙 什么是Azure防火墙 Azure防火墙是一种用…...
【LeetCode】剑指 Offer Ⅱ 第4章:链表(9道题) -- Java Version
题库链接:https://leetcode.cn/problem-list/e8X3pBZi/ 类型题目解决方案双指针剑指 Offer II 021. 删除链表的倒数第 N 个结点双指针 哨兵 ⭐剑指 Offer II 022. 链表中环的入口节点(环形链表)双指针:二次相遇 ⭐剑指 Offer I…...
Android SDK 上手指南|| 第三章 IDE:Android Studio速览
第三章 IDE:Android Studio速览 Android Studio是Google官方提供的IDE,它是基于IntelliJ IDEA开发而来,用来替代Eclipse。不过目前它还属于早期版本,目前的版本是0.4.2,每个3个月发布一个版本,最近的版本…...

Vue--》打造个性化医疗服务的医院预约系统(七)完结篇
今天开始使用 vue3 + ts 搭建一个医院预约系统的前台页面,因为文章会将项目的每一个地方代码的书写都会讲解到,所以本项目会分成好几篇文章进行讲解,我会在最后一篇文章中会将项目代码开源到我的GithHub上,大家可以自行去进行下载运行,希望本文章对有帮助的朋友们能多多关…...
点亮一颗LED灯
TOC LED0 RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB,ENABLE);//使能APB2的外设时钟GPIO_InitTypeDef GPIO_Initstructure;GPIO_Initstructure.GPIO_Mode GPIO_Mode_Out_PP;//通用推挽输出GPIO_Initstructure.GPIO_Pin GPIO_Pin_5;GPIO_Initstructure.GPIO_Speed GPIO_S…...
SSH远程直连--------------Docker容器
文章目录 1. 下载docker镜像2. 安装ssh服务3. 本地局域网测试4. 安装cpolar5. 配置公网访问地址6. SSH公网远程连接测试7.固定连接公网地址8. SSH固定地址连接测试 在某些特殊需求下,我们想ssh直接远程连接docker 容器,下面我们介绍结合cpolar工具实现ssh远程直接连接docker容器…...
———— html5和css3.html基础)
Python/Spring Cloud Alibaba开发--前端复习笔记(1)———— html5和css3.html基础
Python/Spring Cloud Alibaba开发–前端复习笔记(1)———— html5和css3.html基础 1)概述和基本结构 超文本标记语言。超文本指超链接,标记指的是标签。 基本结构: <!DOCTYPE html> 文档声明 <html lang”en”>…...
视频处理)
open cv学习 (十一)视频处理
视频处理 demo1 import cv2 # 打开笔记本内置摄像头 capture cv2.VideoCapture(0) # 笔记本内置摄像头被打开 while capture.isOpened():# 从摄像头中实时读取视频retval, image capture.read()# 在窗口中实时显示读取到的视频cv2.imshow("Video", image)# 等到用…...
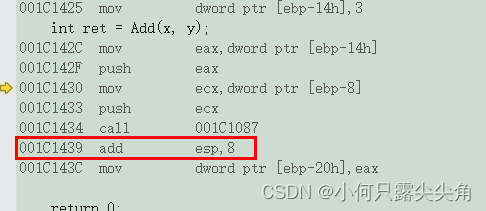
函数栈帧理解
本文是从汇编角度来展示的函数调用,而且是在vs2013下根据调试展开的探究,其它平台在一些指令上会有点不同,指令不多,简单记忆一下即可,在我前些年的学习中,学的这几句汇编指令对我调试找错误起了不小的作用…...

联邦学习与RAG融合:构建隐私保护的分布式智能问答系统
1. 项目概述:当联邦学习遇上检索增强生成最近在折腾一个挺有意思的开源项目,叫fed-rag,来自 Vector Institute。光看名字,老司机们大概就能猜出个七七八八了:这玩意儿是把联邦学习和检索增强生成给揉到一块儿去了。我花…...

终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统
终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers…...

5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南
5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

Perplexity无法解析Springer LaTeX公式?2024.06最新MathJax兼容补丁+3类数学文献精准摘要生成术
更多请点击: https://intelliparadigm.com 第一章:Perplexity解析Springer文献的底层机制与失效归因 Perplexity 作为衡量语言模型预测能力的关键指标,在学术文献解析场景中常被误用为“质量代理”,尤其在处理 Springer 出版集团…...

《QGIS空间数据处理与高级制图》008:OGR2OGR命令行工具核心优势
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

长沙定制开发本地生活APP打造城市便民消费场景
随着长沙城市发展,市民对便民消费的需求越来越高,长沙本地生活APP定制开发也逐渐成为本地商家、政企单位布局数字化的重要选择。不同于通用模板APP,长沙定制本地生活APP可根据长沙本地特色,整合餐饮、生鲜、家政、休闲娱乐、政务便…...

GitHub 74.2k Star的Redis,开发者必备的内存数据库
文章目录GitHub 74.2k Star的Redis,开发者必备的内存数据库核心能力覆盖多数开发场景实际使用建议GitHub 74.2k Star的Redis,开发者必备的内存数据库 Redis是GitHub上的热门开源项目,Star数达到74223,是很多开发者日常工作中常用…...

Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析
Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一款高性能的Adobe ExtendScript二进制格式(JSXBIN&#…...
到Stream API:Java二维数组初始化的几种高效写法与性能对比)
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比 在算法竞赛和数据处理应用中,二维数组的初始化往往是性能优化的第一个瓶颈。我曾在一个图像处理项目中,因为选择了不当的初始化方式,导致整体性能下降了…...

教培机构管理越忙越乱?用对工具,比多雇两个人更高效
不少培训机构校长都有同样的感受:明明团队很拼,每天从早忙到晚,可机构依旧问题不断。招生线索散落在微信、表格、登记本里,跟进不及时就白白流失;排课全靠人工核对,老师冲突、教室撞期、调课通知不到位是常…...