[oneAPI] 基于BERT预训练模型的命名体识别任务
[oneAPI] 基于BERT预训练模型的命名体识别任务
- Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
- 基于BERT预训练模型的命名体识别任务
- 语料介绍
- 数据集构建
- 使用示例
- 命名体识别模型
- 前向传播
- 模型训练
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
在本次实验中,我们在Intel® DevCloud for oneAPI上搭建实验,借助完全虚拟化的环境,专注于模型开发与优化,无需关心底层配置。使用Intel® Optimization for PyTorch,对PyTorch模型进行高效优化。
我们充分发挥了PyTorch和Intel® Optimization for PyTorch的强大功能,经过仔细的优化和拓展。这些优化措施极大地提升了PyTorch在各种任务中的性能,尤其是在英特尔硬件上的表现更为卓越。通过这些优化方法,我们的模型在训练和推断过程中变得更加敏捷高效,大幅缩短了计算时间,从而提升了整体效率。借助深度融合硬件与软件的巧妙设计,我们成功地释放了硬件潜力,使模型的训练和应用变得更加迅速高效。这些优化举措为人工智能应用开辟了崭新的前景,带来了全新的可能性。
基于BERT预训练模型的命名体识别任务
基于BERT预训练模型的第五个下游任务场景,即如何完成命名体识别(Named Entity Recognition, NER)任务。所谓命名体指的是给模型输入一句文本,最后需要模型将其中的实体(例如人名、地名、组织等等)标记出来。
1 句子:涂伊说,如果有机会他想去黄州赤壁看一看!
2 标签:['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O']
3 实体:涂伊(人名)、黄州(地名)、赤壁(地名)
通常来讲,对于任意一个NLP任务来说模型最后所要完成的基本上都是一个分类任务,尽管表面上看起来可能不太像。根据给出的标签来看,对于原始句子中的每个字符来说其都有一个对应的类别标签,因此对于NER任务来说只需要对原始句子里的每个字符进行分类即可,然后再将预测后的结果进行后处理便能够得到句子从存在的相应实体。
原始数据输入为一个句子,我们只需要在句子的首尾分别加上[CLS]和[SEP],然后输入到模型当中进行特征提取并最终通过一个分类层对输出的每个Token进行分类即可,最后只需要对各个Token的预测结果进行后处理便能够实现整个NER任务。
语料介绍
一个中文命名体识别数据集https://github.com/zjy-ucas/ChineseNER,如下所示便是原始数据的存储形式:
1 涂 B-PER2 伊 I-PER3 说 O4 , O5 如 O6 果 O7 有 O8 机 O9 会 O
10 他 O
11 想 O
12 去 O
13 黄 B-LOC
14 州 I-LOC
15 赤 B-LOC
16 壁 I-LOC
17 看 O
18 一 O
19 看 O
20 !O
其中每一行包含一个字符和其对应的所属类别,B-表示该类实体的开始标志,I-表示该类实体的延续标志。例如对于13-16行来说其对应了“黄州”和“赤壁”这两个实体。同时,对于这个数据集来说,其一共包含有3类实体(人名、地名和组织),因此其对应的分类总数便为7,如下所示:
1 {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}
对于数据预处理部分我们可以继续继承之前文本分类处理中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法即可。
数据集构建
在说完数据集构造的整理思路后,下面我们就来正式编码实现整个数据集的构造过程。同样,对于数据预处理部分我们可以继续继承之前文本分类处理中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法即可。
class LoadChineseNERDataset(LoadSingleSentenceClassificationDataset):def __init__(self, entities=None, num_labels=None, ignore_idx=-100, **kwargs):super(LoadChineseNERDataset, self).__init__(**kwargs)self.entities = entitiesself.num_labels = num_labelsself.IGNORE_IDX = ignore_idxif self.entities is None or self.num_labels is None:raise ValueError(f"类 {self.__class__.__name__} 中参数 entities 或 num_labels 不能为空!")@cachedef data_process(self, filepath, postfix='cache'):raw_iter = open(filepath, encoding="utf8").readlines()data = []max_len = 0tmp_token_ids = []tmp_sentence = ""tmp_label = []tmp_entity = []for raw in tqdm(raw_iter, ncols=80):line = raw.rstrip("\n").split(self.split_sep)if len(line) != 1 and len(line) != 2:raise ValueError(f"数据标注有误{line}")if len(line) == 1: # 表示得到一个完整的token id样本if len(tmp_token_ids) > self.max_position_embeddings - 2:tmp_token_ids = tmp_token_ids[:self.max_position_embeddings - 2]tmp_label = tmp_label[:self.max_position_embeddings - 2]max_len = max(max_len, len(tmp_label) + 2)token_ids = torch.tensor([self.CLS_IDX] + tmp_token_ids +[self.SEP_IDX], dtype=torch.long)labels = torch.tensor([self.IGNORE_IDX] + tmp_label +[self.IGNORE_IDX], dtype=torch.long)data.append([tmp_sentence, token_ids, labels])logging.debug(" ### 样本构造结果为:")logging.debug(f" ## 句子: {tmp_sentence}")logging.debug(f" ## 实体: {tmp_entity}")logging.debug(f" ## input_ids: {token_ids.tolist()}")logging.debug(f" ## label: {labels.tolist()}")logging.debug(f" ================================\n")assert len(tmp_token_ids) == len(tmp_label)tmp_token_ids = []tmp_sentence = ""tmp_label = []tmp_entity = []continuetmp_sentence += line[0]tmp_token_ids.append(self.vocab[line[0]])tmp_label.append(self.entities[line[-1]])tmp_entity.append(line[-1])return data, max_lendef generate_batch(self, data_batch):batch_sentence, batch_token_ids, batch_label = [], [], []for (sen, token_ids, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。batch_sentence.append(sen)batch_token_ids.append(token_ids)batch_label.append(label)batch_token_ids = pad_sequence(batch_token_ids, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len)batch_label = pad_sequence(batch_label, # [batch_size,max_len]padding_value=self.IGNORE_IDX,batch_first=False,max_len=self.max_sen_len)# ① 因为label的长度各不相同,所以同一个batch中的label需要padding到相同的长度;# ② 因为进行了padding操作,所以在计算损失的时候需要把padding部分的损失忽略掉;# ③ 又因为label中有0这个类别的存在,所以不能用词表中的PAD_IDX进行padding(PAD_IDX为0),所以要另外取一个IGNORE_IDXreturn batch_sentence, batch_token_ids, batch_labeldef make_inference_samples(self, sentences):if not isinstance(sentences, list):sentences = [sentences]data = []for sen in sentences:tokens = [self.vocab[word] for word in sen]label = [-1] * len(tokens)token_ids = torch.tensor([self.CLS_IDX] + tokens + [self.SEP_IDX], dtype=torch.long)labels = torch.tensor([self.IGNORE_IDX] + label + [self.IGNORE_IDX], dtype=torch.long)data.append([sen, token_ids, labels])return self.generate_batch(data)
使用示例
在完成数据集构造部分的相关代码实现之后,便可以通过如下所示的方式进行使用,代码如下:
class ModelConfig:def __init__(self):self.project_dir = os.path.dirname(os.path.abspath(__file__))self.dataset_dir = os.path.join(self.project_dir, 'ChineseNERdata')self.pretrained_model_dir = os.path.join(self.project_dir, "pretraining")self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')self.device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')self.train_file_path = os.path.join(self.dataset_dir, 'example_train.txt')self.val_file_path = os.path.join(self.dataset_dir, 'example_dev.txt')self.test_file_path = os.path.join(self.dataset_dir, 'example_test.txt')self.model_save_dir = os.path.join(self.project_dir, 'cache')self.model_save_name = "ner_model.pt"self.logs_save_dir = os.path.join(self.project_dir, 'logs')self.split_sep = ' 'self.is_sample_shuffle = Trueself.batch_size = 6self.max_sen_len = Noneself.epochs = 10self.learning_rate = 1e-5self.model_val_per_epoch = 2self.entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}self.num_labels = len(self.entities)self.ignore_idx = -100logger_init(log_file_name='ner', log_level=logging.DEBUG,log_dir=self.logs_save_dir)if not os.path.exists(self.model_save_dir):os.makedirs(self.model_save_dir)# 把原始bert中的配置参数也导入进来bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")bert_config = BertConfig.from_json_file(bert_config_path)for key, value in bert_config.__dict__.items():self.__dict__[key] = value# 将当前配置打印到日志文件中logging.info(" ### 将当前配置打印到日志文件中 ")for key, value in self.__dict__.items():logging.info(f"### {key} = {value}")
命名体识别模型
前向传播
我们只需要在原始BERT模型的基础上再加一个对所有Token进行分类的分类层即可,因此这部分代码相对来说也比较容易理解。首先需要在DownstreamTasks目录下新建一个BertForTokenClassification模块,并完成整个模型的初始化和前向传播过程,代码如下:
from ..BasicBert.Bert import BertModel
import torch.nn as nnclass BertForTokenClassification(nn.Module):def __init__(self, config, bert_pretrained_model_dir=None):super(BertForTokenClassification, self).__init__()self.num_labels = config.num_labelsif bert_pretrained_model_dir is not None:self.bert = BertModel.from_pretrained(config, bert_pretrained_model_dir)else:self.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier = nn.Linear(config.hidden_size, self.num_labels)self.config = configdef forward(self,input_ids=None,attention_mask=None,token_type_ids=None,position_ids=None,labels=None):""":param input_ids: [src_len,batch_size]:param attention_mask: [batch_size, src_len]:param token_type_ids::param position_ids::param labels: [src_len,batch_size]:return:"""_, all_encoder_outputs = self.bert(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids) # [batch_size,hidden_size]sequence_output = all_encoder_outputs[-1] # 取最后一层# sequence_output: [src_len, batch_size, hidden_size]sequence_output = self.dropout(sequence_output)logits = self.classifier(sequence_output)# logit: [src_len, batch_size, num_labels]if labels is not None: # [src_len,batch_size]loss_fct = nn.CrossEntropyLoss(ignore_index=self.config.ignore_idx)loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))return loss, logitselse:return logits
模型训练
对于模型训练这部分内容来说,首先我们需要在Tasks目录下新建一个TaskForChineseNER.py模块,并新建一个配置类ModelConfig来管理整个模型需要用到的参数,代码实现如下:
class ModelConfig:def __init__(self):self.project_dir = os.path.dirname(os.path.abspath(__file__))self.dataset_dir = os.path.join(self.project_dir, 'ChineseNERdata')self.pretrained_model_dir = os.path.join(self.project_dir, "pretraining")self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')self.device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')self.train_file_path = os.path.join(self.dataset_dir, 'example_train.txt')self.val_file_path = os.path.join(self.dataset_dir, 'example_dev.txt')self.test_file_path = os.path.join(self.dataset_dir, 'example_test.txt')self.model_save_dir = os.path.join(self.project_dir, 'cache')self.model_save_name = "ner_model.pt"self.logs_save_dir = os.path.join(self.project_dir, 'logs')self.split_sep = ' 'self.is_sample_shuffle = Trueself.batch_size = 6self.max_sen_len = Noneself.epochs = 10self.learning_rate = 1e-5self.model_val_per_epoch = 2self.entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}self.num_labels = len(self.entities)self.ignore_idx = -100logger_init(log_file_name='ner', log_level=logging.DEBUG,log_dir=self.logs_save_dir)if not os.path.exists(self.model_save_dir):os.makedirs(self.model_save_dir)# 把原始bert中的配置参数也导入进来bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")bert_config = BertConfig.from_json_file(bert_config_path)for key, value in bert_config.__dict__.items():self.__dict__[key] = value# 将当前配置打印到日志文件中logging.info(" ### 将当前配置打印到日志文件中 ")for key, value in self.__dict__.items():logging.info(f"### {key} = {value}")
因为在模型训练过程中需要计算相关的评价指标,如准确率、精确率和召回率等,因此需要对这部分进行实现,代码如下
def accuracy(logits, y_true, ignore_idx=-100):""":param logits: [src_len,batch_size,num_labels]:param y_true: [src_len,batch_size]:param ignore_idx: 默认情况为-100:return:e.g.y_true = torch.tensor([[-100, 0, 0, 1, -100],[-100, 2, 0, -100, -100]]).transpose(0, 1)logits = torch.tensor([[[0.5, 0.1, 0.2], [0.5, 0.4, 0.1], [0.7, 0.2, 0.3], [0.5, 0.7, 0.2], [0.1, 0.2, 0.5]],[[0.3, 0.2, 0.5], [0.7, 0.2, 0.4], [0.8, 0.1, 0.3], [0.9, 0.2, 0.1], [0.1, 0.5, 0.2]]])logits = logits.transpose(0, 1)print(accuracy(logits, y_true, -100)) # (0.8, 4, 5)"""y_pred = logits.transpose(0, 1).argmax(axis=2).reshape(-1).tolist()# 将 [src_len,batch_size,num_labels] 转成 [batch_size, src_len,num_labels]y_true = y_true.transpose(0, 1).reshape(-1).tolist()real_pred, real_true = [], []for item in zip(y_pred, y_true):if item[1] != ignore_idx:real_pred.append(item[0])real_true.append(item[1])return accuracy_score(real_true, real_pred), real_true, real_pred
为了能够在模型训练或推理过程中输入模型的预测结果,因此我们需要实现3个辅助函数来完成。首先需要实现根据logits和input_token_ids来得到每个预测值对应的实体标签,代码如下:
def get_ner_tags(logits, token_ids, entities, SEP_IDX=102):""":param logits: [src_len,batch_size,num_samples]:param token_ids: # [src_len,batch_size]:return:e.g.logits = torch.tensor([[[0.4, 0.7, 0.2],[0.5, 0.4, 0.1],[0.1, 0.2, 0.3],[0.5, 0.7, 0.2],[0.1, 0.2, 0.5]],[[0.3, 0.2, 0.5],[0.7, 0.8, 0.4],[0.1, 0.1, 0.3],[0.9, 0.2, 0.1],[0.1, 0.5,0.2]]])logits = logits.transpose(0, 1) # [src_len,batch_size,num_samples]token_ids = torch.tensor([[101, 2769, 511, 102, 0],[101, 56, 33, 22, 102]]).transpose(0, 1) # [src_len,batch_size]labels, probs = get_ner_tags(logits, token_ids, entities)[['O', 'B-LOC'], ['B-ORG', 'B-LOC', 'O']][[0.5, 0.30000001192092896], [0.800000011920929, 0.30000001192092896, 0.8999999761581421]]"""# entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}label_list = list(entities.keys())logits = logits[1:].transpose(0, 1) # [batch_size,src_len-1,num_samples]prob, y_pred = torch.max(logits, dim=-1) # prob, y_pred: [batch_size,src_len-1]token_ids = token_ids[1:].transpose(0, 1) # [ batch_size,src_len-1], 去掉[cls]assert y_pred.shape == token_ids.shapelabels = []probs = []for sample in zip(y_pred, token_ids, prob):tmp_label, tmp_prob = [], []for item in zip(*sample):if item[1] == SEP_IDX: # 忽略最后一个[SEP]字符breaktmp_label.append(label_list[item[0]])tmp_prob.append(item[2].item())labels.append(tmp_label)probs.append(tmp_prob)return labels, probs
进一步,在得到每个输入句子的预测结果后,还需要将其进行格式化处理得到最终的预测结果,实现代码如下:
def pretty_print(sentences, labels, entities):""":param sentences::param labels::param entities::return:e.g.labels = [['B-PER','I-PER', 'O','O','O','O','O','O','O','O','O','O','B-LOC','I-LOC','B-LOC','I-LOC','O','O','O','O'],['B-LOC','I-LOC','O','B-LOC','I-LOC','O','B-LOC','I-LOC','I-LOC','O','B-LOC','I-LOC','O','O','O','B-PER','I-PER','O','O','O','O','O','O']]sentences=["涂伊说,如果有机会他想去赤壁看一看!","丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!"]entities = {'O': 0, 'B-ORG': 1, 'B-LOC': 2, 'B-PER': 3, 'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}句子:涂伊说,如果有机会他想去黄州赤壁看一看!涂伊: PER黄州: LOC赤壁: LOC句子:丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!丽江: LOC大理: LOC九寨沟: LOC黄龙: LOC涂伊: PER"""sep_tag = [tag for tag in list(entities.keys()) if 'I' not in tag]result = []for sen, label in zip(sentences, labels):logging.info(f"句子:{sen}")last_tag = Nonefor item in zip(sen + "O", label + ['O']):if item[1] in sep_tag: #if len(result) > 0:entity = "".join(result)logging.info(f"\t{entity}: {last_tag.split('-')[-1]}")result = []if item[1] != 'O':result.append(item[0])last_tag = item[1]else:result.append(item[0])last_tag = item[1]
输出结果如下:
1 句子:涂伊说,如果有机会他想去黄州赤壁看一看!2 涂伊: PER3 黄州: LOC4 赤壁: LOC5 句子:丽江、大理、九寨沟、黄龙等都是涂伊想去的地方!6 丽江: LOC7 大理: LOC8 九寨沟: LOC9 黄龙: LOC
10 涂伊: PER
在完成上述所有铺垫之后,便可以来实现模型的训练部分,代码如下(下面只摘录核心部分进行介绍):
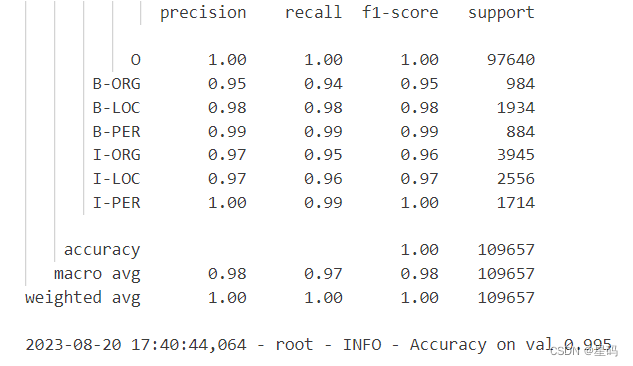
def train(config):model = BertForTokenClassification(config,config.pretrained_model_dir)model_save_path = os.path.join(config.model_save_dir,config.model_save_name)global_steps = 0if os.path.exists(model_save_path):checkpoint = torch.load(model_save_path)global_steps = checkpoint['last_epoch']loaded_paras = checkpoint['model_state_dict']model.load_state_dict(loaded_paras)logging.info("## 成功载入已有模型,进行追加训练......")model = model.to(config.device)optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)'''Apply Intel Extension for PyTorch optimization against the model object and optimizer object.'''model, optimizer = ipex.optimize(model, optimizer=optimizer)model.train()data_loader = LoadChineseNERDataset(entities=config.entities,num_labels=config.num_labels,ignore_idx=config.ignore_idx,vocab_path=config.vocab_path,tokenizer=BertTokenizer.from_pretrained(config.pretrained_model_dir).tokenize,batch_size=config.batch_size,max_sen_len=config.max_sen_len,split_sep=config.split_sep,max_position_embeddings=config.max_position_embeddings,pad_index=config.pad_token_id,is_sample_shuffle=config.is_sample_shuffle)train_iter, test_iter, val_iter = \data_loader.load_train_val_test_data(train_file_path=config.train_file_path,val_file_path=config.val_file_path,test_file_path=config.test_file_path,only_test=False)max_acc = 0for epoch in range(config.epochs):losses = 0start_time = time.time()for idx, (sen, token_ids, labels) in enumerate(train_iter):token_ids = token_ids.to(config.device)labels = labels.to(config.device)padding_mask = (token_ids == data_loader.PAD_IDX).transpose(0, 1)loss, logits = model(input_ids=token_ids, # [src_len, batch_size]attention_mask=padding_mask, # [batch_size,src_len]token_type_ids=None,position_ids=None,labels=labels) # [src_len, batch_size]# logit: [src_len, batch_size, num_labels]optimizer.zero_grad()loss.backward()optimizer.step()losses += loss.item()global_steps += 1acc, _, _ = accuracy(logits, labels, config.ignore_idx)if idx % 20 == 0:logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "f"Train loss :{loss.item():.3f}, Train acc: {round(acc, 5)}")if idx % 100 == 0:show_result(sen[:10], logits[:, :10], token_ids[:, :10], config.entities)end_time = time.time()train_loss = losses / len(train_iter)logging.info(f"Epoch: [{epoch + 1}/{config.epochs}],"f" Train loss: {train_loss:.3f}, Epoch time = {(end_time - start_time):.3f}s")if (epoch + 1) % config.model_val_per_epoch == 0:acc = evaluate(config, val_iter, model, data_loader)logging.info(f"Accuracy on val {acc:.3f}")if acc > max_acc:max_acc = accstate_dict = deepcopy(model.state_dict())torch.save({'last_epoch': global_steps,'model_state_dict': state_dict},model_save_path)
结果

参考资料
基于BERT预训练模型的中文文本分类任务: https://mp.weixin.qq.com/s/bbeN95mlLaE05dFndUAxgA
相关文章:
[oneAPI] 基于BERT预训练模型的命名体识别任务
[oneAPI] 基于BERT预训练模型的命名体识别任务 Intel DevCloud for oneAPI 和 Intel Optimization for PyTorch基于BERT预训练模型的命名体识别任务语料介绍数据集构建使用示例 命名体识别模型前向传播模型训练 结果 参考资料 比赛:https://marketing.csdn.net/p/f3…...

SSL证书如何使用?SSL保障通信安全
由于SSL技术已建立到所有主要的浏览器和WEB服务器程序中,因此,仅需安装数字证书或服务器证书就可以激活功能了。SSL证书主要是服务于HTTPS,部署证书后,网站链接就由HTTP开头变为HTTPS。 SSL安全证书主要用于发送安全电子邮件、访…...
postgresql 的递归查询
postgresql 的递归查询功能很强大,可以实现传统 sql 无法实现的事情。那递归查询的执行逻辑是什么呢?在递归查询中,我们一般会用到 union 或者 union all,他们两者之间的区别是什么呢? 递归查询的执行逻辑 递归查询的…...

Go语言进阶:函数、指针、错误处理
一、函数 函数是基本的代码块,用于执行一个任务。 Go 语言最少有个 main() 函数。 你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。 函数声明包括函数名﹑形式参数列表﹑返回值列表(可省略)以及函数体。 fun…...
-JS句柄)
最强自动化测试框架Playwright(30)-JS句柄
在 Playwright 中,JSHandle 是一个表示浏览器中 JavaScript 对象的类。它提供了与网页中的 JavaScript 对象进行交互和操作的方法。 可以通过调用 Playwright中的 evaluateHandle 或 evaluate 方法来获取 JSHandle from playwright.sync_api import sync_playwrig…...

Ctfshow web入门 命令执行RCE篇 web29-web77 与 web118-web124 详细题解 全
Ctfshow 命令执行 web29 pregmatch是正则匹配函数,匹配是否包含flag,if(!preg_match("/flag/i", $c)),/i忽略大小写 可以利用system来间接执行系统命令 flag采用f*绕过,或者mv fl?g.php 1.txt修改文件名,…...

【C++ STL之map,set,pair详解】
目录 一.map映射1.简介2.包含头文件及其初始化3.基本操作4.用迭代器正反遍历5.添加元素的四种方式6.元素的访问7.对比unordered_map,multimap 二.set集合1.简介2.包含头文件及其初始化3.基本操作4.元素的访问5.set,multiset,unordered_set&am…...

Python LEGB规则解析与应用
引言 推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 「java、python面试题」来自UC网盘app分享,打开手机app,额外获得1T空间 http…...

气象监测站:用科技感知气象变化
气象监测站是利用科学技术感知当地小气候变化情况的气象观测仪器,可用于农业、林业、养殖业、畜牧业、环境保护、工业等多个领域,提高对环境数据的利用率,促进产业效能不断提升。 气象监测站主要由气象传感器、数据传输系统、电源系统、支架…...

Linux debian12解压和压缩.rar文件教程
一、Debian12安装rar命令 sudo apt install rar二、使用rar软件 1.解压文件 命令格式: rar x 文件名.rar实例测试: [rootdoudou tmp]# rar x test.rar2.压缩文件 test是一个文件夹 命令格式: rar a 文件名.rar 文件夹名实例测试&#x…...

探析国际大文件传输的花费与降低开销的小妙招
随着全球化的不断发展,跨国企业日益增多,因此国外大文件传输也日益普遍。在这种背景下,国外大文件传输方式的需求也相应增加。本文旨在深入分析国外大文件传输的成本,并提出有效降低这些成本的方法。 一、国外大文件传输成本分析 …...
Linux中shell脚本——for、while循环及脚本练习
目录 一.for循环 1.1.基本格式 1.2.类C语言格式 二.while循环 2.1.基本格式 2.2.死循环语句 三.跳出循环 3.1.continue跳出循环 3.2.break跳出循环 四.常用循环 4.1.循环打印九九乘法表 4.2.循环ping测试某个网段网络连通性 4.3.while死循环实现猜数字游戏 4.4.数…...
【数字实验室】时钟切换
大部分开发者使用 BUFGCTRL 或 BUFGMUX进行时钟切换,它们在时钟切换上可以提供无毛刺输出。然而,了解所涉及的原理是有好处的。 当然,无论我们在同步逻辑中使用哪种技术,重要的是要确保在进行时钟切换时输出上没有毛刺。任何故障都…...

线性代数的学习和整理7:各种特殊效果矩阵特例(草稿-----未完成)
目录 1 矩阵 1.1 1维的矩阵 1.2 2维的矩阵 1.3 没有3维的矩阵---3维的是3阶张量 2 方阵 3 单位矩阵 3.1 单位矩阵的定义 3.2 单位矩阵的特性 3.3 为什么单位矩阵I是 [1,0;0,1] 而不是[0,1;1,0] 或[1,1;1,1] 3.4 零矩阵 3.4 看下这个矩阵 [0,1;1,0] 3.5 看下这个矩阵…...

springBoot 配置文件 spring.mvc.throw-exception-if-no-handler-found 参数的作用
在Spring Boot应用中,可以通过配置文件来控制当找不到请求处理器(handler)时是否抛出异常。具体的配置参数是spring.mvc.throw-exception-if-no-handler-found。 默认情况下,该参数的值为false,即当找不到请求处理器时…...

linux部署kafka3.5.1(单机)
一、下载jdk17 kafka3.x版本需要jdk11以上版本才能更好的兼容,jdk11、jdk17都是LTS长期维护版本,而且jdk17支持springboot3.x,所以我选择了openjdk17。 下载地址: Archived OpenJDK GA Releaseshttps://jdk.java.net/archive/ 二、上传jdk安装包解压 …...

css 实现svg动态图标效果
效果演示: 实现思路:主要是通过css的stroke相关属性来设置实现的。 html代码: <svgt"1692441666814"class"icon"viewBox"0 0 1024 1024"version"1.1"xmlns"http://www.w3.org/2000/svg"p-id"…...
软件测试项目实战,电商业务功能测试点汇总(全覆盖)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 支付功能怎么测试…...

LeetCode[274]H指数
难度:Medium 题目: 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指…...
MyBatis-Plus快速开始[MyBatis-Plus系列] - 第482篇
悟纤:师傅,MyBatis-Plus被你介绍的这么神乎其乎,咱们还是来的点实际的吧。 师傅:那真是必须的,学习技术常用的一种方法,就是实践。 悟纤:贱贱更健康。 师傅:这… 师傅:…...

比亚迪多款新车激光雷达性能超越华为:千线级感知开启智驾新纪元
2026年,中国智能驾驶行业正式进入“千线级激光雷达”时代。继华为发布896线双光路激光雷达后,比亚迪携速腾聚创EM4数字化激光雷达强势反击,以1080线物理扫描、600米最远探测的硬核参数,在核心感知硬件上实现对华为的全面超越。这一突破不仅标志着比亚迪补齐了智能化短板,更…...

iPhone 抓包失败 4 种具体情况逐个解决方法
抓不到包这个描述太模糊了,在实际调试中,这句话至少对应四种完全不同的情况: 完全没有请求只有浏览器能抓到能抓到但 HTTPS 解不开能抓到但数据不完整 如果不先分清楚是哪一种,就会一直重复安装证书或改代理配置。一、先做一个验证…...

编写程序让智能洗手液机检测手部靠近,自动出液,无需按压。
🧼 项目实战:基于红外测距的智能洗手液机控制系统一、实际应用场景描述 (Scenario)在机场、医院、办公楼等公共场所,传统的按压式洗手液机存在卫生隐患——每个人都需要接触同一个泵头,容易造成细菌交叉感染。目标:通过…...

Vue项目中使用/deep/报错?手把手教你用::v-deep完美解决样式问题
Vue样式穿透难题:从/deep/到::v-deep的优雅升级指南 在Vue生态中,样式作用域管理一直是开发者们津津乐道的话题。当你在使用第三方UI库时,是否遇到过这样的尴尬:明明在本地开发环境调试好的样式,打包后却神秘失效&…...
求解柔性作业车间调度问题(FJSP),提供MATLAB代码)
FJSP:蛇鹫优化算法(SBOA)求解柔性作业车间调度问题(FJSP),提供MATLAB代码
FJSP:蛇鹫优化算法(SBOA)求解柔性作业车间调度问题(FJSP),提供MATLAB代码当车间调度遇上非洲大草原的蛇鹄,会碰撞出什么样的火花?今天咱们用MATLAB实现一种新颖的群智能算法——蛇鹄…...

OpenClaw对比测试:Qwen3.5-9B与其他模型在自动化任务中的表现
OpenClaw对比测试:Qwen3.5-9B与其他模型在自动化任务中的表现 1. 测试背景与实验设计 最近在搭建个人自动化工作流时,我遇到了一个关键问题:OpenClaw框架下究竟该选择哪个大模型作为决策核心?为了找到答案,我花了三天…...

SEO_2024年最新SEO趋势与核心优化方法介绍
<h1 id"seo2024seo">SEO:2024年最新SEO趋势与核心优化方法介绍</h1> <p>在互联网时代,搜索引擎优化(SEO)仍然是网站流量和品牌推广的关键。2024年,SEO领域有许多新的趋势和核心优化方法,帮…...

基于单周期控制的交错并联无桥Boost PFC变换器:宽电压范围与高效率转换技术实现高效电源管理
基于单周期控制的两相交错并联无桥Boost型 PFC 变换器 采用两路 Boost PFC 交错并联实现的,每一路的控制方式和结构都是相同的,由此推出控制方法相同,都为单周期控制,所以只分析一路的结果就可以类比 1、输入电压:150V…...

从杂乱桌面到高效办公 GeekDesk实际应用效果展示
评价一款软件产品的优劣,最具说服力的方式莫过于通过真实的实际案例来直观展示其效果和价值。 今天,本文就以几个不同类型用户的真实使用场景为例,完整展示GeekDesk如何帮助他们从杂乱桌面到高效办公的转变过程。 通过这种直观的效果对比&…...

CLIP-GmP-ViT-L-14入门指南:ViT-L-14主干网络结构与特征提取流程
CLIP-GmP-ViT-L-14入门指南:ViT-L-14主干网络结构与特征提取流程 1. 项目概述 CLIP-GmP-ViT-L-14是一个经过几何参数化(GmP)微调的CLIP模型,在ImageNet和ObjectNet数据集上能达到约90%的准确率。这个模型基于ViT-L-14(Vision Transformer Large 14)主干…...