C++入门知识点——解决C语言不足


😶🌫️Take your time ! 😶🌫️
💥个人主页:🔥🔥🔥大魔王🔥🔥🔥
💥代码仓库:🔥🔥魔王修炼之路🔥🔥
💥所属专栏:🔥魔王的修炼之路–C++🔥
如果你觉得这篇文章对你有帮助,请在文章结尾处留下你的点赞👍和关注💖,支持一下博主。同时记得收藏✨这篇文章,方便以后重新阅读。
文章目录
- 一、前言
- C++的产生
- 各种语言的关系
- 二、关键字
- 三、命名空间
- 介绍
- 命名空间的使用
- 总结
- 四、cin、cout
- 五、缺省参数
- 缺省参数概念
- 缺省参数分类
- 全缺省参数
- 半缺省参数
- 注意点
- 六、函数重载
- 介绍
- 原因
- 其他
- 七、引用
- 概念
- 引用特性
- 使用场景
- 做参数
- 做返回值
- 总结
- 常引用
- 八、auto
- 九、内联函数inline
- 十、其它
- 总结
一、前言
C++的产生
学习完C语言,现在正是开始学习C++,C++是Bjarne Stroustrup(本贾尼)祖师爷在使用C语言时感觉诸多不便,于是个人研发了C++,在C语言的基础上引入并扩充了面和对象的概念,因此,C++是基于C语言产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。

各种语言的关系
C语言。
C++在C语言的基础上进行了扩展,并且兼容C语言。
java抄C++,并且把C++的一些坑修改了或者删了。
C#抄java,但是C#已经与C和C++不像了。
二、关键字
- C++共有63个关键字,C语言有32个关键字。
三、命名空间
介绍
- 在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存
在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,
以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
命名空间可以定义变量/函数/类型。
命名空间可以嵌套(当一个项目很大的时候可以在命名空间里再嵌套命名空间)。
同一个工程里允许多个同名命名空间的出现,编译器最后会合成到同一个命名空间中。
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中,当展开该命名空间后,就相当于把这个命名空间的内容暴露到全局。
命名空间的使用
- 命名空间的使用有三种:
- 指定访问:加命名空间名称及域作用限定符(::),作用为特定只访问::前面那个空间里的成员。当::前面什么都不加时表示访问全局变量(暴露到全局也相当于全局变量)。其他的和C一样,比如不加::的话还是局部优先。
- 部分展开:使用using将命名空间中的某个成员引入。eg:using std::cout; 作用为将该命名空间中的这一个成员暴露到全局。暴露到全局就相当于全局变量了,所以不能和原本的全局变量有重名,否则就是重定义了。
- 全部展开:把这个命名空间全部暴露到全局。eg:using namespace std;这个的意思就是把C++标准库(C++库和STL)暴露到全局。
总结
- 命名空间和#define区别:#define是把包含的那个文件拷贝过来,但是命名空间是指能去访问这一块空间,所以他们是不一样的。
- 定义了一个命名空间后不用像结构体一样在大括号后面加分号。
- 局部域没有展开命名空间这一说,也就是都是在全局域展开命名空间的。
- 既要包含头文件也要使用命名空间:包含头文件是因为让库里该头文件对应的拷贝过来,但是它们是在std域内,所以如果想用,还要展开或某个展开或直接指定到std域内搜索我们相用的库函数。只展开std是只能访问std的空间,但是没包含头文件的话就相当于那些东西没有拷贝过来,那么在std空间里就没有你想访问的那些东西了。
四、cin、cout
- cin、cout:自动识别类型。cout的输出格式化不用掌握,需要输出格式的话用printf就好了。头文件是iostream。endl相当于C语言中的‘\n’,是C++中的换行符,头文件也是iostream。
- <<流插入运算符,>>流提取运算符。
- 速度:C语言的scanf和printf比cin,cout快一点点点。scanf和printf更加底层和高效那么一点点点。
- 注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应
头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,
规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因
此推荐使用iostream+std的方式。
五、缺省参数
缺省参数概念
- 缺省参数是声明或定义函数时为函数的参数(形参)指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
缺省参数分类
全缺省参数
函数的形参都有缺省(默认)参数。
半缺省参数
函数的形参部分有缺省参数。
注意点
- 半缺省参数必须从右往左依次来给出,不能间隔着给。
- 声明和定义不能同时给缺省参数,如果一个函数既有声明又有定义,那么应该只在声明时给缺省参数。
- 缺省值必须是全局变量或者常量。
- C语言不支持(编译器不支持)。
- 给缺省(默认参数)是从右向左给的(也就是函数里的参数从右向左给默认值)。传参是从左向右传的(函数里对应接收传的参数是从函数参数的左边开始一个个对应着接收的)(只能从左向右依次传参)。因此可以说如果有一个没给缺省,那么就至少需要传一个参数。
- 缺省参数只能在声明时给缺省值,首先一定是声明和定义选一个给,不然给的不一样不知道用哪个,然后就是分析选哪一个,如果是定义给声明不给,那么在编译阶段处理单独的源文件时就过不去,因为假如传了一个参数,但是函数可以接收两个,但是声明的时候没给缺省值,那么第二个参数就没有接收的值了,编译阶段就通不过。但是如果是声明的时候给,那就相当于在调用该函数传参时把缺少实参的写上了缺省值,那么就等于没有少传参数,编译就能通过。
- 函数声明是函数的接口,它提供了函数的信息,包括函数名、参数列表和返回类型。默认参数的值需要在函数声明中给定,以便在函数调用时让编译器知道该函数的信息,通过参数类型匹配来确定到底调用哪个函数。
六、函数重载
介绍
函数重载是函数的一种特殊情况,C++允许在同一个作用域出现多个同名函数,这些函数的不同在于函数的参数类型、个数不同,与返回值无关,常用来处理实现功能类似数据类型不同的问题。
原因
那么疑问来了,当调用同名函数时,C++是怎么区分的?
- 函数名修饰规则(编译结束开始更新函数名,编译阶段是根据参数来判断调用哪个同名函数的):会对函数进行语法分析和语义分析,将函数名和参数列表作为函数的标识符。修改的是汇编阶段产生的符号表里的函数名,并不是全部地方都修改了。
其他
- C++自动识别类型都是用到了函数重载。
- 全局变量在全局域时只能定义时初始化,不能进行赋值。
- C++支持函数重载的原因:首先是编译阶段能过:C++因为支持函数重载(同名的需要参数不同,不然就报错了:这个函数已有主体(报错“函数已有主体”意味着在函数的声明和定义之间存在重复的函数定义。这通常是由于在同一个源文件中多次定义了同一个函数导致的),不属于函数重载的问题(函数重载还没开始),在编译阶段错的,算是语法错误),因此在编译阶段会根据传的参数个数及类型来判断到低调的是哪个同名函数,并且可以让相同名字不同参数的同名函数都写入符号表里(写进去的名字会根据函数名修饰规则来修饰)。其次是编译结束后会进行函数名修饰:等编译阶段结束,汇编阶段会将函数参数类型信息作为要形成符号表的函数名,于是链接阶段就能对应上了,所以能让符号表里更新为对应函数的有效地址(如果直接声明和定义在一个文件,那么形成符号表时就是对应的有效地址,该函数就不需要链接了,也就是链接过后该函数对应的符号表里的地址不会变)。
- C语言为什么不支持函数重载:编译器直接在编译阶段就通不过,编译阶段遇见变量名相同就是语法错误,因为C语言不支持重名函数。而且要知道C语言对函数进行语法分析和语义分析,没有将参数列表作为函数的标识符的一部分(也就是没有函数名修饰规则)(这一块就是个规则,跟不支持函数重载没关系,因为函数重载是在链接时用的,但是C若有同名函数,编译器走不到链接这一步)。
- 编译阶段不能得到函数的有效地址:编译阶段虽然能转换成二进制,也就是能有计算机要识别的东西:(二进制不是人看的,所以用汇编的角度来说)编译阶段有了各种指令的操作,比如函数,会call跳到一个地址然后再jump过去,进入那个函数的汇编代码里去执行汇编指令(建立函数栈帧等),但是要知道符号表合并是在链接才开始的,对于test.cpp文件,编译阶段的函数我们只要声明就能通过,形成的符号表里存的是无效地址(如果这个文件只有声明的话),真正有效地址是在定义函数的文件里的,但是编译阶段各个文件是独立的,在链接阶段才会合并,把无效的换为有效的,所以编译阶段得不到调用函数真正的地址。相当于包含一个头文件,预编译时展开,在编译时调用的函数也就都声明了,相当于给了承诺,编译器让通过了,但是有没有兑现承诺还要看之后。链接就相当于兑现承诺,看到底是真话假话。
- 假如返回值与函数名修饰规则有关,C++也不支持只是返回值不同的同名函数:因为如果函数参数一样,返回值不同,假如函数名修饰规则也会根据返回值修改,那么链接时当然能找到对应的有效地址,但是走不到这个阶段,因为编译阶段就会检查出错误:函数已有主体(也就是重定义)(调用函数时不会根据返回类型类判断,参数是相同的,所以认为函数重定义了,会报错)。
- 函数重载与返回值无关:函数名修饰规则与函数返回值无关,因此函数返回值与函数重载没联系。
- 函数不一定必须在链接阶段才能有有效地址:如果函数直接就是定义,那就在编译阶段(汇编阶段)符号表里存的就是函数的有效地址了,该函数就不需要链接有效地址(符号表该函数对应的地址就是有效地址不变)了。
七、引用
概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,目前初学C++可以理解为编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
- 类型& 引用变量名(对象名)= 引用实体;
- 引用类型必须和引用实体是同种类型的。
引用特性
- 引用在定义时必须初始化。
- 一个变量可以有多个引用。
- 引用一旦引用一个实体,再不能引用其他实体。之后的 = 就是赋值的作用。
引用理解:既可以把引用当作是引用的这个变量的别名(可以想成指针解引用),也可以看作是引用类型(可以想成与指针很像,但不是指针)。意思就是引用可以与这两种类型相互操作(怎么看待取决于你是想把它看作哪种)。不过一般就是把引用当作别名来看待,也就是引用的那个变量(而不是指针相关的那个本质)如果是引用与引用之间的操作的话,才看成引用(跟指针相关的,也就是本质)。
使用场景
做参数
首先函数参数可以分为两个:输入型参数和输出型参数
输入型参数:只是实参的拷贝,只是为了用实参的值,修改后对实参没影响。
输出型参数:在函数里边修改的同时也把实参修改了,在C语言中我们是用指针来操作的。
引用是用于输出型参数。
- 引用做参数:1.输出型参数,修改实参 2.减少拷贝,提高效率(不用再拷贝一次实参的大小,只需要弄一个4字节的地址,和指针一样)(引用做参数有的效果指针都有:)。
做返回值
- 减少拷贝,提高效率(返回时不用临时拷贝,要注意返回的变量不能随函数而销毁)(比如如果是用变量接收,只需要在赋值时直接找到返回值(引用)这块空间拷贝一次给要接收的变量,不用先临时拷贝一次了)(如果用引用接收,那就一次也不需要拷贝,直接就相当于给了一个别名),是否会开辟一个指针目前还不了解。
- 获取返回值+修改返回值。
- 注意:函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用
引用返回,如果已经还给系统了,则不能用引用返回(这就类似于访问野指针了)。
总结
- 引用做为参数或者返回值都有提高效率这一优点,这是对于当变量特别大的情况下,变量较小的情况下差距很小。
- 引用的理解:加个&符可以理解为它实质是多了一级指针特性,(自动解引用)。
- 引用实质:语法层面我们认为不开空间,但是在底层实现上其实还是开空间,通过指针来实现。
-
- 引用和指针的区别:
- sizeof计算的是引用的那个变量类型的大小,而不是像指针一样某个地址的大小(4/8字节)。
- 引用的变量不是指针的话,&引用取出来的是那个变量的地址,也就相当于一级指针(是指针的话就是加一级)(&指针的话最少就是二级指针)。
- 有多级指针,但没有多级引用。
- 访问实体方式:指针需要解引用,引用编译器会自动处理。
- 引用比指针更安全(比如没有空引用)。
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何
一个同类型实体;没有NULL引用,但有NULL指针
临时变量:编译截断发生(产生指令时会有体现)。只要发生类型转换(有运算符的地方不同类型需要先转换成相同类型才能进行运算符的作用)(强制类型转换,整型提升,隐式类型转换,截断等),都会产生临时变量。因为并不会修改原本变量的值,而是将原本要修改的变量的修改后的值放入临时变量里再由临时变量赋过去。临时变量具有常性,所以在起别名时需要先限制权限(const),否则不能取别名。一般函数(返回值不是引用的话),返回值一般是要返回的那个东西的临时拷贝,也就是临时变量,临时变量具有常性。是否产生临时变量不是看要返回的那个变量会不会随函数销毁也销毁,而是看返回类型是不是引用。
常引用
- 引用过程中,权限不能放大。可以平移和缩小。缩小后的这个引用不能扩大权限,但是原本有这个权限的引用或变量还可以有原本的权限,并且修改后还是都修改了,因为他们实质都是这一块空间。
八、auto
- 自动推导对应的类型,对于以后很长的类型(比如迭代器),我们可以直接用auto来代替。
- auto不能做返回值(C++11标准后可以做返回值)和参数。
- **使用定义一个变量时必须进行初始化(让auto能够推导变量的类型)。**因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
- 使用细则:
- 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须
加& - 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译
器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。 - auto不能做为函数参数和返回值(c++11标准之后可以做为返回值)。
- auto不能直接用来声明数组。
最爽的用法是新式for循环,目前还没学。
九、内联函数inline
- inline对于编译器仅仅只是一个建议,最终是否成为inline,编译器自己决定,适用于小且频繁调用的非递归函数。
- 比较长的函数或者递归函数等就算加了inline也会被编译器否决掉,因为会代码膨胀(可编译程序变的很大)。比如调用一个函数10000次,这个函数有50个指令,普通调用总指令:10000+50,内联函数总指令:10000*50,因为每次都要再把指令弄到到调用的位置。
- 内联函数不能声明和定义分离,因为内联函数没有地址,不会进入符号表,所以链接时找不到,它是直接在原本那个位置展开了(多个文件的话直接在.h里写全就行了)。
- C++的内联函数可以很好的代替宏。
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会
用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运
行效率。 - inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
原本在调用函数时会call一个地址然后再jump跳转到函数的指令里,当调用内联函数时,它会在这个地方展开函数的那些指令,也就是不再跳转,直接再把那些指令拷贝到这里,所以会增加负担(因为当调用多次一个函数时,函数都会跳到那个特定位置的指令里,但是内联函数的话每次都要在调用函数的地方展开那些指令)。
- 默认debug模式下,inline不会起作用,否则不方便调试了。但如果换成release版本,就不容易看反汇编,所以需要在vs默认debug版本里调一下。
十、其它
- NULL是被C++一个宏定义为常量0,也就是NULL和常量0完全一样,类型是int,所以以后对于空指针用(C++11出来的)nullptr。
在C++11中,nullprt是专门用来表示空指针的,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
nullptr的类型是std::nullptr_t,它是一个独立的类型,专门用于表示空指针。
在使用nullptr表示空指针时,不用包含头文件,它是做为C++关键字出现的。
- 函数参数可以不接收:对于C/C++编译器,只要类型能匹配就行,可以不接收实参,也就是不写形参,只写形参的类型。
总结
- 博主长期更新,博主的目标是不断提升阅读体验和内容质量,如果你喜欢博主的文章,请点个赞或者关注博主支持一波,我会更加努力的为你呈现精彩的内容。
🌈专栏推荐
😈魔王的修炼之路–C语言
😈魔王的修炼之路–数据结构初阶
😈魔王的修炼之路–C++
😈魔王的修炼之路–Linux
更新不易,希望得到友友的三连支持一波。收藏这篇文章,意味着你将永久拥有它,无论何时何地,都可以立即找到重新阅读;关注博主,意味着无论何时何地,博主将永久和你一起学习进步,为你带来有价值的内容。

相关文章:
C++入门知识点——解决C语言不足
😶🌫️Take your time ! 😶🌫️ 💥个人主页:🔥🔥🔥大魔王🔥🔥🔥 💥代码仓库:🔥🔥魔…...

探秘分布式大数据:融合专业洞见,燃起趣味火花,启迪玄幻思维
文章目录 一 数据导论二 大数据的诞生三 大数据概论3.1 大数据的5V特征3.2 大数据的工作核心 四 大数据软件生态4.1 数据存储软件4.2 数据计算软件4.3 数据传输软件 五 Apache Hadoop概述5.1 Apache Hadoop框架5.2 Hadoop的功能5.3 Hadoop的发展5.4 Hadoop发行版本 一 数据导论…...

什么是 SPI,和API有什么区别?
面试回答 Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用。 API Application Programming Interface 大多数情况下ÿ…...
 失败)
python3 安装clickhouse_sqlalchemy(greenlet) 失败
环境信息: centos7操作系统,python3.8 执行pip3 install clickhouse_sqlalchemy或者pip3 install greenlet报以下报错: Command "/opt/python3.6.10-customized/bin/python3.6 -u -c "import setuptools, tokenize;file/tmp/pip-in…...

五款拿来就能用的炫酷表白代码
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:小白零基础《Python入门到精通》 五款炫酷表白代码 1、无限弹窗表白2、做我女朋友好吗,不同意就关机3、…...

Springboot 封装整活 Mybatis 动态查询条件SQL自动组装拼接
前言 ps:最近在参与3100保卫战,战况很激烈,刚刚打完仗,来更新一下之前写了一半的博客。 该篇针对日常写查询的时候,那些动态条件sql 做个简单的封装,自动生成(抛砖引玉,搞个小玩具&a…...

宝塔部署Java+Vue前后端分离项目经验总结
前言 之前部署服务器都是在Linux环境下自己一点一点安装软件,听说用宝塔傻瓜式部署更快,这次浅浅尝试了一把。 确实简单! 1、 买服务器 咋买服务器略,记得服务器装系统就装 Cent OS 7系列即可,我装的7.6。 2、创建…...

【公告】停止更新
CSDN 博客的限制太多了。阅读体验也非常差。后续将不再 CSDN 上更新。 逐步迁移到掘金和个人博客。 欢迎关注 掘金:0xforee 个人博客:0xforee’s blog...
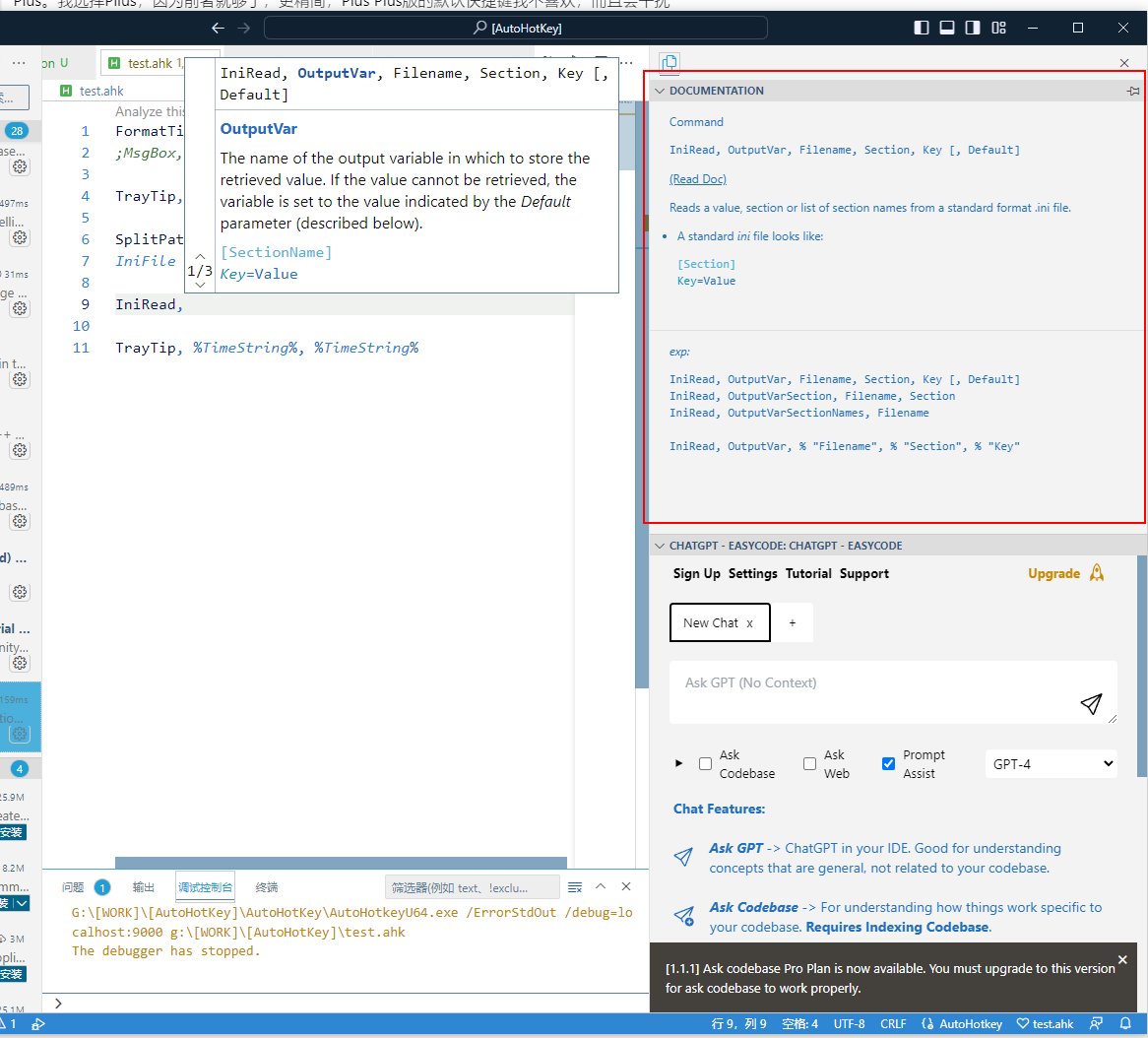
AutoHotKey+VSCode开发扩展推荐
原来一直用的大众推荐的SciTeAHK版,最近发现VSCode更舒服一些,有几个必装的扩展推荐一下: AutoHotkey Plus 请注意不是AutoHotkey Plus Plus。如果在扩展商店里搜索会有两个,一个是Plus,一个是Plus Plus。我选择Pllus&…...

了解 JSON 格式
一、JSON 基础 JSON(JavaScript Object Notation,JavaScript 对象表示法)是一种轻量级的数据交换格式,JSON 的设计目的是使得数据的存储和交换变得简单。 JSON 易于人的阅读和书写,同时也易于机器的解析和生成。尽管 J…...

[RDMA] 高性能异步的消息传递和RPC :Accelio
1. Introduce Accelio是一个高性能异步的可靠消息传递和RPC库,能优化硬件加速。 RDMA和TCP / IP传输被实现,并且其他的传输也能被实现,如共享存储器可以利用这个高效和方便的API的优点。Accelio 是 Mellanox 公司的RDMA中间件,用…...
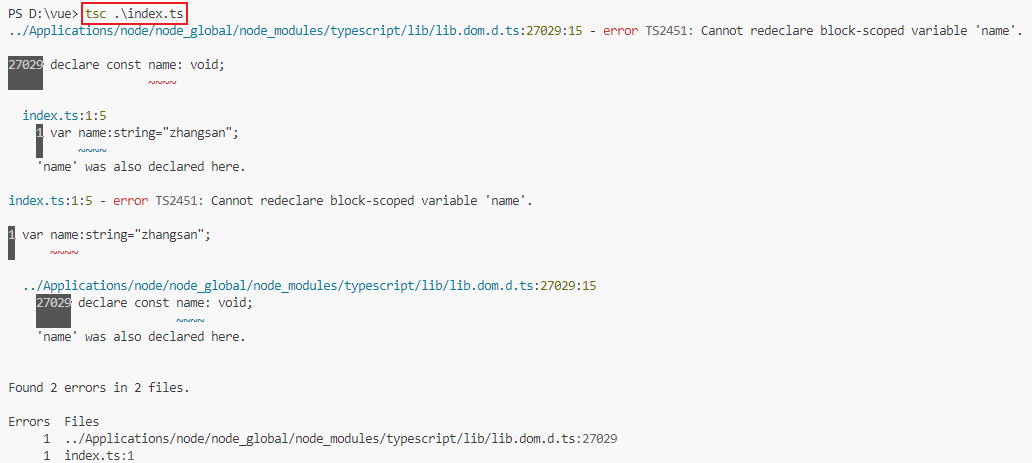
typescript报错:‘name‘ was also declared here
问题再现 用 Typescript 时, 遇到一个声明常量 name 的报错。代码如下: let name:string"zhangsan"; let num:number1001;执行编译时报错: 原因 在默认状态下,typescript 将 DOM typings 作为全局的运行环境&#…...

第十章:联邦学习视觉案例
代码 传送门...
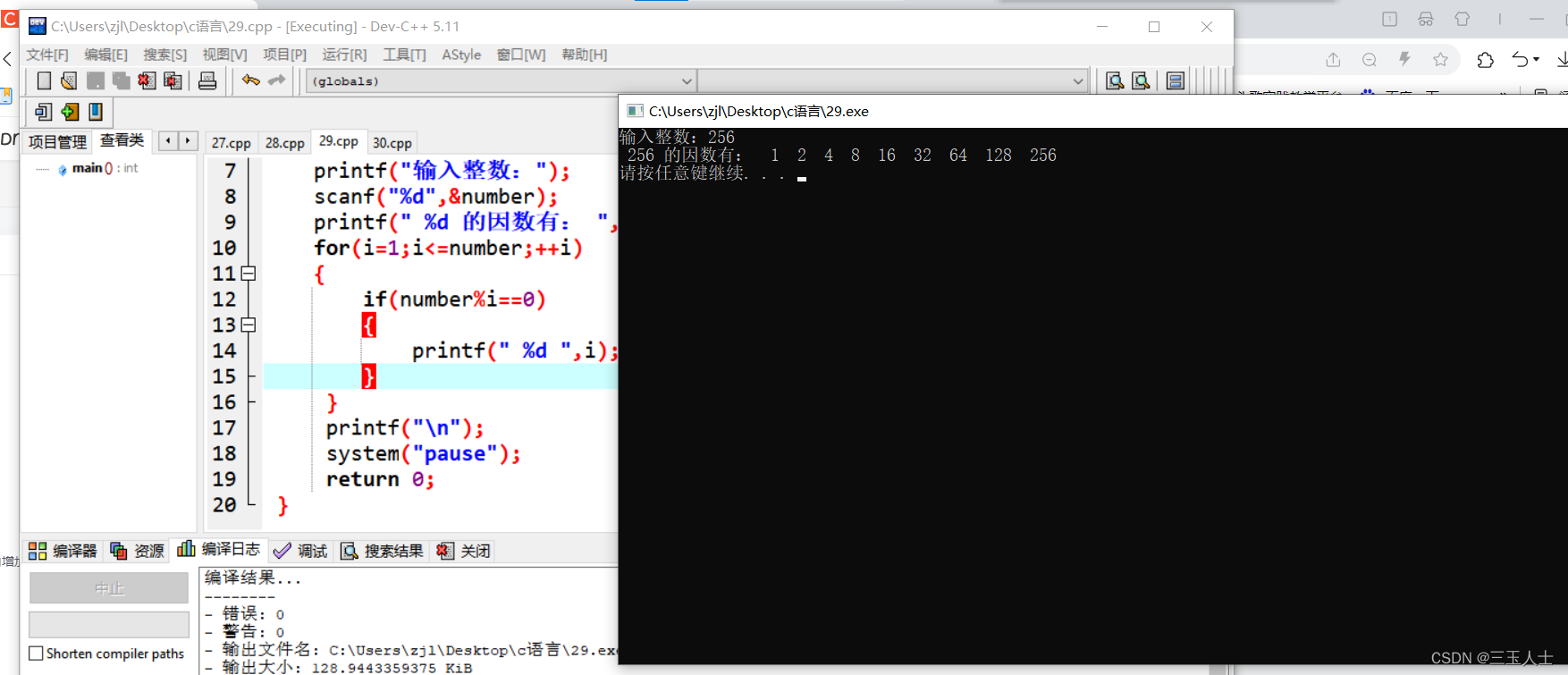
c语言——输出一个整数的所有因数
//输出一个整数的所有因数 #include<stdio.h> #include<stdlib.h> int main() {int number,i;printf("输入整数:");scanf("%d",&number);printf(" %d 的因数有: ",number);for(i1;i<number;i){if(numb…...
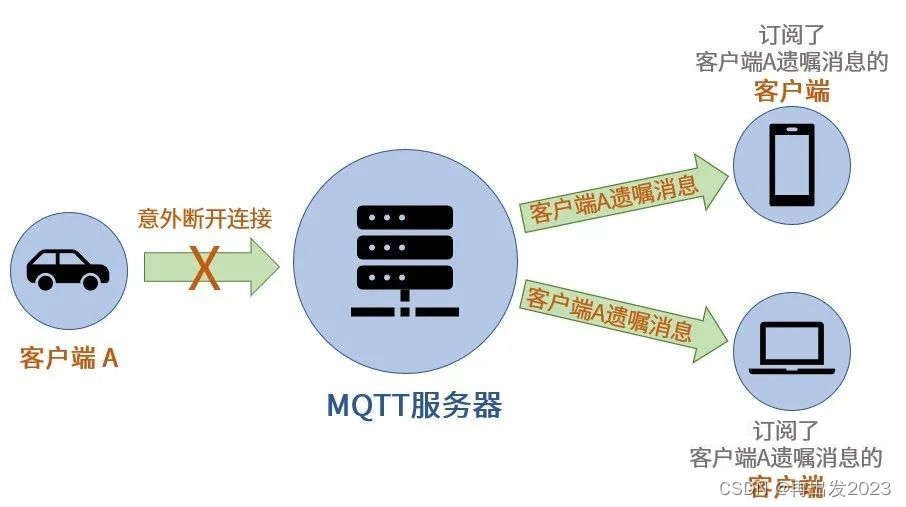
mqtt学习记录
目录 1 匿名登录2 ⽤户名密码登录,配置接收的主题mosquitto 配置文件修改添加⽤户信息添加topic和⽤户的关系登录演示 3 遗嘱机制 1 匿名登录 ⾸先打开三个终端, 启动代理服务:mosquitto -v -v 详细模式 打印调试信息 默认占⽤:…...

爬虫逆向实战(十八)--某得科技登录
一、数据接口分析 主页地址:某得科技 1、抓包 通过抓包可以发现数据接口是AjaxLogin 2、判断是否有加密参数 请求参数是否加密? 查看“载荷”模块可以发现有一个password加密参数和一个__RequestVerificationToken 请求头是否加密? 无…...
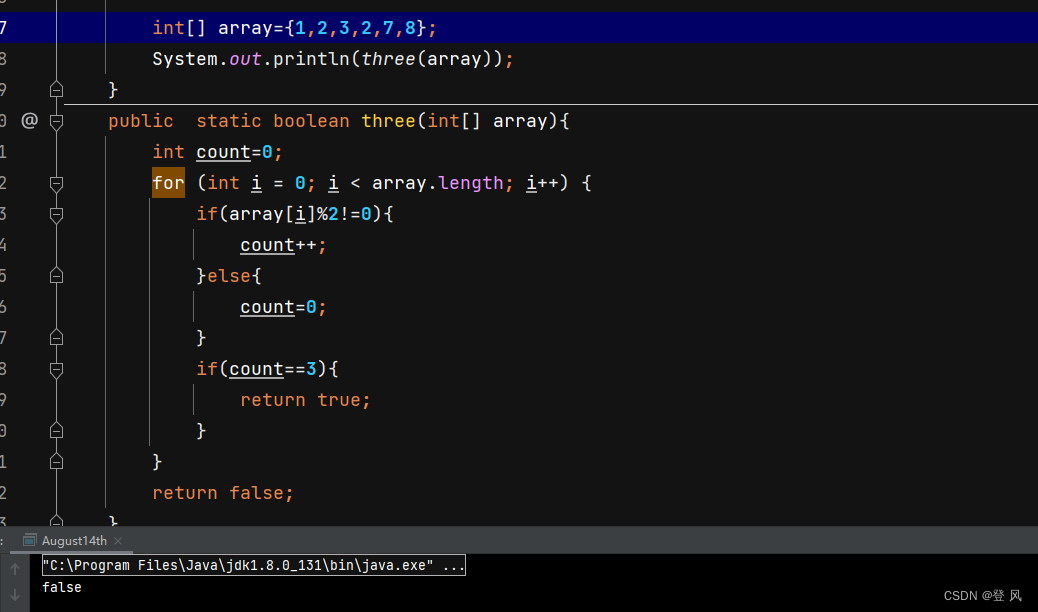
Java-数组
什么是数组 数组:可以看成是相同类型元素的一个集合。在内存中是一段连续的空间。 在java中, 数组中存放的元素其类型相同数组的空间是连在一起的每个空间有自己的编号,起始位置的编号为0,即数组的下标。 数组的创建及初始化 数…...
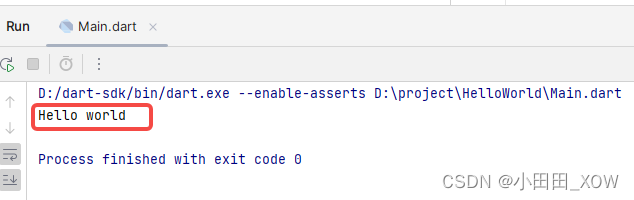
Dart 入门Hello world
1、下载Dart sdk IntelliJ & Android Studio | Dart 2、安装Dart 插件 3、安装后重启IDEA,创建Dart项目 4、创建dart文件 5、编写函数: void main() {print("Hello world"); } 6、运行: 官网学习:Dart 语言开发文…...

HTML是什么?
HTML是什么? 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。 您可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器…...

【UniApp开发小程序】商品详情展示+评论、评论展示、评论点赞+商品收藏【后端基于若依管理系统开发】
文章目录 界面效果界面实现工具js页面日期格式化 后端收藏ControllerServicemapper 评论ControllerServiceMapper 商品Controller 阅读Service 界面效果 【说明】 界面中商品的图片来源于闲鱼,若侵权请联系删除 【商品详情】 【评论】 界面实现 工具js 该工…...

OpenClaw Exec Approvals 机制:在安全与效率之间寻找平衡
OpenClaw Exec Approvals 机制:在安全与效率之间寻找平衡当你第一次看到 /approve 弹窗时,是选择 allow-once 还是 allow-always?这个看似简单的决定,背后是安全与便利的永恒博弈。引言 在 Agent 开发和工作流自动化的世界里&…...

零基础入门AI开发:在快马平台亲手制作你的第一个口播智能体
最近在尝试入门AI开发,发现用InsCode(快马)平台做"旗博士口播智能体"特别适合零基础选手。这个项目不需要自己从头写代码,但能完整走通AI应用开发全流程,分享下我的学习笔记: 项目整体结构 整个项目分三部分:…...
集成方案)
PyTorch 2.8镜像实战落地:教育机构AI教学平台(图文+视频+LLM)集成方案
PyTorch 2.8镜像实战落地:教育机构AI教学平台(图文视频LLM)集成方案 1. 教育AI平台的技术挑战与解决方案 现代教育机构在构建AI教学平台时面临三大技术难题:多模态内容生成、算力资源管理和教学场景适配。PyTorch 2.8深度学习镜…...

Go性能剖析pprof工具使用
Go语言凭借其高效的并发模型和简洁的语法,成为众多开发者的首选。随着项目规模扩大,性能问题逐渐显现。如何快速定位性能瓶颈?Go内置的pprof工具正是解决这一问题的利器。本文将带你深入了解pprof的核心功能,助你轻松优化代码性能…...

别再傻傻分不清HIL和SIL了!用NI PXI和Simulink手把手教你搭建第一个测试环境
从零开始搭建HIL/SIL测试环境:NI PXI与Simulink实战指南 刚接触在环测试的工程师常常被各种术语搞得晕头转向——HIL、SIL、MIL,它们到底有什么区别?更重要的是,接到一个控制器测试任务时,该如何从零开始搭建测试环境&…...

Klipper温度曲线优化终极指南:三步解决95%打印质量问题
Klipper温度曲线优化终极指南:三步解决95%打印质量问题 【免费下载链接】klipper Klipper is a 3d-printer firmware 项目地址: https://gitcode.com/GitHub_Trending/kl/klipper 你是否曾为PLA打印翘边、ABS层间开裂或PETG拉丝问题而烦恼?这些问…...

一篇文章彻底搞懂Linux驱动的并发控制与中断上下半部机制
在嵌入式 Linux 驱动开发中,并发控制与中断处于极其重要的核心地位。本文,我将结合 CPU 的行为与操作系统的调度,深入分析 spinlock 和 mutex 的本质区别,以及 Linux 中断上下半部。1. 上下文的概念 在深入探究锁和中断之前&#…...

R Markdown网站生成器使用教程:如何快速搭建技术文档网站 [特殊字符]
R Markdown网站生成器使用教程:如何快速搭建技术文档网站 📊 【免费下载链接】rmarkdown Dynamic Documents for R 项目地址: https://gitcode.com/gh_mirrors/rm/rmarkdown R Markdown是一个强大的动态文档生成工具,能够将代码、输出…...

Stable Diffusion v1.5功能体验:Guidance Scale参数实测,教你调出最佳效果
Stable Diffusion v1.5功能体验:Guidance Scale参数实测,教你调出最佳效果 1. 引言:为什么Guidance Scale如此重要? 如果你用过Stable Diffusion生成图片,一定遇到过这样的情况:同样的提示词,…...

实战指南|OpenWrt磁盘扩容全流程解析与避坑技巧
1. 为什么需要给OpenWrt扩容? 很多朋友第一次接触OpenWrt时都会遇到一个尴尬的问题:系统默认分配的存储空间太小了。我自己刚开始用OpenWrt时也踩过这个坑,当时想装个Docker跑点服务,结果发现连最基本的镜像都拉不下来。这就像给…...