【100天精通python】Day43:python网络爬虫开发_爬虫基础(urlib库、Beautiful Soup库、使用代理+实战代码)
目录
1 urlib 库
2 Beautiful Soup库
3 使用代理
3.1 代理种类 HTTP、HTTPS 和 SOCKS5
3.2 使用 urllib 和 requests 库使用代理
3.3 案例:自建代理池
4 实战 提取视频信息并进行分析
1 urlib 库
urllib是 Python 内置的标准库,用于处理URL、发送HTTP请求和处理网络数据。它包含多个模块,如urllib.request用于发送请求,urllib.parse用于解析URL,urllib.error用于处理异常等。
urllib.request:用于发送 HTTP 请求和获取响应。urllib.parse:用于解析 URL,拆分和合并 URL 的各个部分。urllib.error:处理异常,如连接错误、HTTP 错误等。
常用语法:
- 发送GET请求:
import urllib.requesturl = "https://www.example.com"
response = urllib.request.urlopen(url)
content = response.read().decode("utf-8")
print(content)
2 发送POST请求:
import urllib.requesturl = "https://www.example.com"
response = urllib.request.urlopen(url)
content = response.read().decode("utf-8")
print(content)
3 实战示例:
爬取网页内容:
import urllib.requesturl = "https://www.example.com"
response = urllib.request.urlopen(url)
content = response.read().decode("utf-8")
print(content)
下载文件:
import urllib.requesturl = "https://www.example.com/sample.pdf"
urllib.request.urlretrieve(url, "sample.pdf")
print("File downloaded.")
处理异常:
import urllib.errortry:response = urllib.request.urlopen("https://www.nonexistent-website.com")
except urllib.error.URLError as e:print("Error:", e)
解析URL:
import urllib.parseurl = "https://www.example.com/page?param1=value1¶m2=value2"
parsed_url = urllib.parse.urlparse(url)
print(parsed_url.scheme) # 输出协议部分
print(parsed_url.netloc) # 输出域名部分
print(parsed_url.query) # 输出查询参数部分
以上示例只是
urllib库的一些用法。这个库非常强大,你可以在许多网络操作中使用它,包括爬虫、API调用等。在实际项目中,你可能需要处理更多的细节,如设置请求头、处理响应等。查阅官方文档可以帮助你更全面地了解urllib库的功能和用法。
4 Handler 处理器和自定义 Opener:
处理器(Handler)允许你自定义请求的处理方式,以满足特定的需求。urllib.request 模块提供了一些默认的处理器,例如 HTTPHandler 和 HTTPSHandler,用于处理 HTTP 和 HTTPS 请求。你还可以通过创建自定义的 Opener 来组合不同的处理器,实现更灵活的请求配置。
自定义 Opener 示例:
import urllib.request# 创建自定义 Opener,组合不同的处理器
opener = urllib.request.build_opener(urllib.request.HTTPSHandler())# 使用自定义 Opener 发送请求
response = opener.open("https://www.example.com")
content = response.read().decode("utf-8")
print(content)
5 URLError 和 HTTPError
URLError和HTTPError都是urllib.error模块中的异常类,用于处理与网络请求相关的错误情况。
URLError:用于捕获与URL相关的异常,如无法解析主机名、网络不可达等。HTTPError:用于捕获 HTTP 错误响应,比如请求的网页不存在(404 Not Found)、服务器错误(500 Internal Server Error)等。
URLError 示例:
import urllib.errortry:response = urllib.request.urlopen("https://www.nonexistent-website.com")
except urllib.error.URLError as e:print("URLError:", e)
HTTPError 示例:
import urllib.errortry:response = urllib.request.urlopen("https://www.example.com/nonexistent-page")
except urllib.error.HTTPError as e:print("HTTPError:", e.code, e.reason)
在示例中,
e.code是 HTTP 错误代码,e.reason是错误原因。总之,处理器和 Opener 允许你自定义网络请求的行为,
URLError和HTTPError则帮助你处理请求中可能出现的错误情况。这些功能在实际网络请求和爬虫任务中都非常有用。
2 Beautiful Soup库
Beautiful Soup 是一个用于解析HTML和XML文档的Python库,它可以从网页中提取数据,操作文档树,并帮助你浏览和搜索文档的不同部分。它能够帮助你处理标签、属性、文本内容等,使得数据提取和处理变得更加方便。
Beautiful Soup 是一个强大的Python库,用于解析HTML和XML文档,提取其中的数据。以下是一些 Beautiful Soup 常用的语法和方法:
from bs4 import BeautifulSoup# HTML 示例
html = """
<html>
<head>
<title>Sample HTML</title>
</head>
<body>
<p class="intro">Hello, Beautiful Soup</p>
<p>Another paragraph</p>
<a href="https://www.example.com">Example</a>
</body>
</html>
"""# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html, "html.parser")# 节点选择器
intro_paragraph = soup.p
print("Intro Paragraph:", intro_paragraph)# 方法选择器
another_paragraph = soup.find("p")
print("Another Paragraph:", another_paragraph)# CSS 选择器
link = soup.select_one("a")
print("Link:", link)# 获取节点信息
text = intro_paragraph.get_text()
print("Text:", text)# 获取节点的属性值
link_href = link["href"]
print("Link Href:", link_href)# 遍历文档树
for paragraph in soup.find_all("p"):print(paragraph.get_text())# 获取父节点
parent = intro_paragraph.parent
print("Parent:", parent)# 获取兄弟节点
sibling = intro_paragraph.find_next_sibling()
print("Next Sibling:", sibling)# 使用 CSS 选择器选择多个节点
selected_tags = soup.select("p.intro, a")
for tag in selected_tags:print("Selected Tag:", tag)# 修改节点文本内容
intro_paragraph.string = "Modified Text"
print("Modified Paragraph:", intro_paragraph)# 添加新节点
new_paragraph = soup.new_tag("p")
new_paragraph.string = "New Paragraph"
soup.body.append(new_paragraph)# 移除节点
link.extract()
print("Link Extracted:", link)
3 使用代理
3.1 代理种类 HTTP、HTTPS 和 SOCKS5
- HTTP代理: 用于HTTP协议的代理,适用于浏览网页等HTTP请求。
- HTTPS代理: 用于HTTPS协议的代理,能够处理加密的HTTPS请求。
- SOCKS5代理: 更通用的代理协议,支持TCP和UDP流量,适用于各种网络请求。
抓取免费代理:
可以使用爬虫技术从免费代理网站获取代理IP和端口。
使用付费代理:
付费代理通常提供更稳定和更快速的连接,适用于需要高质量代理的情况。
3.2 使用 urllib 和 requests 库使用代理
urllib:
import urllib.requestproxy_handler = urllib.request.ProxyHandler({'http': 'http://proxy.example.com:8080'})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('https://www.example.com')
requests:
import requestsproxies = {'http': 'http://proxy.example.com:8080'}
response = requests.get('https://www.example.com', proxies=proxies)
3.3 案例:自建代理池
import requests
from bs4 import BeautifulSoup
import random# 获取代理IP列表
def get_proxies():proxy_url = "https://www.example.com/proxy-list"response = requests.get(proxy_url)soup = BeautifulSoup(response.text, "html.parser")proxies = [proxy.text for proxy in soup.select(".proxy")]return proxies# 从代理池中随机选择一个代理
def get_random_proxy(proxies):return random.choice(proxies)# 使用代理发送请求
def send_request_with_proxy(url, proxy):proxies = {'http': proxy, 'https': proxy}response = requests.get(url, proxies=proxies)return response.textif __name__ == "__main__":proxy_list = get_proxies()random_proxy = get_random_proxy(proxy_list)target_url = "https://www.example.com"response_content = send_request_with_proxy(target_url, random_proxy)print(response_content)
这个案例演示了如何从代理池中随机选择一个代理,并使用选定的代理发送请求。请注意,示例中的URL和方法可能需要根据实际情况进行修改。
这些概念和示例可以帮助你了解如何使用代理,从而在网络爬虫或请求中保护你的身份和数据。
4 实战 提取视频信息并进行分析
import urllib.request
from bs4 import BeautifulSoup# 定义目标网页的 URL
url = 'https://www.example.com/videos'# 定义代理(如果需要使用代理)
proxies = {'http': 'http://proxy.example.com:8080'}# 发起请求,使用代理
req = urllib.request.Request(url, headers={'User-Agent': 'Mozilla/5.0'})
response = urllib.request.urlopen(req, proxies=proxies)# 解析网页内容
soup = BeautifulSoup(response, 'html.parser')# 创建一个空的视频列表
videos = []# 获取视频信息
video_elements = soup.find_all('div', class_='video')
for video_element in video_elements:title = video_element.find('h2').textvideo_link = video_element.find('a', class_='video-link')['href']videos.append({'title': title, 'video_link': video_link})# 输出提取到的视频信息
for video in videos:print(f"Title: {video['title']}")print(f"Video Link: {video['video_link']}")print()# 对视频信息进行分析
num_videos = len(videos)
print(f"Total Videos: {num_videos}")
在这个实例中,我们假设目标网页包含多个视频的信息,每个视频都有标题和视频链接。我们使用
urllib库获取网页内容,然后使用Beautiful Soup解析页面,从中提取视频的标题和链接。最后,我们输出提取到的视频信息并对其进行简单的分析,计算视频的数量。请注意,这个实例仅用于演示基本的数据提取和分析概念。在实际应用中,你可能需要根据目标网页的结构和内容,调整代码以适应实际情况。
相关文章:
)
【100天精通python】Day43:python网络爬虫开发_爬虫基础(urlib库、Beautiful Soup库、使用代理+实战代码)
目录 1 urlib 库 2 Beautiful Soup库 3 使用代理 3.1 代理种类 HTTP、HTTPS 和 SOCKS5 3.2 使用 urllib 和 requests 库使用代理 3.3 案例:自建代理池 4 实战 提取视频信息并进行分析 1 urlib 库 urllib 是 Python 内置的标准库,用于处理URL、发送…...
Linux:安全技术与防火墙
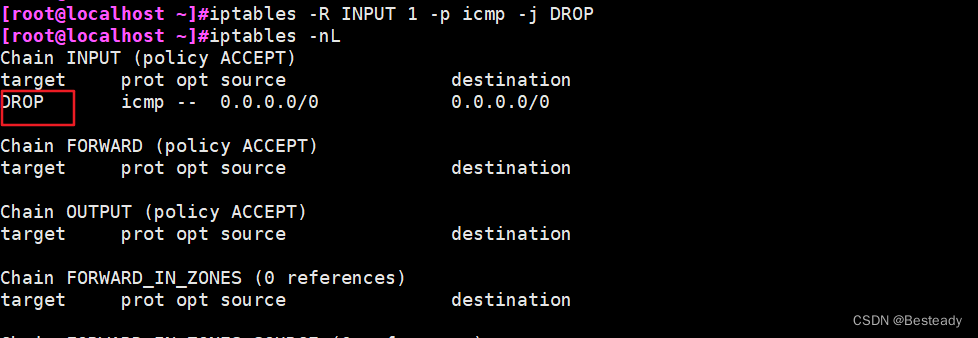
目录 一、安全技术 1.安全技术 2.防火墙的分类 3.防水墙 4.netfilter/iptables关系 二、防火墙 1、iptables四表五链 2、黑白名单 3.iptables命令 3.1查看filter表所有链 iptables -L 编辑3.2用数字形式(fliter)表所有链 查看输出结果 iptables -nL 3.3 清空所有链…...

Confluent kafka 异常退出rd_tmpabuf_alloc0: rd kafka topic info_new_with_rack
rd_tmpabuf_alloc0: rd kafka topic info_new_with_rack 根据网上的例子,做了一个测试程序。 C# 操作Kafka_c# kafka_Riven Chen的博客-CSDN博客 但是执行下面一行时,弹出上面的异常,闪退。 consumer.Subscribe(queueName) 解决方案&…...
最新ChatGPT网站程序源码+AI系统+详细图文搭建教程/支持GPT4.0/AI绘画/H5端/Prompt知识库
一、前言 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...

chatGPT-对话柏拉图
引言: 古希腊哲学家柏拉图,在他的众多著作中,尤以《理想国》为人所熟知。在这部杰作中,他勾勒了一个理想的政治制度,提出了各种政体,并阐述了他对于公正、智慧以及政治稳定的哲学观点。然而,其…...
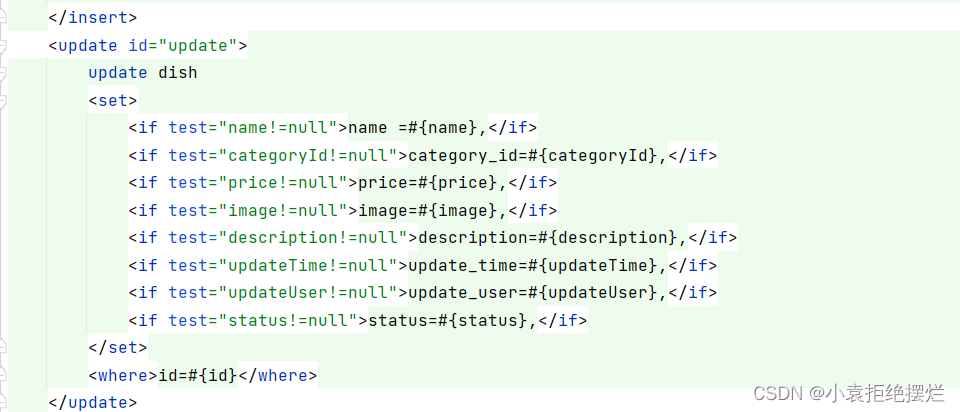
Java项目-苍穹外卖-Day04
公共字段自动填充 这些字段在每张表基本都有,手动进行填充效率低,且后期维护更改繁琐 使用到注解AOP主要 先答应一个AutoFill注解 再定义一个切面类进行通知 对应代码 用到了枚举类和反射 package com.sky.aspect; /*** 自定义切面类,…...

SQL递归获取完整的树形结构数据
在 SQL 中,WITH RECURSIVE 用于创建递归查询,它允许在查询中引用自身。这种查询通常用于处理具有层次结构的数据,例如树形结构。 以下是使用 WITH RECURSIVE 创建递归查询的一般语法: WITH RECURSIVE [alias] ([column1], [colu…...

如何使用营销活动,提升小程序用户的参与度
在当今数字化时代,小程序已成为企业私域营销的重要一环。然而,仅仅拥有小程序还不足以吸引用户的兴趣和参与。营销活动作为推动用户参与的有效手段,可以在激烈的市场竞争中脱颖而出。本文将深入探讨如何使用营销活动,提升小程序用…...
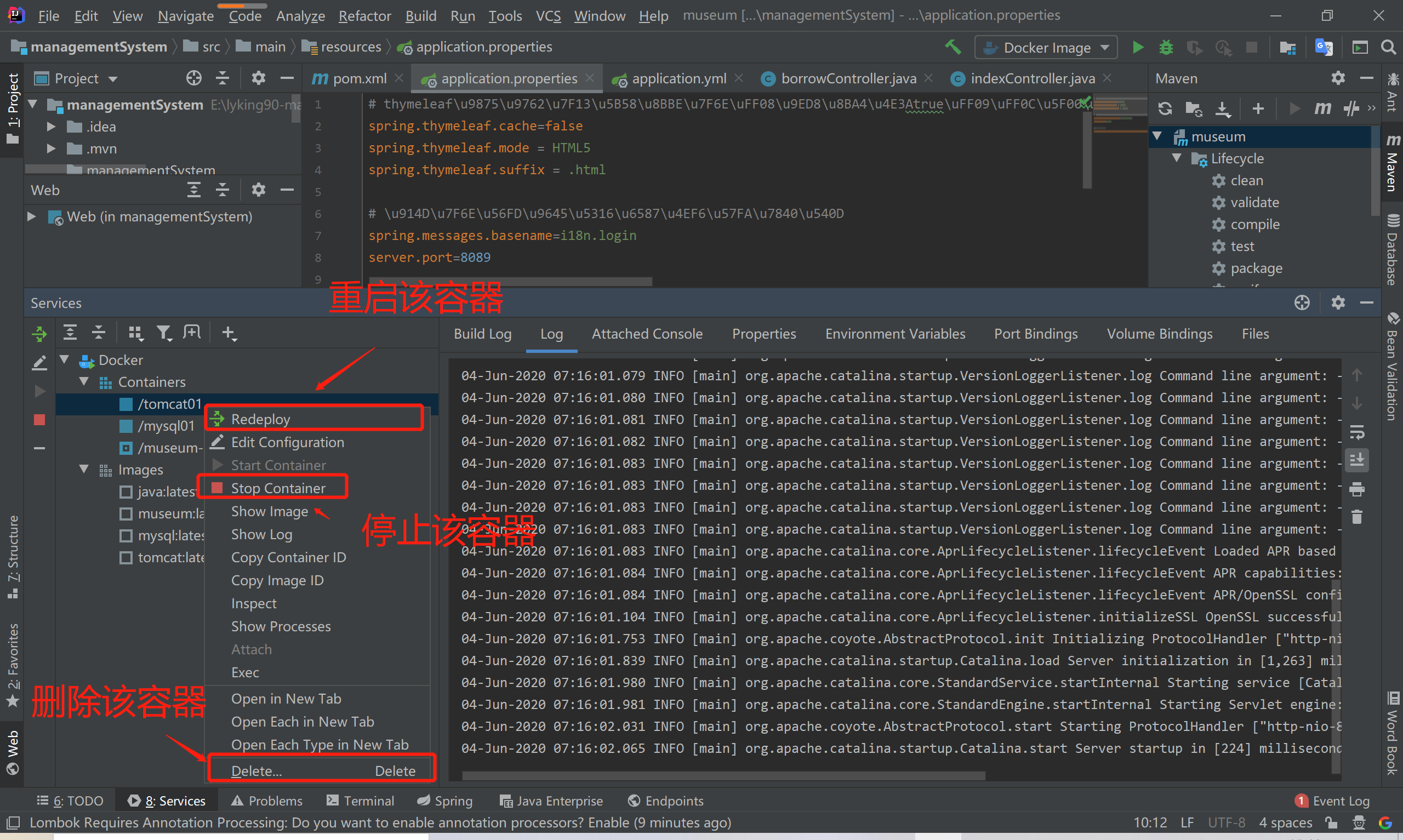
IDEA中使用Docker插件构建镜像并推送至私服Harbor
一、开启Docker服务器的远程访问 1.1 开启2375远程访问 默认的dokcer是不支持远程访问的,需要加点配置,开启Docker的远程访问 # 首先查看docker配置文件所在位置 systemctl status docker# 会输出如下内容: ● docker.service - Docker Ap…...

第7章 高性能门户首页构建
mini商城第7章 高性能门户首页构建 一、课题 高性能门户建设 二、回顾 1、了解文件存储系统的概念 2、了解常用文件服务器的区别 3、掌握Minio的应用 三、目标 1、OpenResty 百万并发站点架构 OpenResty 特性介绍 搭建OpenResty Web站点动静分离方案剖析 2、多级缓存架…...
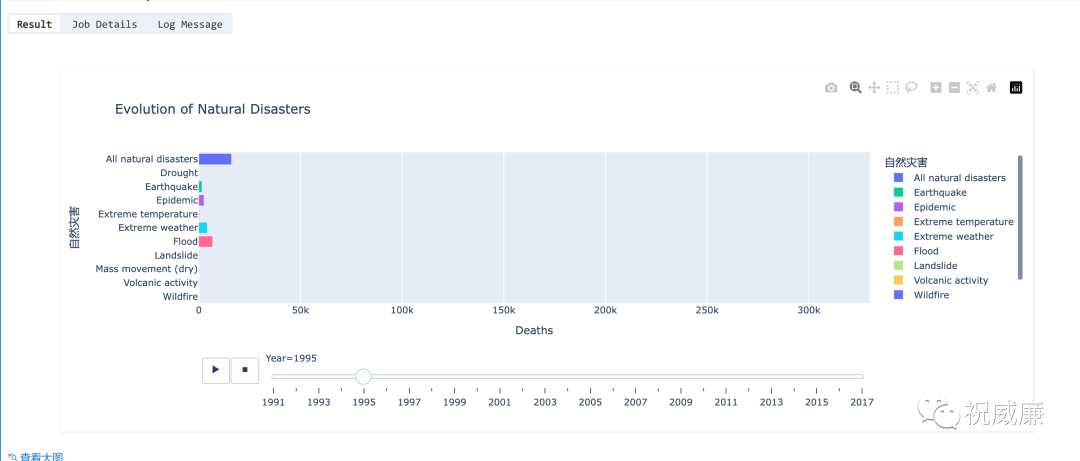
用加持了大模型的 Byzer-Notebook 做数据分析是什么体验
Byzer-Notebook 是专门为 SQL 而研发的一款 Web Notebook。他的第一公民是 SQL,而 Jupyter 则是是以 Python 为第一公民的。 随着 Byzer 引擎对大模型能力的支持日渐完善, Byzer-Notebook 也在不自觉中变得更加强大。我和小伙伴在聊天的过程中才发现他已…...
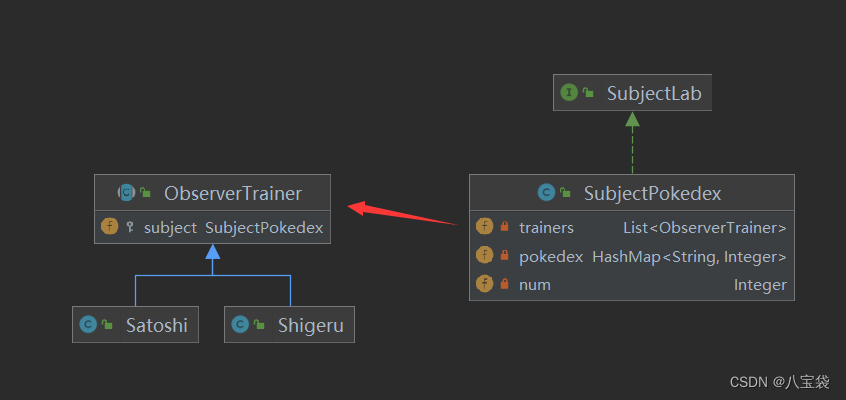
学习设计模式之观察者模式,但是宝可梦
前言 作者在准备秋招中,学习设计模式,做点小笔记,用宝可梦为场景举例,有错误欢迎指出。 观察者模式 观察者模式定义了一种一对多的依赖关系,一个对象的状态改变,其他所有依赖者都会接收相应的通知。 所…...
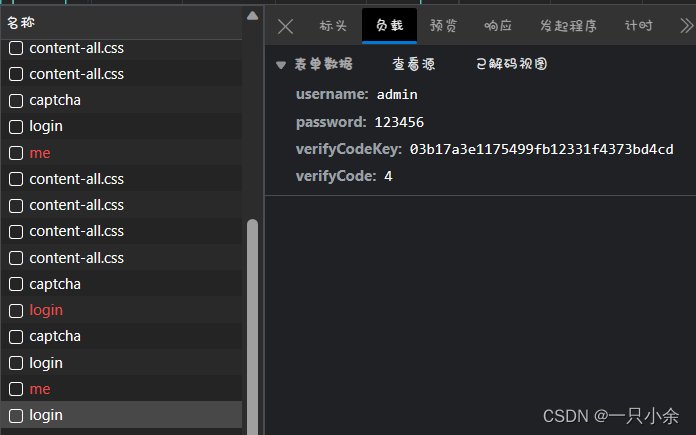
课程项目设计--spring security--用户管理功能--宿舍管理系统--springboot后端
写在前面: 还要实习,每次时间好少呀,进度会比较慢一点 本文主要实现是用户管理相关功能。 前文项目建立 文章目录 验证码功能验证码配置验证码生成工具类添加依赖功能测试编写controller接口启动项目 security配置拦截器配置验证码拦截器 …...
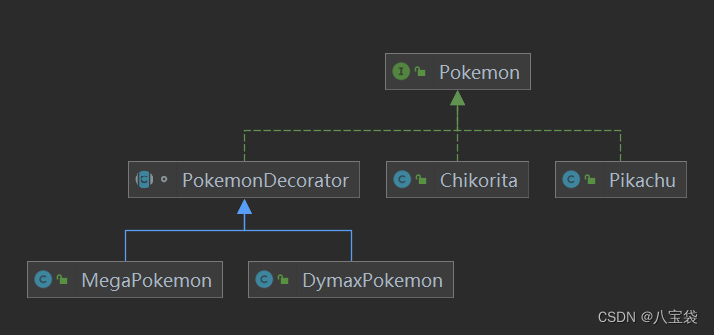
学习设计模式之装饰器模式,但是宝可梦
装饰模式 为了不改变组件的结构,动态地扩展其功能。 通常,扩展功能通过子类进行,但是继承的方式具有静态特征,耦合度高。 意图:动态地给对象添加额外的功能 主要解决:继承方式是静态特征,扩…...
【AWS】创建IAM用户;无法登录IAM用户怎么办?错误提示:您的身份验证信息错误,请重试(已解决)
目录 0.背景问题分析 1.解决步骤 0.背景问题分析 windows 11 ,64位 我的问题情景: 首先我创建了aws的账户,并且可以用ROOT用户登录,但是在登录时选择IAM用户,输入ROOT的名字和密码,就会提示【您的身份验证…...
微服务基础知识
文章目录 微服务基础知识一、系统架构的演变1、单体应用架构2、垂直应用架构3、分布式SOA架构(1)什么是SOA(2)SOA架构 4、微服务架构5、SOA和微服务的关系(1)SOA(2)微服务架构 二、分…...

倒残差结构
倒残差结构: 倒残差结构是MobileNetV2中引入的一种设计,用于增强网络的表达能力和特征提取能力,同时保持轻量级的特点。它的核心思想是在每个瓶颈块中,先使用一个扩张卷积(Dilated Convolution)&#x…...

Docker的基本使用
Docker 概念 Docker架构 docker分为客户端,Docker服务端,仓库 客户端 Docker 是一个客户端-服务器(C/S)架构程序。Docker 客户端只需要向 Docker 服务端发起请求,服务端将完成所有的工作并返回相应结果。 Docker …...

paddlenlp安装踩坑记录
错误1 ModuleNotFoundError: No module named paddle.metric我下载paddlepaddle-gpu2.5.0.post117解决了,最开始下载的2.5.1报错,post后面的117是我的cuda版本,不要写你对应的版本号 python3 -m pip install paddlepaddle-gpu2.5.0.post117…...

微服务流程引擎:简单又灵活,实现流程全生命周期管理!
伴随着日益激烈的市场竞争,传统的办公操作已经无法满足发展需要了。如果采用微服务流程引擎加油助力,就可以帮助企业更好地管理数据资源,高效做好各种表单制作,实现高效率办公。流辰信息以市场为导向,用心钻研低代码技…...

利用Taotoken快速为不同编程语言生成AI调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken快速为不同编程语言生成AI调用示例 在构建现代应用时,全栈开发者常常需要在前端、后端、CLI工具等多个技术…...

基于MCP协议与AI的智能收据处理服务器:从OCR到结构化提取实战
1. 项目概述:一个专为收据处理而生的MCP服务器如果你经常需要处理各种格式的收据、发票或账单,无论是个人记账、公司报销,还是财务审计,那么你肯定对“数据录入”这个繁琐环节深恶痛绝。一张张纸质或电子收据,上面的关…...

Meta与斯坦福:字节级AI实现逐字节生成瓶颈突破与速度提升能力
这项由Meta人工智能基础研究团队(FAIR at Meta)与斯坦福大学、华盛顿大学联合开展的研究,于2026年5月发表,论文预印本编号为arXiv:2605.08044v1。感兴趣的读者可以通过该编号在arXiv平台上查阅完整论文。现代语言模型的工作方式&a…...

AI治理实战:从公平性、可解释性到MLOps全流程落地
1. 项目概述与核心价值最近在整理开源项目时,发现了一个名为“AI_governance”的仓库,作者是bhavya7995。这个标题立刻引起了我的兴趣。在AI技术飞速渗透到各行各业,从代码生成到内容创作,从自动驾驶到医疗诊断的今天,…...

再不碰数字化,文科生简历可能连初筛都过不了
我学的是汉语言文学,大四投简历那段时间,整整两个月只收到了三个面试通知。其中一个HR在电话里很直接地说:“你的文字功底不错,但我们这个岗位需要处理数据、会用AI工具,你简历上看不到相关经历。”电话挂掉之后&#…...

终极换肤方案:R3nzSkin国服特供版完整使用指南
终极换肤方案:R3nzSkin国服特供版完整使用指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤&#x…...

告别300MB限制!用ZotFile插件+坚果云,打造你的免费Zotero文献同步方案
告别300MB限制!用ZotFile插件坚果云打造高效文献同步方案 在学术研究的日常中,文献管理工具Zotero无疑是许多人的得力助手。然而,免费账户仅有的300MB存储空间,对于需要处理大量PDF文献的研究者来说,往往显得捉襟见肘。…...

终极免费图片去重神器:AntiDupl.NET 完全指南,快速清理重复图片释放硬盘空间
终极免费图片去重神器:AntiDupl.NET 完全指南,快速清理重复图片释放硬盘空间 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑中堆…...

别再只会用ActivePart了!CATIA二次开发中,如何用C#递归遍历任意复杂结构树?
CATIA二次开发进阶:用C#递归算法征服任意复杂装配树 在CATIA二次开发领域,ActivePart就像新手司机的自动挡——简单易用却限制重重。当面对包含数百个零件的飞机发动机装配体,或是横跨多个产品的汽车底盘系统时,仅能操作当前激活零…...

告别付费困扰:Linux与Windows双平台免费获取Typora全攻略
1. Typora收费后的免费替代方案 Typora作为一款广受欢迎的Markdown编辑器,突然宣布收费让很多用户措手不及。作为一名长期使用Typora的技术写作者,我完全理解大家的心情。好消息是,我们完全可以在不违反软件许可协议的前提下,继续…...