深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么?
近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的内容。在这场技术革命中,Diffusion模型(扩散模型)已成为一股主导力量,催生了许多当前最先进的成果 1。它们凭借其独特的机制,在图像合成、音频生成等多个领域展现出卓越性能,正迅速成为生成式建模领域的新范式 1。
那么,Diffusion模型的核心思想究竟是什么呢?我们可以将其直观地理解为一个“化腐朽为神奇”的过程:从一堆纯粹的随机噪声开始,模型逐步、迭代地将其“雕琢”成一个结构清晰、内容连贯的样本,就像一位雕塑家从一块璞玉中逐渐显露出精美的艺术品 2。这种结构化、分步骤的生成方式,与一些早期模型更为直接的“一步到位”式生成形成了对比,也正是其能够生成高质量、复杂样本的关键所在。这种逐步求精的特性既是其优势(保证质量)的来源,某种程度上也带来了其劣势(生成速度较慢),这一点我们将在后续讨论中反复看到。
Diffusion模型的迅速崛起,不仅归功于其出色的性能,也得益于其核心概念在理解上的相对优雅。一旦掌握了其基本原理,其吸引力便显而易见,这使得它成为学术研究和产业应用的热点。本文将带领读者踏上一段探索Diffusion模型的旅程:从理解其根本的前向与反向过程,到剖析关键的架构组件,再到探讨高级技术、多样化应用,最后展望其面临的挑战与未来前景。
II. Diffusion模型的核心:前向与反向过程
Diffusion模型的核心机制可以分解为两个互补的过程:前向过程(Forward Process)和反向过程(Reverse Process)。前者通过逐步添加噪声来破坏数据结构,后者则学习如何逆转这个过程以生成新数据。
A. 前向过程(Diffusion):系统性地添加噪声
前向过程,也称为扩散过程,是一个固定的、预定义的马尔可夫链(Markov Chain) 5。它从一个干净的原始数据样本(例如一张图像 x0)开始,通过一系列共 T 个时间步(timesteps)逐渐向其添加少量高斯噪声,直至原始信号几乎被噪声完全淹没,最终近似于一个纯粹的高斯噪声分布 5。
关键概念:
- 马尔可夫链: 在这个过程中,每个时刻的噪声状态 xt 仅依赖于其前一个状态 xt−1,而与更早的状态无关 5。
- 高斯噪声: 在每个时间步添加的噪声通常从高斯分布中采样 5。选择高斯噪声并非偶然,而是因为它具有许多便利的数学性质,能够简化许多推导和运算,例如使得我们可以直接、封闭地计算任意时刻 t 的噪声样本 xt 与初始样本 x0 之间的关系 6。
- 方差表 (βt): 控制每个时间步添加噪声量的参数序列,记为 β1,…,βT。通常情况下,βt 会随着时间步 t 的增加而逐渐增大,意味着越往后的步骤加入的噪声越多 5。例如,在DDPM的实验中,βt 从 β1=10−4 线性增加到 βT=0.02 5。
数学直觉 (简化自 5):
前向过程中,从 xt−1 到 xt 的转移可以表示为:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
这个公式的含义是,当前时间步的样本 xt 是通过对前一时间步的样本 xt−1 进行轻微缩放(乘以 1−βt),并加入均值为0、方差为 βt 的高斯噪声得到的。
前向过程的一个显著特性是,我们可以直接从初始样本 x0 采样得到任意时间步 t 的噪声样本 xt,而无需迭代计算。令 αt=1−βt 且 αˉt=∏s=1tαs,则:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
这个封闭形式的表达式对于模型训练至关重要,因为它允许我们高效地生成任意噪声水平的训练样本。
B. 反向过程(Denoising):学习去除噪声
反向过程是Diffusion模型学习和生成数据的核心。其目标是训练一个神经网络来逆转前向的加噪过程。也就是说,给定一个噪声样本 xt 和当前的时间步 t,网络需要预测出对应的前一个、噪声稍小的样本 xt−1,或者更常见地,预测出在前向过程中从 xt−1 变为 xt 时所加入的噪声 ϵ 2。
神经网络的角色 (ϵθ):
通常,一个U-Net架构的神经网络(后续会详细介绍)被用来执行这个去噪任务。它接收当前的噪声样本 xt 和时间步 t 作为输入,输出对所添加噪声 ϵ 的预测,记为 ϵθ(xt,t) 5。反向过程的每一步可以表示为 pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)),其中神经网络学习的目标是均值 μθ。通过预测噪声 ϵθ,我们可以估算出去噪后的均值 5:
μθ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))
这种将反向过程参数化为预测噪声 ϵ 而非直接预测 xt−1 或 x0 的方式,是一个关键的设计选择。它不仅简化了损失函数,而且在实践中也带来了更好的样本质量 5。这凸显了在模型设计中,目标和输出表示的细微选择可能对生成模型的性能产生深远影响。
迭代生成:
实际生成新样本时,过程从一个纯粹的高斯噪声 xT∼N(0,I) 开始,然后迭代地应用学习到的去噪步骤 T 次(从 t=T 到 t=1),每一步都去除一部分噪声,最终得到一个干净的、全新的样本 x0 5。这种迭代式的精炼是Diffusion模型能够生成高质量样本的关键。
前向加噪过程可以看作是为反向去噪过程提供了一个“课程”。通过在训练中让模型学习去除不同噪声水平(对应不同时间步 t)的噪声,模型被迫学习数据从粗糙到精细的各种结构特征。例如,去除高度噪声(t 较大时)需要模型捕捉数据的宏观结构,而去除轻微噪声(t 较小时)则需要模型关注细节。因此,跨越所有时间步的训练促使模型学习到一种层次化的数据特征表示,这可能是其生成样本高保真度的一个重要原因,也解释了为何时间步 t 是去噪网络的一个关键输入。
C. 训练目标:变分下界(ELBO)
Diffusion模型通常通过优化数据对数似然的变分下界(Evidence Lower Bound, ELBO)来进行训练 5。这个目标函数本质上是鼓励模型能够准确地逆转前向扩散的每一步。
虽然ELBO的完整形式较为复杂,但在实践中,一个简化的损失函数通常被采用,它近似于让神经网络 ϵθ(xt,t) 预测在从 x0 得到 xt 的过程中实际加入的噪声 ϵ(利用前述 q(xt∣x0) 的性质)。这通常表现为一个均方误差损失(Mean Squared Error, MSE):
Lsimple=Et,x0,ϵ[∣∣ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∣∣2]
(此公式基于 5 中关于预测 ϵ 的讨论推导)。这个简化的目标将高层次的ELBO概念与一个更具体、更易于理解的训练任务——噪声预测——联系起来。
III. Diffusion模型为何脱颖而出:优势与比较
Diffusion模型并非孤立存在,理解其相对其他主流生成模型(如GANs和VAEs)的优势与劣势,有助于我们更清晰地认识其在生成式AI领域的地位和价值。
A. Diffusion模型 vs. GANs (生成对抗网络)
- 训练稳定性: Diffusion模型通常提供比GANs更稳定的训练过程。GANs因其对抗性训练机制,常面临模式崩溃(mode collapse)、训练动态振荡等问题,导致训练困难 1。相比之下,Diffusion模型通过直接优化一个定义良好的概率目标(如去噪损失),避免了GANs中常见的这些不稳定性问题 1。这种训练目标的内在稳定性是其相较于GANs更易训练的根本原因。
- 模式覆盖与样本多样性: Diffusion模型倾向于更好地覆盖训练数据的多种模式,从而生成更多样化的样本。而GANs可能遭遇模式崩溃,即生成器只产生有限种类的输出,无法捕捉训练数据的完整分布 1。
- 计算效率 (训练 vs. 推理):
- GANs需要同时训练两个网络(生成器和判别器),而Diffusion模型通常只训练一个核心的去噪网络。这使得Diffusion模型的训练在架构层面可能更直接 1。
- 然而,在推理(即生成样本)阶段,GANs通常更快(单次前向传播),而Diffusion模型则需要多步迭代去噪,速度较慢 3。这是一个重要的权衡。
- 其他优势: Diffusion模型无需额外训练即可用于解决一些逆问题(如图像修复)7,并且对超参数的敏感度较低 1。
B. Diffusion模型 vs. VAEs (变分自编码器)
- 样本质量: Diffusion模型通常能生成比VAEs更高保真度、更清晰的样本。VAEs的生成结果常带有一定的模糊感 3。
- 潜空间: VAEs显式地学习一个压缩的潜空间 z(通常带有高斯先验),这对于表示学习很有用。而Diffusion模型的“潜变量”是与原始数据维度相同的一系列噪声版本 x1,…,xT,其“潜空间”不像VAEs那样直接可解释为一个单一的、压缩的表示 5。可以将Diffusion模型视为自编码器概念的一个强大扩展,但它专注于跨多个噪声水平的去噪任务以实现生成,而不是像传统VAEs那样通过显式的信息瓶颈来学习压缩表示 6。
- 训练: 两者都属于基于似然的模型,训练过程通常都比较稳定 3。
目前,尽管Diffusion模型在生成速度上存在劣势,但其在样本质量和多样性上的卓越表现,使得研究界和实践者更倾向于选择它们,并积极研究缓解其速度瓶颈的方法。这反映出当前领域内对高质量输出的偏好,即便以一定的计算成本为代价。
表1: 主流生成模型对比概览
为了更直观地比较这些模型,下表总结了它们的一些关键特性:
| 特性 | Diffusion模型 | GANs (生成对抗网络) | VAEs (变分自编码器) |
| 训练稳定性 | 通常稳定 1 | 常不稳定,训练困难 1 | 稳定 3 |
| 样本质量 | 非常高,业界领先 2 | 可能很高,但易产生伪影 3 | 常较模糊,清晰度较低 3 |
| 样本多样性 | 较好,模式覆盖更优 1 | 易发生模式崩溃 1 | 较好 |
| 采样速度 | 慢 (迭代式) 3 | 快 (单次前向传播) 3 | 快 (单次前向传播) 3 |
| 理论基础 | 基于似然,得分匹配 5 | 博弈论,最小最大优化 | 基于似然,变分推断 |
| 主要挑战 | 采样慢,计算成本高 3 | 训练不稳定,模式崩溃 1 | 样本保真度较低 3 |
| 逆问题解决 | 无需额外训练即可解决 7 | 通常需要特定训练/架构 | 不太直接适用 |
| 超参数敏感度 | 敏感度较低 1 | 高敏感度 | 中等敏感度 |
此表为理解Diffusion模型在生成模型大家族中的定位提供了一个有价值的参考。
IV. 深入内部:关键架构构建模块
Diffusion模型,尤其是用于图像生成的模型,其核心的去噪网络通常依赖于一些精心设计的架构组件。其中,U-Net和注意力机制扮演着至关重要的角色。
A. U-Net架构:去噪网络的中坚力量
U-Net是一种卷积神经网络架构,因其图形表示呈“U”形而得名 10。它最初是为生物医学图像分割任务设计的 10,但其独特的结构使其非常适合作为Diffusion模型中的去噪网络,尤其是在处理图像这类具有空间结构的数据时 2。
- 结构: U-Net主要由两部分组成:
- 编码器 (Encoder) / 下采样路径 (Downsampling Path): 这部分通过一系列卷积层和池化层(或步进卷积)逐渐减小特征图的空间尺寸,同时增加通道数(特征数量)。这个过程旨在捕捉图像的上下文信息和高级语义特征 10。
- 解码器 (Decoder) / 上采样路径 (Upsampling Path): 这部分通过反卷积(或转置卷积)和上采样操作逐渐恢复特征图的空间尺寸,最终目标是生成与输入噪声图像同样大小的去噪结果(或噪声预测)10。
- 跳跃连接 (Skip Connections): U-Net架构的一个标志性特征是其“跳跃连接”。这些连接将编码器中特定层级的特征图直接传递并拼接(concatenate)到解码器中对应层级的特征图上 10。
- 功能: 在编码器下采样的过程中,一些精细的空间细节(如边缘、纹理)可能会丢失。跳跃连接允许解码器直接访问这些来自编码器早期阶段的高分辨率特征,从而在重建过程中更好地恢复这些细节,生成更清晰、更精确的输出 10。
- 直观理解: 想象U-Net的处理流程。当数据(图像的某种表示)沿着“U”的一臂(编码器)向下传递时,它被不断压缩,模型学习“图像中有什么”。当它沿着另一臂(解码器)向上传递时,它被逐渐放大以重建图像。跳跃连接就像横跨“U”形两臂的桥梁,将编码器早期阶段(分辨率较高)的精细细节信息(如边缘和纹理)直接输送给解码器中相应的阶段。这确保了解码器不必完全依赖于经过高度压缩的瓶颈层表示来“重新发明”所有细节,从而产生更锐利、细节更丰富的输出。
U-Net在Diffusion模型中的成功,并不仅仅因为它能进行多尺度处理。其固有的编码器-解码器结构加上跳跃连接,与去噪任务的概念高度契合:编码器捕捉带噪输入的上下文信息,识别信号与噪声;解码器在跳跃连接提供的未损坏或损坏较少的早期特征的辅助下,重建出更清晰的版本(或预测噪声)。这种结构上的内在偏置(inductive bias)与迭代去噪问题的高度一致性,解释了为何U-Net已成为Diffusion模型(尤其是DDPMs 2)中如此基础且效果显著的组件。
B. 注意力机制:聚焦关键信息
注意力机制(Attention Mechanisms)赋予模型在进行预测时,动态地权衡输入数据不同部分(或其自身内部表示)重要性的能力,从而提升生成质量和一致性 13。
-
自注意力 (Self-Attention):
- 功能: 允许模型理解正在生成的图像(或其特征表示)内部不同空间区域或特征之间的关系。例如,在生成人脸时,自注意力可以帮助确保眼睛和嘴巴的位置在全局上保持协调,即使它们在图像中相距较远 13。这对于在高分辨率图像生成中维持远距离依赖性(例如,天空颜色与地平线的一致性)尤为关键。
-
交叉注意力 (Cross-Attention):
- 功能: 对于条件生成(例如,文本到图像的转换)至关重要。它允许模型将来自条件信号(如文本提示的嵌入向量)的信息与正在生成的视觉特征相关联起来 13。当文本提示中提到“桌子上的红苹果”时,交叉注意力机制会引导模型在图像生成过程中,重点关注与“红色”、“苹果”和“桌子”相对应的区域,同时抑制不相关的细节 13。
- 交叉注意力的整合是Diffusion模型从无条件生成器转变为高度可控的条件生成器(如文本到图像模型)的关键一步,极大地扩展了它们的实际应用范围。
-
计算成本: 需要注意的是,注意力机制,尤其是自注意力,其计算成本可能很高(通常与输入序列长度的平方成正比)。这促使研究者开发各种优化策略,例如仅在较低分辨率的特征图上应用注意力,或使用窗口化注意力(将像素分组到较小区域内部分别计算注意力)等,以在保留注意力优势的同时降低计算负担 13。
尽管U-Net因其在图像处理中的卓越表现而成为Diffusion模型的主流选择,但基于Transformer的架构(如DiT 8)也开始在去噪网络中崭露头角。这预示着一种趋势,即利用Transformer的强大扩展能力和全局关系建模能力,可能克服基于CNN的U-Net在处理超大规模模型或复杂长程依赖性时的一些局限性。这表明Diffusion模型的“骨干网络”可能会持续演进,特别是在模型需要扩展以处理更高分辨率或更复杂条件输入时。对高效U-Net架构的设计仍在积极探索中 15。
V. 提升性能与控制力:高级Diffusion技术
随着Diffusion模型的发展,一系列高级技术被提出,旨在提高其效率、生成质量以及可控性。其中,潜扩散模型(LDMs)和无分类器指导(CFG)是两个里程碑式的进展。
A. 潜扩散模型 (Latent Diffusion Models, LDMs):通过潜空间提升效率
标准的Diffusion模型直接在像素空间进行操作。对于高分辨率图像而言,像素空间维度极高,这使得扩散过程(尤其是多步迭代)的计算成本非常巨大,对内存和计算资源都提出了严峻挑战 16。
- 动机: 为了解决这一问题,潜扩散模型(LDMs)应运而生。其核心思想是将扩散过程从高维像素空间转移到低维的潜空间(latent space)中进行,从而显著降低计算复杂度 16。
- VAE (变分自编码器) 的角色: LDMs利用一个预训练好的VAE。
- 编码器: VAE的编码器首先将输入的图像从像素空间压缩到一个维度较低但信息密度更高的潜表示。
- 解码器: VAE的解码器则负责在扩散过程结束后,将潜空间中生成的表示映射回像素空间,重建出最终图像 17。
- 潜空间中的扩散: 真正的前向加噪和反向去噪过程(如第二节所述)都在这个低维潜空间中进行。LDM中的U-Net也是在这些潜表示上操作的 17。由于潜空间的维度远小于像素空间,模型训练和推理所需的计算能力和内存都大幅减少,使得生成高分辨率图像更为可行 17。
- LDM的关键组件 (据 17):
- CLIP文本编码器 (可选,用于条件生成): 将输入的文本提示转换为嵌入向量,用于指导生成过程。
- VAE: 负责图像与潜空间之间的压缩与解压缩。
- U-Net: 在潜空间中预测噪声,通常会接收时间步和条件嵌入(如文本嵌入)作为额外输入。
LDMs的出现是一项关键的实践创新,它通过将感知压缩(由VAE完成)与生成扩散过程解耦,在没有显著牺牲质量的前提下实现了巨大的效率提升,从而使得强大的高分辨率Diffusion模型能够被更广泛地使用和研究,例如著名的Stable Diffusion模型就是一种LDM。
B. 无分类器指导 (Classifier-Free Guidance, CFG):精准引导生成
无分类器指导(CFG)是一种无需训练额外分类器网络,就能显著增强生成样本与给定条件(如文本提示)的一致性,并常常提升整体样本质量的技术 11。
- 目的: CFG旨在平衡生成结果的多样性与对条件输入的遵循度 11。
- 直观解释 (综合 4):
- 训练阶段: 在训练U-Net去噪模型时,会以一定的概率随机丢弃条件信息。例如,对于文本到图像任务,有时会用文本提示作为条件输入训练模型,有时则用一个空字符串或特殊的“无条件”标记作为输入进行训练。这使得同一个U-Net模型学会了同时进行有条件(ϵθ(xt,t,condition))和无条件(ϵθ(xt,t,∅))的噪声预测 20。
- 推理阶段: 在生成样本的每个去噪步骤中,模型会同时进行有条件和无条件的噪声预测。
- 最终用于实际去噪的噪声预测 ϵ^ 是这两个预测值的一个线性组合(实际上是外插): ϵ^=ϵθ(xt,t,∅)+w⋅(ϵθ(xt,t,condition)−ϵθ(xt,t,∅)) 其中,w 是指导强度(guidance scale)参数。当 w=0 时,生成完全无条件的样本;当 w=1 时,相当于只使用有条件预测;当 w>1 时,会放大有条件预测与无条件预测之间的差异,从而更强调条件信息 19。
- 权衡: 使用CFG时,指导强度 w 的选择是一个权衡。较高的 w 值能使生成结果更贴合文本提示,但也可能降低样本的多样性,甚至导致生成图像过于饱和、出现伪影(所谓的“炸图”现象)11。
CFG可以被视为一种巧妙的技巧,它通过利用模型同时学习条件分布和无条件分布的能力,有效地通过放大“条件信号”(即有条件预测与无条件预测之差)来引导生成过程。这对于基于提示的生成(如文本生成图像)是一个突破,极大地提升了这类模型的可控性和输出质量。
C. 更快的采样:DDIM及其他方法 (简述)
Diffusion模型反向过程的迭代特性(通常需要数百到数千步)使其采样速度非常缓慢,这是其实际应用中的一个主要瓶颈 2。
- 去噪扩散隐式模型 (Denoising Diffusion Implicit Models, DDIM): DDIM通过引入一种非马尔可夫的前向过程,允许在推理时采用更大的步长进行采样,从而在无需重新训练模型的情况下显著减少采样所需的总步数,加快生成速度 2。
- 其他加速方法 (据 8):
- 减少采样步数: 例如,DPM-Solvers通过使用更高级的数值方法来优化采样轨迹,从而用更少的步骤达到相似的生成质量。
- 降低每步成本: 包括模型剪枝(去除冗余参数)、量化(使用低精度表示参数)、缓存机制(复用先前计算结果)等。
- 知识蒸馏: 训练一个参数量更小或结构更简单的“学生”模型,使其能够用更少的步数模仿原始“教师”模型的生成效果 21。
对更快采样技术(如DDIM、DPM-Solvers、蒸馏等)的持续关注,凸显了推理速度是Diffusion模型最主要的实际瓶颈。克服这一瓶颈对于其在实时应用和更广泛部署中至关重要。
VI. Diffusion模型的应用实践:广阔的应用谱系
Diffusion模型凭借其强大的生成能力,已在众多领域展现出惊人的应用潜力,从艺术创作到科学发现,其影响日益深远。
A. 文本到图像合成
这无疑是Diffusion模型最为人所熟知的应用。诸如Stable Diffusion、DALL·E系列和Imagen等模型,能够根据用户输入的文本描述生成高度细致、富有创意甚至达到照片级逼真度的图像 3。这些模型的成功,很大程度上得益于交叉注意力机制(用于关联文本与图像特征)13、无分类器指导(用于增强文本符合度)18以及潜扩散模型(用于高效处理高分辨率图像)16等关键技术的支撑。
B. 高分辨率图像生成与编辑
Diffusion模型不仅能生成图像,还擅长生成高分辨率图像(例如1024x1024像素,甚至通过专门技术达到4K分辨率)22。例如,Diffusion-4K等研究工作正致力于直接生成超高分辨率图像,并提出了如基于小波的微调等方法 22。此外,它们在图像编辑方面也大有可为,包括图像修复(inpainting,填充图像缺失部分)、图像外延(outpainting,扩展图像边界)以及风格迁移等 14。
C. 视频生成
视频生成是Diffusion模型正在迅速拓展的一个前沿领域。OpenAI的Sora和RunwayML的Gen-2等模型已经展示了从文本生成视频片段或将静态图像转化为动态视频的能力 24。Sora模型利用了扩散过程和Transformer架构,不仅能生成视频,还能对现有图像进行动画化处理以及进行视频到视频的编辑 24。尽管面临着保持时间一致性、建模复杂动态以及高计算成本等挑战,但其进展速度惊人。
D. 音频与音乐生成
Diffusion模型在音频领域同样表现出色,被广泛应用于语音合成(文本到语音TTS)、语音增强、音乐创作和通用音效生成等任务。DiffWave 1 和AudioGen (Meta's AudioCraft框架的一部分) 26 是该领域的代表性模型。它们能够生成高质量、听感自然的语音和音乐,甚至可以对生成音频的音高、能量等属性进行细粒度控制 1。
E. 3D内容创作
从文本或图像生成3D形状、纹理和场景是Diffusion模型的另一个令人兴奋的应用方向。这类技术通常利用预训练的2D Diffusion模型作为强大的先验知识,来指导3D表示(如神经辐射场NeRFs)的学习。DreamFusion 28 和Magic3D 28 通过从不同视角渲染3D模型并使用2D Diffusion模型进行评分和优化,实现了从文本到3D模型的生成。Kiss3DGen则通过微调2D Diffusion模型来生成多视图图像和法线图,进而重建3D模型 29。
F. 科学与医学应用
- 医学图像分析: Diffusion模型可用于生成合成医学图像以扩充数据集、进行图像重建(如从低剂量CT重建高质量图像)、图像分割(如肿瘤识别)和异常检测 1。例如,它们已被用于生成合成电子健康记录(EHR)数据,以支持急诊环境下的机器学习应用 1,以及合成足部X光片用于辅助诊断 12。
- 分子设计与药物发现: 在生物医药领域,Diffusion模型被用于生成具有特定期望性质的新型分子结构,有望加速新药的研发过程 3。
Diffusion模型之所以能在图像、视频、音频、3D乃至科学数据等多种模态上取得成功,根本原因在于其核心扩散过程的普适性。它是一种学习如何将噪声结构化为符合特定数据分布的通用方法。只要数据能够被表示为允许逐步加噪和去噪的形式,Diffusion模型就有潜力被应用于该领域,其威力通过与针对特定模态的合适网络架构(如用于图像的U-Net,或用于序列数据的含时序组件的网络)和条件化机制相结合而得以释放。
在将Diffusion模型扩展到更复杂或结构化数据(如3D或视频)时,一个常见的模式是利用预训练的2D图像Diffusion模型作为强大的先验或指导。例如,3D生成方法常通过从不同视角渲染3D候选对象,并利用2D文本到图像模型来评估或优化这些2D视图,从而将2D模型的强大视觉知识迁移到3D领域 28。这种从强大的基础模型中“蒸馏”知识到新领域的方法,是人工智能领域的一个重要趋势,它正在加速那些数据稀缺或直接从头建模难度较大的领域的进展。
同时,Diffusion模型的演进轨迹清晰地显示出从无条件生成到条件生成,再到如今追求细粒度可控生成的趋势 27。这表明Diffusion模型正从单纯的“样本生成器”转变为多功能的“内容创作工具”,赋予用户更强的指导能力。
VII. 挑战导航与未来展望
尽管Diffusion模型取得了巨大成功,但它们仍面临一些固有的挑战。同时,这个领域的研究日新月异,未来的发展方向也充满机遇。
A. 主要障碍
- 计算成本与缓慢的推理速度: 这是Diffusion模型最显著的挑战之一。迭代式的去噪过程在计算上是密集型的,导致模型训练和样本生成都非常耗时,且对硬件资源要求较高 3。虽然已有多种缓解策略,如更快的采样算法(DDIM、DPM-Solvers)、潜扩散(LDMs)、模型压缩与剪枝以及硬件加速等 8,但这仍然是制约其广泛应用,尤其是在资源受限设备或实时场景中的关键瓶颈。
- 高分辨率/高维数据的可扩展性: 尽管LDMs等技术有所帮助,但将Diffusion模型扩展到极高分辨率(如4K视频)或非常复杂的3D场景时,仍然面临巨大的计算和内存挑战 9。
- 可解释性与可控性: 虽然CFG和注意力机制等技术提升了可控性,但深入理解模型为何生成特定输出,或者实现高度精细化、可预测的控制,目前仍有难度 9。
- 模式崩溃与多样性 (虽优于GANs,仍需关注): 尽管Diffusion模型在模式覆盖和样本多样性方面通常优于GANs,但确保完全捕捉复杂数据分布的每一种模式,并避免 subtle 形式的模式塌陷或内容重复,有时仍具挑战性 9。
- 伦理考量:
- 滥用风险: 生成深度伪造(deepfakes)、虚假信息或有害内容 9。
- 偏见问题: 模型可能学习并放大训练数据中存在的偏见 9。
- 社会影响: 可能涉及就业岗位替代、知识产权等问题 9。
Diffusion模型的主要挑战,如速度、成本和可控性,与其核心优势——迭代式、高维度的生成过程——紧密相关。每一个迭代步骤虽然能提升保真度,但也增加了计算开销,并且如果引导不当,可能会累积误差。因此,使得Diffusion模型强大的机制本身,也构成了其实际应用的主要限制。
B. 未来方向 (基于 9)
- 提升效率: 持续研究更快的采样算法、更高效的模型架构(可能包括对U-Net和Transformer的改进或替代方案)以及软硬件协同设计,以降低计算需求和推理延迟 9。
- 增强可控性与可编辑性: 开发更直观、更细粒度的控制方法,使用户能够更精确地指导生成过程,并方便地对已生成内容进行编辑和修改。
- 理论理解的深化: 对Diffusion模型为何如此有效进行更深入的数学分析,包括其收敛性质、学习到的得分函数的几何特性等 9。更扎实的理论基础有望指导更具原则性的方法来解决现有挑战,例如设计出更高效的采样器或保证多样性的新机制,甚至可能催生全新的生成模型范式。
- 多模态整合: 构建能够无缝生成并在不同数据类型(如文本、图像、音频、视频、3D)之间进行转换的统一框架,实现更丰富的跨模态交互与创作 9。
- 负责任的人工智能开发: 发展稳健的AI生成内容检测技术,缓解模型偏见,并建立完善的伦理准则和部署规范,确保Diffusion模型的健康发展和负责任应用 9。
Diffusion模型未来的发展方向表明该技术正在走向成熟——从展示原始的生成能力,转向创造更实用、更可靠、功能更全面,并能负责任地融入现实世界应用的工具。这需要解决上述的实际挑战和伦理问题。
VIII. 结论:不断扩展的Diffusion模型宇宙
本文带领读者回顾了Diffusion模型的核心原理——从前向加噪到反向去噪的优雅范式,探讨了其关键的架构选择如U-Net和注意力机制,介绍了如潜扩散模型(LDMs)和无分类器指导(CFG)等旨在提升性能与控制力的先进技术,并一览了其在文本到图像、视频、音频、3D内容创作乃至科学研究等广阔领域中的多样化应用。
Diffusion模型无疑对生成式AI领域产生了变革性的影响。它们在样本质量、多样性和训练稳定性方面的优势使其脱颖而出,但也面临着推理速度较慢等固有挑战。然而,正如我们所见,Diffusion模型是一个飞速发展的领域,研究人员正积极致力于克服现有局限并探索新的前沿。从最初的概念提出到如今达到业界顶尖水平,其发展历程堪称迅速,而创新的步伐仍在继续。
Diffusion模型的发展叙事是一个快速崛起并持续优化的过程,它由理论洞察、架构创新和实际应用需求之间的良性循环所驱动。最初的基础性论文点燃了火花 5,随后架构上的改进(如U-Net的应用 2)和关键技术(如LDMs 16 和CFG 18)迅速跟进,极大地提升了模型的质量和实用性。这催生了令人惊叹的应用(如文本生成图像和视频 24),而这些应用反过来又进一步激发了对更高效率 8 和新功能(如3D生成 28)的研究。这种基础理解、工程解决方案与应用需求之间的动态相互作用,是该领域保持高速创新活力的关键。
展望未来,随着研究的不断深入和技术的持续迭代,Diffusion模型有望继续在人工智能和创意产业的版图上描绘出更加精彩的图景。
IX. 进一步探索 (可选资源)
对于希望更深入了解Diffusion模型的读者,以下是一些有价值的资源:
- 开创性论文:
- "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" (Sohl-Dickstein et al., 2015) - 早期奠基性工作。
- "Denoising Diffusion Probabilistic Models" (Ho, Jain, Abbeel, 2020) - DDPM论文,对后续研究产生重大影响 5。
- "High-Resolution Image Synthesis with Latent Diffusion Models" (Rombach et al., 2022) - 潜扩散模型(LDM)论文,Stable Diffusion的基础。
- "Classifier-Free Diffusion Guidance" (Ho & Salimans, 2022) - CFG论文 19。
- 开源实现与平台:
- Hugging Face Diffusers 库:提供了大量预训练的Diffusion模型和便捷的调用接口。
- Stable Diffusion 开源代码:了解LDM具体实现细节的宝贵资源。
- 特定主题的深入阅读:
- 关于Diffusion模型数学理论的综述文章或课程笔记。
- 针对特定应用领域(如医学影像、音频生成)的最新研究进展。
相关文章:

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...
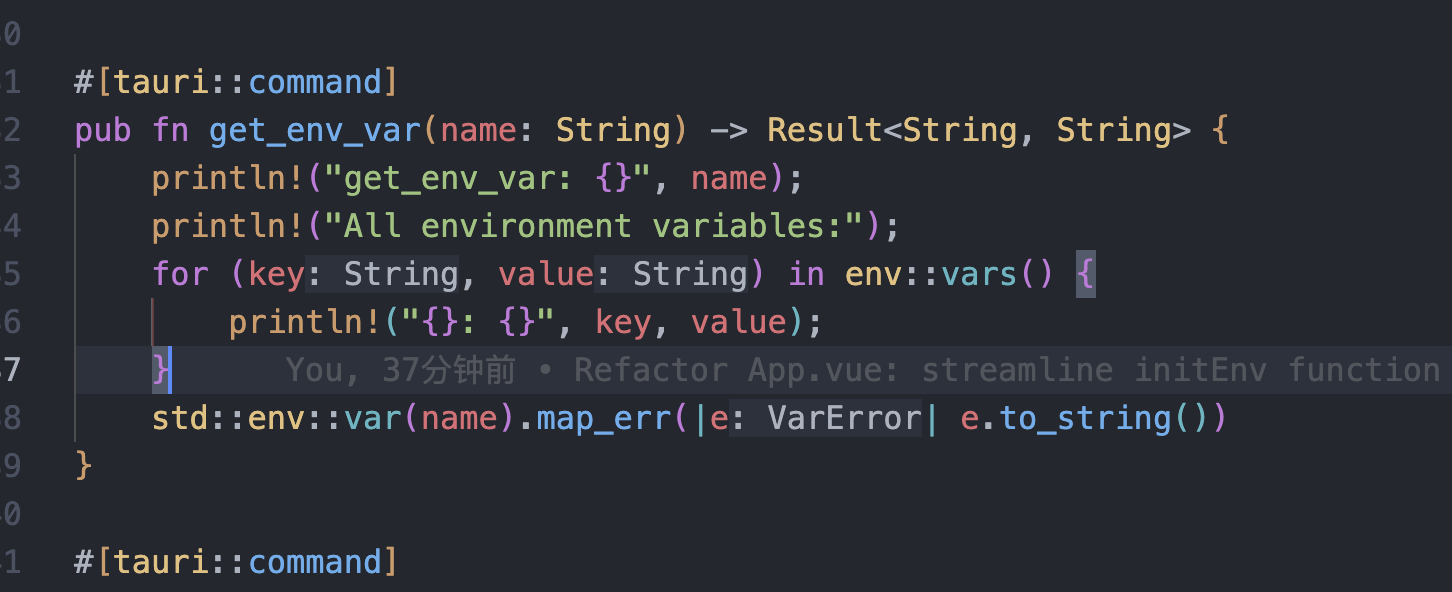
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...
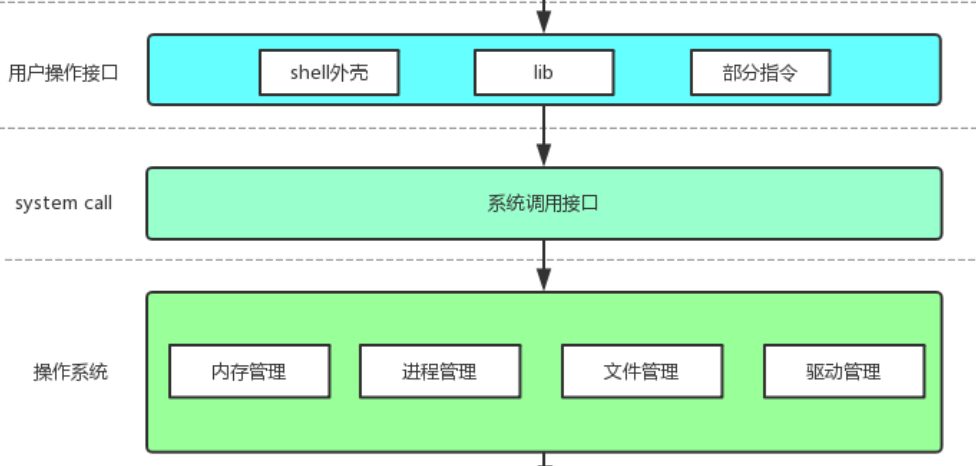
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
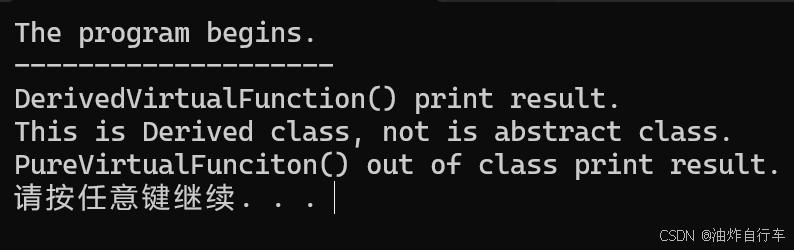
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
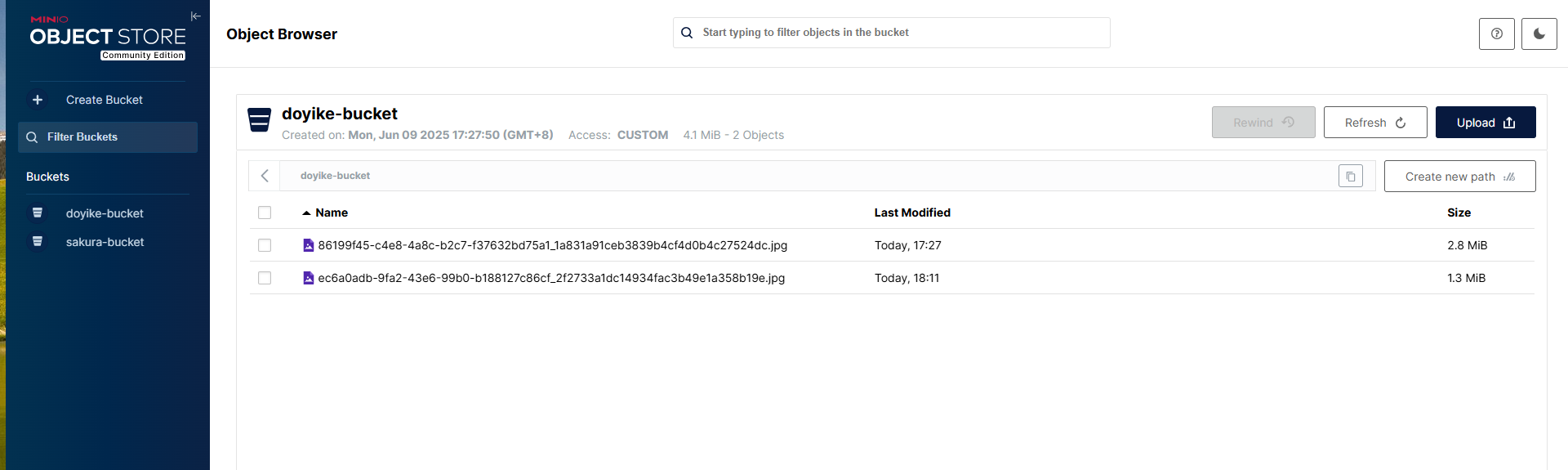
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...