机器学习深度学习——NLP实战(自然语言推断——数据集)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——NLP实战(情感分析模型——textCNN实现)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
NLP实战(自然语言推断——数据集)
- 引入
- 自然语言推断
- 斯坦福自然语言推断(SNLI)数据集
- 读取数据集
- 定义用于加载数据集的类
- 整合代码
- 小结
引入
之前我们分别使用了RNN和textCNN实现了情感分析模型,这个任务的目的是将单个文本序列分类到预定义的类别中,例如一组情感极性中(如“积极”或“消极”)。然而,当需要决定一个句子是否可以从另一个句子推断出来,或者需要通过识别语义等价的句子来消除句子间冗余时,知道如何对一个文本序列进行分类时不够的。相反,我们需要能够对成对的文本序列进行推断,这就是自然语言推断。
自然语言推断
自然语言推断主要研究假设是否可以从前提中推断出来,其中两者都是文本序列。换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
1、蕴涵:假设可以从前提中推断出来。
2、矛盾:假设的否定可以从前提中推断出来。
3、中性:所有其他情况。
自然语言推断也被称为识别文本蕴涵任务。例如,下面的一个文本对将被贴上“蕴涵”的标签,因为假设中的“示爱”可以从前提中的“拥抱”中推断出来:
前提:两个人拥抱在一起。
假设:两个人在示爱。
下面是一个“矛盾”的例子,因为“运行编码实例”表示“不睡觉”,而不是“睡觉”:
前提:一名男子正在运行Dive Into Deep Learning的编码实例。
假设:该男子正在睡觉。
第三个例子显示了一种“中性”关系,因为“正在为我们表演”这一事实无法推断出“出名”或“不出名”:
前提:音乐家们正在为我们表演。
假设:音乐家很有名。
自然语言推断一直是理解自然语言的中心话题。它有着广泛的应用,从信息检索到开放领域的问答。为了研究这个问题,我们将首先研究一个流行的自然语言推断基准数据集。
斯坦福自然语言推断(SNLI)数据集
斯坦福自然语言推断语料库(SNLI)是由500000多个带标签的英语句子对组成的集合。我们进行下载并存储提取的SNLI数据集。
import os
import re
import torch
from torch import nn
from d2l import torch as d2l#@save
d2l.DATA_HUB['SNLI'] = ('https://nlp.stanford.edu/projects/snli/snli_1.0.zip','9fcde07509c7e87ec61c640c1b2753d9041758e4')data_dir = d2l.download_extract('SNLI')
上面的代码下载可能会出现问题,因为SNLI数据集的压缩文件"snli_1.0.zip"里面有两个路径为“snli_1.0\Icon\r”和“’__MACOSX/snli_1.0/._Icon\r’”的文件,导致无法解析此路径进而导致整个文件无法解压。
解决方法:
手动解压data下的数据集"snli_1.0.zip”,然后把data_dir赋值为数据集解压后的路径改一下,也就是改为:
data_dir = "D:\Python\pytorch\data\snli_1.0\snli_1.0"
后序用到download_extract方法的地方也都记得把地址改成这样的。
读取数据集
原始的SNLI数据集包含的信息比我们在实验中真正需要的信息丰富得多。因此,我们定义函数read_snli以仅提取数据集的一部分,然后返回前提、假设及其标签的列表。
#@save
def read_snli(data_dir, is_train):"""将SNLI数据集解析为前提、假设和标签"""def extract_text(s):# 删除我们不会使用的信息s = re.sub('\\(', '', s)s = re.sub('\\)', '', s)# 用一个空格替换两个或多个连续的空格s = re.sub('\\s{2,}', ' ', s)return s.strip()label_set = {'entailment': 0, 'contradiction': 1, 'neutral': 2}file_name = os.path.join(data_dir, 'snli_1.0_train.txt'if is_train else 'snli_1.0_test.txt')with open(file_name, 'r') as f:rows = [row.split('\t') for row in f.readlines()[1:]]premises = [extract_text(row[1]) for row in rows if row[0] in label_set]hypotheses = [extract_text(row[2]) for row in rows if row[0] \in label_set]labels = [label_set[row[0]] for row in rows if row[0] in label_set]return premises, hypotheses, labels
上面代码可以看出,“0”对应“蕴涵entailment”,“1”代表“矛盾contradiction”,“2”代表“中性neutral”。
我们可以打印前面3对的前提和假设,以及它们的标签:
train_data = read_snli(data_dir, is_train=True)
for x0, x1, y in zip(train_data[0][:3], train_data[1][:3], train_data[2][:3]):print('前提:', x0)print('假设:', x1)print('标签:', y)
运行结果:
前提: A person on a horse jumps over a broken down airplane .
假设: A person is training his horse for a competition .
标签: 2
前提: A person on a horse jumps over a broken down airplane .
假设: A person is at a diner , ordering an omelette .
标签: 1
前提: A person on a horse jumps over a broken down airplane .
假设: A person is outdoors , on a horse .
标签: 0
这里的训练集大概有550000对,测试集约有10000对。下面显示了训练集和测试集中的三个标签大致是平衡的:
test_data = read_snli(data_dir, is_train=False)
for data in [train_data, test_data]:print([[row for row in data[2]].count(i) for i in range(3)])
运行结果:
[183416, 183187, 182764]
[3368, 3237, 3219]
定义用于加载数据集的类
下面定义一个用于加载SNLI数据集的类。类构造函数中的变量num_steps指定文本序列的长度,使得每个小批量序列将具有相同的形状。换句话说,在较长序列中的前num_steps个标记之后的标记被截断,而特殊标记“<pad>”将被附加到较短的序列后,直到它们的长度变为num_steps。通过实现__getitem__功能,我们可以任意访问带有索引idx的前提、假设和标签。
#@save
class SNLIDataset(torch.utils.data.Dataset):"""用于加载SNLI数据集的自定义数据集"""def __init__(self, dataset, num_steps, vocab=None):self.num_steps = num_stepsall_premise_tokens = d2l.tokenize(dataset[0])all_hypothesis_tokens = d2l.tokenize(dataset[1])if vocab is None:self.vocab = d2l.Vocab(all_premise_tokens + \all_hypothesis_tokens, min_freq=5, reserved_tokens=['<pad>'])else:self.vocab = vocabself.premises = self._pad(all_premise_tokens)self.hypotheses = self._pad(all_hypothesis_tokens)self.labels = torch.tensor(dataset[2])print('read ' + str(len(self.premises)) + ' examples')def _pad(self, lines):return torch.tensor([d2l.truncate_pad(self.vocab[line], self.num_steps, self.vocab['<pad>'])for line in lines])def __getitem__(self, idx):return (self.premises[idx], self.hypotheses[idx]), self.labels[idx]def __len__(self):return len(self.premises)
整合代码
现在,我们可以调用read_snli函数和SNLIDataset类来下载SNLI数据集,并返回训练集和测试集的DataLoader实例,以及训练集的词表。值得注意的是,我们必须使用从训练集构造的词表作为测试集的词表。因此,在训练集中训练的模型将不知道来自测试集的任何新词元。
#@save
def load_data_snli(batch_size, num_steps=50):"""下载SNLI数据集并返回数据迭代器和词表"""num_workers = d2l.get_dataloader_workers()data_dir = "D:\Python\pytorch\data\snli_1.0\snli_1.0"train_data = read_snli(data_dir, True)test_data = read_snli(data_dir, False)train_set = SNLIDataset(train_data, num_steps)test_set = SNLIDataset(test_data, num_steps, train_set.vocab)train_iter = torch.utils.data.DataLoader(train_set, batch_size,shuffle=True,num_workers=num_workers)test_iter = torch.utils.data.DataLoader(test_set, batch_size,shuffle=False,num_workers=num_workers)return train_iter, test_iter, train_set.vocab
在这里,我们将批量大小设置为128,序列长度设置为50,并调用load_data_snli函数来获取数据迭代器和词表。然后打印词表大小:
train_iter, test_iter, vocab = load_data_snli(128, 50)
print(len(vocab))
运行结果:
read 549367 examples
read 9824 examples
18678
现在我们打印第一个小批量的形状。与情感分析不同,我们有分别代表前提和假设的两个输入X[0]和X[1]:
for X, Y in train_iter:print(X[0].shape)print(X[1].shape)print(Y.shape)break
输出结果:
torch.Size([128, 50])
torch.Size([128, 50])
torch.Size([128])
小结
1、自然语言推研究“假设”是否可以从“前提”推断出来,其中两者都是文本序列。
2、在自然语言推断中,前提和假设之间的关系包括蕴涵关系、矛盾关系和中性关系。
3、斯坦福自然语言推断(SNLI)语料库是一个比较流行的自然语言推断基准数据集。
相关文章:
)
机器学习深度学习——NLP实战(自然语言推断——数据集)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——NLP实战(情感分析模型——textCNN实现) 📚订阅专栏:机器…...
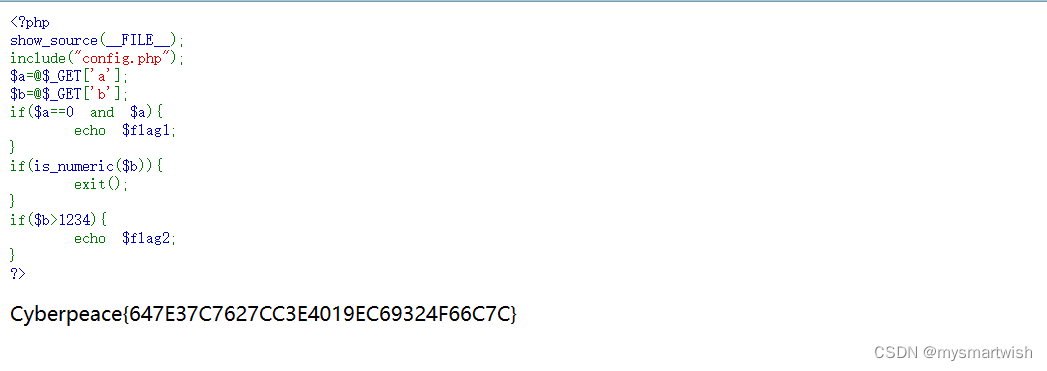
攻防世界-simple_php
原题 解题思路 flag被分成了两个部分:flag2,flag2。获得flag1需要满足变量a0且变量a≠0,这看起来不能实现,但实际上当变量a的值是字符时,与数字比较会发生强制类型转换,所以a为字符型数据即可,变…...

2023MyBatis 八股文——面试题
MyBatis简介 1. MyBatis是什么? MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及 获取结果集。MyBa…...

解决出海痛点:亚马逊云科技助力智能涂鸦,实现设备互联互通
今年6月,《财富》(中文版)发布“2023年值得关注的中国出海主力”盘点,在七个赛道中聚焦不断开拓新领域、影响力与日俱增的出海企业。涂鸦智能顺利入选,作为一家全球化公司,相比于产品直接到海外销售的传统出…...

国际刑警组织逮捕 14 名涉嫌盗窃 4000 万美元的网络罪犯
Bleeping Computer 网站披露,4 月份,国际刑警组织发动了一起为期四个月,横跨 25 个非洲国家的执法行动 “Africa Cyber Surge II”,共逮捕 14 名网络犯罪嫌疑人,摧毁 20000 多个从事勒索、网络钓鱼、BEC 和在线诈骗的犯…...
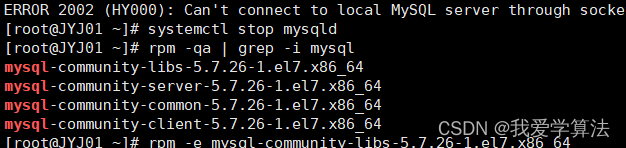
MySQL卸载-Linux版
MySQL卸载-Linux版 停止MySQL服务 systemctl stop mysqld 查询MySQL的安装文件 rpm -qa | grep -i mysql 卸载上述查询出来的所有的MySQL安装包 rpm -e mysql-community-client-plugins-8.0.26-1.el7.x86_64 --nodeps rpm -e mysql-community-server-8.0.26-1.el7.x86_64 -…...
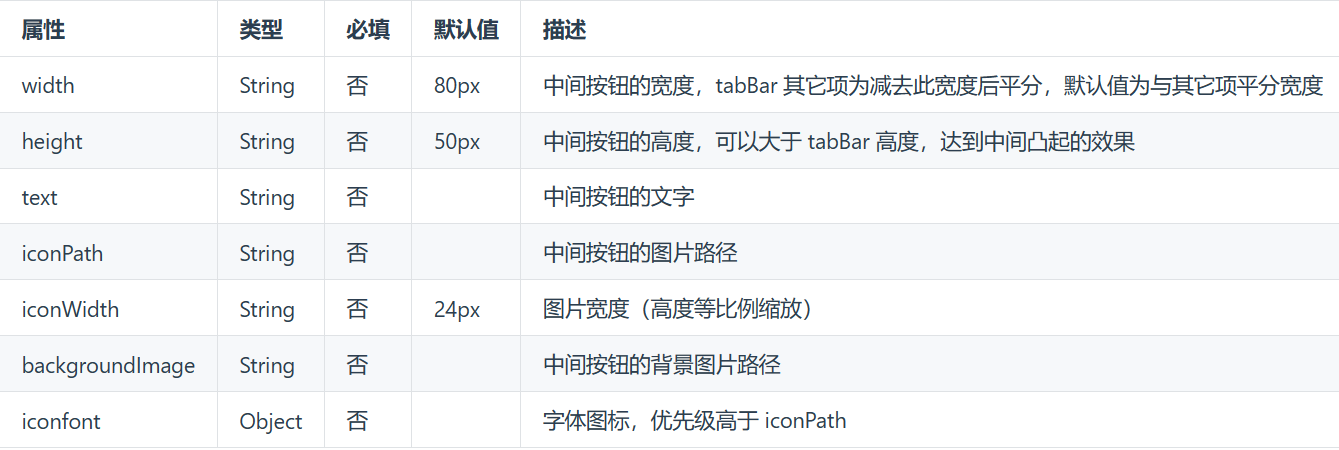
快速学会创建uni-app项目并了解pages.json文件
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 前言 创建 uni-app 项目 通过 HBuilderX 创建 pages.json pages style globalStyle tabBar 前言…...

选云服务器还是物理服务器
选云服务器还是物理服务器 一、为什么需要云服务器或独立服务器取代共享主机 在最早之前,大多数的网站都是共享主机开始的,这里也包含了云虚拟机。这一类的站点还有其他站点都会共同托管在同一台服务器上。但是这种共享机只适用于小的网站,如…...
最新ChatGPT网站AI系统源码+详细图文搭建教程/支持GPT4.0/AI绘画/H5端/Prompt知识库/
一、前言 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...
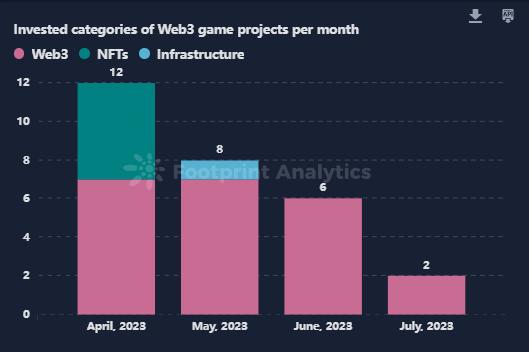
Web3 游戏七月洞察:迈向主流采用的临界点?
作者: lesleyfootprint.network 2023 年 7 月,Web3 游戏领域出现了小幅增长,但对于许多项目来说,用户采用仍然是一个持续的挑战。根据 Footprint Analytics 的数据,活跃的区块链游戏数量略有增加,达到 2,471 个。然而…...

Python爬虫——scrapy_多网页下载
在DangSpider类中设置一个基础url base_url http://category.dangdang.com/pg page 1在parse方法中 # 每一页的爬取逻辑都是一样的,所以只需要执行每一页的请求再次调用parse方法就可以了if self.page < 100:self.page 1url self.base_url str(self.page)…...
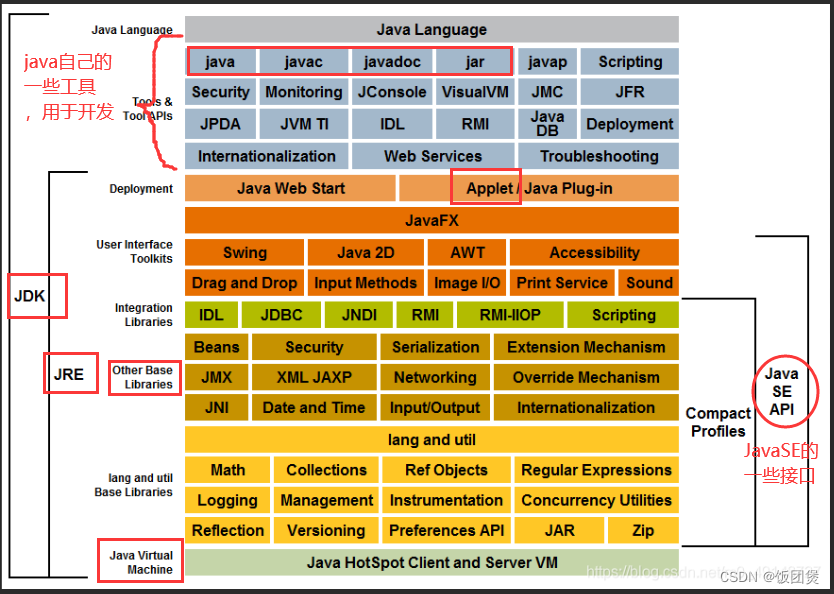
JDK JRE JVM 三者之间的详解
JDK : Java Development Kit JRE: Java Runtime Environment JVM : JAVA Virtual Machine JDK : Java Development Kit JDK : Java Development Kit【 Java开发者工具】,可以从上图可以看出,JDK包含JRE;java自己的一些开发工具中&#…...
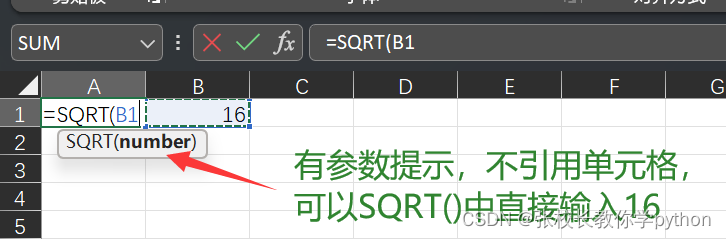
excel常见的数学函数篇2
一、数学函数 1、ABS(number):返回数字的绝对值 语法:ABS(数字);返回数字的绝对值;若引用单元格,把数字换为单元格地址即可 2、INT(number):向小取整 语法:INT(数字);若引用单元格…...

Certify The Web (IIS)
一、简介 Certify The Web 适用于 Windows的SSL 证书管理器用户界面,与所有 ACME v2 CA 兼容,为您的 IIS/Windows 服务器轻松地安装和自动更新来自 Letencrypt.org 和其他 ACME 证书授权机构的免费 SSL/TLS 证书,设置 https 从未如此简单。 …...
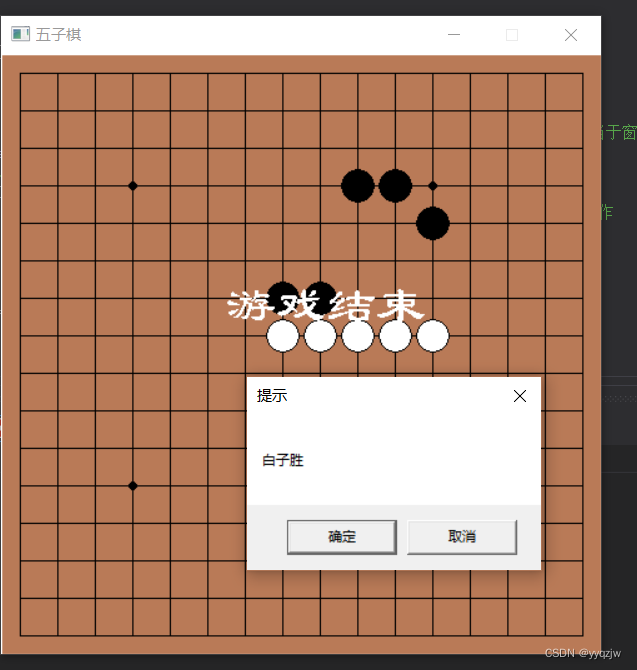
【c语言】五子棋(EasyX图形库+背景音乐)
大家好,有没有觉得写了好多c语言代码,面对的都是黑框框控制台,当我们学习了基础的c语言知识,和EasyX图形库后,终于可以和黑框框saygoodbye,今天要分享给大家的是小游戏五子棋,跟着小张一起学习吧 EasyX图形…...

【OpenCV 】对极几何标定质量验证
标定质量验证: 寻找一对对应点,已经知道对应关系及其详细坐标,根据对极几何推导实现 ///get the camera intrinsics and T_Ci_Bstd::vector<Eigen::Matrix3d> M_K;std::vector<Eigen::Matrix4d> T_Ci_B;for (int i 0; i < ne…...

Netty:ByteBuf的清空操作
说明 io.netty.buffer.ByteBuf有个函数clear(),它可以将ByteBuf的readerIndex和writerIndex都设置为0。 代码示例 package com.thb;import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled;public class Demo {public static void main(String[] args…...
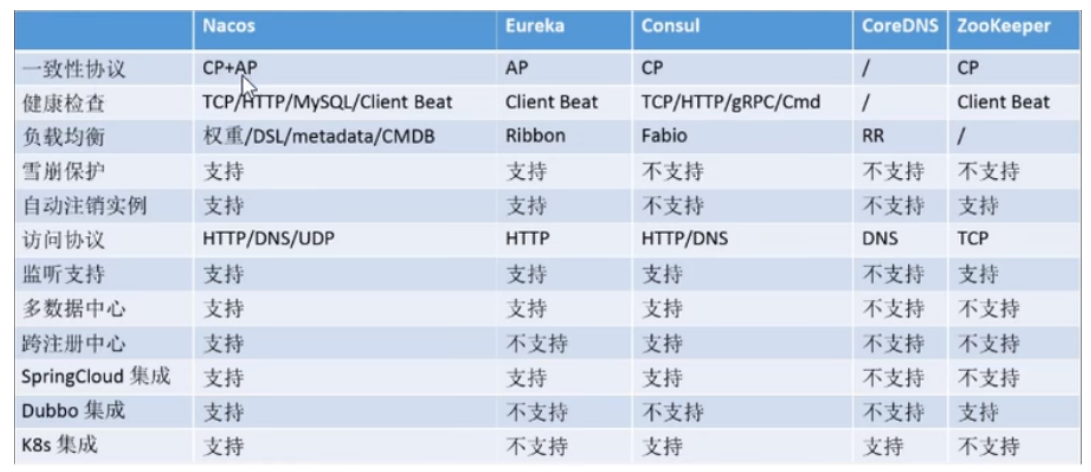
SpringCloud最新最全面试题
目录 一、简单说一说什么是微服务? 二、微服务有哪些优缺点? 三、微服务、分布式、集群的区别? 四、什么是Eureka? 五、Eureka有那两大组件? 六、actuator是什么? 七、Discovery是什么? …...
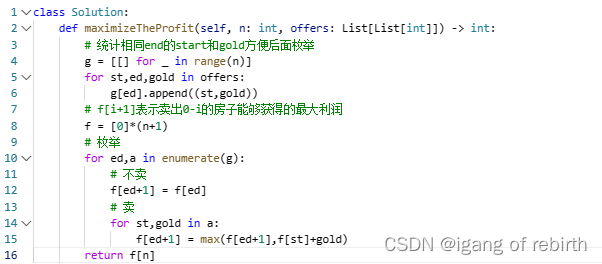
leetcode359周赛
2828. 判别首字母缩略词 核心思想:枚举。只需要枚举首字母和s是否一一对应即可。 2829. k-avoiding 数组的最小总和 核心思想:自己的方法就是哈希表,枚举i的时候,将k-i统计起来,如果出现了那么就跳过。灵神的方法是数学法&#…...
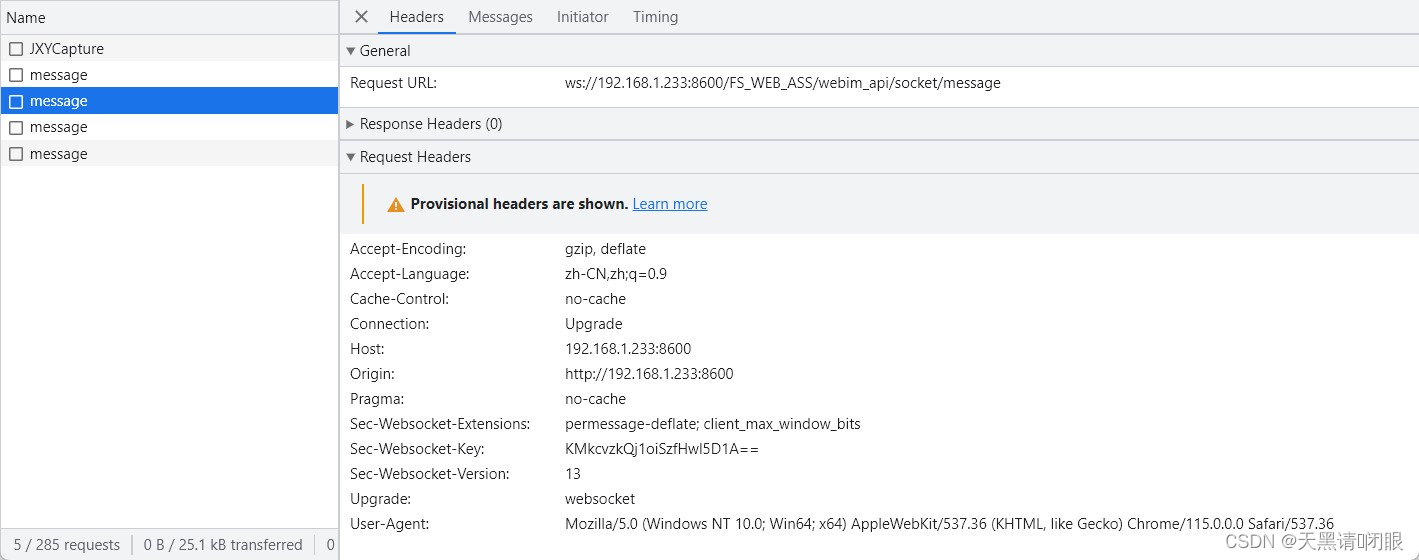
nginx代理webSocket链接响应403
一、场景 使用nginx代理webSocket链接,nginx响应403 1、nginx访问日志响应403 [18/Aug/2023:09:56:36 0800] "GET /FS_WEB_ASS/webim_api/socket/message HTTP/1.1" 403 5 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit…...

Sumi-e风格出图模糊、缺骨法、无气韵?手把手修复4类典型失败案例,含可复用的--s 800+ --style raw进阶参数包
更多请点击: https://intelliparadigm.com 第一章:Sumi-e风格在Midjourney中的本质困境与美学断层 水墨精神与扩散模型的结构性冲突 Sumi-e(日本水墨画)的核心在于“留白即墨、飞白见气、一笔三变”,其审美依赖于笔触…...

Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册
Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) …...

贝叶斯深度学习不确定性估计:集成学习与MC-Dropout实战对比
1. 项目概述:为什么我们需要量化深度学习的不确定性?在自动驾驶汽车识别前方障碍物、医疗AI系统诊断病灶、或者机器人进行精细操作时,一个错误的预测可能导致灾难性的后果。传统的深度神经网络(DNN)在这些任务上表现出…...

在Windows上安装Android应用:APK Installer让跨平台操作变得简单
在Windows上安装Android应用:APK Installer让跨平台操作变得简单 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想过在Windows电脑上直接运行Androi…...

收藏!小白程序员必看:从AI提效到重构产品,企业智能转型4阶段实战指南
本文深入探讨了企业如何拥抱智能时代,通过4个阶段实现AI落地。从提升内部效率开始,逐步激活沉睡数据,重构产品价值,最终形成深场景智能闭环。强调AI不应仅用于替代人工,更要关注为客户创造新价值、提升产品智能化&…...
)
CES效用函数保姆级解析:从公式推导到Python代码实现(附替代弹性计算)
CES效用函数实战指南:从数学本质到Python可视化 在经济学建模和金融工程领域,CES(Constant Elasticity of Substitution)效用函数就像一把瑞士军刀——它不仅能描述消费者偏好,还能通过调整参数δ来模拟完全替代、Cobb…...

终极指南:如何使用Azure Quickstart Templates实现成本管理与预算警报
终极指南:如何使用Azure Quickstart Templates实现成本管理与预算警报 【免费下载链接】azure-quickstart-templates Azure Quickstart Templates 项目地址: https://gitcode.com/gh_mirrors/az/azure-quickstart-templates Azure Quickstart Templates是微软…...

oh-my-prompt:模块化、高性能的终端提示符配置方案
1. 项目概述:一个为现代开发者量身打造的终端提示符如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么终端提示符(Prompt)就是你最亲密的“工作伙伴”。它不仅仅是那个闪…...

多渠道订单数据处理自动化,落地步骤与ERP打通方案 | 2026企业级智能体实战手册
在2026年的数字化转型深水区,企业面临的不再是“是否要自动化”的问题, 而是如何在高并发、多维度的全渠道业务压力下, 实现订单流、资金流与信息流的绝对同步。 传统的OMS(订单管理系统)与ERP(企业资源计划…...

Orama混合搜索实战:从全文检索到向量搜索的轻量级实现
1. 项目概述:从“全文搜索”到“向量搜索”的现代演进如果你做过Web开发,尤其是需要处理大量文本内容的应用,比如博客站、文档中心或者电商平台,那么“搜索”功能绝对是你绕不开的核心需求。传统上,我们可能会直接想到…...