【Django】Task4 序列化及其高级使用、ModelViewSet
【Django】Task4 序列化及其高级使用、ModelViewSet
Task4主要了解序列化及掌握其高级使用,了解ModelViewSet的作用,ModelViewSet 是 Django REST framework(DRF)中的一个视图集类,用于快速创建处理模型数据的 API 视图。

1.Django的序列化
Django 的序列化是指将复杂的数据结构(通常是数据库中的模型对象)转换为可以在不同应用程序间传输和存储的格式,如 JSON、XML 或类似的格式。这使得数据可以在不同系统、平台或前后端之间进行交换和共享。
在 Django 中,序列化主要用于处理以下两个场景:
数据交换和传输: 当您需要在应用程序的不同部分之间传递数据时,例如在后端和前端之间,或在不同的服务之间,您可以将数据序列化为一种通用格式,如 JSON。这样,数据可以在不同系统之间传输和解析。
API 响应: 在开发 Web API 时,您通常会需要将数据库中的数据转换为特定的数据格式(如 JSON),以便客户端可以轻松地消费数据。这就涉及到将 Django 模型对象序列化为 JSON 或其他格式,然后将其返回给客户端。
Django 提供了一个内置的序列化框架,称为 Django REST framework(DRF),它是一个功能强大的工具,用于处理序列化和反序列化。使用 DRF,您可以轻松地将 Django 模型转换为 JSON 格式,或者从 JSON 格式反序列化回模型对象。
1.1序列化常用到的参数
在 Django REST framework 中,进行序列化时,常用的一些参数可以用来控制序列化的行为和输出。以下是一些常用的序列化参数:
fields: 用于指定要序列化的字段列表。您可以选择性地列出要包含在序列化输出中的字段。
exclude: 与 fields 相反,用于指定不包含在序列化输出中的字段列表。
read_only_fields: 用于指定在反序列化(从 JSON 到模型对象)时不允许更新的字段列表。这些字段只能在创建时指定,之后不能更改。
write_only_fields: 与 read_only_fields 相反,用于指定在序列化(从模型对象到 JSON)时不包含在输出中的字段列表。这些字段只用于接收输入。
validators: 用于指定字段级别的验证器列表,这些验证器会在序列化和反序列化过程中执行。
extra_kwargs: 允许您为特定字段提供附加参数,例如指定自定义验证器或者控制序列化行为。
many: 用于指示是否进行批量序列化。如果为 True,则序列化器将在序列化多个对象时执行批量操作。
allow_null: 用于指示是否允许序列化字段的值为 None,默认为 False。
required: 用于指示字段是否为必填字段,如果为 True,则在反序列化时必须提供该字段的值。
default: 用于指定字段的默认值,在反序列化时,如果未提供该字段的值,将使用默认值。
source: 用于指定要从模型中获取数据的字段名称。如果序列化器的字段名称与模型字段名称不同,可以使用该参数来指定模型字段的名称。
label: 用于指定字段在序列化输出中的标签,用于更友好的展示字段名称。
这只是一些常见的序列化参数,Django REST framework 提供了丰富的选项和配置,以满足不同的序列化需求。您可以根据具体的情况选择适当的参数来定制您的序列化器。
1.2序列化示例
以下是一个简单的示例,说明如何使用 DRF 进行序列化:
- serializer.py
# 定义产品序列化器
from rest_framework.serializers import *
from .models import *# 产品分类序列化器
class GoodsCategorySerializer(ModelSerializer):class Meta:model = GoodsCategoryfields = ('name', 'remark')# 产品序列化器
class GoodsSerializer(ModelSerializer):# 外键字段相关的数据 需要单独序列化category = GoodsCategorySerializer()class Meta:model = Goods# 序列化单个字段fields = ('name',)# 序列化多个字段fields = ('name','number',)# 序列化所有字段fields = '__all__'在这个示例中,我们定义了名为 GoodsCategorySerializer、GoodsSerializer 的序列化器,用于将 GoodsCategory、Goods 模型转换为 JSON 格式。通过 serializers.ModelSerializer 类,我们可以很方便地将模型字段映射到序列化器的字段,并使用 Meta 类来指定要序列化的模型和字段。
总之,Django 的序列化是将复杂的数据转换为通用数据格式的过程,用于数据交换、API 响应等场景。Django REST framework 提供了强大的序列化框架,使数据的转换和传输变得更加简便。
- views.py
from django.shortcuts import render
from rest_framework.response import Response
from .models import *
from rest_framework.decorators import api_view
from django.shortcuts import get_object_or_404
from rest_framework.views import APIView
from .serializer import *class GetGoods(APIView):def get(self, request):data = Goods.objects.all()serializer = GoodsSerializer(instance=data, many=True)print(serializer.data)return Response(serializer.data)def post(self, request):# 从请求数据中提取字段request_data = {"category": request.data.get("Goodscategory"),"number": request.data.get("number"),"name": request.data.get("name"),"barcode": request.data.get("barcode"),"spec": request.data.get("spec"),"shelf_life_days": request.data.get("shelf_life_days"),"purchase_price": request.data.get("purchase_price"),"retail_price": request.data.get("retail_price"),"remark": request.data.get("remark"),}# 使用 create() 方法创建新的商品对象new_goods = Goods.objects.create(**request_data)# 对创建的对象进行序列化,并作为响应返回serializer = GoodsSerializer(instance=new_goods)return Response(serializer.data)
- urls.py
from django.contrib import admin
from django.urls import path
from apps.erp_test.views import *urlpatterns = [path('admin/', admin.site.urls),path('getgoods/', GetGoods.as_view()),
]
1.3序列化单个对象
#获取对象
data = Goods.objects.get(id=1)#创建序列化器
sberializer = GoodsSerializer(instance=data)#转换数据
print(serializer.data)
注意点:
instance是一个参数,用于指定要序列化或反序列化的 Python 对象。具体来说,它是一个类实例(Class Instance),通常是指一个从数据库或其他数据源中检索出来的模型实例(Model Instance)。
当我们需要将一个模型实例转换为 JSON 或其他格式时,可以使用 Django 的序列化器(Serializer)来实现。
1.4序列化多个对象
data = Goods.objects.all() # 获取对象# 创建序列化器,many表示序列化多个对象,默认为单个
serializer = GoodsSerializer(instance=data,many=True)print(serializer.data) # 转换数据# 输出:
[OrderedDict([('id', 1), ('number', '1'), ('name', '第一个产品'), ('purchase_price', 100.0), ('retail_price', 150.0), ('remark', '测试产品')]), OrderedDict([('id', 2), ('number', '123'), ('name', '产品2'), ('purchase_price', 123.0), ('retail_price', 4123.0), ('remark', '测试产品2')])]
2.Django的ModelViewSet
ModelViewSet 是 Django REST framework(DRF)中的一个视图集类,用于快速创建处理模型数据的 API 视图。它提供了一组默认的 CRUD(创建、读取、更新、删除)操作,可以用于操作 Django 模型中的数据。
ModelViewSet 通过将常见的 API 操作封装到一个类中,使得编写 API 视图变得更加简洁和方便。它继承自 DRF 中的 GenericAPIView,并结合了 ListModelMixin、CreateModelMixin、RetrieveModelMixin、UpdateModelMixin 和 DestroyModelMixin,从而提供了一系列用于处理模型数据的默认操作。
2.1ModelViewSet示例
以下是一个使用 ModelViewSet 的简单示例:
from rest_framework import viewsets
from .models import Book
from .serializers import BookSerializerclass BookViewSet(viewsets.ModelViewSet):queryset = Book.objects.all()serializer_class = BookSerializer
在这个示例中,假设有一个名为 Book 的模型和相应的序列化器 BookSerializer。通过创建一个继承自 ModelViewSet 的 BookViewSet 类,您可以自动获得以下操作:
| 知识点 | 请求 | url | 特点 |
|---|---|---|---|
| GenericViewSet | 提供一组通用的视图方法,方便实现特定功能 | ||
| ListModelMixin | get | 127.0.0.1:8000/book/ | 提供 list 方法,用于获取资源列表 |
| RetrieveModelMixin | get | 127.0.0.1:8000/book/{1}/ | 提供 retrieve 方法,用于获取单个资源的详细信息 |
| CreateModelMixin | post | 127.0.0.1:8000/book/ | 提供 create 方法,用于创建资源 |
| UpdateModelMixin | put | 127.0.0.1:8000/book/{1}/ | 提供 update 方法,用于更新资源 |
| DestroyModelMixin | detete | 127.0.0.1:8000/book/{1}/ | 提供 destroy 方法,用于删除资源 |
| 自定义 | get/post | 127.0.0.1:8000/book/自定义 | 用户自定义方法/函数 |
这些技术知识点可以配合使用,帮助我们快速构建出具有 CRUD 功能的 Web 应用,并且遵循了 Django 框架的惯例和最佳实践。它们的应用场景包括博客系统、电商平台、社交网络等各种类型的 Web 应用。通过使用这些技术知识点,我们能够提高开发效率,减少重复的代码编写工作,并且保证代码的一致性和可维护性。
列出所有图书:GET 请求将返回所有图书的列表。
创建新图书:POST 请求将创建一个新的图书。
获取单个图书:GET 请求将返回指定图书的详细信息。
更新图书:PUT 或 PATCH 请求将更新指定图书的信息。
删除图书:DELETE 请求将删除指定图书。
ModelViewSet 还允许您通过覆盖一些方法来自定义行为,例如覆盖 get_queryset() 来定义自己的查询集,或者覆盖 perform_create() 来在创建对象时执行自定义操作。
总之,ModelViewSet 是 Django REST framework 中的一个有用的工具,用于快速创建处理模型数据的 API 视图,并且提供了一系列默认操作,减少了繁琐的代码编写。
补充上述图书curd中的Book模型和序列化器
定义 Book 模型:
from django.db import modelsclass Book(models.Model):title = models.CharField(max_length=200)author = models.CharField(max_length=100)publication_date = models.DateField()isbn = models.CharField(max_length=13)def __str__(self):return self.title
与 Book 模型对应的序列化器 BookSerializer:
from rest_framework import serializers
from .models import Bookclass BookSerializer(serializers.ModelSerializer):class Meta:model = Bookfields = '__all__'
在这个示例中,我们创建了一个名为 Book 的模型,其中包含了一些基本的字段,如标题、作者、出版日期和 ISBN 号。然后,我们创建了一个 BookSerializer,使用 serializers.ModelSerializer 类来定义序列化器。在 Meta 类中,我们将模型设置为 Book,并使用 fields = ‘all’ 来指定所有模型字段都会被包含在序列化输出中。
通过这样的设置,可以使用 BookSerializer 来序列化和反序列化 Book 模型的数据,从而在 API 视图中进行数据的展示和操作。
相关文章:
【Django】Task4 序列化及其高级使用、ModelViewSet
【Django】Task4 序列化及其高级使用、ModelViewSet Task4主要了解序列化及掌握其高级使用,了解ModelViewSet的作用,ModelViewSet 是 Django REST framework(DRF)中的一个视图集类,用于快速创建处理模型数据的 API 视…...

FFMPEG RTMP流打开速度慢优化方法一
先上使用方法: codec_ctx->flags | AVFMT_FLAG_NOBUFFER; AVFMT_FLAG_NOBUFFER 标记如果没有设置,就会导致打开时探测的数据包丢AVFormatContext的缓存区中。 播放的时候,就从这些数据包开始,但是整个探测过程时间可能较长&…...
)
NextJs - Middleware(中间件)
中间件允许您在请求完成之前运行代码。然后,根据传入的请求,您可以通过重写、重定向、修改请求或响应标头或直接响应来修改响应。 中间件在缓存内容和路由匹配之前运行。 使用规则 使用项目根目录中的文件 middleware.ts(或 .js)…...

记录几个Hudi Flink使用问题及解决方法
前言 如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下 版本 Flink 1.15.4Hudi 0.13.0 流写 流写…...
Go:测试框架GoConvey 简介
快速开始 GoConvey是一个完全兼容官方Go Test的测试框架,一般来说这种第三方库都比官方的功能要强大、更加易于使用、开发效率更高,闲话少说,先看一个example: package utils import (. "github.com/smartystreets/goconvey…...
JavaWeb-特殊文件(propertis与XML)
目录 Properties文件 一.properties介绍 二.properties使用 三.解决中文乱码问题 XML文件 一.XML介绍 二.XML文件的语法规则 三.XML的使用 Properties文件 一.properties介绍 1.什么是properties文件 Properties文件是一种常用的配置文件格式,用于存储键值…...
ffmpeg合并mp4视频文件
下载ffmpeg Download FFmpeg 2配置环境 右键此电脑-》属性-》高级系统设置 环境变量-》path 解压上面ffmpeg压缩包,找到bin目录,复制完整路径,添加到path环境变量中 测试ffmpeg ffmpeg合并MP4文件 创建一个文本文件,例如inpu…...

ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks使用分析
ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks使用分析 1 ATF的下载链接2 ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks处理流程2.1 ATF BL1/BL2 ufs_read_blocks2.2 ATF BL1/BL2 ufs_write_blocks 3 UFS System Model4 ufs_read_blocks/ufs_write_blocks详细分析4.1 ufs_re…...
Elasticsearch(十二)搜索---搜索匹配功能③--布尔查询及filter查询原理
一、前言 本节主要学习ES匹配查询中的布尔查询以及布尔查询中比较特殊的filter查询及其原理。 复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。 布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些…...
解决Windows下的docker desktop无法启动问题
以管理员权限运行cmd 报错: docker: error during connect: Post http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.40/containers/create: open //./pipe/docker_engine: The system cannot find the file specified. In the default daemon configuration on Windows,…...
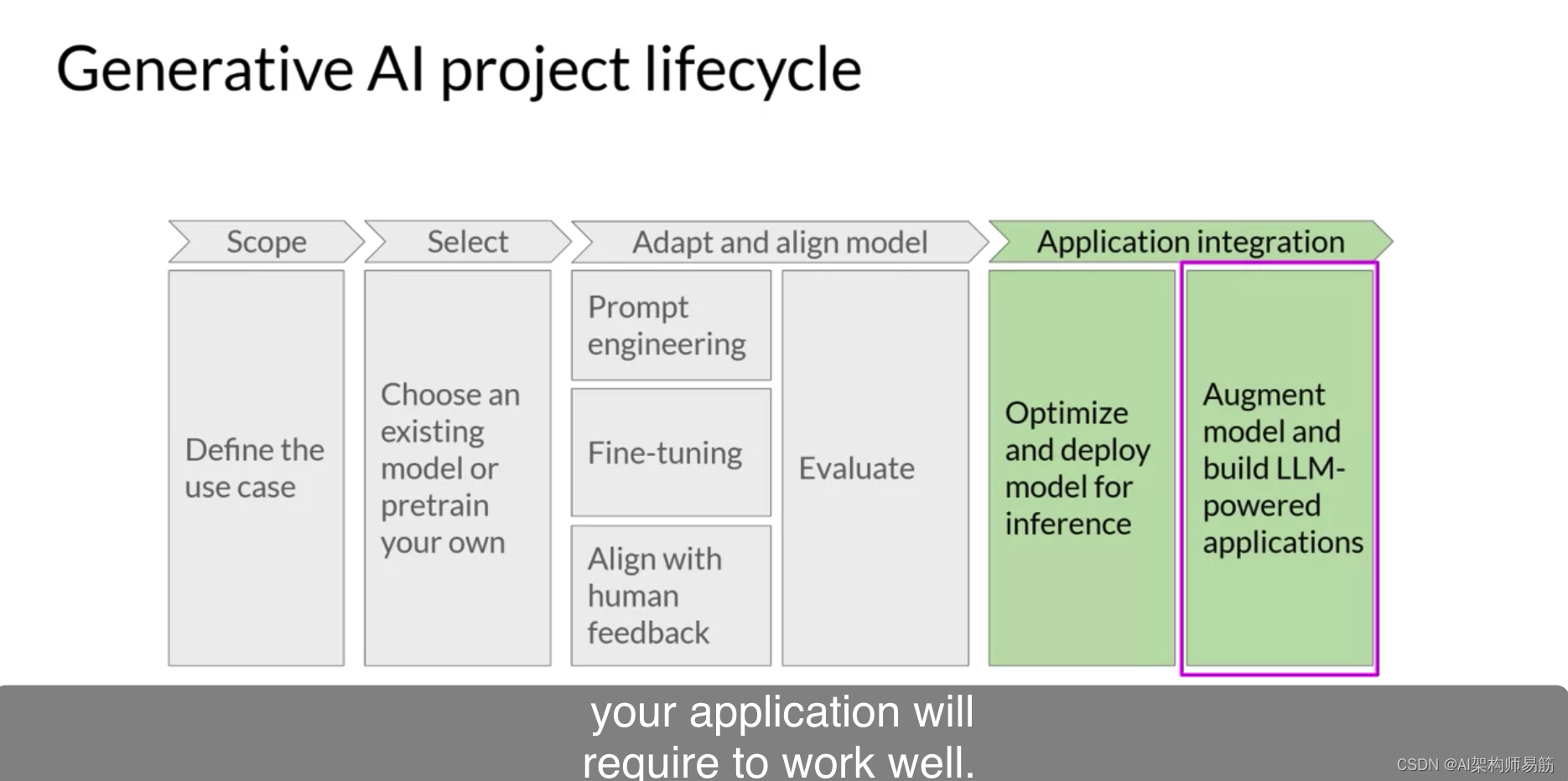
LLM生成式 AI 项目生命周期Generative AI project lifecycle
在本课程的其余部分中,您将学习开发和部署LLM驱动应用所需的技巧。在这个视频中,您将了解一个能帮助您完成此工作的生成式AI项目生命周期。此框架列出了从构思到启动项目所需的任务。到课程结束时,您应该对您需要做的重要决策、可能遇到的困难…...

java高并发系列 - 第13天:JUC中的Condition对象
java高并发系列 - 第13天:JUC中的Condition对象 java高并发系列第13篇文章 本文内容 synchronized中实现线程等待和唤醒Condition简介及常用方法介绍及相关示例使用Condition实现生产者消费者使用Condition实现同步阻塞队列Object对象中的wait(),notify()方法,用于线程等待…...

【TTY子系统】printf与printk深入驱动解析
tty子系统解析 tty子系统是一个庞大且复杂,也是内核维护者所头大的子系统。 At a first glance, the TTY layer wouldn’t seem like it should be all that challenging. It is, after all, just a simple char device which is charged with transferring byte-o…...

无涯教程-PHP - 全局变量函数
全局变量 与局部变量相反,可以在程序的任何部分访问全局变量。通过将关键字 GLOBAL 放置在应被识别为全局变量的前面,可以很方便地实现这一目标。 <?php$somevar15;function addit() {GLOBAL $somevar;$somevar;print "Somevar is $somevar";}addit(); ?> …...
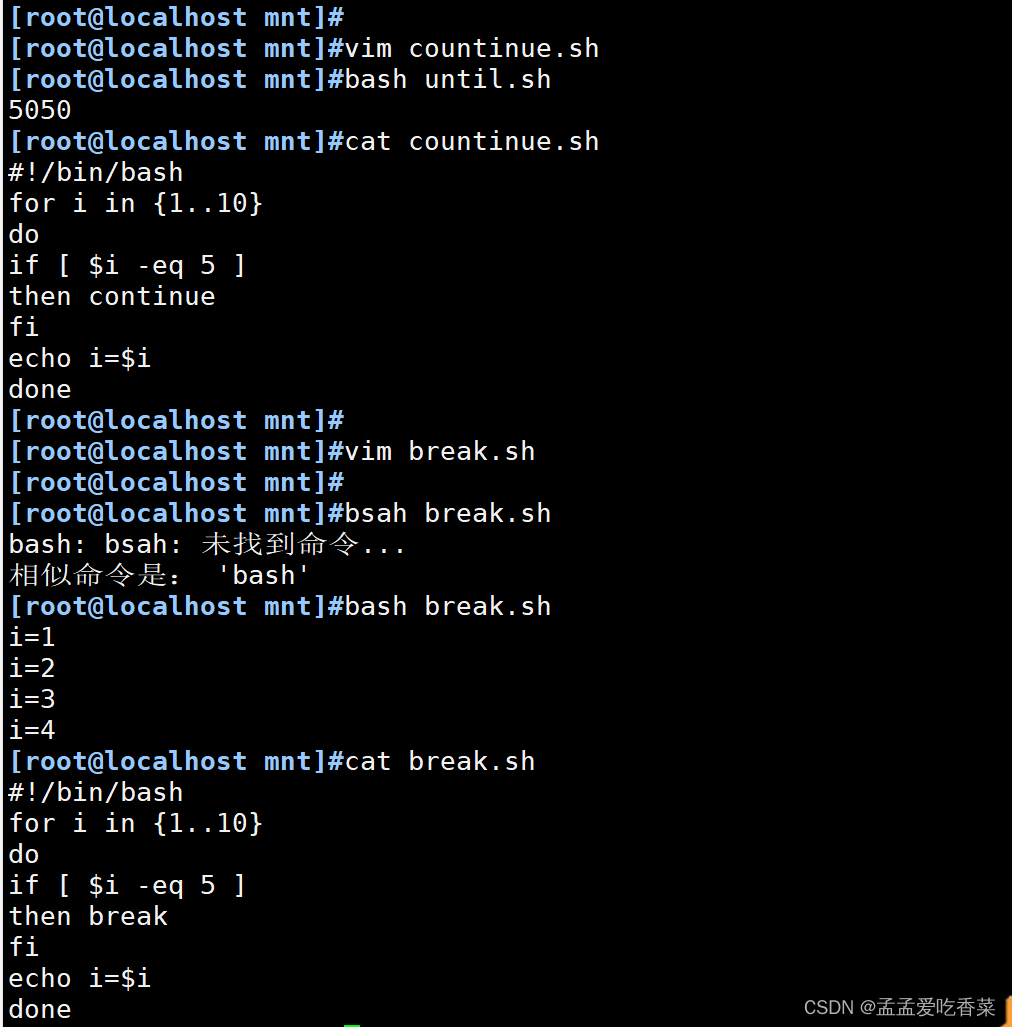
shell脚本之循环语句
循环语句 循环含义 将某代码段重复运行多次,通常有进入循环的条件和退出循环的条件 for循环语句 一般知道循环次数使用for循环 第一类 格式1: for名称 in 取值次数;do;done; 格式2: for 名称 in {取值列表} do done# 打印20次 for i i…...

派森 #P122. 峰值查找
描述 给定一个长度为n的列表nums,请你找到峰值并返回其索引。数组可能包含多个峰值,在这种情况下,返回任何一个所在位置即可。 (1)峰值元素是指其值严格大于左右相邻值的元素。严格大于即不能有等于; &…...

基础网络详解4--HTTP CookieSession 思考
一、cookie技术思考 一台多用户浏览器发起了三笔请求,将某款产品放入购物车中,A一次,选择了篮球;B两次,第一次选了足球,第二次选了钢笔。如何确认选择篮球、足球、钢笔的请求属于谁呢?如果不确认…...

14. 利用Canvas自制时钟组件
1. 说明 在自定义时钟组件时,使用到的基本控件主要是Canvas,在绘制相关元素时有两种方式:一种时在同一个canvas中绘制所有的部件元素,这样需要不断的对画笔和画布的属性进行保存和恢复,容易混乱;另一种就是…...
微信小程序使用云存储和Markdown开发页面
最近想在一个小程序里加入一个使用指南的页面,考虑到数据存储和减少页面的开发工作量,决定尝试在云存储里上传Markdown文件,微信小程序端负责解析和渲染。小程序端使用到一个库Towxml。 Towxml Towxml是一个可将HTML、Markdown转为微信小程…...
【C++】运算符重载 | 赋值运算符重载
Ⅰ. 运算符重载 引入 ❓什么叫运算符重载? 就是:运用函数,将现有的运算符重新定义,使其能满足各种自定义类型的运算。 回想一下,我们以前运算的对象是不是都是int、char这种内置类型? 那我们自定义的“…...

从PDCA到DevOps:构建可落地的持续改进框架与实践指南
1. 项目概述:一个关于持续改进的实践框架在软件工程、产品研发乃至个人成长的领域里,“持续改进”这个词我们听得耳朵都快起茧子了。几乎每个团队都在提敏捷、提DevOps、提精益,其核心思想都绕不开“持续改进”这四个字。但说实话,…...

抠图opencv有现成的开源DNN库
OpenCV 本身并没有像“专门用于抠图(图像分割/抠前景)”的 DNN 模型库,但它可以直接使用一些流行的 语义分割/实例分割 模型来完成抠图。这里我给你梳理一下思路和方案:1️⃣ OpenCV DNN 支持的分割模型OpenCV 的 dnn 模块可以加载…...

ARM架构SCTLR_EL1寄存器详解与配置指南
1. ARM架构中的SCTLR_EL1寄存器概述在ARMv8/v9架构中,系统控制寄存器(System Control Register)是处理器核心的关键配置组件,而SCTLR_EL1作为异常级别1(EL1)的系统控制寄存器,承担着管理系统行为…...

本地AI大模型API网关部署指南:从Ollama到OpenAI兼容接口
1. 项目概述:当本地AI大模型遇上API网关如果你和我一样,是个喜欢折腾本地AI部署的开发者,最近可能被一个词刷屏了:LocalAIPilot。简单来说,它不是一个具体的AI模型,而是一个将本地运行的大型语言模型&#…...

开源工具picprose:AI驱动的图片处理与文案生成一体化解决方案
1. 项目概述与核心价值最近在折腾个人博客和内容创作时,我遇到了一个挺普遍但又很烦人的问题:手头有一堆图片,但要么尺寸不合适,要么色调不统一,要么就是缺少一个能吸引眼球的标题。手动处理吧,费时费力&am…...

PPT数据可视化——从Excel表格到专业图表的5分钟蜕变之路
直接粘贴Excel表格就像"穿睡衣去面试"——内容都对,但看着不专业。 引言:那些年,我们被数据"丑哭"的瞬间 想象一下这个场景:你熬了三个通宵,终于把Q3季度的销售数据分析完了。Excel里密密麻麻的数字,每一行都准确无误。你信心满满地打开PPT,Ctrl+C…...

C++默认成员函数
构造函数构造函数是特殊的成员函数,需要注意的是,构造函数虽然名称叫构造,但是构造函数的主要任务并不是开空间创建对象(局部对象在栈帧创建时,空间就开好了),而是对象实例化时初始化对象。构造函数的本质是要替代我们…...

WorkshopDL终极指南:如何免费下载Steam创意工坊的1000+游戏模组
WorkshopDL终极指南:如何免费下载Steam创意工坊的1000游戏模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在GOG或Epic平台购买了游戏,却无法…...

从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学
从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学 当你从硬盘拷贝一个10GB的电影文件到内存时,系统监控显示CPU占用率几乎没变化——这似乎违背直觉。难道CPU真的在"摸鱼"?实际上,这背后…...

如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南
如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/…...