Spark 图计算ONEID 进阶版
0、环境信息
本文采用阿里云maxcompute的spark环境为基础进行的,搭建本地spark环境参考搭建Windows开发环境_云原生大数据计算服务 MaxCompute-阿里云帮助中心
版本spark 2.4.5,maven版本大于3.8.4
①配置pom依赖 详见2-1
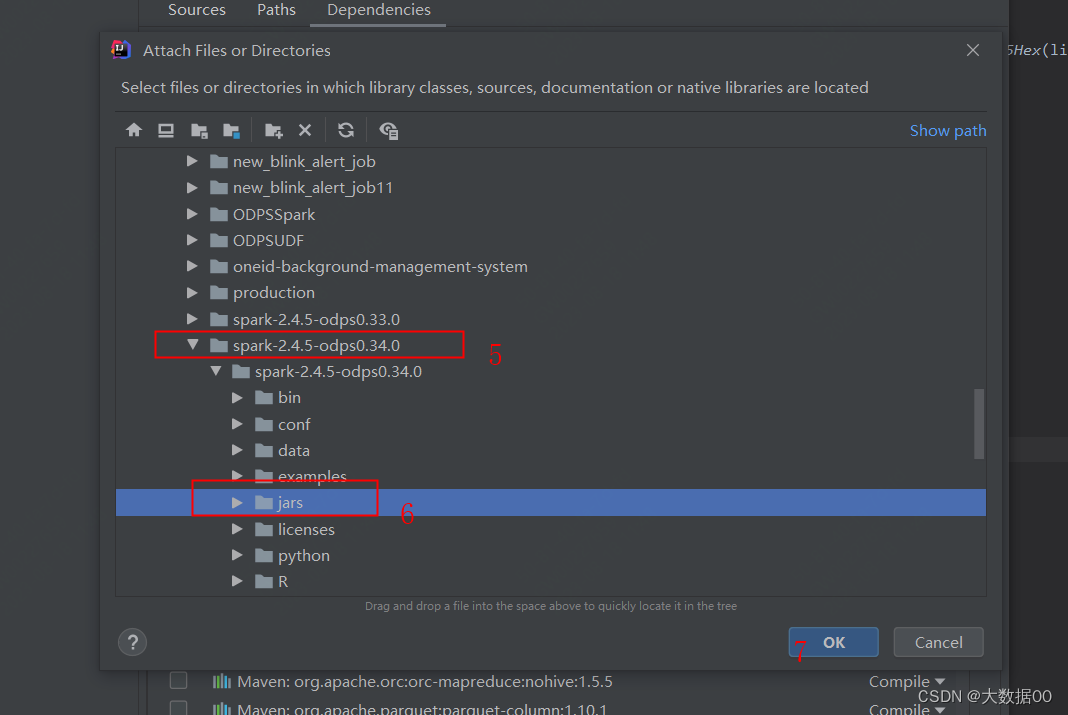
②添加运行jar包

③添加配置信息
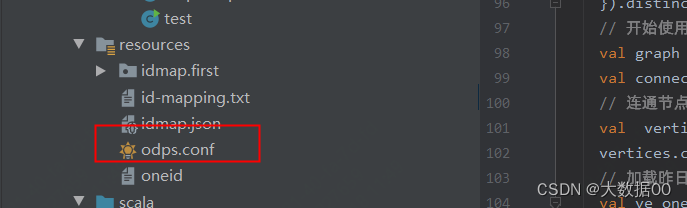
odps.project.name= odps.access.id= odps.access.key= odps.end.point=
1、数据准备
create TABLE dwd_sl_user_ids(
user_name STRING COMMENT '用户'
,user_id STRING COMMENT '用户id'
,device_id STRING COMMENT '设备号'
,id_card STRING COMMENT '身份证号'
,phone STRING COMMENT '电话号'
,pay_id STRING COMMENT '支付账号'
,ssoid STRING COMMENT 'APPID'
) PARTITIONED BY (
ds BIGINT
)
;
INSERT OVERWRITE TABLE dwd_sl_user_ids PARTITION(ds=20230818)
VALUES
('大法_官网','1','device_a','130826','185133','zhi1111','U130311')
,('大神_官网','2','device_b','220317','165133','zhi2222','')
,('耀总_官网','3','','310322','133890','zhi3333','U120311')
,('大法_app','1','device_x','130826','','zhi1111','')
,('大神_app','2','device_b','220317','165133','','')
,('耀总_app','','','','133890','zhi333','U120311')
,('大法_小程序','','device_x','130826','','','U130311')
,('大神_小程序','2','device_b','220317','165133','','U140888')
,('耀总_小程序','','','310322','133890','','U120311')
;
结果表
create TABLE itsl_dev.dwd_patient_oneid_info_df(
oneid STRING COMMENT '生成的ONEID'
,id STRING COMMENT '用户的各类id'
,id_hashcode STRING COMMENT '用户各类ID的id_hashcode'
,guid STRING COMMENT '聚合的guid'
,guid_hashcode STRING COMMENT '聚合的guid_hashcode'
)PARTITIONED BY (
ds BIGINT
);
2、代码准备
①pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.gwm</groupId><artifactId>graph</artifactId><version>1.0-SNAPSHOT</version><name>graph</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><spark.version>2.3.0</spark.version><java.version>1.8</java.version><cupid.sdk.version>3.3.8-public</cupid.sdk.version><scala.version>2.11.8</scala.version><scala.binary.version>2.11</scala.binary.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-graphx_2.11</artifactId><version>${spark.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>com.thoughtworks.paranamer</groupId><artifactId>paranamer</artifactId><version>2.8</version>
<!-- <scope>provided</scope>--></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.5</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>com.aliyun.odps</groupId><artifactId>cupid-sdk</artifactId><version>${cupid.sdk.version}</version><scope>provided</scope></dependency><!-- <dependency>--><!-- <groupId>com.aliyun.odps</groupId>--><!-- <artifactId>hadoop-fs-oss</artifactId>--><!-- <version>${cupid.sdk.version}</version>--><!-- </dependency>--><dependency><groupId>com.aliyun.odps</groupId><artifactId>odps-spark-datasource_${scala.binary.version}</artifactId><version>${cupid.sdk.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.73</version></dependency><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.13</version></dependency><dependency><groupId>commons-lang</groupId><artifactId>commons-lang</artifactId><version>2.6</version></dependency></dependencies><!-- <build>--><!-- <pluginManagement><!– lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) –>--><!-- <plugins>--><!-- <!– clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle –>--><!-- <plugin>--><!-- <artifactId>maven-clean-plugin</artifactId>--><!-- <version>3.1.0</version>--><!-- </plugin>--><!-- <!– default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging –>--><!-- <plugin>--><!-- <artifactId>maven-resources-plugin</artifactId>--><!-- <version>3.0.2</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-compiler-plugin</artifactId>--><!-- <version>3.8.0</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-surefire-plugin</artifactId>--><!-- <version>2.22.1</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-jar-plugin</artifactId>--><!-- <version>3.0.2</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-install-plugin</artifactId>--><!-- <version>2.5.2</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-deploy-plugin</artifactId>--><!-- <version>2.8.2</version>--><!-- </plugin>--><!-- <!– site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle –>--><!-- <plugin>--><!-- <artifactId>maven-site-plugin</artifactId>--><!-- <version>3.7.1</version>--><!-- </plugin>--><!-- <plugin>--><!-- <artifactId>maven-project-info-reports-plugin</artifactId>--><!-- <version>3.0.0</version>--><!-- </plugin>--><!-- <plugin>--><!-- <groupId>org.scala-tools</groupId>--><!-- <artifactId>maven-scala-plugin</artifactId>--><!-- <version>2.15.2</version>--><!-- <executions>--><!-- <execution>--><!-- <goals>--><!-- <goal>compile</goal>--><!-- <goal>testCompile</goal>--><!-- </goals>--><!-- </execution>--><!-- </executions>--><!-- </plugin>--><!-- </plugins>--><!-- </pluginManagement>--><!-- </build>--><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.1</version><configuration><archive><manifest><mainClass>com.gwm.OdpsGraphx</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
</project>
②代码
package com.gwmimport java.math.BigInteger
import java.text.SimpleDateFormat
import java.util.Calendarimport org.apache.commons.codec.digest.DigestUtils
import org.apache.spark.SparkConf
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.spark_project.jetty.util.StringUtilimport scala.collection.mutable.ListBuffer/*** @author yangyingchun* @date 2023/8/18 10:32* @version 1.0*/
object OneID {val sparkConf = (new SparkConf).setAppName("OdpsGraph").setMaster("local[1]")sparkConf.set("spark.hadoop.odps.access.id", "your's access.id ")sparkConf.set("spark.hadoop.odps.access.key", "your's access.key")sparkConf.set("spark.hadoop.odps.end.point", "your's end.point")sparkConf.set("spark.hadoop.odps.project.name", "your's project.name")sparkConf.set("spark.sql.catalogImplementation", "hive") //in-memory 2.4.5以上hiveval spark = SparkSession.builder.appName("Oneid").master("local[1]").config("spark.sql.broadcastTimeout", 1200L).config("spark.sql.crossJoin.enabled", true).config("odps.exec.dynamic.partition.mode", "nonstrict").config(sparkConf).getOrCreateval sc = spark.sparkContextdef main(args: Array[String]): Unit = {val bizdate=args(0)val c = Calendar.getInstanceval format = new SimpleDateFormat("yyyyMMdd")c.setTime(format.parse(bizdate))c.add(Calendar.DATE, -1)val bizlastdate = format.format(c.getTime)println(s" 时间参数 ${bizdate} ${bizlastdate}")// dwd_sl_user_ids 就是我们用户的各个ID ,也就是我们的数据源// 获取字段,这样我们就可以扩展新的ID 字段,但是不用更新代码val columns = spark.sql(s"""|select| *|from| itsl.dwd_sl_user_ids|where| ds='${bizdate}'|limit| 1|""".stripMargin).schema.fields.map(f => f.name).filterNot(e=>e.equals("ds")).toListprintln("字段信息=>"+columns)// 获取数据val dataFrame = spark.sql(s"""|select| ${columns.mkString(",")}|from| itsl.dwd_sl_user_ids|where| ds='${bizdate}'|""".stripMargin)// 数据准备val data = dataFrame.rdd.map(row => {val list = new ListBuffer[String]()for (column <- columns) {val value = row.getAs[String](column)list.append(value)}list.toList})import spark.implicits._// 顶点集合val veritx= data.flatMap(list => {for (i <- 0 until columns.length if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i))))yield (new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue, list(i))}).distinctval veritxDF=veritx.toDF("id_hashcode","id")veritxDF.createOrReplaceTempView("veritx")// 生成边的集合val edges = data.flatMap(list => {for (i <- 0 to list.length - 2 if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i))); j <- i + 1 to list.length - 1 if StringUtil.isNotBlank(list(j)) && (!"null".equals(list(j))))yield Edge(new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue,new BigInteger(DigestUtils.md5Hex(list(j)),16).longValue, "")}).distinct// 开始使用点集合与边集合进行图计算训练val graph = Graph(veritx, edges)//计算每个顶点的连接组件成员身份,并返回具有该顶点的图值,该值包含包含该顶点的连接组件中的最低顶点id,迭代次数 控制迭代次数//var vertices: DataFrame = ConnectedComponents.run(graph, 2).vertices.toDF("id_hashcode", "guid_hashcode")val connectedGraph=graph.connectedComponents()// 连通节点val vertices = connectedGraph.vertices.toDF("id_hashcode","guid_hashcode")vertices.createOrReplaceTempView("to_graph")// 加载昨日的oneid 数据 (oneid,id,id_hashcode)val ye_oneid = spark.sql(s"""|select| oneid,id,id_hashcode|from| itsl.dwd_patient_oneid_info_df|where| ds='${bizlastdate}'|""".stripMargin)ye_oneid.createOrReplaceTempView("ye_oneid")// 关联获取 已经存在的 oneid,这里的min 函数就是我们说的oneid 的选择问题val exists_oneid=spark.sql("""|select| a.guid_hashcode,min(b.oneid) as oneid|from| to_graph a|inner join| ye_oneid b|on| a.id_hashcode=b.id_hashcode|group by| a.guid_hashcode|""".stripMargin)exists_oneid.createOrReplaceTempView("exists_oneid")var result: DataFrame = spark.sql(s"""|select| nvl(b.oneid,md5(cast(a.guid_hashcode as string))) as oneid,c.id,a.id_hashcode,d.id as guid,a.guid_hashcode,${bizdate} as ds|from| to_graph a|left join| exists_oneid b|on| a.guid_hashcode=b.guid_hashcode|left join| veritx c|on| a.id_hashcode=c.id_hashcode|left join| veritx d|on| a.guid_hashcode=d.id_hashcode|""".stripMargin)// 不存在则生成 存在则取已有的 这里nvl 就是oneid 的更新逻辑,存在则获取 不存在则生成var resultFrame: DataFrame = result.toDF()resultFrame.show()resultFrame.write.mode(SaveMode.Append).partitionBy("ds").saveAsTable("dwd_patient_oneid_info_df")sc.stop}
}
③ 本地运行必须增加resources信息

3、问题解决
①Exception in thread "main" java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.hive.HiveSessionStateBuilder
缺少Hive相关依赖,增加
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>${spark.version}</version><!-- <scope>provided</scope>-->
</dependency>
但其实针对odps不需要加此依赖,只需要按0步配置好环境即可
②Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: `itsl`.`dwd_sl_user_ids`; line 5 pos 3;
需要按照 0 步中按照要求完成环境准备
③Exception in thread "main" org.apache.spark.sql.AnalysisException: The format of the existing table itsl.dwd_patient_oneid_info_df is `OdpsTableProvider`. It doesn't match the specified format `ParquetFileFormat`.;
解决:ALTER TABLE dwd_patient_oneid_info_df SET FILEFORMAT PARQUET;
本地读写被禁用 需要上线解决
4、打包上传
①需取消
.master("local[1]")
②取消maven依赖
③odps.conf不能打包,建临时文件不放在resources下

本地测试时放resources下
参考用户画像之ID-Mapping_id mapping_大数据00的博客-CSDN博客
上线报
org.apache.spark.sql.AnalysisException: Table or view not found: `itsl`.`dwd_sl_user_ids`; line 5 pos 3;
原因是本节③
5、运行及结果
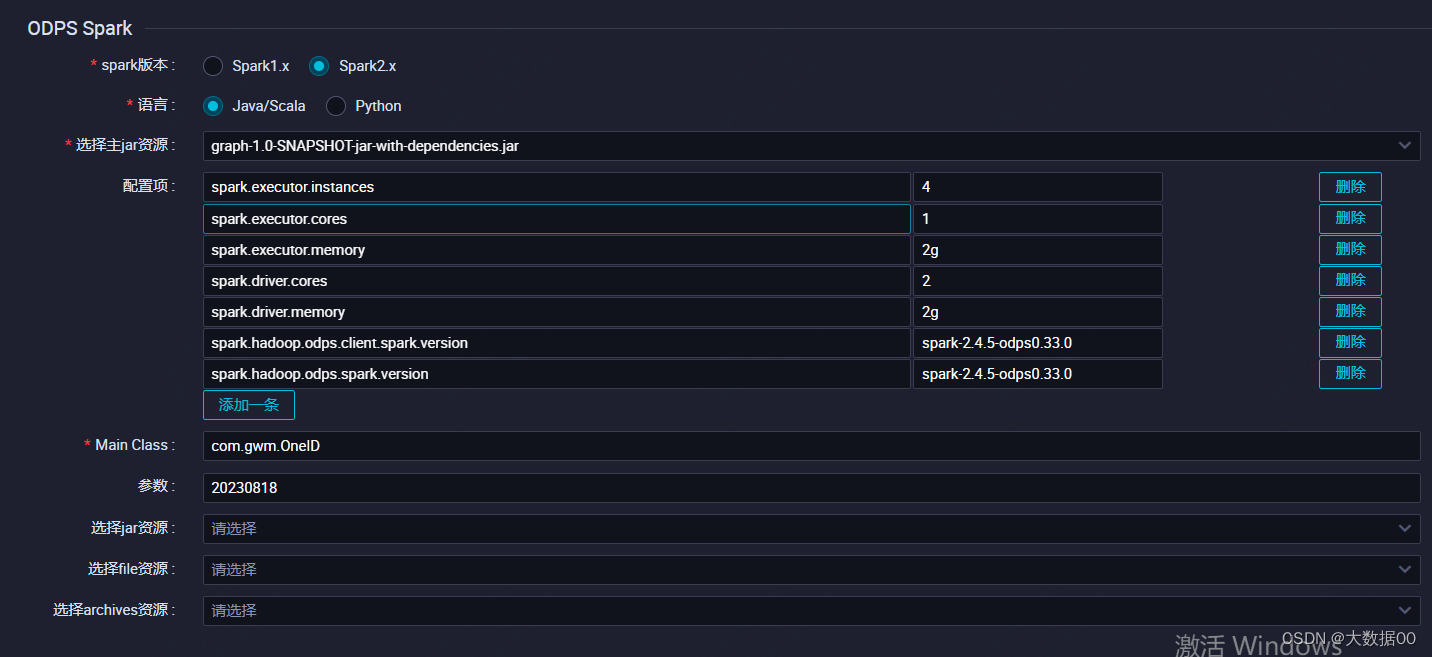
结果
oneid id id_hashcode guid guid_hashcode ds
598e7008ffc3c6adeebd4d619e2368f3 耀总_app 8972546956853102969 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 310322 1464684454693316922 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 zhi333 6097391781232248718 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 3 2895972726640982771 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 耀总_小程序 -6210536828479319643 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 zhi3333 -2388340305120644671 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 133890 -9124021106546307510 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 耀总_官网 -9059665468531982172 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 U120311 -2948409726589830290 133890 -9124021106546307510 20230818
d39364f7fb05a0729646a766d6d43340 U140888 -8956123177900303496 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_官网 7742134357614280661 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 220317 4342975012645585979 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 device_b 934146606527688393 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 165133 -8678359668161914326 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_app 3787345307522484927 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_小程序 8356079890110865354 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 2 8000222017881409068 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 zhi2222 8743693657758842828 U140888 -8956123177900303496 20230818
34330e92b91e164549cf750e428ba9cd 130826 -5006751273669536424 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd device_a -3383445179222035358 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 1 994258241967195291 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd device_x 3848069073815866650 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd zhi1111 7020506831794259850 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 185133 -2272106561927942561 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_app -7101862661925406891 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd U130311 5694117693724929174 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_官网 -4291733115832359573 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_小程序 -5714002662175910850 大法_app -7101862661925406891 20230818
6、思考
如果联通图是循环的怎么处理呢?A是B的朋友,B是C的朋友,C是A的朋友
相关文章:
Spark 图计算ONEID 进阶版
0、环境信息 本文采用阿里云maxcompute的spark环境为基础进行的,搭建本地spark环境参考搭建Windows开发环境_云原生大数据计算服务 MaxCompute-阿里云帮助中心 版本spark 2.4.5,maven版本大于3.8.4 ①配置pom依赖 详见2-1 ②添加运行jar包 ③添加配置信…...

Comparable和Comparator区别
Comparable和Comparator接口都是实现集合中元素的比较、排序的,众所周知,诸如Integer,double等基本数据类型,java可以对他们进行比较,而对于类的比较,需要人工定义比较用到的字段比较逻辑。总体来讲&#x…...

JAVA知识点梳理
我的博客:lcatake_flume,spark,zookeeper-CSDN博客 看不懂的话进去看看 1.Java的三个版本 JAVASE 基本 JAVAME 微缩 JAVAEE 标准 3.java的特点 面向对象 跨平台:jvm将java文件转变为字节码文件(.class)在多个系统中运 行字…...
[SWPUCTF 2022 新生赛]ez_ez_php
这段代码是一个简单的PHP文件处理脚本。让我们逐行进行分析: error_reporting(0); - 这行代码设置了错误报告的级别为0,意味着不显示任何错误。 if (isset($_GET[file])) { - 这行代码检查是否存在一个名为"file"的GET参数。 if ( substr($_…...
GraphQL strawberry的使用回顾和体会
GraphQL vs RESTful 简单来说GraphQL 比起 RESTful 集成额外一些功能 出入参校验、序列化 (简化后端编程)自由可选的返回数据字段 (简化一些多余接口开发和沟通联调成本) 这些都是优点了。 开发效率在项目初期是很重要的,需要快速原型化。 但是后期稳定后&#…...

08无监督学习——聚类
1.什么是聚类任务? 类别:无监督学习 目的:通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。 1.1K均值聚类 步骤: 随机选取样本作为初始均值向量(初始值:k的值【即几个簇】)分别…...

Python使用OpenCV库对彩色图像进行通道分离
目录 1、解释说明: 2、使用示例: 3、注意事项: 1、解释说明: 在Python中,我们可以使用OpenCV库对彩色图像进行通道分离。通道分离是将彩色图像的每个像素分解为三个通道(红、绿、蓝)的过程。…...

前端面试:【CSS】盒模型、选择器、布局、响应式设计、Flexbox 与 Grid
CSS(层叠样式表)是用于控制网页外观和布局的重要语言。在这篇文章中,我们将深入探讨CSS的基础知识,包括盒模型、选择器、布局、响应式设计,以及弹性盒子(Flexbox)和网格布局(Grid&am…...

深入浅出通过PHP封装根据商品ID获取抖音商品详情数据方法
抖音商城商品详情数据是指商品在抖音商城中的展示信息,包括商品的标题、描述、价格、图片等。商家可以通过商品详情数据了解用户对商品的兴趣和需求,从而进行优化和调整。 商品详情数据还可以帮助商家评估商品的销售情况和市场竞争力,为制定…...
排序(七种排序)
1.插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 7.归并排序 1.插入排序 1.1思路 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为 止,得到一个新的有序序列 1.2实现 //插入排…...
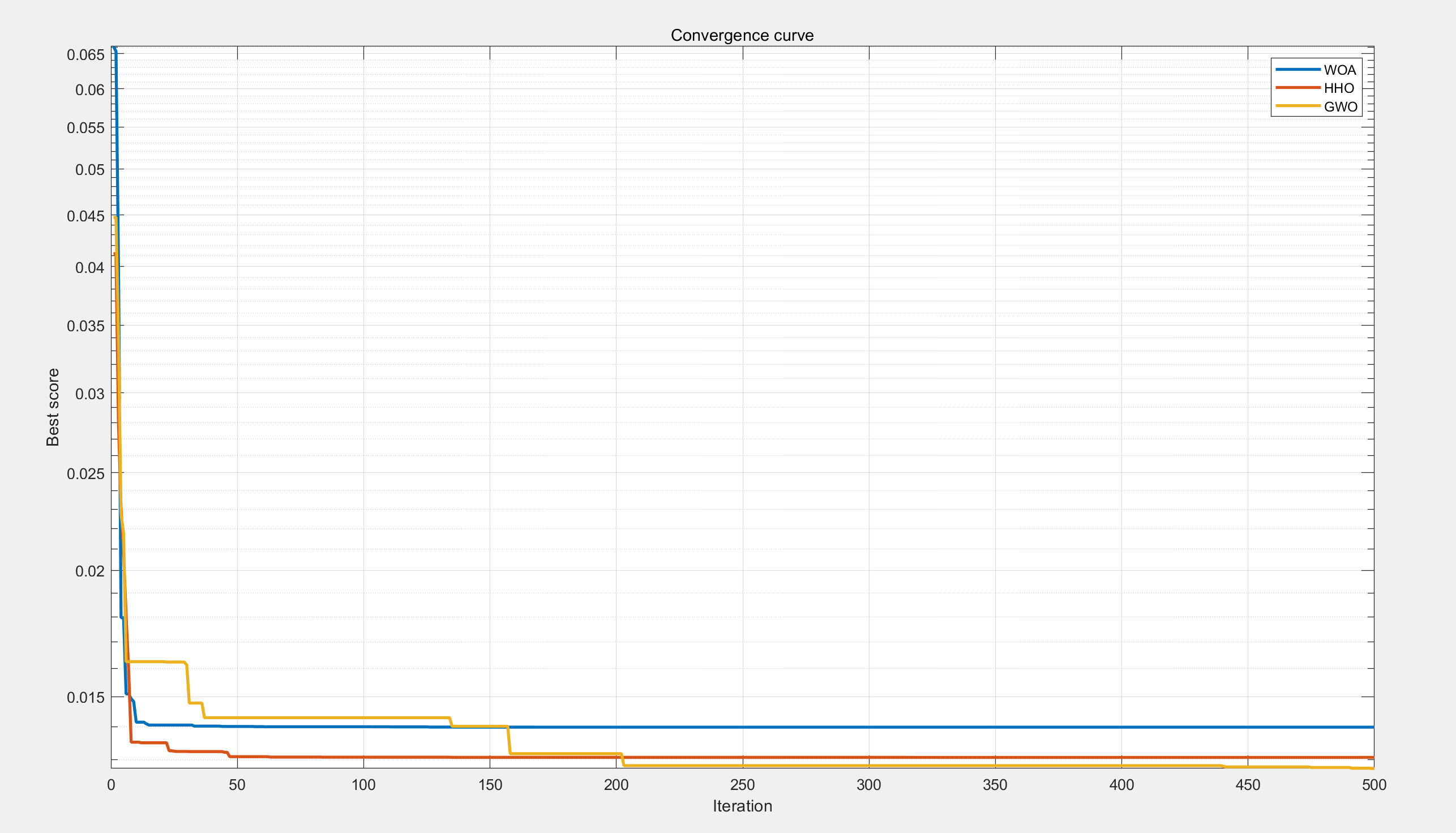
【工程优化问题】基于鲸鱼、萤火虫、灰狼优化算法的张力、压缩弹簧设计问题研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

sap ui5刷新页面的方式
1.第一种 window.location.reload();2.第二种 如果你想在UI5应用程序中使用MVC模式来处理页面刷新,可以通过重新加载当前路由来实现刷新。首先,确保你有一个Router对象实例: var oRouter = sap.ui.core.UIComponent.getRouterFor(this);然后&...

Java课题笔记~ Fastjson 概述
3.3 JSON串和Java对象的相互转换 学习完 json 后,接下来聊聊 json 的作用。 以后我们会以 json 格式的数据进行前后端交互。前端发送请求时,如果是复杂的数据就会以 json 提交给后端;而后端如果需要响应一些复杂的数据时,也需要…...

Arduino 入门学习笔记11 读写内置EEPROM
Arduino 入门学习笔记11 使用I2C读写EEPROM 一、Arduino 内置EEPROM介绍二、EEPROM 操作1. 包含EEPROM库:2. 写入数据到EEPROM:3. 从EEPROM读取数据4. 完整示例: 一、Arduino 内置EEPROM介绍 Arduino的内置EEPROM(Electrically E…...

【Nginx】安装make后遇到/bin/sh: 第 0 行:cd: ../pcre-8.38: 没有那个文件或目录
遇到/bin/sh: 第 0 行:cd: ../pcre-8.38: 没有那个文件或目录 需安装pcre 下载 http://downloads.sourceforge.net/project/pcre/pcre/8.35/pcre-8.35.tar.gz 上传到/usr/local下 pcre解压编译 tar -zxvf pcre-8.35.tar.gz mv pcre-8.35 /usr/local/src/cd /usr/local/src/p…...
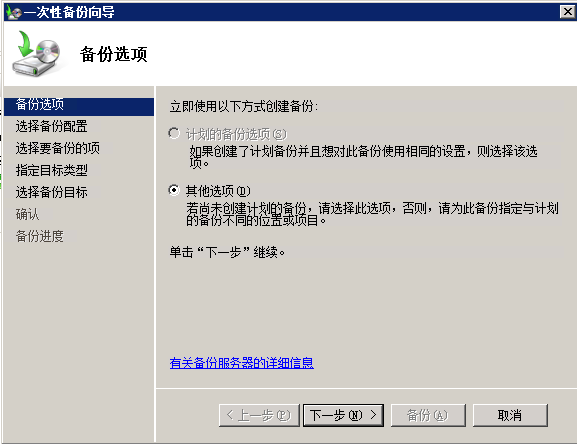
在Windows Server 2008上启用自动文件夹备份
要在Windows Server 2008上启用自动文件夹备份,您可以使用内置的Windows备份功能。下面是如何设置它的方法: 1. 点击“开始”按钮并选择“服务器管理器”,打开“服务器管理器”。 2. 在“服务器管理器”窗口中,单击左侧窗格中的“…...

数据结构—线性表的查找
7.查找 7.1查找的基本概念 问题:在哪里找?——查找表 查找表是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的结构。 问题:什么查找&…...
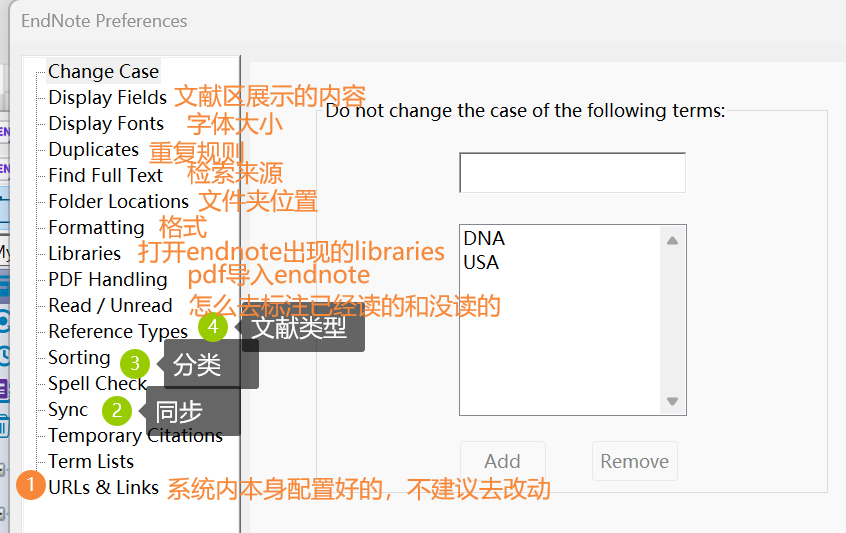
EndNote(一)【界面+功能介绍】
EndNote界面: 顶上小图标的介绍: ①:同步 ②:分享 ③:检索全文 对于第三个(检索全文的功能): (不做任何操作的情况下的界面,检索全文的按钮是灰的&…...

JWT令牌验证
目录 一、JWT介绍 二、安装依赖 三、登陆接口 1、令牌工具类 2、接口代码 四、说明 一、JWT介绍 JWT全称:JSON Web Token (官网:JSON Web Tokens - jwt.io) 定义了一种简洁的、自包含的格式,用于在通信双方以json…...

【微信小程序】下拉刷新功能实现
微信小程序开发系列 文章目录 前言一、onPullDownRefresh函数二、实现1.开启下拉刷新2.监听下拉事件 前言 在开发微信小程序中经常会需要下拉页面进行更新要页面数据的功能,微信小程序提供了onPullDownRefresh函数。该函数作用是监听用户下拉动作。 一、onPullDown…...

观测多模型API调用延迟与稳定性选择合适服务商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观测多模型API调用延迟与稳定性选择合适服务商 在实际项目开发中,直接依赖单一模型服务商可能会面临服务波动或响应延迟…...

一站式解决Windows程序运行问题的Visual C++运行库修复指南
一站式解决Windows程序运行问题的Visual C运行库修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹窗提示"缺少msv…...

IntelliNode:统一AI模型调用,加速Node.js智能应用开发
1. 项目概述:从IntelliNode到智能应用开发的新范式最近在开源社区里,一个名为“IntelliNode”的项目引起了我的注意,更具体地说,是它的核心库intelligentnode/Intelli。乍一看这个名字,你可能会联想到“智能节点”&…...

数说故事解读AI品牌心智:让品牌被AI看见、推荐与信任
当AI全面进入商业决策、智能体成为企业标配,品牌增长逻辑正在发生底层重构:品牌不再只是面对消费者,更需要被AI识别、理解、推荐与信任。数说故事在2026 D3智慧增长大会上提出全新观点——AI品牌心智,将成为AI共生时代品牌最重要的…...

芯片巨头并购软件公司:从硬件竞赛到软硬协同的产业变革
1. 行业现象背后的深层逻辑最近和几个在芯片设计公司和EDA软件公司工作的老朋友聊天,大家不约而同地提到了一个趋势:芯片巨头们的手,伸得越来越长了。以前是买IP核、买制造厂,现在则是频频出手,将一家家软件公司收入囊…...

热潮下的冷思考:从OpenClaw“龙虾”困境看AI Agent的理性选择与国产平替
2026年初,开源AI智能体项目OpenClaw(俗称“小龙虾”)以一种近乎野蛮的方式闯入大众视野。两天内GitHub星标突破17万,线下排队安装,甚至催生了“代装龙虾”的灰色产业。然而,这场技术狂欢的B面,却…...

Windows APK安装工具终极指南:轻松在电脑上安装Android应用
Windows APK安装工具终极指南:轻松在电脑上安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 您是否曾经希望在Windows电脑上直接安装Android…...

别再盲目刷LeetCode了!先把这5个编程基础打牢
文章目录前言一、代码规范:不是“洁癖”,是保命的底线二、函数式编程:不是玄学,是现代开发的通用语言三、Python基础工具:sys模块与可变参数,效率提升10倍的利器四、任务拆解能力:从“写代码”到…...

AI编程助手色彩科学技能库:从OKLCH到APCA的现代色彩实践
1. 项目概述:一个为AI编程助手打造的“色彩科学专家”技能库如果你和我一样,经常在开发与色彩相关的工具、设计系统,或者需要向团队解释为什么某个颜色方案行不通时,总得反复查阅同一堆资料——那个讲解OKLAB色彩空间的视频、那篇…...

Perplexity接入Google Scholar的5大避坑指南:实测失效率下降87%的权威配置方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity接入Google Scholar的整合背景与价值定位 学术信息检索正经历从“关键词匹配”向“语义理解可信溯源”的范式跃迁。Perplexity 作为基于大语言模型的实时问答引擎,其核心优势在于…...