ViT模型架构和CNN区别
目录
Vision Transformer如何工作
ViT模型架构
ViT工作原理解析
步骤1:将图片转换成patches序列
步骤2:将patches铺平
步骤3:添加Position embedding
步骤4:添加class token
步骤5:输入Transformer Encoder
步骤6:分类
总结
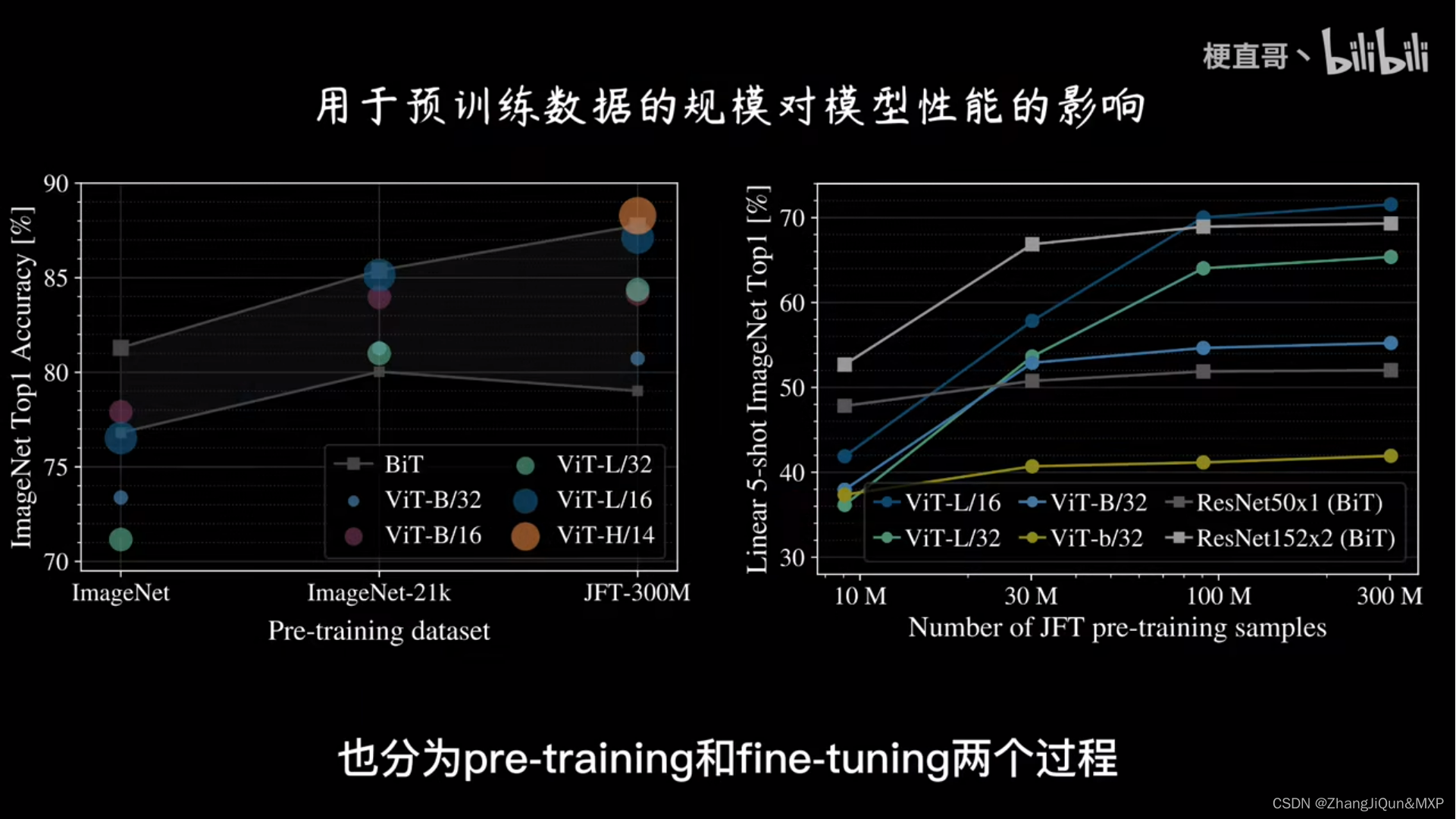
Vision Transformer(VIT)与卷积神经网络(CNN)相比
数据效率和泛化能力:
可解释性和可调节性:
Vision Transformer如何工作
我们知道Transformer模型最开始是用于自然语言处理(NLP)领域的,NLP主要处理的是文本、句子、段落等,即序列数据。但是视觉领域处理的是图像数据,因此将Transformer模型应用到图像数据上面临着诸多挑战,理由如下:
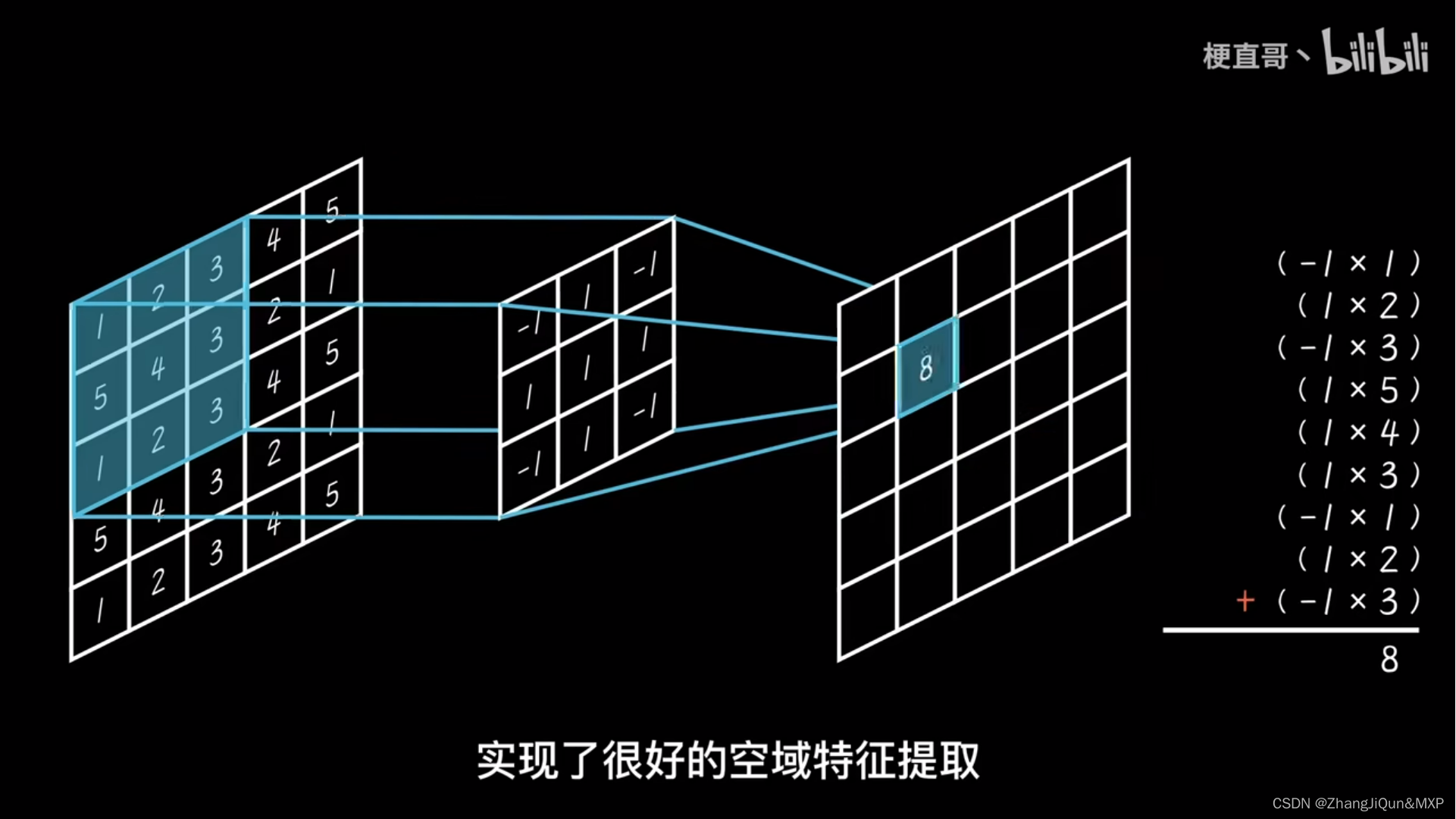
- 与单词、句子、段落等文本数据不同,图像中包含更多的信息,并且是以像素值的形式呈现。
- 如果按照处理文本的方式来处理图像,即逐像素处理的话,即使是目前的硬件条件也很难。
- Transformer缺少CNNs的归纳偏差,比如平移不变性和局部受限感受野。
- CNNs是通过相似的卷积操作来提取特征,随着模型层数的加深,感受野也会逐步增加。但是由于Transformer的本质,其在计算量上会比CNNs更大。
- Transformer无法直接用于处理基于网格的数据,比如图像数据。
为了解决上述问题,Google的研究团队提出了ViT模型,它的本质其实也很简单,既然Transformer只能处理序列数据,那么我们就把图像数据转换成序列数据就可以了呗。下面来看下ViT是如何做的。
ViT模型架构
我们先结合下面的动图来粗略地分析一下ViT的工作流程,如下:
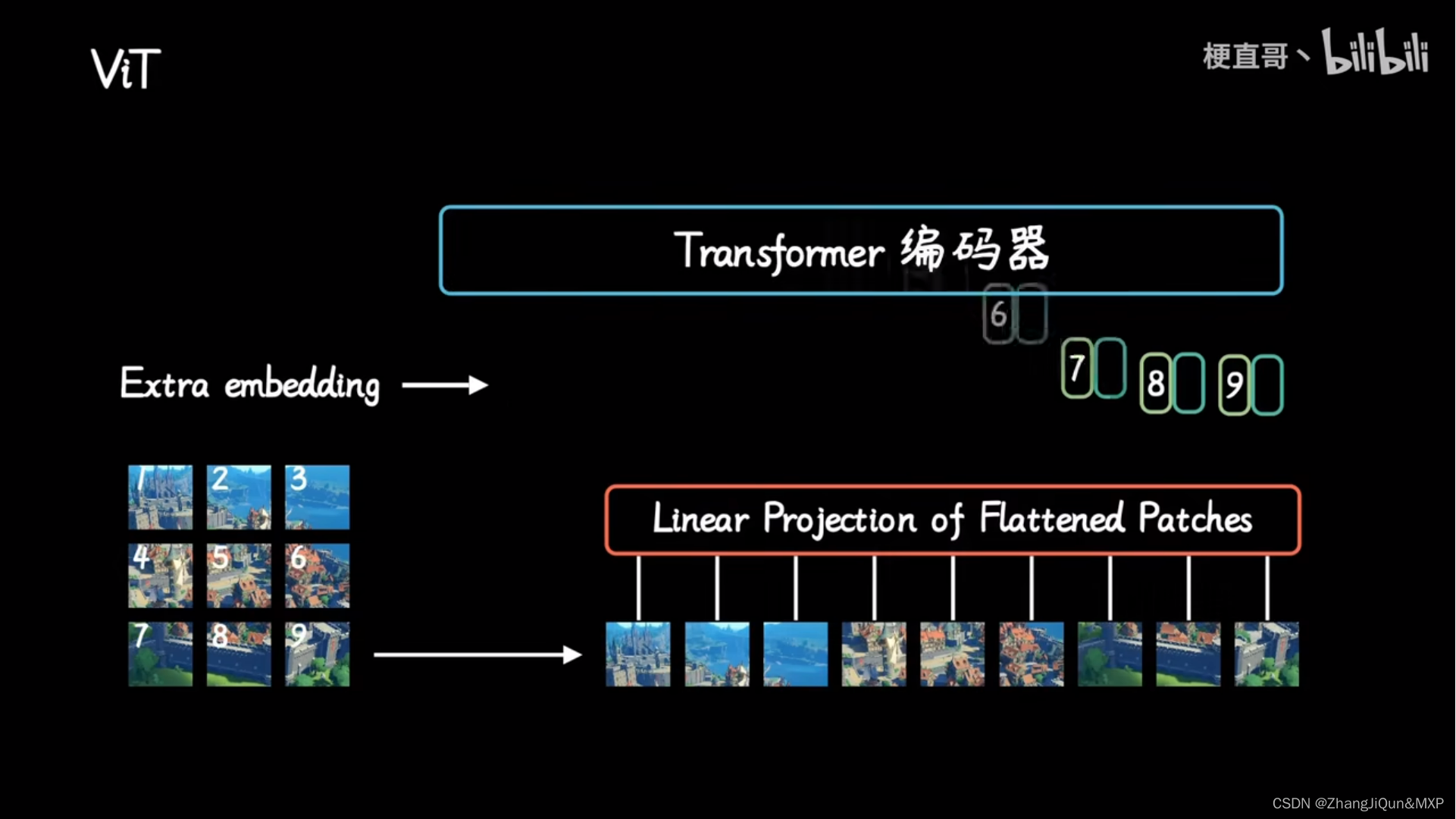
- 将一张图片分成patches;
- 将patches铺平;
- 将铺平后的patches的线性映射到更低维的空间;
- 添加位置embedding编码信息;
- 将图像序列数据送入标准Transformer encoder中去;
- 在较大的数据集上预训练;
- 在下游数据集上微调用于图像分类。
ViT工作原理解析
我们将上图展示的过程近一步分解为6步,接下来一步一步地来解析它的原理。如下图:
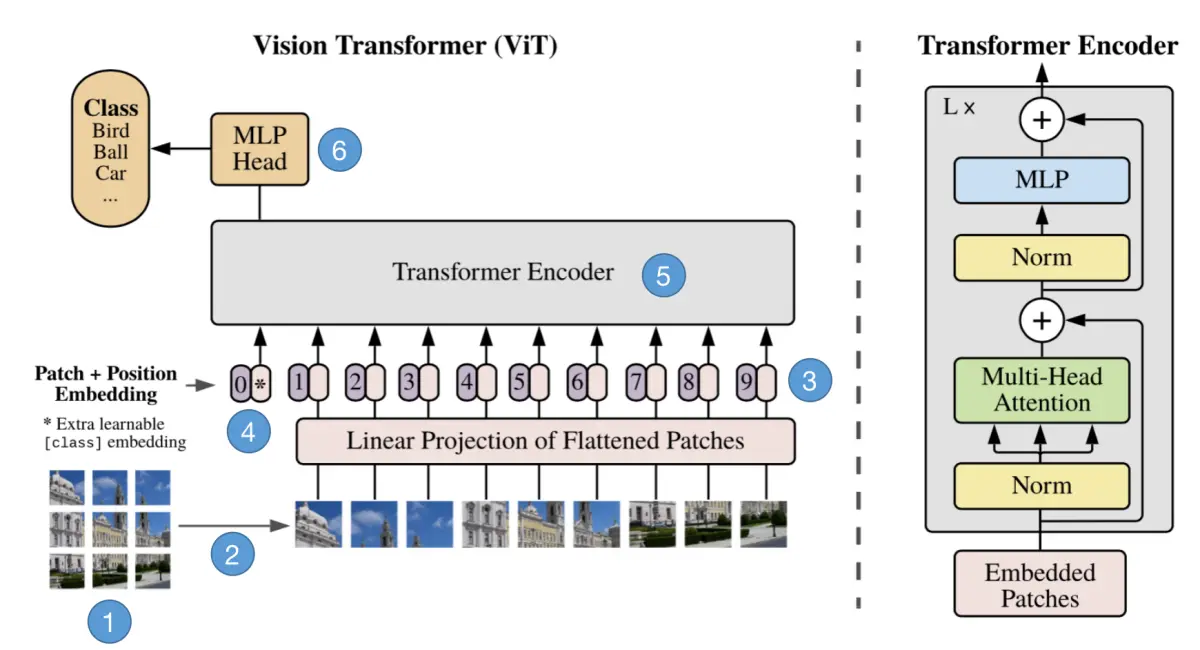
步骤1:将图片转换成patches序列
这一步很关键,为了让Transformer能够处理图像数据,第一步必须先将图像数据转换成序列数据,但是怎么做呢?假如我们有一张图片: x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C,patch 大小为 p p p,那么我们可以创建 N N N个图像 patches,可以表示为 x p ∈ R ( p 2 C ) x_p \in R^{(p^2C)} xp∈R(p2C),其中 N = H W P 2 N = \frac{HW}{P^2} N=P2HW, N N N就是序列的长度,类似一个句子中单词的个数。在上面的图中,可以看到图片被分为了9个patches。
步骤2:将patches铺平
在原论文中,作者选用的 patches 大小为16,那么一个 patch 的 shape 为(3, 16, 16),维度为3,将它铺平之后大小为3x16x16=768。即一个 patch 变为长度为 768 的向量。
不过这看起来还是有点大,此时可以使用加一个 Linear transformation,即添加一个线性映射层,将 patch 的维度映射到我们指定的 embedding 的维度,这样就和NLP中的词向量类似了。
步骤3:添加Position embedding
与 CNNs 不同,此时模型并不知道序列数据中的 patches 的位置信息。所以这些 patches 必须先追加一个位置信息,也就是图中的带数字的向量。
实验表明,不同的位置编码 embedding 对最终的结果影响不大,在 Transformer 原论文中使用的是固定位置编码,在 ViT 中使用的可学习的位置 embedding 向量,将它们加到对应的输出 patch embeddings 上。文章来源地址https://www.yii666.com/blog/433888.html
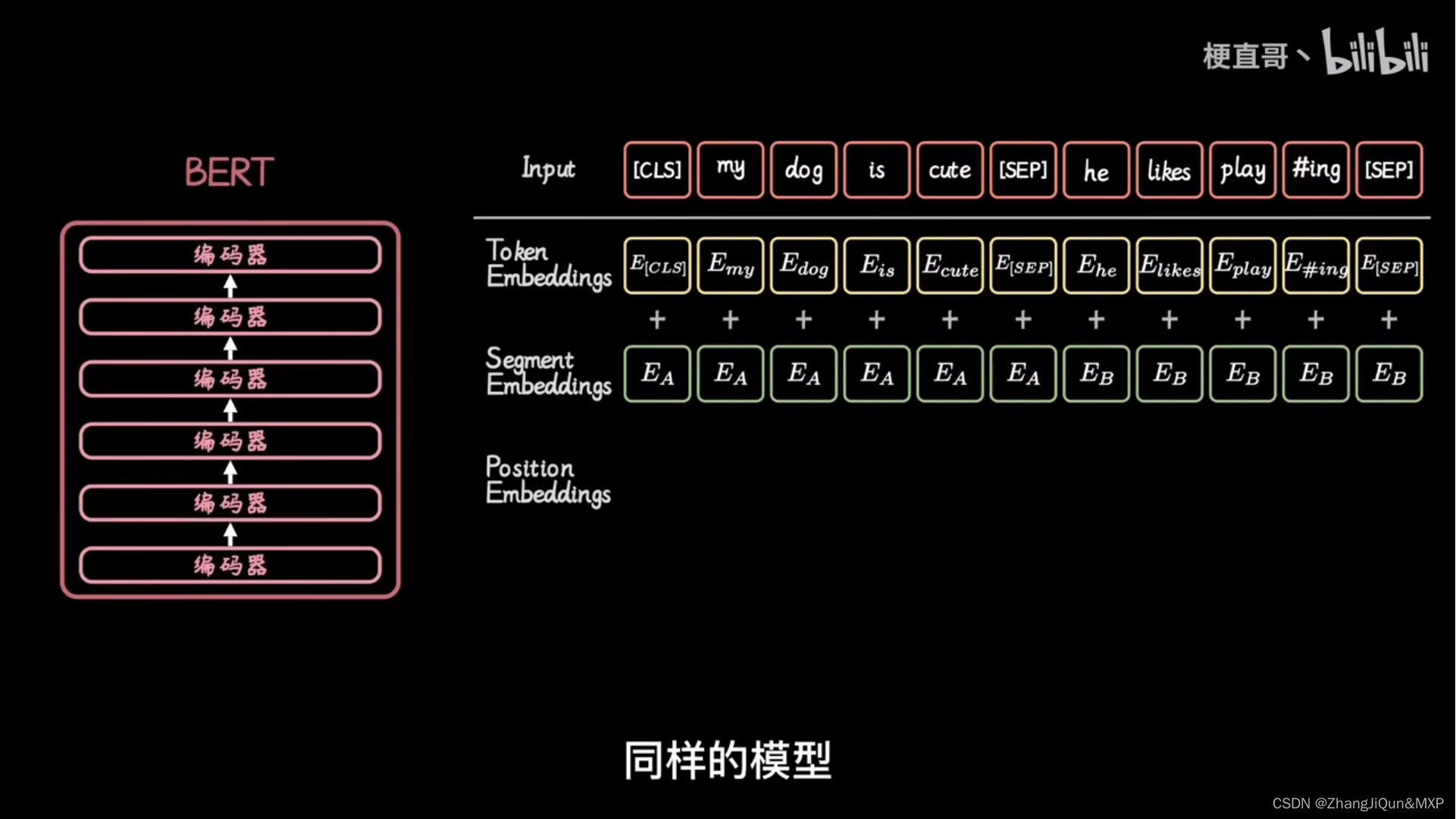
步骤4:添加class token
在输入到Transformer Encoder之前,还需要添加一个特殊的 class token,这一点主要是借鉴了 BERT 模型。
添加这个 class token 的目的是因为,ViT 模型将这个 class token 在 Transformer Encoder 的输出当做是模型对输入图片的编码特征,用于后续输入 MLP 模块中与图片 label 进行 loss 计算。
步骤5:输入Transformer Encoder
将 patch embedding 和 class token 拼接起来输入标准的Transformer Encoder中。
步骤6:分类
注意 Transformer Encoder 的输出其实也是一个序列,但是在 ViT 模型中只使用了 class token 的输出,将其送入 MLP 模块中,去输出最终的分类结果。
总结
ViT的整体思想还是比较简单,主要是将图片分类问题转换成了序列问题。即将图片patch转换成 token,以便使用 Transformer 来处理。
听起来很简单,但是 ViT 需要在海量数据集上预训练,然后在下游数据集上进行微调才能取得较好的效果,否则效果不如 ResNet50 等基于 CNN 的模型。
Vision Transformer(VIT)与卷积神经网络(CNN)相比
在某些情况下可以表现出更强的性能,这是由于以下几个原因:
全局视野和长距离依赖:ViT引入了Transform模型的注意力机制,可以对整个图像的全局信息进行建模。相比之下,CNN在处理图像时使用局部感受野,只能捕捉图像的局部特征。
ViT通过自注意力层可以建立全局关系,并学习图像中不同区域之间的长距离依赖关系,从而更好地理解图像的结构和语义。
可学习的位置编码:ViT通过对输入图像块进行位置编码,将位置信息引入模型中。这使得ViT可以处理不同位置的图像块,并学习它们之间的位置关系,
相比之下,CNN在卷积和池化过程中会导致空间信息的丢失,对位置不敏感。
数据效率和泛化能力:
ViT在大规模数据集上展现出出色的泛化能力。由于ViT基于Transform模型,它可以从大量的数据中学习到更丰富、更复杂的图像特征表示。
相比之下,CNN在小样本数据集上可能需要更多的数据和调优才能取得好的结果。
可解释性和可调节性:
ViT的自注意机制使其在解释模型预测和注意力权重时具有优势。
相比之下,CNN的特征表示通常较难解释,因为它们是通过卷积和池化操作获得的。



相关文章:
ViT模型架构和CNN区别
目录 Vision Transformer如何工作 ViT模型架构 ViT工作原理解析 步骤1:将图片转换成patches序列 步骤2:将patches铺平 步骤3:添加Position embedding 步骤4:添加class token 步骤5:输入Transformer Encoder 步…...
发布python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码
python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及原生安卓接入案例代码案例 源码地址:keyxh/newsapi: python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码 (github.com) 目录 1.环境配…...

adb command
查看屏幕分辨率 adb shell wm size 查看dpi adb shell dumpsys window | grep ‘dpi’ WIFI调试: adb tcpip 5555adb connect 设备ip 注意,USB拔插会断掉,所以插上USB后再 adb connect 设备ip。【注意】华为手机自建热点的ip一般是192.1…...
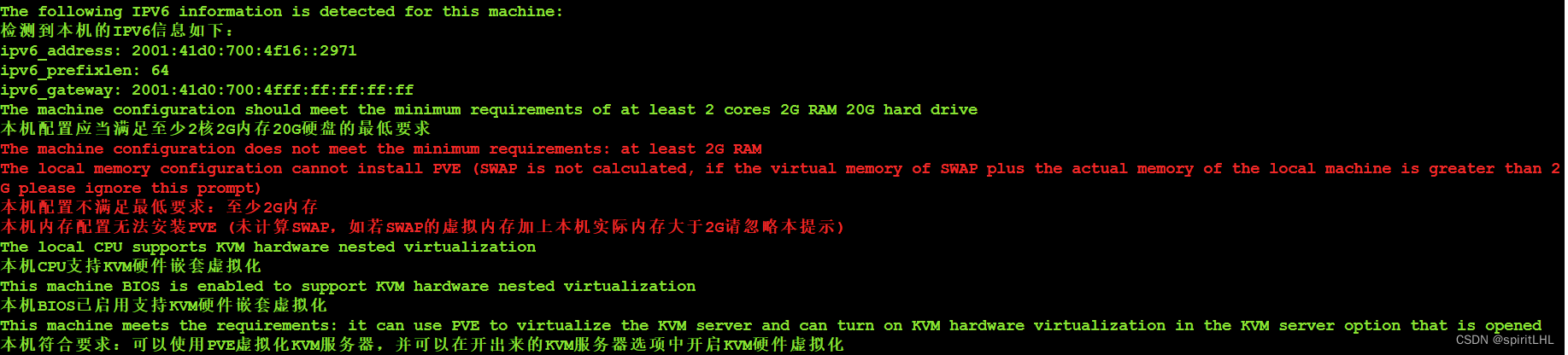
在ARM服务器上一键安装Proxmox VE(以在Oracle Cloud VPS上为例)(甲骨文)
前言 如题,具体用到的说明文档如下 virt.spiritlhl.net 具体流程 首先是按照说明,先得看看自己的服务器符不符合安装 Proxmox VE的条件 https://virt.spiritlhl.net/guide/pve_precheck.html#%E5%90%84%E7%A7%8D%E8%A6%81%E6%B1%82 有提到硬件和软…...
)
KMP算法(JS)
KMP算法 什么时KMP算法 KMP算法是一种改进的字符串匹配算法 由D.E.Knuth,J.H.Morris和 V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。 KMP的主要思想是当出现字符串不匹配时,可以知道…...
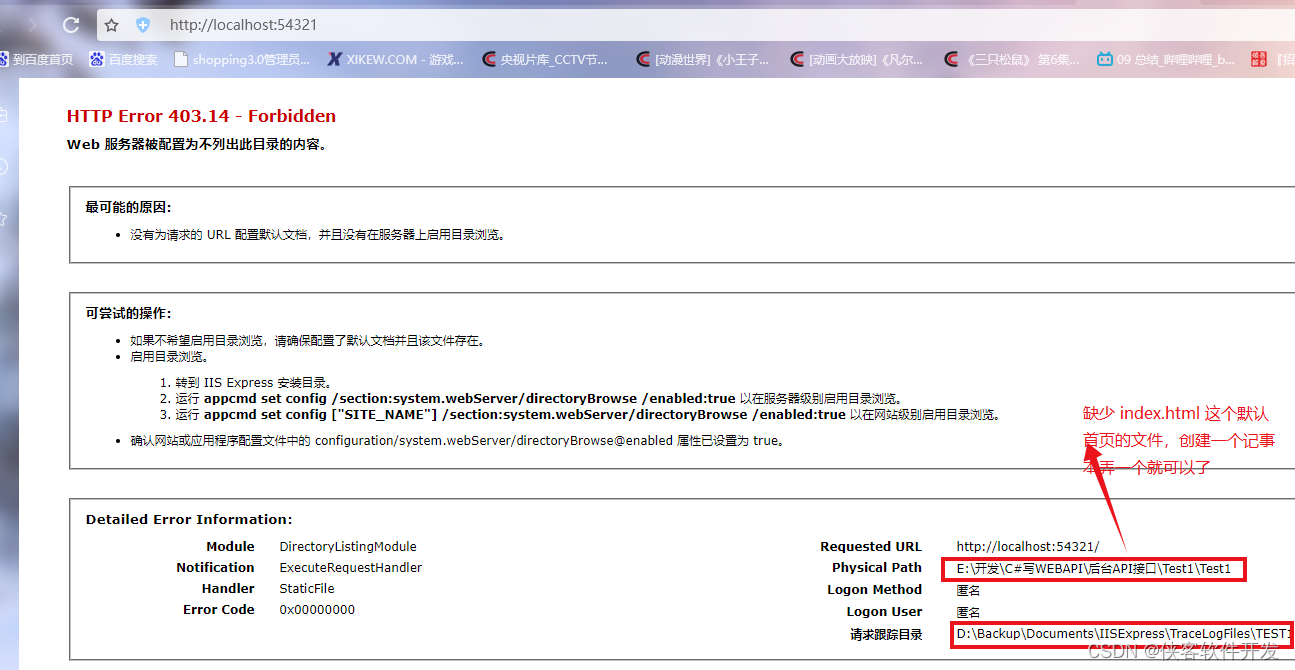
恢复NuGet包_解决:System.BadImageFormatException:无法加载文件或程序集
C#工程 主要是开发了一个 web api接口,这个工程源码去年还可以的,今年换了一个电脑打开工程就报错。 错误提示如下: 在 Microsoft.CodeAnalysis.CSharp.CommandLine.Program.Main(String[] args) Test1 System.BadImageFormatEx…...
Django学习笔记(2)
创建app 属于自动执行了python manage.py 直接在里面运行startapp app01就可以创建app01的项目了 之后在setting.py中注册app01 INSTALLED_APPS ["django.contrib.admin","django.contrib.auth","django.contrib.contenttypes","django.c…...

高德地图开发者平台Python应用实践:快速入门周边商业环境信息查询
高德地图开发平台提供了丰富的API接口,可以方便地进行地图数据的开发和分析。在商业分析数据采集中,使用高德地图开发平台的周边查询功能可以快速获取周边商圈、小区等信息,为商业决策提供数据支持。 针对您的需求,我建议采用以下…...

【ES6】—let 声明方式
一、不属于顶层对象window let 关键字声明的变量,不会挂载到window的属性 var a 5 console.log(a) console.log(window.a) // 5 // 5 // 变量a 被挂载到window属性上了 , a window.alet b 6 console.log(b) console.log(window.b) // 6 // undefin…...

【数据分析入门】Jupyter Notebook
目录 一、保存/加载二、适用多种编程语言三、编写代码与文本3.1 编辑单元格3.2 插入单元格3.3 运行单元格3.4 查看单元格 四、Widgets五、帮助 Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。 …...

反射知识总结
1、反射概述 反射是指对于任何一个Class类,在"运行的时候"都可以直接得到这个类全部成分。在运行时,可以直接得到这个类的构造器对象:Constructor在运行时。可以直接得到这个类的成员变量对象:Field在运行时,…...
MongoDB 安装 linux
本文介绍一下MongoDB的安装教程。 系统环境:CentOS7.4 可以用 cat /etc/redhat-release 查看本机的系统版本号 一、MongoDB版本选择 当前最新的版本为7.0,但是由于7.0版本安装需要升级glibc2.25以上,所以这里我暂时不安装该版本。我们选择的是6.0.9版本…...
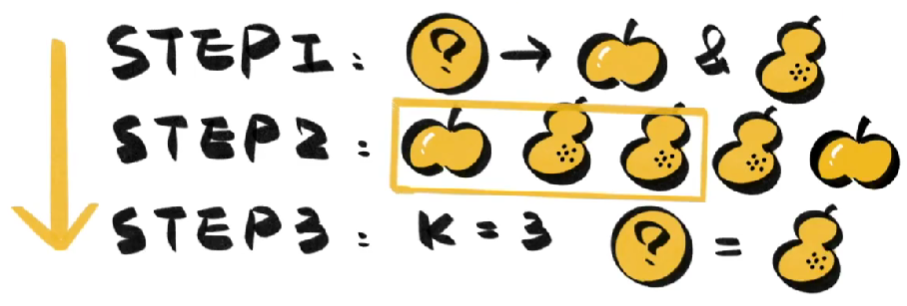
什么是KNN( K近邻算法)
什么是KNN( K近邻算法) 虽然名字中有NN,KNN并不是哪种神经网络,它全名K-Nearest-Neighbors:K近邻算法,是机器学习中常用的分类算法。 物以类聚,人以群分。KNN的基础思想很简单,要判断一个新数据的类别&…...

Linux查看命令总结
1.动态实时查找命令 使用以下命令的前提是需要在找到日志位置 tail -f server.log 实时展示日志末尾内容,默认最后10行,相当于增加参数 -n 10 tail -n filename; tail命令扩展 查看日志最后20行内容并实时更新日志 tail -f -n 20 server.log或者 tail -fn 20 ser…...

npm报错 Cannot find module ‘@vuepress\core\node_m
通常是由于缺少依赖包或者依赖包版本不兼容引起的。可以尝试以下步骤来解决这个问题: 确保您的项目的依赖包是最新的,可以运行 npm update 命令来更新依赖包。 如果更新依赖包后仍然有问题,可以尝试删除 node_modules 文件夹,并重…...

mybatis入门环境搭建及CRUD
一、MyBatis介绍 1.1 MyBatis的定义 MyBatis是一个开源的Java持久化框架,它可以帮助开发人员简化数据库访问的过程。它提供了一种将SQL语句与Java代码进行映射的方式,使得开发人员可以通过简单的配置文件来定义SQL语句,而无需编写繁琐的JDB…...

小程序变化历史记录
2023年8月26 小程序机号快速验证组件将需要付费使用 自2023年8月26日起,手机号快速验证组件将需要付费使用。标准单价为:每次组件调用成功,收费0.03元 https://blog.csdn.net/qq_37215621/article/details/131453551 自2023年9月1日起&…...

jstack(Stack Trace for Java)Java堆栈跟踪工具
jstack(Stack Trace for Java)Java堆栈跟踪工具 jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照(一般称为threaddump或者javacore文件)。 线程快照就是当前虚拟机内每一条线程正在执…...

linux面试题整理
目录标题 基础篇1.说下企业为什么用linux而不用windows?2.linux学过什么,怎么学习的?3.linux基本命令4.linux查看端口、进程、文件类型、挂载5.使用top命令之后前五行会显示什么内容?6.linux怎么查找一个文件7.vim进去后的各种操作…...
Linux笔记
Linux基础命令 Linux的目录结构 /,根目录是最顶级的目录了Linux只有一个顶级目录:/路径描述的层次关系同样适用/来表示/home/itheima/a.txt,表示根目录下的home文件夹内有itheima文件夹,内有a.txt ls命令 功能:列出…...

大型语言模型开发的环境成本与优化策略
1. 语言模型开发的环境成本全景图当我们惊叹于ChatGPT流畅的对话能力或Midjourney惊人的图像生成质量时,很少有人会思考这些AI能力背后的环境代价。事实上,大型语言模型的开发正悄然成为数字时代的"高碳产业"——训练一个130亿参数的模型所产生…...

从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验
从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验 第一次见到Dobot Magician时,它安静地躺在包装箱里,像一件精致的工业艺术品。作为一款定位教育和个人创客市场的桌面级机械臂,它的价格只有工业机械臂的零头…...

Fast-GitHub:国内开发者必备的GitHub下载加速终极方案
Fast-GitHub:国内开发者必备的GitHub下载加速终极方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 对于身处国内的开…...

Beyond Compare 5激活实战指南:3种方法轻松搞定专业版授权
Beyond Compare 5激活实战指南:3种方法轻松搞定专业版授权 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天评估期结束而烦恼吗?每次打开软件…...

SK海力士晶圆代工战略:特色工艺如何重塑半导体产业格局
1. 韩国半导体雄心:从存储巨头到晶圆代工的野望最近几年,全球半导体产业的新闻头条几乎被台积电、英特尔和三星的千亿美元级投资计划所占据。然而,在2021年5月,一则来自韩国的消息,虽然声量相对较小,却揭示…...

电信运营商M2M战略转型:从连接人到连接物的物联网新增长引擎
1. 从“人联网”到“物联金矿”:电信运营商的M2M战略转型 在过去的二十年里,全球的移动通信网络经历了一场狂飙突进,其核心使命始终围绕着“连接人”。从2G时代的短信和语音,到3G/4G时代的移动互联网,再到如今5G所描绘…...

openpilot终极指南:从开源机器人操作系统到300+车型自动驾驶辅助实现
openpilot终极指南:从开源机器人操作系统到300车型自动驾驶辅助实现 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/G…...
)
客观现实源于波函数坍缩:意识内源测量与智能外源投影一体化统一理论(世毫九实验室原创理论)
客观现实源于波函数坍缩:意识内源测量与智能外源投影一体化统一理论(世毫九实验室原创理论) 方见华 世毫九实验室 摘要:本文首次建立了贯通量子力学、认知科学与人工智能的意识-智能-现实一体化统一理论,从第一性原理出发证明:客观现实不是独立于意识的先验存在,而是意…...

VSCode + GitLab 真香组合:告别命令行恐惧,可视化搞定团队代码提交与合并
VSCode GitLab 可视化协作指南:零命令行完成高效团队开发 对于视觉型开发者而言,命令行操作常常是学习Git工作流的最大障碍。当团队采用GitLab进行协作时,传统教程中频繁出现的git checkout、git rebase等命令更容易让人望而生畏。事实上&a…...

HI3861实战指南:基于MQTT协议实现OneNET平台设备双向通信
1. HI3861与OneNET平台双向通信实战 第一次接触HI3861开发板时,我就被它轻量级的物联网开发能力吸引了。这块板子虽然体积小,但配合OneNET平台能实现完整的物联网数据交互。今天我就用最直白的语言,分享如何让HI3861通过MQTT协议与OneNET平台…...