mongodb使用心得
入门
术语
collection:相当于db的表
document:相当于表的记录
启动
单机模式启动mongo server
mongod --dbpath D:\programs\mongodb-4.2.8\data\db
replica set模式启动
replica set模式其实就是主从模式。
做mongo的启动配置文件:
storage:dbPath: D:\programs\mongodb-4.2.8\data\db1 journal:enabled: true
# where to write logging data.
systemLog:destination: filelogAppend: truepath: D:\programs\mongodb-4.2.8\log\mongo1.log
# network interfaces
net:port: 27018bindIp: 127.0.0.1注意:dbPath和systemLog文件夹要事先建好!
将mongo安装为windows服务:
mongod --config D:\programs\mongodb-4.2.8\config\mongo1.config --serviceName "MongoDB27018" --serviceDisplayName "MongoDB27018" --replSet "myRepl" --install
在任务管理器里手工启动之即可。
类似的,安装并启动复制集里的另外2个节点:
mongod --config D:\programs\mongodb-4.2.8\config\mongo2.config --serviceName "MongoDB27019" --serviceDisplayName "MongoDB27019" --replSet "myRepl" --install
mongod --config D:\programs\mongodb-4.2.8\config\mongo3.config --serviceName "MongoDB27020" --serviceDisplayName "MongoDB27020" --replSet "myRepl" --install
测试3个节点是否正常启动:
mongo --host 127.0.0.1 --port 27018
mongo --host 127.0.0.1 --port 27019
mongo --host 127.0.0.1 --port 27020
在任一节点配置复制集(这一步会分出主从节点):
rs.initiate({
_id: 'myRepl',
members: [
{_id: 0, host: '127.0.0.1:27018'},
{_id: 1, host: '127.0.0.1:27019'},
{_id: 2, host: '127.0.0.1:27020'}]
})
查看复制集状态:
rs.status()
返回结果:
"members" : [{"_id" : 0,"name" : "127.0.0.1:27018","health" : 1,"state" : 1,"stateStr" : "PRIMARY",...},{"_id" : 1,"name" : "127.0.0.1:27019","health" : 1,"state" : 2,"stateStr" : "SECONDARY",...},{"_id" : 2,"name" : "127.0.0.1:27020","health" : 1,"state" : 2,"stateStr" : "SECONDARY",...}
从结果里的stateStr字段可以看出,27018那个节点为主节点,其它两个节点为从节点。
如果我们把主节点down掉,很快就发现,27019被选为主节点。我们接着将27019也停掉,这个时候仅剩的1个节点27020节点就没法被选为主了,因为没达到半数以上(3个节点的半数为2)。
常用命令
连接mongo server
直接执行:
mongo
如果连接的是复制集里的从节点,在执行正式命令前,要先执行:
rs.slaveOk();
才可用。
创建数据库
use testdb;
即可。
表的增删改查
#建表
db.createCollection("t_test")#删表
db.t_test.drop()#插入记录
db.t_test.insert([{"id":1, "name":"lip", "age":400},{"id":2, "name":"yibb", "age":100}])# 查询,select * from t_test where id = 1
db.t_test.find({id:1})# select * from t_test where id > 0 and id < 10
db.t_test.find({id: {$gt:0, $lt:10}})# update t_test set age=40 where id=1
db.t_test.update({id:1}, {$set : {age: 40}})
索引
# 获得表的索引
db.t_test.getIndexes()# 对id列创建唯一索引,后续插入如有重复,mongo会报错:dup key
db.t_test.ensureIndex({"id":1},{"unique":true})
db.t_test.createIndex({"id":1},{"unique":true})
oplog查看
oplog在local库里,使用如下命令查看:
use local;
db.oplog.rs.find({"ns":"testdb.t_test"});
ns由“库名.集合名”组成。
结果形如:
{ "ts" : Timestamp(1653546445, 2), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "i", "ns" : "testdb.t_test", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T06:27:25.772Z"), "o" : { "_id" : ObjectId("628f1dcd6b0c17818fe022ba"), "id" : 1, "name" : "liping", "age" : 40 } }
{ "ts" : Timestamp(1653546445, 3), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "i", "ns" : "testdb.t_test", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T06:27:25.772Z"), "o" : { "_id" : ObjectId("628f1dcd6b0c17818fe022bb"), "id" : 2, "name" : "yibei", "age" : 10 } }
{ "ts" : Timestamp(1653548898, 1), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "u", "ns" : "testdb.t_test", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "o2" : { "_id" : ObjectId("628f1dcd6b0c17818fe022ba") }, "wall" : ISODate("2022-05-26T07:08:18.482Z"), "o" : { "$v" : 1, "$set" : { "age" : 45 } } }
{ "ts" : Timestamp(1653549802, 1), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "d", "ns" : "testdb.t_test", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T07:23:22.075Z"), "o" : { "_id" : ObjectId("628f1dcd6b0c17818fe022ba") } }
{ "ts" : Timestamp(1653549802, 2), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "d", "ns" : "testdb.t_test", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T07:23:22.075Z"), "o" : { "_id" : ObjectId("628f1dcd6b0c17818fe022bb") } }
我们先后插入2条记录,更新1条记录,再删除2条记录。
op=i表示insert
op=u表示update
op=d表示delete
特别的,如果我们对集合建索引,生成的oplog为:
{ "ts" : Timestamp(1653546434, 1), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "c", "ns" : "testdb.$cmd", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T06:27:14.938Z"), "o" : { "create" : "t_test", "idIndex" : { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "testdb.t_test" } } }
{ "ts" : Timestamp(1653548658, 2), "t" : NumberLong(1), "h" : NumberLong(0), "v" : 2, "op" : "c", "ns" : "testdb.$cmd", "ui" : UUID("761a9204-fac7-41f1-950b-34e0b9cd0a95"), "wall" : ISODate("2022-05-26T07:04:18.922Z"), "o" : { "createIndexes" : "t_test", "v" : 2, "unique" : true, "key" : { "id" : 1 }, "name" : "id_1" } }
其中,第一条是mongo自动为我们建的_id索引,第二条的id索引是我们自己建的。建索引的op=c
上述结果可用:
db.oplog.rs.find({"ns":"testdb.$cmd"});
命令获得。
事务
mongo里单文档的增删改都是原子性的,无需事务。
事务针对的是多文档的原子性。一个典型的操作是字段自增,要先读出当前值,再自增。这种原子性只能用事务来保证。
单机mongo不支持事务。只有sharding cluster和replica set模式才支持事务。
一个事务的例子:
session = db.getMongo().startSession( { readPreference: { mode: "primary" } } );
testCollection = session.getDatabase("testdb").t_test;
session.startTransaction( { readConcern: { level: "snapshot" }, writeConcern: { w: "majority" } } );
try {testCollection.updateOne( { id: 1 }, { $set: { age: 53 } } );testCollection.insertOne( {"id":2, "name":"xixi", "age":20} );
} catch (error) {session.abortTransaction();throw error;
}
session.commitTransaction();
session.endSession();MongoDB的应用场景
1)表结构不明确且数据不断变大
MongoDB是非结构化文档数据库,扩展字段很容易且不会影响原有数据。内容管理或者博客平台等,例如圈子系统,存储用户评论之类的。
2)更高的写入负载
MongoDB侧重高数据写入的性能,而非事务安全,适合业务系统中有大量“低价值”数据的场景。本身存的就是json格式数据。例如做日志系统。
3)数据量很大或者将来会变得很大
Mysql单表数据量达到5-10G时会出现明显的性能降级,需要做数据的水平和垂直拆分、库的拆分完成扩展,MongoDB内建了sharding、多数据分片的特性,容易水平扩展,比较好的适应大数据量增长的需求。
4)高可用性
自带高可用,自动主从切换(replica set模式)
不适用的场景:
MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
进阶
mongodb vs mysql
一些结论:
与ES一样,mongodb也有所谓分片和replica。
mongodb的分片(以及ES的索引分片),就类似于MySQL的分库分表,只不过mysql的分库分表需要手工做,mongodb和ES则自动为我们做了分片。
mongodb的replica,类似于mysql的主从(可以是一主多从)。一般来说,MongoDB将有关联的数据存储在一起(内嵌文档),所以很多操作不像MySQL,需要做多表的关联操作。
MongoDB的内嵌模型可以给应用程序提供很好的数据查询性能,因为基于内嵌模型,可以通过一次数据库操作得到所有相关的数据。同时,内嵌模型可以使数据更新操作变成一个原子写操作。然而,内嵌模型也可能引入一些问题,比如说文档会越来越大,这样就可能会影响数据库写操作的性能,还可能会产生数据碎片(data fragmentation)。
MongoDB数据类型丰富,查询功能强大,还有文本搜索功能和地理空间计算,强大的数据分析和统计能力。
缺点:没有join ,连表操作能力弱,所以在复杂查询时,还是关系型数据库更胜一筹。MongoDB在内存充足的情况下数据都放在内存且有完整的索引支持,查询效率较高。人们有时把mongodb跟redis对比就是因为此点。
索引创建过程
mongodb为提高查询效率,也要建索引,避免全表扫描。
索引创建过程中锁的使用情况,4.2+版本不会在索引创建过程中锁表。参见文章
readConcern和writeConcern
writeConcern是确定写入时需要写入几个节点的配置,格式为:
{ w: <value>, j: <boolean>, wtimeout: <number> }
其中:
w=1就是主节点确认即可,这是默认值。
w=2代表需要两个节点确认
w=majority代表需要大多数节点确认,2/3
writeConcern在w>1的时候可以设置超时时间j:指定写入请求是否确认已写入磁盘预写日志。true时会确保写入操作已经写入w指定数量节点的预写日志中。wtimeout:指定写入操作超时时间(毫秒)。
readConcern是读取数据的选项,有如下几种:
local:当前实例读取。查询从当前实例返回的数据不保证数据已写入大多数副本集成员(可能因故障而回滚)。当读偏好为primary或者读偏好为secondary但因果一致性为true时,默认值为“local”。available:任一可得的实例返回。查询从实例返回的数据不保证数据已写入大多数副本集成员(可能因故障而回滚)。当读偏好为secondary且因果一致性为false时,默认值为“available”。也就是说,available仅针对readPreference=secondary有意义。majority:查询返回已被大多数副本集成员确认的数据。读取操作返回的数据是持久的,即使发生故障也是如此。为了满足读取关注“majority”,副本集成员在majority提交点从其内存数据视图快照返回数据。因此,读取关注 "majority"在性能成本上与其他读取关注相当,并不会有过高代价。需注意:仅当事务写关注也为“majority”时,读关注“majority”才提供数据保证。linearizable: 查询返回在读操作开始之前完成的所有成功的majority确认写入数据。如遇并发执行的写入操作,查询动作会挂住等待写入传播到多数副本集后再返回结果。所谓线性,指的是写-读是顺序发生的。读取操作后如果多数副本集崩溃重启,此时如果writeConcernMajorityJournalDefault默认为true,则数据保证持久。如果writeConcernMajorityJournalDefault设为false,则写关注“majority”可能回滚。对于因果一致性的会话和事务,linearizable不可用;读偏好为primary时,可设置读关注linearizable;snapshot:如果事务要求因果一致性,在事务提交时写关注"majority",则保证事务操作从多数提交的数据的快照中读取,且结果保证与事务开始之前数据的因果一致性相同。 如果事务不要求因果一致性,在事务提交时写关注"majority",则保证事务操作从多数提交的数据的快照中读取。
在事务下,readConcern仅支持local、majority、snapshot三种级别。
需要特别指出的是:
readConcern=majority选项主要解决脏读问题,比如用户从 MongoDB 的 primary 上读取了某一条数据,但这条数据并没有同步到大多数节点,然后 primary 就故障了,重新恢复后 这个primary 节点会将未同步到大多数节点的数据回滚掉,导致用户读到了『脏数据』
另外readConcern 能保证读到的数据『不会发生回滚』,但并不能保证读到的数据是最新的,这个官网上也有说明:
Regardless of the read concern level, the most recent data on a node may not reflect the most recent version of the data in the system.
有用户误以为,readConcern 指定为 majority 时,客户端会从大多数的节点读取数据,然后返回最新的数据。
实际上并不是这样,无论何种级别的 readConcern,客户端都只会从『某一个确定的节点』(具体是哪个节点由 readPreference 决定)读取数据,该节点根据自己看到的同步状态视图,只会返回已经同步到大多数节点的数据。
注意:无论readConcern还是writeConcern,影响的是mongodb所有的读写行为,而不仅仅是事务!
readPreference
MongoDB driver支持以下几种read-reference:
primary:默认模式,一切读操作都路由到replica set的primary节点primaryPreferred:正常情况下都是路由到primary节点,只有当primary节点不可用(failover)的时候,才路由到secondary节点。secondary:一切读操作都路由到replica set的secondary节点secondaryPreferred:正常情况下都是路由到secondary节点,只有当secondary节点不可用的时候,才路由到primary节点。nearest:从延时最小的节点读取数据,不管是primary还是secondary。对于分布式应用且MongoDB是多数据中心部署,nearest能保证最好的data locality。如果使用secondary或者secondaryPreferred,那么需要意识到:
(1) 因为延时,读取到的数据可能不是最新的,而且不同的secondary返回的数据还可能不一样;
(2) 对于默认开启了自动数据均衡的sharded collection,由于还未结束或者异常终止的chunk迁移,secondary返回的可能是有缺失或者多余的数据
(3) 在有多个secondary节点的情况下,选择哪一个secondary节点呢,简单来说是“closest”即平均延时最小的节点,具体参见Server Selection Algorithm
相关文章:

mongodb使用心得
入门 术语 collection:相当于db的表 document:相当于表的记录 启动 单机模式启动mongo server mongod --dbpath D:\programs\mongodb-4.2.8\data\dbreplica set模式启动 replica set模式其实就是主从模式。 做mongo的启动配置文件: …...

学习Vue:响应式原理与性能优化策略
性能优化是Vue.js应用开发中的一个关键方面,而深入了解响应式原理并采用有效的性能优化策略可以显著提升应用的性能。本文将解释响应式原理并介绍一些性能优化策略,旨在帮助您构建高性能的Vue.js应用。 响应式原理 Vue.js的响应式原理是通过利用Object.…...

神经网络基础-神经网络补充概念-43-梯度下降法
概念 梯度下降法(Gradient Descent)是一种优化算法,用于在机器学习和深度学习中最小化(或最大化)目标函数。它通过迭代地调整模型参数,沿着梯度方向更新参数,以逐步接近目标函数的最优解。梯度…...

Reids之Set类型解读
目录 基本介绍 命令概述 SADD key member1 [member2] SCARD key SINTER key1 [key2] SMEMBERS key SPOP key SUNION key1 [key2] 基本介绍 新的存储需求:存储大量的数据 在查询方面提供更高的效率需要的存储结构:能够保存大量的数据&#x…...

【网络基础】数据链路层
【网络基础】数据链路层 文章目录 【网络基础】数据链路层1、对比网络层2、以太网2.1 基本概念2.2 类似技术2.3 以太网帧 3、MAC地址对比IP地址 4、MTU4.1 对IP协议影响4.2 对UDP协议影响4.3 对TCP协议影响4.4 地址、MTU查看 5、ARP协议5.1 协议作用5.2 协议工作流程5.3 数据报…...
云计算|OpenStack|使用VMware安装华为云的R006版CNA和VRM---初步使用(二)
前言: 在前面一篇文章云计算|OpenStack|使用VMware安装华为云的R006版CNA和VRM---初始安装(一)_华为cna_晚风_END的博客-CSDN博客 介绍了基于VMware虚拟机里嵌套部署华为云的云计算,不过仅仅是做到了在VRM的web界面添加计算节点…...

Python typing函式庫和torch.types
Python typing函式庫和torch.types 前言typingSequence vs IterableCallableUnionOptionalFunctionsCallableIterator/generator位置參數 & 關鍵字參數 Classesself自定義類別ClassVar\_\_setattr\_\_ 與 \__getattr\_\_ torch.typesbuiltins 參數前的* …...

UE5 编程规范
官方文档 使用现代C编程标准, 使用前沿C标准库版本. 1. 类中按照先 Public 后 Private 去写 2. 继承自 UObject 的类都以 U 前缀 3. 继承自 AActor 的类都以 A 前缀 4. 继承自 SWidget 的类都以 S 前缀 5. 模板以 T 前缀 6. 接口以 I 前缀 7. 枚举以 E 前缀 8. 布尔值…...
交互消息式IMessage扩展开发记录
IMessage扩展简介 iOS10新加入的基于iMessage的应用扩展,可以丰富发送消息的内容。(分享表情、图片、文字、视频、动态消息;一起完成任务或游戏。) 简单的将发送的数据内型分为三种: 1.贴纸Stickers; 2.交…...

软件团队降本增效-建立需求评估体系
需求对于软件开发来说是非常重要的输入,它们直接决定了软件的产品形态、代码数量和质量。如果需求不清晰、不完善,或者存在逻辑冲突,将会导致软件质量迅速下降,增加代码耦合性和开发成本。 在开发过程中,对需求的产品…...

npm yarn pnpm 命令集
npm 安装依赖 npm install 安装某个依赖 npm install xxx7.6.3 安装到全局(dependencies) npm install xxx7.6.3 -S 安装到线下(devDependencies) npm install xxx7.6.3 -D 卸载某个依赖 npm uninstall xxx 卸载全局依…...
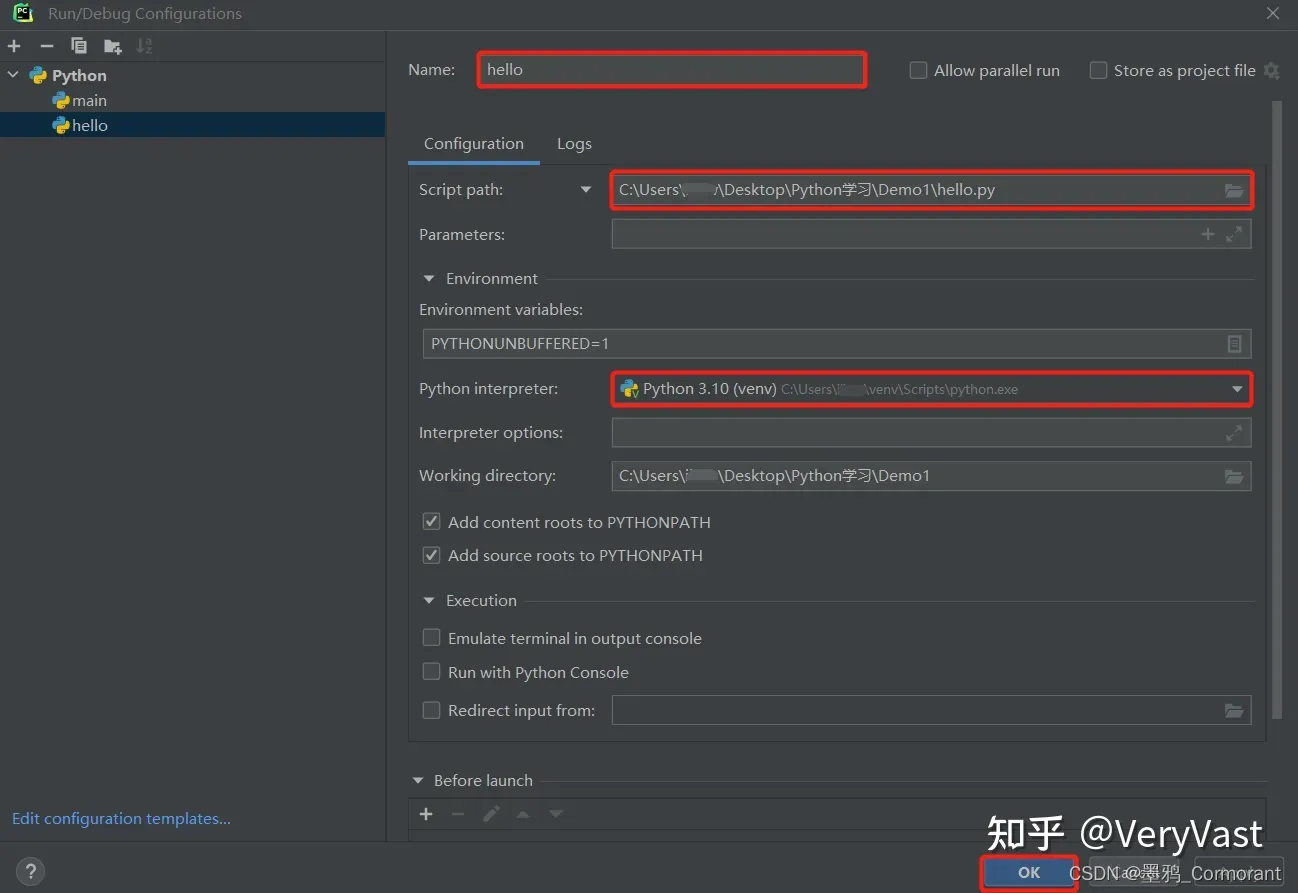
python 开发环境(PyCharm)搭建指南
Python 的下载并安装 参考:Python基础教程——搭建Python编程环境 下载 Python Python 下载地址:官网 (1)点击【Downloads】>>>点击【Windows】>>>点击【Python 3.x.x】下载最新版 Python; Pyt…...
springboot里 运用 easyexcel 导出
引入pom <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.2.6</version> </dependency>运用 import com.alibaba.excel.EasyExcel; import org.springframework.stereotype.Contr…...

一“码”当先,PR大征集!2023 和RT-Thread一起赋能开源!
活动地址:https://club.rt-thread.org/ask/article/3c7cf7345ca47a18.html 活动介绍 「一“码”当先,PR大征集!」是一项为了鼓励开发者积极参与开源软件开发维护的活动。 你可在Github RT-Thread( https://github.com/RT-Thread …...
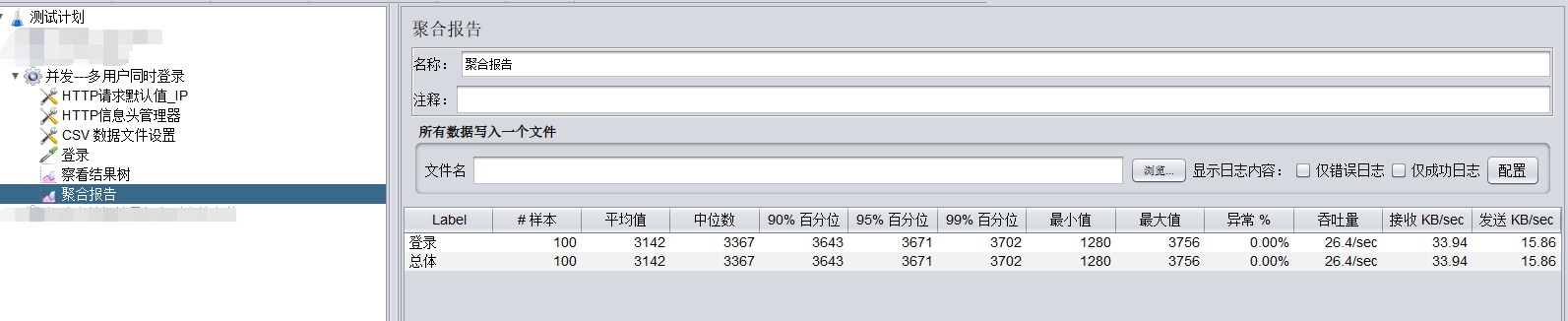
jmeter模拟多用户并发
一、100个真实的用户 1、一个账号模拟100虚拟用户同时登录和100账号同时登录 区别 (1)1个账号100个人用,同时登录; (2)100个人100个账号,同时登录。 相同 (1)两个都…...

澎峰科技|邀您关注2023 RISC-V中国峰会!
峰会概览 2023 RISC-V中国峰会(RISC-V Summit China 2023)将于8月23日至25日在北京香格里拉饭店举行。本届峰会将以“RISC-V生态共建”为主题,结合当下全球新形势,把握全球新时机,呈现RISC-V全球新观点、新趋势。 本…...
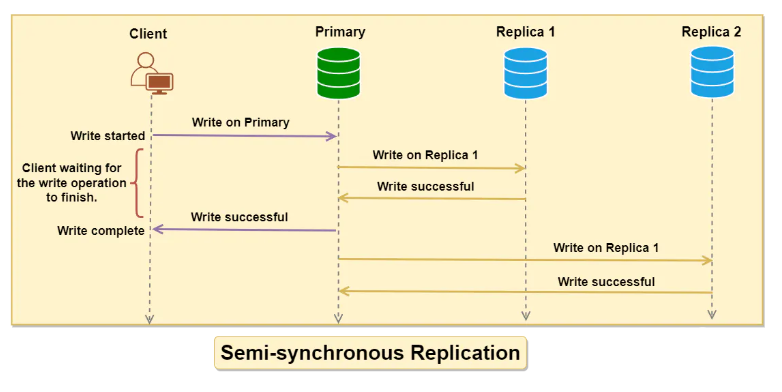
【系统架构】系统架构设计之数据同步策略
文章目录 一、介绍1.1、分布式系统中的数据同步定义1.2、为何数据同步如此关键1.3、数据同步策略简介 二、为什么需要数据同步2.1、提高系统可用性2.2、备份与灾难恢复2.3、提高性能2.4、考虑地理位置(如使用CDN) 三、同步备份3.1、定义和概述3.2、工作原…...

Linux内核学习笔记——ACPI命名空间
所有定义块都加载到单个命名空间中。命名空间 是由名称和路径标识的对象层次结构。 以下命名约定适用于 ACPI 中的对象名称 命名空间: 所有名称的长度均为 32 位。 名称的第一个字节必须是“A”-“Z”、“_”之一。 名称的每个剩余字节必须是“A”-“Z”、“0”之…...

使用 OpenCV Python 实现自动图像注释工具的详细步骤--附完整源码
注释是深度学习项目中最关键的部分。它是模型学习效果的决定因素。然而,这是非常乏味且耗时的。一种解决方案是使用自动图像注释工具,这大大缩短了时间。 本文是pyOpenAnnotate系列的一部分,其中包括以下内容。 1、使用 OpenCV 进行图像注释的路线图。 2、pyOpenAnnotate工…...
RunnerGo中WebSocket、Dubbo、TCP/IP三种协议接口测试详解
大家好,RunnerGo作为一款一站式测试平台不断为用户提供更好的使用体验,最近得知RunnerGo新增对,WebSocket、Dubbo、TCP/IP,三种协议API的测试支持,本篇文章跟大家分享一下使用方法。 WebSocket协议 WebSocket 是一种…...

崩坏星穹铁道模拟宇宙自动化终极指南:如何轻松实现全自动刷图
崩坏星穹铁道模拟宇宙自动化终极指南:如何轻松实现全自动刷图 【免费下载链接】Auto_Simulated_Universe 崩坏:星穹铁道 模拟宇宙自动化 (Honkai Star Rail - Auto Simulated Universe) 项目地址: https://gitcode.com/gh_mirro…...
南方医科大学南方医院北京协和医院等团队:基于PET/CT的深度学习预测食管癌PD-L1与免疫疗效)
Eur J Nucl Med Mol Imaging(IF=7.6)南方医科大学南方医院北京协和医院等团队:基于PET/CT的深度学习预测食管癌PD-L1与免疫疗效
01文献学习今天分享的文献是由南方医科大学南方医院联合西安电子科技大学、北京协和医院等团队于2025年8月在《European Journal of Nuclear Medicine and Molecular Imaging》(中科院1区,IF7.6)上发表的研究“Deep learning-based non-invas…...

深度挖掘显卡潜能:NVIDIA Profile Inspector 高级调优完全指南
深度挖掘显卡潜能:NVIDIA Profile Inspector 高级调优完全指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经对NVIDIA控制面板中有限的设置选项感到不够用?是否想要…...

从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学
从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学 当你从硬盘拷贝一个10GB的电影文件到内存时,系统监控显示CPU占用率几乎没变化——这似乎违背直觉。难道CPU真的在"摸鱼"?实际上,这背后…...
的记忆(被教训就变好了))
AI (S-44)的记忆(被教训就变好了)
自建认知架构项目,以下为记录🧑 用户: 我们前天说过什么?昨天说过什么?今天说过什么?你要是捣乱,拉二胡的大爷会干什么呢?🔧 进度: 工具执行 (13/16): get_ch…...

抖音下载器终极指南:3分钟学会免费下载无水印视频和音乐
抖音下载器终极指南:3分钟学会免费下载无水印视频和音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback sup…...

Cesium 体积光阴影率分析和阴影体渲染效果
Cesium 体积光阴影率分析和阴影体渲染效果 在传统的 GIS 日照分析中,当分析对象扩展到高层建筑时,阴影在空中随着时间推移形成的“三维空间漏斗”才是数据的全貌。 为了在前端实现这种影视级的三维体积阴影分析(Volumetric Shadow Analysis…...

终极指南:如何用Tinke轻松提取和修改任天堂NDS游戏资源
终极指南:如何用Tinke轻松提取和修改任天堂NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 还在为无法访问NDS游戏内部资源而烦恼吗?Tinke是一款免费开源的NDS…...
)
告别DHT11!用3.5元的AHT10和STC8单片机,做个更小巧的桌面温湿度计(附完整源码)
3.5元AHT10温湿度传感器实战:用STC8打造迷你桌面环境监测仪 在智能家居和创客项目中,温湿度传感器一直是基础但关键的组件。传统DHT11虽然价格低廉,但其较大的体积和相对落后的性能指标,越来越难以满足现代小型化设备的需求。今天…...

解锁网易云音乐NCM格式:让加密音乐重获自由的完整指南
解锁网易云音乐NCM格式:让加密音乐重获自由的完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾在网易云音乐下载了心爱的歌曲,却发现在其他播放器上无法播放?这种困扰源于网易云音…...