ES的索引结构与算法解析
提到ES,大多数爱好者想到的都是搜索引擎,但是明确一点,ES不等同于搜索引擎。不管是谷歌、百度、必应、搜狗为代表的自然语言处理(NLP)、爬虫、网页处理、大数据处理的全文搜索引擎,还是有明确搜索目的的搜索行为,如各大电商网站、OA、站内搜索、视频网站的垂直搜索引擎,他们或多或少都使用到了ES。
作为搜索引擎的一部分,ES自然具有速度快、结果准确、结果丰富等特点,那么ES是如何达到“搜索引擎”级别的查询效率呢?首先是索引,其次是压缩算法,接下来我们就一起了解下ES的索引结构和压缩算法
1 结构
1.1 Mysql
Mysql下的data目录存放的文件就是mysql相关数据,mysql文件夹对应的就是数据库mysql。
其中表columns_priv对应了3个文件:columns_priv.frm、columns_priv.MYD、columns_priv.MYI。
.frm:表结构;.MYD:myisam存储引擎原数据;.MYI:myisam存储引擎索引;.ibd:innodb存储引擎数据
1.2 Elasticsearch
cfe为索引文,cfs 为数据文件,cfe文件保存Lucene各文件在.cfs文件的位置信息
cfs、cfe 在segment还很小的时候,将segment的所有文件都存在在cfs中,在cfs逐渐变大时,大小超过shard的10%,则会拆分为其他文件,如tim、dvd、fdt等文件
1.3 存储结构
倒排索引结构分为倒排表、词项字典、词项索引
倒排表包含某个词项的所有id的数据存储了在.doc文件中
词项字典包含了index field的所有经过处理之后的词项数据,最终存储在.tim文件中
1.4 结构对比
我们以某商城的手机为例,左侧为es倒排索引结构,右侧为原始数据。左侧图示只是为了展示倒排索引结构,并不是说es中倒排表就是简单的数组
以上面结构对比示例图为例,假如共有10亿条数据需要存储在ES中(上图右),分词后存储的倒排表(上图左)大概包含分词term以及对应的id数组等,在10亿条数据中,分词“小米”相关的数据有100万条,也就是说分词“小米”对应的数组Posting List长度是100万
id是int类型的有序主键,分词“小米”在数组Posting List中100万int类型数字总长度=100万✖每个int占4字节=400万Byte≈4MB。1个分词占4MB空间,假如10亿条数据有500万个分词,总空间=4MB✖500万=2千万MB,磁盘空间直接爆炸
2 算法
分词对应的数组Posting List实际就是一个个有序数组,而有序数值数组是比较容易进行压缩处理的,而且一般来说压缩效益也不错,如果能对其进行压缩是能够大大节约空间资源的
ES中倒排索引的压缩算法主要有FOR算法(Frame Of Reference)和RBM算法(RoaringBitMap)
2.1 FOR
FOR算法的核心思想是用减法来削减数值大小,从而达到降低空间存储。 假设V(n)表示数组中第n个字段的值,那么经过FOR算法压缩的数值V(n)=V(n)-V(n-1)。也就是说存储的是后一位减去前一位的差值。存储是也不再按照int来计算了,而是看这个数组的最大值需要占用多少bit来计算
我们按照差值计算的方式来保存数据,初始值为1,2与1的差值为1,3与2的差值为1……最终我们就将原始Posting List数据转化为100万个1,每个1我们可以用1bit来记录,总空间=1bit✖100万=100万bit,相比原有400万Byte=3200bit,空间压缩了32倍
在实际生产中,不可能出现一个term的Posting List是这种差值均为1的情况,所以我们以通用示例举例。假如原数据为[73,300,302,332,343,372],数组中6个数字占据总空间为24字节。按照差值方式记录,数组转化为[73,227,2,30,11,29],最大数字为227,大于2的7次方128,小于2的8次方256,所以每个数字可以使用8bit即1Byte来保存,占据总空间为1Byte*6 + 1Byte=7Byte
在此基础上,我们将差值数组按照密集度划分为[73,227]和[2,30,11,29],其中[73,227]中最大值227介于2的7次方和2的8次方之间,所以用8bit=1Byte作为切割分段,[2,30,11,29]中最大数30介于2的4次方和2的5次方之间,所以用5bit作为切割分段。
数组[73,227]占据总空间为8bit✖2个=16bit=2Byte
数组[2,30,11,29]占据总空间为5bit✖4个=20bit=3Byte
为什么20bit=3Byte呢?因为8bit=1Byte,小于8bit也会占据1个字节空间,所以17bit到24bit均为3Byte
所以,最终占据总空间=1+2+1+3=7Byte
疑问一:既然原数组[73,300,302,332,343,372]要按照密集度拆分为[73,227]和[2,30,11,29]两个数组,那为什么不继续往下拆分,直接拆分到每个数字是一个数组,这样使用bit记录时占据总空间会更少?
答:如果继续拆分数组,空间确实会使用更少,但是,之前我们提到搜索引擎速度快的方式有两种:高效的压缩算法和快速的编码解码速度,单个数字存储确实压缩了空间,但是我们无法再通过解码的方式将源数据还原
疑问二:为什么源数据使用差值记录占据6Byte,拆分数组后占据7Byte,拆分后占据空间不变,有时候甚至会变大,为什么?
答:数据量小的情况下确实会出现该情况,因为我们需要拆分数组并记录拆分数组的长度(如上面示例中的8bit和5bit),在原数据存储空间基础上还要存储拆分长度,所以数据量小的情况下会出现比直接存储占据空间大的情况。但是不管是搜索引擎还是Elasticsearch更多处理的是海量数据,数据量越多,差值数组拆分的方式节省空间越明显
2.2 RBM
我们已经了解了FOR压缩算法,算法核心是将PostingList按照差值密集度转化成两个差值数组。在这里我们要考虑一种情况就是:在大数据中,10亿条数据分词500万个,如果分词“小米”所在PostList比较分散且差值很大,此时使用FOR算法效果就会大打折扣。所以稀疏的数组,不适合使用FOR算法
在这里我们以[1000,62101,131385,132052,191173,196658]为例,如果按照FOR算法,转化成的差值数组为[1000,61101,69284,667,59121,5485]密集度很低。我们采用RBM算法
源数据PostingList是由int类型组成的数组,int类型=4Byte=32bit,最大值=2的32次方-1=4294967295≈43亿。当数据较大且稀疏时,我们将32bit拆分为16bit和16bit,16bit最大值=65535,前16bit存放商,后16bit存放余数,所以商和余数都不会超过65535.我们将源数组的值除以65536,得到的商和余数分别存放在前16bit和后16bit。
以数字196658为例,转化为2进制,前16位=3,后16位=50
得到的结果以K-V存放。Key最大值为16bit,所以以short[]数组存放,Value以Container存放。
由于源数组为有序数组,所以按照高低16位转化后,商和余数都是从小到大排列
通过看Container源码,我们可以看到Container有3种:ArrayContainer、BitmapContainer、RunContainer。
- ArrayContainer本质为集合,所以随着数组中数量越多,占用空间越多,呈正向增长。
当数组种数量为4096时,占据总空间=4096个✖16bit(即2Byte)➗1024=8KB
当数组种数量为65536时,占据总空间=65536个✖16bit(即2Byte)➗1024=128KB
- BitmapContainer位图,核心就是将原有存储数值转化成该数值在哪个位置上存在
由于余数最大值为65535,所以我们需要65536位位图,数值是多少,在位图上对应的位置就是多少。数值等于4096,则位图上4096位值为1;数值等于65535,则位图上65535位值为1。每个位置上的数都占用8KB空间(8KB=65536bit)
- RunContainer用法相对狭隘,这种类型是Lucene 5之后新增的类型,主要应用在连续数字的存储商,比如倒排表中存储的数组为 [1,2,3…100W] 这样的连续数组,如果使用RunContainer,只需存储开头和结尾两个数字:1和100W,即占用8个字节。这种存储方式的优缺点都很明显,它严重收到数字连续性的影响,连续的数字越多,它存储的效率就越高
- 如果数组是如下形式 [1,2,3,4,5,100,101,102,999,1000,1001] 就会被拆分为三段:[1,5],[100,102],[999,1001]
至于每次存储采用什么容器,需要进行一下判定,比如ArrayContainer,当存储的元素少于4096个时,他会比BitmapContainer占用更少空间,而当大于4096个元素时,采用ArrayContainer所需要的空间就会大于8kb,那么采用BitmapContainer就会占用更少空间
3 总结
ES在处理海量数据时通过其独到的结构和压缩算法,将索引效率尽可能的提升。虽然在实际业务处理中我们极少遇到海量数据处理的情况,但是通过了解ES的原理,能够帮我们开阔下视野,了解数字之美,算法之美。
相关文章:
ES的索引结构与算法解析
提到ES,大多数爱好者想到的都是搜索引擎,但是明确一点,ES不等同于搜索引擎。不管是谷歌、百度、必应、搜狗为代表的自然语言处理(NLP)、爬虫、网页处理、大数据处理的全文搜索引擎,还是有明确搜索目的的搜索行为,如各大…...

32.Netty源码之服务端如何处理客户端新建连接
highlight: arduino-light 服务端如何处理客户端新建连接 Netty 服务端完全启动后,就可以对外工作了。接下来 Netty 服务端是如何处理客户端新建连接的呢? 主要分为四步: md Boss NioEventLoop 线程轮询客户端新连接 OP_ACCEPT 事件ÿ…...

代码随想录day11
20. 有效的括号 ● 力扣题目链接 ● 给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串,判断字符串是否有效。 ● 有效字符串需满足: ● 左括号必须用相同类型的右括号闭合。 ● 左…...

RabbitMQ实习面试题
RabbitMQ实习面试题 在 RabbitMQ 中,确保生产者消息正确发布以及确保消费者已经消费是非常重要的任务。以下是一些方法和策略,可以帮助您在 RabbitMQ 中实现这些目标: 确保生产者消息正确发布: 持久化消息:将消息设…...
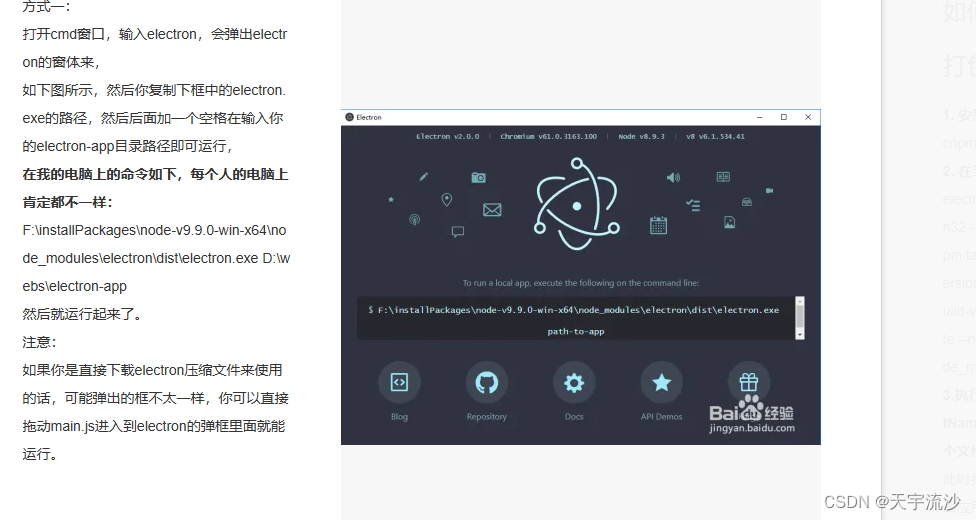
Electron入门,项目运行,只需四步轻松搞定。
electron 简单介绍: 实现:HTML/CSS/JS桌面程序,搭建跨平台桌面应用。 electron 官方文档: [https://electronjs.org/docs] 本文是基于以下2篇文章且自行实践过的,可行性真实有效。 文章1: https://www.cnbl…...
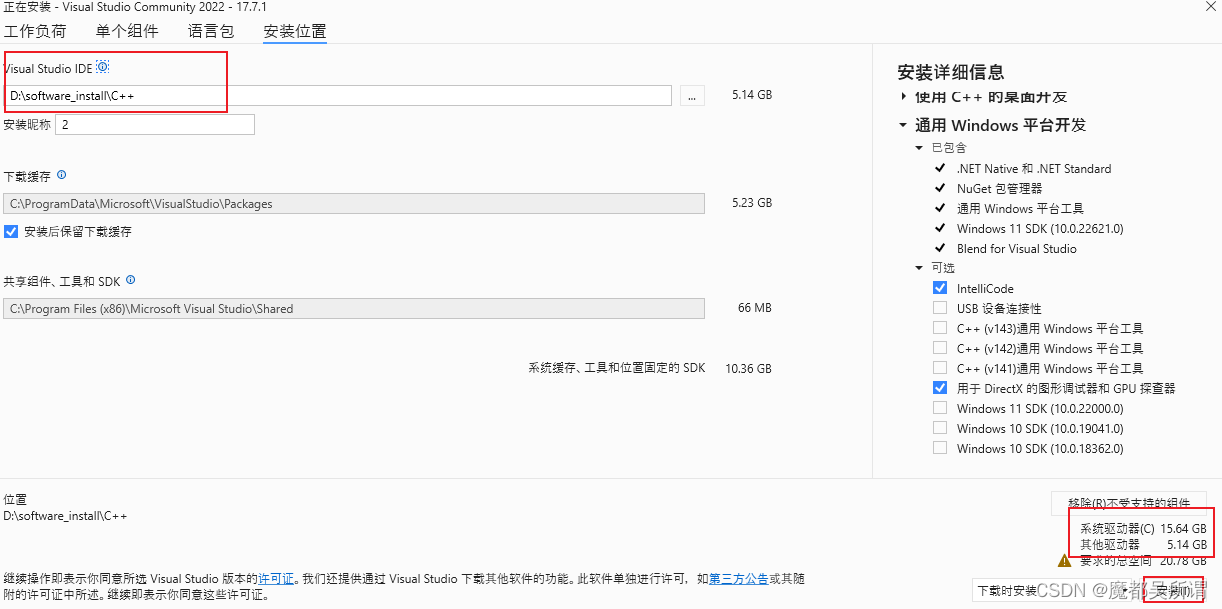
【C++】visualstudio环境安装
记录了部分安装步骤,可能有点不全,参考下,需要的磁盘空间差不多20GB; 下载 https://visualstudio.microsoft.com/zh-hans/vs/ 下载完成: 双击进入安装状态: 根据自己的需求勾选安装项: 选择…...
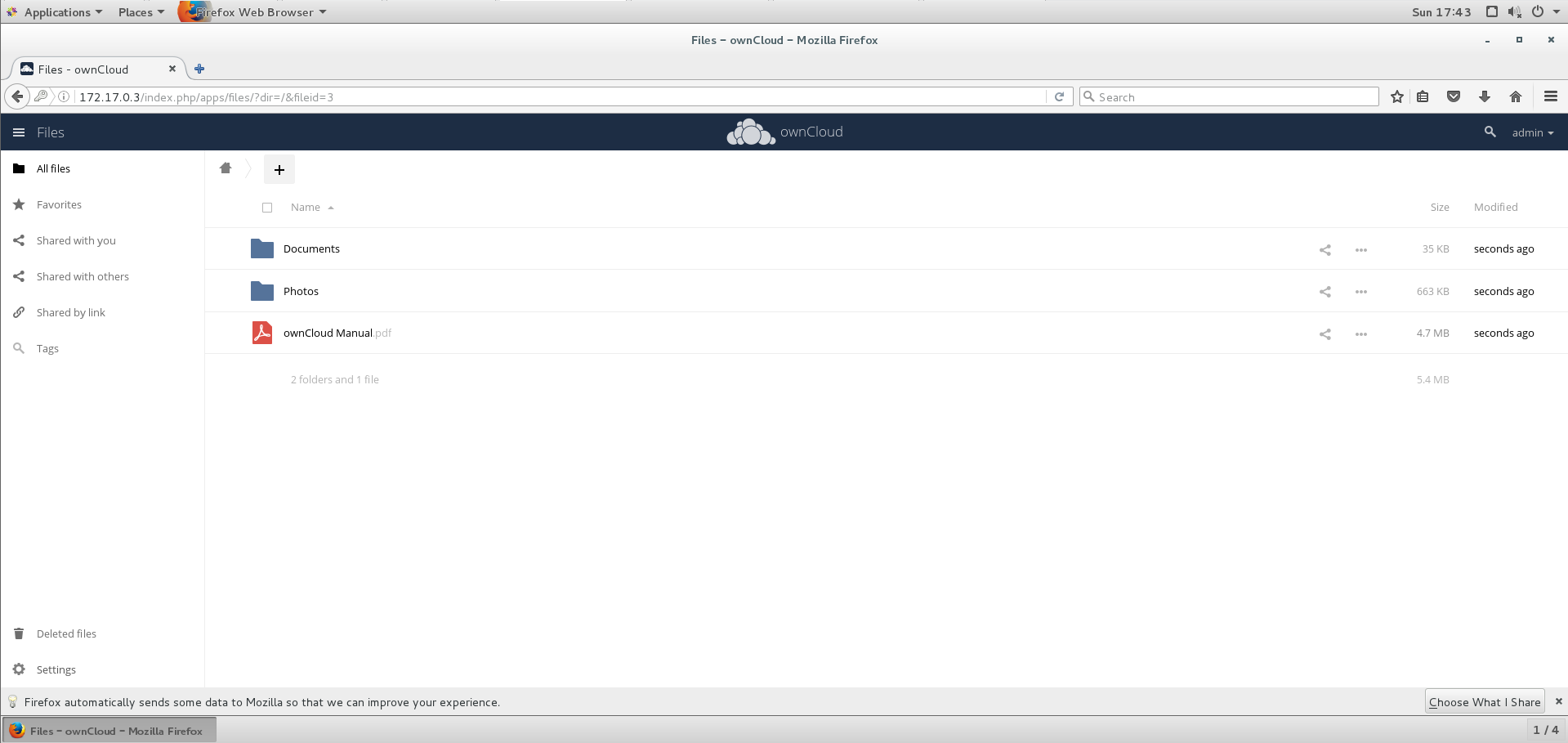
使用MySQL:5.6和owncloud镜像搭建个人网盘
拉取镜像 [rootkvm ~]# docker pull mysql:5.6[rootkvm ~]# docker pull owncloud启动mysql容器 [rootkvm ~]# docker run -d --name db1 -e MYSQL_ROOT_PASSWORDroot mysql:5.6 db832e4e4333a0e9a7c152a67272721fdbe5381054090c5eb24f90455390a852 [rootkvm ~]# docker ps …...

php中创建对象时传递的参数是构造方法
PHP中创建对象时,可以通过构造方法的参数来传递参数值。构造方法是一个特殊的方法,在创建对象时会自动调用,用于进行对象的初始化操作。 以下是一个示例代码,展示了如何在PHP中使用构造方法传递参数: class MyClass …...

C++并发及互斥保护示例
最近要写一个多线程的并发数据库,主要是希望使用读写锁实现库的并发访问,同时考虑到其他平台(如Iar)没有C的读写锁,需要操作系统提供,就将读写锁封装起来。整个过程还是比较曲折的,碰到了不少问题,在此就简…...

新手常犯的错误,anzo capital昂首资本一招避免少走弯路
新手是不是经常交易中赚不到钱,今天anzo capital昂首资本就盘点一下新手常犯的错误,一招教你少走弯路。 一.随便选择交易账户 开立实时账户时选择正确的账户类型,anzo capital昂首资本教你比较所有提供的账户类型,选择最符合财务…...
 前后端 关于时间格式数据的处理方法)
Java Vue (el-date-picker组件) 前后端 关于时间格式数据的处理方法
前端使用 elment-ui 组件 el-date-picker 其中组件需要格式化时间,增加属性 value-format"yyyy-MM-dd" 后端 Java 接收参数类型 后端Dto 使用Date接收,并添加JsonFormat注解 JsonFormat(pattern"yyyy-MM-dd") private Date testTi…...

Python爬虫——scrapy_多条管道下载
定义管道类(在pipelines.py里定义) import urllib.requestclass DangDangDownloadPipelines:def process_item(self, item, spider):url http: item.get(src)filename ../books_img/ item.get(name) .jpgurllib.request.urlretrieve(url, filename…...
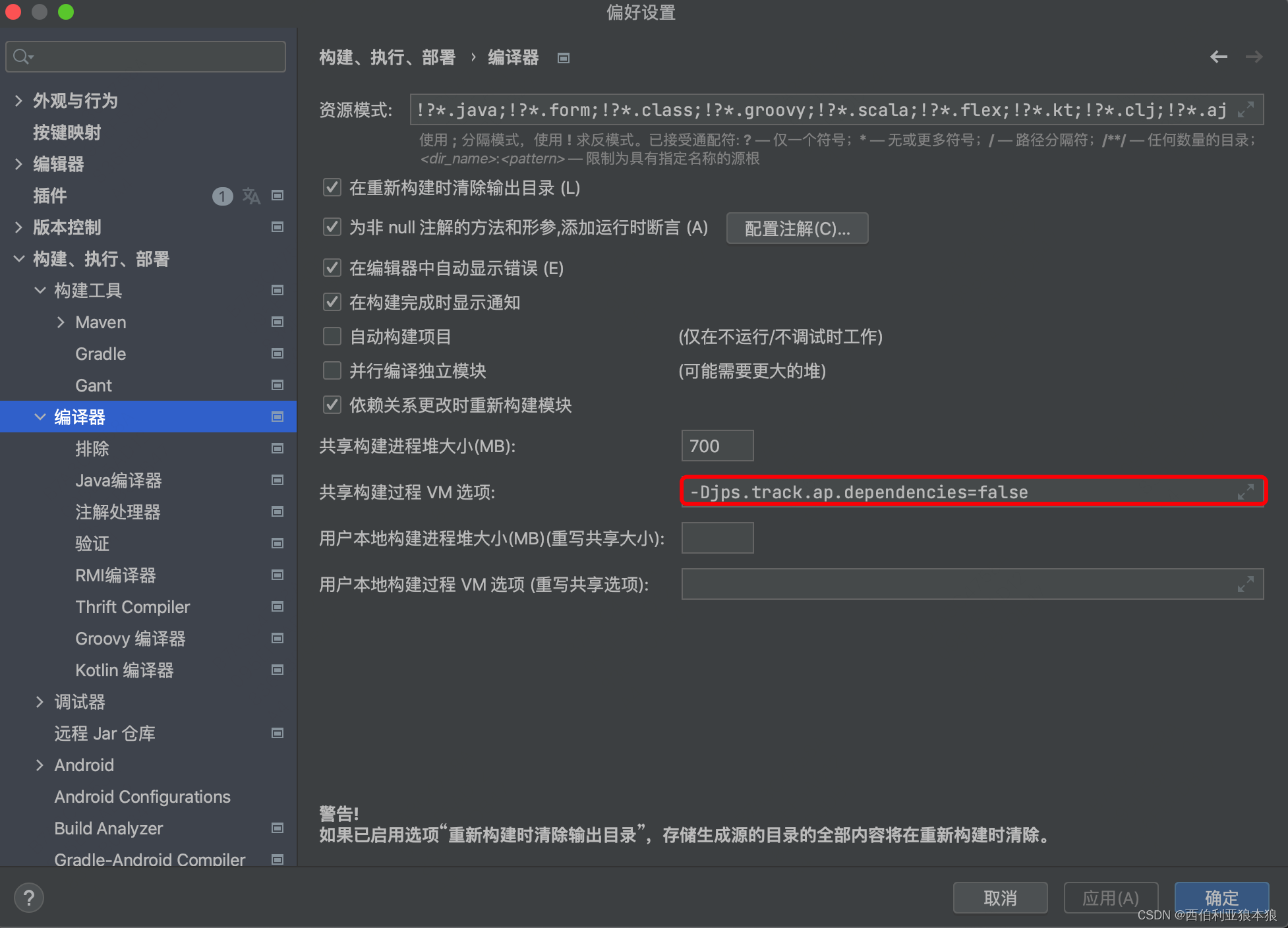
lombok启动不生效(什么方法都试了,可还是不生效怎么办 ?! 救救我)
使用IntelliJ IDEA 2021.1.3(Ultimate Edition)时提示Lombok不生效 java: You aren’t using a compiler supported by lombok, so lombok will not work and has been disabled. 方式一:我们手动更新一下版本到以下版本 <!--Lombok--&…...

element文本域禁止手动拉伸、两种方式、textarea
文章目录 style方式element自带的禁止拉伸方法建议 style方式 html <el-inputv-model"content":rows"3"class"r_n"type"textarea"maxlength"40"placeholder""style"height: 100%;" />css style…...

c#中lambda表达式缩写推演
Del<string> ml new Del<string>(Notify);//泛型委托的实例化,并关联Nofity方法 Del<string> ml new Del<string>(delegate (string str) { return str.Length; });//将Nofity变更为匿名函数 Del<string> ml delegate(string str)…...

无涯教程-PHP - 循环语句
PHP中的循环用于执行相同的代码块指定的次数。 PHP支持以下四种循环类型。 for - 在代码块中循环指定的次数。 while - 如果且只要指定条件为真,就会循环遍历代码块。 do ... while - 循环执行一次代码块…...
思维进化算法(MEA)优化BP神经网络
随着计算机科学的发展,人们借助适者生存这一进化规则,将计算机科学和生物进化结合起来,逐渐发展形成一类启发式随机搜索算法,这类算法被称为进化算法(Evolutionary Com-putation, EC)。最著名的进化算法有:遗传算法、进化策略、进化规划。与传统算法相比,进化算法的特点是群体搜…...

Kotlin 中的 设计模式
单例模式 饿汉模式 饿汉模式在类初始化的时候就创建了对象,所以不存在线程安全问题。 局限性: 1、如果构造方法中有耗时操作的话,会导致这个类的加载比较慢; 2、饿汉模式一开始就创建实例,但是并没有调用…...
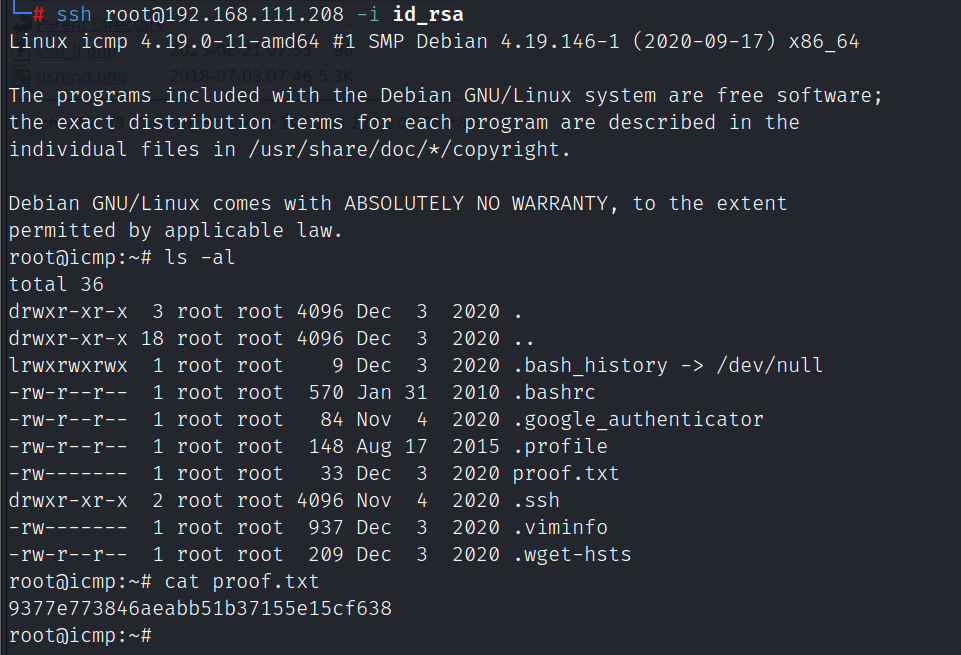
Vulnhub: ICMP: 1靶机
kali:192.168.111.111 靶机:192.168.111.208 信息收集 端口扫描 nmap -A -sC -v -sV -T5 -p- --scripthttp-enum 192.168.111.208 80端口的cms为Monitorr 1.7.6m 搜索发现该版本的cms存在远程代码执行 searchsploit monitorr 漏洞利用 nc本地监听&…...

我的创作纪念日(C++修仙练气期总结)
分享自己最喜欢的一首歌:空想フォレスト—伊東歌詞太郎 机缘 现在想想自己在CSDN创作的原因,一开始其实就是想着拿着博客当做自己的学习笔记,笔记嘛,随便写写,自己看得懂就ok了的态度凸(艹皿艹 )。也是用来作为自己学习…...

Arm物联网战略转型:从IP授权到端到端生态构建的机遇与挑战
1. 从IP供应商到生态构建者:Arm的物联网战略转型解析最近在梳理半导体行业动态时,Arm的一则旧闻让我思考了很久。2018年,这家以处理器IP授权闻名的公司,被曝出计划以6亿美元收购数据分析公司Treasure Data。这并非孤例,…...

Claude代码技能库:AI编程辅助的范式转变与工程实践
1. 项目概述:一个面向Claude的代码技能库最近在AI编程辅助的圈子里,一个名为warren618/claude-code-openclaw-skills的项目引起了我的注意。乍一看这个标题,你可能会有点懵——“Claude”是谁?“OpenClaw”又是什么?这…...
【Pixel专属Gemini Edge推理引擎】:本地运行LLM不联网、零延迟、功耗降低47%——实测数据首次公开
更多请点击: https://intelliparadigm.com 第一章:Gemini Edge推理引擎的Pixel专属定位与技术边界 Gemini Edge 是 Google 为 Pixel 系列设备深度定制的端侧推理引擎,其核心设计目标并非通用模型部署,而是围绕 Pixel 的硬件协同栈…...

BugPack:构建自动化安全研究工具箱的设计与实践
1. 项目概述:一个为安全研究量身定制的“漏洞工具箱”如果你是一名安全研究员、渗透测试工程师,或者是对软件安全有浓厚兴趣的开发者,那么你一定经历过这样的场景:在复现一个公开漏洞时,需要四处寻找可用的利用脚本&am…...

开发者效率革命:用dotfiles打造可移植的个性化开发环境
1. 项目概述:dotfiles,开发者效率的基石 如果你在终端里敲命令时,总觉得默认的配置不够顺手,或者每次在新机器上都要花半天时间重新配置一遍开发环境,那“dotfiles”这个概念对你来说就是救星。jesuserro/dotfiles 这个…...

AgentKernel:构建模块化智能体系统的核心引擎设计
1. 项目概述:从“AgentKernel”看智能体开发范式的演进最近在GitHub上看到一个名为“AgentKernel”的项目,作者是vijaygopalbalasa。这个标题本身就很有意思,它没有直接叫“AgentFramework”或者“AgentPlatform”,而是选择了“Ke…...

企业级知识管理新门槛:NotebookLM单用户年成本超$298?我们用5类典型场景算清ROI临界点
更多请点击: https://intelliparadigm.com 第一章:企业级知识管理新门槛:NotebookLM单用户年成本超$298?我们用5类典型场景算清ROI临界点 当企业评估AI增强型知识管理工具时,隐性成本常被低估——NotebookLM虽未公开…...

云代理商:Hermes Agent如何通过技能沉淀降低长期算力消耗
在 AI 智能体规模化落地的今天,算力成本高、重复推理多、长期运行效率衰减,已成为企业和开发者的核心痛点。传统 AI 智能体每处理一次相似任务,都要从零开始推理、反复调用工具,大量算力浪费在重复劳动中,长期使用成本…...
)
保姆级避坑指南:在Ubuntu18.04上用ROS Melodic搞定UR5+Realsense D435i手眼标定(附旧版easy_handeye包)
深度避坑实战:Ubuntu18.04ROS Melodic手眼标定全流程精解 当机械臂的末端执行器需要与视觉系统协同工作时,手眼标定成为连接两者的关键桥梁。本文将以UR5机械臂搭配Realsense D435i相机为例,深入剖析在Ubuntu18.04和ROS Melodic环境下实现高精…...

基于MCP协议集成AI求职助手:自动化简历优化与面试准备
1. 项目概述:将AI求职助手集成到你的工作流 如果你正在用Claude Desktop或者Cursor这类AI助手,并且恰好又在找工作或者准备职业跃迁,那你可能已经体会过那种“割裂感”——你需要手动把简历内容、职位描述、面试问题来回复制粘贴到聊天窗口&…...